
Всем привет! Меня зовут Ольга, я студентка второго курса НИУ ВШЭ магистерской программы «Системный анализ и математические технологии». В прошлом году я прошла отбор в совместный образовательный проект VK Education и НИУ ВШЭ — Инженерно-математическую школу (ИМШ), где стала участницей мастерской по прикладному искусственному интеллекту. В одном из проектов мы командой из четырёх человек решали реальную технологическую задачу под руководством эксперта VK и научных сотрудников университета. Мы исследовали технологию создания трёхмерной модели человека по фотографии. Хочу рассказать вам про наш подход к решению этой задачи.
Кому и для чего это нужно?
3D-модели востребованы в кино, в играх, в приложениях дополненной реальности — на самом деле список длинный. Существующие решения не всегда могут автоматически подстроиться под реалистичного персонажа. Чаще всего такие модели либо требуют ручной донастройки параметров, таких как выбор цвета волос, кожи или одежды, либо выглядят мультяшно. Мы решили исследовать существующие методы и создать систему, которая по одной фотографии человека автоматически генерирует трёхмерный аватар, состоящий из текстурированной полигональной сетки. При этом модель должна содержать скелет и анимацию. Здесь и далее термин «модель» (она же сетка, она же меш (mesh)) означает совокупность вершин, которые вместе составляют оболочку трёхмерного объекта.
Подходы, которые нам не подошли
Мы начали изучение генерации трёхмерных моделей с технологии NERF, которая способна обрабатывать сцену с разных ракурсов по набору исходных фотографий и уже применяется при создании видео, текстур зданий и в фотограмметрии. NERF — впечатляющий подход, но для нашей задачи необходимы более узкоспециализированные инструменты, работающие быстрее.

Также мы обратили внимание на ICON. Это «прародитель» модели, которую мы в итоге использовали. ICON плохо прорабатывает руки и лица, делает много склеек в итоговой сетке.

Из всех моделей к решению нашей задачи более всего приблизился нейросетевой фреймворк ECON. Его мы и взяли за основу.
Что такое ECON?
Архитектура фреймворка:

ECON предназначен для «оцифровки человека по цветному изображению» и разработан группой студентов-аспирантов и их научных руководителей. На вход принимается RGB-изображение и встроенная модель SMPL-X, которая представляет собой полигональную сетку человеческого тела без одежды, волос и других деталей. Сетка определяется набором параметров внутри нейросети, которые настраивают рост, размер частей тела, позу и т. д. Затем предсказываются две карты нормалей одежды: спереди и сзади. Затем они вместе с картами глубины подаются в оптимизатор для получения передней и задней поверхности тела. Итоговая модель склеивается из полученных кусков, а проработанные руки берутся из SMPL-X.
Пока ECON плохо моделирует согнутые ноги, однако эту проблему мы решаем добавлением скелета и сменой позы. Когда я говорю о том, что ноги согнуты, я имею в виду это:

Для GLTF-формата мы написали на Python модули автоматической привязки скелета к сетке и создания текстуры. Тестирование и просмотр финального результата проводим в Blender и MeshLab.
Внутри ECON мы оптимизировали код: добавили сборщики мусора и очистку кеша видеокарты. В результате нейросеть заработала на видеокарте с 6 Гб памяти, хотя в документации рекомендуется минимум 12.
Схема работы системы:

Расскажу подробнее про каждый из этапов.
Скелет
Чтобы анимировать трёхмерную модель, точнее полигональную сетку, нужно перемещать вершины в определённом направлении так, чтобы создавалось ощущение анатомического движения. Поэтому скелет для анимации похож на настоящий скелет человека. Художники обычно создают его с использованием ПО для 3D-моделирования. Мы можем управлять движением сетки с большим количеством вершин (вплоть до миллионов точек) относительно малым количеством костей (в среднем скелет содержит 20-100). Чем больше костей, тем точнее и детализированнее можно моделировать движения.
Скиннинг (skinning) — процесс привязки скелета к полигональной сетке, чтобы при его движении двигалась и сама модель персонажа. Обычно под скиннингом имеют в виду алгоритм Linear Blend Skinning. Каждая кость скелета используется для изменения положения вершин полигональной сетки. Каждая вершина имеет набор коэффициентов (весов), который определяет, как сильно каждая кость влияет на эту вершину. Например, вершина, которая находится в районе руки, может иметь более высокий вес для кости руки, чем головы. Таким образом, новое положение вершины определяется через линейную комбинацию вершины и веса. Во время скиннинга в каждой вершине задаются веса для каждой кости.

После того, как каждая вершина сетки сопоставлена с соответствующими костями, модель может быть анимирована с помощью изменения положения и вращения костей:
Сначала вся геометрия переводится в систему координат определённой кости (или сустава).
Каждая вершина трансформируется.
Финальный результат рассчитывается с учётом весов.
Так как на первом этапе работы ECON восстанавливает параметры для SMPL-X-модели, а на её основе создаёт финальную полигональную сетку, в которой «дорисовывает» одежду, волосы, обувь и аксессуары, то можно взять скелет и скиннинг из SMPL-X. На основе вектора параметров создаётся полигональная сетка тела человека без одежды, волос и прочих деталей. Она состоит из 7 000 вершин. Внутри расположены 23 основные кости, которые отвечают за конечности, а также кости для движения пальцев рук.

Основная идея алгоритма по переносу скелета такова: если ECON генерирует полигональную сетку на основе SMPL-X-модели, то можно скопировать оттуда скелет и информацию о скиннинге. На вход подаётся файл формата GLTF, в котором сетки SMPL-X и ECON совмещены в нулевой координате.

Для каждой вершины сетки ECON ищется ближайшая вершина в сетке SMPL-X. Для этого используется KDTree — это структура данных с разбиением пространства для упорядочивания точек в k-мерном пространстве. Она применяется при решении задач с поиском ближайшего соседа.

Затем в каждую из вершин сетки ECON копируется вес ближайшей к нему вершины сетки SMPL-X. Для каждой кости пересчитывается матрица InversedBindMatrix. Она переводит всю геометрию в систему координат кости и используется при скиннинге. Подробнее об InversedBindMatrix и скиннинге в GLTF можно почитать здесь:

Мы создали скелет в полигональной сетке ECON с помощью переноса из SMPL-X-модели. Теперь полигональную сетку из ECON можно анимировать как полноценного трёхмерного персонажа.
Анимация
После скиннинга у нас задана сила воздействия отдельных костей на сетку, и теперь при их перемещении двигается и модель. Создание анимации вручную — очень кропотливая работа. Чтобы движения персонажа выглядели органично, нужно постоянно проверять расположение костей в скелетной анимации и их перемещение в ключевых кадрах. Поэтому для анимации на данном этапе мы используем ретаргет с дополнением для Blender — Rokoko, которому задаются исходные и целевые кости из двух скелетов. Ретаргет — перенаправление готовых анимаций на объект с идентичным скелетом, но с другой сеткой, или на объект, скелет которого отличается от оригинала иерархией костей, но имеет с ним сходства в строении.
Анимированные (source) скелеты берутся из базы bvh-файлов, то есть движения модели записаны датчиками с движений людей. Таким образом, у нас есть ограниченный набор анимаций, которые хорошо передают движения тела. На данном этапе проекта нам важно понять, как работает система и как модель будет выглядеть, когда мы соберём всё вместе.
̶Б̶о̶л̶ь̶ Текстура
ECON не умеет генерировать текстуру, поэтому у нас есть только раскрашенные вершины спереди, из которых раскрашиваются полигоны. В чём проблема раскрасить аналогично и сзади? Как бы замечательно это ни звучало, но на выходе мы лицезреем довольно-таки мыльную картинку. Дело в том, что с изначального изображения человека переносится далеко не все пиксели, а их недостаток компенсируется интерполяцией (треугольники раскрашиваются по их цветным вершинам). К тому же, при постобработке меша, в частности при ремешинге (уменьшении количества вершин и полигонов) мы понижаем разрешение модели , что пагубно влияет на «текстуру».

Что делать? Будем жить по правилам трёхмерного мира, где для моделей создаётся, так называемая, UV-карта, или развёртка: каждой вершине сетки присваивается двумерная координата (U, V). А в совокупности с полигонами получаем развёрнутую на плоскости модель, у которой каждый треугольник раскрашивается соответствующей областью на UV-карте.
То есть можно сформировать интересующую нас развёртку и далее использовать нейросети для генерации недостающих фрагментов. Однако развёртка должна быть инвариантная относительно вершин под каждую часть тела. К примеру, какая-то область левой ягодицы должна всегда находиться в одном месте в развёртке. Нужно это для того, чтобы нейросети было проще обучиться, так как ей не придётся каждый раз формировать геометрию развёртки.
Из более «классических» решений на основе развёртки сетки наиболее подходящей для нас оказалась модель Texformer. Она сделана на визуальных трансформерах. По фотографии формируется uv-карта, только для определённой SMPL-X-модели. То есть из конкретной развёртки мы получаем раскрашенную картинку, которую мы не можем просто так взять и применить из-за разного разрешения трёхмерных моделей (большая разница в количестве вершин). Отсюда и вытекает задача по построению «стандартизированной» развёртки — этот вопрос стоит для нас наиболее остро.


Как сделать такую UV-карту? Вроде бы тривиальная задача, но у неё много нюансов. Главный из них — получаемая трёхмерная сетка, то есть абстрактное множество вершин в пространстве и составленных из них полигонов. Мы не знаем, за какую часть тела отвечает конкретная вершина. И, к сожалению, ECON относится к тому типу моделей, результат которых плохо поддаётся обобщению, ведь на выходе мы буквально получаем разные сетки.
Из альтернативных подходов очень интересным оказалось решение TEXTure, главная идея которого — итеративное формирование текстуры с разных точек обзора, причём на входе важны текстовое описание и сама сетка. Это универсальное решение, так как текстура делается непосредственно под имеющуюся сетку. При перемещении камеры на другое место рендерится картинка с текущего ракурса, а также карта глубины, служащая в каком-то смысле подсказкой, которые в свою очередь подаются в диффузионную модель. На основе таких наборов изображений и строится итоговая текстура.
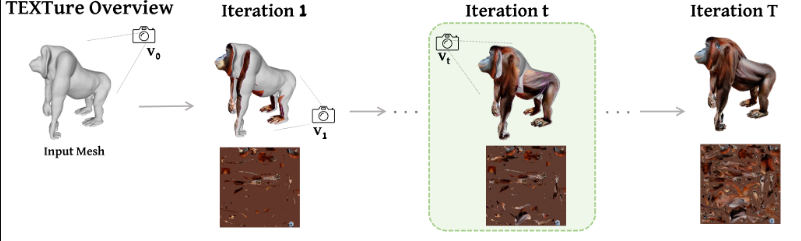
Здесь можно выделить два основных недостатка. Первое, prompt — это текст, а не изображение. Даже если мы идеально захватим изображение, нет гарантии, что одежда и лицо будут соответствовать оригиналу. Второе, из-за принципа работы TEXTure наилучший результат достигается на формах, которые равномерно распределены по объёму описывающей сферы. А человек имеет продолговатую форму, и качество модели на наших примерах оставляет желать лучшего.


Как работать с системой
Предполагается, что в систему будут загружать фронтальную фотографию человека в полный рост. Он при этом стоит прямо, руки немного в стороны. При такой фотографии мы минимизируем склейки сетки, а одежда будет лучше всего видна и понятна для генерации.
Итоги
Мы исследовали различные методы создания полигональной сетки. За основу взяли ECON, который мы доработали и оптимизировали под потребности проекта, при этом улучшили его производительность. И до сих пор тестируем методы создания текстур.
Важным этапом была разработка метода генерации скелета для анимации. Мы успешно решили эту задачу с помощью модели SMPL-X. Она позволяет создавать живые и естественные движения для моделей. Все компоненты проекта интегрированы в единую систему, обеспечивающую совместную работу полигональной сетки, текстур и скелета.
Комментарии (4)

Robastik
08.12.2023 11:14Стоило упомянуть, что тема весьма разработанная, что бы не сказать заезженная, и чем ваше решение отличается от аналогов.


sprayer
08.12.2023 11:14И зачем это непотребство, это даже для геймдева не годится для ААА проекта. Nerf вообще какашка требующая топовую видеокарту. И все эти технологии называются фотограметрии, а в ней лидер realitycapture которую купили эпики, там наиболее точный результат генерируется, но фотограметрию нужно доделывать, не только описанные в статье, нужно делать ретопологию, и не автоматическую как в статье в купе со скиннингом, а руками. В пример привели кино, но для кино детализация колоссальная нужна не какие автоматические инструменты и ии не сделают сами грамотную сетку и веса. Для кино ещё куча технологий используется. А в статье описано как сделать болванчик для веб презентации. Кому и зачем это нужно? Тем более в вк, они игровой движок собрались делать но по итогу взяли исходники от вар фандера и туда будут прикручивать веб поддержку?
raamid
Скажите пожалуйста, вы пробовали библиотеку MediaPipe? Если пробовали, то чем не подошла?
Лично мне очень понравилась данная библиотека, работает даже в браузере. Если что, на сайте проекта есть возможность в реальном времени потестировать при помощи веб камеры. Не сочтите за рекламу, мопед не мой, так сказать. Просто имею успешный опыт применения.
Документация
https://developers.google.com/mediapipe/solutions/vision/pose_landmarker
Веб-камера
https://mediapipe-studio.webapps.google.com/studio/demo/pose_landmarker