

Когда мы общаемся с нашими заказчиками, то, будучи специалистами в этой области, активно используем соответствующую терминологию, в частности слово «распознавание». При этом слушающая аудитория, воспитанная на Cuneiform и FineReader, часто вкладывает в этот термин именно задачу сопоставления вырезанного участка изображения некоторому числу (коду символа), которая в наши дни решается нейросетевым подходом и является далеко не первым этапом в задаче распознавания информации. В начале необходимо локализовать карточку на изображении, найти информационные поля, выполнить сегментацию на символы. Каждая перечисленная подзадача с формальной точки зрения является самостоятельной задачей распознавания. И если для обучения нейронных сетей существуют зарекомендовавшие себя подходы и инструменты, то в задачах ориентации и сегментации каждый раз требуется индивидуальный подход. Если вам интересно узнать про подходы, которые мы использовали при решении задачи распознавания банковской карточки, тогда добро пожаловать под кат!
Распознавание данных с кредитной карты одновременно является высокоактуальной и весьма интересной с точки зрения алгоритмов задачей. Хорошо реализованная программа распознавания пластиковых карт может избавить человека от надобности вводить большую часть данных вручную при осуществлении интернет-платежей и платежей в мобильных приложениях. С точки зрения распознавания, банковская карта — это сложный документ стандартного размера (85,6 ? 53,98 мм), выполненный на типовом бланке и содержащий определенный набор полей (как обязательных, так и дополнительных): номер карты, имя держателя карты, дата выдачи, срок действия, номер аккаунта, CVV2-код или его аналог. Часть полей находится на лицевой стороне, другая часть — на обратной. И несмотря на то, что для совершения платежной транзацкии требуется указать только номер карты, практически все платежные системы (в качестве проверки подлинности) дополнительно требуют указать имя держателя карты, срок действия и CVV2-код. Сосредоточимся дальше на задаче распознавания информационных полей лицевой стороны карточки (объективно, она в разы сложнее).
Итак, для совершения интернет-платежа в большинстве случаев требуется распознать на изображении номер карточки, имя держателя и срок действия карты.
В качестве первого этапа необходимо найти координаты углов карточки. Так как геометрические характеристики карточки нам известны (все карточки выполнены строго в соответствии с стандартом ISO 781), то для определения четырехугольника карточки воспользуемся алгоритмом поиска и перебора прямых, про который мы уже рассказывали в одной из наших публикаций на Хабре.
При известном четырехугольнике нетрудно вычислить и применить к изображению проективное преобразование, приводящее изображение карты к ортогональному виду с фиксированным разрешением. Будем считать, что такое исправленное изображение приходит на вход последующим этапам — ориентации и распознаванию конкретных информационных полей.
С точки зрения архитектуры, распознавание трех целевых полей состоит из одних и тех же частей:
- Предварительная фильтрация изображения (с целью подавления фона карточки, который бывает удивительно разнообразным).
- Поиск зоны (строки) целевого информационного поля.
- Сегментация найденной строки на “коробки символов”.
- Распознавание найденных “коробок символов” с помощью искусственной нейронной сети (ИНС).
- Применение постобработки (использование алгоритма Луна для выявления ошибок распознавания, применение словарей имен и фамилий, проверка даты на валидность и т.п.).
Хотя состав шагов распознавания один и тот же, сложность сильно разнится. Легче всего распознать номер карты (не даром существует достаточное количество SDK для различных мобильных платформ, в том числе и выложенных в свободном доступе) в силу целого набора причин:
- номер карточки содержит только цифры;
- формат номера строго определен для каждого типа платежной карты;
- геометрическое положение номера не сильно “гуляет” вне зависимости от производителя;
- существует алгоритм Луна, позволяющий проверить правильность распознавания номера.
Сложнее дело обстоит с двумя оставшимися полями: срок действия и имя держателя карты. В этой статье подробнее остановимся на процедуре распознавания срока действия карты (распознавание имени выполняется аналогично).
Алгоритм распознавания срока действия
Пусть изображение карты у нас уже выправлено (как было сказано выше). Результатом работы алгоритма должны быть 4 десятичные цифры: по две на месяц и год срока окончания действия. Считается, что алгоритм выдал правильный ответ, если полученные 4 цифры совпадают с теми, что изображены на карте. Символ, разделяющий их, не учитывается и может быть любым. Отказ от распознавания трактуется как неверный ответ.
Первым шагом требуется локализовать поле на карточке (в отличии от номера, расположение этого поля не стандартизовано). Использование «метода грубой силы» по всей площади карты – занятие малоперспективное, поскольку соответствующий текстовый фрагмент очень короткий (чаще всего 5 символов), синтаксическая избыточность невелика, и вероятность ложного обнаружения на произвольном фрагменте текста или даже пестром участке фона оказывается неприемлемо большой. Поэтому применим хитрость: будем искать не саму дату, а некоторую информационную зону, расположенную под номером карточки и обладающую устойчивой геометрической структурой.

Рисунок 1. Примеры искомой трехстрочной информационной зоны
Рассматриваемая зона разбивается на три строки, одна из которых часто пустая. Важно, что расположение строки с датой внутри этой зоны хорошо определено. Эта парадоксальная фраза означает следующее: в случае, когда непустых строк в зоне две, их межстрочный интервал либо совпадает с межстрочным интервалом трехстрочных зон, либо примерно равен сумме удвоенного интервала и высоты строки.
Поиск зоны и разбиение ее на 3 строки осложняется наличием на карте фона, который, как мы уже говорили, разнообразный. Для решения этой задачи к изображению карточки применяется комбинация фильтров, целью чего является выделение вертикальных границ букв и гашение остальных деталей изображения. Последовательность фильтров следующая:
- Осерение изображения путем усреднения значений цветных каналов с помощью формулы
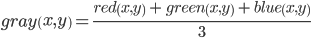 , см. рисунок 2б.
, см. рисунок 2б. - Вычисление изображения вертикальных границ с помощью формулы
 , см. рисунок 2в.
, см. рисунок 2в. - Фильтрация маленьких вертикальных границ с помощью математической морфологии (конкретно путем применения эрозии с прямоугольным окном размера
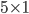 ), см. рисунок 2г.
), см. рисунок 2г.

Рисунок 2. Предварительная фильтрация изображения кредитной карты: а) исходное изображение, б) изображение в градациях серого в) изображение вертикальных границ, г) фильтрованное изображение вертикальных границ
В нашей реализации для экономии времени морфологические операции реализованы с использованием алгоритма ван Херка. Он позволяет вычислять морфологические операции с прямоугольным примитивом за время, не зависящее от размеров примитива, что позволяет использовать сложные морфологические фильтры большой площади в задачах распознавания документов в режиме реального времени.
После фильтрации интенсивности пикселей обработанного изображения проецируются на вертикальную ось:
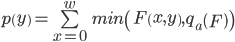
где
 — фильтрованное изображение,
— фильтрованное изображение, 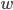 — ширина изображения,
— ширина изображения,  — квантиль уровня
— квантиль уровня  (эта величина используется для порогового отсечения с целью подавить влияние резких шумовых границ, которые как правило возникают из-за наличия нанесенного краской статического текста типа “valid thru” и т.п.).
(эта величина используется для порогового отсечения с целью подавить влияние резких шумовых границ, которые как правило возникают из-за наличия нанесенного краской статического текста типа “valid thru” и т.п.).По полученной проекции
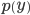 теперь возможно найти наиболее вероятное положение строк, предполагая отсутствие горизонтальных границ в межстрочных интервалах. Для этого минимизируем сумму по проекции по всевозможным периодам
теперь возможно найти наиболее вероятное положение строк, предполагая отсутствие горизонтальных границ в межстрочных интервалах. Для этого минимизируем сумму по проекции по всевозможным периодам  и начальным фазам
и начальным фазам 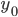 из заранее заданного интервала:
из заранее заданного интервала:
Поскольку локальные минимумы
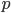 , как правило, достаточно выражены и на внешних границах текста, оптимальное значение
, как правило, достаточно выражены и на внешних границах текста, оптимальное значение  равняется четырем (подразумевая, что на карте 3 строки, а, следовательно, 4 локальных минимума). В результате мы найдем параметры
равняется четырем (подразумевая, что на карте 3 строки, а, следовательно, 4 локальных минимума). В результате мы найдем параметры 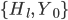 , задающие центры межстрочных интервалов, а также внешние границы текста (см. рисунок 3).
, задающие центры межстрочных интервалов, а также внешние границы текста (см. рисунок 3).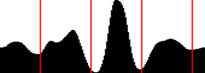
Рисунок 3. Вид проекции и оптимальные разрезы, выделяющие на ней области трех строк
Теперь область поиска даты можно существенно сократить, одновременно учитывая исходную форму области и найденное на данном изображении положение строк. Для такого пересечения генерируется множество возможных положений подстрок, с которым и будет вестись работа далее.
Каждая из подстрок-кандидатов сегментируется на символы, учитывая, что все символы на таких картах моноширинные. Это позволяет использовать алгоритм динамического программирования для поиска межсимвольных разрезов без распознавания символов (все, что требуется знать — допустимый интервал для ширины символа). Здесь изложим основные идеи алгоритма.
- Пусть y нас есть фильтрованное изображение вертикальных границ строки, содержащей дату. Построим проекцию данного изображения на горизонтальную ось. Полученная проекция будет содержать локальные максимумы в местах вертикальных границ (то есть в зоне букв) и минимумы между буквами. Пусть — ожидаемый период, а
 — максимальное отклонение значения периода.
— максимальное отклонение значения периода. - Будем двигаться слева направо по построенной проекции. Заведем дополнительный массив-аккумулятор, где в каждом элементе будет храниться накопленный штраф. На каждом шаге
 рассмотрим отрезок аккумулятора
рассмотрим отрезок аккумулятора  . Запишем в качестве текущего значения штрафа сумму значения проекции в точке и минимальное значение штрафа из рассматриваемого отрезка. Дополнительно сохраним индекс предыдущего шага, доставляющего указанный минимум.
. Запишем в качестве текущего значения штрафа сумму значения проекции в точке и минимальное значение штрафа из рассматриваемого отрезка. Дополнительно сохраним индекс предыдущего шага, доставляющего указанный минимум. - Пройдя описанным образом всю проекцию, можем проанализировать массив-аккумулятор штрафов и, благодаря сохранению индексов предыдущих шагов, восстановить все разрезы.
После сегментации на символы, пришло время распознавания с помощью искусственной нейронной сети (ИНС). К сожалению, сколь-нибудь подробное описание этого процесса выходит за рамки данной статьи. Отметим только пару фактов:
- Для распознавания используются сверточные нейронные сети, обученные с помощью инструмента cuda-convnet.
- Алфавит обученной сети содержит цифры, знаки препинания, пробел и знак не-символа («мусора»).
Таким образом, для каждого изображения символа мы получим массив, содержащий псевдовероятностные оценки нахождения соответствующего символа алфавита на данном изображении. Казалось бы, правильный ответ — построить строку из наилучших вариантов (с наибольшими значением псевдовероятности). Однако ИНС иногда ошибается. Часть ошибок ИНС можно исправить с помощью постобработки благодаря существующим ограничениям на ожидаемые значения даты (например, не бывает 13-го месяца). Для этого используется так называемый алгоритм “рулетки”, итерационно перечисляющий все возможные варианты “прочтения строки” в порядке убывания общей псевдовероятности. Первый удовлетворяющий существующим ограничениям вариант считается ответом.
Конечно, помимо описанного “элементарного” постпроцесса в нашей системе используются и дополнительные контекстно-зависимые методы, описание которых не попало в данную статью.
Результаты работы
Для того, чтобы оценить качество работы нашего SDK, мы собрали базу изображений карточек различных платежных систем, выпущенных разными банками в размере 750 изображений (количество уникальных карточек — 60 штук). На собранном материале получили следующие результаты:
- Качество распознавания номера — 99%
- Качество распознавания даты — 99%
- Качество распознавания имени держателя карты — 90%
- Общее время распознавания карты на iPhone 4S — 0.6 секунды.
Список полезных источников
- van Herk М. A fast algorithm for local minimum and maximum filters on rectangular and octogonal kernels // Pattern Recognition Letters, 1992, V. 13, № 7, pp. 517–521.
Комментарии (11)

ZlodeiBaal
09.12.2015 11:05+4Классно. Но сразу возникает ряд вопросов:
1) Вся база — сделана на одном и том же столе? Если будут меняться внешние условия: направление освещения, углы наклона, и.т.д. всё продолжает работать?
2) Обучались на символы по какой базе? По тем же самым 750 фотографиям, или по другой?
3) Шрифты у всех банков одинаковые? Не нашлось ли кого-то, кто хотел выпендириться?
4) Горизонтальные и вертикальные фильтры это хорошо, я сам люблю их применять для похожих задач. Но как только имеется высокочастотный фон (вот смотрю на свою карточку Тинькова), то сразу весь этот подход рушиться. Как удалось разрешить такие ситуации?
5) На csv код обученный алгоритм не работает? Как я понимаю там-то у всех банков точно разные шрифты.
Буду ждать статьи про обучение свёрточных сетей. Любопытно как вы решали там несколько проблем.
Хотя, конечно, у меня есть мнение, что когда в задаче реально сделать хорошую сегментацию, то всё остальное уже просто реализуется любым другим способом. Хоть SVM, хоть корреляцией:)
SmartEngines
09.12.2015 14:08+1Спасибо за интересные вопросы! Ниже ответы по пунктам:
1) База сделана в различных условиях. Менялись устройства, освещение, снимали разные люди (иногда даже пальцы на картах присутствуют). При этом в основном снимали карточку «на весу», стол использовали в основном для получения рекламных фотографий.
2) Обучение свёрточных сетей производилось на искусственно созданной базе изображений (благо целевой шрифт известен – OCR-B) с последующей аугментацией. Ни одно изображение из упомянутых 750 картинок не использовалась для обучения.
3) Шрифт на картах один (OCR-B) и места для творчества платежные системы здесь не предоставляют. Фон придумывает банк. Было замечено использование OCR-A шрифта на indent-картах некоторых банков. Но для нас не проблема, так как мы используем искусственно созданную обучающую выборку.
4) Пестрый высокочастотный фон действительно создает дополнительные трудности. В этом месте нас спасает тот факт, что алгоритм поиска анализирует изображение границ, зная, что ищется три геометрически описанных строки. Такая задача похожа чем-то с распознаванием у окулиста цветных зашумленных карточек с цифрами: без знания того, что на карточках цифры распознать на них что-то разумное проблематично.
5) В настоящий момент наше SDK не распознает CSV код. При этом понимаем, что эта задача представляет собой omni-шрифтовое распознавание текстовой строки, которое у нас имплементировано.


tbl
09.12.2015 15:14Можно будет взять изображения из вашей статьи для моей статьи по теории и алгоритмам устранения искусственного размытия (deblur)?
atd
[немного офтопик] на первой картинке 7136 8525 ?
SmartEngines
Нет.
redmanmale
Полученный вами номер карты принадлежит банку в Перу, что явно не так [!].
mirrr
21… же