
 На Хабре уже неоднократно затрагивалась тема применения так называемых “бандитов” для интеллектуального анализа данных. В отличии от уже привычного обучения машин по прецедентам, которое сплошь и рядом применяется в задачах распознавания, многорукий бандит применяется для построения в некотором смысле “рекомендательных” систем. На Хабре уже очень подробно и доступно рассказано о идее многорукого бандита и применимости ее к задаче рекомендации интернет-контента. Мы же в своем очередном посте хотели рассказать вам о симбиозе обучения по прецедентам и обучения с подкреплением в задачах распознавания видеопотока.
На Хабре уже неоднократно затрагивалась тема применения так называемых “бандитов” для интеллектуального анализа данных. В отличии от уже привычного обучения машин по прецедентам, которое сплошь и рядом применяется в задачах распознавания, многорукий бандит применяется для построения в некотором смысле “рекомендательных” систем. На Хабре уже очень подробно и доступно рассказано о идее многорукого бандита и применимости ее к задаче рекомендации интернет-контента. Мы же в своем очередном посте хотели рассказать вам о симбиозе обучения по прецедентам и обучения с подкреплением в задачах распознавания видеопотока.Рассмотрим задачу детектирования геометрически жесткого объекта в видеопотоке. В далеком 2001 первом году Паул Виола и Майкл Джонс предложили алгоритм детектирования (далее будем называть его метод Виолы и Джонса [1]), с помощью которого можно выполнять поиск такого рода объектов на отдельных изображениях за доли секунды. Хотя алгоритм исходно разрабатывался для решения задачи поиска лиц, в наши дни он успешно применяется в различных областях машинного зрения там, где необходима детекция в режиме реального времени.
Но как быть, когда в видеопотоке требуется искать несколько разнотипных объектов? В таких случаях обычно обучают несколько различных детекторов Виолы и Джонса и применяют их независимо на кадрах видеопотока, замедляя тем самым процедуру поиска в пропорциональное количеству объектов число раз. К счастью, на практике довольно часто возникает ситуация, когда несмотря на большое количество допустимых объектов, в каждый момент времени на кадре присутствует не более одного искомого объекта. В качестве примера приведем реальную задачу из нашей практики, обретенной в процессе кропотливого создания Smart IDReader. Банковский служащий с помощью веб-камеры регистрирует выдаваемые клиентам банковские карты, при этом требуется по нанесенному логотипу определить тип карты и распознать номер. Несмотря на то, что в настоящее время существует более десяти различных видов платежных систем (а следовательно, более 10 различных логотипов), в каждый момент времени оператор показывает только одну карту.
Задача о многоруком бандите
Исходная форма задачи об n-руком бандите формулируется следующим образом. Пусть приходится многократно осуществлять выбор одной из n различных альтернатив (вариантов действий). Каждый выбор влечет за собой получение определенного вознаграждения, зависящего от выбранного действия. Среднее вознаграждение за выбор данного действия называется ценностью действия. Целью последовательности действий является максимизация ожидаемого полного вознаграждения за заданный период времени. Часто каждая такая попытка называется игрой.
Хотя точные значения ценности действий не известны, их оценки могут быть получены с каждой новой игрой. Тогда в каждый момент времени найдется хотя бы одно действие, для которого такая оценка будет наибольшей (такие действия называются жадными). Под применением понимается выбор жадного действия в очередной игре. Под изучением понимается выбор одного из нежадных действий в данной игре с целью более точной оценкой ценности нежадного действия.
Обозначим через Vt(a) предполагаемое значение ценности действия a в t-ой игре. Если к моменту времени t начала t-ой игры действие a было выбрано ka раз, что привело к последовательному получению вознаграждения r1, r2,…, rka, то ценность действия для всех ka > 0 будет оцениваться по формуле:
Несмотря на то, что проще всего в каждой игре выбирать действие, обладающее максимальной предполагаемой ценностью, такой подход не приводит к успеху из-за отсутствия процедуры исследования. Существует большое количество способов избавиться от этой проблемы. Часть из них очень простая и быстро приходит на ум каждому математику. Часть из них уже была изложена здесь на Хабре. В любом случае, мы считаем, что правильнее будет не сжимать математически красивую теорию в масштабы и форматы Хабра, а предоставить уважаемому читателю ссылку на доступную литературу [2].
Задача выбора распознающего детектора
Итак, вернемся к нашей задаче поиска объектов в видеопотоке. Пусть есть видеофрагмент, содержащий T кадров. На каждом кадре видеопоследовательности может находиться не более одного объекта, который требуется детектировать. Всего N различных типов объектов, причем для каждого типа обучен собственный каскад Виолы и Джонса. Объекты на видеопоследовательности появляются и исчезают естественным путем, не существует мгновенного появления или исчезновения объектов (например, в задаче регистрации банковских карт с помощью веб-камеры, описанной во введении, естественность заключается в плавном последовательном появлении и исчезновении карты в кадре). Необходимо построить алгоритм выбора детектора (будем обозначать его буквой a) для каждого кадра видеофрагмента, обеспечивающий максимально точное детектирование объектов.
Чтобы была возможность сравнивать различные алгоритмы выбора детектора необходимо определить функционал качества Q(a). Чем лучше наш алгоритм “подбирает” распознающий детектор для очередного кадра, тем выше должно быть значение функционала. Тогда, опуская математику (с ней всегда можно ознакомиться в нашей полной версии статьи [3]), будем вычислять функционал как количество правильно распознанных кадров видеопоследовательности.
Алгоритм жадного выбора детектора
Перейдем непосредственно к описанию алгоритма, который, напомним, оперирует инструментом машинного обучения с подкреплением.
Если в задаче о многоруком бандите вознаграждение возникает естественным образом, то в задаче поиска объектов понятие «вознаграждение» требует отдельного определения. Интуитивно понятно, что вознаграждение за выбор действия (распознающего каскада) должно быть положительным, если удалось правильно найти объект, и нулевым в противном случае. Однако в момент игры достоверной информации об имеющихся на кадрах объектах нет, так как в противном случае задача поиска объектов на изображении не имеет смысла. Тогда, предполагая, что детекторы целевых объектов обладают хорошей точностью и полнотой, будем поощрять выбор соответствующего детектора только за найденные на изображении объекты (то есть вознаграждение в очередной игре равно 1 при нахождении объекта на кадре и 0 в противном случае).
Теперь рассмотрим способ вычисления ценности действия. Формула, представленная в описании многорукого бандита хорошо подходит только для стационарных задач (когда система не меняется со временем). В нестационарных задачах более поздние вознаграждения обладают большим приоритетом, чем более ранние. Наиболее распространенный способ этого добиться состоит в использовании экспоненциального среднего. Тогда ценность действия a при получении очередного вознаграждения rk+1 определяется по следующей рекурсивной формуле:
где ? — размер шага (чем больше значение ?, тем больший вес в ценности действия имеет новое вознаграждение). С физической точки зрения параметр ? регулирует насколько быстро текущее действие становится жадным.
С учетом вышесказанного алгоритм адаптивного выбора детектора представим в виде следующей последовательности шагов.
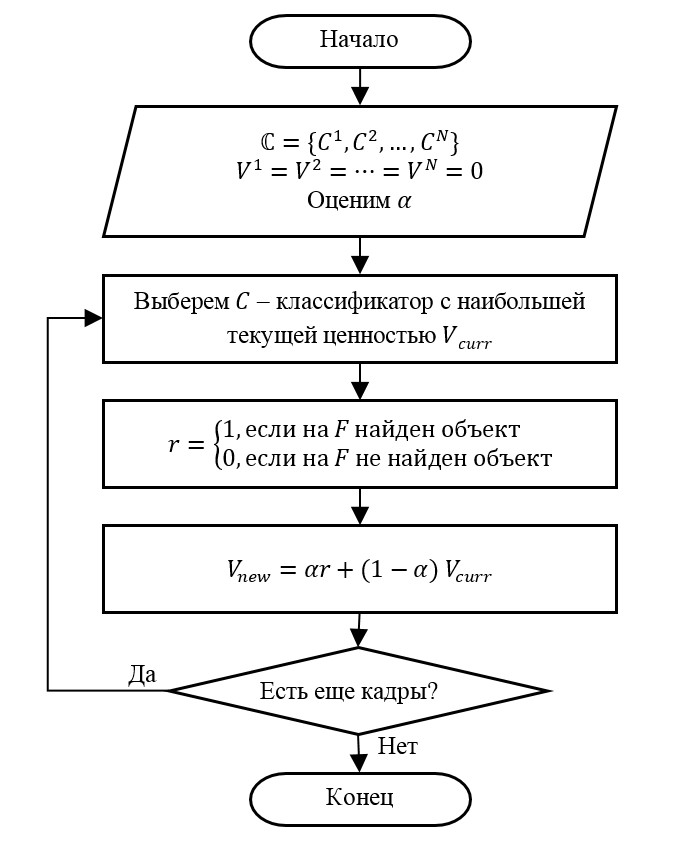
Шаг 1 (Инициализация). Пусть есть N детекторов. Зададим начальное значение ценности для детектора V1 = V2 = ? = VN = 0. Выберем значение параметра ?.
Шаг 2. Выберем детектор C с максимальным текущим значением ценности Vcurr. Если таких детекторов несколько, выберем один из них произвольным образом.
Шаг 3. Применим на очередном кадре F выбранный детектор C. Определим выигрыш детектора r в соответствии с введенным правилом (то есть r = 1, если на F есть объект).
Шаг 4. Обновим значение ценности Vnew для детектора C по представленной выше рекурсивной формуле.
Шаг 5. Перейдем на шаг 2, если есть еще кадры для поиска объектов. Иначе заканчиваем обработку.
Экспериментальные результаты
Как мы говорили в самом начале, данный алгоритм применялся нами для решения задачи определения типа банковской карточки в видеопотоке. Оператор предъявляет web-камере банковскую карту, а система распознавания должна определить тип карты по имеющемуся логотипу.

Для оценки качества предложенного алгоритма мы подготовили тестовый видеофрагмент, содержащий 29 представлений банковских карт следующих пяти типов: VISA, MasterCard, American Express, Discover и UnionPay. Общее количество кадров видеофрагмента составило 1116. Покадровый состав тестового видеофрагмента представлен в таблице. Сами детекторы логотипов платежных систем мы предварительно обучили с помощью метода Виолы и Джонса (естественно, на совершенно других изображениях).
| Тип объекта | Кол-во карт | Общее кол-во кадров |
|---|---|---|
| VISA | 16 | 302 |
| MasterCard | 8 | 139 |
| American Express | 2 | 37 |
| UnionPay | 1 | 17 |
| Discovery | 2 | 34 |
| Кадры без карты | - | 587 |
| ИТОГО | 29 | 1116 |
Эффективность предложенного алгоритма выбора детектора (АВД) оценивалась по сравнению с поочередным алгоритмом (обученные детекторы логотипов применяются к кадрам по очереди). Такой поочередный алгоритм вполне осмысленен и реализует идею ускорения детектирования за счет прореживания. В таблице представлено значение функционала качества Q, а также отношение функционала качества к общему числу обработанных кадров Qr для отдельных интервальных точек.
| Метод | 300 | 600 | 900 | 1116 |
|---|---|---|---|---|
| Поочередный | 191 (0.64) | 379 (0.63) | 547 (0.61) | 676 (0.61) |
| АВД | 216 (0.72) | 446 (0.74) | 682 (0.76) | 852 (0.76) |
Графическое представление представленных табличных данных изображено на следующем рисунке.

Несмотря на то, что описанный алгоритм выбора детектора обеспечивает лучшее качество детектирования по сравнению с поочередным методом, идеальное качество всё же не достигается. Отчасти это связано с собственными параметрами качества используемых каскадов Виолы и Джонса (определяемыми точностью и полнотой). Чтобы подтвердить это, мы провели эксперимент по одновременному применению всех детекторов логотипов к каждому кадру (конечно, не обращая в этом случае внимания на время). В результате этого эксперимента было получено максимально возможное значение функционала качества Q*=1030 (Qr*=0.92), что по сути говорит о необходимости обучения новых, более точных детекторов :-)
Заключение
В задачах поиска объектов в видеопотоке важное значение имеет скорость обработки отдельного кадра. Существуют задачи, для которых даже применение быстрых алгоритмов, таких как метод Виолы и Джонса, не обеспечивает необходимой скорости. В таких случаях иногда комбинирование различных способов машинного обучения (как то обучение по прецедентам и обучение с подкреплением) позволяет элегантно разрешить поставленную задачу, не прибегая к сверхоптимизации алгоритмов и внеплановому апгрейду железа.
Список использованной литературы
- Viola P., Jones M. Robust Real-time Object Detection // International Journal of Computer Vision. 2002.
- Саттон Р.С., Барто Э.Г. Обучение с подкреплением. М.: БИНОМ. Лаборатория знаний, 2012. 399 с.
- Усилин С.А. Использование метода преследования для повышения быстродействия алгоритма многоклассовой детекции объектов в видеопотоке каскадами Виолы-Джонса // Труды Института системного анализа Российской академии наук (ИСА РАН). 2017. № 1 (67). C. 75–82.
Поделиться с друзьями
babylon
Сами придумывают задачи и сами же их решают. Молодцы.Открытым остаётся вопрос — "Зачем?". Ясно, что распознавание объектов в ВП реализовать гораздо проще чем распознать тот же объект по одиночному кадру.