
Всем привет!
Меня зовут Александр Денисов. Я работаю в компании Naumen и отвечаю за документирование и локализацию программного продукта Naumen Contact Center (NCC).
В этой статье я расскажу о том, как у нас был автоматизирован процесс перевода документации с помощью нейродвижков без использования CAT-систем и каких-либо других инструментов перевода.
Немного о продукте Naumen Contact Center
Продукт Naumen Contact Center – это очень сложное программное обеспечение для организации контактных центров, который содержит:
30 000 – 40 000 строк интерфейса.
3 000 – 4 000 страниц документации.
Локализуем и переводим документацию на английский и немецкий языки.
Как чаще всего переводят документацию
Как обычно переводит документацию какая-либо более или менее крупная компания:
Обращается в бюро переводов, связывается с менеджером.
Если компания уже более или менее опытная, то она готовит глоссарий.
Отправляет менеджеру по E-mail глоссарий и тексты, которые нужно перевести.
Практически любое бюро переводов использует CAT-систему, в которую менеджер загружает тексты и глоссарий.
Дальше, либо переводчик сразу переводит тексты по предложениям, либо предварительно тексты переводятся привязанным нейродвижком.
Далее, в зависимости от требований к качеству, может выполняться вычитка.
В завершение, менеджер выгружает результаты перевода и отправляет компании-заказчику вместе с актом и счетом, и компания оплачивает работу.
На схеме этот процесс можно представить следующим образом.

Интерфейс переводчика в CAT-системе (Computer-Aided (Assisted) Translation) выглядит следующим образом:

В левой части можно увидеть, как все тексты в CAT-системе разбиваются по предложениям, в левой колонке – исходный текст, в правой – переведенный текст. В правой части можно увидеть, что для выделенной строки в глоссарии у нас есть, например, термин «Оператор», который должен переводиться как «Agent», а также есть термин «Проект», который должен переводиться как «Campaign». А еще есть такой проблемный термин, как «Обзвон», для которого в английском языке отсутствует нормальный перевод. В документации таких разработчиков решений для контактных центров, как Cisco или Avaya везде фигурирует сочетание «Outbound Dialing Campaign». И что интересно, что это сочетание «Outbound Dialing Campaign» содержит в себе слово «Campaign», что еще больше все осложняет. Т. о. у переводчика стоит непростая задача по выправлению всей этой терминологии в ручном режиме.
Проблема
Сначала мы переводили документацию с помощью бюро переводов на английский, частично на немецкий, потратили много денег. Но потом несколько лет не обновляли переводы, т. к. продажи не пошли. В итоге документация сильно устарела.
Но приходит партнер и говорит, что документация устарела, а продавать то ему как-то хочется. И вот в чем собственно проблема:
Средняя стоимость перевода – 2-3 рубля за слово.
250 слов на страницу.
3 000 – 4 000 страниц сложной технической документации.
2 языка – английский, немецкий.
Надо 3-6 миллионов рублей.
Сроки до полугода и выше.
Качество – еще надо проверять.
Но надо то все вчера, а денег уже никто не даст, клиентов то еще нет. Тем более, что один раз уже денег дали, а результата не было.

Решение
В данной ситуации выхода уже никакого не было, кроме как поставить вопрос, а нельзя ли все просто перевести нейродвижком? И забегая вперед скажу, что да – можно! И ниже я постараюсь объяснить почему для нас это стало возможным, и что у нас уже получилось.

Дак почему же перевод нейродвижком стал возможен?
Долгие годы нам говорили, что качество автоматического перевода все еще не дотягивает до необходимого, дак почему же уже стало можно:
Во-первых, качество нейродвижков с каждым годом становится все лучше, и на данный момент оно сопоставимо с качеством перевода среднего переводчика, да, где-то хуже, но где-то даже лучше.
А нам и не надо для наших целей супер-качество. Нам надо переводить техническую документацию, нам главное, чтобы с помощью нее можно было решить задачу. Мелкие шероховатости нас мало волнуют. Да и вспомните Microsoft, они уже давным-давно переводят свою документацию (качество, надо сказать у них ужасное, но тем не менее), если уж в Microsoft себе такое позволяют, то почему мы не можем. Да и на текущем этапе мы даже не знаем, будет ли нашу документацию кто-то читать или она отправится в стол.
А как переводят в бюро переводов? Все больше и больше бюро переводов также переводит нейродвижками. И чтобы это проверить, нужна независимая вычитка. Дак почему нам не сделать эту первоначальную работу самим, т. о. мы можем точно знать какое у нас качество и дальше уже принимать решения что с ним делать дальше.
Как я рассказывал выше, нам нужен глоссарий, который загружается в CAT-систему. С недавних пор движки перевода научились применять глоссарий налету и выдавать перевод с учетом глоссария, при этом CAT-системы еще не умеют передавать глоссарий в нейродвижок или еще только учатся делать это.
Т. о. было решено, что надо просто пробовать!
Конечно, сначала было интересно понять, какой выбрать нейродвижок, какой из них лучше. И я приступил к тестированию.
Выбор нейродвижка
Изначально было известно, что лучшим считается DeepL, но хотелось убедиться лично какой движок переводит лучше и какой лучше работает с глоссарием.
Сначала я просто протестировал движки, которые удалось подключить в CAT-системе и стало понятно, что там использовать глоссарий на стороне нейродвижка невозможно.
После этого я стал тестировать движки, которые умеют работать с глоссарием, выбрал 3 дивижка: PROMPT, Yandex и DeepL. Ниже привожу небольшую таблицу сравнения.
Yandex |
DeepL |
PROMT |
|
Тип использования |
Облако |
Облако |
Ставится внутри контура компании, сложно внедрять |
Работа с глоссарием |
Хорошо |
Отлично |
Хорошо, но глоссарий не применяется к глаголам |
Оплата |
Дешево, оплата по карте в рублях |
Дешево, есть сложность с оплатой из РФ |
Дорого внедрять, после внедрения бесплатно |
Сложность выбора еще была в том, что на момент начала тестирования DeepL не имел возможности применять глоссарий при переводе с русского на немецкий, поэтому изначально было принято решение делать двойной перевод с русского на английский Yandex-ом, а затем переводить с английского на немецкий с помощью DeepL. Но вскоре в DeepL появилась возможность применения глоссария с русского как на английский, так и на немецкий, и тестирование пришлось начинать сначала.
Почему глоссарий – это важно?
В первую очередь интересовал глоссарий, т. к. как я сказал выше, у нас к нему есть специфические требования и поэтому для нас это очень важно.
На изображении ниже можно увидеть пример применения глоссария нейродвижками. В верхней части пример перевода в CAT-системе без применения глоссария, а ниже перевод напрямую через API Yandex и DeepL.

Т. о. можно увидеть, что наше сочетание «проект обзвона» переводится следующим образом:
Без глоссария – «calling project».
Yandex с глоссарием – «outgoing outbound dialing campaign».
DeepL с глоссарием – «outbound dialing campaign».
Как можно заметить, Yandex не плохо умеет применять глоссарий, но в таких сложных случаях как у нас он по факту дублирует слова, что, конечно, необходимо выправлять вручную. Но, как видно, DeepL решает задачу на отлично! Такой же результат мы увидели и с таким сочетанием как «исходящий обзвон», DeepL справился лучше и с ним. Т. о. мы поняли, что DeepL для нас лучше.
Скорость перевода нейродвижком
Перевод нейродвижком – это очень быстро:
Вся документация переводится за ночь.
Еженедельные обновления занимают несколько минут.
Стоимость перевода нейродвижком
Перевод нейродвижком – это очень дешево. 2-3 рубля за слово превращаются в 0,003-0,004 рубля за слово:
Полный перевод: 2-3 миллиона рублей (с помощью бюро перевода) превращаются в 2 000 рублей нейродвижком.
Двухнедельное обновление – пара рублей.
Но что, если все же нужно отличное качество?
Предположим, что мы все перевели просто через API нейродвижка, но что если нам все же нужно повысить качество:
Тогда нам нужно сохранить все переводы и обеспечить себе возможность загрузки этих переводов в CAT-систему, чтобы отдать их на вычитку переводчику. Для этого переводы можно сохранить в XLIFF-файле.
Качество можно улучшать постепенно, например, по мере поступления замечаний. Для этого необходимо организовать обратную связь. В моем случае я обрабатываю замечания от партнера.
Изначально можно посмотреть, а какие из переведенных материалов должны быть качественными. Можно построить статистику по просмотру документации на исходном языке и сделать качественными только страницы с наибольшим просмотром.
Автоматизация процесса перевода
Вернемся к той схеме, что я приводил сначала. В итоге нам не нужно все взаимодействие с бюро переводов и CAT-системой.

А нужно лишь отправить текст через API в нейродвижок, получить перевод и сохранить его. Т. о., в качестве R&D был написан скрипт на Python, который выполняет следующие действия:
Выкачивает GIT-репозиторий в котором лежит проект с исходными текстами документации.
Выкачивает из GIT-репозитория XLIFF-файл с двуязычными текстами и загружает его в память (если это первый перевод, то файл пустой).
Выгружает по API из WebLate (инструмент, в котором мы делаем локализацию) XLIFF файлы, которые также могут быть полезны при переводе.
Весь исходный текст разбивается на параграфы. Для каждого параграфа:
- Проверяет есть ли перевод в XLIFF из WebLate. Если есть, подставляет.
- Проверяет есть ли перевод в XLIFF от нейродвижка. Если есть, подставляет.
- Если в сохраненных переводах ничего не найдено, то отправляет текст и глоссарий на перевод в нейродвижок. Полученные результаты подставляет в переводимый файл и сохраняет в XLIFF от нейродвижка.Сохраняет переводы в GIT-репозиторий.
На схеме это можно представить следующим образом.

После этого в одно и то же время на всех языках в автоматическом режиме может происходить сборка документации.
Немного о структуре проекта документации
Документация разрабатывается в MadCap Flare и структуру проекта примерно можно представить как на изображении ниже.

Каждый прямоугольник – это файл, который имеет определенное назначение:
Target – файл, который отвечает за сборку документации. Для каждого формата свой Target-файл, но к нему может быть привязан один и тот же TOC-файл.
TOC (Table of Content) – оглавление. Может иметь древовидную структуру и включать другие TOC-файлы, к оглавлению как листики к дереву крепятся HTML-файлы.
HTML – топики, которые содержат текст в формате HTML. HTML могут содержать сниппеты (Snippets), изображения (PNG-файлы) и переменные (Variables).
Snippets – маленькие кусочки текста в формате HTML. Могут встраиваться в большие HTML-файлы, а также содержать в себе другие сниппеты, переменные или изображения.
PNG – изображения (скриншоты или диаграммы).
Variables – XML-файлы со строками (переменными). Переменные могут содержать только не форматированный текст, а также содержать другую переменную. Предполагается, что переменная может динамически изменяться.
Скрипту перевода в качестве параметра указывается TOC-файл, он по цепочке выдергивает все тексты из всех файлов и переводит их.
Использование переменных со строками интерфейса
Нейродвижок не может угадать правильный перевод для элементов интерфейса. Как видно на изображении ниже, нейродвижок перевел название формы не так, как на скриншоте.
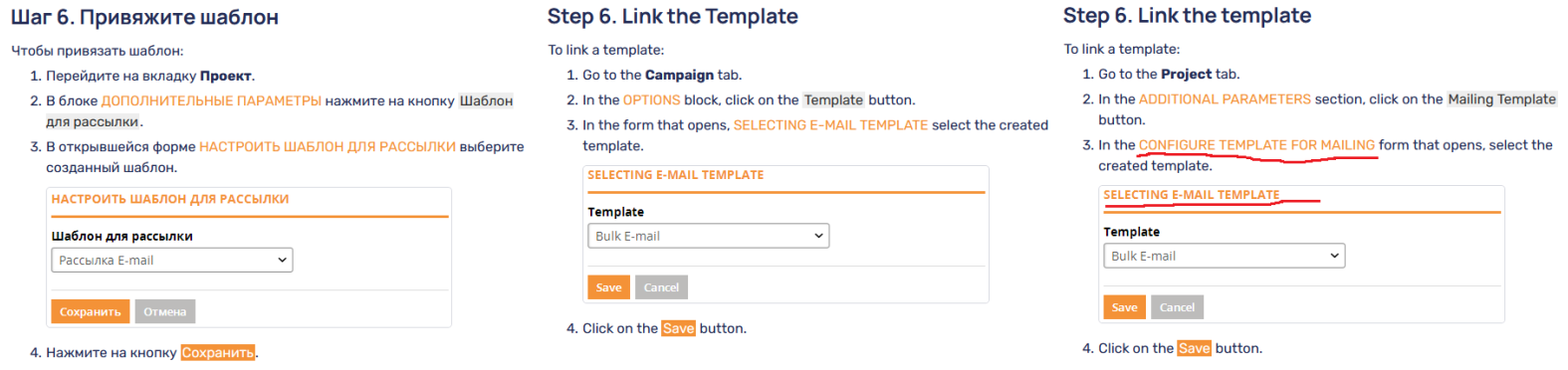
Для решения этой проблемы мы вместо текстов интерфейса используем переменные, которые получаем путем конвертации файлов ресурсов из репозитория разработки в формат переменных MadCap Flare.
HTML-код с переменной, в данном случае, выглядит следующим образом:
<p>В открывшейся форме <MadCap:variable name="PMS/outcallproject.setTemplate.form-title" class="PMSHeaderBlock" /> выберите созданный шаблон.</p>Т. о. тексты из интерфейса всегда соответствуют интерфейсу и скриншотам (если они, конечно, не устарели).
Непереводимые части строки
В процессе тестирования возникла проблема с тем, что разные названия сервисов, переменных, параметров и других слов в предложениях на английском может:
Влиять на контекст. Например, два одинаковых предложения, но содержащие разное название переменной могли переводиться по-разному, что не красиво, особенно тогда, когда предложения идут друг за другом, например в списке или таблице.
Сами эти английские названия могут портиться и становиться не валидными. Например, у названия переменной после перевода может поменяться регистр.
Для решения этой проблемы было решено все, что не должно переводиться, с помощью регулярных выражений, заменять на плейсхолдеры. Т. о. на перевод в нейродвижок отдается текст с плейсхолдерами, возвращается перевод с плейсхолдерами, а затем плейсхолдеры заменяются обратно:
<trans-unit id="61325d88-5203-11ee-acd9-6255c1ae6d7b">
<source>
В конфигурационном файле _plchldrid001_ для параметра _plchldrid003_ установлено значение по умолчанию _plchldrid005_ в семплах (см. раздел _plchldrid007_).
</source>
<target>
In the _plchldrid001_ configuration file, the _plchldrid003_ parameter is set to the default value _plchldrid005_ in samples (see section _plchldrid007_).
</target>
</trans-unit>А что еще можно сделать, когда перевод автоматизирован скриптом?
Теперь, когда перевод выполняет скрипт, встает вопрос, а что можно еще автоматизировать? Да все что угодно! Можно делать любые проверки и преобразования.

Например, как известно, в английском есть особые правила написания заголовков. Первая буква каждого слова должна быть большой. Не составило большого труда найти библиотеку и после перевода конвертировать тексты в тегах h1-h6 в формат заголовка. На изображении ниже видно, как перевод выглядит в CAT-системе и какой перевод получается автоматически после перевода скриптом ниже.

Побочные плюсы
В процессе перевода и при проверке результатов периодически находятся ошибки в исходных материалах:
Непонятный текст в переводе может быть просто по причине того, что он плохо написан в исходнике. В данном случае мы сразу делаем задачу на правку исходного текста и не трогаем перевод. После изменения исходного текста просто выполняем перевод повторно.
Неверный текст в переводе может быть по причине выбора неверных терминов или неверно переведенных терминов. В данном случае дорабатываем и правим терминологию в исходных текстах и пополняем глоссарий.
Иногда при разборе структуры проекта скрипт находит различные другие проблемы, которые мы также исправляем, например:
- Битые ссылки на топики, изображения, сниппеты и переменные.
- Использование «запрещенных» нами тегов в HTML.
Выводы
В качестве выводов можно сказать, что на 99% удалось автоматизировать перевод текста. Да, иногда возникают некоторые проблемы, которые приходится устранять в ручном режиме, но, в любом случае, все эти проблемы незначительны по сравнению с тем, какой объем работы выполняется автоматически.
На данный момент переведена подавляющая часть документации и ей уже пользуются партнеры.
Есть еще много идей что можно автоматизировать и что мы уже пытаемся делать, постараюсь рассказать об этом в следующих статьях.


dimitrii_z
А почему не рассматривали ChatGPT? Судя по ещё прошлогоднему исследованию (а тогда ещё не было 4.5 модели), работает достойно
avdenisov Автор
Спасибо за вопрос и за ссылку, очень интересно! Да, абсолютно согласен, ChatGPT переводит не хуже! И уже некоторое время пробую переводить с помощью него тоже. По факту в самом подходе ничего не меняется, меняется только API. Думаю позже смогу рассказать что в итоге получилось.