

Tarantool — NoSQL СУБД, которая разрабатывается и широко используется в Mail.Ru Group. Об объемах использования можно сделать вывод по публикациям:
Недавно Mail.Ru Group выпустила виртуальную машину с предустановленным Tarantool для Microsoft Azure:
- Tarantool on Microsoft Azure Marketplace
- Открытая БД Tarantool от Mail.Ru сертифицирована и размещена в Azure Marketplace
Мы решили проверить, насколько хорошо Tarantool работает в Microsoft Azure в сравнении с другими подобными предложениями — Azure Redis Cache, Bitnami Memcached, Aerospike и VoltDB. Под словом «хорошо» будем понимать «быстро», то есть сравнивать будем число обрабатываемых запросов в секунду (Throughput, RPS).
Azure Redis Cache
Нам потребуется инстанс Azure Redis Cache уровня «Базовый C4» (13 Гб), в котором мы включаем не SSL-порт (для честного сравнения SSL нам не требуется). Использовать именно базовый уровень нужно для того, чтобы исключить репликацию. Azure Redis Cache предоставляется как сервис, и доступа к виртуальной машине мы не имеем. Мы не знаем, как он настроен, не можем на это повлиять. Ориентировочная стоимость Redis Cache нашего размера — 9765 рублей в месяц.
Tarantool VM
Нам потребуется одна виртуальная машина Tarantool VM Standard D11 с 14 Гб с HDD-дисками. Данная конфигурация обойдется нам в 9067 рублей в месяц. Мы будем тестировать Tarantool в двух режимах: с включенным write-ahead logging (для персистентности данных) и с выключенным, так как мы не знаем достоверно, включена ли соответствующая настройка у Redis.
Для смены режима записи в /etc/tarantool/instances.enabled/example.lua меняем настройку wal_mode (none для работы без WAL, write — с WAL, fsync — весьма специфичный режим работы, который тестировать не будем).
Tarantool, в отличие, например, от Redis, имеет TREE-индексы, однако нам нужно сравнивать равное с равным, поэтому использовался HASH-индекс.
Memcached
Мы взяли для теста образ виртуальной машины Standard D11 с предустановленным Memcached от Bitnami.
В Azure Marketplace есть и другой Memcached — облачный сервис от Redis Labs, однако доступен он только на территории США, и протестировать его не получилось.
После развертывания виртуальной машины мы отключили аутентификацию в конфигурационном файле memcached.conf (опция –S).
Memcached не умеет обеспечивать персистентность данных.
Aerospike
Для Aerospike мы взяли официальный образ из Azure Marketplace (Standard D11).
VoltDB
А вот VoltDB в Azure Marketplace нет. Пришлось брать чистую виртуалку (Ubuntu 14.04 LTS) и устанавливать вручную из исходников. Зато приятно удивила Web-админка «из коробки», которая включала в себя живые графики, в том числе и число запросов в секунду.
Синхронно-асинхронный тест
Мы попробуем провести «синхронно-асинхронный» тест, то есть интерфейс у нас будет синхронный, но внутри с соединением будем работать асинхронным образом. Этот вид теста позволяет имитировать работу через одно соединение для множества синхронных клиентов. Чтобы исключить сомнения в идентичности теста для Redis Cache, Tarantool VM и Memcached, всю общую логику вынесем в абстрактный класс NoSQLConnection, от которого потом отнаследуем TarantoolConnection, RedisConnection и MemcachedConnection (см. исходник).
В классе есть две очереди (обычные std::list) — OutputQueue (будет отправлено в сокет) и InputQueue (принятое из сокета), а также методы SendThreadFunc и ReceiveThreadFunc, которые запускаются в отдельных потоках и, при наличии соответствующих непустых очередей, отправляют/принимают информацию пачкой с помощью методов Send и Receive (чистые виртуальные, реализованы в наследниках).
Синхронный интерфейс представлен методом DoSyncQuery, который кладет запрос в OutputQueue и ждет ответа в InputQueue. Тестовая виртуалка должна быть достаточно мощной (мы использовали Standard D3) и находиться географически рядом с базой данных (мы использовали расположение «Западный регион США»).
Ввиду особого строения клиентских библиотек Aerospike и VoltDB (встроенный event-loop), тест для них был написан отдельно.
В диапазоне до 10 клиентских потоков с шагом 1 ёмы близки к полностью синхронному режиму работы (а один поток, по сути, им и является). На графике наблюдается более-менее линейный рост. Redis и Memcached дают примерно равную производительность, Tarantool быстрее, Aerospike самый быстрый, а вот VoltDB, наоборот, самый медленный.
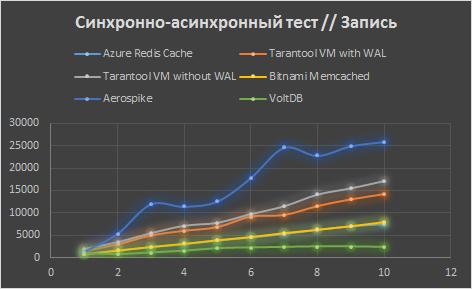

Следующий график — до 100 потоков с шагом в 10, для Tarantool, Redis и Memcached линейный рост продолжается, Aerospike и VoltDB «тормозятся», причем на разных значениях.
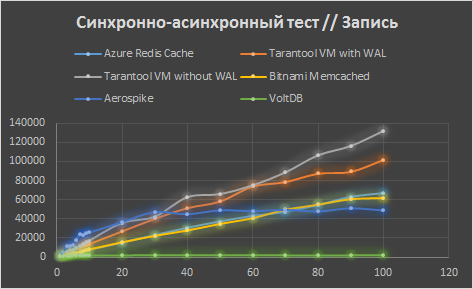
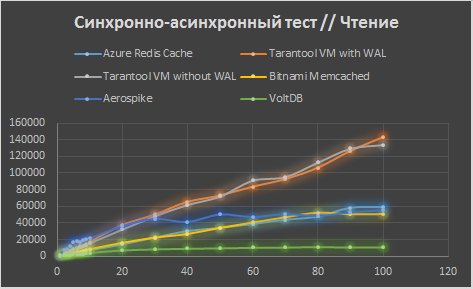
Далее идем до 1000 с шагом в 100 потоков. Рост замедляется везде, а для Memcached и вовсе останавливается.
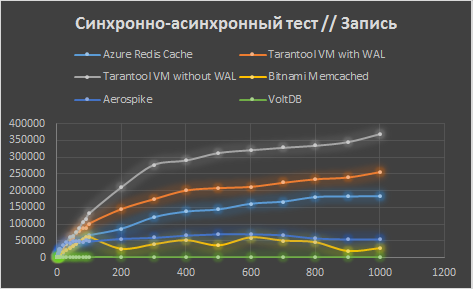
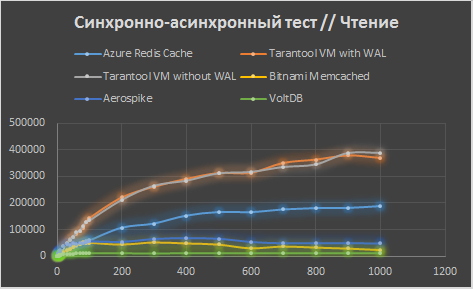
И наконец, идем до 8000 потоков с шагом 1000. Рост прекращается. После 4000 клиентов Memcached перестает работать — закрывает соединение, поэтому протестировать его не удается. VoltDB умирает еще раньше — на 3000 клиентах.
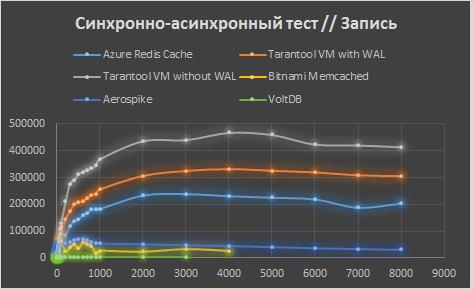

В итоге, мы видим лидерство Tarantool на больших нагрузках (на небольших Aerospike все-таки побыстрее).
А что с синхронным тестом?
А тут все просто. Запускаем синхронно-асинхронный тест в один поток, и он очевидным образом становится просто синхронным. Но если клиентов много, то потребуется много соединений… Хорошо, тогда запустим несколько тестов параллельно и просуммируем результаты.
Aerospike и VoltDB в таком режиме не тестировались.
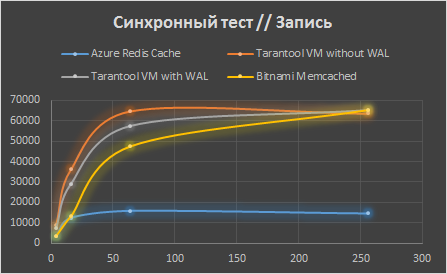

Мы видим, что синхронный тест имеет определенный «потолок», который ниже, чем у синхронно-асинхронного соединения. Этот потолок вызван накладными расходами на сеть.
Сравнение цен
Сами Tarantool, Memcached, Aerospike и VoltDb бесплатны, оплачивать нужно только виртуальную машину, на которой они запущены. Мы использовали Standard D11 (14 Гб оперативной памяти), который стоит ~9067 рублей в месяц. Azure Redis Cache немного дороже — ~9765 рублей в месяц за базовый C4 инстанс (13 Гб оперативной памяти). Визуализируем.
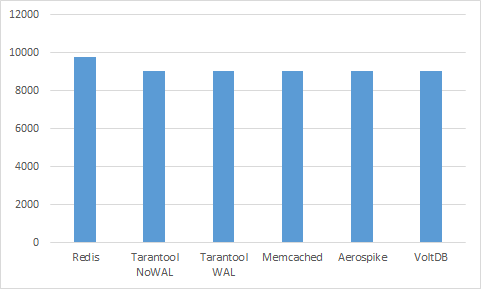
Согласны, что ничего не понятно? Цены почти равны… Однако, как мы видели ранее, эти базы данных имеют разную производительность. Попробуем выразить стоимость не в месяц, а на миллиард запросов. Сперва посмотрим, сколько стоит миллиард запросов записи при 1000 клиентах.
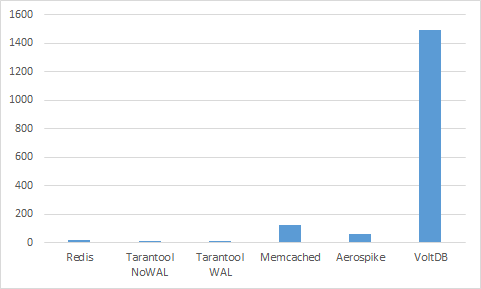
VoltDB тут явный аутсайдер. Уберем его.
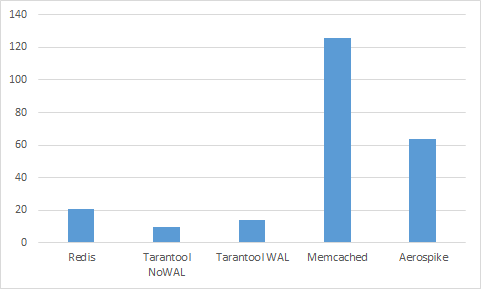
Теперь уберем Aerospike и Memcached, чтобы посмотреть на лидеров вблизи.
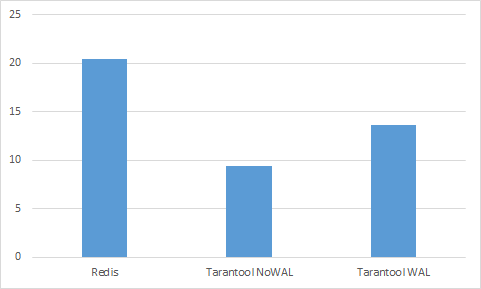
А теперь как изменится стоимость, если считать запросы на чтение на 100 клиентах.

Оставляем только лидеров.

Выводы
В процессе тестирования тестовый процесс в синхронно-асинхронном тесте вызывал нагрузку на процесс Tarantool до 70% CPU, в синхронном режиме — до 100%. На всех графиках Tarantool VM, вне зависимости от режима WAL, показал себя лучше конкурентов. Заметим, что наличие или отсутствие WAL не влияет на скорость чтения из Tarantool (на графиках чтения оранжевая и серая кривые совпадают), так как при чтении из Tarantool диск не используется. Кроме того, Tarantool VM оказался самым дешевым решением как на единицу времени (в месяц), так и на каждый запрос.
Комментарии (68)


buriy
18.04.2016 20:56+4Скажите, а есть ли аналог команды redis PIPELINE в tarantool ( http://redis.io/topics/pipelining )? Как-то грустно напрягать сеть 10000 раз в секунду и писать параллельные программы ради batch actions, когда можно сразу выполнить 10000 вставок одной передачей данных.
Кроме того, без этой команды вы ставите сервера в неравные условия — мне кажется, у вас network stack ограничивает производительность в половине примеров.
dedokOne
19.04.2016 10:24Чтобы не напрягать сеть можно посылать 'комманды' (в тарантуле правда нет такого термина) пачками по N, если у вас клиент асинхронный и вам не нужен пока результат выполнения 'пачки' то, минимум горлышков в execution на клиенте будет.
buriy
19.04.2016 10:36Если на каждую команду у нас всё равно socket.send(), то будет 10к запросов в секунду на поток, а не 3к, вот и всё.
Потолок — 10к сообщений в секунду, каждое сообщение по 10 байт. Обидно, нет?
danikin
19.04.2016 10:59+1Тарантул группирует запросы, отправляемые параллельно в один сокет внутри клиентской библиотеки. Ровно тоже самое делается на стороне сервера при получении ответа. Сокет можно использовать полностью асинхронно в Тарантула для чтения и записи в оба конца. Этим самим Тарантул максимально утилизирует сеть. Собственно, результаты тестов это хорошо отражают.
buriy
19.04.2016 11:18А он может как-нибудь группировать мелкие запросы, отправляемые последовательно в одно соединение?
Представьте, что мне нужно сделать batch update для 10 млн значений в хеш-таблицу, и я хочу, чтобы это не требовало часа времени.
Как мне это проще всего сделать?danikin
19.04.2016 12:53Просто посылать в сокет все запросы подряд, а потом читать из этого же сокета все ответы. То же самое можно сделать через клиентские билиотеки.
buriy
19.04.2016 11:25+1>Этим самим Тарантул максимально утилизирует сеть
Что вы вкладываете здесь в слово «максимально»? Посчитайте сами: пусть сеть — 1 ГБит. Сколько запросов размером 10 байт нужно отправить в секунду, чтобы «максимально утилизировать сеть»?
Тарантул — отличный инструмент для большого числа параллельных потоков. Но для групповых операций в нём простого метода, как я понимаю, нет — «пишите lua-скрипт под ваши нужды».danikin
19.04.2016 12:52+21. Про сеть. В Ажуре сеть далеко не 1Гбит. Попробуйте поставить те инстансы, которые описываются в статье и покопируйте файлики между ними. Будет дай бог 20 мбайт в секунду. Далее, размер запроса не 10 байт, а байт 30-40. Тарантул тянет до 500К запросов в секунду, т.е. 15-20 мбайт в секунду. Он реально хорошо утилизирует сеть. Попробуйте :)
2. Вы будете смеяться, но для Тарантула не нужен такой метод. Он полностью асинхронен. Вы просто в сокет кидаете все операции, сколько хотите, и потом получаете в сокет ответ. Кинете сразу 100 операций — улетит все 100 в одном пакете и потом прилетит ответ в одном пакете. Вы не должны говорить Тарантулу — «вот тут группа начинается», «а вот тут группа заканчивается». Он сам все разрулит и сделает максимально эффективно :)buriy
19.04.2016 13:25>1. Попробуйте :)
Сейчас попробую.
>2. Вы будете смеяться, но для Тарантула не нужен такой метод. Он полностью асинхронен. Вы просто в сокет кидаете все операции, сколько хотите, и потом получаете в сокет ответ. Кинете сразу 100 операций — улетит все 100 в одном пакете и потом прилетит ответ в одном пакете. Вы не должны говорить Тарантулу — «вот тут группа начинается», «а вот тут группа заканчивается».
>Он сам все разрулит и сделает максимально эффективно :)
Но вообще, хотелось бы, чтобы это вы не мне в треде по секрету говорили, а это было бы видно сразу как существенное преимущество библиотеки.
А во-вторых, это, увы, никак не снимает претензию к тестированию других библиотек, которые так не умеют — вместо ваших красивых графиков вы могли померить всего два параметра:
а) скорость работы для batch-режима
б) задержка сети до вашего сервера (3к пингов в секунду).
Всё остальное на практике обычно укладывается в формулу
QPS = min(latency * sync_clients, max_throughput).
Как я понимаю, неожиданностей не произошло.danikin
19.04.2016 13:30+2Почему не умеют? Возможно, и умеют. Но мы как раз специально написали синхронно-асинхронный код (см. начало теста, см. исходники теста), чтобы максимально разогнать всех наших конкурентов, если они умеют работать в асинхронном режиме.
Наша цель была провести максимально объективное тестирование. Возможно, что мы что-то не учли. Мы не претендуем на абсолютную истину. Если у вас есть идеи как ускорить любого из конкурентов Тарантула (по другому настроить, переписать клиентскую либу, написать поверх либы другую правильную либу и тд), то милости просим, покажите. Код теста, повторюсь, открыт. Можете на его основе делать.
Про ваши рекомендации как нам надо было менять наши красивые графики, я не совсем понял. Можете разжевать?buriy
19.04.2016 18:07Я действительно не понимаю.
Вы загружаете на сервер данные батчами или по одному значению за один раз?
Как я вижу, ваш код может загрузить батч. Но делает ли он это?
>Вы не должны говорить Тарантулу — «вот тут группа начинается», «а вот тут группа заканчивается».
>Он сам все разрулит и сделает максимально эффективно :)
А tnt_flush это для гарантии отправки последнего сетевого пакета?
>Про ваши рекомендации как нам надо было менять наши красивые графики, я не совсем понял. Можете разжевать?
Ну, я по поводу того, что графики рисуют две линии, плавно переходящие одна в другую. Одна y=kx до насыщения, вторая почти горизонтальная (уровень насыщения).
Наиболее интересны для меня как раз параметры этих линий, и объяснение именно таких значений этих параметров.
Например, я не понимаю, почему у вас на одном потоке всего около 3к запросов в секунду на всех тестируемых базах данных.
Получается, вы не используете возможность групповой загрузки и чтения данных?
rvncerr, почему вы групповую загрузку не хотите протестировать?
Статья называется «Сравнение Tarantool с конкурентами в Microsoft Azure», такое название и первый абзац подразумевают широту изложения.
rvncerr
19.04.2016 18:35+1Все-таки наличие тестирования не подразумевает тестирование ВСЕХ случаев.
Тестировать можно по-разному: синхронно, асинхронно, синхронно-асинхронно, с батчингом и без него, с хранилками.
Но все и сразу — нет. Это будет месиво информации, которое бросят читать на полпути.
Я уже делал тест с батчингом (правда, асинхронный) и демонстрировал его результаты на хайлоаде.
Тут я захотел сделать тест без батчинга — по этой причине. Кратко — я взял типовой, по моему мнению, профиль нагрузки и сделал тест под нему.buriy
19.04.2016 19:18-3Спорно. По моему субъективному мнению, получилось необъективно, особенно учитывая расположение поста в блоге mail.ru.
Как-то так: https://gyazo.com/624e16eda973e742e4cb02059d629d6f
Попробую объяснить, почему, на мой взгляд теряется объективность:
Есть ли юз-кейсы, где redis лучше, чем tarantool?
Если читать ваш пост, то нет, tarantool всегда лучше всех. А на деле — есть. Я показал один такой юз-кейс.rvncerr
19.04.2016 19:32+1Мне действительно жаль, что у вас возникло такое ощущение, хотя я такого и не заявлял. Тем не менее, мой юзкейс чрезвычайно часто встречается в реальном мире, и именно этом обоснован мой выбор.
buriy
19.04.2016 20:49Я согласен, что ваш юз-кейс весьма часто встречается, и безусловно, это самый часто встречаемый кейс.
Но загрузка и выгрузка данных тоже весьма распространены.
Вы согласны, что рассмотрение явлений с разных сторон увеличивает объективность исследования?
danikin
19.04.2016 19:53+3Можете напомнить, в каком конкретно случае Редис лучше? (желательно с доказательствами)
buriy
20.04.2016 00:09Потолок скорости python-процесса, общающегося с базой данных, в redis в 3-5 раза выше, чем в tarantool, если есть возможность использовать группировку операций (aka batching). Но это относится только к питоновскому клиенту tarantool, в котором поддержки батчинга пока нет, в С-шном коде из топика поддержка батчинга есть (но почти не используется, поэтому там максимальная скорость 3к операций в секунду на поток).
Поэтому, если вы уменьшите требования к синхронности в ваших тестах, то redis обгонит tarantool в некоторой части этих тестов.
Я был бы доволен, если бы вы смогли упомянуть этот момент в статье, а ещё лучше, если бы вы смогли добавить график теста с групповыми операциями.
См. подробности ниже в https://habrahabr.ru/company/mailru/blog/281841/#comment_8859953
(это я для новых читателей, вы-то в курсе).danikin
20.04.2016 00:19+1А, все же, какой движок используется в тарантул, когда redis в 3-5 раз быстрее — sophia или memtx?
buriy
20.04.2016 09:06Отключен wal. Любой из движков. Ссылка на конфиг: https://habrahabr.ru/company/mailru/blog/281841/#comment_8860143
20k RPS из клиента в tarantool, 120k из redis.
Вы как будто не читаете другие комменты.danikin
20.04.2016 10:25А можете еще раз дать исходник теста? Я хочу все элементы этого пазла свести воедино. Как вариант, могу ли я позвонить вам на телефон/скайп, чтобы за один присест получить всю информацию?
buriy
20.04.2016 18:35+1Что же вы такой невнимательный. Ctrl-F «gist» в этом посте, и найдутся:
Все бенчмарки и их результаты: https://gist.github.com/buriy/329bdac8f42f2c0c0e678bcbfe26ee0e
Мой конфиг: https://gist.github.com/buriy/c9383845754ff552c83d81ba9f60fbed
Запуск профайлера для bench.py: https://dl.dropboxusercontent.com/u/1703221/batch.prof (я использую runsnakerun чтобы их смотреть)
Запуск профайлера для mbench.py 20: https://dl.dropboxusercontent.com/u/1703221/mbatch.prof
Добавил контакты в профиль хабра, пишите в скайп или телеграм: https://habrahabr.ru/users/buriy/
rvncerr
19.04.2016 15:02+1На batch-режим есть одна достаточно серьезная претензия.
Он совершенно не всегда может быть органически встроен в структуру проекта.
Придется писать дополнительный код, который эти пачки формирует.
То есть в теории, конечно, попробовать можно протестировать, но а практике не факт что этот подход будет легко применим, ИМХО.
То есть нам важно не «сколько из СУБД можно выжать в принципе» (сферический конь в вакууме), а сколько можно выжать на типовой бизнесовой задаче.
+ Делая пачку, мы увеличиваем latency для первых запросов в ней. (!)buriy
19.04.2016 15:29С этим я в целом согласен, но «типовые задачи» бывают разные.
Почему вы ограничиваетесь только проектами, имеющие однотипную нагрузку?
Что мне делать, если мне в один день нужно в БД всё быстро положить, потом день — считать, на третий день — выгрузить?
«Вы не сможете быстро положить ваши гигабайты данных в нашу БД, не сможете быстро их выгрузить, но зато мы быстро с ними работаем, пока данные находятся внутри» — бывает такая проблема у некоторых облачных вычислительных центров.
У меня пока вопрос только по быстрой загрузке данных — счёт и выгрузка вроде бы в порядке.
(Собственно, счёт и не может быть медленным, если скорость обмена память-процессор порядка 30 ГБ/с на десктопных Haswell — сеть гораздо медленнее)
Улучшите загрузку данных в клиентских библиотеках — я с удовольствием слезу с redis, к которому у меня тоже есть определённые претензии, и перелезу на tarantool для подходящей части моих задач.rvncerr
19.04.2016 15:31Ответ простой. :)
Потому что я всегда пишу тесты под задачу. Сегодня выбрал такую.
Батчинг — интересная тема, но для совсем другого теста.
В целом этот тест больше для «масс-маркета», чем тест с батчингом.
Основная же идея — сравнивать равное.
danikin
19.04.2016 15:51+2Загрузка данных в Тарантул происходит очень быстро. В этом легко убедиться, если написать простейший скрипт, который селектит из редиса и записывает в Тарантул.
Но, на самом деле, я понимаю вашу проблему. Вы хотите бесшовную миграцию. И идеально было бы, если бы Тарантул полностью поддерживал интерфейс редиса и мог бы реплицироваться из него. Мы работаем над этим в том числе.buriy
19.04.2016 17:26Так я же и написал скрипт: https://habrahabr.ru/company/mailru/blog/281841/#comment_8859149
Нет, спасибо, я не хочу бесшовную миграцию — слишком разные базы данных, вряд ли кто-то будет держать сразу обе.
Я хочу просто лёгкую и удобную загрузку данных в базу данных. Желательно, без гринлетов.
Вполне подойдёт такое:
with conn.pipeline() as p:
for i in xrange(100000):
p.insert((i, value))
Но я согласен и на менее специализированное p.insert_many((i, value)) — это всё же более частая задача для меня, имеющая отдельное значение.
Я не хочу вместо этого переходить на python 3 или писать лапшу, как в https://habrahabr.ru/company/mailru/blog/281841/#comment_8859211
Но готов рассмотреть данный вариант в случае отсутствия более приличных.
Как минимум, есть ситуация начальной загрузки базы данных в случае падения сервера.
На самом деле, вероятно, всё дело именно в особенностях питоновской библиотеки. Если бы она не ждала ответа сервера, всё было бы намного быстрее.danikin
19.04.2016 18:04Как вариант — мы можем пригласить вас в чатик разработчиков Тарантула — можете задать им вопросы и пообщаться в онлайне. Они обязательно на все ответят и помогут! Плюс, в этом чатике есть и пользователи Тарантула — они тоже обладают кладезью бесценных знаний. Если вы Ок, то напишите в личку ваш телефон (чатик в телеграме) — и я вас туда добавлю.
buriy
19.04.2016 18:14Ну, вопросы мои я все перечислил уже, я буду благодарен, если вы сможете их передать разработчикам.
Могу и сам передать, конечно. https://telegram.me/yuri_baburov (это юзернейм)danikin
19.04.2016 18:27Ok. Попросил разработчиков вылезти сюда и ответить :)
Вот по этой ссылке https://telegram.me/joinchat/ABEGwD2KQS3ZzYLbHwIrpA можете добавиться в чатик — это на случай, если они не ответят за разумное время :)
bigbes
19.04.2016 18:41+1Оффициально — в питоновском драйвере такой возможности нет, но неоффициально, для примера, можно привести кусок кода из тестов:
from tarantool import Connection from tarantool.request import RequestInsert from tarantool.response import Response c = Connection('localhost', 3301) c.connect() request1 = RequestInsert(c, 512, [1, "baobab"]) request2 = RequestInsert(c, 512, [2, "obbaba"]) s = c._socket try: s.send(bytes(request1) + bytes(request2)) except OSError as e: print ' => ', 'Failed to send request' response1 = Response(c, c._read_response()) response2 = Response(c, c._read_response()) print response1.__str__() print response2.__str__()
Оффициально батчинг (пайплайнинг) поддерживается в драйвере для C.
Как минимум, есть ситуация начальной загрузки базы данных в случае падения сервера.
Вот об этом, пожалуйста, поподробнее.
buriy
19.04.2016 19:08+1Спасибо, буду ждать появления батчинга/пайплайнинга в драйвере для Python и в подобных постах, сравнивающих базы данных!
>>Как минимум, есть ситуация начальной загрузки базы данных в случае падения сервера.
>Вот об этом, пожалуйста, поподробнее.
Это круто, если сервер никогда не падает. В redis с этим бывают проблемы, поэтому я всегда об этом думаю заранее.
Также ещё два момента перечислены в комментарии ниже ( https://habrahabr.ru/company/mailru/blog/281841/#comment_8859149 ), но первый, про delete и select — это, возможно, особенности питоновского драйвера, а второй момент — что сервер отжирает память и никому не отдаёт — это даже в чём-то плюс для больших серверов и постоянных нагрузок, но, увы, минус для переменных нагрузок. Хотя, может, это как-то и регулируется в опциях.bigbes
19.04.2016 19:52буду ждать появления батчинга/пайплайнинга в драйвере для Python
Было-бы прекрасно если бы вы отписались/апнули тикет https://github.com/tarantool/tarantool-python/issues/55
Это круто, если сервер никогда не падает. В redis с этим бывают проблемы, поэтому я всегда об этом думаю заранее.
Для этого нужно использовать репликацию и snapshot/xlog (аналоги aof/rdb для редиса). Или я не совсем понял вашу проблему.
но первый, про delete и select — это, возможно, особенности питоновского драйвера
Select — не особенности питоновского драйвера, а ограничение на уровне Тарантула. 2 Гб это максимум пакета, который отправляется по сети. Но есть у меня небольшое впечатление, что это можно/проще обрабатывать прямо на борту Тарантула (но всё, конечно, зависит от задачки).
Delete — оборачивается, проще всего, в хранимку на Lua.
что сервер отжирает память и никому не отдаёт
Это, конечно, так, но касается только памяти под данные.
buriy
19.04.2016 15:10Ну что же, пока мне что-то не смешно.
Тест показывает, что вы не правы, или я не умею правильно запускать ваши «асинхронные запросы»:
https://gist.github.com/buriy/329bdac8f42f2c0c0e678bcbfe26ee0e
$ python batch.py
7 bytes: 2.5 sec, 20263.7 RPS, 0.1 MB/s
1009 bytes: 2.4 sec, 20474.2 RPS, 20.7 MB/s
10009 bytes: 2.9 sec, 17380.0 RPS, 174.0 MB/s
20009 bytes: 3.4 sec, 14531.8 RPS, 290.8 MB/s
50009 bytes: 4.9 sec, 10230.7 RPS, 511.6 MB/s
100011 bytes: 7.1 sec, 7059.3 RPS, 706.0 MB/s
200011 bytes: 12.2 sec, 4110.2 RPS, 822.1 MB/s
300011 bytes: 31.4 sec, 1590.9 RPS, 477.3 MB/s
Аналогично с gtarantool.
У batch.py всегда загрузка около 80-90% CPU, как вы догадываетесь, всё дело в socket.send и socket.recv:
https://gyazo.com/5d2206dea2a93be28e06073f2f9a2ed9
P.S. И ещё два замечания:
1) нет простого способа получить только часть полей: delete всегда возвращает удалённое значение, а select вообще ломается при попытке получить больше 2 гб данных — это актуально для манипуляции данными большого размера.
2) сервер не возвращает память обратно ОС.
shveenkov
19.04.2016 15:36+2Сделайте несколько гринлетов, и выполняйте insert через общий tarantool-connection.
Можно посмотреть кейсы для gevent: https://habrahabr.ru/company/mailru/blog/254727/buriy
19.04.2016 18:51+1Добавил тест с гринлетами (10, 20 и 100 параллельных), добавил redis для сравнения.
Всё равно не могу добиться больше 50к RPS от tarantool.
https://gist.github.com/buriy/329bdac8f42f2c0c0e678bcbfe26ee0e
Что я теперь-то делаю не так? :)shveenkov
19.04.2016 19:42Ну уже видно, что gtarantool в 10 гринлетов быстрее чем обычный синхронный коннектор!
Подберите оптимальное кол-во гринлетов, а если питон утилизировал 1 ядро cpu на 100%, то делайте fork и грузите тарантул больше.
Еще вы сравниваете insert в tarantool и insert в redis, под капотом это немного различные вещи.
Запись на диск или в память. Ваш тест не ждет когда redis синканет все данные на диск.
Сравните разницу на select-ах в gtarantool и redis.buriy
19.04.2016 20:37>Подберите оптимальное кол-во гринлетов, а если питон утилизировал 1 ядро cpu на 100%, то делайте fork и грузите тарантул больше.
Ещё и fork делать? Нет уж, я лучше подожду батчинга/пайплайнинга в драйвере для Python, ветка здесь: https://habrahabr.ru/company/mailru/blog/281841/#comment_8859627
>Еще вы сравниваете insert в tarantool и insert в redis, под капотом это немного различные вещи.
>Запись на диск или в память. Ваш тест не ждет когда redis синканет все данные на диск.
Нет, проблема явно не в этом:
$ python mbatch.py 100
7 bytes: 0.9 sec, 57176.5 RPS, 0.4 MB/s
Вряд ли тут дело в том, что 0.4 MB не смогли записаться на SSD диск за одну секунду.shveenkov
19.04.2016 20:49Ещё и fork делать?
А как вы собираетесь весь процесор на python занять без fork?
redis вас тут тоже не спасет.
> Нет, проблема явно не в этом:
отключите запись на диск в tarantool, и запустите свой бенчмарк для сравнения.
Внутри gtarantool запросы группируются в пачки, несколько запросов в отдельном гринлете отправляются через один вызов soket.send. В отдельном гринлете из сокета вычитываются несколько ответов за один soket.recv.buriy
19.04.2016 21:30>отключите запись на диск в tarantool, и запустите свой бенчмарк для сравнения.
Отключён. Вообще, как я понимаю, sophia основана на leveldb, а он 150к writes/second без проблем выдерживает.
>А как вы собираетесь весь процесор на python занять без fork?
>redis вас тут тоже не спасет.
Это да, но redis в свой потолок одного ядра без гринлетов утыкается на 120k RPS — около 1.1 MB/s, а не на 20к RPS (или на 50к RPS с извращениями и гринлетами).
Пусть у вас 24 ядра, все грузят данные. За какое время вы забьёте 24 GB мелкими данными при таком сценарии? Пусть оверхед от многопоточности будет 50%.
Ответ: полчаса у Redis, и 3 часа у tarantool (1.2 часа с гринлетами).
Вообще, не так уж и долго, конечно, кроме того, настолько мелкие данные попадаются не часто — 100-байтовые значения более вероятны, чем 10-байтовые, а на них скорость будет в 10 раз выше.
В общем, случай редкий.
Тем не менее, я знаю, что случай не единственный, batching нужен ещё много где, и вижу, что с батчингом скорость библиотеки можно улучшить раз в 10. Буду ждать, а может и сам как-нибудь патч напишу, когда надо будет. Там, в общем-то, ничего сложного, дольше обсуждаем и велосипеды изобретаем.bigbes
19.04.2016 22:21+1Во первых — Sophia не основана на LevelDB. Если интересно, то вы можете почитать здесь и здесь
Во вторых — тут имеют ввиду отключить запись WAL и не использовать engine='sophia', для спейса, который вы бенчмаркаете:
box.cfg{ wal_mode='none' } box.schema.create_space('test', { engine = 'memtx' })
PS можете показать ваш конфиг тарантула?
buriy
19.04.2016 23:42>Во первых — Sophia не основана на LevelDB.
Ну, я просто чьи-то слова повторил из комментов к прошлым обсуждениям, может, что-то переврал — но ощущение осталось, что там-то уж точно тормозить не должно.
>PS можете показать ваш конфиг тарантула
Дефолтный из поставки debian для 1.6, example.lua, минимальные исправления.
https://gist.github.com/buriy/c9383845754ff552c83d81ba9f60fbed
danikin
19.04.2016 23:24София выдает 150k writes/second и даже больше, если используется upsert — т.е. insert, если нет записи в индексе и update, если есть. Если же использовать простой insert, то софия сначала должна сделать select, чтобы убедиться, что записи нет в индексе, и это весьма вероятно приведет к походу на диск.
buriy
19.04.2016 23:56>и это весьма вероятно приведет к походу на диск.
Ну и что, ведь есть файловый кеш.
cProfile указывает на socket.recv() как основную причину торможения. Батчинг как раз это улучшил бы.
Посмотрите сами: https://dl.dropboxusercontent.com/u/1703221/batch.prof и https://dl.dropboxusercontent.com/u/1703221/mbatch.prof (гринлеты cProfile учитывает как-то плохо, мне кажется, нужно игнорировать верхние 4 строчки, а дальше вроде бы более-менее правдоподобно)danikin
20.04.2016 00:05+1Давайте так, София не идеальна пока по скорости. Есть куда стремиться. Но! Давайте ее сравнивать apples to apples с другими дисковыми СУБД, например с MySQL. А если вы берете Редис, то предлагаю сравнивать его с мемтиксом.
buriy
20.04.2016 09:17+1Дело явно не в Sophia, это питоновский драйвер медленный.
Сам tarantool спокойно вытягивает 400k RPS при параллельной загрузке без WAL, и 250к RPS с WAL.
У redis 120к — это тоже потолок скорости одного соединения из питона.
Но если вы утверждаете, что проблема с диском, тогда уж сравнивайте с LevelDB или LMDB, а не MySQL:
http://symas.com/mdb/ondisk/ и http://symas.com/mdb/inmem/scaling.htmldanikin
20.04.2016 09:46Не исключено. Я просто лишь о том, что надо сравнивать яблоки с яблоками. Мы уже исследуем проблему медленного питоновского драйвера. Спасибо, что обратили внимание!
Кстати, сразу вопросы:
1. Когда Тарантул упирается в 20К, то как выглядит top на сервере с тарантулом?
2. Клиентский код запускается на том же сервере, что и Тарантул или на другом?buriy
20.04.2016 18:22>1. Когда Тарантул упирается в 20К, то как выглядит top на сервере с тарантулом?
75-85% от одного ядра у питоновского процесса, 30% от другого ядра у тарантула (что тоже немного странно, конечно). У mbatch 95% CPU core на маленьких размерах данных.
>2. Клиентский код запускается на том же сервере, что и Тарантул или на другом?
На том же сервере, но не на HT-ядрах (вручную выставлено с помощью taskset).
( В роли сервера — обычный i4790K с 24 Гб памяти и ubuntu, работает без троттлинга на скорости 4 ГГц — это чтобы исключить медленность сервера. кстати, интересно было бы потестировать на серверах с большим числом ядер — там обычно всего около 2 ГГц — как бы там ещё в два раза потолок на CPU не уменьшался. )
danikin
19.04.2016 10:58+1В Тарунтуле есть круче — есть server-side-scripting на Lua. Т.е. можно писать программу целиком внутри Тарантула, избегая сети таким образом. Вот тут несколько статьей:
https://habrahabr.ru/company/mailru/blog/272669/
https://habrahabr.ru/company/mailru/blog/252065/
https://habrahabr.ru/post/254533/
Взаимодействие с сетью часто является узким местом, это правда. Но какие-то СУБД работают с сетью эффективней других. Тест и это тоже показывает.

zlob
20.04.2016 18:59-2Полное игнорирование таких незаменимых в быту вещей как MGET, MSET и PIPELINE. Не хватает только ссылки на мнение автора Redis, про подобные сравнения. antirez.com/news/85

nucleusv
18.04.2016 21:39как-то про VoltDB неожиданно, и мне кажется, что это неправильная настройка скорей всего так как там имеет большое значение партиционирование и возможно даже при одной ноде.
rvncerr
18.04.2016 21:49+1Был бы рад с вами пообщаться на эту тему, если вы не против.
Хочу «разогнать» VoltDB и перечертить графики, но пока это лучшее, что удалось на таком тесте.
danikin
19.04.2016 11:00+1Соглашусь с rvncerr. Если кто-то умеет правильно настроить тестируемые нами системы, то мы очень велкам поучиться. Ибо наша задача как раз показать объективные тесты, поэтому мы прилагаем максимум усилий к правильной настройке всех систем, чтобы из всех выжать все соки.

smart
19.04.2016 01:05+1Aerospike и VoltDB в таком режиме не тестировались.
– а почему? А что будет, если протестировать?rvncerr
19.04.2016 12:56Немного лени. :)
Там цель была не в сравнении, а показать, что при синхронном тесте мы упираемся в потолок раньше.
Но раз вопрос возник — попробую нарисовать — покажу.


gurinderu
А можно ссылочку на бенчмарк? Картиночки красивые конечно, но хотелось бы увидеть методику тестирования.
rvncerr
Сразу под заголовком «Синхронно-асинхронный тест» в конце первого абзаца есть ссылка.
Но я там красоту не наводил, выложил AS IS.
gurinderu
А можно добавить в сравнение Apache Ignite?
rvncerr
Конечно, по не «прямо сейчас». К следующей статье. :)