
Атрибуция товаров ― важный процесс для электронной коммерции. Атрибуты, такие как цвет, размер, материал, длина платья, фасон, модель рукава и многие другие, обеспечивают точный поиск по товарам, который, в свою очередь, увеличивает вероятность покупки.
Наш клиент, крупный маркетплейс товаров из Китая, определил “цвет”, как один из самых важных атрибутов на сайте, именно этот параметр встречается в 23 категориях из 30.
Однако в нашем случае, фильтрация товаров по цвету является сложной задачей, потому что, карточки товаров заполняют не представители маркетплейса, а продавцы конкретных товаров, которые не всегда понимают, что заполнять данные о продукции стоит максимально подробно и понятно для каждой позиции. В свою очередь, маркетплейс также не регламентирует каких-то четких правил описания товаров. Это привело к тому, что характеристики товара заполнены неверно или неточно. Особенно наглядно это проявляется в описании цвета, где некоторые селлеры могут написать что-то непонятное, например, “цвет утреннего рассвета”.
Как можно решить задачу
Процесс решения в обоих случаях стартует с анализа и составления списка, какие атрибуты и значения должны быть у каждой категории товаров. На этом этапе мы вместе с бизнесом анализируем поведение и портрет пользователей, стратегию конкурентов и прочие бизнес метрики чтобы ответить на вопрос - сколько должно быть цветов на фильтре на сайте? Какими они должны быть? Будет достаточно базовых или нужна расширенная палитра?
Решение проблемы по заполнению атрибутов товаров можно выполнить двумя способами: вручную или с помощью машинного обучения (ML).
С первым способом все понятно: используя список возможных атрибутов и их значений, каждая позиция просматривается вручную и заполняются характеристики продукта, основываясь на базовой информации о товаре, такой как описание и картинки.
Второй способ – с помощью ML – также использует список возможных параметров и их значений. Помимо этого, базовый подход к решению предполагает, что у нас есть обучающий набор, в котором у товаров верно заполнены все необходимые атрибуты. Модель обучается (тренируется) на этих примерах и используется для прогнозирования характеристик в других случаях, где мы не знаем правильные ответы. Объем набора данных для обучения составляет несколько тысяч товаров. Чем больше товаров, для которых мы не знаем точные значения, тем больше должен быть набор данных для обучения.

А если данных для обучения нет?
В нашем случае, данных для обучения ML-моделей, к сожалению, нет. То есть мы не можем выделить группу товаров для тренировки, в которой мы были бы заведомо уверены, что атрибуты проставлены верно. Предварительная оценка показала, что только в 31% товаров цвет был заполнен одним из значений, которые мы впоследствии хотим видеть в фильтрах, но даже это не значит, что он заполнен верно без ручной проверки.
Кроме того, товаров очень много – более 100 млн. Заполнять атрибуты вручную для каждого товара займет слишком много времени и ресурсов, которые тратить никто не готов.
CLIP модель в ecommerce
Фишкой данного решения является минимальное использование обучающих данных для достижения высокой точности в классификации изображений. Это достигнуто благодаря использованию модели CLIP (Contrastive Language-Image Pretraining), которая предназначена для zero-shot и one-shot обучения, изначально созданная для сопоставления изображения и его текстового описания.
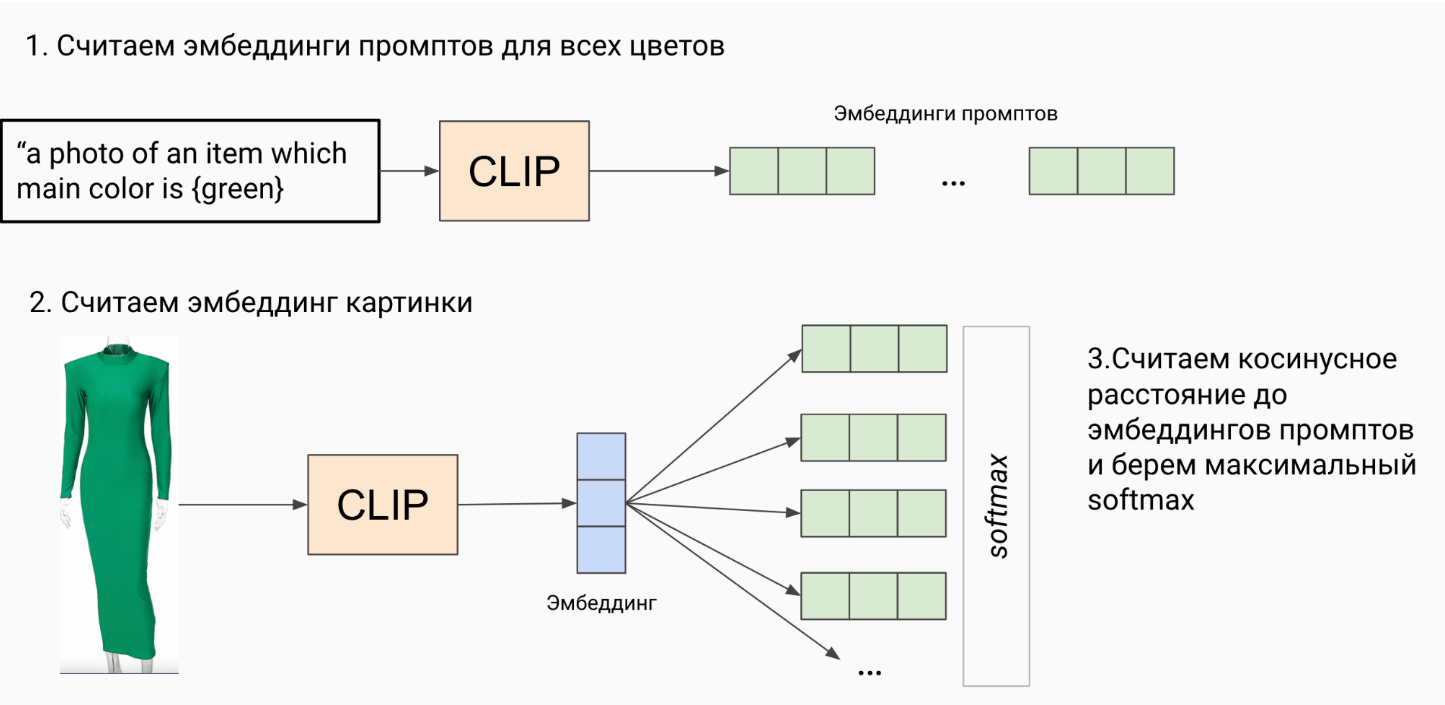
Мы использовали эту модель для решения задачи классификации, модель CLIP создает векторы (эмбеддинги) изображения товара, а также векторы из набора текстов, описывающих этот товар одним из вариантов цветов, после чего модель выявляла наиболее подходящее описание для данного товара, используя косинусное расстояние.

Технически CLIP работает следующим образом:
Предварительное обучение (pretraining): Модель предварительно обучена на наборе из более чем 2 миллиардов пар, изображений и соответствующих им текстовых описаний. В процессе обучения модель стремится связать каждое изображение с соответствующим текстовым описанием таким образом, чтобы векторные представления изображения и текста были близкими друг к другу в пространстве.
Кодирование изображений и текстов: После предварительного обучения CLIP может кодировать изображения и тексты в векторные представления. Для изображений используется сверточная нейронная сеть или модель трансформер, для извлечения признаков изображения. Выбор модели делается из необходимого потенциала модели по качеству и скорости работы. Для текста используется модель трансформера для его кодирования.
Оценка связи между изображениями и текстом: Для поиска схожих изображений модель вычисляет косинусное расстояние между векторными представлениями изображений и текстовых описаний. Чем ближе косинусное расстояние к единице, тем более связанными считаются изображение и текст.
Ранжирование результатов: После вычисления косинусных расстояний модель ранжирует по степени их схожести с запросом. Наиболее близкий вариант определяет необходимый атрибуты. Расстояние до всех вариантов может быть интерпретировано как уверенность модель в основном ответе, и ее сомнения относительно других вариантов.
Такой подход может быть особенно полезен для сайтов интернет-магазинов, если обучающий набор данных ограничен или вообще не доступен. Помимо этого, подход на основе CLIP позволяет быть более гибкими в изменении списка атрибутов и их значений. Например, если бизнес решит, что отныне в фильтре требуется дополнительный цвет, это может быть легко добавлено в отличии от классического supervised подхода к построению модели ― в этом случае для добавления нового значения атрибута процесс запускается заново начиная от сбора обучающих данных до обучения и тестирования модели.
Использование zero-shot и one-shop моделей, таких как CLIP ‘это новое перспективное направление в области машинного обучения, которое имеет множество преимуществ, чтобы решить задачу на высоком уровне.
Этот подход имеет ограничения, связанные с тем, что исходные 2 миллиарда данных могут покрыть большинство, но все же не все вариации атрибутов и значений, которые могут потребоваться. Однако, эту модель также можно дообучить, адаптировав ее к новой задаче классификации. При этом процесс сбора необходимых данных происходит проще и дешевле, обеспечивая аналогичное качество. О том, как мы это делаем мы расскажем вам в одной из следующих статей.
Менее, чем за год, наше решение было успешно интегрировано во внутренний пайплайн маркетплейса и используется для более чем 100 миллионов товаров.
Результаты показали высокую точность более 90% без обучающего набора данных и увеличение покрытия списком атрибутов с 16% до 83%.
Как итог:
Точность более 90% без обучающего набора данных
Покрытие списком атрибутов увеличилось с 31% до 83%
Решение позволяет определять характеристики для более, чем 100 млн товаров
Пайплайн содержащий данную модель используется также для определения других атрибутов и для других категорий товаров без существенных изменений
victor30608
Слишком сильно напоминает данную статью https://habr.com/ru/articles/540312/, только теперь задача другая.
Что будете делать в случае не английского языка?
И как понять фразу "данных для обучения нет" ? У вас же есть конкретный маркетплейс, могли бы спарсить, попытаться обучить что-то на этом. Воспользоваться идеями ArcFace/ Margin Loss, чтобы понимать, когда у вас появился новый цвет/выбросы.
acc0unt
Так английский язык ведь используется только для изготовления эмбеддингов для CLIP. Потому что CLIP предобучена на парах "изображение - описание на английском", и поэтому английский - её родной язык. Вне зависимости от языка маркетплейса.
FlexiTech Автор
Да, вы правы, статья описывается схожий подход, и наш вклад здесь был показать, что CLIP можно успешно использовать в реальных бизнес кейсах на большом масштабе. Материлов как сделать pet-project c помощью него достаточно много, но не все архитектуры при этом могут дать тот же эффект в жизни.
По поводу вопроса с данными - здесь дело не в объеме (товаров очень много), а в разметке. Спарсить можно, но как понять, что метки атрибутов там правильные? Мы разметили часть данных руками и нашли группы товаров, у которых были верные атрибуты для обучения классификационной CNN, но на фоне всего количества товаров и их вариаций, но этого не хватало чтобы добиться от нее хорошей обобщающей способности. Так что в случае большого объема, размеченных товаров "мало" скорее всего значит что их "нет". Но часть данных все равно размечать полезно - для валидации и контроля метрик.
По поводу ArcFace не совсем понял в чем поинт. ArcFace/Margin Loss вместо обычного Cross-Entropy в классификации помог бы понять какие товары не попадают ни в один из классов и понять метрику их близости к этим классам. Но список классов чаще всего фиксированный (атрибуты это кнопки на сайте, их конечное число). Если мы добавляем новый класс, то ArcFace все равно нужно будет переобучать, как и классификацию. CLIP не нужно. Можно использовать метрику близости от ArcFace, но трешхолды близости для каждого класса будут разные и их сложно выбрать, не понятно как получить четкое соответствие с классами, а не top-k. По мне, вариантом с ArcFacе решить эту задачу сложнее, чем с помощью Cross-Entropy, а им, как я говорил, на таком объеме данных не получается.
С языком никаких проблема нет. Во первых, для классификации изображений, из текста нам нужен только список классов, нет проблем указать его на англ. Во вторых, если речь идет о классификации текстов есть multi-lingual версии CLIP для таких случаев, или, на худой конец, можно переводить текст для классификации переводчиком.