
Сбор и разметка данных в реальном мире может быть длительным и дорогостоящим занятием. Кроме того, у этих данных могут быть проблемы с качеством, разнообразием и количеством. К счастью, подобные проблемы можно решать при помощи синтетических данных.

Для обучения модели машинного обучения нужны данные. Задачи data science обычно непохожи на соревнования Kaggle, где у вас есть отличный крупный датасет с готовой разметкой. Иногда приходится собирать, упорядочивать и очищать данные самостоятельно. Такой процесс сбора и разметки данных в реальном мире может быть долгим, неудобным, неточным, а иногда и опасным. Более того, в конце этого процесса может оказаться, что полученные в реальном мире данные не соответствуют вашим требованиям с точки зрения качества, разнообразия (например, дисбаланс классов) и количества. Мы перечислим распространённые проблемы, которые возникают при работе с реальными данными:
К счастью, подобные проблемы можно решить при помощи синтетических данных. Возможно, вы задаётесь вопросом, что же такое синтетические данные? Синтетические данные — это искусственно сгенерированные данные, обычно создаваемые при помощи алгоритмов, симулирующих процессы реального мира, от поведения других водителей на дороге до взаимодействия света с поверхностями. В этом посте мы расскажем об ограничениях данных реального мира и о том, как синтетические данные помогают преодолеть этих проблемы и повышать точность модели.
Для маленьких датасетов обычно можно собирать и размечать данные вручную; однако для обучения во многих сложных задачах машинного обучения требуются огромные датасеты. Например, модели, обучаемые для беспилотного вождения, требуют больших объёмов данных, собираемых с датчиков, прикреплённых к автомобилям или дронам. Этот процесс сбора данных очень медленный, он может занимать месяцы или даже годы. После сбора сырых данных их должны вручную аннотировать живые люди, что тоже долго и дорого. Более того, нет гарантии, что полученные размеченные данные принесут пользу в качестве данных обучения, поскольку они могут не содержать примеров, заполняющих текущие пробелы в знаниях модели.
Для разметки таких данных обычно применяется труд людей, вручную рисующих метки поверх данных датчиков. Это очень дорогостоящий процесс, поскольку высокооплачиваемые команды ML часто тратят большую долю своего времени на проверку меток и их возврат разметчикам. Главное преимущество синтетических данных заключается в том, что можно сгенерировать любое нужное количество идеально размеченных данных. И для этого необходим лишь способ генерации качественных синтетических данных.
Опенсорсное ПО для генерации синтетических данных:
Kubric (обработка видео с множеством объектов, маски сегментирования, карты глубин и оптический поток) и SDV (табличные, реляционные и временные данные).
Вот некоторые из множества компаний, продающих продукты или создающих платформы, способные генерировать синтетические данные: Gretel.ai (синтетические датасеты, обеспечивающие конфиденциальность реальных данных), NVIDIA (omniverse) и Parallel Domain (беспилотный транспорт). Другие компании можно посмотреть в списке 2022 года компаний, занимающихся синтетическими данными.

Некоторые данные люди не могут полностью интерпретировать и разметить. Ниже представлены некоторые примеры, в которых единственным вариантом остаются синтетические данные:
Синтетические данные крайне полезны для применения в областях, в которых непросто получить реальные данные. Например, это касается данных дорожно-транспортных происшествий и большинства типов данных о здоровье, на которые накладываются юридические ограничения (в частности, на электронные медицинские карты). В последние годы исследователей в сфере здравоохранения заинтересовала тема прогнозирования мерцательной аритмии (нарушения сердечного ритма) при помощи сигналов электрокардиографии и фотоплетизмографии. Разработка детектора аритмии сложна не только тем, что аннотирование таких сигналов — монотонный и дорогостоящий процесс, но и из-за юридических ограничений. Это одна из причин, по которой проводятся исследования по симуляции таких сигналов.
Важно подчеркнуть, что сбор реальных данных не только требует времени и энергии, но и может быть по-настоящему опасным. Одна из основных проблем робототехники, например, беспилотных автомобилей, в том, что они являются физическим применением машинного обучения. Нельзя использовать небезопасную модель в реальном мире, которая приведёт к автокатастрофе из-за нехватки релевантных данных. Подобных проблем позволяет избежать аугментация датасета синтетическими данными.
Вот некоторые из компаний, использующих синтетические данные для повышения безопасности применения ИИ: Toyota, Waymo и Cruise.

Синтетическое изображение частично невидимого ребёнка на велосипеде, появляющегося из-за школьного автобуса и едущего по улице в среде, напоминающей калифорнийский пригород.
Системам беспилотного вождения часто приходится иметь дело с относительно «редкими» (по сравнению с обычными условиями вождения) событиями, например, с пешеходами ночью или с велосипедистами, едущими посередине дороги. Для обучения таким сценариям моделям часто нужны сотни тысяч или даже миллионы примеров. Серьёзная проблема заключается в том, что собираемые в реальном мире данные могут не соответствовать требованиям качества, разнообразия (например, дисбаланса классов, погодных условий, местоположения) и количества. Ещё одна проблема заключается в том, что в случае автономных автомобилей и роботов мы не всегда знаем, какие именно данные потребуются, в отличие от традиционных задач машинного обучения с фиксированными датасетами и бенчмарками. Хотя бывают полезными техники аугментации данных, систематически или случайно изменяющие изображения, эти техники способны привносить собственные проблемы.
И здесь на помощь приходят синтетичекие данные. API генерирования синтетических данных позволяют проектировать датасеты. Эти API экономят кучу средств, поскольку изготовление роботов и сбор данных в реальном мире — чрезвычайно затратная задача. Гораздо лучше и быстрее попытаться сгенерировать данные и определить принципы проектирования при помощи генерирования синтетического датасета.
Вот некоторые из примеров того, как синтетические данных помогают моделям обучаться: предотвращение мошеннических транзакций (American Express), улучшенное распознавание велосипедистов (Parallel Domain) и анализ хирургических операций (Hutom.io).

Этапы цикла разработки модели
Существует множество факторов, влияющих на жизнеспособность/показатели проекта машинного обучения в разработке и продакшене (например, получение данных, аннотирование, обучение модели, масштабирование, развёртывание, мониторинг, повторное обучение модели и скорость разработки). Недавно 18 инженеров машинного обучения приняло участие в исследовании-интервью, целью которого стало понимание распространённых практик MLOps и сложностей в различных организациях и сферах применения (например, в беспилотном вождении, компьютерном оборудовании, розничной торговле, рекламе, системах рекомендаций и так далее). Одним из выводов исследования стала важность скорости разработки, то есть способность быстро прототипировать и выполнять итерации с идеями.
Один из факторов, влияющих на скорость разработки — это необходимость наличия данных для первоначального обучения и оценки модели, а также для частого повторного обучения модели вследствие постепенного снижения точности модели из-за дрейфа данных, дрейфа концепций или даже из-за training-serving skew.

Результаты исследования также говорят, что эта потребность заставила некоторые организации создать команду для частой разметки актуальных данных. Это дорогой и долгий процесс, ограничивающий возможность быстрого повторного обучения моделей.
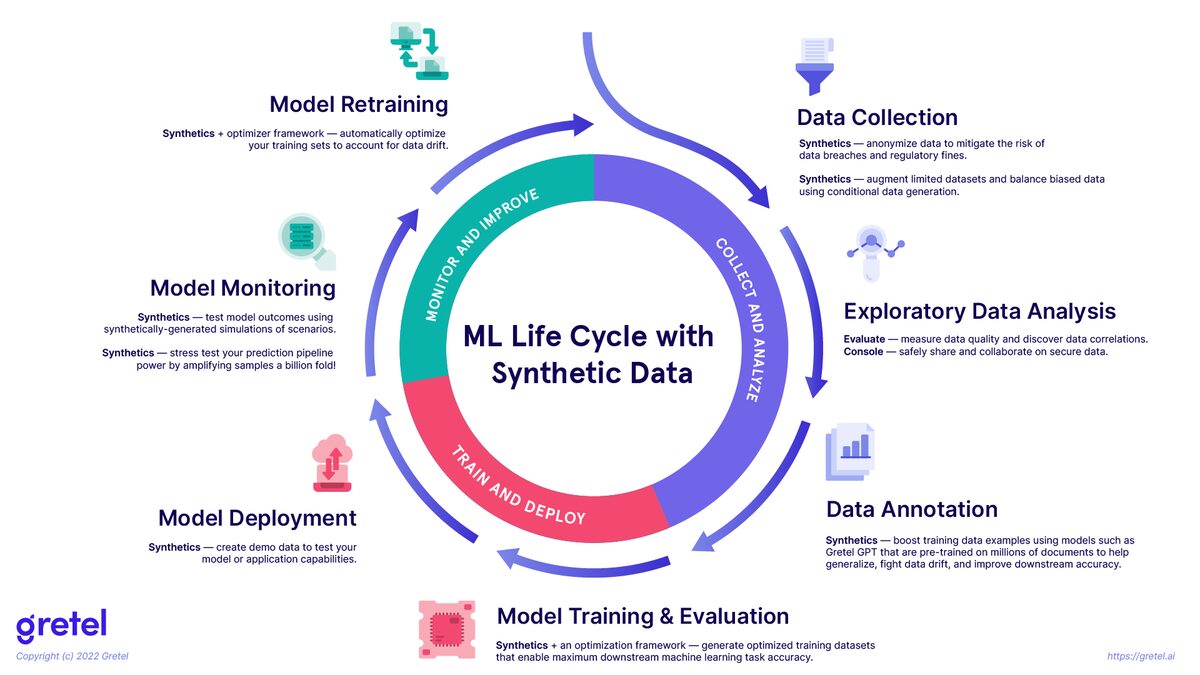
Стоит заметить, что в этой схеме не отражено, что синтетические данные можно использовать для операций наподобие MLOps-тестирования систем рекомендаций.
Синтетические данные имеют потенциал применения наряду с данными реального мира в жизненном цикле машинного обучения (показанном на изображении выше), чтобы обеспечивать более долговременную точность моделей.
Генерирование синтетических данных всё чаще используется в рабочих процессах машинного обучения. На самом деле, Gartner прогнозирует, что к 2030 году синтетические данные будут использоваться в обучении моделей машинного обучения гораздо больше, чем данные реального мира.
Для обучения модели машинного обучения нужны данные. Задачи data science обычно непохожи на соревнования Kaggle, где у вас есть отличный крупный датасет с готовой разметкой. Иногда приходится собирать, упорядочивать и очищать данные самостоятельно. Такой процесс сбора и разметки данных в реальном мире может быть долгим, неудобным, неточным, а иногда и опасным. Более того, в конце этого процесса может оказаться, что полученные в реальном мире данные не соответствуют вашим требованиям с точки зрения качества, разнообразия (например, дисбаланс классов) и количества. Мы перечислим распространённые проблемы, которые возникают при работе с реальными данными:
- Сбор и разметка реальных данных не масштабируются
- Ручная разметка реальных данных не всегда возможна
- Реальные данные имеют проблемы с конфиденциальностью и безопасностью
- Реальные данные не программируемы
- Показатели модели, обученной исключительно на реальных данных, недостаточно высоки (например, маленькая скорость разработки)
К счастью, подобные проблемы можно решить при помощи синтетических данных. Возможно, вы задаётесь вопросом, что же такое синтетические данные? Синтетические данные — это искусственно сгенерированные данные, обычно создаваемые при помощи алгоритмов, симулирующих процессы реального мира, от поведения других водителей на дороге до взаимодействия света с поверхностями. В этом посте мы расскажем об ограничениях данных реального мира и о том, как синтетические данные помогают преодолеть этих проблемы и повышать точность модели.
Сбор и разметка реальных данных не масштабируются
Для маленьких датасетов обычно можно собирать и размечать данные вручную; однако для обучения во многих сложных задачах машинного обучения требуются огромные датасеты. Например, модели, обучаемые для беспилотного вождения, требуют больших объёмов данных, собираемых с датчиков, прикреплённых к автомобилям или дронам. Этот процесс сбора данных очень медленный, он может занимать месяцы или даже годы. После сбора сырых данных их должны вручную аннотировать живые люди, что тоже долго и дорого. Более того, нет гарантии, что полученные размеченные данные принесут пользу в качестве данных обучения, поскольку они могут не содержать примеров, заполняющих текущие пробелы в знаниях модели.
Для разметки таких данных обычно применяется труд людей, вручную рисующих метки поверх данных датчиков. Это очень дорогостоящий процесс, поскольку высокооплачиваемые команды ML часто тратят большую долю своего времени на проверку меток и их возврат разметчикам. Главное преимущество синтетических данных заключается в том, что можно сгенерировать любое нужное количество идеально размеченных данных. И для этого необходим лишь способ генерации качественных синтетических данных.
Опенсорсное ПО для генерации синтетических данных:
Kubric (обработка видео с множеством объектов, маски сегментирования, карты глубин и оптический поток) и SDV (табличные, реляционные и временные данные).
Вот некоторые из множества компаний, продающих продукты или создающих платформы, способные генерировать синтетические данные: Gretel.ai (синтетические датасеты, обеспечивающие конфиденциальность реальных данных), NVIDIA (omniverse) и Parallel Domain (беспилотный транспорт). Другие компании можно посмотреть в списке 2022 года компаний, занимающихся синтетическими данными.
Ручная разметка данных иногда может быть невозможной
Некоторые данные люди не могут полностью интерпретировать и разметить. Ниже представлены некоторые примеры, в которых единственным вариантом остаются синтетические данные:
- Точная оценка глубины и оптического потока по отдельным изображениям.
- Сферы применения беспилотного вождения, в которых используются данные, невидимые человеческому глазу.
- Генерирование deepfake, которые можно использовать для тестирования систем распознавания лиц.
Реальные данные имеют проблемы с конфиденциальностью и безопасностью
Синтетические данные крайне полезны для применения в областях, в которых непросто получить реальные данные. Например, это касается данных дорожно-транспортных происшествий и большинства типов данных о здоровье, на которые накладываются юридические ограничения (в частности, на электронные медицинские карты). В последние годы исследователей в сфере здравоохранения заинтересовала тема прогнозирования мерцательной аритмии (нарушения сердечного ритма) при помощи сигналов электрокардиографии и фотоплетизмографии. Разработка детектора аритмии сложна не только тем, что аннотирование таких сигналов — монотонный и дорогостоящий процесс, но и из-за юридических ограничений. Это одна из причин, по которой проводятся исследования по симуляции таких сигналов.
Важно подчеркнуть, что сбор реальных данных не только требует времени и энергии, но и может быть по-настоящему опасным. Одна из основных проблем робототехники, например, беспилотных автомобилей, в том, что они являются физическим применением машинного обучения. Нельзя использовать небезопасную модель в реальном мире, которая приведёт к автокатастрофе из-за нехватки релевантных данных. Подобных проблем позволяет избежать аугментация датасета синтетическими данными.
Вот некоторые из компаний, использующих синтетические данные для повышения безопасности применения ИИ: Toyota, Waymo и Cruise.
Реальные данные не программируемы
Синтетическое изображение частично невидимого ребёнка на велосипеде, появляющегося из-за школьного автобуса и едущего по улице в среде, напоминающей калифорнийский пригород.
Системам беспилотного вождения часто приходится иметь дело с относительно «редкими» (по сравнению с обычными условиями вождения) событиями, например, с пешеходами ночью или с велосипедистами, едущими посередине дороги. Для обучения таким сценариям моделям часто нужны сотни тысяч или даже миллионы примеров. Серьёзная проблема заключается в том, что собираемые в реальном мире данные могут не соответствовать требованиям качества, разнообразия (например, дисбаланса классов, погодных условий, местоположения) и количества. Ещё одна проблема заключается в том, что в случае автономных автомобилей и роботов мы не всегда знаем, какие именно данные потребуются, в отличие от традиционных задач машинного обучения с фиксированными датасетами и бенчмарками. Хотя бывают полезными техники аугментации данных, систематически или случайно изменяющие изображения, эти техники способны привносить собственные проблемы.
И здесь на помощь приходят синтетичекие данные. API генерирования синтетических данных позволяют проектировать датасеты. Эти API экономят кучу средств, поскольку изготовление роботов и сбор данных в реальном мире — чрезвычайно затратная задача. Гораздо лучше и быстрее попытаться сгенерировать данные и определить принципы проектирования при помощи генерирования синтетического датасета.
Вот некоторые из примеров того, как синтетические данных помогают моделям обучаться: предотвращение мошеннических транзакций (American Express), улучшенное распознавание велосипедистов (Parallel Domain) и анализ хирургических операций (Hutom.io).
Показатели модели, обученной исключительно на реальных данных, недостаточно высоки
Этапы цикла разработки модели
Существует множество факторов, влияющих на жизнеспособность/показатели проекта машинного обучения в разработке и продакшене (например, получение данных, аннотирование, обучение модели, масштабирование, развёртывание, мониторинг, повторное обучение модели и скорость разработки). Недавно 18 инженеров машинного обучения приняло участие в исследовании-интервью, целью которого стало понимание распространённых практик MLOps и сложностей в различных организациях и сферах применения (например, в беспилотном вождении, компьютерном оборудовании, розничной торговле, рекламе, системах рекомендаций и так далее). Одним из выводов исследования стала важность скорости разработки, то есть способность быстро прототипировать и выполнять итерации с идеями.
Один из факторов, влияющих на скорость разработки — это необходимость наличия данных для первоначального обучения и оценки модели, а также для частого повторного обучения модели вследствие постепенного снижения точности модели из-за дрейфа данных, дрейфа концепций или даже из-за training-serving skew.
Результаты исследования также говорят, что эта потребность заставила некоторые организации создать команду для частой разметки актуальных данных. Это дорогой и долгий процесс, ограничивающий возможность быстрого повторного обучения моделей.
Стоит заметить, что в этой схеме не отражено, что синтетические данные можно использовать для операций наподобие MLOps-тестирования систем рекомендаций.
Синтетические данные имеют потенциал применения наряду с данными реального мира в жизненном цикле машинного обучения (показанном на изображении выше), чтобы обеспечивать более долговременную точность моделей.
Заключение
Генерирование синтетических данных всё чаще используется в рабочих процессах машинного обучения. На самом деле, Gartner прогнозирует, что к 2030 году синтетические данные будут использоваться в обучении моделей машинного обучения гораздо больше, чем данные реального мира.
Zara6502
я бы подобрал синоним, например - тренировка.
rPman
Устоявшаяся терминология именно обучение модели, например есть термин переобученная, предобученная и т.п.
Жаль в статье ничего не сказано про методы создания этих данных, ведь в них кроются проблемы, которые можно привнести в обеспечивать модель