
В прошлом году на конференции AIJ 2023 мы представили первую версию OmniFusion — мультимодальной языковой модели (LLM), способной поддерживать визуальный диалог и отвечать на вопросы по картинкам. Спустя несколько месяцев мы готовы представить обновление — OmniFusion 1.1 — SoTA на ряде бенчмарков (среди моделей схожего размера) и, более того, модель хорошо справляется со сложными задачами и понимает русский язык! Самое главное — всё выкладываем в открытый доступ: веса и даже код обучения.

Ниже расскажем об особенностях модели, процессе обучения и примерах использования. В первую очередь остановимся на архитектуре, а потом отдельно расскажем о проделанных экспериментах как в части архитектурных трюков, так и о работе с данными. Ну а несколько интересных кейсов на английском и русском языках можно посмотреть на палитре ниже.



Архитектура
Принципиально OmniFusion 1.1 очень похож на предыдущую версию, да и в целом в области мультимодальных LLM сейчас все подходы формируются вокруг связки языковой модели и визуального энкодера через специальный обучаемый адаптер, который умеет отображать картиночные эмбеддинги в пространство текстовых эмбеддингов. Мы концентрировались на двух направлениях работы с визуальной модальностью, которые нашли отражение в соответствующих архитектурных особенностях. На рисунке ниже показаны два типа архитектуры: со смешиванием нескольких визуальных энкодеров (слева) и с упором на развитие единого визуального энкодера (справа).

Выбор визуального энкодера
К выбору «глаз» для мультимодальной модели нужно подойти серьёзно, поэтому мы провели исследования большого количества самых свежих моделей. Похоже, что самым важным критерием является размерность визуальных эмбеддингов и «нативное разрешение» энкодера — чем оно выше, тем лучше. Сравнение характеристик и результаты в таблице ниже. Мы остановились на модели InternViT, визуальные представления которой позволяют наилучшим образом описывать картинки в контексте метрик на валидационных VQA бенчмарках. Ниже в таблицах показаны параметры каждого визуального энкодера и показатели качества для основных бенчмарков при наличии только одного из исследуемых энкодеров: CLIP ViT-bigG, CLIP ViT-large, SigLIP-base и InternViT-6B. Следует отметить, что последний энкодер в списке существенно отличается по количеству параметров, и тем интереснее было рассмотреть его вклад в конечные метрики. Мы также хотели попробовать специфические надстройки над энкодерами на базе Q-Former, но к текущей версии статьи закончить не успели.

Типы адаптеров
На этот раз мы сделали акцент на изучении различных видов адаптеров и энкодеров, другим словами — способах извлечения визуальной информации из картинки и её агрегации с языковой моделью. Вот что мы попробовали в качестве адаптера:
Простой линейный слой
Multi Layer Perceptron (MLP)
Трансформерный слой
Послойный микс двух энкодеров через MLP с weight sharing
Микс энкодеров вдохновлён работой “From Clip to Dino: Visual Encoders Shout In Multi-modal Large Language Models”. Этот немного грязный трюк позволяет обогатить экспрессивность визуальных фичей, причём, почему-то простое суммирование спроецированных выходов двух энкодеров работает лучше, чем более хитрые способы вроде Attention-based пулинга или Q-Former для микса выходов двух энкодеров. Следуя оригинальной статье в качестве дополнительного энкодера, мы взяли DINO-v2, т.к. в отличие от CLIP он обучен полность в self-supervised режиме и его признаки могут обладать той информацией, которой не хватает основному энкодеру.
Последовательность визуальных эмбеддингов с каждого энкодера проходит через независимые layer-wise линейные слои для отображения в единое пространство. Затем происходит попарное сложение признаков двух энкодеров. После этого применяется нелинейность и, наконец, ещё одним линейным слоем присходит отображение в пространство текстовых эмбеддингов базовой языковой модели.

Нарезание картинки
Судя по всему разрешение картинки — это один из самых важных факторов, влияющих на качество модели. Поэтому следуя методологии LLaVA-NeXT, мы использовали адаптивное изменение размера изображений в соответствии с размером и нарезание картинки их на неперекрывающиеся секции в зависимости от разрешения визуального энкодера. Это дополнительно забустило метрики. К сожалению, этот подход приводит к увеличению количества визуальных токенов, что критически сказывается на скорости работы модели, поэтому мы провели эксперименты только с теми энкодерами, которые дают небольшое количество эмбеддингов на выходе, хотя задача компактного представления эмбеддингов для сокращения визуального контекста без потери содержательности эмбеддингов безусловно супер важная.
Датасеты и обучение
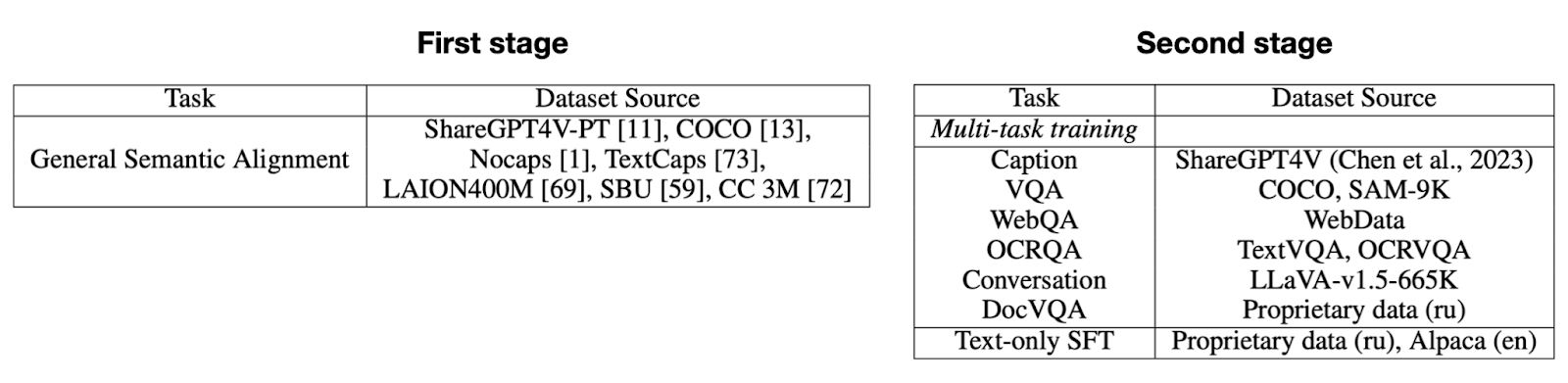
Обучение, как и раньше, происходит в два этапа:
Pretrain — размораживается только адаптер и эмбеддинги спецтокенов старта и конца модальности. На этом шаге датасет большой и может быть грязным.
Supervised fine-tuning (SFT) — обучение на небольшом и чистом сете инструктивных визуальных диалогов. При этом в ходе тюна дополнительно размораживается языковая модель.
Ниже показаны списки сетов, участвовавших в обеих стадиях обучения.
Здесь также нельзя не упомянуть бенчмарки, которые мы используем для оценки качества модели:
Science QA (full/img) — бенчмарки, состоящие из вопросов с несколькими вариантами ответов по разным научным темам: география, биология, химия, история и т.д. Сам набор данных отлично подходит для моделей на базе LLM, так как содержит набор вопросов только по тексту и с включением изображений, т.е. с помощью него можно оценить и способности самой языковой модели (их рост или падение в процессе мультимодального дообучения)
MMMU — бенчмарк для оценки междисциплираных способностей мультимодальных моделей. Содержит ряд задач, решение которых требует предметных знаний уровня университета (старшей школы)
GQA — бенчмарк с данными для проверки «пространственного мышления» моделей. В наборе содержатся вопросы, для ответа на которые нужно оценивать информацию об объектах, их расположению друг относительно друга, проводить рассуждения
POPE — бенчмарк для оценки галлюцинаций мультимодальных моделей в части интерпретации объектов на картинке (у человека, например, такие "галлюцинации" могут возникать из-за близорукости, когда четко объект вдалеке не видно, и он пытается додумать, что бы это могло быть)
VQAv2 — бенчмарк с вопросами на общую тему, оценивает способность модели понимать и обрабатывать визуальную информацию в общем домене
TextVQA — бенчмарк, содержащий задачи на обработку текстовой информации на изображении. Для успешного выполнения заданий модель должна распознать текст на изображении и провести рассуждение по этому тексту для ответа на вопрос
MM-Vet — бенчмарк проверяет целый комплекс способностей мультимодальных моделей: распознавание объектов, распознавание текста, фактологические знания, пространственное мышление, математические способности. Ответы моделей оцениваются с помощью GPT-4
Параметры обучения модели для обоих этапов показаны в таблице ниже.

Исследование компонент модели
Первым делом, мы конечно же оценили влияние визуального энкодера на качество ответов модели на бенчмарках. В таблице можно увидеть заметный отрыв большего по числу параметров энкодера InternViT-6B, при этом входное разрешение у него не самое большое.

На следующем шаге мы зафиксировали два энкодера CLIP VIT-L/14 и DinoV2 и проверили несколько вариантов смешивания эмбеддингов: от простой конкатенации перед передачей в адаптер до использования различных механик проецирования эмбеддингов. Из таблицы ниже видно, что лучшим методом оказался тот, который использует эмбеддинги всех слоев энкодеров и складывает их. Мы также заметили, что последний подход с multi-head attention оказался худшим с точки зрения скорости работы, да и по метрикам заметна серьезная просадка.

Следующий тип эксперимента был посвящён анализу качества при наращивании длины визуального контекста при нарезании картинки на фрагменты и энкодинге каждого из фрагментов в дополнение к энкодингу целой картинки при снижении разрешения до необходимого визуальному энкодеру. Здесь можно заметить, что нарезка даёт качественный буст и метрики близки к использованию одного 6B энкодера. Что более интересно, это эксперимент с добавлением специального сета RusDocVQA, который состоит из визуальных вопросов по документам — это дало прирост метрик даже на general бенчмарках.

Ну и конечно же, добавление специфических данных при обучении даёт буст метрик на соответствующих специфических бенчмарках (как будто могло быть иначе ?). Прирост метрик можно посмотреть в таблице ниже.

Сводная таблица экспериментов приведена ниже, где мы сравниваем разные варианты архитектур между собой и с существующими Open Source и проприетарными мультимодальными моделями. Отдельно подробно комментировать её необходимости нет, стоит просто детально посмотреть на метрики в каждой группе результатов, где жирным выделены SoTA значения, а нижним подчёркиванием top-2 результат.
В целом следует отметить, что OmniFusion на базе GigaChat-7B и визуальным экнкодером CLIP-ViT-L и нарезанием изображения даёт лучшие метрики среди всех 7B моделей и обходит даже некоторые более крупные мультимодальные решения.

Примеры работы модели





Заключение
В заключении хотелось отметить, что за несколько месяцев нам удалось провести широкий спектр экспериментов, бустануть в ряде метрик и наметить планы по развитию мультимодального направления: сжатие визуальных эмбеддингов, дополнительные надстройки над энкодерами, повышение метрик на специфических доменах (например, математические и логические задачи, анализ медицинских снимков и др.), ну и конечно, продолжить наращивать список обрабатываемых модальностей, например, видео и 3D. Интересно также посмотреть на различные варианты оптимизации базовой архитектуры с целью увеличения длины возможного обрабатываемого контекста. Обо всём этом обязательно расскажем в следующих обновлениях.
В остальном, выкладывая наши результаты в open source мы очень хотим мотивировать комьюнити помогать развивать модель, делать её более сильной и умной как на отдельных downstream задачах, так и на общих бенчмарках. Будем рады вашим пулл реквестам в репозиторий OmniFusion?
Технические детали можно прочитать в нашем тех репорте по ссылке.
Авторы
Обучением модели и экспериментальными исследованиями занималась научная группа FusionBrain Института AIRI при участии учёных и разработчиков из Sber AI и Sber Devices.
В работе над text-rich модальностью нам помогала команда SberDevices IDP, более подобно про их работу можно посмотреть тут.
Список авторов: Елизавета Гончарова, Антон Разжигаев, Матвей Михальчук, Максим Куркин, Ирина Абдуллаева, Матвей Скрипкин, Сергей Марков, Иван Оселедец, Денис Димитров и руководитель научной группы FusionBrain Андрей Кузнецов
Следите за новостями в каналах: CompleteAI, AbstractDL, Dendi Math&AI
Комментарии (21)

Kristaller486
10.04.2024 09:49+4Спасибо за работу. Её можно сконвертировать в GGUF?

kuznetsoff87 Автор
10.04.2024 09:49+1Думаю, что это отличная задача для комьюнити:)
Kristaller486
10.04.2024 09:49Тут проблема в том, что вероятно ggml/llama.cpp не поддерживает проджектор от OmniFusion


prohodil_mimo
10.04.2024 09:49+1К чёрту подробности - может ли она по ссылке или по загруженной пдфке прочесть содержимое и использовать эту информацию в ответах?
kuznetsoff87 Автор
10.04.2024 09:49+1OCR опция будет чуть позже, сейчас как раз активно доучиваем в сегменте анализа документов/сканов/графиков и тд
prohodil_mimo
10.04.2024 09:49+2Тут не столько про оцр, сколько про возможность хорошо использовать предоставленную информацию в ответах на вопросы. Например, дать ей пусть даже в виде родного текстового сообщения инструкцию по пылесосу - и чтобы она потом могла ответить, как часто менять мешок, что означает большая круглая крутилка сверху и т.п.
kuznetsoff87 Автор
10.04.2024 09:49+2Понял теперь! Отличный кейс, добавил в лог

andretisch
10.04.2024 09:49Так разве не для этого обучают модель? RAG именно для этого и используют. Дают промт, дают текст (инструкцию), генерируется ответ. Если модель не сможет разобраться в инструкции от пылесоса это будет эпично)))
kuznetsoff87 Автор
10.04.2024 09:49+1Первично учим картинки понимать и уметь оперировать максимально подробно ими. RAG - это бонус
prohodil_mimo
10.04.2024 09:49Я не очень разбираюсь в этих терминологиях. Понимать картинки и оперировать ими максимально подробно - это включает в себя оперирование информацией с той же картинки или не включает? Про оцр понял, текст пока не возьмёт с картинки. Но если передать инструкцию к ПО в виде скриншотов, где красными квадратиками и стрелочками обозначено, куда тыкать и что получится, оно пока тоже не сможет по ним подсказать, что и куда тыкать пользователю, который спросит - что мне и куда тыкать, чтобы вот это?
andretisch
10.04.2024 09:49Так попробуй. Она ж в доступе. Но я бы сконвертировал в картинку
prohodil_mimo
10.04.2024 09:49Миллионы лет мои предки учились активно использовать чужой опыт и побеждали из-за этого в эволюционной схватке не для того, чтобы я потом, как слабак и нытик сам разворачивал нейросеть, чтобы ответить на свои вопросы!
andretisch
10.04.2024 09:49Так и они отдали в открытый доступ, чтоб под каждого не настраивать сервер. Я думаю в миллионах лет опыта можно найти полчасика на освоение colab от гугл. Но в целом да, было-бы удобнее если был хотя бы ТГ бот

StanSemenoff
10.04.2024 09:49Сколько времени занимает обучение и на каких мощностях?
kuznetsoff87 Автор
10.04.2024 09:49+12-3 A100, по 1-2 дня на каждую фазу обучения. Ну и в параллели несколько экспериментов обычно ставится под разные архитектурные особенности.

d00m911
10.04.2024 09:49+3В какое же прекрасное время бы живём, выходят прекрасные бесплатные модели - эта, Command r+, Llama 3 уже на следующей неделе будет, говорят... и ведь технология становится все лучше и лучше! Это как жить в эпоху промышленной революции, когда придумали станки, но круче)

RealFSA
10.04.2024 09:49Отличная сеть. Надеемся на продолжение. Но есть вопрос. Можно ли при запросе о наличии объекта на картинке, получить квадрат с позицией объекта на изображении?
mst_72
Latex формула на последней картинке сбилась
Razant
Вроде это не баг а фича, т.к. мы хотели показать как именно она распозналась
kuznetsoff87 Автор
Именно так! Черипики идеальные любой может показать