
Немного истории
На заре вычислительной техники динамическая память вполне себе работала на частоте процессора. Мой первый опыт работы с компьютером был связан с клоном компьютера «ZX Spectrum». Процессор Z80 осуществлял обработку инструкций в среднем по 4 такта на операцию, при этом два такта использовалось на осуществление регенерации динамической памяти, что дает нам при частоте в 3,5 МГц, не более 875 000 операций в секунду.
Однако спустя некоторое время частоты процессоров достигли такого уровня, когда динамическая память уже не справлялась с нагрузкой. Для компенсации этого, было введено промежуточное звено в виде кэш-памяти, что позволило за счет операций выполняемых на небольшом объеме данных сгладить разницу в скорости работы процессора и основной памяти.
Давайте рассмотрим что представляет из себя оперативная память компьютера сейчас, и что с ней можно сделать, чтобы увеличить быстродействие компьютерной системы.
Вкратце о статической и динамической памяти
Память строится в виде таблицы, состоящей из строк и столбцов. В каждой ячейке таблицы находится информационный бит (мы обсуждаем полупроводниковую память, впрочем множество других реализаций строиться по тому же принципу). Каждая такая таблица называется «банком». В микросхеме/модуле может размещаться несколько банков. Совокупность модулей памяти проецируется в линейное адресное пространство процессора в зависимости от разрядности отдельных элементов.
Ячейка статической памяти строится на основе триггера, который обычно находиться в одном из стабильных состояний «А» или «Б»(А =! Б). Минимальное количество транзисторов для одной ячейки составляет 6 штук, при этом сложность трассировки в ячейках видимо не позволяет сделать модули статической памяти в 1 гиг, по цене обычного модуля в 8 гиг.
Ячейка динамической памяти состоит из одного конденсатора отвечающего за хранение информации и одного транзистора отвечающего за изоляцию конденсатора от шины данных. При этом в качестве конденсатора используется не навесной электролит, а паразитная емкость p-n перехода между «подложкой» и электродом транзистора (специально для этих целей увеличенная, обычно от нее стараются избавиться). Недостатком конденсатора является ток утечки (как в нем самом, так и в ключевом транзисторе) от которого очень сложно избавиться, кроме того с увеличением температуры он увеличивается что влечет вероятность искажения хранимой информации. Для поддержки достоверности, в динамической памяти применяется «регенерация», она заключается в периодическом обновлении хранимой информации не реже заданного периода в течении которого информация сохраняет достоверное значение. Типовой период регенерации составляет 8 мс, при этом чаще обновлять информацию можно, реже не рекомендуется.
В остальном принцип функционирования идентичен и заключается в следующем:
— первоначальная выборка строки памяти приводит к доступу ко всему ее содержимому помещаемому в буферную строку с которой идет дальнейшая работа, или происходит мультиплексирование обращения к столбцам (старый, медленный подход);
— запрошенные данные передаются к главному устройству (обычно это ЦПУ), или происходит модификация заданных ячеек при операции записи (тут есть небольшая разница, для статической памяти возможна непосредственная модификация ячейки выбранной строки, для динамической памяти модифицируется буферная строка, и только потом выполняется обратная запись содержимого всей строки в специальном цикле);
— закрытие и смена строки памяти так-же различна для разного типа памяти, для статической возможна мгновенная смена строки если данные не менялись, для динамической памяти необходимо содержимое буферной строки обязательно записать на место, и только потом можно выбрать другую строку.
Если на заре вычислительной техники каждая операция чтения или записи завершалась полным циклом памяти:
— выбор строки;
— операция чтения/записи из ячейки;
— смена/перевыбор строки.
Современный операции работы с микросхемами «синхронной памяти а ля DDRX» заключается в следующем:
— выбор строки;
— операции чтения/записи ячеек строки группами по 4-8 бит/слов (допускается множественное обращение в рамках одной строки);
— закрытие строки с записью информации на место;
— смена/перевыбор строки.
Такое решение позволило сэкономить время доступа к данным когда после чтения значения из ячейки «1», требуется обращение к ячейкам «2, 3, 4, или 7» расположенным в той-же строке, либо сразу после операции чтения, необходимо записать назад измененное значение.
Подробнее о работе динамической памяти в союзе с кэшем
Контроллер памяти (в чипсете или встроенный в процессор) выставляет адрес блока и номер строки (старшую часть адреса блока) в микросхему/модуль памяти. Выбирается соответствующий блок (дальше будет рассматриваться работа в рамках одного блока) и полученный «двоичный номер» декодируется в позиционный адрес строки, после чего происходит передача информации в буфер, из которого в последствии осуществляется доступ к данным. Время в тактах необходимое на данную операцию называется tRCD и отображается в схемах «9-9-9/9-9-9-27» на втором месте.
После того как строка активизирована можно обращаться к «столбцам» для этого контроллер памяти передает адрес ячейки в строке, и спустя время «CL» (указывается в выше обозначенной схеме «х-х-х» на 1 месте) данные начинают передаваться от микросхемы памяти в процессор (почему во множественном числе? потому что здесь вмешивается КЭШ) в виде пакета из 4-8 бит (для отдельно взятой микросхемы) в строку кэша (размер зависит от процессора, типовое значение 64 байта — 8 слов по 64 бита, но встречаются и другие значения). Спустя определенное количество тактов, необходимых для передачи пакета данных можно сформировать следующий запрос на чтение данных из других ячеек выбранной строки, или выдать команду на закрытие строки которая выражается в виде tRP указанное в виде третьего параметра из «х-х-х-...». Во время закрытия строки, данные из буфера записываются обратно в строку блока, после окончания записи можно выбрать другую строку в данном блоке. Кроме этих трех параметров есть минимальное время в течении которого строка должна быть активна «tRAS», и минимальное время полного цикла работы со строкой разделяющего две команды по активизации строки (влияет на случайный доступ).
grossws 19 апреля 2016 в 12:40
CL — CAS latency, tRCD — RAS to CAS delay, tRP — row precharge, CAS — column address strobe, RAS — row address strobe.
Быстродействие полупроводниковой техники определяется задержками элементов схемы. Для того чтобы на выходе получить достоверную информацию, необходимо выждать определенное время для того чтобы все элементы приняли устойчивое состояние. В зависимости от текущего состояния банка памяти меняется время доступа к данным, но в целом можно охарактеризовать следующие переходы:
Если блок находится в состоянии покоя (нет активной строки), контроллер выдает команду выбора строки, в результате двоичный номер строки преобразуется в позиционный номер, и происходит чтение содержимого строки за время «tRCD».
После того как содержимое строки было считано в буферную зону, можно выдавать команду выбора столбца, по которой двоичный номер столбца преобразуется в позиционый номер, за время «CL», но в зависимости от выравнивания младших адресов может поменяться очередность передачи бит.
Перед тем как сменить/закрыть строку, необходимо записать данные на место, так как во время чтения, информация была фактически уничтожена. Время необходимое на восстановление информации в строке «tRP».
По полной спецификации для динамической памяти есть еще множество временных параметров определяющих очередность и задержки изменения управляющих сигналов. Одним из таких является «tRCmin» определяющее минимальное время полного цикла строки, включающее в себя: выбор строки, доступ к данным и обратную запись.
Сигнал RAS определяет факт выдачи адреса строки;
Сигнал CAS определяет факт выдачи адреса столбца.
Если раньше все управление перекладывалось на сторону контроллера памяти и управлялось данными сигналами, то сейчас идет режим команд, когда в модуль/микросхему выдается команда, а спустя некоторое время идет передача данных. Более подробно лучше ознакомиться в спецификации стандарта, например DDR4.
Если говорить о работе с dram в общем, то при массовом чтении она обычно выглядит следующим образом:
выставили адрес строки,
выставили RAS (и через такт сняли),
выждали tRCD,
выставили адрес колонки с которой читаем (и каждый следующий такт выставляем следующий номер колонки),
выставили CAS,
выждали CL, начали читать данные,
сняли CAS, прочитали остаток данных (ещё CL тактов).
При переходе не следующий ряд делается precharge (RAS + WE), выжидается tRP, выполняется RAS с установленным адресом строки и далее выполняется чтение как описано выше.
Latency чтения случайной ячейки естественным образом вытекает из описанного выше: tRP + tRCD + CL.
В действительности зависит от предыдущего состояния «банка памяти» к которому идет обращение.
Нужно обязательно помнить что у оперативной памяти DDR есть две частоты:
— основная тактовая частота определяющая темп передачи команд и тайминги;
— эффективная частота передачи данных (удвоенная тактовая частота, которой и маркируются модули памяти).
Интеграция контроллера памяти увеличило быстродействия подсистемы памяти за счет отказа от промежуточного передающего звена. Увеличение каналов памяти требудет учитывать это со стороны приложения, так например четырех канальный режим при определенном расположении файлов не дает прироста производительности (12 и 14 конфигурации).
Обработка одного элемента связного списка с разным шагом (1 шаг = 16 байт)

Теперь немного математики
Процессор: рабочие частоты процессоров сейчас достигают 5 ГГц. По заявлениям производителей, схемотехнические решения (конвейеры, предсказания и прочие хитрости) позволяют выполнять одну инструкцию за такт. Для округления расчетов возьмем значение тактовой частоты в 4 ГГц что даст нам одну операцию за 0,25 нс.
Оперативная память: возьмем для примера оперативную память нового формата DDR4-2133 с таймингом 15-15-15.
Дано:
процессор
Fтакт = 4 ГГц
Tтакт = 0,25 нс (по совместительству время выполнения одной операции «условно»)
Оперативная память DDR4-2133
Fтакт = 1066 МГц
Fдата = 2133 МГц
tтакт = 0,94 нс
tдата = 0,47 нс
СПДмакс = 2133 МГц * 64 = 17064 Мбайт/с (скорость передачи данных)
tRCmin = 50 нс (минимальное время между двумя активациями строк)
Время получения данных
Из регистров и кэша, данные могут быть предоставлены в течении рабочего такта (регистры, кэш 1 уровня) или с задержкой в несколько тактов процессора для кэша 2-го и 3-го уровня.
Для оперативной памяти ситуация похуже:
— время выбора строки составляет: 15 clk * 0,94 нс = 14 нс
— время до получения данных с команды выбора столбца: 15 clk * 0,94 нс = 14 нс
— время закрытия строки: 15 clk * 0,94 нс = 14 нс (кто бы подумал)
Из чего следует что время между командой запрашивающей данные из ячейки памяти (в случае если в кэш не попали) может варьироваться:
14 нс — данные находятся в уже выбранной строке;
28 нс — данные находятся в невыбранной строке при условии что предыдущая строка уже закрыта (блок в состоянии «idle»);
42-50 нс — данные находятся в другой строке, при этом текущая строка нуждается в закрытии.
Количество операций которые может выполнить (вышеобозначенный) процессор за это время составляет от 56 (14 нс) до 200 (50 нс смена строки). Отдельно стоить отметить что ко времени между командой выбора столбца и получением всего пакета данных добавляется задержка загрузки строки кэша: 8 бит пакета * 0,47 нс = 3,76 нс. Для ситуации когда данные будут доступны «программе» только после загрузки строки кэша (кто знает что и как там накрутили разработчики процессоров, память по спецификации позволяет выдать нужные данные вперед), мы получаем еще до 15-и пропущенных тактов.
В рамках одной работы я проводил исследование скорости работы памяти, полученные результаты показали, что полностью «утилизировать» пропускную способность памяти возможно только в операциях последовательного обращения к памяти, в случае произвольного доступа увеличивается время обработки (на примере связного списка из 32-х битного указателя и трех двойных слов одно из которых обновляется) с 4-10 (последовательный доступ) до 60-120 нс (смена строк) что дает разницу в скорости обработки в 12-15 раз.
Скорость обработки данных
Для выбранного модуля имеем пиковую пропускную способность в 17064 Мбайт/с. Что для частоты в 4 ГГц дает возможность обрабатывать за такт 32-х битные слова (17064 Мб / 4000 МГц = 4,266 байт на такт). Здесь накладываются следующие ограничения:
— без явного планирования загрузки кэша, процессор будет вынужден простаивать (чем выше частота, тем больше ядро просто ждет данные);
— в циклах «чтение модификация запись» скорость обработки снижается в два раза;
— многоядерные процессоры разделят между ядрами пропускную способность шины памяти, а для ситуации когда будут конкурирующие запросы (вырожденный случай), производительность работы памяти может ухудшиться в «200 раз (смена строк) * Х ядер».
Посчитаем:
17064 Мбайт/с / 8 ядер = 2133 Мбайт/с на ядро в оптимальном случае.
17064 Мбайт/с / (8 ядер * 200 пропущенных операций) = 10 Мбайт/с на ядро для вырожденного случая.
В переводе на операции получаем для 8-и ядерного процессора: от 15 до 400 операций на обработку байта данных, или от 60 до 1600 операций/тактов на обработку 32-х битного слова.
На мой взгляд медленно как-то. По сравнению с памятью DDR3-1333 9-9-9, где время полного цикла примерно равно 50 нс, но отличаются время таймингов:
— время доступа к данным уменьшается до 13,5 нс (1,5 нс * 9 тактов);
— время передачи пакета из восьми слов 6 нс (0,75 * 8 вместо 3.75 нс) и при случайном доступе к памяти, разница в скорости передачи данных практически исчезает;
— пиковая скорость составит 10 664 МБайт/с.
Не слишком все далеко ушло. Ситуацию немного спасает наличие в модулях памяти «банков». Каждый «банк» представляет собой отдельную таблицу памяти к которой можно обращаться раздельно, что дает возможность сменить строку в одном банке пока идет чтение/запись данных из строки другого, за счет уменьшения простоя позволяет «забить» шину обмена данными под завязку в оптимизированных ситуациях.
Собственно здесь пошли нелепые идеи
Таблица памяти, содержит в себе заданное количество столбцов, равное 512, 1024, 2048 бит. С учетом времени цикла по активации строк в 50 нс, мы получаем потенциальную скорость обмена данными: «1/0,00000005 с * 512 столбцов * 64 бит слово = 81 920 Мбайт/с» вместо текущих 17 064 Мбайт/с (163 840 и 327 680 МБайт/с для строк из 1024 и 2048 столбцов). Скажете: «всего раз в 5 (4,8) быстрее», на что я отвечу: «это скорость обмена, когда все конкурирующие запросы обращены к одному банку памяти, и доступная пропускная возможность увеличивается пропорционально количеству банков, и увеличением длины строки каждой таблицы (потребует увеличение длины операционной строки), что в свою очередь упирается главным образом в скорость шины обмена данными».
Смена режима обмена данными потребует передачи всего содержимого строки в кэш нижнего уровня, для чего надо разделить уровни кэша не только по скорости работы, но и по размеру кэш строки. Так например реализовав «длину» строки кэша N-го уровня в (512 столбцов * 64 размер слова) 32 768 бит, мы можем за счет уменьшения количества операций сравнения увеличить общее количество строк кэша и соответственно увеличить максимальный его объем. Но если сделать параллельную шину в кэше такого размера, мы можем получить уменьшение частоты функционирования, из чего можно применить другой подход организации кэша, если разбить указанную «Jumbo»-строку кэша на блоки по длине строки верхнего кэша и производить обмен с небольшими порциями, это позволит сохранить частоту функционирования, разделив задержку доступа на этапы: поиск строки кэша, и выборку нужного «слова», в найденной строке.
Что касается непосредственно обмена между кэшем и основной памятью: необходимо передавать данные с темпом обращения к строкам одного банка, или имея определенный запас для распределения запросов к разным банкам. Помимо этого, есть сложность со временем доступа к данным размещенным в разных областях строки, для последовательной передачи помимо первоначальной задержки связанной с выборкой строки, есть задержка передачи данных зависящей от количества данных «в пакете», и скорости передачи. Даже подход «rambus» может не справиться с возросшей нагрузкой. Ситуацию может спасти переход на последовательную шину (возможно дифференциальную), за счет дальнейшего уменьшения разрядности данных, мы можем увеличить пропускную скорость канала, я для уменьшения времени между передачей первого и последнего бита данных, применить разделение передачи строки на несколько каналов. Что позволит использовать меньшую тактовую частоту одного канала.
Оценим скорость такого канала:
1/0,00000005 нс = 20 МГц (частота смены строк в рамках одного блока)
20 Мгц * 32 768 бит = 655 360 Мбит/с
Для дифференциальной передачи с тем-же размером шины данных получаем:
655 360 Мбит/с / 32 канала = 20 480 Мбит/с на канал.
Такая скорость выглядит приемлемо для электрического сигнала (10 Гбит/с для сигнала со встроенной синхронизацией на 15 метров доступен, почему бы и 20 ГБит/с с внешней синхронизацией на 1 метр не осилить), однако необходимое дальнейшее увеличение скорости передачи для уменьшения задержки передачи между первым и последним битом информации, может потребовать увеличения пропускной способности, с возможной интеграцией оптического канала передачи, но это уже вопрос к схемотехникам, у меня маловато опыта работы с такими частотами.
и тут Остапа понесло
Изменение концепции проецирования кэша на основную память к использованию «основной памяти как промежуточного сверхбыстродействующего блочного накопителя» позволит переложить предсказание загрузки данных с схемотехники контроллера на алгоритм обработки (а уж кому лучше знать куда он ломанется через некоторое время, явно не контроллеру памяти), что в свою очередь позволит увеличить объем кэша внешнего уровня, без ущерба производительности.
Если пойти дальше можно дополнительно изменить концепцию ориентирования архитектуры процессора с «переключение контекста исполнительного устройства», на «рабочее окружение программы». Такое изменение может существенно улучшить безопасность кода через определение программы как набора функций с заданными точками входа отдельных процедур, доступным регионом размещения данных для обработки, и возможностью аппаратного контроля возможности вызова той или иной функции из других процессов. Такая смена позволит также эффективнее использовать многоядерные процессоры за счет избавления от переключения контекста для части потоков, а для обработки событий использовать отдельный поток в рамках доступного окружения «процесса», что позволит эффективнее использовать 100+ ядерные системы.
P.S.: случайное использование зарегистрированных товарных знаков или патентов является случайным. Все оригинальные идеи доступны для использования по лицензионному соглашению «муравейник».
Комментарии (53)
novice2001
19.04.2016 15:06+1А можно узнать, какую практическую задачу должно решать вот это все?
Т.е. в каких именно задачах из реального мира не хватает пропускной способности памяти?
kasperos
19.04.2016 16:01Пропускная способность памяти увеличена за счет количества каналов, теперь представьте себе ситуацию когда все необходимые данные расположены на одном модуле (вполне рабочая ситуация).
Проще решить вопрос с размером кэша 3-го уровня.
Не забывайте что кроме нужного 1 байта, вместе с ним прилетает в компании еще 31-63 байта. Для ситуации с обходом связных списков (деревьев), повышенная пропускная способность в купе с оптимизацией размещения данных, позволит ускорить обработку таблиц баз данных состоящих из количества рабочих элементов превышающих размер кэша.novice2001
19.04.2016 23:05+3Нужно использовать оптимальные структуры данных, а не брутфорсить железом ситуацию, когда лишние байты неизбежно будут читаться вместе с необходимыми.
И так уже имеем ситуацию, когда в кармане у каждого лежит многоядерный компьютер, мощнее, чем любой суперкомпьютер 60-х годов или управляющий компьютер «Шаттла» или «Бурана», но используемый настолько неоптимально, что даже отрисовка UI на нем может тормозить.
КМК предложенные решения совершенно неоптимальны. Объем кэша ограничен отнюдь не «малой» длиной его строки, а «транзисторным бюджетом», т.е. размером кристалла, его стоимостью и энергопотреблением. Сверхдлинные строки кэша приведут к тому, что для доступа к одному байту придется читать уже не 31/63 лишних байта, а 4095. И когда понадобится освободить одну из строк кэша, в память придется записать целых 4 Кб, что почти на 2 порядка дольше записи стандартной 64-байтной строки. Соответственно, это катастрофически увеличит латентность. Предзагрузка в кэш реализована уже давным-давно, поэтому если встроенный prefetcher не справляется с каким-то хитрым шаблоном, то никто не мешает приложению самому загружать необходимые данные. Ну и т.п.kasperos
20.04.2016 10:48Задачка на масштабирование обработки данных
есть связный список из N элементов
«указатель на следующий элемент», «некое число 32 бит для сравнения (не равно 0)», «32-х битное число для инкремента (заставить строку кэша записаться назад в память)», «32-х битное число для выравнивания» — итого L=16 байт.
Обход списка оценивается как O=N
Из этого можно предположить что многократная обработка займет пропорциональное время в следующих ситуациях:
N=(100*N)/100=(1000*N)/1000
X=Z*N -> N=(100*X)/(100*Z)
Однако если «X * L» превысит объем кэша, если скорость обработки данных превысит скорость доступа к данным (которая может быть увеличена только за счет многоканальности), никакая оптимизация не поможет сохранить отношение:
N = (100*1)/100 = (100*N)/100 = (100*X)/(100*Z) при N*L*16 < K < X*L, и X = Z * N
Здесь 16 это множитель с запасом для уменьшения влияния канальности кэша.
Сможете доказать обратное?
HINT: самая быстрая скорость обработки будет в ситуации когда элементы списка размещены последовательно друг за другом.
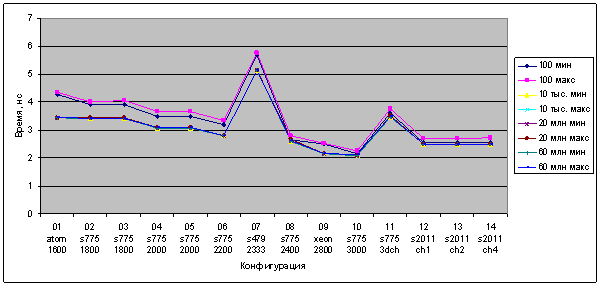
i7-3820 с частотой 3600 МГц и памятью DDR3-1600 обрабатывал списки (длиной 1,100, 1000) размещенные в кэше с темпом 2,5 нс на элемент
обработка списка из 1 000 000 элементов была с темпом 2,96 нс для 4-х канальной памяти, 3 нс для 2-х канальной, и 3,5 нс для одноканальной памяти. При этом был не самый быстрый «код», можно сделать и побыстрее.
код ассемблераxor edx, edx
mov ebx, ds:[start_pointer]
next:
cmp ebx, 0
jne @f
ret
@@:
inc dword ptr es:[ebx+12]
mov eax, es:[ebx]
mov ebx, eax
inc edx
dec ecx
jnz next
ret
novice2001
20.04.2016 12:32+11. Я нигде не утверждал, что размер кэша не влияет на скорость доступа. Я утверждал, что в существующих условиях размер кэша ограничен не малой длиной строки, а стоимостью и энергопотреблением.
2. Утверждение о том, что темп для данных в кэше и в памяти таков-то без указания в каком именно кэше не имеет смысла. В процессорах, начиная с архитектуры Nehalem латентность кэша L1D выросла с 3 до 4 тактов. А латентность доступа к Last Level Cache (L2 у Wolfdale и L3 у Ivy Bridge) при сравнимом объеме у Wolfdale вообще двое ниже — 15 тактов против ~30. Так что пока данные умещаются в L1D или превышают объем L2 Ivy Bridge, но умещаются в L2 Wolfdale последний будет быстрее, даже несмотря на меньшую частоту именно благодаря значительно меньшей латентности кэша. Но как только объем данных значительно превысит размер кэша, любой процессор с интегрированным контроллером памяти (iMC) будет превосходить по скорости работы процессор без IMC буквально в разы.
3. Я недаром спрашивал про ПРАКТИЧЕСКУЮ задачу, которую должно решать глобальное изменение архитектуры. Как и ожидалось, вместо практической задачи представлен сферический конь в вакууме, где как минимум 25% объема памяти теряется на абсолютно бессмысленное выравнивание, соответственно 25% объема кэша и 25% ПСП теряются впустую.
4. Мне неясен философский смысл инкремента edx и декремента ecx в приведенном ассемблерном коде. Они никуда не записываются и ни с чем не сравниваются.
Итого. Будет реальная задача, для которой так уж необходима глобальная перестройка всей архитектуры компьютеров? Естественно с кодом. С полным кодом, а не выдранным куском. Который можно скомпилировать/сассемблировать, измерить скорость, оптимизировать и т.п.khim
20.04.2016 12:41Я утверждал, что в существующих условиях размер кэша ограничен не малой длиной строки, а стоимостью и энергопотреблением.
Если бы. Вы знаете сколько стоит и потребляет какой-нибудь POWER8? А у него ведь кеш такого же размера, как у всех: всё те же 64K.
Это физическое ограничение — выше головы не прыгнешь.
Остальное — всё верно.novice2001
20.04.2016 12:59Можно узнать какие физические законы нарушает кэш размером более 64К?
khim
20.04.2016 13:22Причём тут физические законы? Тут простая банальная логика. Процессорное ядро и кеш должны быть сравнимы по размерам и, стало быть, по количеству транзисторов. Кеш может быть чуть больше, так как провода там «прямее», но не сильно. Два кеша по 64K кеша требуют, грубо, 5-6 миллионов транзисторов (4-6 на ячейку SRAM плюс ещё нужно тегирование и прочие накладыне расходы) — то есть как раз примерно столько же, сколько занимает современное процессорное ядро.
Можно сделать больше? Да, конечно. Но смысл? Придётся снижать частоту всей системы, что в 99 случаях из 100 даст в результате проигрыш.novice2001
20.04.2016 13:30Частоту системы не приходится снижать даже для многомегабайтных кэшей L3.
Еще попытка?khim
20.04.2016 13:36+1Частоту системы не приходится снижать даже для многомегабайтных кэшей L3.
Процессор отдающий данные за 4 такта из «многомегабайтного кеша L3» — в студию!
Еще попытка?
А может хватит изображать из себя идиота, а?novice2001
20.04.2016 13:48Идиота тут скорее изображаете именно вы.
Не надо путать ПСП и латентность. ПСП зависит от ширины шины и частоты. А латентность еще и от организации кэша.khim
20.04.2016 14:02ПСП зависит от ширины шины и частоты.
Это ещё с какого перепугу? Кто вам сказал что кеш L3 (или, тем более, оперативная память) смогут вам каждый такт данные поставлять?
А латентность еще и от организации кэша.
Тут вы правы, но лишь отчасти. Плохая организация кеша может её увеличть, но никакая организация кеша не сможет её ускорить. Кеш L3 как выдавал данные за десятки тактов, так и выдаёт. И ничего вы с этим не сделаете.
Домашнее задание: подумать над тем как увеличит скорость работы кеша увеличение частоты на которой он работает. Как поймёте почему правильный ответ «теоретически в предельном случае можно достигнуть увеличения скорости в два раза, но на практике эффект не превышает 20-30%» — заходите, будет о чём поговорить.novice2001
20.04.2016 15:34Знаете, я не заметил, чтобы вы были ведущим инженером-архитектором Intel или IBM, чтобы с таким апломбом выдавать мне «домашнее задание».
И стоит избавиться от идиотской привычки возражать на то, чего оппонент никогда не говорил.
Независимо от того, может или не может L3 кэш выдавать данные каждый такт, его ПСП прямо пропорциональна тактовой частоте, его латентность в тактах от частоты не зависит, а в наносекундах — обратно пропорциональна ей.
Как только сможете тестами опровергнуть это — заходите, будет о чем поговорить.
kasperos
20.04.2016 15:201. Объем кэша 3-го уровня превышает 10 мб, однако скорость доступа к нему гораздо медленнее по простой причине: время необходимое выждать чтобы каждый из элементов строк кэша смог проверить соответствие хранимой информации, запрошенному адресу выше для большего количества элементов.
3. База данных с количеством элементов, индексное поле которой превышает в несколько раз объем кэша. Конечно, это задача из разряда «640 кб, этого объема должно хватить всем»
4. edx — рудимент, проверить что количество циклов соответствует заданному количеству, связный список зациклен, те сначала идет подготовка списка из N-элементов, при этом последний элемент ссылается на первый.
ecx — если внимательно посмотреть, определяет «выход» по достижению заданного количества циклов. Команда DEC при получении 0 в уменьшаемой переменной обнуляет флаг Z, дальше идет JNZ который осуществляет переход если флаг нуля не говорит что был ноль. Но видимо нужно было поставить:
DEC ECX
CMP ECX, 0
JNZ NEXT
проверка «cmp ebx,0» это «имитация бурной деятельности», в реальности список зациклен, и ebx не получает 0.
2. «чисто для смеха» я уменьшил код до:
next:
inc dword ptr es:[ebx+12]
mov ebx, es:[ebx]
dec ecx
jnz next
ret
под рукой был только Atom-1600 MHz и i7-980 3333 MHz 3ch DDR3-1600
будут четыре значения соответсвующие длинному и короткому коду для атома и для i7
записей/количество циклов
100/10: 3,4 / 2,5 / 3,0 / 1,5
1000/10: 3,4 / 2,5 / 3,0 / 1,5
1млн/20: 15 / 14,87 / Х / 5 (лень было восстановить длинный код, поэтому измерения нет)
1млн/60: 14,9 / 14,9 / X / 4,8
1/10000: 3,4 / 2,5 / 3,0 / 1,5 (Да, это интенсивная обработка 16 байт)
1/100: 4,7 / 3,6 / 3,2 / 1,7
(если кому интересно то отключение кэширования замедляет работу в 100-1000 раз
а старенький Xeon судя по результатам измерений, сделал вид что ему кэш не отключали)
тактовая частота 1600 = 0,625 нс / 3333 = 0,3 нс
3,4 нс = 5+ тактов, 15 нс = 24 такта
1,5 нс = 5 тактов процессора i7 (4 активных команды, в принципе совпадает)
5 нс = порядка 16 тактов (погодите, только что тот-же процессор все делал за 5-6 тактов)
наблюдается четкая разница в 3 раза для работы встроенного контроллера, между работой с данными в кэше и с данными в памяти
ДЛЯ ЖУТКО ОПТИМИЗИРОВАННЫХ ДАННЫХ но разного объема.
Реальная задача на текущий момент это обработка больших объемов информации. Для примера можно взять хоть и не совсем удачный пример Учёт в муравейнике.novice2001
20.04.2016 16:02Начнем с конца. «Учет в муравейнике» — это I/O bound задача. Причем даже не I/O памяти, а практически безумно медленного по сравнению с процессором HDD. Так что никакое увеличение ПСП памяти там не поможет принципиально.
Далее. Объем L3 кэша среднего Core i5 и старших 2-ядерных Wolfdale равны (по 6 МБ). При этом у Wolfdale вдвое выше ассоциативность и вдвое же ниже латентность. Так что количество строк само по себе на скорость не влияет.
Еще далее. Не нужны пустые слова. Нужна КОНКРЕТНАЯ практическая задача. Пока вижу сферического коня в вакууме. И он стал еще сферичнее, а вакуум еще глубже.
Т.е. по сути никакой практической задачи нет и не предвидится. Есть гениальная задумка, для доказательства которой приводится абсолютно бессмысленный тест. Ну да, если вам действительно нужно исполнять с предельной скоростью эти 5 инструкций в такой последовательности, то всенепременно нужно потратить триллионы долларов, чтобы кардинально поменять архитектуру компьютеров.
Причем даже в этой совершенно вырожденной задаче ПОЛОВИНА ПСП и объема кэша тратится совершенно впустую. Потому что мало того, что используется абсолютно бессмысленное выравнивание, так еще и второй элемент вообще никак не используется.kasperos
20.04.2016 16:51Обход двоичных деревьев достаточно реальная задача?
2 указателя, 1 сравнение, 1 нагрузка для выравнивания.
Ограничиваемся 32-х битными значениями. Предложите «эффективную структуру/алгоритм» для текущей архитектуры, я предложу свои «теоретические расчеты и алгоритм».
Завтра встречаемся здесь же.novice2001
20.04.2016 17:26Это может быть и реальная задача, которую предложили решить студенту. Но при этом очередной бессмысленный сферический конь в вакууме.
Я спрашивал про ПРАКТИЧЕСКУЮ задачу. Система продажи билетов, например. Тот же «муравейник». Разница понятна?
Из практической задачи естественным образом вытекают ее ограничения. А в сферической задаче в вакууме они придуманы произвольным образом.
Практическую задачу можно решать с помощью различных алгоритмов и структур данных. И совсем не обязательно это будут двоичные деревья.
А у вас опять совершенно вырожденный случай, где деревья не несут никакой полезной информации — есть ключ, есть 2 указателя, есть совершенно бессмысленное выравнивание, а никаких хранимых данных нет. Ок, можно «выравнивание» посчитать полезной нагрузкой. Вы действительно считаете, что структура с 75% служебных и 25% полезных данных оптимальна?kasperos
20.04.2016 18:22Насчет сферических коней в вакууме это вы физикам скажите. У них сначала «сферический конь в вакууме» в теории образуется, а потом они строят всякие ускорители за миллиарды, чтобы подтвердить или опровергнуть существование этого коня.
качаем отсюда архивчик
Планируем сервис по определению действительности паспорта из расчета однопоточного приложения.novice2001
20.04.2016 19:00Сферический конь в вакууме образовался у физиков не в теории, а в анекдоте. Именно как случай крайнего вырождения модели, которая и близко не напоминает оригинал.
Ну, ОК. Скачал я эту базу и распаковал. Имеем файл примерно со ~100 млн. записей.
Насколько я понимаю, требуется по вводимым серии и номеру определить есть ли паспорт среди недействительных.
Какова частота обновления самой базы? Какова архитектура машины, на которой это должно работать (х86/х64)?
novice2001
20.04.2016 19:07И вдогонку: ваши предложения по структурам данных и алгоритмам.
kasperos
20.04.2016 20:29На ваш выбор, должно быть быстро, и в разумных пределах (по расходу памяти). Хочу отдельно отметить что там есть номера старого формата с римскими числами «XX-М,559701» так что:
Средняя длина номера паспорта 12 символов включая разделитель и символ в запас.
Ограничимся кодовой таблицей из 256 символов но на каждом месте.
Может получится в «интерпол» продать алгоритм, там может понадобиться широкий диапазон вариантов номеров.novice2001
20.04.2016 21:18Вы опять превращаете конкретную практическую задачу в сферического коня.
Для задачи быстрого поиска недействительных российских паспортов мы можем взять априорные знания о том каким может и не может быть этот номер.
Плюс важна частота обновления этих данных, от этого тоже многое зависит.
Быстрый поиск недействительных российских паспортов — это одно, быстрый поиск всего чего угодно неизвестного заранее объема и длины — это совершенно другое. «Средняя длина» и «ограничимся» — это как раз то самое превращение коня с 4 ногами в шар.
И, кстати, номера советских паспортов в этой базе — нонсенс. Серия банально не умещается в заданном поле, это ошибочные данные, которые нужно отфильтровывать, а не обрабатывать, потому что корректно обработать их (реально, а не формально) просто невозможно.kasperos
21.04.2016 06:50На входе получаем строку из серии и номера паспорта, входные символы должны быть ограничены таблицей из 256 символов.
Делим символ на две половины, каждую половину представляем в виде узла из 16 указателей.
12 символов это дерево глубиной в 24 символа, при этом мы получаем динамическую структуру которой можно описать и более длинные строки. 50 нс * 24 прохода = 1,2 — 1,5 мкс, максимальное время поиска.
Это просто задача в лоб без учета «экономии», решить ее таким образом можно? можно.
Можно использовать таблицу указателей из 256 записей, тогда время поиска уменьшиться в два раза.kasperos
21.04.2016 07:58Чет я ступил, в 4096 байт влезет корень из 16 записей, и еще 16 по 16 = 256 указателей (1088 байт).
Что автоматически ускоряет поиск до 0,6-0,75 мкс.
novice2001
22.04.2016 16:00Меня всегда умиляет, как люди умудряются отвечать на вопросы, которые им не задавали.
Вот объясните мне, каким образом из конкретной практической задачи поиска номеров недействительных паспортов вырастают уши у задачи поиска произвольной строки длиной почему-то 12 символов?
Для конкретной практической задачи поиска номера паспорта все эти ваши деревья не нужны абсолютно. Соответственно, и предложения по глобальному изменению архитектуры, которые вытекают из вашего маниакального желания использовать для поиска в данном случае именно двоичные деревья — тоже.
Если вы разрабатываете новый академический алгоритм поиска строки — это совершенно другая история. Но даже в этом случае логично менять именно алгоритм, учитывая особенности железа, а не наоборот.kasperos
24.04.2016 21:07Какой-же Вы скучный человек, даже ругаться с вами скучно. Сидите спокойно себе на готовых технологиях. Покупайте всегда свеженький ифончик, а я пойду еще пару нелепых идей придумаю.
novice2001
24.04.2016 21:24+1Как я люблю людей, которые мнят себя великими новаторами, но при этом мыслят штампами. Это я про «свеженький ифончик».
А вы, да, продолжайте придумывать нелепые идеи.
Только не рассчитывайте, что они вдруг станут революционными. Потому что пока я вижу натягивание совы на глобус. Совершенно ненужное и баснословно дорогое. И вряд ли в других нелепых идеях это как-то изменится.kasperos
24.04.2016 21:35Из «законов Мерфи»: «Чтобы вы не делали, как бы не хорош был ваш поступок, всегда найдется недовольный человек».
Что такого баснословно дорогого в этой реализации? чисто поржать.novice2001
24.04.2016 21:46Ну так вы реализуйте свой подход, раз он недорог. Покажите всем его преимущества. Глядишь, люди к вам и потянутся. Какой нибудь Intel купит патент за миллиард-другой.
А менять архитектуру подсистемы памяти только из-за того, что кто-то применяет неоптимальные алгоритмы и структуры данных никто не будет.
И прикрываться «Законами Мерфи» не стоит. Во-первых, я пока не вижу вообще никакого поступка. И тем более нет ничего хорошего в идее брутфорсить железом неоптимальность софта.
khim
20.04.2016 12:37Кстати Pentium E5700 с частотой 3000 МГц обрабатывал списки в кэше с темпом 2,1 нс и 9,8 нс при доступе к памяти, это к вопросу что размер кэша не влияет на скорость доступа к нему.
Думалку включить слабо? Вы перепутали причину и следствие. Hint: процессор, выпущенный четверть века назад имел кеш в 32K, к началу XXI века объём был доведён до 64K — и такой же кеш в процессорах, выпускающихся сегодня.
Никто не стал бы создавать всех эти кеши 2го, 3го, 4го уровня, если бы «размер кеша не влиял на скорость доступа к нему». Влияет и ещё как! На полную частоту получается сделать32K-64K, не больше. ZX Spectrum работающий 5GHz с соотвествующей памятью сегодня, скорее всего, сделать удастся. А вот компьютер с гигабайтом или терабайтом оперативки — нет. И ничего ваши «широкие» каналы не изменят, только усложнят работу кеша. Больше 64K его сделать не удаётся, а размер строки в 4K при кеге в 64K — бессмысленен.novice2001
20.04.2016 13:05Боюсь, вы в корне заблуждаетесь.
ВСЕ кэши процессоров Sandy Bridge, Ivy Bridge и Haswell работают на «полной частоте».khim
20.04.2016 13:33ВСЕ кэши процессоров Sandy Bridge, Ivy Bridge и Haswell работают на «полной частоте».
Это что за чушь? Какой бы в них был смысл если бы так всё было? Оставили бы L3 и всё.
Или вы имеете в виду что в них сигнал синхронизации поноскоростной поступает? А какая разница?
Отдать данные они могут только на пониженной в 3-4 раза (L1) скорости, а то и в 15-30 раз (L2, L3, etc) скорости. А программе, в общем, без разницы какая частота заведена в какие части системы, тут время в наносекундах решает :-) Ну или в циклах (если вы хотим сравнивать не конкретные процессоры, а архитектуры). А в циклах — всё работает примерно так.
И если подумать то, в общем, сложно сделать чтобы оно работало по другому. Поднять ПСП кешей, конечно, можно, но без изменения архитектуры это всё — мёртвому припарки, так как задержки-то от этого не уменьшатся — скорее возростут!novice2001
20.04.2016 13:45Смысл именно в том, что ПСП и латентность — величины в некоторой степени ортогональные.
А такой величины как «скорость» в данном случае вообще не существует.khim
20.04.2016 14:40А такой величины как «скорость» в данном случае вообще не существует.
Это кто ж вам такую чушь сказал? Скорость — это произведение ширины шины время доставки данных.
Теоретически скорость можно повысить до заоблачных величин за счёт увеличения ширины шины, но практически — нет: чем «шире» у вас канал, тем выше задержки, но главное — задачи, выполняемые на CPU, гораздо более чувствительны именно к задержкам. Повышать ПСП за счёт увеличения задержек — чревато замедлением программ, а не ускорением.
На GPU — жизнь другая, там максимальная осмысленная ширина шины гораздо больше.
kasperos
20.04.2016 16:00Насколько я помню, я не заявлял что размер кэша не влияет на скорость доступа к нему, и связано это со временем ожидания пока все элементы списка получат адрес, проверят соответствие, и самый дальний (по сигналу) пошлет ответ «у меня! у меня есть эти данные».
khim
20.04.2016 12:31+1Не забывайте что кроме нужного 1 байта, вместе с ним прилетает в компании еще 31-63 байта. Для ситуации с обходом связных списков (деревьев)
… это приводит к тому, что увеличение «ширины» канала приводит к тому, что вы начинаете сильнее нагревать окружающаю среду — и только.
повышенная пропускная способность в купе с оптимизацией размещения данных
Так вы деревья обходите или «оптимизируете размещение данных»? Если первое, то «широкий» канал вам только мешать будет — и вы это сами только что объяснили. Если вы хотите «оптимизировать данные», то к вашим услугам GPU и HBM.
Вы уж определитесь — чего вы хотите, а потом и обсуждать можно.

gorodnev
19.04.2016 21:08Не увидел раздела «Ссылки», но без сомнений для всех заинтересовавшихся пригодится книга «Что каждый программист должен знать о памяти» — rus-linux.net/lib.php?name=/MyLDP/hard/memory/memory.html

Psychosynthesis
27.04.2016 03:13Вашу бы изобретательность да на доработку программных алгоритмов…
khim
27.04.2016 10:55Ничего не поможет. Этим занимаются десятки тысяч программистов, но проблема в том, что любые их достижения с готовностью «просираются», когда «миллионы хомячков» используют их, чтобы построить ещё более высокую башню технологий. Потери на каждом «этаже» это баншли вроде невелики (где-то 20-30%), но при наличии 10-20 этажей оказывается, что 99% ресурсов современных компьютеров уходит, грубо говоря, «в песок».
В случае необходимости в этой башне пробивается «дыра» для решения какой-то задачи — и тогда получается, что «в песок» уходит не 99% ресурсов, а, скажем, 90%. Иногда даже, о боги, «в дело» идёт 90%!
Но вообще — законы Натана действуют. Особенно первый.Psychosynthesis
27.04.2016 13:57Сдаётся мне, операционки не «хомяки» пишут. Так почему это сейчас чтобы запустить окошки нужно минимум в десять раз больше мощности чем 15 лет назад?
Можете не отвечать, я знаю почему. Это был скорее риторический вопрос, к вопросу о улучшении алгоритмов.khim
27.04.2016 15:42Сдаётся мне, операционки не «хомяки» пишут.
С чего вы решили? Большая часть того, что сейчас понимается под словом «операционка» — как раз написано «миллионом сумасшедших хомячков».
И даже люди, которые могли бы сделать лучше не не делают этого, так как времени нет. Вплоть до того, что некоторые модули оказывают буквально в 30-50 раз больше и требуют во столько же раз больше ресурсов, чем могли бы!
kasperos
28.04.2016 13:4515 лет назад стандартное разрешение экрана составляло 1024*768 точек при 16 бит цвете (1 572 864 байт).
Сейчас 1920*1080*32 бит (8 294 400 байт), уже это дает практически порядок в объеме данных для обработки, хотя частота функционирования процессоров увеличилась разве что в 2-4 раза.
Помимо этого сейчас мало кто пишет на низком уровне, всем подавай готовые модули и библиотеки для ускорения написания программ что не особо сказывается на производительности.novice2001
29.04.2016 16:27-1Как связан объем фреймбуфера с частотой процессоров?
khim
29.04.2016 16:35А как связана грузоподъёмность автомобиля с мощностью его движка?
novice2001
29.04.2016 17:42-1Открою страшный секрет — никак.
khim
29.04.2016 19:15Карьерный самосвал с грузоподъёмностью 100 тонн и движком в 100 лошадей — в студию!
novice2001
29.04.2016 21:13Нет ни одной технической причины, которая не позволяла бы построить такой самосвал.
Есть ограничение экономического, эксплуатационного характера — такой самосвал будет очень медленно ездить.
Но к грузоподъемности мощность двигателя не имеет никакого отношения. И любому инженеру это очевидно.
novice2001
29.04.2016 16:35-1Можно узнать какие именно «ресурсы» уходят «в песок» на 99%? Ну, хотя бы на 90?
grossws
Стоило бы расшифровать, что CL — CAS latency, tRCD — RAS to CAS delay, tRP — row precharge, CAS — column address strobe, RAS — row address strobe, а также объяснить откуда они берутся и зачем они нужны.
Если говорить о работе с dram в общем, то при массовом чтении она обычно выглядит следующим образом:
При переходе не следующий ряд делается precharge (RAS + WE), выжидается tRP, выполняется RAS с установленным адресом строки и далее выполняется чтение как описано выше.
Latency чтения случайной ячейки естественным образом вытекает из описанного выше: tRP + tRCD + CL.
Вам не показалось это странным, когда писали? 4-8 бит — это 1/2-1 байт, а 4-8 слов обычно 16-64 байта (в зависимости от размера слова). Шина SDRAM обычно не менее 32 бит, так что по 4-8 бит уж точно никто не читает.
kasperos
Добавлю цитату.
В контексте «блока/таблицы памяти» выдача идет по битам, в контексте модуля по 64-битным словам, сами микросхемы могут иметь различную разрядность шины данных, из за чего зависит их количество на модуле памяти. В результате во время обращения к памяти идет пересылка 256/512 бит, или 32/64 байт, или 4/8 64-х битных слов. При этом не используется хранение байта целиком в одной строке одного блока памяти, он размещается побитно в 8-ми различных блоках памяти внутри одной или нескольких микросхем по идентичному геометрическому адресу «ROW x COL». Хотя ничего не мешает разместить все 64-битное слово в одной строке, но такой подход существенно замедлит операции последовательного чтения из за увеличения частоты смены строк. Так что мне не показалось странным указать что пересылка идет пакетом 4-8 бит/СЛОВ.