
В этой статье я углублённо сравню потребление памяти между асинхронными и многопоточными программами популярных языков вроде Rust, Go, Java, C#, Python, Node.js и Elixir.
Недавно я проводил сравнение производительности нескольких программ, предназначенных для обработки большого количества сетевых подключений. В итоге я увидел огромную разницу в потреблении этими программами памяти, порой в 20 раз и больше. Некоторые потребляли при 10К подключений чуть более 100 МБ в то время, как другие занимали почти 3 ГБ. К сожалению, эти программы были довольно сложными и также отличались своим функционалом, поэтому было бы трудно сравнить их непосредственно и сделать какие-то осмысленные выводы. Тут то у меня и возникла идея создать специальный синтетический бенчмарк.
Бенчмарк
Я написал на различных языках простую программу, работающую следующим образом:
Мы запускаем N конкурирующих задач, каждая из которых ожидает 10 секунд. Когда все эти задачи завершаются, программа закрывается. Количество задач управляется аргументом командной строки.
С небольшой помощью ChatGPT я смог создать эту программу всего за несколько минут, даже на языках, которые использую редко. Для вашего удобства весь код бенчмарка доступен в моём репозитории GitHub.
▍ Rust
На Rust я написал 3 программы. Первая использует традиционные потоки. Вот её основная часть:
let mut handles = Vec::new();
for _ in 0..num_threads {
let handle = thread::spawn(|| {
thread::sleep(Duration::from_secs(10));
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}В двух остальных версиях иcпользуется асинхронная обработка, одна в среде выполнения
tokio, а другая в async-std. Вот основная часть варианта tokio:let mut tasks = Vec::new();
for _ in 0..num_tasks {
tasks.push(task::spawn(async {
time::sleep(Duration::from_secs(10)).await;
}));
}
for task in tasks {
task.await.unwrap();
}Версия
async-std очень похожа, поэтому я её приводить не буду.▍ Go
В Go многопоточность строится на основе горутин. При этом мы не ожидаем их по-отдельности, а используем
WaitGroup:var wg sync.WaitGroup
for i := 0; i < numRoutines; i++ {
wg.Add(1)
go func() {
defer wg.Done()
time.Sleep(10 * time.Second)
}()
}
wg.Wait()▍ Java
В Java традиционно используются потоки, но JDK 21 предлагает предварительную версию виртуальных потоков, которые очень похожи на горутины. В связи с этим я создал два варианта бенчмарка. Мне было интересно сравнить потоки Java с потоками Rust.
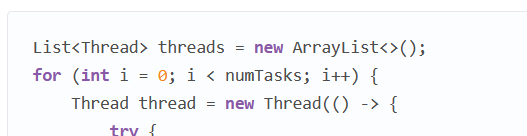
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < numTasks; i++) {
Thread thread = new Thread(() -> {
try {
Thread.sleep(Duration.ofSeconds(10));
} catch (InterruptedException e) {
}
});
thread.start();
threads.add(thread);
}
for (Thread thread : threads) {
thread.join();
}А вот версия с виртуальными потоками. Заметьте, насколько она похожа на предыдущую. Почти идентична!
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < numTasks; i++) {
Thread thread = Thread.startVirtualThread(() -> {
try {
Thread.sleep(Duration.ofSeconds(10));
} catch (InterruptedException e) {
}
});
threads.add(thread);
}
for (Thread thread : threads) {
thread.join();
}▍ C#
В C#, как и в Rust, есть отличная поддержка функционала
async/await:List<Task> tasks = new List<Task>();
for (int i = 0; i < numTasks; i++)
{
Task task = Task.Run(async () =>
{
await Task.Delay(TimeSpan.FromSeconds(10));
});
tasks.Add(task);
}
await Task.WhenAll(tasks);▍ Node.js
То же касается Node.js:
const delay = util.promisify(setTimeout);
const tasks = [];
for (let i = 0; i < numTasks; i++) {
tasks.push(delay(10000);
}
await Promise.all(tasks);▍ Python
В версии Python 3.5 также появился функционал
async/await, поэтому можно написать:async def perform_task():
await asyncio.sleep(10)
tasks = []
for task_id in range(num_tasks):
task = asyncio.create_task(perform_task())
tasks.append(task)
await asyncio.gather(*tasks)▍ Elixir
Elixir тоже известен своими асинхронными возможностями:
tasks =
for _ <- 1..num_tasks do
Task.async(fn ->
:timer.sleep(10000)
end)
end
Task.await_many(tasks, :infinity)▍ Тестовая среда
- Оборудование: Intel® Xeon® CPU E3-1505M v6 @ 3.00GHz
- ОС: Ubuntu 22.04 LTS, Linux p5520 5.15.0-72-generic
- Rust: 1.69
- Go: 1.18.1
- Java: OpenJDK “21-ea” build 21-ea+22-1890
- .NET: 6.0.116
- Node.JS: v12.22.9
- Python: 3.10.6
- Elixir: Erlang/OTP 24 erts-12.2.1, Elixir 1.12.2
Все программы по возможности запускались с использованием режима Release. Остальные опции я оставлял по умолчанию.
Результаты
▍ Минимальная нагрузка
Начнём с небольшой нагрузки. Поскольку некоторые среды выполнения требуют памяти сами по себе, сначала мы запустим всего одну задачу.
Рис. 1: пиковое потребление памяти при запуске одной задачи
Здесь у нас явно выделяется две группы программ. Программы Go и Rust, скомпилированные статично в нативные бинарники, требуют очень мало памяти. Другие программы, выполняющиеся на управляемых платформах или через интерпретаторы, потребляют её уже больше, хотя Python тут выглядит очень достойно. Потребление памяти между этими группами отличается почти на порядок.
Меня удивило, что .NET умудрилась продемонстрировать худший показатель, но это наверняка можно скорректировать настройками. Поделитесь в комментариях, если знаете какие-либо уместные приёмы. Между режимами Debug и Release я особой разницы не заметил.
▍ 10К задач
Рис. 2: пиковое потребление памяти при запуске 10,000 задач
Здесь у нас обнаружилось несколько сюрпризов. Вы, пожалуй, ожидали, что потоки в этом бенчмарке сильно проиграют. И это оказалось верно для потоков Java, которые действительно потребили почти 250 МБ. Однако нативные потоки Linux, используемые из Rust, оказались достаточно легковесными, чтобы в количестве 10,000 нагружать память меньше, чем при простое во многих других процедурах. Асинхронные задачи, или виртуальные потоки, могут быть легче нативных потоков, но при всего 10К задач это преимущество мы не заметим.
Ещё один сюрприз связан с Go. Ожидалось, что горутины являются очень легковесными, но по факту они потребили более 50% от объёма памяти, задействованной потоками Rust. Честно говоря, я ожидал более значительное отличие в пользу Go. Так что можно сделать вывод, что при 10К конкурирующих задач потоки всё равно оказываются довольно сильной альтернативой. Ядро Linux определённо хорошо здесь справляется.
Go также утратил своё крохотное преимущество перед Rust, продемонстрированное в предыдущем бенчмарке, и теперь потребляет в 6 раз больше памяти, чем наиболее оптимальная программа Rust. При этом его также обошёл Python.
И последним сюрпризом стало то, что при 10К задач потребление памяти программой .NET по сравнению с состоянием простоя возросло незначительно. Возможно, она использует заранее выделенную память, либо потребление этого ресурса в режиме простоя настолько велико, что 10К задач большой разницы не вносят.
▍ 100К задач
Мне не удалось запустить 100,000 потоков в моей системе, поэтому соответствующие бенчмарки пришлось исключить. Возможно, это можно было как-то наладить через настройки, но после часа безуспешных попыток я сдался. Так что при 100К задач вряд ли стоит использовать потоки.
Рис. 3: пиковое потребление памяти при запуске 100,000 задач
В этом тесте программу Go обошёл не только Rust, но также Java, C# и Node.js.
А .NET, похоже, здесь хитрит, поскольку её потребление памяти так и не возросло. Мне пришлось перепроверить, действительно ли она запускает правильное количество задач, но оказалось, что так и есть. При этом она также выходит через 10 секунд, значит основной цикл не блокируется. Просто магия! Хорошая работа, .NET.
▍ 1 миллион задач
Перейдём к экстремальным испытаниям.
При 1 миллионе задач программа Elixir сдалась с ошибкой
** (SystemLimitError) a system limit has been reached. Дополнено: в комментариях мне указали, что можно увеличить лимит процессов. После добавления в вызовelixirпараметра--erl '+P 1000000'программа заработала.
Рис. 4: пиковое потребление памяти при запуске 1 миллиона задач
Наконец, мы видим увеличение потребления памяти программой C#. Но она всё ещё остаётся весьма конкурентной и даже немного обошла одну из сред выполнения Rust.
Отставание Go от соперников увеличилось. Теперь этот язык проигрывает победителю в 12 раз. Он также в 2 раза уступает Java, что противоречит распространённому мнению о том, что JVM является пожирателем памяти, а Go – легковесным языком.
Среда
tokio осталась непревзойдённой. И это не удивительно после того, как она показала себя при 100К задач.Выводы
Как мы пронаблюдали, большое число конкурирующих задач могут потреблять значительный объём памяти, даже без обработки сложных операций. Различные среды выполнения языков несут в себе различные компромиссы. Некоторые являются легковесными и эффективно справляются с небольшим числом задач, плохо масштабируясь на сотни тысяч. При этом другие накладывают большие изначальные издержки, но могут с лёгкостью обрабатывать тяжёлую нагрузку. Важно отметить, что не все среды выполнения смогли осилить очень большое число конкурирующих задач при базовых настройках.
Это сравнение было сосредоточено исключительно на потреблении памяти, хотя другие факторы вроде скорости запуска задачи и передачи данных являются не менее важными. Примечательно, что при 1 миллионе задач стали очевидны издержки на их запуск, и большинству программ для завершения потребовалось более 12 секунд.
Комментарии (51)

gdt
04.06.2023 10:34+17Соглашусь с предыдущим оратором, как минимум в .Net запустить 10К тасок != запустить 10К параллельных задач. Так-то асинхронность и на одном потоке бывает.

ksbes
04.06.2023 10:34И кстати автор забыл по Future в Java, которые обычно и используются для таких задач. Возможно специально - т.к. там пул потоков надо явно настраивать и вся разность между асинхронностью и параллелизмом сразу бы вылезла.

MountainGoat
04.06.2023 10:34+6Ещё один сравниот. Берём первый же код на Расте и читаем первые строки и... num_threads это сколько? Если по числу задач, то код дурак писал. Если по числу ядер CPU, то что с чем сравниваем дальше? И почему не rayon тогда?

Tsimur_S
04.06.2023 10:34+5Берём первый же код на Расте и читаем первые строки и... num_threads это сколько
Ответ на этот вопрос можно найти в формулировке задачи.
Если по числу задач, то код дурак писал
Код писал chatgpt и кстати в полном соответствии с задачей.
то что с чем сравниваем дальше
Ответа на этот вопрос нет даже в оригинале статьи.
И почему не rayon тогда?
Точный ответ не известен но скорее всего автор либо о нем не знал либо избегал фреймворк не мейнстримных.

awfun
04.06.2023 10:34Подскажите пожалуйста, корректно ли в этом случае считать размер потребляемой памяти как количество потоков умноженное на размер стека для одного потока (Xss = 512 кб в java) ? Чем обусловлено различие между обычными и виртуальными потоками?

thevlad
04.06.2023 10:34+2Разница примерно такая, как между аппаратными потоками и корутинами. Формально ОС может аллоцировать физическую память, только в момент когда она будет нужна, то есть page fault, и это работает для стэка, по крайней мере в линукс. Какие дополнительные факторы вводит Java VM, я не знаю, но думаю на логику ядра не должно сильно влиять.

mentin
04.06.2023 10:34Для короутин в .NET - точно нет, они требуют только память для state machine и переменных, а стек выделяется только при активном исполнении, при асинхронном ожидании стек не используется.
Про другие языки не уверен, но наверное эта память выделяется тоже только на физические потоки.
Но главное, автор не указал как измерял потребление памяти. XSS это в основном виртуальная память, реально используется мало. Скорее всего виртуальную память он не включал.

tmaxx
04.06.2023 10:34В Java размер памяти скорее всего будет меньше чем Xss * n_threads. Во-первых, стек спящего виртуального потока находится в куче и выделяется динамически, блоками (которые меньше Xss). Во-вторых, если у разных потоков первые (нижние) блоки стека совпадают, то они переиспользуются.

inso
04.06.2023 10:34+29В этой статье я углублённо сравню потребление
Нет, в этой статье весьма поверхностно что-то сравнивается непонятно зачем.

programmerjava
04.06.2023 10:34И как вишенка на торте (только то, что я знаю лучше):
Бенчмарк без прогрева jvm :) а старт ух как много занимает
Виртуальные потоки в java еще только preview и недоступны без дополнительных флагов запуска jvm. Еще сыро
С++ нет в сравнении :)
Автор не пользуется формулой расчета количества потоков: операции неблокирующие => в пределах количества ядер cpu; блокирующие => создавать как можно больше потоков.
Бессмысленное создание огромного количества потоков. Отсутствует нивелирование тред пулом, о реактивном подходе и говорить не приходится.
Для его задач можно указать размер стека треда по дефолту в java. в hotspot там 1mb, но могу ошибаться. если сделать в два раза ниже, то и графики будут лучше :)

Sulerad
04.06.2023 10:34+4В моём понимании, весь этот тест задумывался именно как анализ накладных расходов на запуск тасок внутри разных рантаймов, а не как эксперимент по запуску миллиона системных тредов из разных языков. И тогда он получается почти полностью осмысленный. Огорчает что правда почти никаких реальных ресурсов не создаётся и переключений между тасками нету, но может оно и к лучшему.
Без прогрева JVM
Сравнивается же память, а не время. Кажется, прогрев здесь не поможет, нет? Мне честно интересно, я с JVM почти не сталкиваюсь, на самом деле.
С++ нет в сравнении
А в нём есть какой-то достаточно меинстримный event loop? Всё-таки здесь по большей части сравниваются рантаймы, чем умение запустить миллион системных тредов из десяти разных языков. Опять не знаю ответа, на самом деле.
Автор не пользуется формулой расчета количества потоков
Если я всё правильно понимаю, то тут как раз таки блокирующий sleep и имеет смысл именно что запускать миллион тасок одновременно: на CPU нагрузки считай что нет. А вот память на обработку этих тасок действительно интересно поглядеть.
Отсутствует нивелирование тред пулом,
Большинство здесь приведённых рантаймов как раз таки раскидывают таски по тредам из своего пула. Не ручками же это реализовать, коли язык уже содержит довольно хорошую реализацию.
programmerjava
04.06.2023 10:34прогрев здесь не поможет, нет? Мне честно интересно, я с JVM почти не сталкиваюсь, на самом деле
Надо просто хотя бы вычесть размер памяти для jvm. Но опять же, если это нормально, то и не надо может быть.
как раз таки раскидывают таски по тредам из своего пула. Не ручками же это реализовать
Либо я не понял. Либо вы. Но в коде вы просто создаете платформенные потоки в Java при чем их число равно количеству задач
Не понял как вы смогли таким образом 100к запустить потоков. У вас возможно зависнуть должно было еще ранее. Но что точно, так миллион задач вы бы реально не смогли. Но все таки в диаграмму и по c100k и по c1000k вывели записали какие-то данные. Не могли бы вы подсказать сразу откуда ? В моем понимании должно было зависнуть у вас. На железе, которое мощнее и 200к не запустить.
А в нём есть какой-то достаточно меинстримный event loop?
Вы имеете ввиду event-loop из ui движка ? Мне кажется мы о разном... На c++ много что есть. Попробуйте реактивное программирование на нем, если вам именно фреймворки интересуют или подходы какие-то.
Если я всё правильно понимаю, то тут как раз таки блокирующий sleep и имеет смысл именно что запускать миллион тасок одновременно
На самом деле у вас не запустились таски одновременно и вы кстати не проверили результат каждого потока. Так что и не уверен, что какая-нибудь платфрома не забила и не оптимизировала так, что можно не запускать бесполезный поток или что-то с ним сделать. Попробуйте рамдомное число брать от каждого потока и складывать куда-нибудь в коллекцию по окончанию. Потом посчитать. Было бы интересно увидеть как изменятся графики
Sulerad
04.06.2023 10:34Но все таки в диаграмму и по c100k и по c1000k вывели записали какие-то данные.
Вариант с платформенными тредами как раз таки (ожидаемо) довольно быстро вылетел из соревнования и с большими числами запускался уже только
Thread.startVirtualThreadНа самом деле у вас не запустились таски одновременно
Они определённо не запустились in parallel — ни ядер, ни системных потоков никак не хватит. Но я уверен, что объекты тасок создавались и каждая concurrently ждала своего sleep(10) — ни одна таска не завершилась раньше десяти секунд. Кажется в этом же и суть бенчмарка — насоздавать (легковесных) тасок и посмотреть накладные расходы. А внутри них sleep чтобы весь миллион действительно висел в памяти в один момент времени.
Так что и не уверен, что какая-нибудь платфрома не забила и не оптимизировала
I/O-bound таске и не нужен отдельный поток для себя одной, а у нас здесь именно такие. При этом я плохо представляю как платформа может оптимизировать запуск миллиона тасок ждущих 10 секунд в что-то более оптимальное вроде «одна таска которая ждёт 10+ε секунд». У нас же есть сайд-эффект, что программа выполняется вполне конкретное время, его надо как-то сохранить.
Было бы интересно увидеть как изменятся графики
К сожалению, я не автор, а лишь простой мимокрокодил =)


click0
04.06.2023 10:34+14Очень странно не видеть кода и сравнения тестов на С и С++...

Dominux
04.06.2023 10:34По факту будет аналогичный расту результат, особенно с компилятором на llvm
Уверен, автор решил не рассматривать их ещё и потому, что оч многое в сишке зависит от наддоченной настройкой компиляции. Ребята в комментах под статьями про низкие уровни мериются, у кого подобный хелоу уорлд выполнится на нс быстрее других и на 1 байт меньше аллоцируют памяти


powerman
04.06.2023 10:34+14Миллион что-то вычисляющих задач не имеет практической пользы, если только не запускается на компе со сравнимым числом ядер (а это явно не наш случай).
Миллион задач занятых I/O вполне имеет смысл, но там на каждую задачу будут выделяться буферы, как ядра (для сокетов), так и на уровне приложения (для обработки данных). Эти буферы сожрут во много раз больше памяти, и на этом фоне указанные в бенчмарках числа просто потеряются.
Резюмируя, практическая польза от этого бенчмарка сводится к "вот эти языки позволяют запустить миллион параллельных задач" на домашнем компе. И это даже не эквивалентно чуть более полезному "на этих языках миллион параллельных задач будет эффективно выполняться".
thevlad
04.06.2023 10:34+1Переключение задач занимает не нулевое время, что приведет к трэшингу шедулера и печальной производительности. Поэтому для сокетов при решении таких задач(c10k и c100k problem) используются механизмы async io, epoll в линукс, и iocp в windows.
powerman
04.06.2023 10:34+1В целом да, но с "поэтому" я не соглашусь. Все эти механизмы используются не потому, что реальные треды OS долго переключать, а потому, что на реальные треды выделяется стек совершенно другого размера (около 1 MB, если не путаю), поэтому миллион реальных тредов OS потребует 1 TB памяти только на стек. Вот поэтому для таких задач используют исключительно "лёгкие" треды и мапинг M лёгких тредов на N (обычно N == количеству ядер) тредов OS. Т.е. epoll (а скоро его заменят на iouring) сотоварищи нередко используется совместно с тредами OS, а не вместо них.
thevlad
04.06.2023 10:34+1Epoll обычно используется с количеством потоков, которые могут плюс минус работать параллельно физически. Стэк не аллоцируется весь физически при старте потока, как я писал выше. https://unix.stackexchange.com/questions/127602/default-stack-size-for-pthreads
И микросекунда в лучшем случаи на context switch это совсем не мало.

0xd34df00d
04.06.2023 10:34+2поэтому миллион реальных тредов OS потребует 1 TB памяти только на стек.
Виртуальной. Ничего особо страшного.

vadimr
04.06.2023 10:34Согласен с Вами. Добавлю, что на компе с миллионом ядер параллелизм обеспечивается не тредами, так как не бывает общей памяти на миллион ядер.
А так-то домашнему компу начинает плохеть банально при постоянном LA > Cores.
Ну и async/await вообще не является средством многозадачности.

GennPen
04.06.2023 10:34+9Мне кажется, тест не объективный. Нужно в задачах хоть что-то, хотя бы цикл на увеличение общего счетчика N раз. Таким образом можно отследить, не хитрит ли компилятор/транслятор отбрасывая ничего не значащее sleep(). Да и скорость обработки переключений и запуска можно измерить.
GennPen
04.06.2023 10:34К слову, на C# добавление в задачу простого цикла for на увеличение общего счетчика увеличивает потребление памяти в два раза, примерно до 850 Мб.

MarlyasDad
04.06.2023 10:34+3Автор тут сравнивает красное с мягким (конкурентное и параллельное выполнение). Async/await в том же самом Python выполняется на 1-м (Карл!!!) ядре. Не надо так!

Farongy
04.06.2023 10:34+6Из статьи я понял только то, что, если человек не понимает что он делает, ChatGPT ему не поможет)

galkon
04.06.2023 10:34+2>Между режимами Debug и Release я особой разницы не заметил.
На самом деле оч сильно влияет
Basically debug deployment will be slower since the JIT compiler optimizations are disabled.
a-tk
04.06.2023 10:34Задача спать 10 секунд примерно одинаковая для обоих режимов. Если бы там числа Фибоначчи считали время от времени, то можно было бы за это говорить, а так..
galkon
04.06.2023 10:34Смысл это обсуждать, если даже условия тестов некорректны? Даже не углубляясь в задачу это можно сказать
Блин, да не должен пользователь вообще работать с Debug сборками, априори.
Вот на С++ например, отладочный рантайм вообще не поставляется в vcredist, у конечного пользователя приложенька даже не запустится, аллокация памяти будет идти медленнее и т.д

Schokn-Itrch
04.06.2023 10:34+1Вопрос не в языке, а в оптимизации. Нужно сравнивать не только объем используемой памяти, но и время на исполнение кода.
Если кто-то уложится в гиг при 10 минутах, против кого-то в 100 гигов при 1 минуте, то первый вариант для кого-то предпочтительнее, а для кого-то другой.
Но, в целом, я согласен что тест нерепрезентативен. Хотя бы потому, что не учитывает вариант последовательного исполнения менее поточных, но менее затратных по времени.

navferty
04.06.2023 10:34+1Вообще не понимаю смысла публикации, в одном случае старт потоков с блокирующем ожидаением, в другом - асинхронное ожидание отложенного коллбека. Жаль, не могу поставить минус статье.

sv_911
04.06.2023 10:34Но вопрос на самом деле интересный. В чем разница между блокирующим ожиданием и ожиданием коллбека? И там и там есть event loop, только в одном случае он реализован в ядре, в другом - на уровне приложения. Почему тогда коллбеки лучше?
Да, можно привести множество разных доводов (типа для ядра выполняется больше проверок безопасности, поэтому получается медленнее, но почему в ядро не добавить опцию "не делать проверки" и т.п.)
ksbes
04.06.2023 10:34Дело не в том, что лучше, а что это абсолютно разные механизмы. В одном случае ОС даёт нам свою отдельную независимую нить исполнения со собственным стеком и прочими плюшками и оверхедом, а во втором просто в табличке в памяти создаётся строчка что мол в такую-то миллисекунду или позже вызови такую функцию.
И то и то имеет свои плюсы и минусы, но сравнивать их так в тупую, ка сделано в статье - это просто бессмысленно.
Я не удивлюсь, если окажется, что тот же компилятор Го или Раста вообще соптимизировали и выкинули создание корутин/тасков и заменили просто на один 10 секундный таймер.sv_911
04.06.2023 10:34Да нету никакой принципиальной разницы. Разве что между stackless и stackfull корутинами есть (в данном случае в ядре stackfull корутины), но и то нужно специальные примеры подбирать, чтобы разницу увидеть.
Соптимизировать да, в теории могли, но на практике это очень маловероятно

aceofspades88
04.06.2023 10:34+4И самое главное у каждого вот такого Пети(автор оригинала) есть свой блог, куча статей в медиуме и даже книга "Как надо писать код"(особенно у индусских Петь) и весь этот "контент" неокрепшие умы впитывают как истину)

Panzerschrek
04.06.2023 10:34В Go, насколько я понимаю, там стек под задачу выделяется, хоть поначалу и весьма небольшой. А в Rust же async функции стека вовсе не имеют и занимают памяти ровно столько, сколько нужно под локальные переменные и аргументы. В случае с async функцией, которая только sleep вызывает, там этой памяти может быть на пару-тройку указателей (24 б) да и только.

mohtep
04.06.2023 10:34+1Бенчмарк для го написан совершенно неверно. Чтобы не расходовать стек под горутины их надо "приземлять". Если будут запросы - покажу как этот код надо переделать для миллиона потоков.

Areso
04.06.2023 10:34+1Можете статью написать?
Не знаю как другим, мне было бы интересно.
mohtep
04.06.2023 10:34+1Хорошо, сделаю :)
Есть какие-то конкретные нюансы, которые интересны? или технологию в-общем?Areso
04.06.2023 10:34+1Ну, про горутины много где описано, включая го-тур.
Интересуют более сложные примеры, чем те, что есть в документациях и везде. Как одна из частностей, стоящих для рассмотрения -- вот, вариант с миллионом потоков.
Можно рассмотреть несколько разных примеров под разные задачи.

mikhanoid
04.06.2023 10:34+2Это просто прекрасно: сравнивать последовательный await задач с waitall. GPT - программирование, не приходя в сознание, - сегодня в тестах, завтра в production!

pererat_rs
04.06.2023 10:34+1Я запустил код который использует tokio, и он выполняется 10 секунд. Таски выполняются паралельно, а не последовательно.
a-tk
04.06.2023 10:34Поскольку задачи создаются горячими, то подождать последнюю можно и пересчитав все.
Tsimur_S
А уж сам автор просто образец желтой журналистики, сравнивает треды с промисами.
neJS69T4urCFe3gXW6Er
А что не так с переводом concurrent как параллельный?
Concurrent tasks - задачи, исполняемые одновременно (параллельно относительно друг друга)
Насчет "сравнения тредов с промисами" вы тоже мимо: реализации на системных потоках добавлены лишь для классического примера значительной деградации способности их плодить при росте количества задач (вплоть до отказа).
Реализации для каждого языка на системных тредах предшествуют реализациям на виртуальных.
Зачастую в таких сравнениях хочется понаблюдать на какой стадии каждая из реализаций упирается в свои пределы.
В общем, лишь бы придраться ????
sgjurano
Concurrency is not parallelism, традиционное занудство о терминологии :)
https://m.youtube.com/watch?v=oV9rvDllKEg
Bright_Translate Автор
Спасибо за отчетливое прояснение.
Tsimur_S
Тем что это разные вещи.
Интересное определение но оно противоречит общепринятому. https://en.wikipedia.org/wiki/Concurrency_(computer_science) То что вы дали это на самом деле определение параллельного исполнения. А конкурентные задачи это задачи которые друг от друга не зависимы, они могут выполняться как последовательно так параллельно, это роли не играет.
Ну и какой смысл сравнивать разные вещи?
Не для каждого.
orcy
Может знаете какой-нибудь перевод на русский для concurrent в смысле задач?
По моему разница которая есть в терминах на английском для данного текста особо не существенна, тест вполне интересен т.к. показывает накладные расходы разных подходов когда вот такие параллельные задачи делают ничего (голый sleep). Сравнение с тредами для наглядности тоже не лишнее.
Другой вопрос как тут уже написали ниже будет ли разница в оверхеде иметь значение когда у тебя вместо sleep реальная нагрузка (типа буферов для I/O, различные состояния, итд). Тем ни менее все равно интересно знать какая разница в "минималке" у различных языков.
a-tk
Одновременный.
ri_gilfanov
Вариант 1. Конкурентность (контекст употребления см. ниже):
Вариант 2. Кооперативность (контекст употребления см. ниже):
В случае с asyncio и trio в Python возможно подходят оба термина (если понятие кооперативность применимо в рамках одного процесса).
Оператор
awaitвроде бы и есть явная передача управления другим сопрограммам (с циклом событий в качестве посредника).В любом случае, "одновременный" как вариант по умолчанию в Google Translate -- это скорее приблизительный перевод слова в общем житейском смысле.
Для сравнения, среди определений concurrent в англоязычном Викисловаре есть одно с пометкой "(computing, of code)":