


Автор статьи: Рустем Галиев
IBM Senior DevOps Engineer & Integration Architect. Официальный DevOps ментор и коуч в IBM
Привет, Хабр! Это первая часть топика, где мы поговорим о Reliability в рамках практик SRE.
Давайте рассмотрим некоторые из сложных методов, которые SRE может принять и внедрить при разработке системы, способствующей повышению надежности. Некоторые из этих методов решают компромиссы по‑разному, так что последствия не являются значительными. Несколько новых методов и стратегий компенсируют неудачи.
Circuit Breaker
Обнаружение сбоев и инкапсуляция логики предотвращения постоянного повторения сбоя во время обслуживания, временного внешнего сбоя системы или непредвиденных проблем с системой. Используя основные принципы проектирования для надежности, SRE может обменять качество на задержку в шаблоне Circuit Breaker.
В типичной распределенной среде службы основаны на функциях, предоставляемых другими службами.
Как правило, SRE стараются избегать жестких зависимостей, чтобы вызывающая служба могла справиться с недоступностью вызываемой службы. Однако вызывающая сторона все равно должна подождать определенное время — тайм‑аут запроса — чтобы определить, что служба недоступна. В этом сценарии в игру вступает шаблон Circuit Breaker.
Обычно цепь разомкнута, и связь между вызывающим и вызываемым происходит так, как вы могли ожидать. Однако, если вызываемый недоступен, цепь замыкается. Каждый последующий запрос немедленно сообщает о недоступности службы и не требует ожидания тайм‑аута. По истечении периода, который определяется политикой, прерыватель проверяет, доступна ли базовая служба снова. В этом случае выключатель переключается обратно в открытое положение.

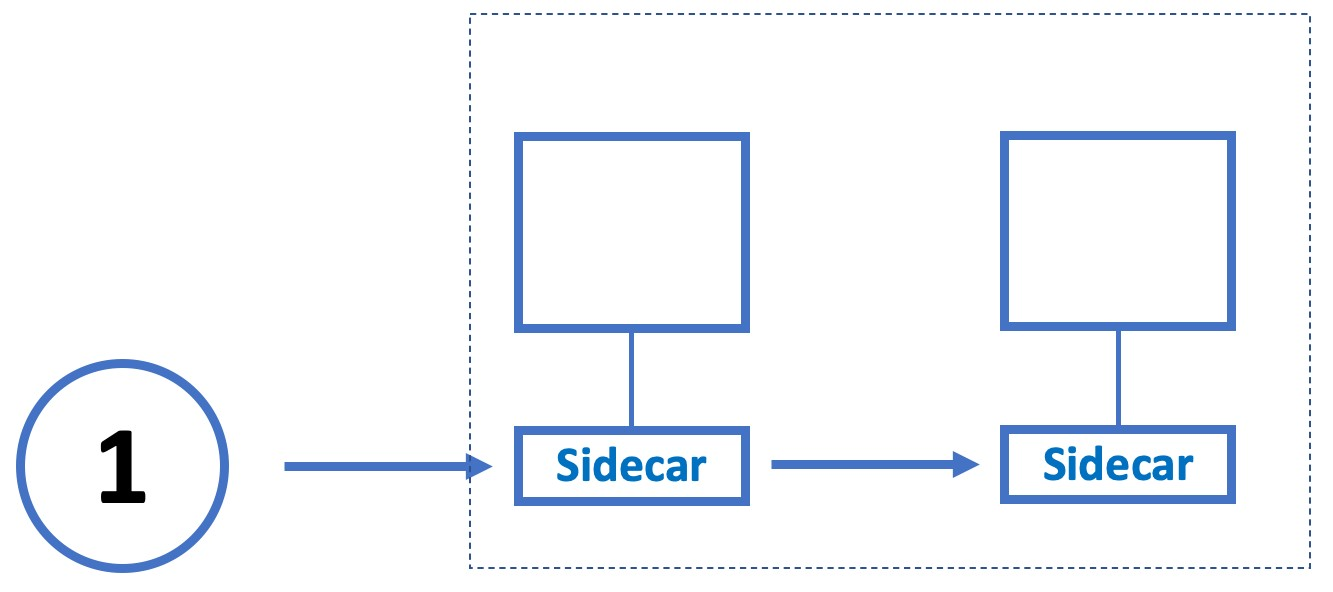
Sidecar
Включите плоскость управления (control plane) сервисной сеткой (service mesh) для обеспечения безопасности, контроля и наблюдения.
Сайдкары обрабатывают связь между сервисами. Вместо прямого обмена данными между службами, связь абстрагируется от отдельных служб и завершается сайдкаром.
При этом sidecar обрабатывает критически важные возможности, поэтому их не нужно обрабатывать в сервисном коде:
Балансировка нагрузки
Шифрование
Наблюдаемость
Отслеживаемость
Аутентификация и авторизация
Динамическая маршрутизация запросов
Стратегии развертывания и релиза, такие как канареечные релизы, A/B‑тестирование и сине‑зеленые деплои.
-
Поддержка паттерна circuit breaker
Таким образом, разработчики могут сосредоточиться на разработке, поддержке и обслуживании кода приложения. Операционные группы могут поддерживать сервисную сетку, а также развертывать и запускать приложение.
Exponential backoff
Размещайте повторяющиеся запросы или повторные передачи одного и того же блока данных, часто во избежание перегрузки ресурсов.
Когда разработчики разрабатывают код, им иногда нужен непрерывный расширяемый буфер. Примерами являются блоки памяти и блоки дискового пространства. Разработчики начинают выделять определенный объем буфера, но рано или поздно его становится недостаточно. Когда им нужно увеличить буфер, насколько они его увеличивают?
Для новых элементов достаточно одного очевидного ответа. Однако их, скорее всего, попросят снова увеличить буфер. Когда этого достаточно, это может привести к накладным расходам, потенциально O(n^2). Увеличивайте буферы экспоненциально, каждый раз удваивая размер буфера. Эта практика упрощает перераспределение неиспользуемого пространства операционной системой.

Waterfall
Запустите несколько экземпляров транзакции и используйте один результат, отбрасывая другие ответы.
В некоторых случаях допустимо выполнять одну и ту же транзакцию несколько раз. Стратегия надежности может состоять в том, чтобы запустить несколько экземпляров транзакции, а затем выбрать лучший ответ для обслуживания клиента. Как решить, какой ответ выбрать, может быть основан на различных предпочтениях, таких как первый возвращенный результат или результат с лучшим качеством.
Реализация требует, чтобы транзакция была идемпотентной: идемпотентная операция не имеет дополнительного эффекта, если она вызывается более одного раза с одними и теми же входными параметрами. Хотя операции GET обычно идемпотентны по своей структуре, другие операции, такие как POST или PUT, требуют большей осторожности. Один из подходов заключается в использовании уникального идентификатора для каждой операции. Бэкенд‑система сначала проверяет, была ли обработана транзакция с тем же идентификатором. Если транзакция не была завершена, система запускает транзакцию.

Partitioning или “Sharding”
Разделите рабочую нагрузку на отдельные независимые части, чтобы повысить доступность и производительность. Раздел — это разделение логической базы данных или ее составных элементов на отдельные независимые части. Разделение базы данных обычно выполняется для обеспечения управляемости, производительности или доступности или для балансировки нагрузки. Он популярен в системах управления распределенными базами данных, где каждый раздел может быть распределен по узлам с пользователями на узле, выполняя локальные транзакции в разделе.
Политика разделения набора данных основана на операционном использовании службы. В результате повышается производительность для сайтов с регулярными транзакциями, включающими определенные представления данных, доступность и безопасность.

Fail static
Ограничьте количество ресурсов, используемых службой, чтобы служба могла продолжать функционировать, соблюдая соглашения об уровне обслуживания(SLA) даже при экстремальной нагрузке.
Компоненты выходят из строя, потому что, как бы правильнее выразиться: “их напряжение превышает их прочность”. Проверяя “прочность” компонента, SRE могут определить характеристики нагрузки, которую может выдержать система. Основываясь на этом понимании, они могут затем разрешить воздействовать на систему только определенной нагрузкой, например, количеством входящих запросов. Запросы, превышающие лимит, отклоняются входной системой. Хорошим примером, но очень отдаленным примеров статической нагрузки является, если мы представим условный объект на подставке для этого объекта. Условный объект является статической нагрузкой для подставки. Нагрузки сами по себе не вызывают статического разрушения.
Например, если сеть становится перегруженной, сетевые системы сортируют перегрузку трафика и отбрасывают больший, менее чувствительный к задержкам трафик, чтобы сохранить меньшие потоки трафика, чувствительные к задержкам.
Другая стратегия заключается в понижении качества некритических служб, чтобы могли функционировать критически важные службы. Например, система видеоконференционной связи может переключаться на звук только во время задержки или проблем с пропускной способностью. Вариантом этого шаблона является шаблон зала ожидания.
Убедитесь, что нагрузка прикладывается к системе медленно и остается постоянной без значительных изменений в течение длительного периода времени. Избегайте пиков и спадов, так как тест фокусируется на статической нагрузке.

Caching
Храните данные, чтобы будущие запросы на них могли обслуживаться быстрее.
Кэш — это программный компонент, который хранит данные, чтобы будущие запросы на эти данные могли обслуживаться быстрее. Данные в кэше могут быть результатом более ранних вычислений или копией данных, хранящихся в другом месте.
Попадание в кеш происходит, когда запрошенные данные могут быть найдены в кеше. Промах кэша происходит, когда запрошенные данные не могут быть найдены. Попадания в кэш обслуживаются путем чтения данных из кэша, что быстрее, чем повторное вычисление результата или чтение из более медленного хранилища данных. Чем больше запросов может быть обслужено из кэша, тем быстрее работает система.
Важно учитывать операционную сторону кэша. Кэш снимает большую часть нагрузки, которая в противном случае могла бы напрямую повлиять на службу. Если кеш пуст (кэш кода), все запросы напрямую попадают в службу. Обязательно найдите стратегию, позволяющую избежать «грохочущего стада» при перезапуске кэша. Одна из стратегий заключается в «прогреве» кэша перед маршрутизацией через него трафика.
Примером технологии кэширования является Memcached, высокопроизводительная система кэширования объектов с распределенной памятью с открытым исходным кодом.

Queuing
Ставьте запросы в очередь и обрабатывайте их асинхронно, чтобы повысить стабильность системы.
Служба может быть перегружена большой нагрузкой и частыми запросами, что может повлиять на доступность. Ставя такие запросы в очередь и обрабатывая их асинхронно, SRE могут повысить стабильность системы. Очередь эффективно устраняет пики частоты запросов в службе, сериализует запросы и гарантирует, что частота запросов, попадающих в службу, ограничена определенной скоростью.
Основываясь на этом общем принципе, возможны несколько расширенных шаблонов:
Возможно, служба может автоматически масштабироваться в зависимости от размера очереди.
Служба может переключиться с FIFO на LIFO, если существует слишком много запросов. Возможно, время ожидания старых запросов уже истекло или система попыталась повторить попытку. Чтобы не усугубить эту ситуацию, алгоритм переключается на LIFO.

Throttling
Ограничьте количество ресурсов, которые использует служба.
Если служба сталкивается с экстремальной нагрузкой, примените регулирование. При регулировании SRE ограничивают количество ресурсов, используемых службой или ее компонентами, чтобы служба могла продолжать функционировать и соответствовать SLO.
Регулирование также может применяться на стороне клиента, например, для постоянного увеличения времени между запросами во избежание насыщения ресурсов.

Load Shedding
Намеренно отключать потребителей, чтобы защитить сеть от коллапса.
Если спрос на систему превышает доступное предложение, SRE должны внедрить процесс сброса нагрузки, чтобы предотвратить дисбаланс и последующее отключение. Сброс нагрузки также осуществляется, если времени недостаточно для запроса ограничения нагрузки.
Сброс нагрузки часто применяется в распределении энергии. В качестве крайней меры и превентивной меры намеренно отключаются потребители вахтовым методом, чтобы предохранить сеть от обрушения.
В зависимости от этапа провайдер инструктирует ключевых потребителей о реализации сброса нагрузки в соответствии с их графиком. Клиенты с некритичными системами участвуют в плане сброса нагрузки, в то время как критически важные системы остаются в сети.
Клиентам должна быть предоставлена гарантия того, что услуги вернутся в нормальное состояние по истечении определенного периода времени. Чтобы мотивировать клиентов, участвуйте в расписании и предоставляйте им стимул.

Bulkhead
Изолируйте компоненты приложения, чтобы сбой одного из них не повлиял на остальные. SRE, которые хотят повысить надежность своих услуг за счет ограничения радиуса поражения потенциальных проблем, должны внедрить схему переборок.
Переборка обозначает перегородки корабля. Если одна перегородка скомпрометирована, вода попадает только в эту перегородку, спасая корабль от затопления. Те же принципы можно применить к составному приложению. Если отдельная служба скомпрометирована, система в целом не выйдет из строя полностью.
Контейнеры — отличный способ реализовать шаблон переборки. Они обеспечивают изоляцию различных функций и позволяют ограничивать критически важные ресурсы. Платформы управления контейнерами, такие как Kubernetes или Red Hat® OpenShift®, обеспечивают автоматическое масштабирование для выделения большего количества экземпляров в зависимости от потребности.
В то же время интерфейс должен справляться с проблемами надежности отдельных функций. Вместо того, чтобы выставлять отдельный сбой как деградацию всей службы, выявляется только сбой функции. Например, если служба выбора места недоступна в системе бронирования авиабилетов, потребители все равно могут искать стыковочные рейсы и тарифы. Шаблон Backend for Frontend (BFF) может помочь раскрыть эти характеристики масштабируемым способом в соответствии с выбранным внешним интерфейсом.

Waiting room
Этот подход можно применить к приоритизации посетителей, чтобы выбрать в соответствии с политикой, какие запросы пользователей обслуживать, а какие запросы направлять в зал ожидания. Выбор может быть сделан с помощью бизнес-приоритетов, таких как предыдущее покупательское поведение, или технических приоритетов, таких как именованные и анонимные пользователи.

Compensating transaction
Записывает все шаги рабочего процесса и начинает отменять операции в случае сбоя.
Последовательность является критически важной функцией, особенно в случаях в финансовом секторе. Однако строгая согласованность является проблемой в распределенной среде. Теорема BAC описывает проблемы, связанные с тремя качествами: резервное копирование, доступность и согласованность. Согласованность в конечном счете — это модель согласованности, которая используется в распределенных вычислениях для достижения высокой доступности. Это неофициально гарантирует, что если в элемент данных не будут внесены новые обновления, в конечном итоге все обращения к этому элементу вернут последнее обновленное значение.
При сбое шага в распределенном рабочем процессе предыдущие шаги должны быть отменены. Журнал отслеживает все шаги, которые были сделаны. В качестве компенсации журнал возвращает эти операции в случае сбоя.
Одним из подходов к компенсации является шаблон Saga. В этом шаблоне SRE реализуют каждую бизнес-транзакцию, которая охватывает услуги, как сагу. Сага — это последовательность локальных транзакций. Каждая локальная транзакция обновляет базу данных и публикует сообщение или событие, чтобы инициировать следующую локальную транзакцию в саге. Если локальная транзакция терпит неудачу из-за нарушения бизнес-правила, сага запускает серию компенсирующих транзакций, которые отменяют изменения, внесенные предыдущими локальными транзакциями.
Event-driven architecture
Интегрируйте сервисы через архитектуру публикации/подписки.
С увеличением числа гибридных облачных реализаций и внедрения микросервисов событийно-управляемая архитектура (EDA) используется для удовлетворения требований слабой связи микросервисов и предотвращения сложной интеграции связи.
Принятие модели связи публикации/подписки, источников событий, разделения ответственности команд и запросов (CQRS) и шаблонов Saga помогает внедрять микросервисы, поддерживающие высокую масштабируемость и надежность для облачного развертывания.
EDA становится обязательным подходом для гибкой архитектуры. Он открывает возможность добавления сервисов ИИ для обработки событий и обработки потоков событий для получения аналитики.

Дополнительные методы повышения надежности
В дополнение к шаблонам архитектуры SRE могут использовать другие подходы для повышения надежности системы. Как правило, эти методы помогают управлять системой или понимать поведение сложных систем. Хотя они не повышают надежность напрямую, эти методы могут помочь SRE понять систему и разработать стратегии повышения надежности.
System theory
Контроллер управляет возникающими свойствами посредством действий и обратной связи. Система выполняет действия и раскрывает свои эмерджентные свойства. Такое поведение помогает SRE тестировать надежность и безопасность сложной системы.

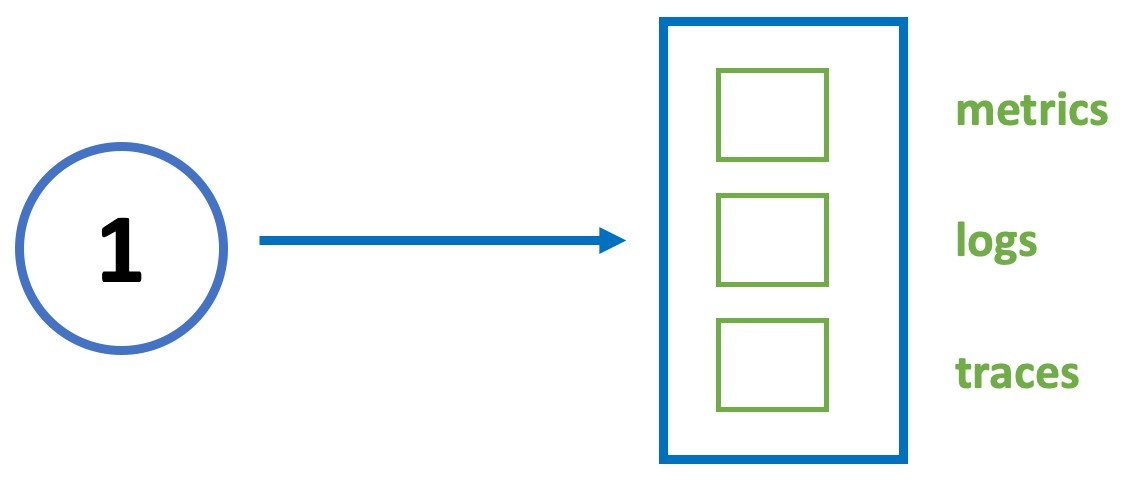
Observability
Мониторинг работоспособности службы жизненно важен. SRE могут сделать это с помощью:
Метрики
Журналы(логи)
Трассировка
SRE должны следить за обслуживанием, поскольку потребители испытывают его, чтобы быстро обнаруживать отклонения от нормы, как определено с помощью целей уровня обслуживания и индикаторов уровня обслуживания. Им также необходимо достаточное понимание системы, чтобы изолировать проблему и устранить ее как можно быстрее.
Наблюдаемость — это мера того, насколько хорошо внутренние состояния системы могут быть выведены из знания ее внешних выходов. Он состоит из трех измерений мониторинга: метрики, журналы и трассировки. Каждое из этих измерений показывает свое представление системы, включающее события, информационные панели и ссылки.
Интегрируя эти различные представления в одно решение, SRE может получить более полное представление, а также быстрее выявлять и устранять инциденты.
SRE могут работать с командой разработчиков на ранних этапах цикла разработки, чтобы продвигать концепции «создания для управления», включая создание API-интерфейсов проверки работоспособности для всех встроенных сервисов, чтобы способствовать обеспечению наблюдаемости.
Подходы к реализации и фреймворки
Чтобы упростить реализацию надежности, SRE могут использовать несколько подходов и сред для предоставления нескольких методов. Двумя примерами являются сервисная сетка(service mesh) и API gateway.
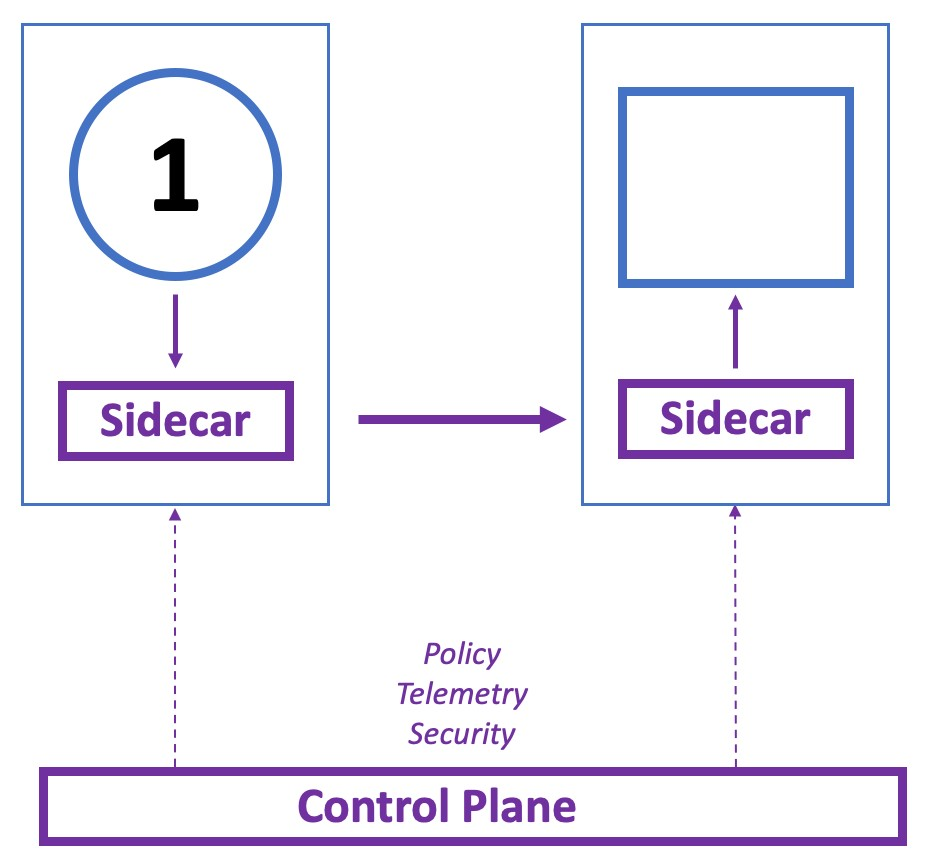
Service Mesh
Сервисная сетка — это настраиваемый уровень инфраструктуры, который управляет взаимодействием между сервисами в микросервисной архитектуре. Сервисная сетка снижает сложность, связанную с архитектурой микросервисов, и предоставляет следующие функции:
Балансировка нагрузки
Обнаружение службы
Health checks и трассировка
Аутентификация и авторизация
Управление трафиком и маршрутизация
Circuit break и failover
Безопасность
Метрики и телеметрия
Введение ошибки
SRE могут реализовать множество шаблонов через сервисную сетку, чтобы обеспечить быструю, надежную и безопасную связь между контейнерными и эфемерными службами инфраструктуры приложений.
API Gateway
Внедрите шлюз API, который является единой точкой входа для всех клиентов. Внедрение API проверки работоспособности важно для SRE, чтобы убедиться, что приложение микрослужбы готово к работе.
Шлюз API обрабатывает запросы одним из двух способов:
Маршрутизация или проксирование некоторых запросов к соответствующему сервису
Разветвление других запросов на несколько служб
На высоком уровне управление API во многом совпадает с новой концепцией сервисной сетки, но управление API и сервисная сетка применимы к разным областям. Управление API сосредоточено на том, как API из группы микросервисов предоставляются другим группам. Сервисная сетка обеспечивает маршрутизацию внутри группы.

Как часто бутерброд падает маслом вниз? Математики уверены: чаще, чем орёл vs решка. А теперь представьте самолет, или банковскую систему, начиненную подобными бутербродами. Как инженерам и бизнесу удается сохранять устойчивость сложных систем? Как при усложнении систем надежность не уменьшается, а порой и увеличивается? И при чем тут вообще бутерброды? Об этом мои коллеги из OTUS расскажут на открытом уроке курса SRE. Присоединяйтесь.
mirwide
Кто как и я перечитал 3 раза и не понял о чём речь, этот абзац - гугл перевод с англоязычной вики, из которого удалили ключевое слово "паттерн". Стриггерился на SRE в заголовке, а тут, сорри, какая-то чушь.
Shesoff
Представьте если бы "плоскость управления сервисной сеткой" были бы без оригинала в скобках :-)
mirwide
Да жесть. Понятно, что корп. блог оплачен и всё стерпит, но не до такой же степени.
therb1
Я пошел комменты смотреть после "Размещайте повторяющиеся запросы или повторные передачи одного и того же блока данных, часто во избежание перегрузки ресурсов."