

Команда VK Cloud перевела пошаговую инструкцию о том, как установить и сконфигурировать ingress-nginx, Prometheus и Grafana, а также настроить оповещения для ключевых метрик Ingress. Для работы понадобится кластер Kubernetes и Helm v3.
Устанавливаем Prometheus и Grafana
Первым делом установим Prometheus для сбора метрик и Grafana для визуализации и создания оповещений на их основе.
Установим Helm chart kube-prometheus-stack, скопировав следующие команды в свой терминал. Так мы установим Grafana, Prometheus и другие компоненты для мониторинга.
# Add and update the prometheus-community helm repository.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
cat <<EOF | helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--create-namespace -n monitoring -f -
grafana:
enabled: true
adminPassword: "admin"
persistence:
enabled: true
accessModes: ["ReadWriteOnce"]
size: 1Gi
ingress:
enabled: true
ingressClassName: nginx
hosts:
- grafana.localdev.me
EOF
Давайте убедимся, что установленные компоненты работают:
kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
kube-prometheus-stack-grafana-7bb55544c9-qwkrg 3/3 Running 0 3m38s
prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 3m14s
...
Переходим к следующему этапу.
Установка и настройка Ingress Nginx
На этом этапе устанавливаем и настраиваем контроллер Nginx ingress и включаем метрику, которую собирает Prometheus.
1. С помощью следующей команды устанавливаем ingress Nginx в кластер:
helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespace \
--set controller.metrics.enabled=true \
--set controller.metrics.serviceMonitor.enabled=true \
--set controller.metrics.serviceMonitor.additionalLabels.release="kube-prometheus-stack"
Чтобы Prometheus мог обнаружить монитор служб и автоматически подтягивать из него метрики, в качестве
release: kube-prometheus-stack указываем serviceMonitor.additionalLabels.2. Установив чарт, давайте для примера выполним деплоймент приложения podinfo в пространстве имен по умолчанию.
helm install --wait podinfo --namespace default \
oci://ghcr.io/stefanprodan/charts/podinfo
3. Теперь создаем ingress для выполненного деплоймента podinfo:
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo-ingress
spec:
ingressClassName: nginx
rules :
- host: podinfo.localdev.me
defaultBackend:
service:
name: podinfo
port:
number: 9898
EOF
Давайте немного углубимся в эту конфигурацию ingress:
- В качестве ingress-контроллера мы используем ingress-nginx, поэтому класс
ingressопределяется какnginx.
- В этой конфигурации я использовал
podinfo.localdev.meкак адрес хоста для Ingress.
- DNS *.localdev.me трансформируется в 127.0.0.1, так что этот DNS можно использовать для любого локального тестирования, не добавляя запись в файл /etc/hosts.
- Приложение Podinfo обслуживает HTTP API через порт 9898, и поэтому мы указываем его для backend-порта. То есть трафик, поступающий в домен http://podinfo.localdev.me, направляется на порт 9898 службы podinfo.
4. Далее с терминала трафик необходимо перенаправить на порт службы ingress-nginx, чтобы можно было направлять трафик с локального терминала.
kubectl port-forward -n ingress-nginx service/ingress-nginx-controller 8080:80 > /dev/null &Порт хоста 80 — привилегированный порт, так что его мы не трогаем. Вместо этого мы привяжем порт 80 службы nginx к порту 8080 хост-машины. Можно указать любой допустимый порт на ваш выбор.
Если вы запускаете службу в облаке, в перенаправлении портов нет необходимости, так как LoadBalancer службы ingress-nginx создается автоматически — служба определяется как LoadBalancer по умолчанию.
5. Теперь выполняем следующий запрос curl к конечной точке podinfo и получаем ответ:
> curl http://podinfo.localdev.me:8080
"hostname": "podinfo-59cd496d88-8dcsx"
"message": "greetings from podinfo v6.2.2"
6. URL в браузере будет выглядеть симпатичнее: http://podinfo.localdev.me:8080/

Настройка дашбордов Grafana для мониторинга Ingress Nginx
Чтобы запустить Grafana, нужно открыть в браузере URL с учетными данными admin:admin : http://grafana.localdev.me:8080/.
Чтобы импортировать дашборд, скопируйте отсюда thenginx.json и вставьте в http://grafana.localdev.me:8080/dashboard/import. Вот так должен выглядеть импортированный дашборд:
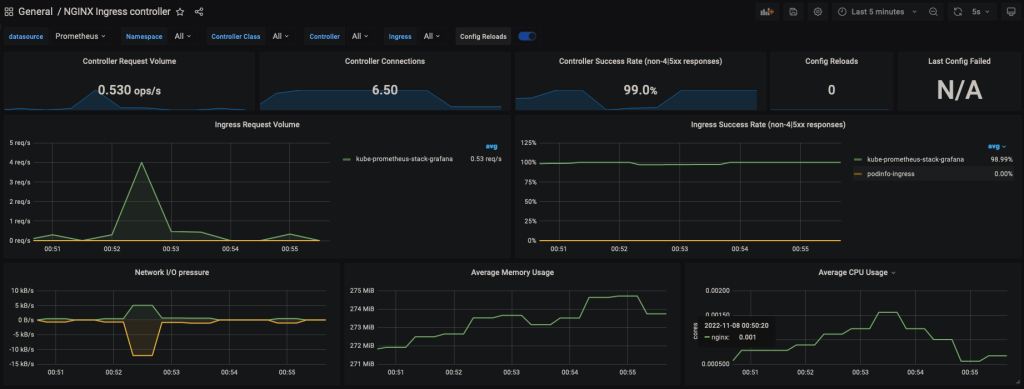
Генерируем нагрузки для примера
Чтобы направить трафик в приложение podinfo, воспользуемся инструментом нагрузочного тестирования vegeta. Его можно взять отсюда. Для примера давайте создадим трафик HTTP 4xx. Для этого выполните следующую команду, которая запускается с частотой запросов 10 RPS на 10 минут:
echo "GET http://podinfo.localdev.me:8080/status/400" | vegeta attack -duration=10m -rate=10/s
Можно изменить код состояния с 400 на 500 и выполнять команду и для тестового трафика 5xx.
Для проверки задержки я использовал команду
GET /delay/{seconds} waits за указанный период:echo "GET http://podinfo.localdev.me:8080/delay/3" | vegeta attack -duration=10m -rate=100/s
Примечание: здесь можно дополнительно почитать о конечных точках в приложении podinfo.
Оповещения о метриках SLI в Grafana
В последних версиях Grafana поддерживается собственный механизм отправки оповещений. Таким образом, можно собрать в одном месте все оповещения о конфигурации и правилах и даже аварийные оповещения. Давайте настроим оповещения для распространенных SLI.
Частота ошибок 4xx
1. Чтобы создать оповещение, давайте перейдем в http://grafana.localdev.me:8080/alerting/new.
2. Для получения частоты ошибок 4xx в процентах можно использовать следующую формулу: (общее количество запросов 4xx / общее количество запросов) * 100.
3. Добавьте в запрос следующее выражение:
(sum(rate(nginx_ingress_controller_requests{status=~'4..'}[1m])) by (ingress) / sum(rate(nginx_ingress_controller_requests[1m])) by (ingress)) * 100 > 5
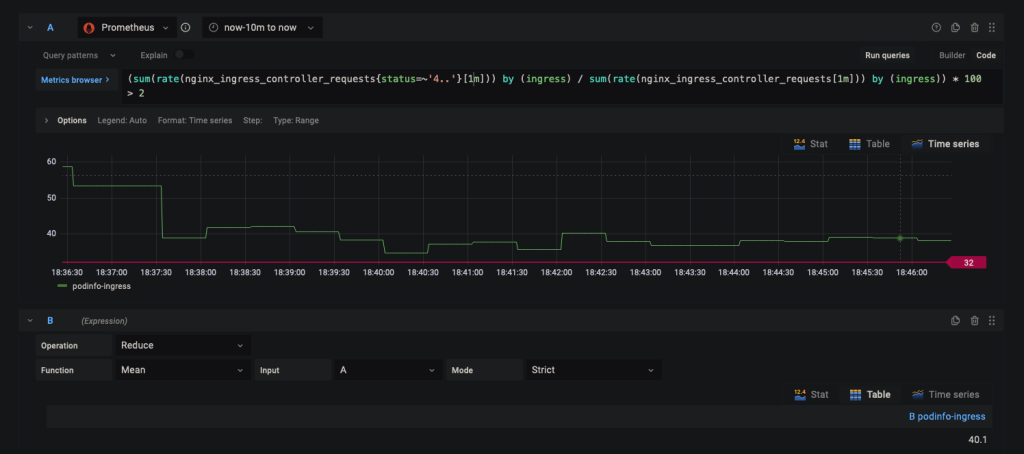
4. В выражении B используйте операцию редукции с функцией Mean для вводных A.
5. В Alert Details назовите оповещение так, как вам нравится. Я свое назвал Ingress_Nginx_4xx.
6. Summary можно сделать максимально коротким: просто показать имя Ingress с меткой {{ $labels.ingress }}.
Ingress High Error Rate : 4xx on *{{ $labels.ingress }}*
7. В Description я использовал
printf "%0.2f", чтобы проценты отображались с точностью до двух знаков после запятой.4xx : High Error rate : `{{ printf "%0.2f" $values.B.Value }}%` on *{{ $labels.ingress }}*.
8. В целом оповещение должно быть похоже на снапшот ниже:

9. В конце можно добавить пользовательскую метку, например
severity : critical. Частота ошибок 5xx
Как и в случае с настройкой оповещений 4xx, для частоты ошибок 5xx можно использовать следующий запрос:
sum(rate(nginx_ingress_controller_requests{status=~'5..'}[1m])) by (ingress,cluster) / sum(rate(nginx_ingress_controller_requests[1m]))by (ingress) * 100 > 5
В соответствии с настройками оповещение отправляется, когда процент 5xx/4xx превышает 5 %. Настраиваем таким образом, чтобы это соответствовало нашим требованиям, а именно Error budget — времени, в течение которого система может испытывать проблемы без нарушений SLA.
Большая задержка (p95)
Чтобы рассчитать 95-й процентиль продолжительности запросов за последние 15 минут, можно использовать метрику
nginx_ingress_controller_request_duration_seconds_bucket. Так вы получите The request processing time in milliseconds. Поскольку это бакет, мы можем использовать функцию histogram_quantile. Создайте оповещение, похожее на пример выше, и используйте следующий запрос:histogram_quantile(0.95,sum(rate(nginx_ingress_controller_request_duration_seconds_bucket[15m])) by (le,ingress)) > 1.5
Я установил пороговое значение на уровне 1,5 секунды, но его можно изменить в соответствии с вашим SLO.
Высокая частота запросов
Чтобы получить частоту запросов в секунду (RPS), можно использовать следующий запрос:
sum(rate(nginx_ingress_controller_requests[5m])) by (ingress) > 2000
В таком случае оповещение отправляется, когда частота запросов превышает 2000 RPS.
Другие SLI
Скорость подключения. Измеряет количество активных подключений к Nginx ingress и может использоваться для выявления потенциальных проблем с подключениями.
rate(nginx_ingress_controller_nginx_process_connections{ingress="ingress-name"}[5m])
Upstream response time. Время на ответ исходной службы на запрос; помогает выявлять проблемы не только с ingress, но и со службой.
histogram_quantile(0.95,sum(rate(nginx_ingress_controller_response_duration_seconds_bucket[15m])) by (le,ingress))
Шаблон оповещений в Slack
Чтобы сообщения с оповещениями были удобочитаемыми, можно использовать шаблоны оповещений в Grafana.
1. Чтобы их настроить, перейдем в http://grafana.localdev.me:8080/alerting/notifications и создадим новый шаблон. Назовем его slack и скопируем следующий блок кода:
{{ define "alert_severity_prefix_emoji" -}}
{{- if ne .Status "firing" -}}
:white_check_mark:
{{- else if eq .CommonLabels.severity "critical" -}}
:fire:
{{- else if eq .CommonLabels.severity "warning" -}}
:warning:
{{- end -}}
{{- end -}}
{{ define "slack.title" -}}
{{ template "alert_severity_prefix_emoji" . }} {{- .Status | toUpper -}}{{- if eq .Status "firing" }} x {{ .Alerts.Firing | len -}}{{- end }} | {{ .CommonLabels.alertname -}}
{{- end -}}
{{- define "slack.text" -}}
{{- range .Alerts -}}
{{ if gt (len .Annotations) 0 }}
*Summary*: {{ .Annotations.summary}}
*Description*: {{ .Annotations.description }}
Labels:
{{ range .Labels.SortedPairs }}{{ if or (eq .Name "ingress") (eq .Name "cluster") }}• {{ .Name }}: `{{ .Value }}`
{{ end }}{{ end }}
{{ end }}
{{ end }}
{{ end }}
2. Настраиваем новую точку контакта типа Slack. Для этого нужно создать входящий вебхук из Slack. Все подробно расписано в этом документе.
3. Редактируем точку контакта slack, прокручиваем вниз и выбираем параметр Optional Slack settings.
4. В Title ниже укажем, какой шаблон использовать:
{{ template "slack.title" . }}
5. В Text Body введем приведенный ниже код и сохраним его:
{{ template "slack.text" . }}
6. Перейдем в http://grafana.localdev.me:8080/alerting/routes и укажем Slack в параметре Default contact point.
Вот, наконец, и сообщение с оповещением!
Все шаги выполнены, мы получили результат: вот так выглядит оповещение в Slack.
Частота ошибок 4xx:

Частота ошибок 5xx:

Задержка p95:

В зависимости от актуальных требований можно исправить множество вещей. Например, если у вас несколько кластеров Kubernetes, можно добавить метку кластера, которая поможет идентифицировать в оповещении исходный кластер.
Aviator: автоматизируйте тяжеловесные процессы merge

Aviator автоматизирует тяжелые рабочие процессы для разработчиков, управляя запросами Pull (Pr) в Git; благодаря тестированию в ходе непрерывной интеграции (CI) это помогает избежать сломанных сборок, оптимизировать утомительные процессы объединения, управлять cross-PR-зависимостями и справляться с нестабильными тестами, соблюдая при этом требования безопасности.
Aviator состоит из четырех основных компонентов:
-
MergeQueue — автоматизированная очередь, которая управляет рабочим процессом Merging для репозитория GitHub, защищая важные ветви от неисправных сборок. Бот Aviator использует GitHub Labels для идентификации готовых к объединению запросов Pull (PR), подтверждает проверки CI, обрабатывает семантические конфликты и автоматически объединяет PR.
-
ChangeSets — рабочие процессы, призванные синхронизировать валидацию и объединение нескольких PR в одном репозитории или в нескольких. Может пригодиться, если у вашей команды часто появляются группы связанных между собой PR, которые нужно объединить или иным образом обработать как единый, более крупный блок изменений.
-
FlakyBot — инструмент, который умеет автоматически определять и обрабатывать результаты нестабильных тестов в инфраструктуре CI.
-
Stacked PRs CLI — инструмент командной строки для работы с cross-PR-зависимостями. Этот инструмент также автоматизирует синхронизацию и объединение PR в стеке. Помогает развивать культуру небольших инкрементальных PR вместо больших изменений и подходит для ситуаций, когда ваши рабочие процессы завязаны на синхронизацию нескольких зависимых PR.
Вы можете опробовать мониторинг Kubernetes в облаке VK Cloud. Новым пользователям мы начисляем 3000 приветственных бонусов.