
Мы продолжаем публикацию перевода по тестированию и анализу производительности от команды Patterns&Practices о том, с чем нужно есть ключевые показатели производительности. За перевод спасибо Игорю Щегловитову из Лаборатории Касперского. Остальные наши статьи по теме тестирования можно найти по тегу mstesting
В первой статье цикла по анализу ключевых показателей производительности мы наладили контекст, теперь переходим к конкретным вещам. В этой части — про анализ метрик пользовательских, бизнесовых и внутри приложения.
Пользовательские метрики дают представление о том, как пользователи используют систему. Производительность на этом уровне определяется тем, как пользовательский интерфейс обрабатывает запросы и работает с ресурсами клиента. Большинство современных пользовательских интерфейсов — это браузеры и девайсы. В этом случае основными метриками будут являться время загрузки страниц, JavaScript-код, тип браузера или устройства, географическое положение.
Итак,
Как собирать пользовательские метрики?..
Большинство современных браузеров позволяют собирать данные о производительности, которые включают сетевой трафик и профилирование клиентского кода. Эта информация может быть полезной с точки зрения разработки и тестирования, но в продакшене собирать данные подобные образом непрактично. Другое решение – включать на стороне клиента дополнительный JavaScript-код, который бы записывал и передавал в определенное место информацию о времени выполнении того или иного участка когда. Подобный код может перехватывать время загрузки страниц, данные сессии (время выполнения какого-то сценария, который может включать открытие нескольких страниц или выполнение нескольких операций), JavaScript или ошибки на стороне клиента, время выполнения AJAX запросов. JavaScript-код посылает эти данные на сервис, который собирает данную информацию, а также позволяет впоследствии исследовать ее. Boomerang — это open source решение, реализующее данный подход.
Microsoft AppInsights работает похоже — вы можете явно встраивать в код вызовы функций AppInsight API. Используя такие функции, как TrackPageView и TrackEvent, вы можете измерять производительность браузерных сессий и практически в реальном времени на портале Azure изучать собранную информацию. Пример на рисунке ниже.
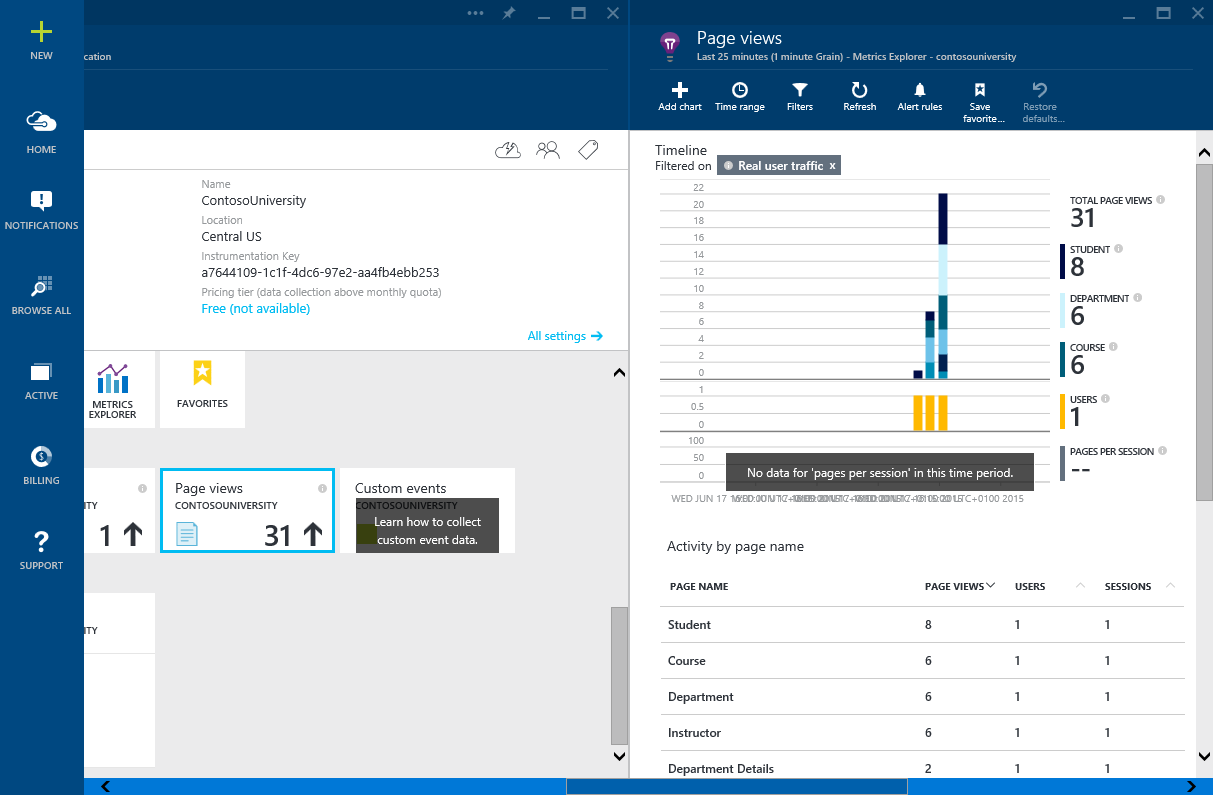
Многие утилиты мониторинга производительности приложений (Application Performance Monitoring или APM) поддерживают клиент-серверную браузерную трассировку. Эти утилиты, подобно Boomerang, вставляют JavaScript-элементы в веб-страницу, собирая и отображая информацию. На рисунке изображена информация, собранная при просмотре страниц браузера популярным APM-инструментом New Relic.
Примечание: Внедренный код может не работать, если пользовательский браузер находится за брандмауэром или прокси, у которого нет доступа к CDN New Relic либо доступ к публичной сети заблокирован.
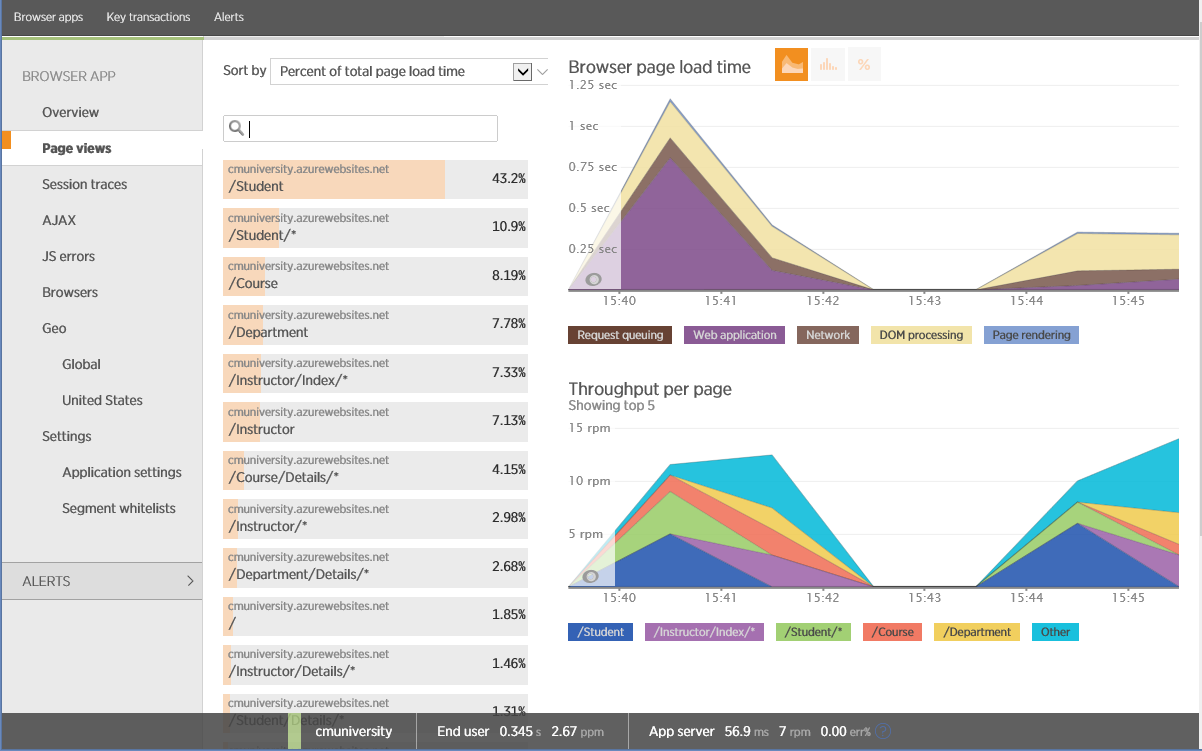
Мониторинг производительности в New Relic
На что обращать внимание?
Ниже приводятся общие сведения об инструментировании кода на клиентской стороне.
Просмотры страниц, время загрузки страницы и время, проведенное на странице
Эти пользовательские метрики производительности являются ключевыми. Если, например, время загрузки некоторых популярных страниц оказывается большим, то пользователи могут начать жаловаться и переставать туда заходить. С точки зрения системы эти данные представляют сквозную (end-to-end) телеметрию для измерения пропускной способности (от начала запроса до его полного выполнения).
Трассировка сессий
Трассировку сессий можно использовать для слежения за длительностью операций и потреблением ресурсов в сессиях. Необходимо контролировать весь загружаемый контент, каждый AJAX запрос, все пользовательское взаимодействие (клики мыши и скроллинг), все JavaScript-cобытия, все исключения.
Экосистема на стороне клиента
Клиентский код может быть запущен на различных девайсах и операционных системах, включая различные версии Windows, Android и iOS, а также различные типы браузеров. Собирать телеметрию производительности клиентского кода в различных окружениях — это важно, так как это позволяет выявить различные факты как, например, в каком браузере код работает быстрее.
Ниже показан пример данных, собранных с помощью New Relic. На графике вы можете видеть пропускную способность, измеренную в страницах в минуту (ppm), и другие метрики типа времени загрузки страницы.
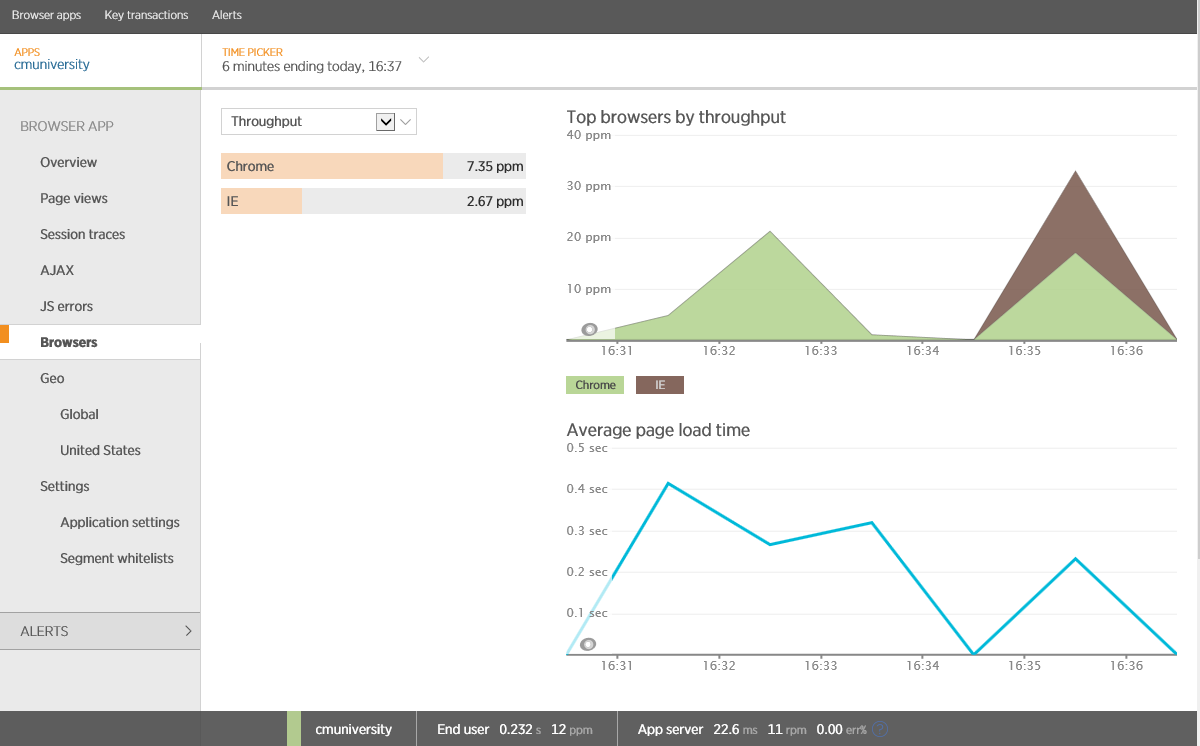
Анализ просмотра страниц по браузерам в New Relic
Обратите внимание, что New Relic строит отчет для различных браузеров. Между типом устройства и операционной системой может существовать корреляция – скорее всего, устройства Apple будут работать на iOS и использовать браузер Safari, устройства с Android будут использовать Chrome, устройства Windows — Internet Explorer. Могут быть и исключения: другие типы устройств, браузеров и операционных систем, и в этом случае нужно будет использовать код, который будет сохранять данные об устройстве, ОС и браузере. Ниже показан пример использования Application Insights для сбора информации об ОС клиента
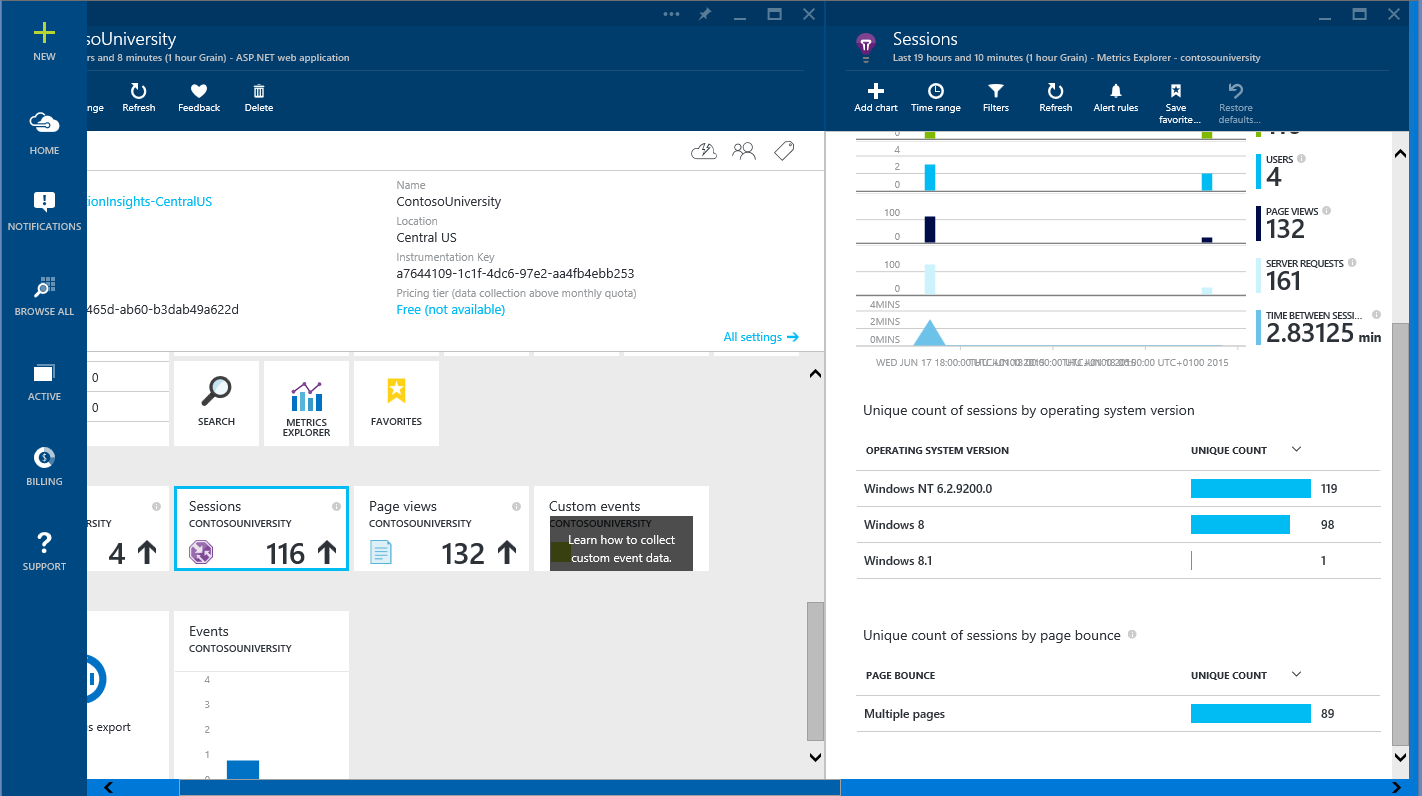
Анализ сессий по операционным системам, собранный при помощи Application Insights
JavaScript и ошибки рендеринга HTML.
JavaScript и HTML-код в веб-приложениях могут использовать не везде поддерживаемые функции. Важно найти их и определить, как можно исправить ситуацию – это можно сделать с помощью APM-утилит, многие из которых способны ловить ошибки рендеринга и JavaScript.
Географическое расположение клиентов
Географическое расположение клиентов обычно связано с временем загрузки страницы, а также с задержками, возникающими при использовании приложения. Многие клиенты будут приходить из мест, отличных от расположения вашего приложения. Данные по расположению клиентов можно извлечь из ресурсов, на загрузку которых тратиться значительное время. Эта информация может оказаться полезной при проектировании приложений, которые должны обеспечивать минимальные задержки (даже в зависимости от региона). На рисунке показан график среднего время загрузки страницы в зависимости от штата в США.
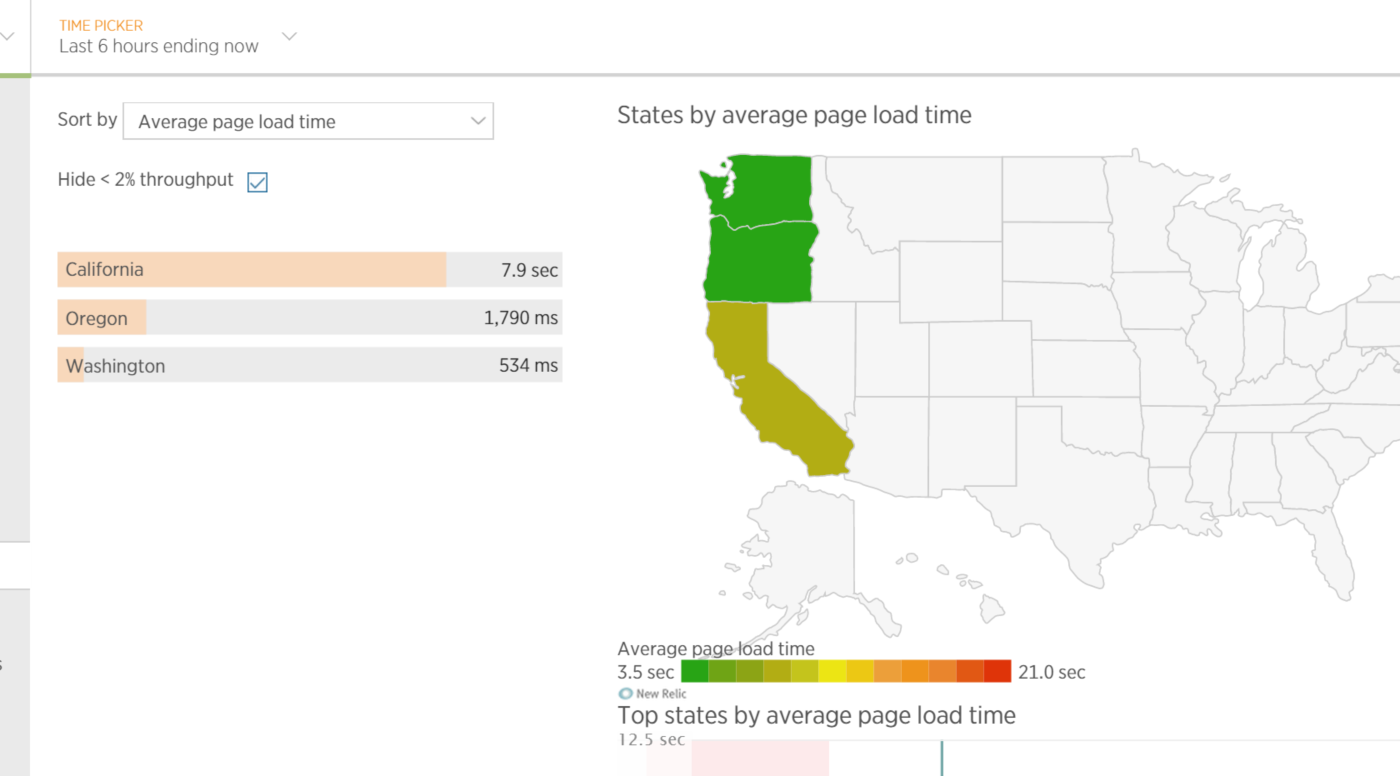
Среднее время загрузки страницы веб-приложения в зависимости от расположения клиента в конкретном штате США
Session ID и User ID запросов
В некоторых ситуациях полезной может оказаться трассировка активности пользователей или конкретных сессий. Большинство APM по умолчанию подобную трассировку вести не могут, но позволяют добавлять кастомные пользовательские метрики (явные вставки трассировочных вызовов в клиентский код) для наблюдения за активностью пользователей (игнорируя соображения конфиденциальности).
Бизнес-метрики
Бизнес-метрики направлены на измерение объема и частоты бизнес-операций и транзакций. Эти метрики могут помочь вам определить, выполняет ли ваше приложение требуемые от него бизнес-ожидания — например, для приложения, которое обрабатывает большие объемы видео (видео-сервер), может потребоваться измерять количество видеофайлов, загруженных за период времени, скорость поиска нужного видео, а также как часто просматривают то или иное видео.
Этот процесс обычно оценивает бизнес-влияние на систему в целом, за счет изучения и агрегирования данных бизнес-телеметрии, которая собирается в режиме реального времени с сопоставлением исторических данных. Собирая эти долгосрочные аналитические данные, бизнес-аналитик может быть заинтересован в таких насущных вопросах как определение, почему сбои бизнес-операций пересекаются с проблемами производительности.
Как их собирать
Существует множество APM-инструментов, разработанных специально для сбора подобной информаци. Например, New Relic использует .NET Profiling API — агенты мониторинга регистрируются как профайлеры CLR, когда приложение запускается.
Этот процесс не требует изменения кода приложения. Агенты New Relic перехватывают CLR вызовы и сохраняют их в репозиторий. =New Relic =может представлять перехваченную телеметрию в виде потока активностей в разрезе времени. Если вам нужно перехватывать дополнительную информацию, у New Relic есть API, используя которое, вы можете включать сбор кастомных метрик.
Используя такой подход, New Relic может собирать данных об отдельных бизнес-операциях, вызываемых клиентами. Вы можете свести эту информацию воедино для того, чтобы отобразить пропускную способность (в запросах в минуту) и среднее время отклика (в миллисекундах), как показано на рисунке.
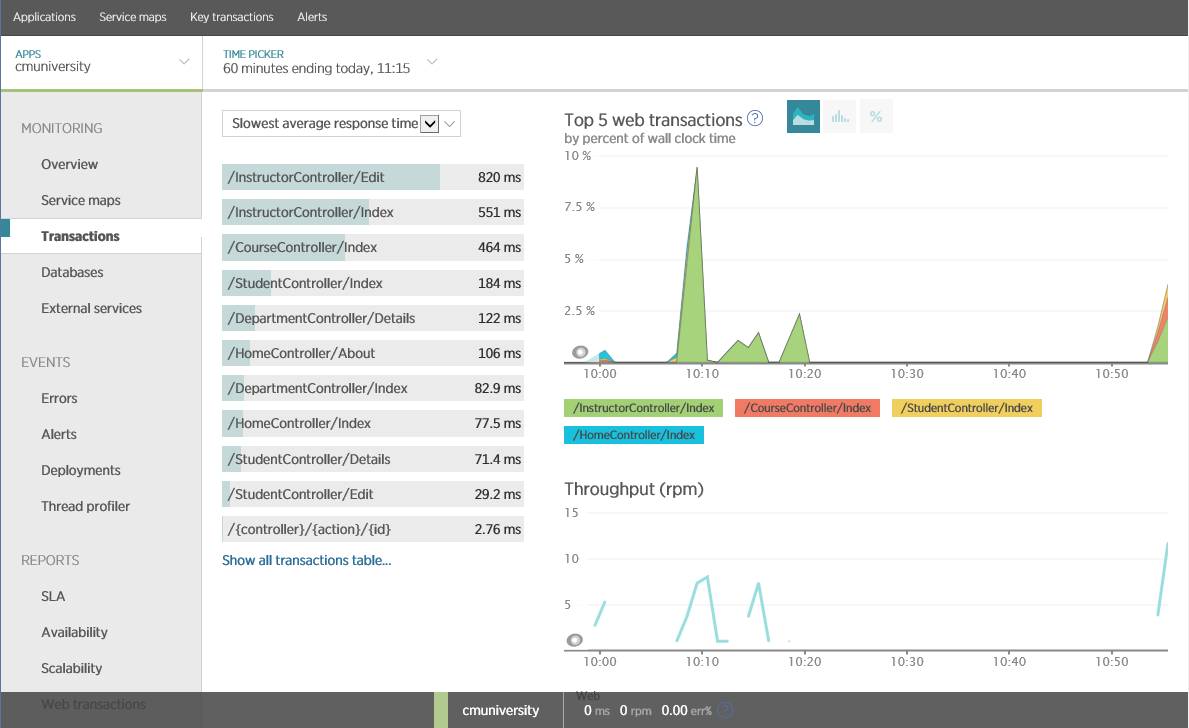
Среднее время операций в New Relic
Application Insights имеет аналогичные функции, которые позволяют записывать производительность и пропускную способность для каждой операции в веб-приложении.
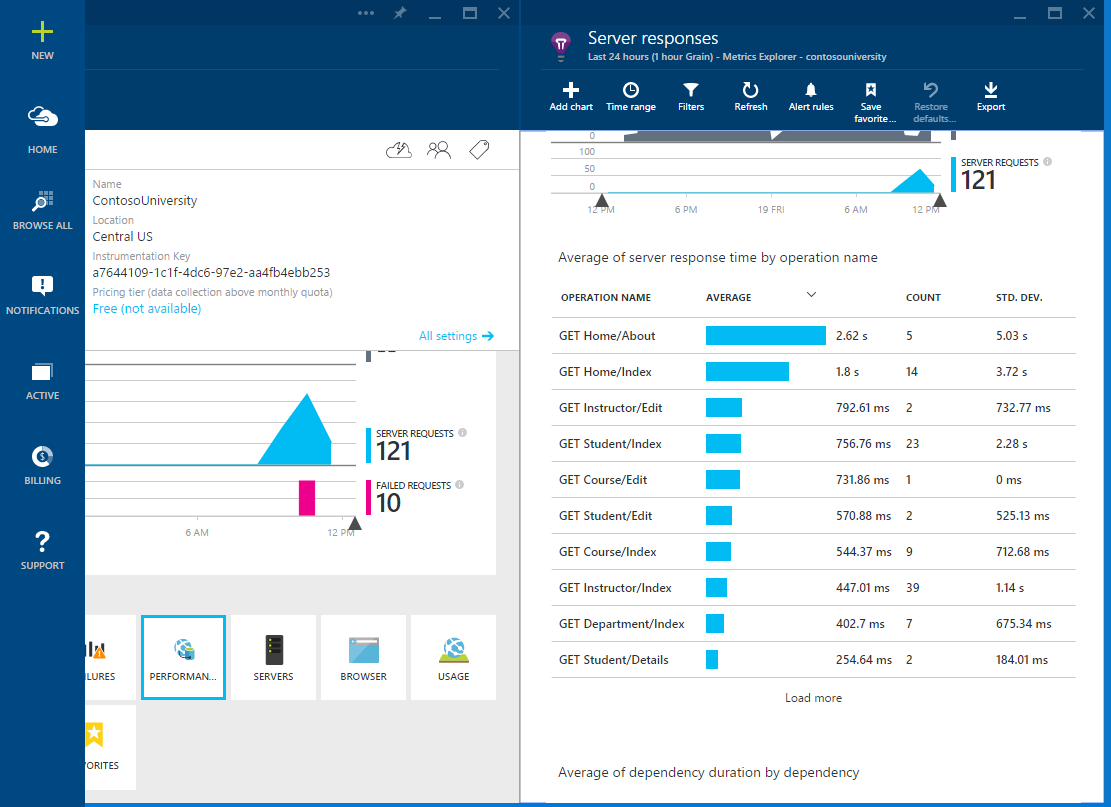
Среднее время операций в Application Insights
Анализ бизнес-метрик для определения долгосрочных трендов требует доступа к исторической телеметрии. Многие APM-инструменты имеют возможность хранения данных за определенный период (например, за последние 30 дней), но выполнение анализа может потребовать сбора, логирования и загрузки данных о производительности в такие локальные инструменты как Excel. Эти данные могут поступать из различных источников (логов событий, счетчиков производительности, трейсов приложения и сервера). Вы должны настроить ваше приложения для сохранения ключевых метрик производительности, которые может потребовать анализ.
На что обращать внимание?
Рассмотрим вопросы выбора бизнес-метрик для мониторинга.
Бизнес-транзакции, нарушающие Service Level Objectives (SLO)
При нарушении SLO любой из бизнес-транзакций должно возникать соответствующее предупреждение. SLO является частью соглашения об уровне обслуживания (SLA), и в этом документе описывается приемлемый для вашей организации уровень производительности бизнес-операций. SLO должно быть определено в терминах измеряемых аспектов системы, таких как процент времени отклика операции (например, 99% всех запросов для операции Х должно выполняться за время Y в мс или меньше). Вы должны быть в курсе, если ваша система не выполняет SLO. Application Insights позволяет определять правила, которые могут отправлять соответствующие нотификации операторам в случае, если показатели производительности превышают установленные в данных правилах пороговые значения. В примере на рисунке показывается настройка правила – отправка сообщения электронной почты, если время отклика любой веб-страницы превысит 1 секунду.
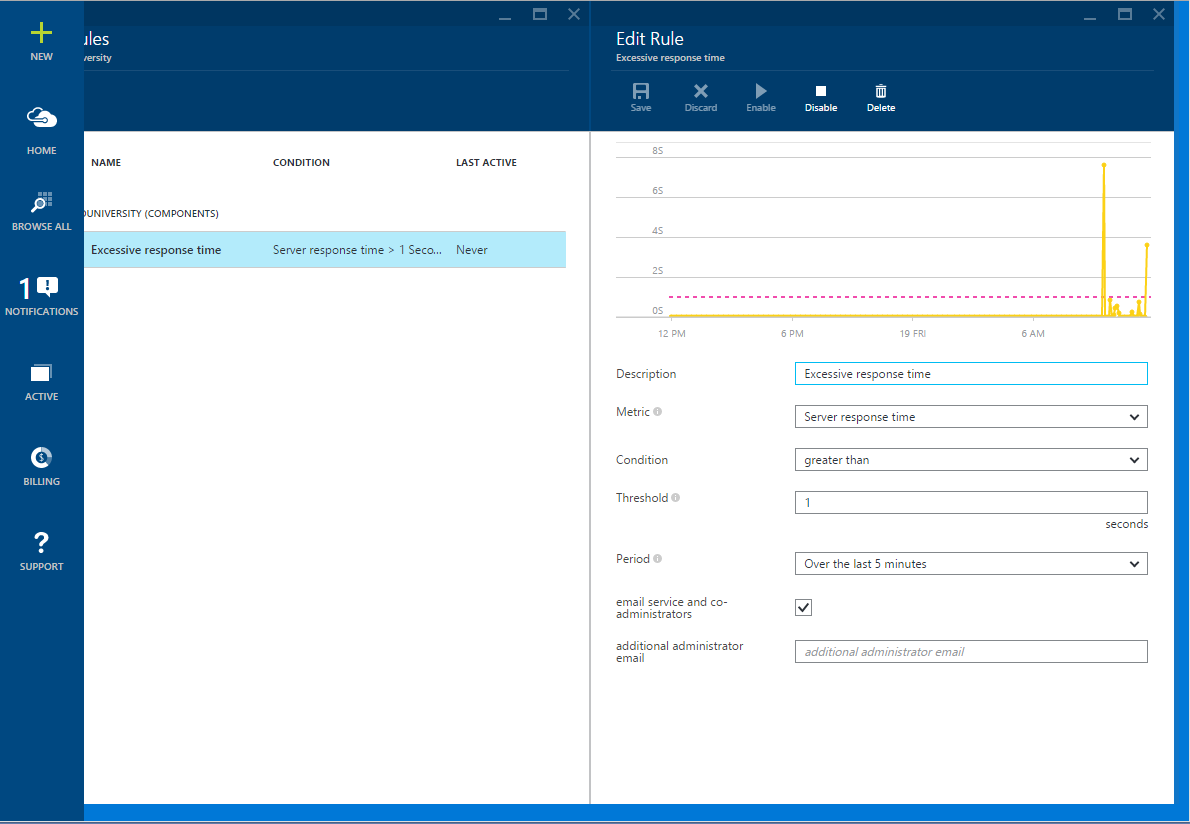
Создание нотификации в Application Insights
На рисунке ниже показана нотификация от Application Insights.
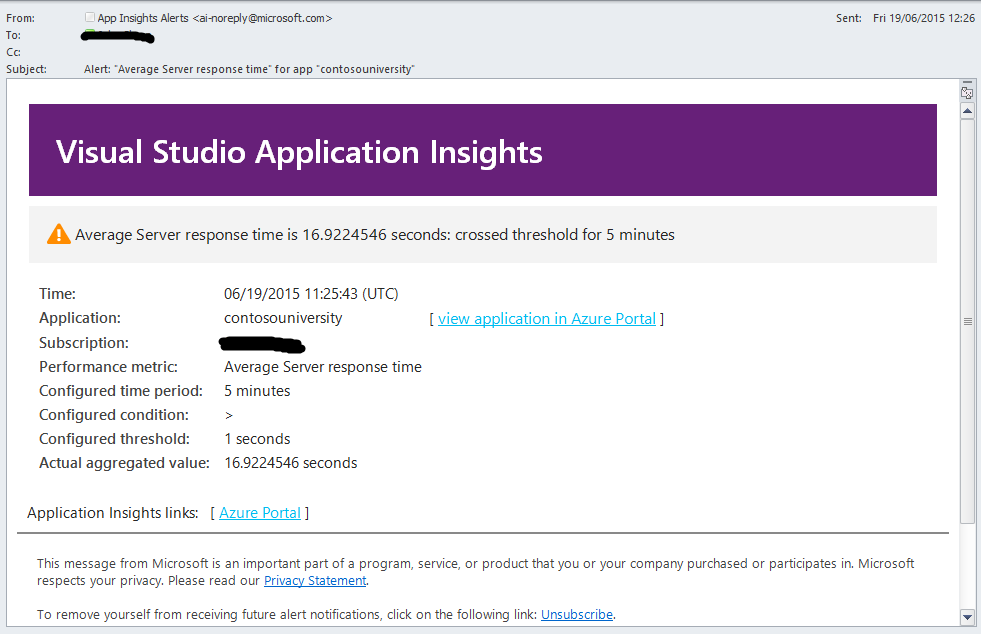
Уведомление от Application Insights
Оператор может использовать письма электронной почты для просмотра текущего состояния системы. New Relic также позволяет задавать политики, которые могут инициировать нотификацию, когда Индекс Производительности Системы (Application Perfomance Index или Apdex) для бизнес-транзаций показывает плохие показатели.
Примечание: Apdex – отраслевой стандарт единиц измерений согласно которому 1 показывает отличную производительность, а 0 означает проблемы. Более подробную информацию про это можно почитать на сайте APDEX.org
На рисунке ниже показана политика по умолчанию для транзакций в New Relic. Создается предупреждение тогда, когда среднее значение Apdex в интервале за 10 минут падает ниже значения 0.85 или ниже 0.7 за 5 минут. Также создается предупреждение, если частота ошибок превышает 1% за 10 минут или 5% за 3 минуты. Также New Relic создаст соответсвующее предупреждение, если веб-приложение будет недоступным в течении 1 минуты (проверка осуществляется с помощью пинга на заранее сконфигурированную конечную точку приложения).
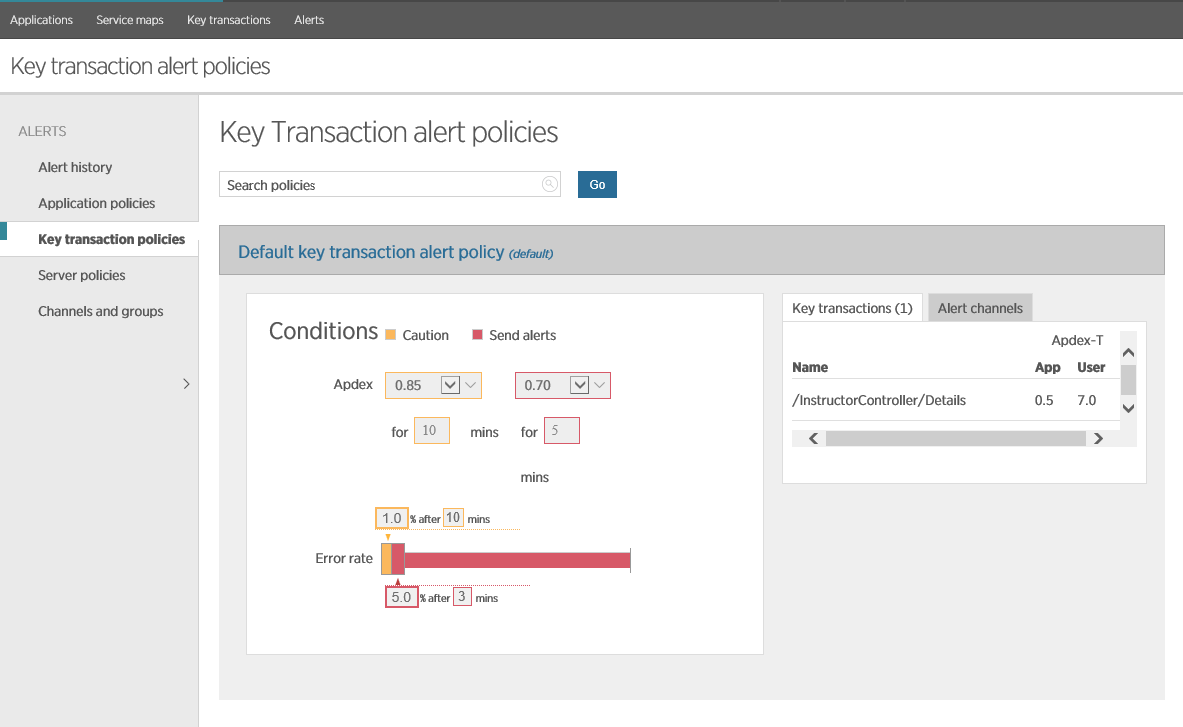
Настройка уведомлений в New Relic
Падающие бизнес-транзакции
Все бизнес-транзакции должны контролироваться на предмет сбоев. Предупреждения SLO могут указывать на повторяющиеся проблемы в течении определенного периода, но они также важны и для определения причин индивидуальных сбоев. Информация об исключениях может быть получена различными способами: приложение может записывать их в журнал событий windows либо использовать кастомное логирование APM (которое было описано ранее). На следующем рисунке показано, как эту информацию отображает New Relic.
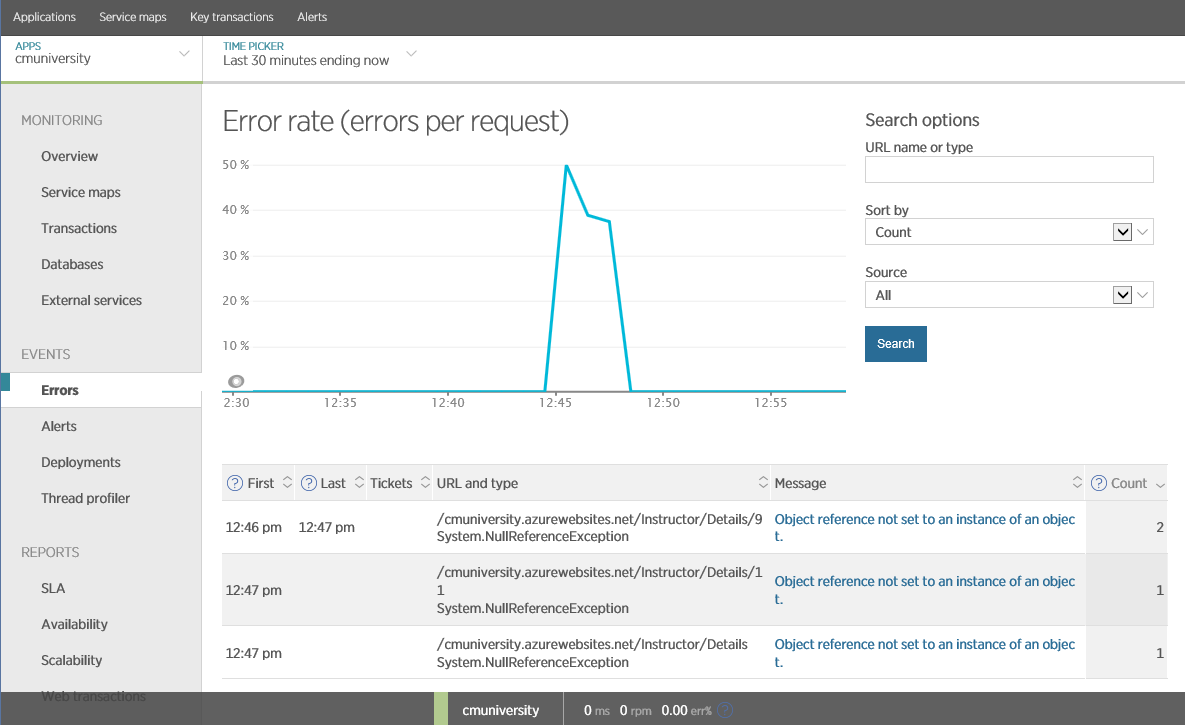
Исключения в New Relic
Вы можете получить аналогичную информацию при помощи Application Insights, а также определять, с помощью нее причины отдельных исключений.
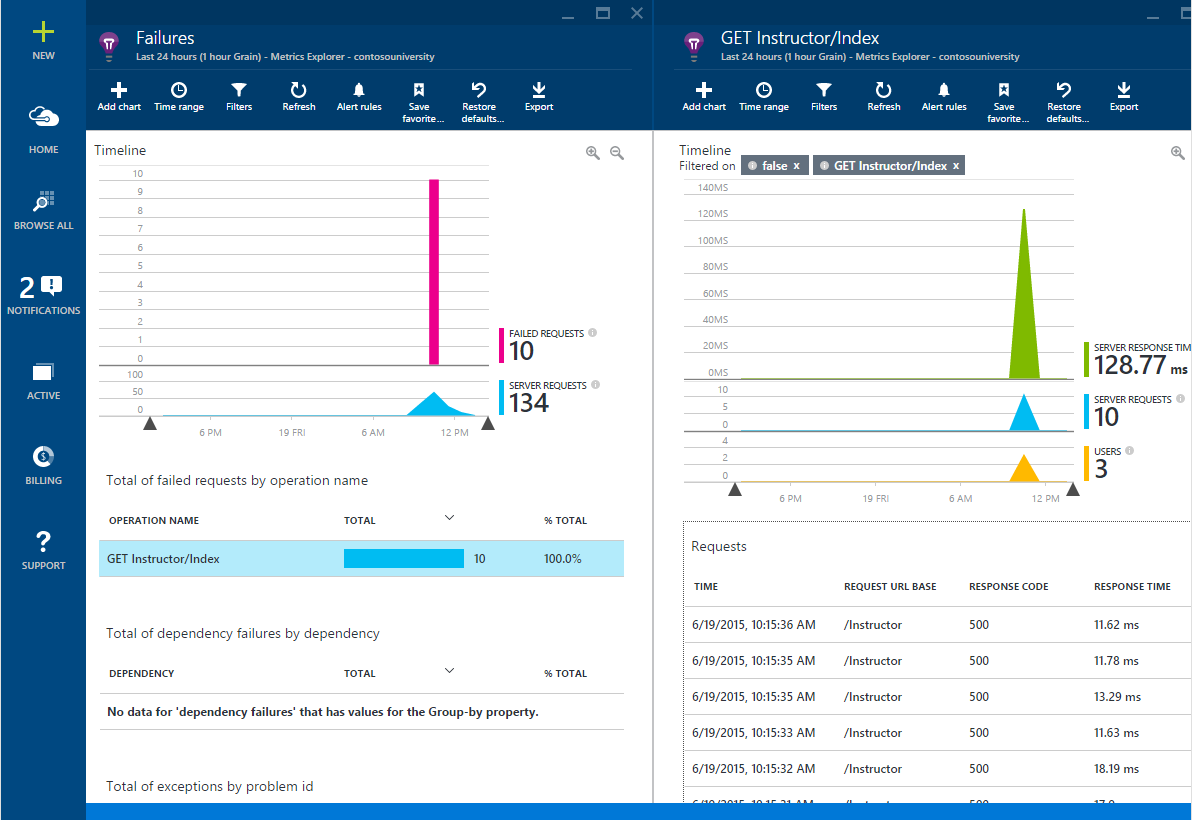
Проваленные запросы в Application Insights
Закономерности пропускной способности и времени ответа бизнес-транзакций
Все бизнес-транзакции должны контролироваться на предмет пропускной способности и времени выполнения, что позволит проводить динамический анализ исторических срезов. Для этого необходимо, чтобы APM имел доступ к историческим данным, Многие APM могут создавать отчеты, которые позволяют анализировать исторические данные производительности отдельных операций. Представленный ниже отчет был сгенерирован с помощью New Relic, он показывает как текущая производительность различных веб-транзакций соотносится с данными, полученными за вчерашний день.
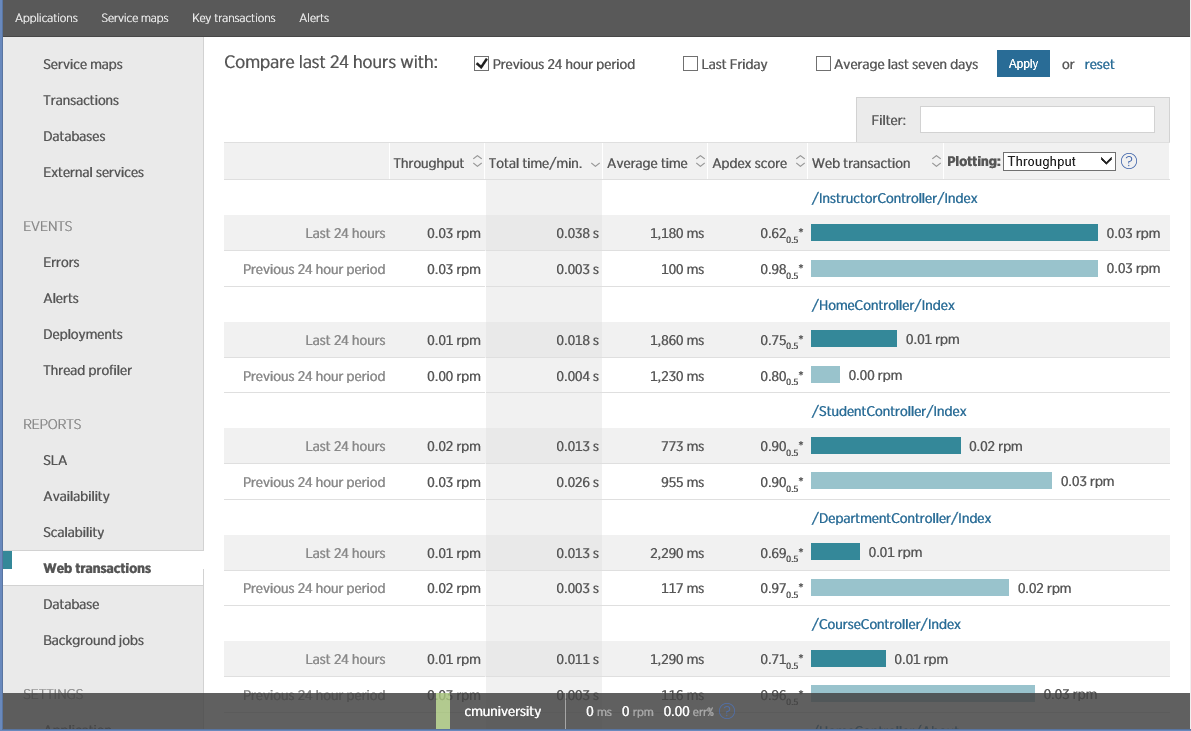
Закономерности в New Relic
Вы можете кастомизировать и изменять эти отчеты. Одна из особенностей New Relic заключается в возможности сравнения показателей текущего дня к показателем того же дня на прошлой неделе. Если бизнес носит циклический характер (в одни дни ожидается большая нагрузка нежели в другие), то подобная форма анализа может оказаться полезной.
Если у вас есть доступ к историческим данным производительности, то вы можете скачать их и проанализировать. Например, можно загрузить их в Excel и строить отчеты о производительности вашей системы в зависимости от времени суток, дня недели, конкретной операции или в зависимости от пользователя.
Метрики приложения
Метрики приложения заключают в себе низкоуровневое представление того, насколько хорошо система работает под нагрузкой (что именно происходит под “капотом” приложения). Получение данной информации требует отслеживание логов приложения, соединений БД, а также того, как приложение использует внешние сервисы (кэш, ServiceBus, авторизацию/аунтетификацию и тп). Метрики фреймворка тоже важны — счетчики ASP.NET и CLR (для приложения построенных на .NET), информация об исключениях, блокировка ресурсов и использование потоков.
Как их собирать
Многие из этих метрик могут быть получены очень просто, при помощи системных счетчиков производительности или другие сервисов, предоставляемых операционной системой. Как было описано ранее, многие APM-инструменты также позволяют внедрять (без ручного изменения кода) в вашу систему различные диагностические модули, способные фиксировать информацию, формируемую при работе приложения (вызовы БД, сторонних служб и т.п.).
При необходимости вы также можете внедрить в код вашего приложения кастомные функции для выделения вызовов внешнего API и других значимых действий (подобное изменение кода необходимо свести к минимуму, т.к. это оказывает влияние на общую производительность). Это можно сделать с применением логирования (подключением интерфейса logger) или расширенного API, которое предоставляет используемый вами APM.
Примечание: Данный подход привязывает ваше приложение к конкретному API, которое требует ручной вставки в код определенных диагностических вызовов, ожидающих данные специфического для конкретного APM-инструмента формата.
Причины высокой латентности и низкой пропускной способности
Операции, выполняемые приложением, включают в себя не только интерактивные запросы от пользователей, но и пакетную обработку и периодически выполняющиеся фоновые задания. Мониторинг бизнес-уровня может дать вам информацию о том, насколько выполняется SLO. Метрики приложения дают понимание, почему этого не происходит — в них может содержаться информация о различных аспектах запросов и о том, как они выполняются внутри системы.
На рисунке ниже показан главный экран New Relic, на котором изображены показатели рабочей системы. Оператором выделен момент времени, когда система выполняла тяжелые операции с БД (СУБД MsSQL). На рисунке видно, что приложение выполняет их плохо (Apdex на уровне 0.53, что указывает на какие-то проблемы). В это время пропускная способность составляла 710 запросов в минуту. Работа приложения характеризуется двумя операциями (веб-транзакциями), одна из которых – транзакция по адресу ChattyProduct, по-видимому, составляет большую часть серверного времени.
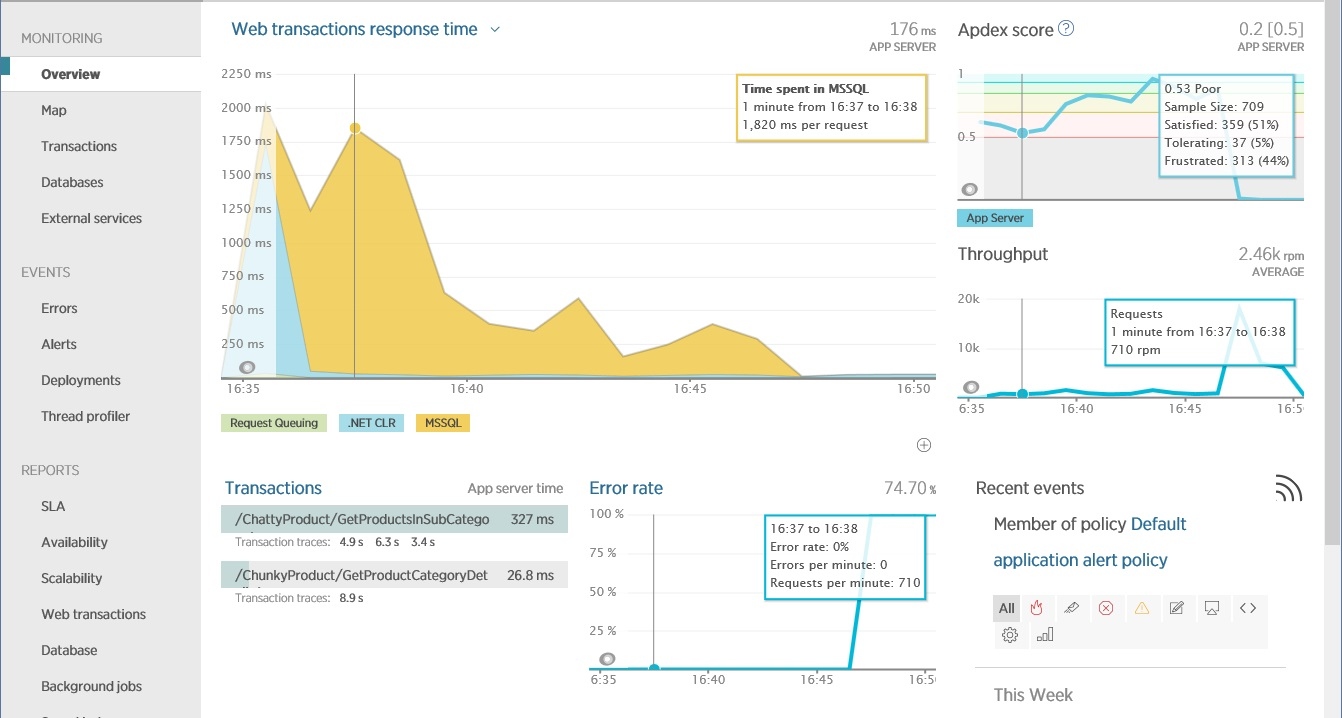
Экран Overview в New Relic, показывающий пропускную способность и латентность в веб-приложении за короткий промежуток времени.
Для запросов ChattyIO необходимо понять, какие ресурсы используются неэффективно. Телеметрия даст возможность детализировать запрос для определения того, что он на самом деле делает. В New Relic для этой цели предлагается сделать трассировку транзакций так, как показано на рисунке.
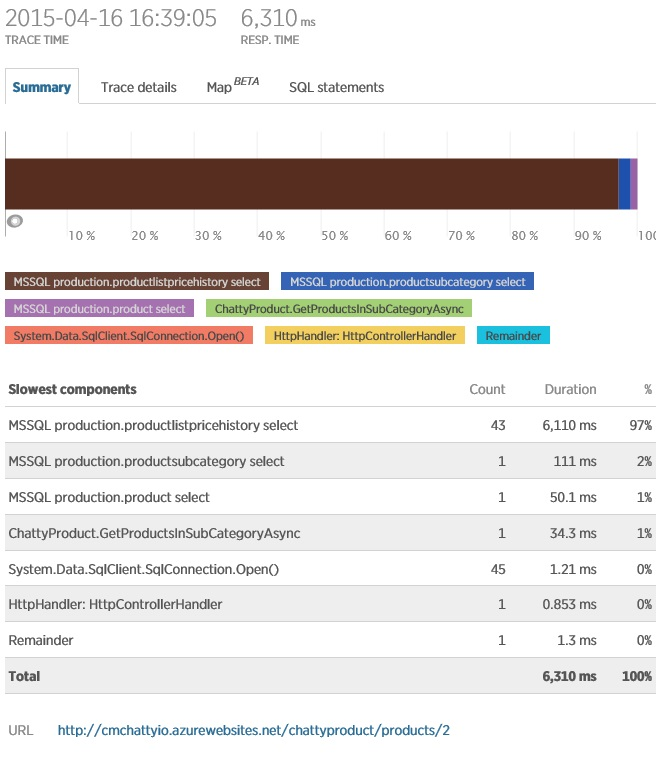
Очевидно, что операция использует значительные ресурсы БД, открывая 45 соединений. Один конкретный запрос выполняется 43 раза. Эта активность БД может объяснить, почему операция требует времения для выполнения.
Более глубокое расмотрение деталей трассировки показывает, как операция работает с соединениями – она их создает для каждого запроса, а не переиспользует существующие.
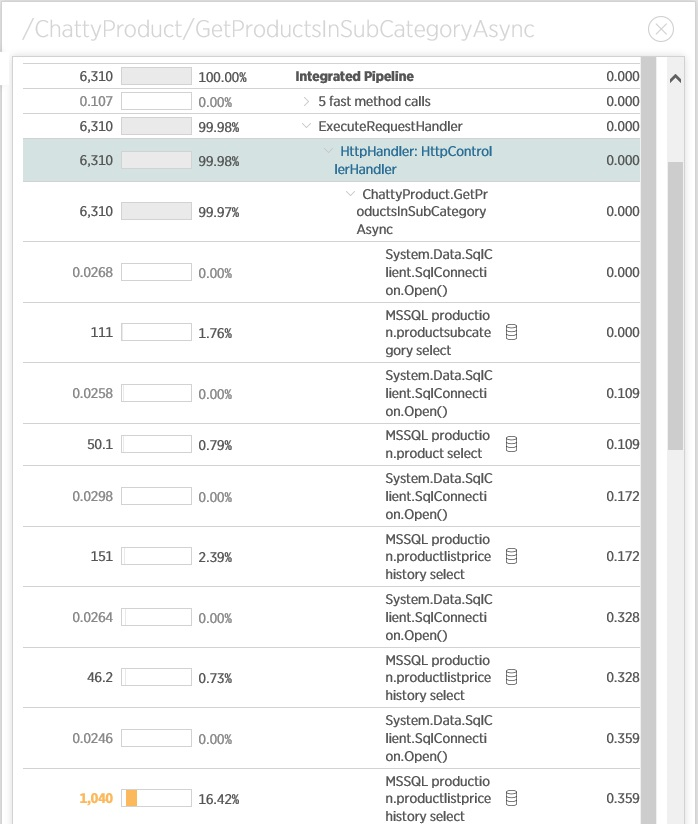
Эта операция должна быть проанализирована на предмет оптимиации количества подключения и запросов к БД.
Исключения
Исключения часто являются причиной разочарования пользователей. Они могут указывать на ошибке в коде, но также они могут возникать в результате чрезмерного потребления или недоступности ресурсов. Чтобы избежать потери бизнеса и финансовые проблемы, выявлять причины исключений необходимо оперативно.
На экране Overview в New Relic (см. ниже), видно, что что-то привело к возникновению большого числа исключений. Это вызвало значительное падения производительности (Apdex упал до 0). В этой точке также наблюдается значительный скачок пропускной способности, который, вероятно, связан с ошибками, приводящими к быстрым сбоям в операциях.
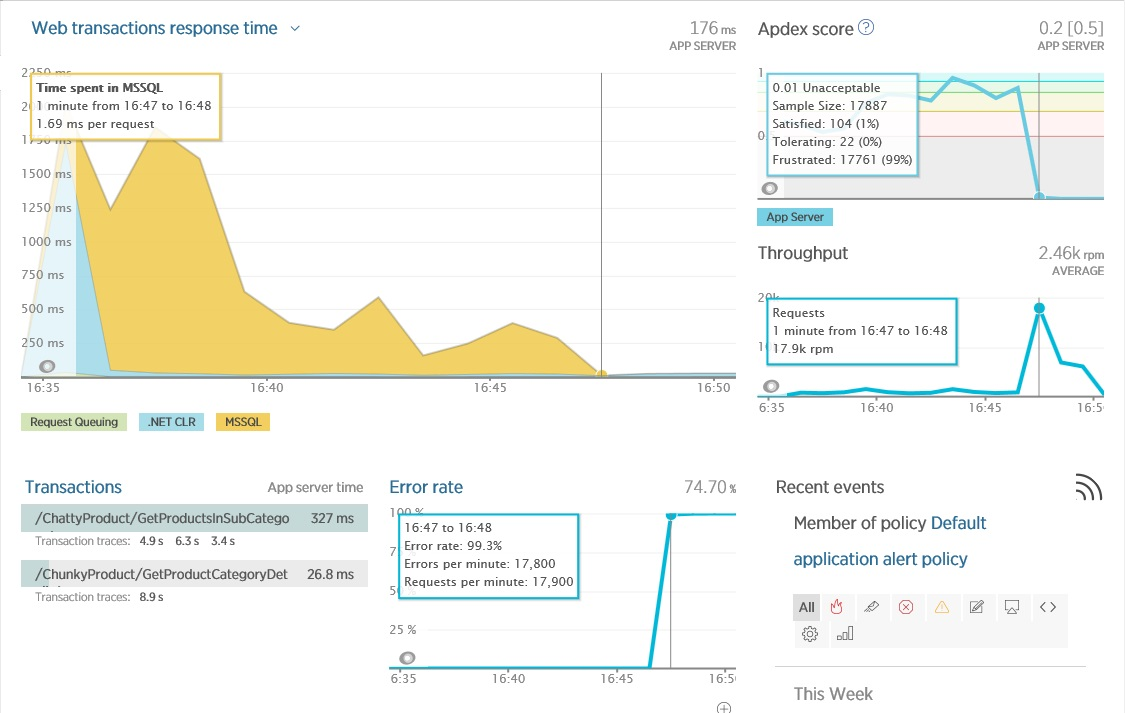
Изучение ошибок на экране Errors в New Relic дает дополнительную информацию, включающую детали исключения и операции, которая была выполнена в этот момент. Обратите внимание, что New Relic позволяет переходить во внутринние исключения для получения полного стека.
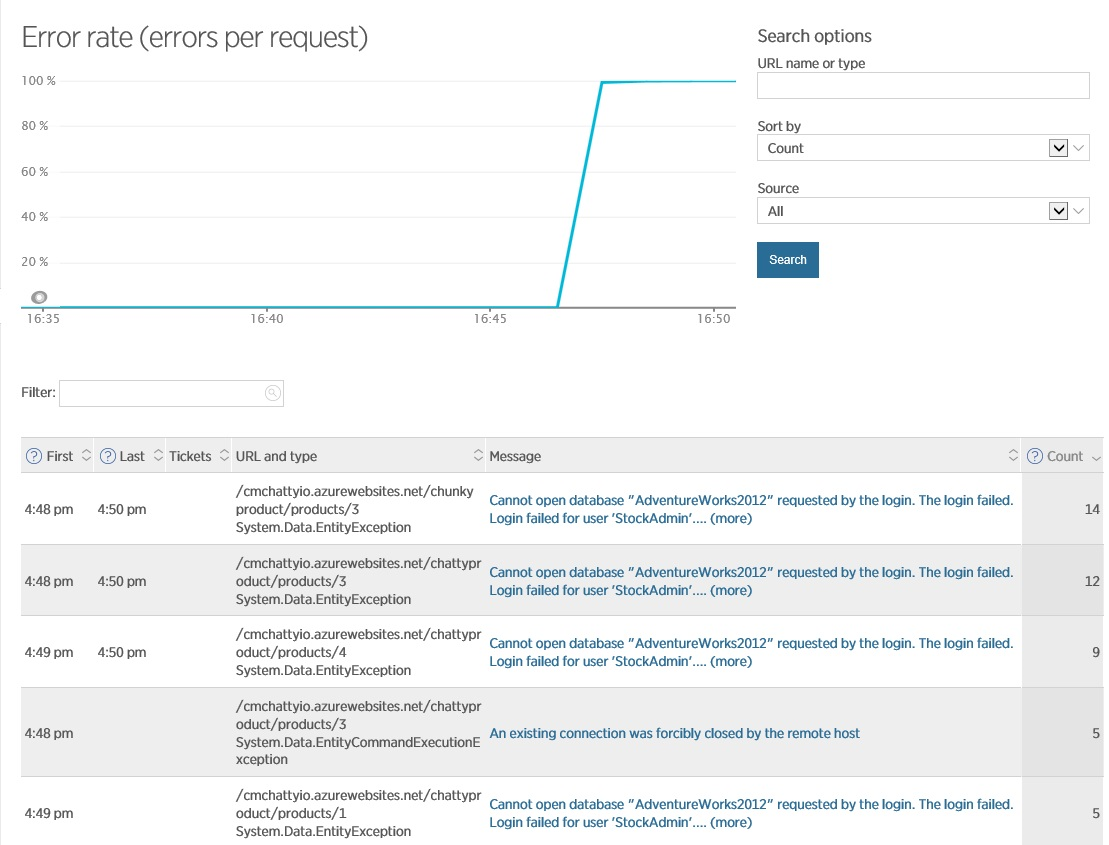
Эта информация дает вам понимание того, что проблема лежит в БД – иногда подключения отваливается. Это может быть связано с предыдущем сценарием – открытие большого количества соединений, которое может исчерпать ресурсы доступные для соединения и приводить к тому, что при выполнении новых запросов не удасться создать новых соединения к БД, или это может быть проблема с самой БД, что требует проверки сервера.
Производительность фреймворков
Код вашего приложения в рантайме может использовать такие технологии как .NET Framework, ASP.NET или другие фреймворки. Важно понимать, что они оказывают влияние на производительность вашей системы. Во многих случаях они предоставляют свои собственные метрики, позволяющие заглянуть внутрь процессов происходящих в приложение, что помогает вам использовать эти механизмы эффективнее и оптимизировать код. Например счетчики производительность .NET включают метрики показывающие как часть запускает процесс сборки мусора, и сколько объектов находится в куче. Вы можете использовать эту информацию для выявления нерационального использования памяти и связанных с ней ресурсов в коде вашего приложения (например, создание неоправданно больших массивов, постоянное создание и уничтожение больших строк или ошибки неправильного уничтожения ресурсов).
Веб-приложения зависят от веб-сервера, который принимает запросы от клиента и перенаправляет их в код обработки. Бизнес-нагрузка для облачных приложений может быть сильно асимметричной, с непредсказуемыми всплесками высокой активности, которые сменяются периодами покоя. Типичный веб-сервер способен обработать только некоторое максимальное количество параллельных запросов, поэтому остальные запросы могут быть поставлены в очередь. Если запрос не обработается в течении некоторого периода времени, то клиенту может вернуться ошибка тайм-аута. В некоторых системах, если число запросов в очереди превысит заданное пороговое значение, то последующие запросы будут сразу отброшены с сообщением об ошибке, которая вернется клиенту. Это встроенный механизм безопасности для предотвращения незапланируемого внезапоного всплеска клиентских запросов. Данная стратегия также препятствует клиенту оказаться “заблокированным”, когда запрос скорее всего и так вернется с ошибкой таймаута. Однако, если это происходит часто, то может потребоваться распределить нагрузку по нескольким веб-серверам или произвести исследование приложения на предмет проблем или оптимизации. Поэтому очень важно контроллировать скорость обработки запросов, а также число запросов ожидающих в очереди. Например, для ASP.NET приложений вы можете использовать следующие счетчики производительности:
- ASP.NET\Requests Queued, число запросов ожидающих в очереди на обработку
- ASP.NET\Requests Current, суммарное количество выполняющихся в настоящее время запросов. Значение этого счетчика включает в себя число обрабатывающися запросов, находящихся в очереди и ожидающих отправки клиенту. Если это значение превышает параметр requestQueueLimit, который расположен в секции processModelsection файла конфигурации веб-сервера, то последующие запросы будут отбрасываться.
- ASP.NET Application\Requests Executing, показывает количество одновременно выполняющихся запросов.
- ASP.NET Application\Requests/sec, текущую пропускную способность приложения
- ASP.NET Application\Request Execution Time, время выполнения (в мс) посденего запроса
- ASP.NET Application\Wait Time, время ожидания в очереди последнего запроса.
Примечание: По умолчанию конфигурация служб IIS, ASP.NET и .NET Framework`a оптимизирована исходя из количества ядер CPU. Но для приложений, часто выполняющих I/O операции ( например, веб-сервисы использующие внешние ресурсы) некоторые изменения данной конфигурации могут сущственно улучшить производительность.
Продолжим расматривать примеры с веб-сервером. вы всегда должны исследовать причины большой длины очереди. Большое количество ожидающих запросов в совокупности с низкой загрузкой CPU, сетевой утилизацией или памятью может указывать на проблемы с бэкендом. Например, если облачная служба для хранения данных использует БД SQL, и последняя содержит некоторую логику обработки (хранимые процедуры, тригеры), то сама БД может оказаться узким местом, что приведет к накапливанию запросов в очереди. Если мониторинг производительности бекенд сервисов покажет, что они работают нормально, но длина очереди вашего приложения будет сохраняться, то причиной проблем веб-сервера могут оказаться нехватка потоков, вызванная блокировкой синхронных операций.
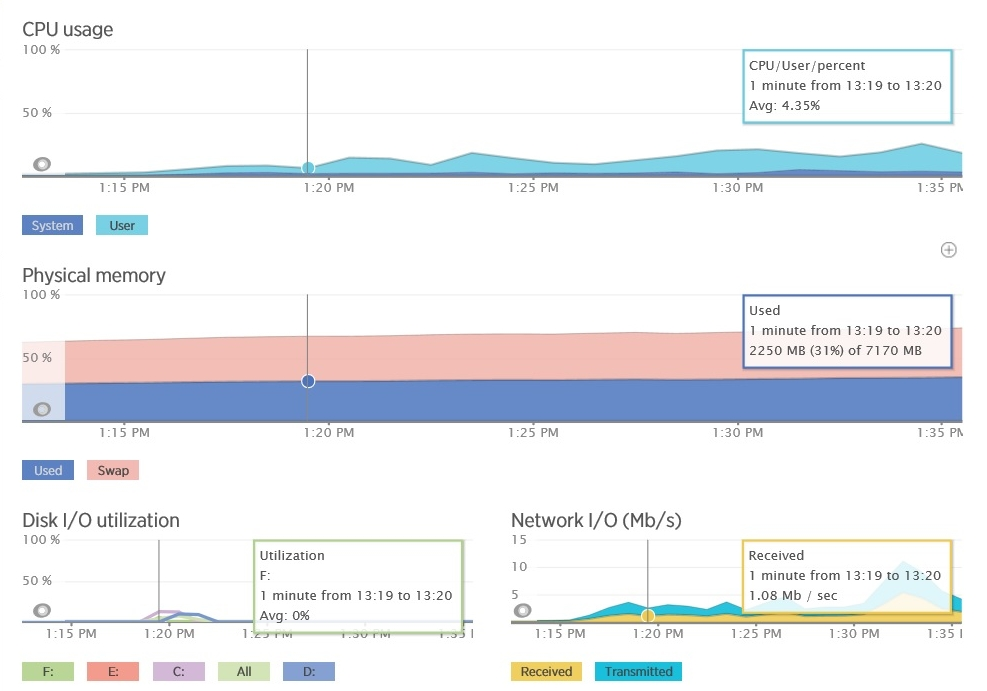
Ниже показан пример диаграммы (созданный New Relic), на котором время ожидания в очереди запросов для простого приложения обусловлено синхронными I/O операциями. Из-за нехватки доступных потоков IIS становится не в состоянии выполнять запросы своевременно и время, проведенное в очереди, постепенно увеличивается. Обратите внимание, что процессорное время и использование сети (показано на втором графике) очень низкие.
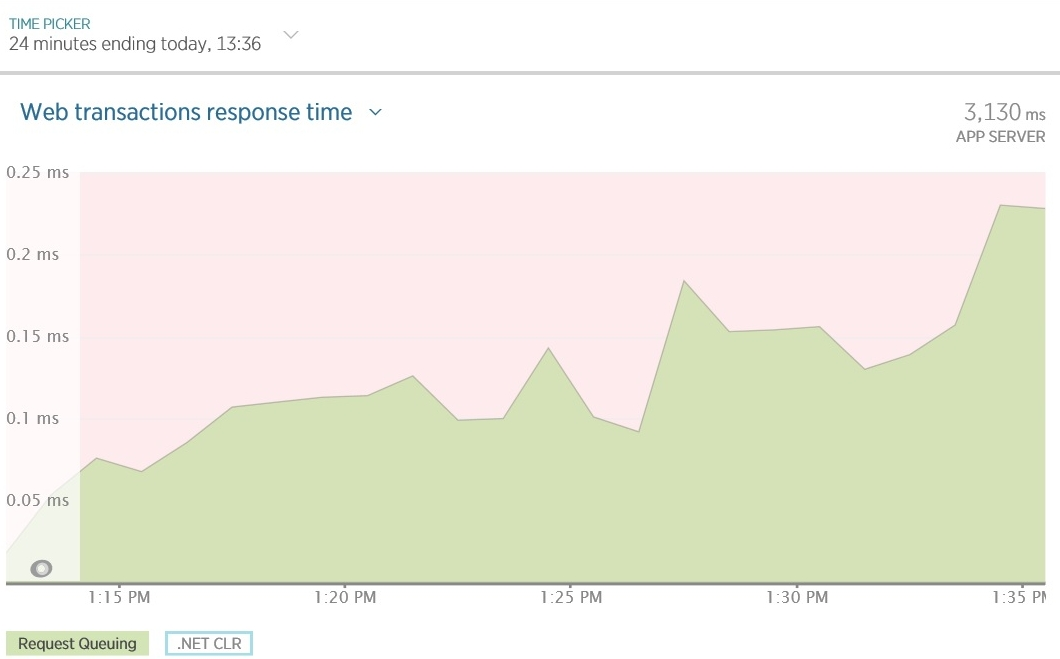
Вместе с ростом длины очереди растет время отклика и увеличивается число неудачных запросов. Приведенный ниже график показывает результаты нагрузочного теста простого приложения. При увеличении нагрузки (количества одновременных пользователей) возрастают латентность (время операций) и пропускная способность (количество операций в секунду). Обратите внимание, что левая ось отображает пользовательскую нагрузку, а логарифмическая правая ось измеряет латентность и пропускную способность. Когда пользовательская нагрузка превышает показатель 6000, запросы начинают генерировать исключения (либо таймауты, либо отказы из-за чрезмерной длины очереди). Эти исключения приводят к снижению латентности и увеличении пропускной способности по причине того, что исключение генерируются быстрее, чем выполняются успешные запросы.
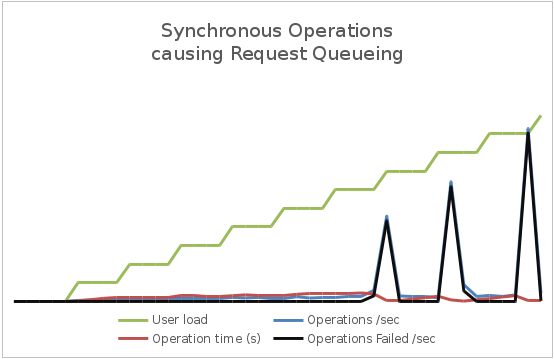
Вместе с увеличением пользовательской базы будет расти и общая нагрузка на систему. Вы должны убедиться, что система не достигнет точки, когда она может внезапно рухнуть под нагрузкой. Для этого необходимо контролировать использование системой общих ресурсов (CPU, память, пропускную способность сети и т.д.) и графики зависимости этой информации от пропускной способности и латентности и/или задержки. Подобная форма измерения часто требует, чтобы вы контролировали инфраструктурные метрики и телеметрию других сервисов, от которых зависит ваше приложение. В качестве примере на следующем рисунке показана телеметрия New Relic от приложения, описанного ранее – мы видим данные по использованию памяти и загрузке процессора для приложения. Утилизация (загрузка) процессора является относительно-постоянной величиной в пределах некоторых границ (если в системе несколько процессоров, то его утилизация может превышать 100%), несмотря на перепады пропускной способности. Вы должны проверить, начнет ли система генерировать исключения в этой точке. Если да, то это может указывать на недостаточную емкость для роста нагрузки. Утилизация памяти также довольно стабильна, хотя и может медленно расти с нагрузкой. Но если она начинает расти без какой-либо причины, то это может указывать на утечку памяти.
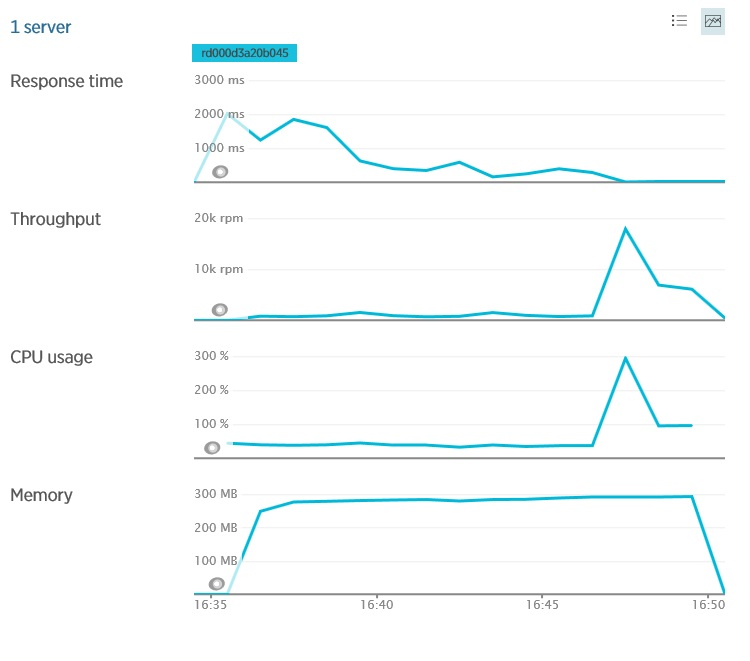
Ресурсы сервера в New Relic
Спасибо всем за внимание! В следующей, и заключительной части — про системные метрики и прочие интересные для анализа моменты.
Части статьи:
Анализ ключевых показателей производительности — часть 1
Анализ ключевых показателей производительности — часть 2, про анализ метрик пользовательских, бизнесовых и приложения
Анализ ключевых показателей производительности — часть 3, последняя, про системные и сервисные метрики.
Комментарии (3)

SychevIgor
09.12.2015 19:10Спасибо!!!
А можно ссылку на оригинал статей?
Не то, чтобы мне перевод не нравился, но хотелось бы весь цикл самому глянуть.

teleavtomatika
Вам не кажется, что это очень коряво для заголовка?