
Привет, Хабр! Меня зовут Татьяна, я разработчик в Росбанке, и в этом посте я расскажу про регулярные выражения. По своему опыту могу сказать, что регулярки — это очень полезный инструмент. Я часто пользуюсь ими, решая задачи по обработке текста в базах данных. Вначале я остановлюсь на теории, а затем рассмотрю несколько реальных задач, которые были решены с использованием регулярных выражений.

Регулярные выражения — это механизм для поиска и замены текста. Все задачи регулярных выражений в моей практике можно свести к трём ключевым: определить, найти и заменить последовательность символов.
Регулярные выражения можно назвать ключевым навыком в работе аналитика, а также очень интересным инструментом, который открывает множество новых возможностей при решении задач.
Символьные классы
Чтобы регулярные выражения могли работать с текстом, им необходимы инструменты. И первый из них, о котором мы поговорим — это символьные классы. Символьный класс обозначает принадлежность символа к определенному типу. Это может быть цифра, пробел, класс «слово» (латинские буквы, цифры и знаки подчеркивания), «не цифра», «не пробел» и «не слово». Также существует класс «точка» — он обозначает любой символ кроме символа новой строки.

В примере выше приведена последовательность из цифр, пробелов и дополнительных символов — это номер телефона. Если написать регулярное выражение, состоящее из одного символьного класса «цифра», мы получим все цифры из номера.
Начало и конец строки
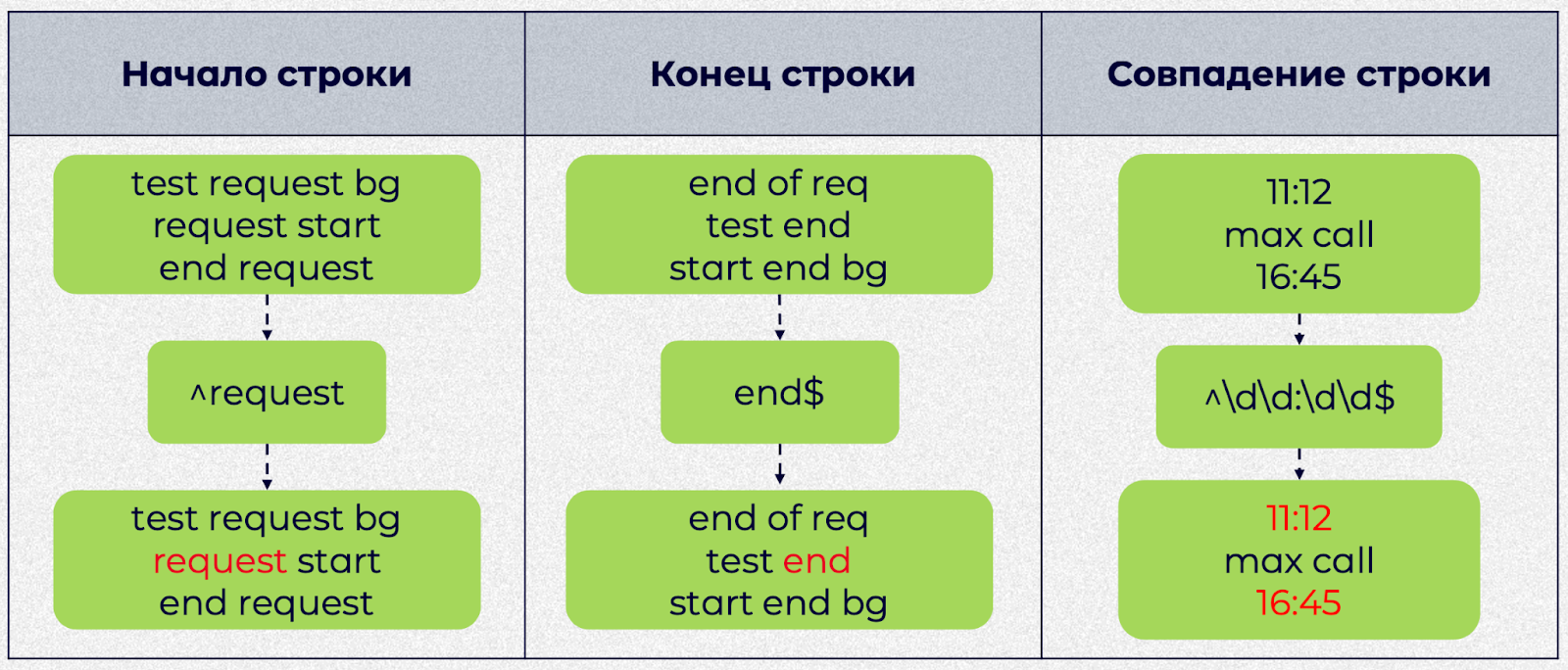
Перейдем к специальным символам начала и конца строки. Слева у нас есть последовательность. К ней мы пишем регулярку, состоящую из символа начала строки «^» и слова «request». Оно найдет все слова request, которые стоят в начале строк. В результате мы видим, что выражение сработало, и мы получили только слово «request» из начала строки.
Также у нас есть символ для обозначения конца строки. Во втором примере мы пишем слово «end» и символ конца строки «$». Это регулярное выражение нашло то слово «end», которое находится именно в конце строки.
Мы можем использовать комбинацию этих символов, чтобы найти строки в определенном формате. В третьем примере представлено более сложное регулярное выражение: символы начала и конца строки, а между ними цифры, попарно разделенные через двоеточие. В результате будут найдены все строки, имеющие заданный формат — например, время.
Наборы и диапазоны

Рассмотрим наборы и диапазоны. Первое выражение начинается с буквы «s». Далее в квадратных скобках есть три символа «a», «r», «e» — это набор, который обозначает, что на втором месте у нас должен быть один из символов набора. В конце регулярного выражения — буквы «e» и «r». Согласно заданным параметрам, здесь было выбрано первое и третье слово, а второе не подошло.
Во втором примере мы используем диапазоны. Регулярка начинается с сочетания «req». Далее в квадратных скобках идут два символа, разделенные дефисом, — «a-z». Это и есть диапазон — некий отрезок, в который должен попадать символ. В нашем случае в диапазон попадают все строчные буквы латинского алфавита. Далее мы задаем диапазон из цифр «1-9» и заканчиваем набор еще одним возможным вариантом, символом подчеркивания «_». Итоговым требованиям соответствует первое, второе и четвертое сочетание; в третьем на конце стоит «0», который ни в один из наших диапазонов не входит.
Существует и исключающий диапазон, который задает, что в результат попасть не должно. Он обозначается символом «^» перед диапазоном. В третьем примере мы начинаем регулярку с «req», открываем набор через квадратные скобки, задаем исключающий диапазон через «^» и пишем два диапазона, «1-3» и «a-c». Этим требованиям соответствует все, кроме первого сочетание.
Квантификаторы
Квантификаторы в регулярных выражениях обозначают количество повторений.
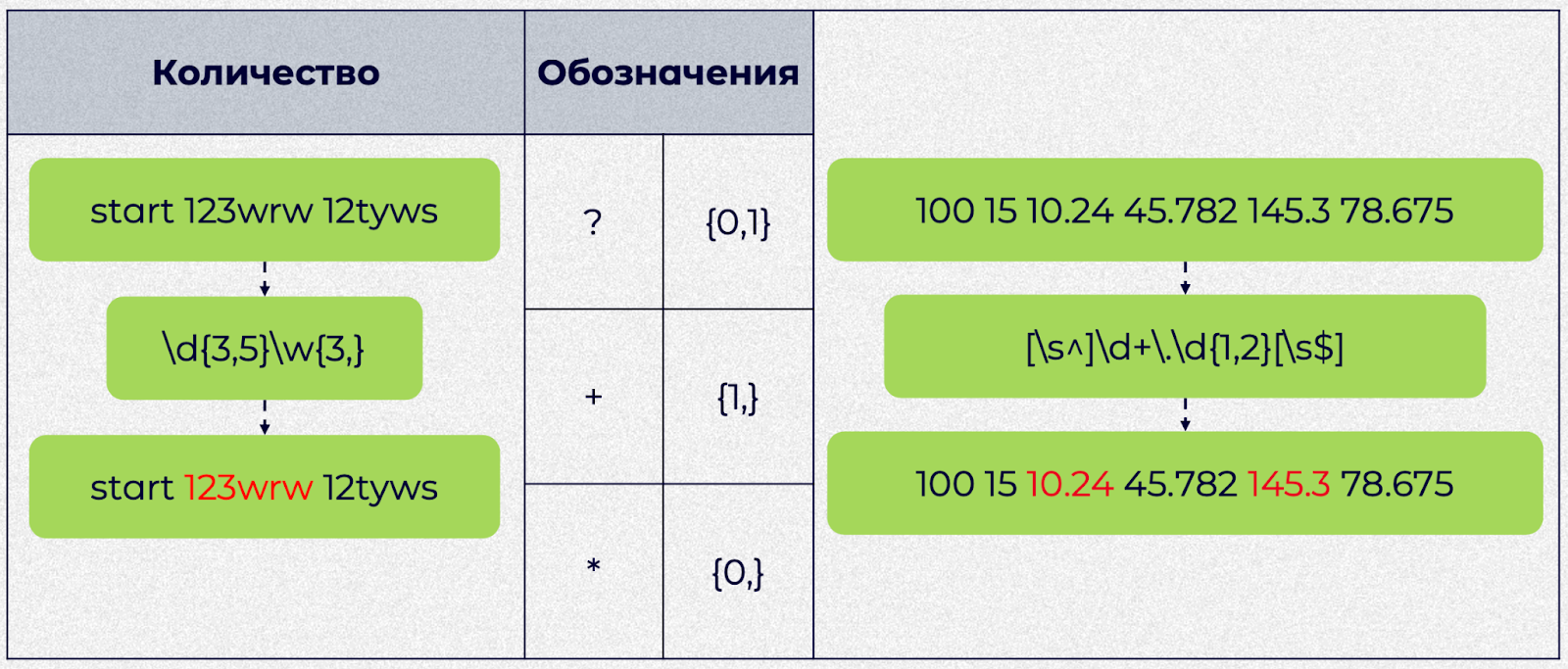
В примере слева регулярка начинается с символьного класса «цифра». Дальше идут фигурные скобки — это и есть квантификатор. «{3,5}» означает, что цифра должна повторяться от 3 до 5 раз. Затем идет класс «слово» и квантификатор «{3,}» — то есть всё, что относится к классу «слово», должно повторяться 3 раза и более. Этим требованиям соответствует только второе выражение.
У квантификаторов есть свои краткие обозначения. От 0 до 1 повторений — знак «?», от 1 и более — «+», от 0 и более — «*».
В задаче справа нам нужно найти все числа с двумя знаками после запятой. Регулярное выражение начинаем с «[\s^]» — это значит, что результат должен начинаться либо с пробела, либо с начала строки. «\d+» значит, что цифра должна повторяться 1 или более раз. Символ «\» перед точкой означает, что точка здесь экранированная, то есть не используется как служебный символ. После точки мы пишем символьный класс «цифра» и квантификатор «от 1 до 2», то есть цифра после точки должна повторяться от 1 до 2 раз. Заканчиваться результат должен или пробелом, или символом конца строки — «[\s" class="formula inline">]».
В результате получилось два числа. Первый и второй вариант не подходят из-за отсутствия части после точки, а в четвертом и шестом цифр после точки слишком много.
Жадная и ленивая квантификация
Квантификация бывает двух типов — жадная (greedy) и ленивая (lazy).

Представим, что у нас есть последовательность, из которой мы хотим получить все слова в кавычках. Мы пишем регулярку: открыли и закрыли кавычки, между которыми указали повторение любого символа 1 и более раз — «.+». В результате получаем не то, что нужно, в выборку попали лишние слова.
Как здесь отработала регулярка? Она нашла первую кавычку. Далее по требованию «.+» подходили все символы до конца строки, так что регулярка дошла до конца строки и начала поиск в обратном направлении. Нашла первую закрывающую кавычку с конца и выдала результат. Это пример жадной квантификации.
Чтобы эту проблему решить, существует ленивая квантификация. Она вводится с помощью «?» после квантификатора.
Как работает регулярка, если мы добавим «?»? Она находит первую кавычку и идет уже не до конца строки, а до границы результата — закрывающей кавычки. Затем проверяет содержимое внутри границ и снова переходит к следующей открывающей кавычке.
Группы

Рассмотрим пример. У нас есть список электронных адресов, в котором нужно найти все адреса с корректным доменом. Корректный домен в нашей задаче — домен, имеющий несколько частей, разделенных точкой. Возникает проблема: мы не знаем, сколько раз может повторяться часть с точкой. Мы решим её с помощью групп.
Рассмотрим нашу регулярку. Сначала у нас идет набор. Точка в нем не экранирована, так как находится внутри набора. У набора стоит квантификатор «1 и более раз», потом идет «@».
Дальше начинается самое интересное. Мы открываем круглые скобки — так обозначается группа в регулярных выражениях. Внутри группы — набор из символьного класса, точки и дефиса. Он повторяется 1 и более раз — знак «+». Далее идет точка — уже экранированная, потому что находится вне набора. Вся эта группа может повторяться 1 и более раз — знак «+» после круглых скобок. После точки у нас обязательно должны идти символы, ведь домен не может заканчиваться точкой. Поэтому в конце выражения мы пишем «\w+». В результате требованиям подошел первый и третий вариант.
Во втором примере приведены даты, из которых нужно извлечь только те, что имеют нужный формат: день, месяц и год через разделитель. Решим эту задачу с использованием групп. Первая группа — это цифра, которая повторяется от 1 до 2 раз. Далее идет группа с разделителем: им может быть дефис, слеш или точка. Слеш в наборе нужно экранировать, в отличие от точки. После разделителя мы опять задаем 1–2 цифры, повторяем разделитель и задаем обозначение года — обязательно 4 цифры. В итоге нам подошла первая и третья дата. Хоть эту задачу можно решить и без использования групп, на ней мы можем увидеть, как работают группы.
Группы с захватом (capturing) и без захвата (non-capturing)
В чем разница между группами с захватом и без захвата?

Рассмотрим предыдущий пример с датами. В выражении у нас повторяется разделитель. Чтобы не прописывать группу с разделителем повторно, мы можем обратиться к ней по порядковому номеру в выражении — «\2». В регулярных выражениях по умолчанию все группы с захватом.
Чтобы исключить группу из учета по порядку, перед ней нужно поставить «?:». Так группа с захватом становится группой без захвата. В выражении справа мы исключаем первую группу, и наша группа с разделителем теперь становится первой, поэтому мы обращаемся к ней уже через «\1». Смысл у двух регулярных выражений, как и результат, одинаковый.
Теперь перейдем к реальным практическим задачам, которые решаются с использованием регулярных выражений.
Валидация данных и определение направления платежа в платежном поручении
Платежное поручение — это определенный тип перевода, где клиент вводит ряд реквизитов. Наша задача — провалидировать эти реквизиты (то есть проверить их корректность) и определить направление платежа.
План решения таков. Сначала мы определяем правила для реквизитов: какими они должны быть и как сочетаться. Затем нужно формализовать все наши требования средствами регулярных выражений — проще говоря, написать сами регулярки. Последний шаг — это создание sql-запроса на основе выражения.
Эта задача решена средствами базы данных на языке PL/SQL. Поддержка регулярных выражений в базе данных – большой плюс.

Перейдем к первому шагу. Рассмотрим два реквизита из возможных. Корреспондентский счет — это счет банка получателя. В нем нужно проверить начало счета и соответствие счету получателя. Для чего нам проверять соответствие? Если банк получателя, например, Сбербанк, то и счет получателя платежа тоже должен быть из Сбербанка.
Второй реквизит — счет получателя платежа. В нем мы тоже рассмотрим начало счета (оно также называется «план счетов») и сочетание цифр в счете.

Далее мы формализуем все наши требования средствами регулярных выражений. Сначала поработаем внутри столбца. Каким может быть корреспондентский счет, то есть счет банка? Он может быть либо любым, либо начинаться на 4102: мы ставим символ начала строки «^», 4102 и далее любые символы.
В счете получателя правил больше. Он может начинаться на 475 или 60323. Или начинаться на 40, затем содержать цифру 3, 9 и 2, сочетание цифр 09, цифры вместо точек, цифру 4 и далее любые символы.
Рассмотрим построчное сочетание реквизитов. Например, счету банка получателя, который начинается на 40102, соответствует счет получателя на 3100, 3212 и так далее. То есть, кроме работы внутри столбца, мы также проверяем сочетание построчно.

Перейдем к решению задачи. Рассмотрим табличку payment_rules. Для начала — по столбцам. Каждый столбец — это наш реквизит из платежного поручения.
Первый столбец BIC — БИК — может быть любой, и к нему особых требований нет. Второй столбец CORR_ACCOUNT — счет банка получателя. Он может быть либо любой, либо начинаться на 40307. Третий столбец PAY_ACCOUNT — получатель счета — может начинаться на 68097, 3541, 3921 и так далее. KBK — код бюджетной классификации — может быть любой. Последний столбец — результирующий, откуда мы будем брать направление.
В столбцах перечислено, какие могут быть реквизиты, но мы также смотрим и сочетание столбцов между собой. Например, рассмотрим вторую строку. Клиент вводит любой БИК, счет банка получателя начинается на 40307, счет получателя на 3541, КБК любой — при выполнении этих условий мы получаем, что у нас здесь бюджетный платеж, так как во второй строке в последнем столбце указано именно это направление.
select pr.DIRECTION
from payment_rules_pr
where REGEXP_LIKE (v_Bank_Bik, pr.BIC)
and REGEXP_LIKE (v_Corr_Account, pr.CORR_ACCOUNT)
and REGEXP_LIKE (v_Pay_Account, pr.PAY_ACCOUNT)
and REGEXP LIKE (v_KBK, pr.KBK)Как это всё реализуется запросом? Мы определяем направление платежа, вытягивая данные из последнего столбца таблицы payment_rules — это таблица, которую мы рассмотрели выше.
Далее идет секция where с REGEXP_LIKE — данная функция работает с регулярными выражениями в PL/SQL, в ней два аргумента. Первый аргумент — это переменная, куда подтягиваются данные, которые ввел клиент — v_Bank_Bik, v_Corr_Account и т. д. Вторая часть — это данные из таблицы, откуда подтягивается регулярное выражение. Функция REGEXP_LIKE осуществляет проверку данных из переменной с помощью регулярного выражения. Как только каждый реквизит пойдет в конкретную ячейку и все они попадут в результирующую строку, из последнего столбца найденной строки в этой таблице мы вытянем направление платежа.
Теперь расскажу, как изменился поиск ошибки в реализации с использованием регулярных выражений. В моем опыте данный подход позволяет найти ошибку быстрее, чем подход с алгоритмом, содержащим большое количество итераций проверки.

Рассмотрим пример. Здесь мы ошиблись в одной цифре в счете получателя, и направление платежа определилось у нас неправильно. Мы можем выполнить запрос к базе и увидеть, какой из реквизитов проверяется некорректно.

Посмотрим, как с использованием регулярок изменились настройки. Чтобы нам реализовать, например, новое направление платежа или исправить реквизиты в существующем, не нужно править код. Мы можем сделать это даже на этапе бизнес- или системного анализа, если у нас есть интерфейс для доступа в базу. Если необходимо добавить новое направление, мы можем сделать это сами, без правок в текущей реализации.
Разбор логов: найти нужный запрос, достать строку с ключевыми словами
Следующая практическая задача — это задача с логами. Как мы ее будем решать?
Первое, что нужно сделать, — определить формат лога. Из чего он состоит, какие содержит строки, как сохранены данные — в общем, нужно посмотреть, что представляет собой лог. Второй этап — выделить ключевые слова, символы; непосредственно то, что мы будем искать. Третий этап — формализация требования к результату: написание регулярок на основе того, что мы выделили на предыдущем шаге. И наконец, нам нужно осуществить поиск данных при помощи полученных регулярных выражений.

Посмотрим на файл лога. У него есть несколько особенностей. Первая — очень большой объем, иногда слишком большой даже чтобы открыть его программными средствами, не говоря уже о поиске через Ctrl+F. Вторая особенность — очень много нерелевантных данных. Третья особенность — очень сложные правила отбора.

Перейдем к первому шагу и определим формат нашего лога. Открываем лог и видим, что в каждой строке у нас сначала идут цифры с символами, а затем запрос. Напишем регулярное выражение, чтобы найти все строки с запросом «data_request»:
^.+ data_request.+$В начале строки у нас должен быть любой символ. Квантификатор «+» показывает повторение от одного и более раз. После этого указываем нужный запрос — «data_request». Далее указываем наличие любого символа 1 и более раз и заканчиваем строку. В результате по этому выражению мы можем найти все строки с нашим запросом.

Рассмотрим еще одну подобную задачу. Теперь нам нужно вытянуть не всю строку лога, а конкретный запрос с данными — например, запрос «transaction_response»:
transaction_response\(.*\)Сначала мы пишем название запроса «transaction_response». Далее у нас идет открывающая скобка; она экранированная, так как скобка может быть служебным символом. После скобки — данные запроса: «.» для обозначения любого символа и «» для обозначения «0 и более раз» (ведь в запросе теоретически может и не быть никаких данных). И в конце — закрывающая скобка, также экранированная.

Теперь посмотрим, как решить такую задачу, если мы хотим вытянуть не целиком запрос с его данными, а только данные из запроса:
(?<=transaction_response\().*(?<!\))Здесь нам понадобится такой инструмент, как опережающие и ретроспективные проверки. Как это работает? «.» в нашей регулярке — это как раз то, что мы ищем, данные внутри запроса, которых может не быть вовсе. До этой части обязательно должно быть слово «transaction_response» и открывающая скобка, а после нее — скобка закрывающая. Мы проверяем, есть ли перед нашей частью строки или после нее что-либо конкретное — это и есть опережающая и ретроспективная проверки. Задав такие проверки, мы сможем вычленить данные внутри «transaction_response» без названия запроса и скобок.
Это, можно сказать, типичная задача в работе аналитика и не только его. Подход с использованием регулярок позволяет достаточно технично взаимодействовать с логами не только разработчику.
Ограничения регулярных выражений
Ограниченная функциональность. Регулярки могут решать не все задачи. Например, если мы хотим проверить корректность закрытия скобок в тексте, средствами регулярных выражений данную задачу не решить — их необходимо использовать с дополнительными средствами, например, в коде.
Зависимость от применяемой технологии. Регулярные выражения принято считать кросс-платформенным решением, но, несмотря на это, нужно помнить, что в зависимости от технологии, в рамках которой будут использоваться регулярные выражения, может меняться не только их синтаксис, но и функциональность.
Сложность прочтения и понимания. Когда мы в задаче используем регулярку, нужно обязательно её описывать. Для тех, кто будет дорабатывать или просто использовать наше решение, регулярное выражение может быть совершенно непонятно, особенно если человек знаком с темой поверхностно или вообще ни разу с этим не работал.
Сложная адаптация одной реализации к разным задачам. Регулярное выражение — узконаправленный инструмент, и даже в немного отличающемся кейсе оно может сработать совсем по-другому. Придется либо тщательно тестировать старое выражение в новой задаче, либо сразу писать новое выражение.
Преимущества регулярных выражений
Подведу итоги и скажу о плюсах использования регулярных выражений.
Возможность решения широкого спектра задач. В посте я разобрала две абсолютно разные задачи, где использовались разные технологии и разное тестирование. Сфер, где мы можем использовать регулярные выражения, намного больше, это универсальный и полезный инструмент.
Необходимый инструмент при работе с текстовыми документами. Если вы часто работаете с текстами, с большими файлами, со сложными задачами по поиску и замене текстовых данных, регулярные выражения — это маст-хэв.
Кросс-платформенность. Я упоминала, что в зависимости от применяемой технологии синтаксис и функциональность регулярных выражений может меняться. Но если вы помните об этих ограничениях, то кросс-платформенность будет большим преимуществом.
Быстрый поиск и анализ текстовых данных. Мне часто приходится работать с текстом, выбирать данные определенного формата и решать связанные задачи. Когда я понимаю, что использую слишком много функций по работе со строками, решение становится очень громоздким и вероятность ошибки увеличивается. В таких случаях помогают регулярные выражения: всё можно уместить в одну-две регулярки, это быстрее и удобнее.
Комментарии (14)

Ghool
05.10.2023 11:03+2Спасибо за статью.
Я очень люблю регулярки.Полюбить их я смог после вот этого поста на хабре:
https://habr.com/ru/articles/224799/

Zekori
05.10.2023 11:03+1Как-то для себя открыл утилиту RegexBuddy, в ней есть чуть больше чем надо, от обработки данных, до тестирования регулярок и готового сниппета в любой доступный ЯП.

ReinRaus
05.10.2023 11:03+5Не обижайтесь, но если Вы хотели сделать обучающий материал для новичков, то статья получилась очень слабой в этом плане.
Есть большое количество качественных обучающих материалов по регулярным выражениям, которые не приводят учебные примеры по парсингу строк вроде
dfd123- если статья для обучения новичков, то такие примеры строк текста мозг поломают.С картинками примеров я даже не сразу понял, что сначала написан входной текст, потом регулярное выражение, а потом подсветка найденных совпадений. Можно убрать с картинок входной текст, а оставить только регулярку и подсвеченное совпадение.
Вы делаете слишком категоричные заявления, например, что
.- это любой символ, кроме начала строки - это не так, всё зависит от флагаm;^и$- аналогично зависит от флагаs;заявление, что
REGEX_LIKEпринимает 2 аргумента - тоже не корректно и может ввести в заблуждение. Эта функция может принять и третий аргумент.Если цель - научить чему-то, то лучше выбрать узкую тему и излагать материал последовательно, а не прыгать по разным темам.
Регулярное выражение начинаем с «[\s^]» — это значит, что результат должен начинаться либо с пробела, либо с начала строки
Возможно, в PG/SQL особая обработка данного выражения, но скорее всего символ
^в данном случае является литералом, а не мета-символом начала строки.Лучше бы Вы сконцентрировались на реальных кейсах, которые использовали и в которых регулярные выражения спасли Вам кучу времени, такие кейсы воодушевят новичков учить регулярные выражения и гуглить качественные обучающие материалы.

ptr128
05.10.2023 11:03Возможно, в PG/SQL особая обработка данного выражения, но скорее всего символ
^в данном случае является литералом, а не мета-символом начала строки.Никто не изобретал велосипед.
SELECT regexp_instr('123^abc','[\s^]');
возвращает 4.

saboteur_kiev
05.10.2023 11:03Уточню, что spacer это может быть еще и символ табуляции, и да, ^ в данном случае должен быть просто литералом.

Deosis
05.10.2023 11:03Регулярное выражение начинаем с «[\s^]» — это значит, что результат должен начинаться либо с пробела, либо с начала строки
Вот тут мозг немного сломался, так как ^ в квадратных скобках имеет особое значение.
То есть конструкция [^^] означает любой символ кроме начала строки?
Akina
05.10.2023 11:03То есть конструкция [^^] означает любой символ кроме начала строки?
Нет, конечно. Второй символ ^ в данном случае воспринимается литерально - именно как символ крышки. Хотя никто не мешает подстраховаться и написать [^\^] - уж тут точно никаких сомнений не будет.
Если надо "не с начала строки", то можно, например, поступить наивно и сказать, что между началом строки и искомым фрагментом есть хотя бы один символ: ^.+{паттерн}
saboteur_kiev
05.10.2023 11:03так как ^ в квадратных скобках имеет особое значение.
Только если он идет в начале
[^d] и [d^] - совершенно разные, прочти противоположные значения

Valkiriya_l
05.10.2023 11:03+2Мне в свое время хорошо помогла разобраться с регулярками книга Дж. Фридла "Регулярные выражения". Пока читала различные статьи, в голове все-таки не так хорошо укладывалось, а после прочтения книги стало понятно.

dbsjsk
05.10.2023 11:03+1Для меня всегда регулярки были штукой, используешь классно, не используешь забыл как используешь

BEERsk
05.10.2023 11:03С другой стороны, это как езда на велосипеде или плавание - если научился, то уже не "разучишься" обратно. Глянул на шпаргалку, пару-тройку примерчиков накидал и вперёд !
Кстати, эта статья в качестве такой шпаргалочки волне себе подойдёт в памяти освежить.

mikegordan
05.10.2023 11:03У меня не получилось регуляркой сделать диапазон исключения с символьным классом, для какого стандарта данная статья ?
например исключить \d или _
[^\d_]
ptr128
Баян https://habr.com/ru/articles/545150/