
Сегодня я хочу рассказать о трёх задачах, практически не связанных друг с другом, и объединённых лишь тем, что все они приводят к распределению случайных дискретных величин, с функцией вероятности, выражающейся через числа Стирлинга первого рода. Это распределение не относится к числу популярных и широко известных, у него даже имени устоявшегося нет. Так что пусть в русскоязычной сети появится статья, в которой будут описаны и контекст, в котором это распределение появляется, и его основные свойства. На нашем пути встретятся перестановки, стохастические цепочки, свёртка распределений, немного алгебры и даже Ага!-момент в конце статьи.
Приглашаю к чтению тех, кто хочет расширить свой кругозор, или просто любит всякую комбинаторику с вероятностями.
Сюжет первый. Рекорды
В одном околоматематическом паблике появилась любопытная задачка.
В затылок друг другу выстроились восемь человек. Более высокие загораживают более низких так, что тех не видно. Чему равно математическое ожидание числа людей, которых видно?
Можете, если хотите, переформулировать задачу для видимых домов в микрорайоне с многоэтажной застройкой.
Попытки во время прогулки оценить возможный ход решения в уме, привели к соображению, что нужно знать распределение людей по высоте, ведь, если оно будет равномерным, то получится один ответ, а если, например, вырожденным (все люди в очереди одинакового роста), то другой, а именно, единица. Нужно пробовать и экспериментировать.
Так субботняя прогулка привела меня к компьютеру, и через часик была готова нехитрая программка, моделирующая людей в очереди, набором чисел. Она честно перебирает все возможные варианты, коих в очереди из человек будет
, если люди имеют
различных значений роста, вычисляет количество видимого народа, и даже учитывает распределение людей по росту и ведёт статистику. С её помощью быстро удалось просчитать разные варианты, и они говорили о том, что, всё-таки, для ответа нам нужно знать то, каким именно будет распределение вероятности для высоты людей. То есть, ответ зависит от этого распределения и одним числом его не выразить.
Увлёкшись, я даже воспользовался статистикой по длине нынешнего народонаселения из одной статьи на Хабре, и подставил её в программу. И вот тут я с удивлением обнаружил, что от конкретного выбора распределения ответ меняется, но как-то... неубедительно. Гораздо больше на него влияет количество разнообразных вариантов роста, или, выражаясь более формально, мощность носителя распределения. Более того, по мере увеличения числа этих вариантов, среднее число видимых людей неспешно сходится к некоторому значению, фиксированному для длины очереди.
Размышления о распределении для роста завели меня не туда. А тем временем, один из комментаторов уже выдал ответ, причём, для меня несколько неожиданный. Среднее количество видимых людей в очереди, по его версии, оказалось равно гармоническому числу (частичной сумме гармонического ряда):
Как выяснилось, приведённый результат был тоже получен с помощью численного эксперимента на компьютере. Сравнение этого ответа с моим показало, что оно верно описывает то самое предельное значение, которое получается в случае непрерывной функции распределения роста людей.
Гармонические числа не так уж часто встречаются в теории вероятностей и в комбинаторике, и я, по-киношному прищурившись, произнёс: "Мне кажется я знаю этого парня..." Похоже, мы имеем дело с распределением, которое можно считать довольно редким и далёким от популярности, в отличие от нормального, экспоненциального, гамма-распределения и прочих устойчивых и высокоэнтропийных звёзд теории вероятностей и статистики. Это распределение рекордных случайных величин.

Рекордной величиной (или просто рекордом) в последовательности случайных величин называется величина, которая превосходит все предыдущие. А ведь это же именно наш случай! Каждый верзила, загораживающий впереди стоящих, это очередной рекорд по высоте.
Я рассматривал варианты всех возможных очередей с людьми, рост которых округлён до некоторых дискретных значений. При этом, в очереди могли оказываться люди с одинаковым (при округлении до 5 или 10 см) ростом. Если мы примем, что рост не округлён и мы имеем дело с непрерывным распределением, то точное совпадение по росту имеет вероятность, эффективно равную нулю, а значит, в очереди все люди будут иметь различный рост. В таком случае, уже не важно, как именно он распределён: мы всегда можем ранжировать их по росту и поставить каждому в соответствие натуральное число, сохраняющее отношение порядка.

Если мы заменим настоящий рост людей на их порядковый номер в ранжировании по росту, то ответ на вопрос: "Кто кого загораживает?" или, что то же самое: "Кто является рекордсменом?" не изменится. Таким образом, мы можем смело забыть о конкретном распределении, лишь бы оно было непрерывным, и свести задачу от перебора вариантов, к перебору перестановок из
различимых элементов, которых, как известно,
штук. Итак, задача наша формализуется следующим образом:
Найти распределение для числа рекордов в перестановках длины n.
В комбинаторике полезно поиграть с исследуемой системой на малых числах. Посмотрим на то, как рекорды распределяются в перестановках длины 2, 3 и 4:

Пусть это количество перестановок длины
таких, чтобы количество рекордов в них было равно
Выясним, чему будет равно
то есть, сколько будет способов получить
рекордов, если мы добавим в перестановку ещё один элемент. Если его величина превышает все уже задействованные числа, то мы можем поставить его в конце последовательности и количество способов получить
рекордов будет равно
-тым рекордом будет этот последний элемент. Если же его величина оказывается где-то посередине, то существует ровно
способов его поставить так, чтобы в любом из уже рассмотренных
вариантов он оказался загорожен каким-нибудь рекордом и не нарушил числа
. Таким образом, получается, что
Если в последовательности всего один элемент, то Кроме того, есть пара тривиальных граничных значений для отсутствия рекордов и отсутствия людей в очереди:
Итак, мы получили ответ в форме рекуррентного соотношения. Оно в точности совпадает с определением беззнаковых чисел Стирлинга первого рода. Для них принято обозначение, похожее на число сочетаний, только в квадратных скобках. Определяются они так:
Всех перестановок, как мы помним, штук, так что можно от количества перестановок с указанным числом рекордов, перейти к вероятностям.

Я позволю себе называть это распределение именем Стирлинга и обозначу . Было бы разумным называть гармоническим распределением, но это имя уже занято. Перечислим основные характеристики распределения Стирлинга.
Носитель распределения:
Функция вероятности:
Среднее:
Дисперсия:
Функция распределения в конечной форме не выражается, но имея функцию вероятности, несложно вычислить её прямым суммированием.
Сразу замечу, что то, что среднее для этого распределения выражается гармоническими числами, является его ключевым свойством, о котором мы подробно поговорим ниже. То, что это так, несложно доказать индукцией по Однако, есть и другие способы доказательства, один из них хорошо и подробно изложен в статье Артура Бенджамина с соавторами A Stirling Encounter with Harmonic Numbers, которую я рекомендую тем, кто хочет познакомиться с числами Стирлинга первого рода в контексте комбинаторики.
Сюжет второй. Стохастические цепочки
С героем нашего рассказа я впервые встретился несколько лет назад, когда решал совсем другую задачу, работая над научно-популярной книгой посвящённой законам подлости. Тогда я выяснял, каким будет распределение для длины цепочки последовательных дел, которые можно успеть выполнить до наступления некоторого предельного срока, дедлайна.
Постановка задачи была такой. Пусть в нашем распоряжении имеется дней. В этот срок необходимо выполнить некоторую работу, состоящую из цепочки последовательных этапов. Говоря "последовательных" я имею в виду, что
-тый этап можно выполнить только по завершении
этапа, никакого распараллеливания процессов не предполагается, так что два дела в один день выполнить не удастся. При этом исполнитель придерживается безалаберной, но вполне реалистичной житейской стратегии: в какой-то, произвольно выбранный день, выполняется первый этап работы; второй этап выполняется в один из оставшихся дней, третий — в какой-либо день после второго, и так далее, до тех пор, пока не наступит дедлайн. Я хотел найти вероятность
для того, что цепочка будет иметь максимальную длину
. Под максимальной длиной подразумевается, что
этап выполнить уже не удастся, или, что то же самое, что выполнение
-ого этапа приходится на последний
-ный день.
Мы будем рассуждать, рассматривая размещение точек в обратном порядке. Любая цепочка завершается выполнением последнего этапа в последний день. Вероятность того, что первый и последний этап придётся именно на день с номером , будет равна
, ведь для нашего безалаберного исполнителя все дни одинаковы. Дальше можно действовать индуктивно. Для произвольного
последний этап обязательно должен случиться в последний день, это, как мы знаем, может случиться с вероятностью
. Потом мы можем выполнить предпоследний этап в любой из предыдущих дней, скажем в день с номером m, сведя при этом задачу к случаю
этапов и
дней. Выбор
ограничен сверху числом
, поскольку два этапа — последний и предпоследний — уже на местах. Сложив вероятности всех таких вариантов, мы получим вероятность
Таким образом, у нас уже есть способ получить точное решение искомой задачи, но для этого нужно знать решения всех входящих в неё подзадач:
Полученную рекуррентную формулу мне, не без труда, удалось упростить, приведя к форме:
которая соответствует распределению Стирлинга.
То, что ожидаемое число последовательных дел, которые можно успеть выполнить, имея ограниченное время, выражается гармоническим числом, наводит на философские мысли. Гармонические числа растут неограниченно,но чрезвычайно медленно, и имея серьёзные планы на пять, десять или на пятьдесят лет, нужно иметь в виду, что если выполнять их не регулярно, а придерживаясь стратегии "когда-нибудь обязательно сделаю", то и за всю жизнь можно успеть сделать не так уж много.

Сюжет третий. Циклы в перестановках
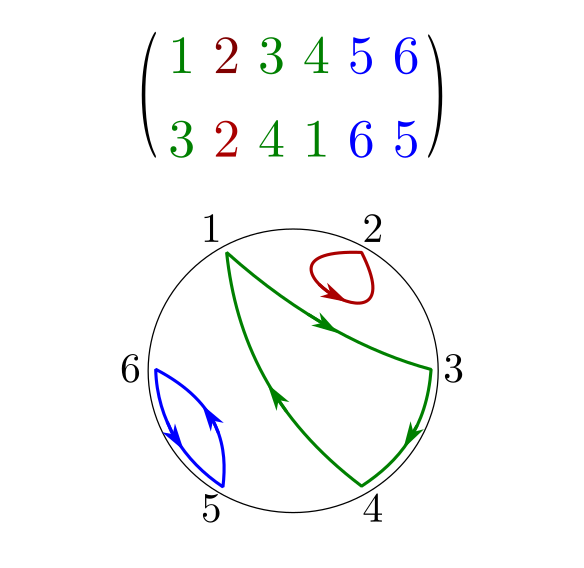
В любой справочной или вводной статье, посвящённой числам Стирлинга первого рода, говорится, что они фигурируют в комбинаторике, а именно, отражают количество перестановок, имеющих ровно циклов. Напомню, что любую перестановку можно однозначно представить в виде произведения непересекающихся циклов. Например, перестановка
содержит в себе такие циклы:
и
и одну неподвижную точку 2, которую можно считать тривиальным циклом. На иллюстрации она показана в форме подстановки, для наглядности.
То что количество циклов связано с числами Стирлинга, доказывается точно такими же, рассуждениями, какими мы вывели рекуррентное соотношение для числа рекордов в последовательности различающихся величин.
Пусть — это число циклов длины
в перестановке длины
. Увеличим длину перестановки на единицу, и вычислим
. При этом возможны два случая:
Дополнительный элемент может оказаться неподвижной точкой, и для того, чтобы число
осталось неизменным, мы должны прибавить этот тривиальный цикл только к тем перестановкам длины
, в которых число циклов равно
. Количество таких перестановок
.
Новый элемент может войти в перестановку, имеющую
циклов, став частью одного из них. Это можно сделать вставив новый элемент между любыми двумя элементами перестановки длины
, в том числе, между последним и первым элементами, которые могут входить в один цикл. Таким образом, получается
различных вариантов добавления элемента, не нарушающих числа циклов, в каждую из
перестановок с
циклами. Так мы получаем ещё
перестановок.
Складывая эти два результата, мы вновь получим рекуррентное соотношение для беззнаковых чисел Стирлинга первого рода:
Осталось заметить, что перестановка с единственным элементом имеет единственный цикл , и что не существует перестановок без циклов, а также циклов без элементов в перестановке:
Совпадение формул,и даже приводящих к ним рассуждений, может создать ощущение, что число циклов и число рекордов должны быть как-то связаны. Но если мы посмотрим на то, как по количеству рекордов и циклов перестановки делятся на классы, то увидим, что эти классы имеют одинаковую мощность, однако между ними есть "беглые" элементы.

Что же объединяет эти сюжеты?
Рассмотренные нами три задачи не сводятся друг к другу. В каждой из них к числам Стирлинга приводит свой путь. И хотя в случае подсчёта рекордов и циклов в перестановках, рассуждения были одинаковыми, различия в получающихся классах эквивалентности говорят о том, что эти задачи можно считать независимыми. Как же связаны рекорды, стохастические цепочки и циклы в перестановках? Оказывается, объединяет их алгебра многочленов.
Роберт Стирлинг, работавший в начале XIX века, оставил своё имя в науке, дав его машине внешнего сгорания, знаменитой формуле для аппроксимации факториала, и коэффициентам в разложении полиномов, известных, как восходящие факториалы. Эти-то коэффициенты и входят в распределение, которое мы обсуждаем в этой статье.
Восходящим факториалом называют многочлены следующего вида:
Сравните коэффициенты в этих многочленах с гистограммами, полученными нами для перестановок. В том, что это, действительно, числа Стирлинга первого рода, легко убедиться, раскрыв скобки в выражении, определяющем :
Если вычислить коэффициент при в
обозначив его, как
, то получится знакомое выражение:
Поделив восходящий факториал на
, получим многочлен в котором коэффициенты при
равны вероятностям для числа
в распределении Стирлинга:
Такие многочлены называются производящими функциями вероятности для дискретного распределения.
Но при чём тут рассмотренные нами задачи? Давайте присмотримся к тому факту, что математическое ожидание для случайной величины, подчиняющейся распределению Стирлинга, равно гармоническому числу, то есть, сумме дробей:
Математическое ожидание линейно, это значит, что матожидание для суммы случайных величин равно сумме матожиданий для каждой из них. Это наводит на мысль: не является ли распределение Стирлинга распределением для суммы случайных величин, каждая из которых имеет математическое ожидание, равное ?
Распределение для суммы случайных величин вычисляется, как свёртка их распределений. Свёртка — не самая интуитивно понятная операция, но в случае дискретных распределений мы можем воспользоваться тем, что коэффициенты произведения многочленов представляют свёртку последовательностей коэффициентов этих многочленов. Значит, произведение производящих функций вероятности для двух распределений будет производящей функцией для их свёртки.
Например, многочлен с коэффициентами, соответствующими распределению Бернулли с вероятностью , имеет вид
. Свёрткой
бернуллиевых величин будет произведение этих многочленов, или, согласно биномиальной формуле:
В коэффициентах этого многочлена мы без труда разглядим биномиальное распределение.
Вооружившись этим знанием, давайте перепишем выражение для производящей функции для распределения Стирлинга таким образом:
Теперь видно, что каждый множитель здесь — это производящая функция вероятности для распределения Бернулли с параметрами . Таким образом, мы можем сделать важный вывод:
Сумма случайных величин, подчиняющихся распределениям Бернулли с гармонично убывающими вероятностями, подчиняется распределению Стирлинга:

Методом "пристального всматривания", можно разглядеть это свойство в рекуррентной формуле для вероятности длины стохастической цепочки с дедлайном, в индуктивной форме:
где кружком обозначен оператор свёртки. Именно этот итерационный процесс показан на анимации.

Эта связь с распределением Бернулли и есть основное свойство распределения Стирлинга, которое кроется во всех трёх задачах и "уши" которого "торчат" в выражении для среднего значения. Похоже, что в каждой из них мы имеем дело с суммами случайных величин, подчиняющиеся распределению Бернулли с параметром . Давайте выясним, что это за величины для каждого из трёх сюжетов.
Циклы
Применительно к циклам в перестановках, нетрудно показать, что вероятность в случайной перестановке длины встретить цикл длины
равна
.
Действительно, среди всех возможных перестановок,
содержат некоторый конкретный цикл длины
. При этом существует
способов наполнить этот цикл элементами и
способов переставить в нём элементы, получая уникальные циклы (деление на
исключает одинаковые циклы, отличающиеся друг от друга лишь циклической перестановкой). Итого, вероятность обнаружить цикл длины
равна:
Рекорды
Вероятность того, что в перестановке длины рекордом будет конкретное число
, равна
Убедиться в этом можно пересчитав сколько раз рекордными оказывались числа 1, 2, 3 и 4 в примерах, приведённых на иллюстрации, показывающей гистограммы для числа рекордов в перестановках .
Число может стать рекордом, только если все числа превышающие его, оказываются по правую сторону от его позиции в перестановке, при этом, нас не интересует расположение чисел не превышающих
. Перестановку, в которой число
является рекордом, можно схематично показать так:
. Здесь буквами
условно обозначены числа превышающие
, количество которых равно
.
Множество всех перестановок такого вида можно факторизовать, считая эквивалентными те перестановки, в которых последовательность одинакова, не зависимо от их конкретного положения. Все классы эквивалентности будут содержать одинаковое количество элементов, равное
а всего таких классов будет Перемножив эти два выражения, мы получим общее количество перестановок, в которых число
является рекордом:
Поделив его на , получаем искомую вероятность
Например, в перестановке длиной 4, вероятность того, что число 4 будет рекордом равна 1, для 3 она равна , для 2 —
, и для 1 —
.
Стохастические цепочки
В результате описанной нами безалаберной стратегии выполнения дел до наступления дедлайна, получаются строго возрастающие последовательности индексов от до
, соответствующих этапам работы. В качестве примера, перечислим все возможные последовательности этапов для четырёх дней:

Если бы расположение этапов по дням было независимым друг от друга, то все эти восемь вариантов были бы равновероятны, и мы получили бы биномиальное распределение для длин цепочек. Однако, время выполнения этапов в цепочках зависит от времени предыдущих этапов. При этом, по мере уменьшения числа оставшихся дней, вероятность выбора конкретного дня для очередного этапа увеличивается:
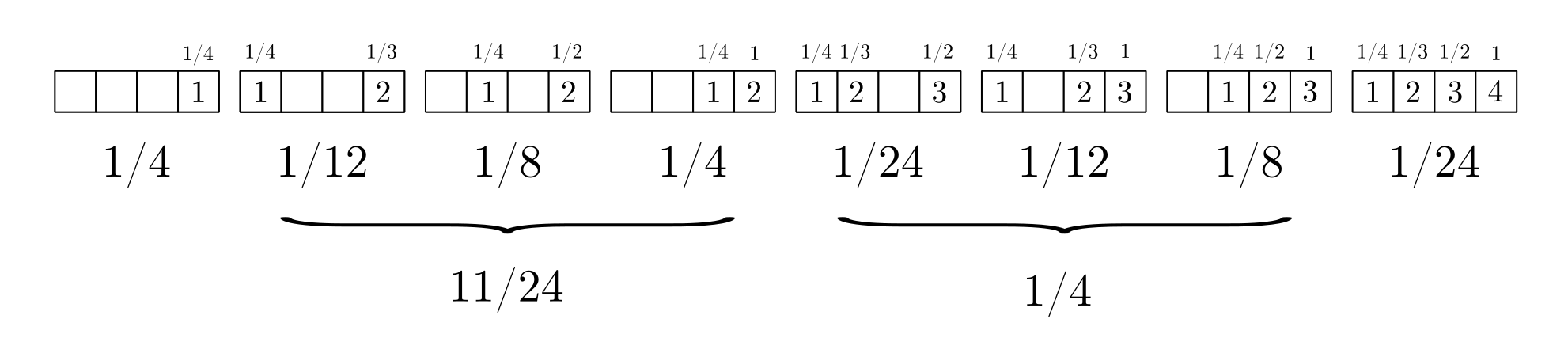
Для каждой цепочки эти вероятности перемножаются, в свою очередь, вероятности для цепочек с одинаковым числом этапов, складываются. Так получается распределение вероятности для длин цепочек в случае четырёх дней. Умножив эти вероятности на мы получим последовательность чисел Стирлинга для
: 6, 11, 6 и 1.
Если с помощью диаграммы аккуратно вычислить вероятность того, что этап работы придётся на день то получим следующее распределение по дням:
Переводя все наши задачи на классический язык теории вероятностей, можно все их свести к такой канонической форме:
В урне находится
шаров, пронумерованных числами от 1 до
. Доставая из урны по одному шару, составляем из них убывающую последовательность натуральных чисел, игнорируя шары с номерами, превышающими номер, который является текущим минимумом.
Вероятность того, что конкретный номер
окажется в полученной последовательности равна
, в силу линейности среднего, ожидаемая длина последовательности выражается гармоническим числом
, а длина последовательности подчиняется распределению Стирлинга.
Комментарии (6)

dmagin
00.00.0000 00:00+1Как всегда круто и познавательно, спасибо.
Мне ещё кажется, что числа Стирлинга 1-го рода могут быть связаны с детерминантами матрицы смежности графов. Поскольку последние тоже связаны с циклами на графе. Но могу и ошибаться.
samsergey Автор
00.00.0000 00:00Соображение интересное, но пока не соображу как бы на прямую они могли быть связаны. Определитель можно задать суммированием по перестановкам, но его значение не сводится к комбинации циклов. Надо поразмыслить.
dmagin
00.00.0000 00:00+1Будет возможность - сам гляну. Просто известно, что детерминанты лапласиана графа - это статистика деревьев, а детерминанты смежности - статистика циклов. В статистике деревьев числа Стирлинга точно всплывают, но 2-го рода. Отсюда и предположение.

Anton_Olegovich
00.00.0000 00:00+1Простите, но я не понял график с количеством дел, которые можно успеть за n лет. Складывается ощущение, что при подобном, полностью случайном и безалаберном подходе, цепочку из пяти стадий можно гарантированно выполнить лишь за 70-80 лет, я правильно интерпретировал?
samsergey Автор
00.00.0000 00:005 годовых (по длительности) дел за 70 лет не гарантированное, а ожидаемое количество. Конечно же, это всего лишь, простая модель, но я в книжке рассматривал более сложные стратегии.
shuhray
"Метод пристального внимания" порадовал. Как говорил один наш лектор "Если долго смотреть на эту формулу, она становится очевидной".