
Автор статьи: Олег Блохин
Выпускник OTUS
В ходе поиска темы проектной работы, которой должен был завершиться курс Machine Learning. Professional, я решил поэкспериментировать с данными о фильмах, мультфильмах, сериалах и прочей схожей продукции. Немного сожалея, что времени смотреть кинопродукцию у меня почти нет, приступим.
Сбор данных
Попробуем взять данные (описания фильмов) с сайта Кинопоиск, а затем по описанию фильма определить жанр картины.
Структура адресной строки страницы со списком фильмов оказалась тривиальной:

А страница фильма выглядит тоже неплохо:
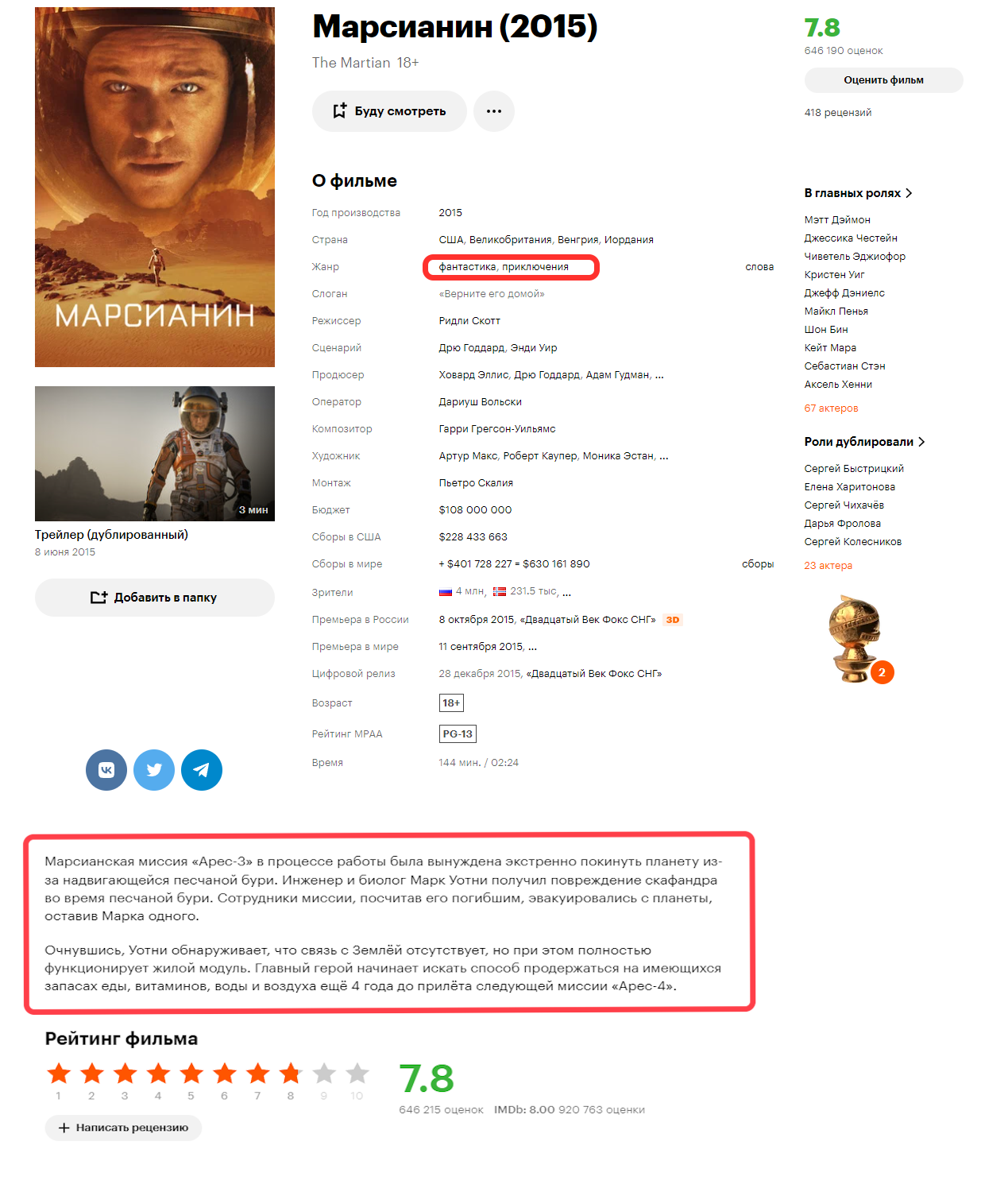
Немного потрудившись, был написан нехитрый алгоритм сбора данных.
Исходный код
import numpy as np # Библиотека для матриц, векторов и линала
import pandas as pd # Библиотека для табличек
import time # Библиотека для времени
from selenium import webdriver
browser = webdriver.Firefox()
time.sleep(0.3)
browser.implicitly_wait(0.3)
from bs4 import BeautifulSoup
from lxml import etree
from tqdm.notebook import tqdm
def get_dom(page_link):
browser.get(page_link)
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
return etree.HTML(str(soup))
def get_listpage_links(page_no):
# page_link = f'https://www.kinopoisk.ru/lists/movies/year--2010-2019/?page={page_no}'
page_link = f'https://www.kinopoisk.ru/lists/movies/year--2021/?page={page_no}'
dom = get_dom(page_link)
return dom.xpath("body//div[@data-tid='8a6cbb06']/a[@href]/@href")
def get_moviepage_info(movie_link):
page_link = 'https://www.kinopoisk.ru' + movie_link
dom = get_dom(page_link)
elem = dom.xpath("body//div/span//span[@data-tid='939058a8']")
rating = elem[0].text if elem else ''
elem = dom.xpath("body//div//h1[@data-tid='f22e0093']/span")
name = elem[0].text if elem else ''
features = {}
elem = dom.xpath("body//div/div[@data-test-id='encyclopedic-table' and @data-tid='bd126b5e']")[0]
for child in elem.getchildren():
#print(etree.tostring(child))
feature = child.xpath('div[1]')[0].text
ahrefs = child.xpath('div[position()>1]//a[text()] | div[position()>1]//div[text() and not(*)] | div[position()>1]//span[text()]')
values = [ahr.text for ahr in ahrefs]
features[feature] = values
elem = dom.xpath("body//div/p[text() and not(*) and @data-tid='bfd38da2']")
short_descr = elem[0].text if elem else ''
elem = dom.xpath("body//div/p[text() and not(*) and @data-tid='bbb11238']")
descr = ' '.join([x.text for x in elem])
return (name, rating, short_descr, descr, features)
_df = pd.DataFrame(columns=['id', 'type', 'name', 'rating', 'short_descr', 'descr', 'features'])
for page_number in tqdm(range(1, 912), desc='List pages'):
try:
links = get_listpage_links(page_number)
_df = pd.DataFrame(columns=['id', 'type', 'name', 'rating', 'short_descr', 'descr', 'features'])
for movie_link in links:
movie_id = movie_link.split('/')[1:3]
name, rating, short_descr, descr, features = get_moviepage_info(movie_link)
data_row = {'id':movie_id[1], 'type':movie_id[0], 'name':name, 'rating':rating, 'short_descr':short_descr, 'descr':descr, 'features': features}
_df = pd.concat([_df, pd.DataFrame([data_row])], ignore_index=True)
with open('kinopoisk_2010-2019.csv', 'a') as f:
_df.to_csv(f, mode='a', header=f.tell()==0, index=False)
except Exception as err:
print(f"Unexpected {err=}, {type(err)=}")
Итогом работы алгоритма (если честно, то просто надоело ждать) стали свыше 50 тысяч записей о фильмах. Нам, для нашего исследования необходимы только описание и список ассоциированных с фильмов жанров.

Посмотрев на количество представителей каждого из имеющихся жанров, становится понятно, что мы имеем крайне несбалансированную выборку по классам:
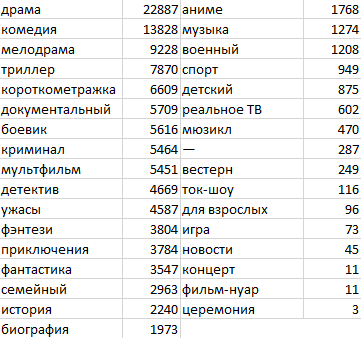
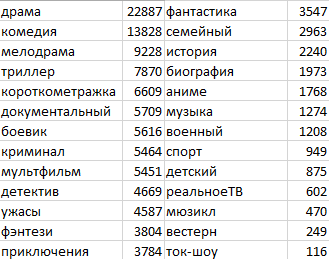
Избавимся от тех жанров, где количество представителей меньше 100, а заодно уберем непонятный жанр "--". В результате такой фильтрации для экспериментов осталось 26 жанров и более 53 тысяч фильмов. Должно хватить :)
Изначально я использовал алгоритмы multi-class классификации, когда каждой записи присваивается единственная метка класса. При таком подходе значения метрик получались достаточно скромными (что интуитивно понятно, зачастую даже зрителю-человеку непросто понять, чего в картине больше - драмы, комедии или даже мелодрамы), поэтому не буду тратить время читателей на это. К тому же, с моей точки зрения, жанры, представленные на вышеупомянутом ресурсе, во многих случаях не являются классами в классическом математическом понимании задачи классификации: боевик может быть представлен в мультипликационной форме (а "мультфильм" и "боевик" - разные жанры в аннотации кинопоиска), а аниме - и вовсе всегда является мультфильмом (да простят мне мое невежество любители данного жанра, если я ошибаюсь :) ). В общем, примем как данность, что модель, когда каждый фильм характеризуется принадлежностью лишь к одному жанру, слишком упрощает реальность.
Будем решать задачу multilabel классификации, когда одному фильму присваиваются одна или более меток разных жанров.
Технически подготовить данные для решения этой задачи оказалось достаточно просто с помощью библиотеке sklearn. В нашем случае в DataFrame (pandas.DataFrame) была создана колонка genre_multi, которая содержала разделенные запятой названия жанров (к примеру "драма,криминал,биография,комедия"). Следующий код добавляет колонки, названия которых совпадают с названием жанра-класса, и содержат нули или единички, в зависимости от того, указан ли конкретный жанр для картины, или нет.
Исходный код
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
mlb_result = mlb.fit_transform([str(data.loc[i,'genre_multi']).split(',') for i in range(len(data))])
data = pd.concat([data, pd.DataFrame(mlb_result, columns = list(mlb.classes_))], axis=1)
target_strings = mlb.classes_
Результат работы этого кода выглядит примерно так:
name |
descr |
lemmatized_descr |
genre_multi |
аниме |
биография |
боевик |
вестерн |
военный |
детектив |
... |
мюзикл |
приключения |
реальное ТВ |
семейный |
спорт |
ток-шоу |
триллер |
ужасы |
фантастика |
фэнтези |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1+1 (2011) |
Пострадав в результате несчастного случая, бог... |
пострадать результат несчастный случай богатый... |
драма,комедия,биография |
0 |
1 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Джентльмены (2019) |
Один ушлый американец ещё со студенческих лет ... |
ушлый американец студенческий год приторговыва... |
криминал,комедия,боевик |
0 |
0 |
1 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Волк с Уолл-стрит (2013) |
1987 год. Джордан Белфорт становится брокером ... |
год джордан белфорт становиться брокер успешны... |
драма,криминал,биография,комедия |
0 |
1 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Разделение данных на обучающую и тестовую выборки
Одна из первых сложностей, которая неизбежно возникает при попытке разделить данные на обучающую и тестовую выборки - огромное количество вариантов "меток": при multilabel-классификации мы пытаемся предсказать не просто метку класса, а вектор из нулей и единичек длины N, где N - количество жанров в нашем случае. В нашем случае количество теоретически возможных исходов равно 226, что многократно превышает размер всех наших данных.
Стандартный метод train_test_split с опцией stratify из sklearn.model_selection ожидаемо не справился с этой задачей. Поиск по всемирной сети подсказал следующий вариант, основанный на статье 2011 года:
Исходный код
from iterstrat.ml_stratifiers import MultilabelStratifiedShuffleSplit
from sklearn.utils import indexable, _safe_indexing
from sklearn.utils.validation import _num_samples
from sklearn.model_selection._split import _validate_shuffle_split
from itertools import chain
def multilabel_train_test_split(*arrays,
test_size=None,
train_size=None,
random_state=None,
shuffle=True,
stratify=None):
"""
Train test split for multilabel classification. Uses the algorithm from:
'Sechidis K., Tsoumakas G., Vlahavas I. (2011) On the Stratification of Multi-Label Data'.
"""
if stratify is None:
return train_test_split(*arrays, test_size=test_size,train_size=train_size,
random_state=random_state, stratify=None, shuffle=shuffle)
assert shuffle, "Stratified train/test split is not implemented for shuffle=False"
n_arrays = len(arrays)
arrays = indexable(*arrays)
n_samples = _num_samples(arrays[0])
n_train, n_test = _validate_shuffle_split(
n_samples, test_size, train_size, default_test_size=0.25
)
cv = MultilabelStratifiedShuffleSplit(test_size=n_test, train_size=n_train, random_state=random_state)
train, test = next(cv.split(X=arrays[0], y=stratify))
return list(
chain.from_iterable(
(_safe_indexing(a, train), _safe_indexing(a, test)) for a in arrays
)
)
Все приведенные в дальнейшем отчеты о результатах классификации будут приводиться на одной и той же тестовой выборке, размер которой составляет 20% от всех имеющихся данных.
Классические методы
Классические методы работают с предварительно обработанными данными. Использовалась стандартная техника лемматизации, единственная особенность - добавлено стоп-слово "фильм".
Исходный код
import nltk
nltk.download('stopwords')
stop_words = nltk.corpus.stopwords.words('russian')
stop_words.append('фильм')
#word_tokenizer = nltk.WordPunctTokenizer()
import re
regex = re.compile(r'[А-Яа-яA-zёЁ-]+')
def words_only(text, regex=regex):
try:
return " ".join(regex.findall(text)).lower()
except:
return ""
from pymystem3 import Mystem
from string import punctuation
mystem = Mystem()
#Preprocess function
def preprocess_text(text):
text = words_only(text)
tokens = mystem.lemmatize(text.lower())
tokens = [token for token in tokens if token not in stop_words\
and token != " " \
and token.strip() not in punctuation]
text = " ".join(tokens)
return textЛогистическая регрессия и TF-IDF
Для начала была обучена модель логистической регрессии, при этом векторизация текстов производилась методом TF-IDF. Multilabel классификация достигается путем "оборачивания" стандартной модели из sklearn в стандартный же MultiOutputClassifier из все той же библиотеки sklearn. Объединение всех этих компонентов в единый pipeline позволило произвести подбор гиперпараметров одновременно и для векторизатора, и самой модели логистической регрессии. Удобно!
Исходный код
pipe = Pipeline([
('tfidf', TfidfVectorizer(max_features=1700, min_df=0.0011, max_df=0.35, norm='l2')),
('logregr', MultiOutputClassifier(estimator= LogisticRegression(max_iter=10000, class_weight='balanced', multi_class='multinomial', C=0.009, penalty='l2'))),
])
pipe.fit(train_texts, train_y)
pred_y = pipe.predict(test_texts)
print(classification_report(y_true=test_y, y_pred=pred_y, target_names=target_strings))
Отчет о классификации представлен ниже:
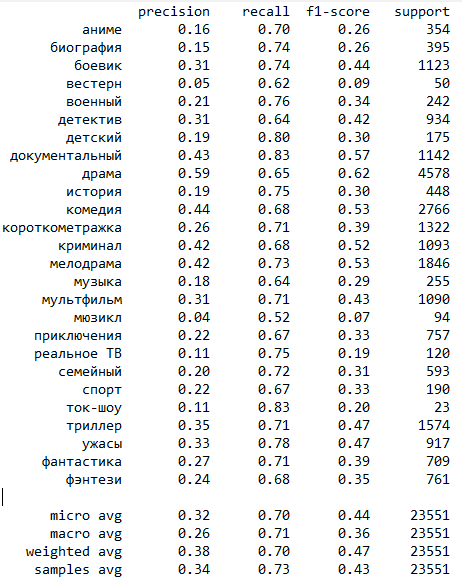
Забегая немного вперед, результаты метрики recall у данной модели оказались самыми высокими среди всех моделей, поучаствовавших в эксперименте.
Да и в целом - очевидно, что результаты определения жанра моделью гораздо лучше, нежели просто случайный выбор.
Catboost + TF-IDF
Аналогично поступим с Catboost. Хотя Catboost сам "умеет в multilabel классификацию", мы пойдем другим путем (зачем мы так делаем - станет ясно чуть позже): точно так же "завернем" CatBoostClassifier в MultiOutputClassifier. Заодно посмотрим, как работает multilabel классификация в реализации Catboost. Забегая вперед: результаты классификации отличались мало, зато с MultiOutputClassifier алгоритм сработал на CPU за 89 минут против 150 минут средствами multilabel классификации Catboost.
Исходный код с MultiOutputClassifier
from catboost import CatBoostClassifier
pipe2 = Pipeline([
('tfidf', TfidfVectorizer(max_features=1700, min_df=0.0031, max_df=0.4, norm='l2')),
('gboost', MultiOutputClassifier(estimator= CatBoostClassifier(task_type='CPU', verbose=False))),
])
pipe2.fit(train_texts, train_y)
pred_y = pipe2.predict(test_texts)
print(classification_report(y_true=test_y, y_pred=pred_y, target_names=target_strings))Исходный код без MultiOutputClassifier
pipe3 = Pipeline([
('tfidf', TfidfVectorizer(max_features=1700, min_df=0.0031, max_df=0.4, norm='l2')),
('gboost', CatBoostClassifier(task_type='CPU', loss_function='MultiLogloss', class_names=target_strings, verbose=False)),
])
pipe3.fit(train_texts, train_y)
pred_y = pipe3.predict(test_texts)
print(classification_report(y_true=test_y, y_pred=pred_y, target_names=target_strings))Результаты классификации Catboost с MultiOutputClassifier :
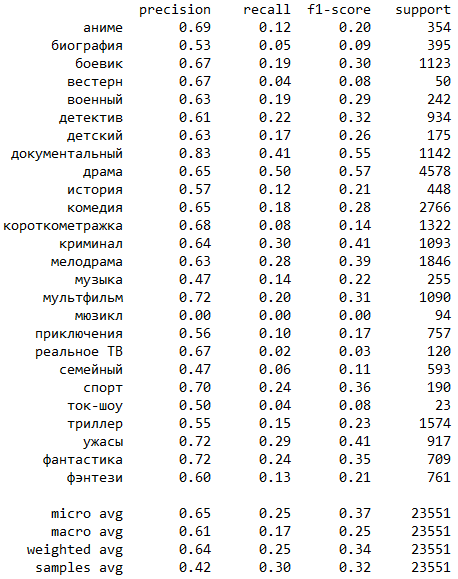
Результаты классификации Catboost без MultiOutputClassifier :
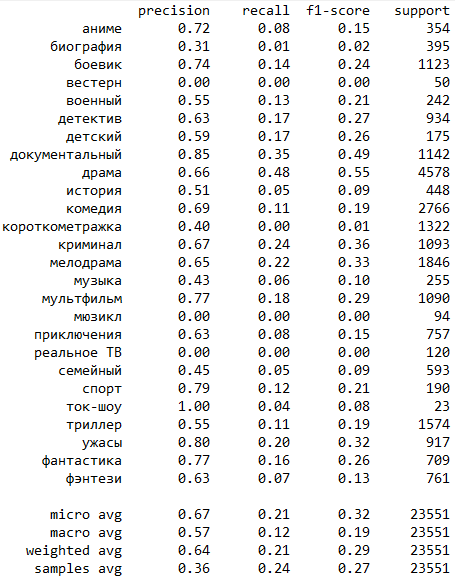
Можно заметить, что у Catboost уклон скорее в сторону метрики precision, а метрика recall сильно проигрывает результатам логистической регрессии.
Примеры характерных слов
Теперь настало время объяснить, зачем мне был нужен MultiOutputClassifier даже для градиентного бустинга: таким образом можно извлечь из модели слова, характерные для конкретного жанра. Что мы сейчас и проделаем. А на результаты посмотрим в виде облаков слов :)
Исходный код
import matplotlib.pyplot as plt
from wordcloud import WordCloud
def gen_wordcloud(words, importances):
d = {}
for i, word in enumerate(words):
d[word] = abs(importances[i])
wordcloud = WordCloud()
wordcloud.generate_from_frequencies(frequencies=d)
return wordcloud
for idx, x in enumerate(target_strings):
c1 = pipe['logregr'].estimators_[idx].coef_[0]
words1 = pipe['tfidf'].get_feature_names_out()
wc1 = gen_wordcloud(words1, c1)
c2 = pipe2['gboost'].estimators_[idx].feature_importances_
words2 = pipe2['tfidf'].get_feature_names_out()
wc2 = gen_wordcloud(words2, c2)
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 10))
ax1.imshow(wc1, interpolation="bilinear")
ax1.set_title(f'Log regr - {x}')
ax1.axis('off')
ax2.imshow(wc2, interpolation="bilinear")
ax2.set_title(f'Catboost - {x}')
ax2.axis('off')
plt.tight_layout()


Остальные 23 жанра























На мой субъективный взгляд разительнее всего для логистической регрессии и Catboost отличаются характерные слова для жанра "драма", наиболее богато представленного в наших данных.
На этом закончим эксперименты с классическими моделями, вернемся к ним лишь ненадолго в конце статьи, когда будем сравнивать их результаты с результатом трансформерных моделей.
Трансформерные модели
Кстати о них, то бишь о трансформерных моделях. Попробуем применить технику fine-tuning к предобученным трансформерным NLP моделям, с целью решить нашу задачу определения жанра фильма по описанию.
Эксперимент был проведен на следующих предобученных моделях с ресурса huggingface:
Трансформерные модели работают в связке с собственными векторизаторами (tokenizers). Исходный код токенизации текстов приведен ниже.
Исходный код
from transformers import BertTokenizer, AutoTokenizer
selected_model = 'ai-forever/ruBert-base'
# Load the tokenizer.
tokenizer = AutoTokenizer.from_pretrained(selected_model)
from torch.utils.data import TensorDataset
def make_dataset(texts, labels):
# Tokenize all of the sentences and map the tokens to thier word IDs.
input_ids = []
attention_masks = []
token_type_ids = []
# For every sentence...
for sent in texts:
# `encode_plus` will:
# (1) Tokenize the sentence.
# (2) Prepend the `[CLS]` token to the start.
# (3) Append the `[SEP]` token to the end.
# (4) Map tokens to their IDs.
# (5) Pad or truncate the sentence to `max_length`
# (6) Create attention masks for [PAD] tokens.
encoded_dict = tokenizer.encode_plus(
sent, # Sentence to encode.
add_special_tokens = True, # Add '[CLS]' and '[SEP]'
max_length = 500, # Pad & truncate all sentences.
padding='max_length',
return_attention_mask = True, # Construct attn. masks.
return_tensors = 'pt', # Return pytorch tensors.
truncation=True,
return_token_type_ids=True
)
# Add the encoded sentence to the list.
input_ids.append(encoded_dict['input_ids'])
token_type_ids.append(encoded_dict['token_type_ids'])
# And its attention mask (simply differentiates padding from non-padding).
attention_masks.append(encoded_dict['attention_mask'])
# Convert the lists into tensors.
input_ids = torch.cat(input_ids, dim=0)
token_type_ids = torch.cat(token_type_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels.values)
dataset = TensorDataset(input_ids, token_type_ids, attention_masks, labels)
return datasetБиблиотека fransformers предоставляет набор классов, которые дооснащают модель инструментами решения стандартных задач. В частности, для решения нашей задачи подходит класс AutoModelForSequenceClassification. С помощью параметра problem_type="multi_label_classification" указываем, что нас интересует именно multilabel классификация. В этом случае будет использована следующая функция потерь: BCEWithLogitsLoss.
Исходный код
import transformers
model = transformers.AutoModelForSequenceClassification.from_pretrained(
selected_model,
problem_type="multi_label_classification",
num_labels = 26, # The number of output labels--2 for binary classification.
# You can increase this for multi-class tasks.
output_attentions = False, # Whether the model returns attentions weights.
output_hidden_states = False, # Whether the model returns all hidden-states.
)Далее было произведено стандартное обучение нейронной сети. Чтобы отслеживать метрки, меняющеся по ходу обучения, я подключил прекрасную утилиту tensorboard. Графики, приведенные ниже, получены именно с помощью него.
Исходный код
from torch.utils.tensorboard import SummaryWriter
from sklearn import metrics
def log_metrics(writer, loss, outputs, targets, postfix):
print(outputs)
outputs = np.array(outputs)
predictions = np.zeros(outputs.shape)
predictions[np.where(outputs >= 0.5)] = 1
outputs = predictions
accuracy = metrics.accuracy_score(targets, outputs)
f1_score_micro = metrics.f1_score(targets, outputs, average='micro')
f1_score_macro = metrics.f1_score(targets, outputs, average='macro')
recall_score_micro = metrics.recall_score(targets, outputs, average='micro')
recall_score_macro = metrics.recall_score(targets, outputs, average='macro')
precision_score_micro = metrics.precision_score(targets, outputs, average='micro', zero_division=0.0)
precision_score_macro = metrics.precision_score(targets, outputs, average='macro', zero_division=0.0)
writer.add_scalar(f'Loss/{postfix}', loss, epoch)
writer.add_scalar(f'Accuracy/{postfix}', accuracy, epoch)
writer.add_scalar(f'F1 (Micro)/{postfix}', f1_score_micro, epoch)
writer.add_scalar(f'F1 (Macro)/{postfix}', f1_score_macro, epoch)
writer.add_scalar(f'Recall (Micro)/{postfix}', recall_score_micro, epoch)
writer.add_scalar(f'Recall (Macro)/{postfix}', recall_score_macro, epoch)
writer.add_scalar(f'Precision (Micro)/{postfix}', precision_score_micro, epoch)
writer.add_scalar(f'Precision (Macro)/{postfix}', precision_score_macro, epoch)Обучение сети произведено стандарнтым способом. Посколько в моем распоряжении имелся компьютер с видеокартой NVIDIA GeForce RTX 2080 Ti (12 GB), обучение выполнялось с использование GPU. При этом для разных моделей приходилось использовать разные размеры batch_size, а время достижения минимума функции потерь различась в разы. Эти данные для удобства восприятия я собрал в табличке ниже.
Исходный код
optimizer = torch.optim.AdamW(model.parameters(),
lr = 2e-5, # args.learning_rate - default is 5e-5, our notebook had 2e-5
eps = 1e-8 # args.adam_epsilon - default is 1e-8.
)
from transformers import get_linear_schedule_with_warmup
# Number of training epochs. The BERT authors recommend between 2 and 4.
# We chose to run for 4, but we'll see later that this may be over-fitting the
# training data.
epochs = model_setup[selected_model]['epochs']
# Total number of training steps is [number of batches] x [number of epochs].
# (Note that this is not the same as the number of training samples).
total_steps = len(train_dataloader) * epochs
# Create the learning rate scheduler.
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0, # Default value in run_glue.py
num_training_steps = total_steps)
from tqdm import tqdm
def train(epoch):
# print(f'Epoch {epoch+1} training started.')
total_train_loss = 0
model.train()
fin_targets=[]
fin_outputs=[]
with tqdm(train_dataloader, unit="batch") as tepoch:
for data in tepoch:
tepoch.set_description(f"Epoch {epoch+1}")
ids = data[0].to(device, dtype = torch.long)
mask = data[2].to(device, dtype = torch.long)
token_type_ids = data[1].to(device, dtype = torch.long)
targets = data[3].to(device, dtype = torch.float)
res = model(ids,
token_type_ids=None,
attention_mask=mask,
labels=targets)
loss = res['loss']
logits = res['logits']
optimizer.zero_grad()
total_train_loss += loss.item()
fin_targets.extend(targets.cpu().detach().numpy().tolist())
fin_outputs.extend(torch.sigmoid(logits).cpu().detach().numpy().tolist())
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
tepoch.set_postfix(loss=loss.item())
return total_train_loss / len(train_dataloader), fin_outputs, fin_targets
def validate(epoch):
model.eval()
fin_targets=[]
fin_outputs=[]
total_loss = 0.0
with torch.no_grad():
for step, data in enumerate(test_dataloader, 0):
ids = data[0].to(device, dtype = torch.long)
mask = data[2].to(device, dtype = torch.long)
token_type_ids = data[1].to(device, dtype = torch.long)
targets = data[3].to(device, dtype = torch.float)
res = model(ids,
token_type_ids=None,
attention_mask=mask,
labels=targets)
loss = res['loss']
logits = res['logits']
total_loss += loss.item()
fin_targets.extend(targets.cpu().detach().numpy().tolist())
fin_outputs.extend(torch.sigmoid(logits).cpu().detach().numpy().tolist())
return total_loss/len(test_dataloader), fin_outputs, fin_targets
writer = SummaryWriter(comment= '-' + selected_model.replace('/', '-'))
for epoch in range(epochs):
avg_train_loss, outputs, targets = train(epoch)
log_metrics(writer, avg_train_loss, outputs, targets, 'train')
avg_val_loss, outputs, targets = validate(epoch)
log_metrics(writer, avg_val_loss, outputs, targets, 'val')А теперь давайте посмотрим на графики. Для удобства я привел рядом "легенду", по которой нетрудно догадаться, к какой модели относятся графики.Начнем с функции потерь.
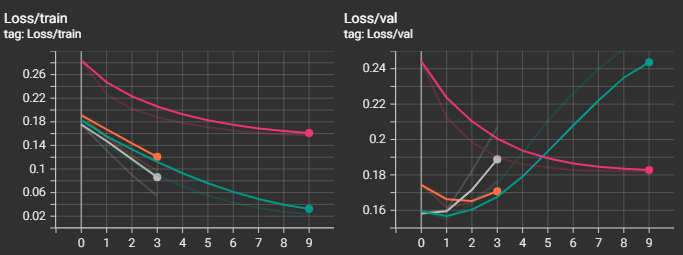
Видно, что наилучший результ получился у "среднеразмерной" модели "ai-forever/ruBert-base". "cointegrated/rubert-tiny2" остался далеко позади от победителя, что и понятно. Интересно, что "большие" модели "ai-forever/ruBert-large" и "ai-forever/ruRoberta-large" уступили в качестве базовой модели. В случае с "ai-forever/ruBert-large" это вызвано, скорее всего, не самыми точными параметрами обучения, и, к примеру, снижение скорости обучения могло бы вывести эту модель в лидеры.
Посмотрим также на прочие графики. Не зря же я тратил на них время :)
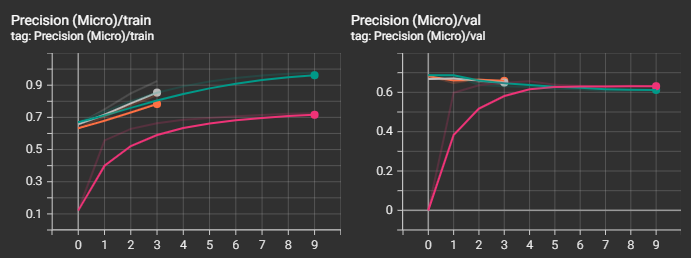
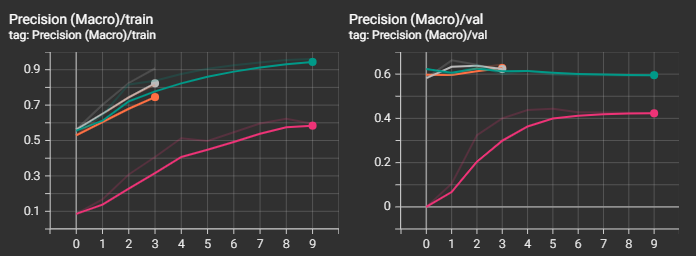
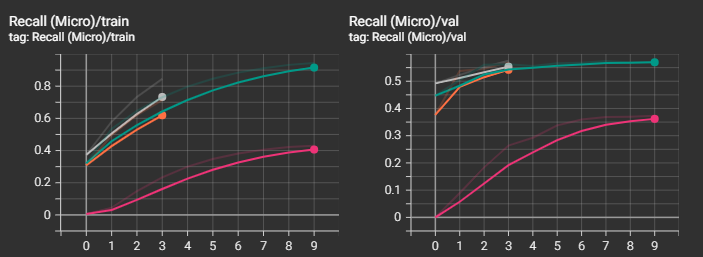
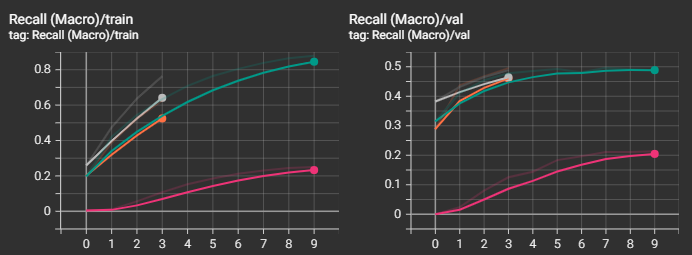
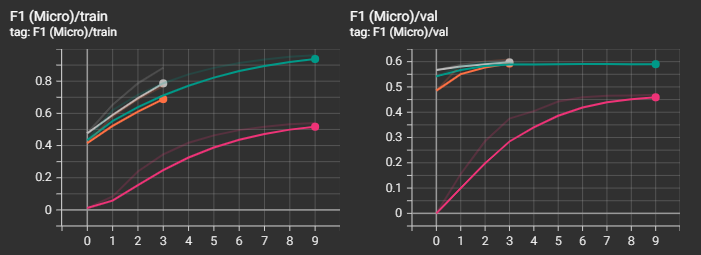
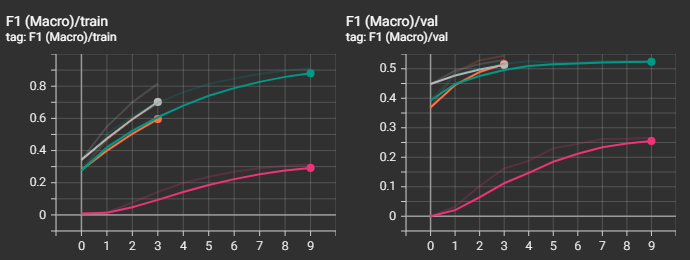
Видно, что несмотря на то, что loss-функция на валидационной выборке начинала уже возрастать, метрики recall и f1 продолжали улучшаться и далее, а вот с метрикой precision незначительно ухудшалась.
А теперь обещанная табличка. Жирным шрифтом указаны лучшие значения. Последняя колонка - время до достижения минимума функции потерь на валидационной выборке.
Имя модели |
Loss |
Precision (micro/ macro) |
Recall (micro/ macro) |
F1 (micro/ macro) |
Batch size |
Время, мин |
|---|---|---|---|---|---|---|
cointegrated/rubert-tiny2 |
0.1819 |
0.6307 / 0.4246 |
0.373 / 0.2136 |
0.4688 / 0.2661 |
32 |
25 |
ai-forever/ruBert-base |
0.1553 |
0.6863 / 0.5963 |
0.5039 / 0.4105 |
0.5811 / 0.4907 |
8 |
57 |
ai-forever/ruBert-large |
0.1582 |
0.6673 / 0.5817 |
0.4922 / 0.3824 |
0.5665 / 0.4482 |
2 |
112 |
ai-forever/ruRoberta-large |
0.1644 |
0.6672 / 0.6275 |
0.5457 / 0.4672 |
0.6004 / 0.5285 |
2 |
320 |
Можно заметить, что "ai-forever/ruRoberta-large" набрала набольшее количество лучших показателей метрик, несмотря на не самое лучшее значение функции потерь. Если бы не длительность обучения, я бы, пожалуй, объявил победителем ее. Но все же, победителем объявляется "ai-forever/ruBert-base".
Далее будем рассматривать результаты только этой модели.
Отчет о классификации ruBERT-base
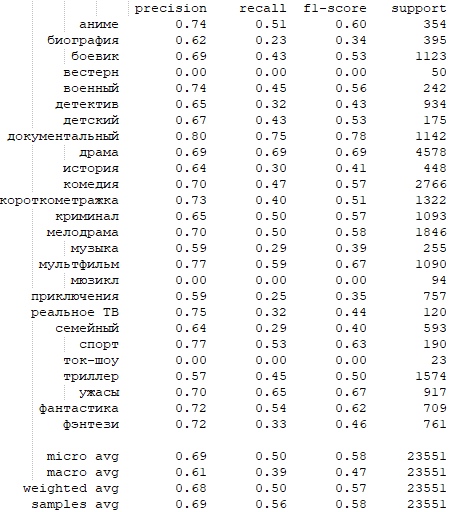
Значения метрик выглядят поприятнее, чем у классических моделей.
Сравнение classification report
Сравним результаты, посмотрев на таблицы отчетов о классификации.
Логистическая регрессия
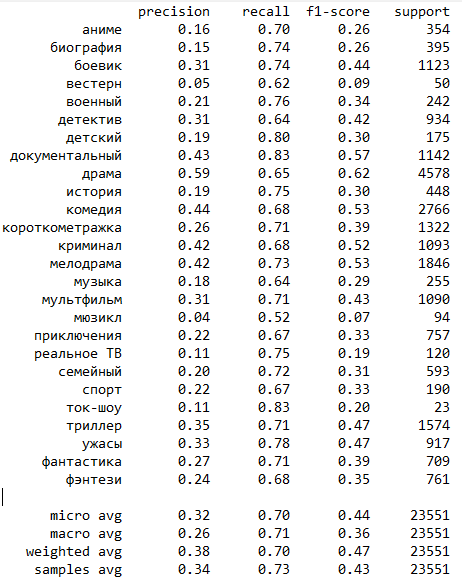
CatBoost

ruBert-base

Значение метрики recall, как ранее уже было сказано, наилучшее у нашей самой простой модели - логистической регрессии. Значениях метрик precision и f1 лучшие у трансформерной модели.
Примеры
Рассмотрим несколько примеров.
Джентльмены (2019)

Один ушлый американец ещё со студенческих лет приторговывал наркотиками, а теперь придумал схему нелегального обогащения с использованием поместий обедневшей английской аристократии и очень неплохо на этом разбогател. Другой пронырливый журналист приходит к Рэю, правой руке американца, и предлагает тому купить киносценарий, в котором подробно описаны преступления его босса при участии других представителей лондонского криминального мира — партнёра-еврея, китайской диаспоры, чернокожих спортсменов и даже русского олигарха.
Аннотация кинопоиска: криминал,комедия,боевик
Логистическая регрессия: биография,боевик,документальный,криминал
Catboost: криминал
BERT: драма,криминал
Как приручить дракона (2010)

Вы узнаете историю подростка Иккинга, которому не слишком близки традиции его героического племени, много лет ведущего войну с драконами. Мир Иккинга переворачивается с ног на голову, когда он неожиданно встречает дракона Беззубика, который поможет ему и другим викингам увидеть привычный мир с совершенно другой стороны…
Аннотация кинопоиска: мультфильм,фэнтези,комедия,приключения,семейный
Логистическая регрессия: аниме,военный,документальный,история,короткометражка,мультфильм,приключения,семейyый,фэнтези
Catboost: драма
BERT: мультфильм,приключения,семейный,фэнтези
Как прогулять школу с пользой (2017)

Вслед за городским мальчиком Полем зрителям предстоит узнать то, чему в школе не учат. А именно — как жить в реальном мире. По крайней мере, если это мир леса. Здесь есть хозяин — мрачный граф, есть власть — добродушный, но строгий лесничий Борель, и есть браконьер Тотош — человек, решивший быть вне закона, да и вообще подозрительный и неприятный тип. Чью сторону выберет Поль: добропорядочного лесничего Бореля или браконьера Тотоша? А может, юный сорванец и вовсе станет лучшим другом надменному графу?
Аннотация кинопоиска: драма,комедия,семейный
Логистическая регрессия: аниме,детский,мультфильм,мюзикл,приключения,семейный,фэнтези
Catboost:
BERT: мультфильм,семейный
Мой комментарий: фильм настолько странный, что Catboost отказался его классифицировать :)
Как я встретил вашу маму

Действие сериала происходит в двух временах: в будущем - 2034 году, где папа рассказывает детям о знакомстве с мамой и этапах создания их семьи, и в настоящем, где мы можем видеть, как все начиналось. Герой сегодня - молодой архитектор Дима, который еще не знает, как сложится его жизнь. Однажды ему даже кажется, что он встретил девушку своей мечты… Но так ли это на самом деле? Разобраться в этом Диме помогают его друзья: Паша и Люся – молодая пара, собирающаяся вот-вот пожениться, а также их общий друг Юра, ортодоксальный холостяк и циник, чей идеал – случайная связь на одну ночь. Он считает, что нет ничего глупее долгих отношений, а брак – устаревшее понятие.
Аннотация кинопоиска: комедия
Логистическая регрессия: драма,комедия,мелодрама
Catboost: драма,мелодрама
BERT: комедия
Заключение
Данные, использованные в моем эксперименте, как это зачастую бывает, несовершенны. Например, для мультипликационного фильма "Как приручить дракона" на мой субъективный взляд, из описания комедийность не просматривается. Да и писали это описание вовсе не с целью подготовить хороший набор данных для машинного обучения :) А информация о жанрах лишь дополняет описание. Да и она, скорее, субъективна.
Тем не менее, эксперимент получился интересным. Надеюсь, что для читателей тоже :)
belonesox
Спасибо! А может опубликуете уже весь проект, чтобы прямо «pipenv run python -m pip install -r requirements.txt» + «./download-all-models.sh» и любой сможет поиграть (параметры, типы, посмотреть что выдают модели для любимых/известных каждому фильмов)?