
Я занимаюсь внедрением продуктов мониторинга от компании IBM и мне стало интересно, чего достиг open source в сравнении с решениями от IBM в направлении мониторинга железа и программного обеспечения. Для чего я стал устанавливать наиболее популярные системы мониторинга из мира open source и читать документацию. Меня в основном интересовали архитектура решений. В мое поле зрения попали следующие open source продукты: Zabbix, Nagios, NetXMS. Я счел их наиболее популярными и часто упоминаемыми. Все их можно сравнить с IBM Tivoli Monitoring (ITM). ITM это ядро мониторинга сервисов от IBM. В результате решил описать не документируемую архитектуру ITM продукта, которая и является преимуществом в крупных инсталляциях.
Стоит упомянут, что ITM не единственный продукт такого функционала у IBM на сегодняшний день. Недавно появился продукт под названием IBM Application Performance Management, но про его архитектуру в другой раз.
В виду особенности ITM не рекомендуется его использовать для мониторинга большого числа сетевого оборудования. Бывают всякие необычные ситуации, но обычно для этого применяют IBM Tivoli Network Manager.
Упомяну о zabbix. Я часто его встречал у заказчиков и много наслышан. Один раз меня заказчик сильно поразил требованиями получать данные с агента каждые 10 секунд. Он же был сильно разочарован, что в ITM нельзя создать триггеры по среднему за период (если на спор, то можно наворотить костылей, но зачем?). Он был знаком с zabbix.
В zabbix (схожая ситуация и с NetXMS) триггеры анализируют исторические данные. Это очень круто, но у меня никогда такой нужны не возникало. Агент zabbix передает данные серверу (или через zabbix прокси). Данные сохраняются в базе данных. После чего по ним отрабатывают триггеры, а мощная система макросов им помогает. Отсюда появляются требования к производительности железа для выполнения основного функционала.
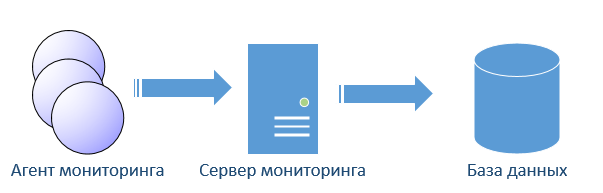
В ITM свои особенности. Сервер ITM все данные получает исключительно от агентов. Никаких встроенных протоколов SNMP и т. п. Сервер представляет собой многопоточное приложение со встроенной базой данных. Особенность ITM в работе триггеров (они же ситуации, но для соблюдения общей терминологии буду назвать триггеры). Триггеры исполняются на агенте. В добавок эти триггеры представляют собой sql-запросы с условием. Сервер компилирует триггеры в бинарный sql-код и отдает агенту на исполнение. Архитектура агента такова, что он похож на базу данных.
Всевозможные метрики уже встроенные в агент (относительно недавно добавили возможность получение данных от приложений/скриптов) и описаны как таблички в реляционной базе данных. Агент исполняет sql запрос согласно заданного интервала. Прослойка, которую дилетантски назову «база данных», выполняет необходимы запросы к операционной системе(ОС) и кладет данные виде таблицы. Частота запросов к ОС не чаще 30 сек. То есть данные в таблице чаще 30 сек. не обновить. Понятно, что агент может исполнять множество однообразных триггеров, что не сильно скажется на загрузке, поскольку опять-таки чаще 30 сек. данные он собирать не будет. Интересно еще то, что агент не будет тревожить сервер до тех пор пока выполняемый им sql запрос возвращает 0 строк. Как только sql запрос вернул несколько строк, все эти строки уйдут на сервер (условие триггера наступило). Сервер в свою очередь, положит данные во временную таблицу до момента пока по ней не пройдется отдельный поток, который проверит на дополнительные условия и сгенерирует событие в системе. Предвещая вопрос как же агент обрабатывает события, например логи? Там с этим все нормально, такие данные агент сразу отправляет на сервер в активном режиме.
Отсюда вывод. База данных сервера ITM не содержит историю, только оперативные данные. Триггеры исполняются на стороне агента который примет на себя часть нагрузки.
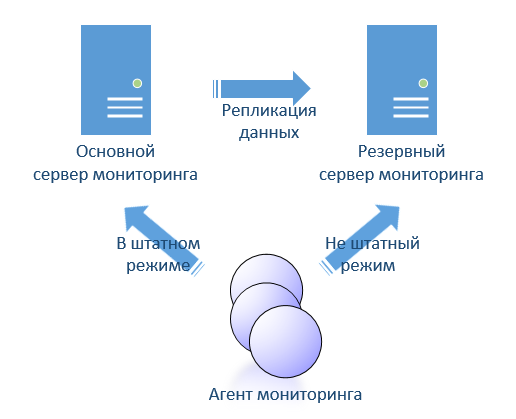
Так же рассматривая open source я сразу задавался вопросом реализации отказоустойчивости. Я не увидел того чего хотелось бы. Поскольку ITM позволяет реализовать hot-stanby (горячее резервирования), то хотелось бы что-нибудь вроде такого в open source. В ITM это реализовано достаточно просто. Два сервера, которые реплицируют свои базы от активного к пассивному. В настройках агента указаны оба сервера. Агенты переключаются между двумя серверами автоматически.
Cбор истории в ITM реализуется теми же триггерами, только в системе они помечены как исторические и настраиваются отдельно. Согласно настройке истории сервер отдает агенту исторические sql запросы на исполнения, только они без условия (вроде select * from table). Результатом этих sql является все данные в таблицах агента. Эти данные складываются в файл. Агент периодически отдает исторические данные специальному warehouse proxy агенту, который в свою очередь кладет их в специальную базу данных, которую обычно называют Warehouse. Если агент потеряет связь с сервером или с прокси агентом, то ничего страшного кроме роста файла истории не случиться. Агент отдаст историю прокси как только сможет. ITM-сервер к базе warehouse доступа не имеет и следовательно делать триггеры поверх истории не получиться.

Мне нравиться open source и доступные решения имеют свои достоинства и недостатки. Есть некое чувство, что выбор архитектуры был обусловлен где первоначально решение применялось. Вот ядро ITM родилось в недрах другой компании видимо где-то в начале 90-х. Предполагаю в те времена памяти было мало, процессора слабые по современным меркам. По этому искались сложные решения экономии ресурсов.
Стоит упомянут, что ITM не единственный продукт такого функционала у IBM на сегодняшний день. Недавно появился продукт под названием IBM Application Performance Management, но про его архитектуру в другой раз.
В виду особенности ITM не рекомендуется его использовать для мониторинга большого числа сетевого оборудования. Бывают всякие необычные ситуации, но обычно для этого применяют IBM Tivoli Network Manager.
Упомяну о zabbix. Я часто его встречал у заказчиков и много наслышан. Один раз меня заказчик сильно поразил требованиями получать данные с агента каждые 10 секунд. Он же был сильно разочарован, что в ITM нельзя создать триггеры по среднему за период (если на спор, то можно наворотить костылей, но зачем?). Он был знаком с zabbix.
В zabbix (схожая ситуация и с NetXMS) триггеры анализируют исторические данные. Это очень круто, но у меня никогда такой нужны не возникало. Агент zabbix передает данные серверу (или через zabbix прокси). Данные сохраняются в базе данных. После чего по ним отрабатывают триггеры, а мощная система макросов им помогает. Отсюда появляются требования к производительности железа для выполнения основного функционала.
В ITM свои особенности. Сервер ITM все данные получает исключительно от агентов. Никаких встроенных протоколов SNMP и т. п. Сервер представляет собой многопоточное приложение со встроенной базой данных. Особенность ITM в работе триггеров (они же ситуации, но для соблюдения общей терминологии буду назвать триггеры). Триггеры исполняются на агенте. В добавок эти триггеры представляют собой sql-запросы с условием. Сервер компилирует триггеры в бинарный sql-код и отдает агенту на исполнение. Архитектура агента такова, что он похож на базу данных.
Всевозможные метрики уже встроенные в агент (относительно недавно добавили возможность получение данных от приложений/скриптов) и описаны как таблички в реляционной базе данных. Агент исполняет sql запрос согласно заданного интервала. Прослойка, которую дилетантски назову «база данных», выполняет необходимы запросы к операционной системе(ОС) и кладет данные виде таблицы. Частота запросов к ОС не чаще 30 сек. То есть данные в таблице чаще 30 сек. не обновить. Понятно, что агент может исполнять множество однообразных триггеров, что не сильно скажется на загрузке, поскольку опять-таки чаще 30 сек. данные он собирать не будет. Интересно еще то, что агент не будет тревожить сервер до тех пор пока выполняемый им sql запрос возвращает 0 строк. Как только sql запрос вернул несколько строк, все эти строки уйдут на сервер (условие триггера наступило). Сервер в свою очередь, положит данные во временную таблицу до момента пока по ней не пройдется отдельный поток, который проверит на дополнительные условия и сгенерирует событие в системе. Предвещая вопрос как же агент обрабатывает события, например логи? Там с этим все нормально, такие данные агент сразу отправляет на сервер в активном режиме.
Отсюда вывод. База данных сервера ITM не содержит историю, только оперативные данные. Триггеры исполняются на стороне агента который примет на себя часть нагрузки.
Так же рассматривая open source я сразу задавался вопросом реализации отказоустойчивости. Я не увидел того чего хотелось бы. Поскольку ITM позволяет реализовать hot-stanby (горячее резервирования), то хотелось бы что-нибудь вроде такого в open source. В ITM это реализовано достаточно просто. Два сервера, которые реплицируют свои базы от активного к пассивному. В настройках агента указаны оба сервера. Агенты переключаются между двумя серверами автоматически.
Cбор истории в ITM реализуется теми же триггерами, только в системе они помечены как исторические и настраиваются отдельно. Согласно настройке истории сервер отдает агенту исторические sql запросы на исполнения, только они без условия (вроде select * from table). Результатом этих sql является все данные в таблицах агента. Эти данные складываются в файл. Агент периодически отдает исторические данные специальному warehouse proxy агенту, который в свою очередь кладет их в специальную базу данных, которую обычно называют Warehouse. Если агент потеряет связь с сервером или с прокси агентом, то ничего страшного кроме роста файла истории не случиться. Агент отдаст историю прокси как только сможет. ITM-сервер к базе warehouse доступа не имеет и следовательно делать триггеры поверх истории не получиться.
Мне нравиться open source и доступные решения имеют свои достоинства и недостатки. Есть некое чувство, что выбор архитектуры был обусловлен где первоначально решение применялось. Вот ядро ITM родилось в недрах другой компании видимо где-то в начале 90-х. Предполагаю в те времена памяти было мало, процессора слабые по современным меркам. По этому искались сложные решения экономии ресурсов.
Поделиться с друзьями
Комментарии (10)

cru5ader
07.10.2016 16:48+1Что мне нравится в заббикс в первую очередь-это мощное сообщество, которое не оставит в беде.С ITM чуть грустнее, есть конечно форум, где могу ответитьили не ответить на вопрос (уже недели две жду ответа), ну и конечно же сайт в котором как бы объяснено все, но ты остаешься один на один с собой, потому как нет боевых примеров от коллег по «цеху»
Gray_Wolf
07.10.2016 18:28но ты остаешься один на один с собой
Как и с любым другим коммерческим софтом всегда можно завести тикет со своим вопросом. (Хотя согласен что способ заведения тикетов из России которые перед первой линией попадают к российским менеджерам, несколько удручает.)
alexvl
07.10.2016 18:49+1Как и с любым другим коммерческим софтом всегда можно завести тикет со своим вопросом.
И при использовании открытых OSS решений можно завести тикет. Наличие поддержки от вендора не определяется тем, коммерческий (закрытый) софт или нет.
Передовые открытые решения с коммерческой поддержкой от вендора обладают всеми преимуществами закрытых продуктов (поддержка, предсказуемый lifecycle), так и своей бесплатностью (!), открытостью кода и связанных с этим свобод. В этом смысле закрытые продукты не выдерживают конкуренции.
alienrom
13.10.2016 16:07Ох и тормоз же этот ITM!
У меня есть куча причин не использовать его и такая же куча использовать. Как-нибудь надо собраться и написать пост.
alexvl
Должен отметить, что Zabbix агенты умеют локально накапливать данные и независимо отправлять из на разные Zabbix серверы. Преимущество Zabbix в том, что логика анализа данных и обнаружения проблем имеет доступ ко всей накопленной истории со всех устройств, что позволяет описывать исключительно сложные условия возникновения проблем и находить их в режиме реального времени.
a2001
«Триггеры исполняются на агенте.» Это не совсем корректно. С агента сервер получает значения нужных атрибутов. Проверка на пересечение порогов происходит на сервере. Т.е. на сервер уходит не событие о пересечении порога а текущее значение атрибута.
alexvl
keich
Про ITM — Согласен. Подробней так:
1) Задаем в портале ситуацию.
2) Ситуация компилируется в select вариант. Потом в бинарный вид.
3) Результат на шаге 2 отправляется на агенты.
4) Агент исполняет этот sql с заданным периодом(скажем каждые 5 минут).
5) Если sql вернул строки, то данные уходят на сервер, где проверяются на пороги и генерируются события.
Если говорить о метриках, то в ITM это строка из таблицы с несколькими полями, а не ключ- значение.
В Zabbix агент каждый раз собирает метрики(сохраняет в буфер или сразу шлет, не важно) и отсылает на сервер. Я хотел донести мысль, что можно не отсылать данные на сервер если пороги не превышены.
a2001
Просто это два разных подхода. Например агент HP Operation Manager тоже отправляет на сервер событие о пересечении порога.
В случае ITM подход получения не события а атрибутов оправдан в том числе тем, что используя тот же метод идет и сбор истории(о чем вы написали). Кроме этого если вы строите представление и хотите отобразить какой-то график в реальном времени то так же идет обращение к агенту за значением атрибутов.
Вот тут тоже не совсем корректно: «относительно недавно добавили возможность получение данных от приложений/скриптов», Agent Builder есть уже довольно давно. Можно легко собрать любой нужный агент.
keich
Опять согласен. Я имел ввиду, агент ОС заполучил такую возможность, которой раньше не было.