
Предыдущая лекция с Data Fest была посвящена алгоритмам, необходимым для построения нового вида поиска. Сегодняшний доклад тоже в некотором смысле про разные алгоритмы, а точнее про математику, лежащую в основе множества из них. О матричных разложениях зрителям рассказал доктор наук и руководитель группы вычислительных методов «Сколтеха» Иван Оселедец.
Под катом — расшифровка и большинство слайдов.
Есть небольшое — относительно machine learning — сообщество, которое занимается линейной алгеброй. Есть линейная алгебра, а в ней есть люди, которые занимаются мультилинейной алгеброй, тензорными разложениями. Я к ним отношусь. Там получено достаточно большое количество интересных результатов, но в силу способности сообщества самоорганизовываться и не выходить наружу, некоторые из этих результатов неизвестны. Кстати, это относится и к линейной алгебре тоже. Если посмотреть на статьи ведущих конференций NIPS, ICML и т. д., то можно увидеть достаточно много статей, связанных с тривиальными фактами линейной алгебры. Так происходит, но тем не менее.
Будем говорить о тензорных разложениях, но прежде надо сказать про матричные разложения.

Матрицы. Просто двумерная таблица. Матричное разложение — это представление матрицы в виде произведений булевых простых. На самом деле они используются везде, у всех есть мобильные телефоны, и пока вы сидите, они решают линейные системы, передают данные, разлагают матрицы. Правда, эти матрицы очень небольшие — 4х4, 8х8. Но практически эти матрицы очень важны.
Надо сказать, что есть LU-разложение, разложение Гаусса, QR-разложение, но я буду в основном говорить о сингулярном разложении, которое почему-то, например, в курсах линейной алгебры в наших университетах незаслуженно забывается. Читают такую ерунду с точки зрения вычислительной науки, как жорданова форма, которая нигде не используется. Сингулярное разложение обычно где-то в конце, опционально и т. д. Это неправильно. Если взять книжку Голуба и ван Лоуна, «Матричные вычисления», то она начинается ни с LU-, ни с QR-, а с сингулярного разложения. Это представление матрицы в виде произведения унитарной, диагональной и унитарной.
Про матричные разложения хорошо то, что про них действительно много чего известно. Для базовых разложений существуют эффективные алгоритмы, они устойчивые, существует ПО, которое вы можете вызвать в MATLAB, в Python, написаны они и на Фортране. Корректно расценивать это как единичную операция, которую можно посчитать, и вы уверены, что получите точный результат — что вам не нужно делать никаких градиентных спусков. Фактически это один квант операции. Если вы свели свою задачу к вычислению матричных разложений, то вы её, фактически, решили. Это, например, лежит в основе различных спектральных методов. Например, если есть ЕМ-алгоритм, он итерационный, у него медленная сходимость. А если вам удалось получить спектральный метод, то вы молодцы и у вас будет решение в один шаг.
Напрямую то же самое сингулярное разложение никакую задачу не решает, но является этаким строительным блоком для решения общих задач. Вернемся к мобильным телефонам. Этот пример меня беспокоит по понятным причинам: мы работаем с телекоммуникационными компаниями, которым это очень надо.

Есть посмотреть на то, что такое сингулярное разложение и записать его в индексном виде, мы получим следующую формулу. Это приводит к классической старой идее — к разделению переменных, если вернуться к первым курсам университета. Раскладываем x от t, а здесь отделяем I от j, один дискретный индекс отделяем от другого, то есть представляем функцию от двух переменных в виде произведения функций от одной переменной. Ясно, что практически никакая функция в таком виде не приближается, но если вы напишете сумму таких функций, вы получите достаточно широкий класс.
Фактически, основное применение сингулярного разложения — это построение таких малоранговых аппроксимаций. Это матрица ранга r, и, естественно, нас интересует случай, когда ранг существенно меньше, чем общий размер матрицы.
Здесь все хорошо. Мы можем зафиксировать ранг, поставить задачу поиска наилучшей аппроксимации и решение будет дано для сингулярного разложения. На самом деле там известно гораздо больше и можно это сделать быстрее, чем с помощью сингулярного разложения: не вычисляя всех элементов матрицы и т. д. Существует большая красивая теория — теория малоранговых матриц, которая продолжает развиваться и еще далеко не закрыта.

Тем не менее, она не закрыта, но хочется сделать больше, чем два индекса.
Мой изначальный интерес к этой теме был сугубо теоретический. Мы умеем что-то делать с матрицами, разлагать их, представлять в некоторых приложениях — пока неважно, в каких. В конце скажу.
А что будет, если вместо А(i, j) мы напишем А (i, jk), и тоже попробуем разделить переменные. Отсюда совершенно естественным образом возникает задача тензорных разложений. У нас есть тензор — под тензором я понимаю многомерный массив, простую двумерную таблицу, — и мы хотим эти многомерные массивы, грубо говоря, сжать, построить малопараметрическое представление и, обычно красивые слова говорят, — преодолеть проклятье размерности. На самом деле этот термин — он, как всегда, появился совершенно в другой связи с совершенно другой задачей, в работе Беллмана в 1961 году. Но сейчас он используется в том смысле, что n в степени d — это очень плохо. Если вы хотите увеличить d, то у вас будет экспоненциальный рост и т. д.
Факторизация в самом общем смысле: вы пытаетесь выбрать некий класс тензоров, который возникает в вашей прикладной задаче, и построить такое малопараметрическое представление, что по нему вы достаточно быстро сможете восстановить сам тензор. А параметров мало. В принципе, можно сказать, что нейронные сети в каком-то смысле решают задачу аппроксимации тензоров, потому что пытаются построить отображение из пространства параметров куда-то еще.

Если в задачах факторизации, то есть в представления в виде произведения простых объектов, есть матрицы и произведения матриц с тензорами, то определить тензоры — задача уже более сложная. Но если мы посмотрим на индексную запись неполного сингулярного разложения малоранговой аппроксимации, у нас совершенно естественным образом возникнет аналогичная формула. Вот она. Мы пытаемся приблизить тензор объектами, которые являются произведениями функции от одной дискретной переменной, функция t1 умножить на функцию t2. Идея совершенно естественная. Если слагаемое только одно, ничего вы так не приблизите. А если вы разрешаете брать достаточно небольшое количество параметров, возникает очень интересный класс тензоров, который явно или неявно используется во многих задачах методов. Можно сказать, что примерно такой формат используется в квантовой химии для представления волновой функции. Там еще антисимметричность, вместо произведения возникает определитель — но целая огромная область науки основана, фактически, на такой сепарабельной аппроксимации.
Поэтому, естественно, интересно изучить свойства, понять, что здесь происходит, и т. д.

Эта сущность — представление в виде суммы произведения функций от одной переменной — называется каноническим разложением. Впервые оно было предложено где-то в 1927 году. Потом использовалось далеко не в математике. Были работы в статистике, в журналах — таких как Chemometrics, Psychomatrix, — где люди получали кубы данных. Есть признаки — что-то получилось. Таким образом они строили многофакторные модели. Эти матрицы факторов можно интерпретировать как некие факторы. Из них, в свою очередь, можно делать какие-то выводы.
Если посчитать число параметров, мы получим d-n-r параметров. Если r маленький, то все хорошо. Но проблема, которую я пытаюсь решать — это что в принципе посчитать такую аппроксимацию, даже если известно, что она существует, — задача сложная. Можно даже сказать, что она NP-сложная в общем случае — как и задача вычисления ранга. Для матрицы это не так. Ранг матрицы вы можете посчитать — например, с помощью Гауссова исключения это можно сделать за полиномиальное число операций. Здесь всё не так.
Есть пример тензора размера 9х9х9, для которого до сих пор неизвестно точное значение минимального числа слагаемых. Известно, что оно не больше 23 и не меньше 21. Суперкомпьютеры, простые полиномиальные: это вопрос разрешимости системы полиномиальных уравнений. Но такая задача может быть очень сложной. А тензор имеет практическое значение. Ранг этого тензора связан с показателем сложности алгоритма умножения матриц. Штрассен-логарифм двоичный от семи. Соответственно, на самом деле задача вычисления экспоненты сводится к вычислению канонического ранга некоторого тензора.
Во многих приложениях это представление для какого-то конкретного тензора работает хорошо. Но в общем случае эта задача плохая.
Недавно появилась работа достаточно уважаемых людей, где они это представление с разделяющими переменными пытаются связать с глубокими нейронными сетями и доказывают некие результаты. На самом деле они, если их расшифровать, являются достаточно интересными алгебраическими результатами по тензорным разложениям. Если перевести результаты на язык тензорных разложений, получится, что одно тензорное разложение, каноническое, лучше другого. То, которое лучше, я еще не показал, а каноническое показал. Каноническое — плохое в этом смысле. Такой вывод обосновывается тем, что каноническая архитектура — shallow, неглубокая, а должна быть глубокая, более обширная и т. д.
Поэтому давайте попытаемся плавно к этому перейти. Для канонического разложения оптимизационные алгоритмы сходятся медленно, то есть существует болото и т. д. Если посмотреть на эту формулу, каждый, кто знаком с линейной алгеброй, сразу поймет, какой алгоритм можно использовать. Можно градиентные спуски использовать — фиксировать все сомножители кроме одного и получать линейную задачу наименьших квадратов. Но такой метод будет достаточно медленным.
У такой модели есть одно хорошее свойство: если решение все-таки найдено, оно единственное с точностью до тривиальных вещей. Например, не возникает проблемы матричных разложений, когда вы можете вставить s, s-1. Если каноническое разложение посчитано, оно единственное, и это хорошо. Но к сожалению, посчитать его иногда достаточно сложно.

Есть другое разложение Таккера. Это был какой-то психометрик. Идея в том, чтобы ввести некий здесь склеивающий множитель — чтобы не было связи каждого с каждым. Все хорошо, это разложение становится устойчивым, наилучшее приближение всегда существует. Но если вы попытаетесь его использовать, скажем, для d=10, то возникнет вспомогательный двумерный массив, который нужно будет хранить, и проклятье размерности, хотя и в ослабленном виде, останется.
Да, например, для трехмерных-четырехмерных задач разложение Таккера прекрасно работает. Существует достаточно большое количество работ, где оно применяется. Но тем не менее, наша конечная цель состоит не в этом.

Мы хотим получить нечто, где по умолчанию нет экспоненциального числа параметров, но где мы всё можем посчитать. Исходная идея была достаточно простая: если для матриц всё хорошо, давайте лепить матрицы из тензоров, многомерных массивов. Как это делать? Достаточно просто. У нас d индексов — давайте разбивать их на группы, делать матрицы, считать разложения.
Разбиваем. Одну часть индексов объявляем строчными индексами, другую часть — столбцовыми. Может, как-то переставляем. В MATLAB и Python это все делается командой reshape и transpose, считаем малоранговую аппроксимацию. Другой вопрос — как мы это делаем.
Естественно, мы можем попытаться сделать возникшие маленькие массивы рекурсивно. Достаточно легко видеть, что если мы их сделаем наивным образом, у нас получится примерно такая сложность: rlog d. Она уже не экспоненциальная, но r будет в достаточно большой степени.
Если сделать это аккуратно, то — я только одну фразу скажу — возникнет один дополнительный индекс. Его надо считать новым индексом. Пусть у нас был девятимерный массив и мы разбили индексы на 5+4, разложили, получили один дополнительный индекс, получили один шестимерный и один пятимерный тензор и продолжаем их разлагать. В таком виде никакой экспоненциальной сложности не возникает, и получается представление, которое имеет вот такое число параметров. А если нам кто-то сказал, чтобы все получающиеся по дороге матрицы имели малый ранг? Получается такая рекурсивная структура. Она достаточно противная, программировать ее достаточно противно, мне было лень это делать.

В какой-то момент я понял, что можно выбрать самый простой вид данной структуры — который, тем не менее, достаточно мощный. Это то, что стало тензорным поездом, tensor-train. Мы такое предложили, имя прижилось. Потом оказалось, что мы были, естественно, не первыми, кто это придумал. В физике твердого тела оно было известно под названием matrix product states. Но я на каждом докладе повторяю, что хорошую вещь надо открыть как минимум дважды — иначе не очень понятно, хорошая ли она. По крайней мере, это представление открывалось минимум два, а то и два с половиной раза или даже три.
Вот представление, разложением и исследованием которого я занимаюсь последние лет шесть-семь, и до конца не могу сказать, что оно изучено.
Мы представляем тензор в виде произведения объектов, которые зависят только от одного индекса. Фактически, речь идет о разделении переменных, но за одним маленьким исключением: теперь эти маленькие штучки — матрицы. Мы перемножаем, чтобы получить значения тензоров точки, эти матрицы. Первый элемент — строчка, потом матрица, матрица, столбец — мы получаем число. А указанные матрицы зависят от параметров, их можно хранить как трехмерный тензор. У нас есть коллекция матриц, вначале — коллекция строчек. Мы говорим: нам нужна нулевая строчка отсюда, пятая матрица отсюда, третья отсюда — мы их просто перемножаем. Ясно, что вычисление элемента занимает dr2 операций. В индексном виде тоже. Компактный такой вид.
Вроде ничего сильно не меняется, но на самом деле такое представление сохраняет все свойства сингулярного разложения. Его можно посчитать, можно ортогонализовывать, можно находить наилучшие аппроксимации. Это малопараметрическое многообразие во множестве всех тензоров, но можно сказать, что мы — если нам повезло и решение на нем лежит — легко его найдем.

Здесь — некие свойства. У нас теперь не один ранг. В матрице только один ранг, столбцовый или строчный, но они одинаковые для матрицы, так повезло. Для тензоров рангов много. Число r вначале — это канонический ранг. Здесь у нас ранг d-1. Для каждого d свой ранг, у нас много рангов. Тем не менее, все эти определяющие сложность ранги и память для хранения такого представления можно посчитать, по крайней мере, теоретически — как ранги некоторых матриц, так называемых разверток. Берем многомерный массив, превращаем в матрицы, считаем ранги — ага, есть разложение с такими рангами.
Почему это называется форматом? Если у нас объекты хранятся в таком формате, алгебраические операции сложения, умножения, вычисления нормы можно сделать напрямую — не выходя из формата. При этом все равно что-то происходит. Например, если мы сложили два тензора, то результат будет иметь ранг, который не превосходит сумму рангов. Если проделывать такое много раз в каком-нибудь итерационном процессе, то ранг станет очень большим — даже несмотря на то, что по d зависимость линейная, а по r — квадратичная. Спокойно можно работать с рангом 100-200. Физики на кластерах умеют работать с рангами 4000-5000, но больше нельзя, потому что надо хранить достаточно большие плотные матрицы.
Но есть очень простой и красивый алгебраический алгоритм, позволяющий уменьшать ранги. Я имею некую допустимую точность в норме Фрабениуса и хочу найти минимальные ранги, которые дают точность. Но я одновременно уменьшаю ранги. Округление. Когда вы работаете с числами с плавающей точкой, вы же не храните все 100 цифр. Вы оставляете только 16 цифр. Мы находим те параметры, такой размер этих матриц, которые дают допустимую точность. Есть надежный робастный алгоритм, который это делает, — он занимает 20-30 строк в MATLAB или на Python.
Есть и еще одна красивая вещь. Физики ее точно не знали. Этим результатом я горжусь, он мой с моим тогдашним шефом, Евгением Евгеньевичем Тартышниковым. Если мы знаем, что данный нам тензор имеет такую структуру, то мы его точно можем восстановить по dnr2 элементов. То есть мы, не вычисляя всех элементов, можем посмотреть на небольшое их количество и восстановить весь тензор, не используя ни базисов, ничего. Это интересный факт, он для матриц не насколько хорошо известный, каким мог бы быть. Есть d = 2, матрица ранга r. Ее можно восстановить по r столбцам и r строкам.
Когда у нас есть такое многообразие, мы можем минимизировать функционал с ограничением на ранги. Стандартная ситуация: доступа к элементам у нас нет, но есть некий функционал качества, который мы хотели бы минимизировать. Для этого возникает целое отдельное направление исследований вопроса, как оптимизировать с указанными ограничениями. Речь идет не о выпуклом множестве, но оно имеет много интересных топологических свойств, требующих отдельного изучения.
В последнее время, в основном для задач, возникающих из уравнения в частных производных, наконец удается доказать оценку, что ранги ведут себя логарифмически в зависимости от требуемой точности. Есть целые классы задач, где такие представления являются квазиоптимальными.

Пробежимся по тому, как считать ТТ-ранги. Берем матрицу, первые k индексов считаем строчными индексами, последние d-k — столбцовыми. Делаем огромную матрицу, считаем ранги. Тогда существует разложение вот с такими рангами.
Теорема конструктивная и дает алгоритм вычисления. Фактически, речь идет просто о последовательном вычислении сингулярных разложений небольших матриц. И можно доказать оценку устойчивости такого алгоритма. Там возникает множитель — корень из d-1 относительно сингулярных чисел, которые мы по дороге отбрасываем. Но в целом, если мы работаем с точностью 10-6, это ни на что не влияет.
Операции имеют линейную по d сложность. Вот моя любимая операция — ее можно написать короче всего. Если мы берем два тензора и хотим их поэлементно перемножить, то ядра просто перемножаются кронекоровым образом. Размер ядер был 10х10, значит будет 100х100. Если сделать так пару раз, уже будет 10000х10000, поэтому нужно округлять.

Округление можно сделать за dnr3 операций. Можно точно построить это разложение, если кто-то дал нам уже неоптимальное представление.
То же самое для матриц. Если вам кто-то дал матрицу ранга 100 и эту факторизацию, построить факторизацию ранга 10 можно дешево, не считая всю матрицу.
Проекцию на множество тензоров с ограниченными рангами тоже можно вычислить устойчивым образом. Это очень важно в различных оптимизационных алгоритмах.

Крестовая аппроксимация. Я говорил, что матрицы и тензоры малого ранга можно восстанавливать по подмножеству элементов. Это незаслуженно малоизвестный факт. Сейчас в Америке он приобрел некую популярность, но тем не менее, всё надо переоткрывать и т. д. Однако он давно был известен и в России в группе Тартышникова, и в Германии.
Если у вас есть матрица ранга r, вы можете точно восстановить ее по r столбцам и r строкам, используя вот такую замечательную формуле. Взяли столбцы, взяли подматрицу, которая невырождена, и вот она формула.
Если на нее внимательно посмотреть, выяснится, что это формула гауссова исключения. Можно спокойно сказать, что все это придумал Гаусс и не мучиться, но тем не менее формула замечательная. Если матрица — миллион на миллион и вы знаете, что она ранга 5, то вам в ней достаточно посчитать 5 столбцов и 5 строчек, чтобы восстановить ее целиком.
Ясно, что возникает проблема поиска этих столбцов и строчек устойчивым образом. Вы должны попасть в подматрицу, которая достаточно хорошо обусловлена.
Существуют достаточно эффективные эмпирические алгоритмы, которые, естественно, не будут работать в общем случае. Какой-то нехороший человек возьмет и здесь один элемент испортит. Вы такой элемент никогда не найдете, не просмотрев всю матрицу. Но если матрица обладает неким свойством гладкости и к ней нехорошие люди не допускаются, то для классов таких матриц можно доказать, что у вас все будет хорошо. И на практике эти методы работают совершенно блестяще. Устоявшийся алгоритм: вам дали матрицу, они это делают.
Совершенно то же самое можно сделать для тензоров. Если мы знаем, что тензоры имеют малые ранги в смысле ТТ-формата, то можем потыкать в некие подмножества и восстановить весь тензор. Естественно, тогда эффект может быть огромным. Вы сможете считать тензоры, число элементов в которых формально больше, чем число атомов во Вселенной. Причем делаться это будет на ноутбуке. Целиком никто никогда не посчитает, но тем не менее.
Существуют, как я сказал, эффективные эмпирические алгоритмы.
Самое серьезное направление исследований — решение оптимизационных задач, к которым сводится большинство практических. Когда у вас есть некий функционал, неизвестный объект может быть проиндексирован d-индексами. d-индекс введен либо естественным образом, либо искусственны. Это отдельная тема. Можно брать вектор длины 2d и превращать его в тензор 2х2х2х2. И у него будут малые ранги, даже если взятый вектор состоит просто из значений одномерной функции. Такова одна из красивых вещей. Можно искусственно делать тензоры, вводить виртуальные размерности в данные, где их не было, и получать малые ранги.
Даже если исходный функционал был квадратичным — например, если мы хотим приближенно решить какую-то линейную систему или найти собственный вектор, — то в результате ограничений на ранги мы получаем невыпуклую задачу, которую надо как-то решать.
Но у нас есть очень специальный формат. Это совершенно открытая тема. Возникает специальное многообразие, возникает риманова геометрия. Такое надо уметь делать, но мы много чего умеем делать, и у нас есть программы, которые такие алгоритмы реализуют. Минимизация функционала с ограничением — достаточно много задач можно так сформулировать.
Есть два пакета: ttpy для Python и TT-Toolbox для MATLAB. Документированы они фигово, но все же работают, и все алгоритмы, которые есть у нас, имеются и там. Базовые, продвинутые, придуманные нами и не только нами.
О примерах применений. Так как я одной ногой ощущаю себя в численном анализе, в решении дифференциальных интегральных уравнений, то на самом деле речь идет об одной из областей, где машинное обучение не представлено практически никак и имеет безумно плохую репутацию. Если ты скажешь человеку, который занимается решением уравнений в частных производных, что хочешь что-то делать нейронными сетями, он будет плеваться. Репутация более-менее понятная. Наверное, за этим стоит фундаментальная проблема: в таких уравнениях нужно получать решения с высокой точностью. Нужны значения 10-6 или 10-8. Для задач классификации нейронные сети — блестящая идея, а вот для задач регрессии — не всегда удачная. Как это можно было бы применить — совершенно отдельная тема, совершенно пустая. Успешных примеров мало, и людей, которые этим занимаются, тоже не так много. Я пытаюсь и то, и то делать, в надежде, что что-то замечательное придумается. Посмотрим.
Есть ощущение, что можно что-то задействовать, но требуется серьезная доработка. Нельзя взять условный TensorFlow и применить. Мы взяли, применили — ничего не работает, надо думать. Когда что-то не работает, это замечательная ситуация. Значит, ты должен понять, почему оно не работает.
Тем не менее, тензоры хорошо работают в этом случае. Есть теорема. Мы их формально дискретизируем в задачу на сетке из 260 виртуальных ячеек и строим решение на ноутбуке за несколько секунд. Там возникает куча всяких проблем. Мы берем трехмерный кубик, разбиваем его на n3 ячеек, а n = 2d, то есть 220, то есть миллион на миллион на миллион. И все перечисленное мы превращаем в 2х2х2х2, 60-мерный тензор. Вот эту штуку мы и ищем.
На самом деле, число параметров очень маленькое: 2 на d, которое 60, и на ранг, который 50. Формально мы решаем задачу, где очень много неизвестных.
Отдельный вопрос, зачем это нужно. Есть применение, связанное, например, с многомасштабным моделированием, когда есть очень маленькие масштабы и формально их надо разрешать. Тогда делать это можно в режиме черного ящика.

Дальше есть пример, когда ТТ был применен напрямую к нейронным сетям. Это TensorNet, работа Саши Новикова и группы Дмитрия Ветрова, работа с NIPS прошлого года. Просто вместо полносвязного слоя взят слой, который имеет вот такую структуру. У нас получается нелинейный структурированный слой, но при этом число параметров падает в огромное количество раз, а точность меняется несильно.
Можно сжимать и сверточные слои. Была у нас работа с группой Виктора Лемпицкого. Он сегодня будет читать блестящую лекцию, всем рекомендую.
Там мы ТТ не применяли, применили каноническое разложение. Сверточный слой можно представить как свертку с четырехмерным тензором, который мы просто засунули в ПО, считающее малоранговые аппроксимации. Оказалось, что можно восемь раз сжать. Там есть детали, напрямую оно не сработало, но результат следующий: можно действительно сжать восемь раз, и без особой потери точности.
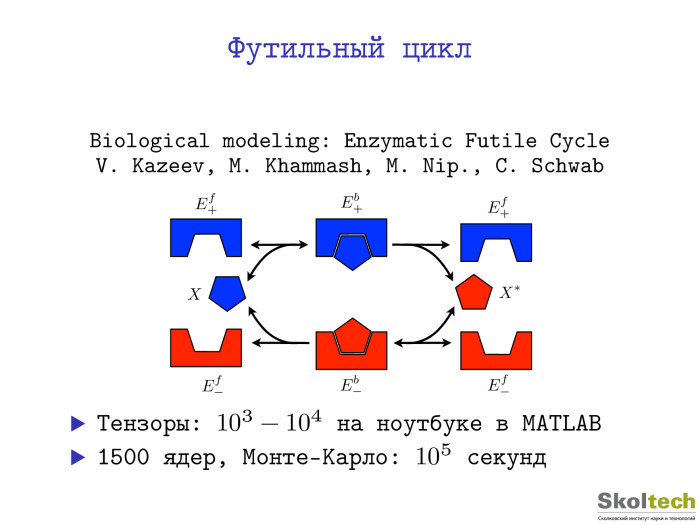
Вот пример из биологии. Что мне нравится в таких вещах: можно применять практически один и тот же код в биологии, в машинном обучении, в химии, да еще и не зная предметного языка, а переводя всё на язык многомерных массивов и запуская черный ящик. Конечно, этому ящику требуется доработка, но всё же примеров применения в совершенно разных областях у нас уже достаточно много. Речь идет о неком биологическом цикле, где задача шестимерная. Он возникает, когда медведь спит — ему нужно быстро выработать энергию, чтобы прогреться. Это футильный бесполезный цикл, работа группы Кристофа Шваба из Цюриха. Владимир Козеев, который был студентом нашей кафедры ЭВМ, когда я там работал. Есть метод Монте-Карло, решающий некое стохастическое дифференциальное уравнение. 1500 ядер — 105 секунд. В MATLAB это все считалось тысячу секунд. Хорошее ускорение.

Считали колебательные состояния молекул. Было 12 степеней свободы, 12-мерная задача, примерно 3012 формальных неизвестных. По сравнению с некоторыми хитрыми и достаточно сложными химическими методами удалось добиться ускорения в десятки раз.

Недавняя работа на воркшопе с Сашей Новиковым под гордым названием Exponential Machines, где в качестве фич мы выбираем x1, x2, всевозможные подмножества, которых 2d. Мы запихнули их в тензор 2х2х2х2 и сказали: пусть он будет малого ранга. Работает. Дальше возникает оптимизация по этому тензору, надо всё делать, но работает.
Последний пример связан с рекомендательными системами. Мой аспирант Женя Фролов, большой эксперт в рекомендательных системах, может часами про них говорить. Часто поговорить ему о них не с кем, поэтому если кто-то интересуется рекомендательными системами — напишите ему, пожалуйста. Недавно нашу статью приняли на RecSys. Он создал некий фреймворк для рекомендательных систем под названием Polara. Там мы тензоры применили к классической задаче построения рекомендаций, где у вас есть пользователи, фильмы и рейтинг. В этой области есть некая проблема: все современные методы рекомендаций не учитывают негативный фидбек. Здесь пример: человек говорит, что ему не нравится фильм «Лицо со шрамом», а ему SVD рекомендует посмотреть еще «Крестного отца». «История игрушек» ему бы больше понравилась. Статья написана очень хорошо. Идея такая: вместо рассмотрения матрицы «пользователь — фильм» мы рассматриваем матрицу «пользователь — фильм — рейтинг» и пишем единицу, если пользователь поставил фильму оценку. В каком-то смысле рейтинги становятся выровненными. Мы к указанному трехмерному тензору уже строим факторизацию, делаем практически то, что делается стандартно, и получаем что-то вроде парадигмы: если вам не нравится это, вам, возможно, понравится нечто другое. Мы можем давать осмысленные рекомендации на основе одного негативного фидбека, что достаточно сложно.

Есть классы задач, когда у вас имеется экспоненциальная точность — то есть когда ошибка по числу параметров бывает экспоненциальной. Есть надежный набор алгоритмов. Можно вложить и сказать, что это тоже deep learning. В данной работе товарища из Израиля как раз говорится, что речь идет про arithmetic circuit. Но для него есть надежный набор алгоритмов, можно считать.
У нас есть страничка, проект на GitHub, можно писать и спрашивать. Всё, спасибо.
Под катом — расшифровка и большинство слайдов.
Есть небольшое — относительно machine learning — сообщество, которое занимается линейной алгеброй. Есть линейная алгебра, а в ней есть люди, которые занимаются мультилинейной алгеброй, тензорными разложениями. Я к ним отношусь. Там получено достаточно большое количество интересных результатов, но в силу способности сообщества самоорганизовываться и не выходить наружу, некоторые из этих результатов неизвестны. Кстати, это относится и к линейной алгебре тоже. Если посмотреть на статьи ведущих конференций NIPS, ICML и т. д., то можно увидеть достаточно много статей, связанных с тривиальными фактами линейной алгебры. Так происходит, но тем не менее.
Будем говорить о тензорных разложениях, но прежде надо сказать про матричные разложения.
Матрицы. Просто двумерная таблица. Матричное разложение — это представление матрицы в виде произведений булевых простых. На самом деле они используются везде, у всех есть мобильные телефоны, и пока вы сидите, они решают линейные системы, передают данные, разлагают матрицы. Правда, эти матрицы очень небольшие — 4х4, 8х8. Но практически эти матрицы очень важны.
Надо сказать, что есть LU-разложение, разложение Гаусса, QR-разложение, но я буду в основном говорить о сингулярном разложении, которое почему-то, например, в курсах линейной алгебры в наших университетах незаслуженно забывается. Читают такую ерунду с точки зрения вычислительной науки, как жорданова форма, которая нигде не используется. Сингулярное разложение обычно где-то в конце, опционально и т. д. Это неправильно. Если взять книжку Голуба и ван Лоуна, «Матричные вычисления», то она начинается ни с LU-, ни с QR-, а с сингулярного разложения. Это представление матрицы в виде произведения унитарной, диагональной и унитарной.
Про матричные разложения хорошо то, что про них действительно много чего известно. Для базовых разложений существуют эффективные алгоритмы, они устойчивые, существует ПО, которое вы можете вызвать в MATLAB, в Python, написаны они и на Фортране. Корректно расценивать это как единичную операция, которую можно посчитать, и вы уверены, что получите точный результат — что вам не нужно делать никаких градиентных спусков. Фактически это один квант операции. Если вы свели свою задачу к вычислению матричных разложений, то вы её, фактически, решили. Это, например, лежит в основе различных спектральных методов. Например, если есть ЕМ-алгоритм, он итерационный, у него медленная сходимость. А если вам удалось получить спектральный метод, то вы молодцы и у вас будет решение в один шаг.
Напрямую то же самое сингулярное разложение никакую задачу не решает, но является этаким строительным блоком для решения общих задач. Вернемся к мобильным телефонам. Этот пример меня беспокоит по понятным причинам: мы работаем с телекоммуникационными компаниями, которым это очень надо.
Есть посмотреть на то, что такое сингулярное разложение и записать его в индексном виде, мы получим следующую формулу. Это приводит к классической старой идее — к разделению переменных, если вернуться к первым курсам университета. Раскладываем x от t, а здесь отделяем I от j, один дискретный индекс отделяем от другого, то есть представляем функцию от двух переменных в виде произведения функций от одной переменной. Ясно, что практически никакая функция в таком виде не приближается, но если вы напишете сумму таких функций, вы получите достаточно широкий класс.
Фактически, основное применение сингулярного разложения — это построение таких малоранговых аппроксимаций. Это матрица ранга r, и, естественно, нас интересует случай, когда ранг существенно меньше, чем общий размер матрицы.
Здесь все хорошо. Мы можем зафиксировать ранг, поставить задачу поиска наилучшей аппроксимации и решение будет дано для сингулярного разложения. На самом деле там известно гораздо больше и можно это сделать быстрее, чем с помощью сингулярного разложения: не вычисляя всех элементов матрицы и т. д. Существует большая красивая теория — теория малоранговых матриц, которая продолжает развиваться и еще далеко не закрыта.
Тем не менее, она не закрыта, но хочется сделать больше, чем два индекса.
Мой изначальный интерес к этой теме был сугубо теоретический. Мы умеем что-то делать с матрицами, разлагать их, представлять в некоторых приложениях — пока неважно, в каких. В конце скажу.
А что будет, если вместо А(i, j) мы напишем А (i, jk), и тоже попробуем разделить переменные. Отсюда совершенно естественным образом возникает задача тензорных разложений. У нас есть тензор — под тензором я понимаю многомерный массив, простую двумерную таблицу, — и мы хотим эти многомерные массивы, грубо говоря, сжать, построить малопараметрическое представление и, обычно красивые слова говорят, — преодолеть проклятье размерности. На самом деле этот термин — он, как всегда, появился совершенно в другой связи с совершенно другой задачей, в работе Беллмана в 1961 году. Но сейчас он используется в том смысле, что n в степени d — это очень плохо. Если вы хотите увеличить d, то у вас будет экспоненциальный рост и т. д.
Факторизация в самом общем смысле: вы пытаетесь выбрать некий класс тензоров, который возникает в вашей прикладной задаче, и построить такое малопараметрическое представление, что по нему вы достаточно быстро сможете восстановить сам тензор. А параметров мало. В принципе, можно сказать, что нейронные сети в каком-то смысле решают задачу аппроксимации тензоров, потому что пытаются построить отображение из пространства параметров куда-то еще.
Если в задачах факторизации, то есть в представления в виде произведения простых объектов, есть матрицы и произведения матриц с тензорами, то определить тензоры — задача уже более сложная. Но если мы посмотрим на индексную запись неполного сингулярного разложения малоранговой аппроксимации, у нас совершенно естественным образом возникнет аналогичная формула. Вот она. Мы пытаемся приблизить тензор объектами, которые являются произведениями функции от одной дискретной переменной, функция t1 умножить на функцию t2. Идея совершенно естественная. Если слагаемое только одно, ничего вы так не приблизите. А если вы разрешаете брать достаточно небольшое количество параметров, возникает очень интересный класс тензоров, который явно или неявно используется во многих задачах методов. Можно сказать, что примерно такой формат используется в квантовой химии для представления волновой функции. Там еще антисимметричность, вместо произведения возникает определитель — но целая огромная область науки основана, фактически, на такой сепарабельной аппроксимации.
Поэтому, естественно, интересно изучить свойства, понять, что здесь происходит, и т. д.
Эта сущность — представление в виде суммы произведения функций от одной переменной — называется каноническим разложением. Впервые оно было предложено где-то в 1927 году. Потом использовалось далеко не в математике. Были работы в статистике, в журналах — таких как Chemometrics, Psychomatrix, — где люди получали кубы данных. Есть признаки — что-то получилось. Таким образом они строили многофакторные модели. Эти матрицы факторов можно интерпретировать как некие факторы. Из них, в свою очередь, можно делать какие-то выводы.
Если посчитать число параметров, мы получим d-n-r параметров. Если r маленький, то все хорошо. Но проблема, которую я пытаюсь решать — это что в принципе посчитать такую аппроксимацию, даже если известно, что она существует, — задача сложная. Можно даже сказать, что она NP-сложная в общем случае — как и задача вычисления ранга. Для матрицы это не так. Ранг матрицы вы можете посчитать — например, с помощью Гауссова исключения это можно сделать за полиномиальное число операций. Здесь всё не так.
Есть пример тензора размера 9х9х9, для которого до сих пор неизвестно точное значение минимального числа слагаемых. Известно, что оно не больше 23 и не меньше 21. Суперкомпьютеры, простые полиномиальные: это вопрос разрешимости системы полиномиальных уравнений. Но такая задача может быть очень сложной. А тензор имеет практическое значение. Ранг этого тензора связан с показателем сложности алгоритма умножения матриц. Штрассен-логарифм двоичный от семи. Соответственно, на самом деле задача вычисления экспоненты сводится к вычислению канонического ранга некоторого тензора.
Во многих приложениях это представление для какого-то конкретного тензора работает хорошо. Но в общем случае эта задача плохая.
Недавно появилась работа достаточно уважаемых людей, где они это представление с разделяющими переменными пытаются связать с глубокими нейронными сетями и доказывают некие результаты. На самом деле они, если их расшифровать, являются достаточно интересными алгебраическими результатами по тензорным разложениям. Если перевести результаты на язык тензорных разложений, получится, что одно тензорное разложение, каноническое, лучше другого. То, которое лучше, я еще не показал, а каноническое показал. Каноническое — плохое в этом смысле. Такой вывод обосновывается тем, что каноническая архитектура — shallow, неглубокая, а должна быть глубокая, более обширная и т. д.
Поэтому давайте попытаемся плавно к этому перейти. Для канонического разложения оптимизационные алгоритмы сходятся медленно, то есть существует болото и т. д. Если посмотреть на эту формулу, каждый, кто знаком с линейной алгеброй, сразу поймет, какой алгоритм можно использовать. Можно градиентные спуски использовать — фиксировать все сомножители кроме одного и получать линейную задачу наименьших квадратов. Но такой метод будет достаточно медленным.
У такой модели есть одно хорошее свойство: если решение все-таки найдено, оно единственное с точностью до тривиальных вещей. Например, не возникает проблемы матричных разложений, когда вы можете вставить s, s-1. Если каноническое разложение посчитано, оно единственное, и это хорошо. Но к сожалению, посчитать его иногда достаточно сложно.
Есть другое разложение Таккера. Это был какой-то психометрик. Идея в том, чтобы ввести некий здесь склеивающий множитель — чтобы не было связи каждого с каждым. Все хорошо, это разложение становится устойчивым, наилучшее приближение всегда существует. Но если вы попытаетесь его использовать, скажем, для d=10, то возникнет вспомогательный двумерный массив, который нужно будет хранить, и проклятье размерности, хотя и в ослабленном виде, останется.
Да, например, для трехмерных-четырехмерных задач разложение Таккера прекрасно работает. Существует достаточно большое количество работ, где оно применяется. Но тем не менее, наша конечная цель состоит не в этом.
Мы хотим получить нечто, где по умолчанию нет экспоненциального числа параметров, но где мы всё можем посчитать. Исходная идея была достаточно простая: если для матриц всё хорошо, давайте лепить матрицы из тензоров, многомерных массивов. Как это делать? Достаточно просто. У нас d индексов — давайте разбивать их на группы, делать матрицы, считать разложения.
Разбиваем. Одну часть индексов объявляем строчными индексами, другую часть — столбцовыми. Может, как-то переставляем. В MATLAB и Python это все делается командой reshape и transpose, считаем малоранговую аппроксимацию. Другой вопрос — как мы это делаем.
Естественно, мы можем попытаться сделать возникшие маленькие массивы рекурсивно. Достаточно легко видеть, что если мы их сделаем наивным образом, у нас получится примерно такая сложность: rlog d. Она уже не экспоненциальная, но r будет в достаточно большой степени.
Если сделать это аккуратно, то — я только одну фразу скажу — возникнет один дополнительный индекс. Его надо считать новым индексом. Пусть у нас был девятимерный массив и мы разбили индексы на 5+4, разложили, получили один дополнительный индекс, получили один шестимерный и один пятимерный тензор и продолжаем их разлагать. В таком виде никакой экспоненциальной сложности не возникает, и получается представление, которое имеет вот такое число параметров. А если нам кто-то сказал, чтобы все получающиеся по дороге матрицы имели малый ранг? Получается такая рекурсивная структура. Она достаточно противная, программировать ее достаточно противно, мне было лень это делать.
В какой-то момент я понял, что можно выбрать самый простой вид данной структуры — который, тем не менее, достаточно мощный. Это то, что стало тензорным поездом, tensor-train. Мы такое предложили, имя прижилось. Потом оказалось, что мы были, естественно, не первыми, кто это придумал. В физике твердого тела оно было известно под названием matrix product states. Но я на каждом докладе повторяю, что хорошую вещь надо открыть как минимум дважды — иначе не очень понятно, хорошая ли она. По крайней мере, это представление открывалось минимум два, а то и два с половиной раза или даже три.
Вот представление, разложением и исследованием которого я занимаюсь последние лет шесть-семь, и до конца не могу сказать, что оно изучено.
Мы представляем тензор в виде произведения объектов, которые зависят только от одного индекса. Фактически, речь идет о разделении переменных, но за одним маленьким исключением: теперь эти маленькие штучки — матрицы. Мы перемножаем, чтобы получить значения тензоров точки, эти матрицы. Первый элемент — строчка, потом матрица, матрица, столбец — мы получаем число. А указанные матрицы зависят от параметров, их можно хранить как трехмерный тензор. У нас есть коллекция матриц, вначале — коллекция строчек. Мы говорим: нам нужна нулевая строчка отсюда, пятая матрица отсюда, третья отсюда — мы их просто перемножаем. Ясно, что вычисление элемента занимает dr2 операций. В индексном виде тоже. Компактный такой вид.
Вроде ничего сильно не меняется, но на самом деле такое представление сохраняет все свойства сингулярного разложения. Его можно посчитать, можно ортогонализовывать, можно находить наилучшие аппроксимации. Это малопараметрическое многообразие во множестве всех тензоров, но можно сказать, что мы — если нам повезло и решение на нем лежит — легко его найдем.
Здесь — некие свойства. У нас теперь не один ранг. В матрице только один ранг, столбцовый или строчный, но они одинаковые для матрицы, так повезло. Для тензоров рангов много. Число r вначале — это канонический ранг. Здесь у нас ранг d-1. Для каждого d свой ранг, у нас много рангов. Тем не менее, все эти определяющие сложность ранги и память для хранения такого представления можно посчитать, по крайней мере, теоретически — как ранги некоторых матриц, так называемых разверток. Берем многомерный массив, превращаем в матрицы, считаем ранги — ага, есть разложение с такими рангами.
Почему это называется форматом? Если у нас объекты хранятся в таком формате, алгебраические операции сложения, умножения, вычисления нормы можно сделать напрямую — не выходя из формата. При этом все равно что-то происходит. Например, если мы сложили два тензора, то результат будет иметь ранг, который не превосходит сумму рангов. Если проделывать такое много раз в каком-нибудь итерационном процессе, то ранг станет очень большим — даже несмотря на то, что по d зависимость линейная, а по r — квадратичная. Спокойно можно работать с рангом 100-200. Физики на кластерах умеют работать с рангами 4000-5000, но больше нельзя, потому что надо хранить достаточно большие плотные матрицы.
Но есть очень простой и красивый алгебраический алгоритм, позволяющий уменьшать ранги. Я имею некую допустимую точность в норме Фрабениуса и хочу найти минимальные ранги, которые дают точность. Но я одновременно уменьшаю ранги. Округление. Когда вы работаете с числами с плавающей точкой, вы же не храните все 100 цифр. Вы оставляете только 16 цифр. Мы находим те параметры, такой размер этих матриц, которые дают допустимую точность. Есть надежный робастный алгоритм, который это делает, — он занимает 20-30 строк в MATLAB или на Python.
Есть и еще одна красивая вещь. Физики ее точно не знали. Этим результатом я горжусь, он мой с моим тогдашним шефом, Евгением Евгеньевичем Тартышниковым. Если мы знаем, что данный нам тензор имеет такую структуру, то мы его точно можем восстановить по dnr2 элементов. То есть мы, не вычисляя всех элементов, можем посмотреть на небольшое их количество и восстановить весь тензор, не используя ни базисов, ничего. Это интересный факт, он для матриц не насколько хорошо известный, каким мог бы быть. Есть d = 2, матрица ранга r. Ее можно восстановить по r столбцам и r строкам.
Когда у нас есть такое многообразие, мы можем минимизировать функционал с ограничением на ранги. Стандартная ситуация: доступа к элементам у нас нет, но есть некий функционал качества, который мы хотели бы минимизировать. Для этого возникает целое отдельное направление исследований вопроса, как оптимизировать с указанными ограничениями. Речь идет не о выпуклом множестве, но оно имеет много интересных топологических свойств, требующих отдельного изучения.
В последнее время, в основном для задач, возникающих из уравнения в частных производных, наконец удается доказать оценку, что ранги ведут себя логарифмически в зависимости от требуемой точности. Есть целые классы задач, где такие представления являются квазиоптимальными.
Пробежимся по тому, как считать ТТ-ранги. Берем матрицу, первые k индексов считаем строчными индексами, последние d-k — столбцовыми. Делаем огромную матрицу, считаем ранги. Тогда существует разложение вот с такими рангами.
Теорема конструктивная и дает алгоритм вычисления. Фактически, речь идет просто о последовательном вычислении сингулярных разложений небольших матриц. И можно доказать оценку устойчивости такого алгоритма. Там возникает множитель — корень из d-1 относительно сингулярных чисел, которые мы по дороге отбрасываем. Но в целом, если мы работаем с точностью 10-6, это ни на что не влияет.
Операции имеют линейную по d сложность. Вот моя любимая операция — ее можно написать короче всего. Если мы берем два тензора и хотим их поэлементно перемножить, то ядра просто перемножаются кронекоровым образом. Размер ядер был 10х10, значит будет 100х100. Если сделать так пару раз, уже будет 10000х10000, поэтому нужно округлять.
Округление можно сделать за dnr3 операций. Можно точно построить это разложение, если кто-то дал нам уже неоптимальное представление.
То же самое для матриц. Если вам кто-то дал матрицу ранга 100 и эту факторизацию, построить факторизацию ранга 10 можно дешево, не считая всю матрицу.
Проекцию на множество тензоров с ограниченными рангами тоже можно вычислить устойчивым образом. Это очень важно в различных оптимизационных алгоритмах.
Крестовая аппроксимация. Я говорил, что матрицы и тензоры малого ранга можно восстанавливать по подмножеству элементов. Это незаслуженно малоизвестный факт. Сейчас в Америке он приобрел некую популярность, но тем не менее, всё надо переоткрывать и т. д. Однако он давно был известен и в России в группе Тартышникова, и в Германии.
Если у вас есть матрица ранга r, вы можете точно восстановить ее по r столбцам и r строкам, используя вот такую замечательную формуле. Взяли столбцы, взяли подматрицу, которая невырождена, и вот она формула.
Если на нее внимательно посмотреть, выяснится, что это формула гауссова исключения. Можно спокойно сказать, что все это придумал Гаусс и не мучиться, но тем не менее формула замечательная. Если матрица — миллион на миллион и вы знаете, что она ранга 5, то вам в ней достаточно посчитать 5 столбцов и 5 строчек, чтобы восстановить ее целиком.
Ясно, что возникает проблема поиска этих столбцов и строчек устойчивым образом. Вы должны попасть в подматрицу, которая достаточно хорошо обусловлена.
Существуют достаточно эффективные эмпирические алгоритмы, которые, естественно, не будут работать в общем случае. Какой-то нехороший человек возьмет и здесь один элемент испортит. Вы такой элемент никогда не найдете, не просмотрев всю матрицу. Но если матрица обладает неким свойством гладкости и к ней нехорошие люди не допускаются, то для классов таких матриц можно доказать, что у вас все будет хорошо. И на практике эти методы работают совершенно блестяще. Устоявшийся алгоритм: вам дали матрицу, они это делают.
Совершенно то же самое можно сделать для тензоров. Если мы знаем, что тензоры имеют малые ранги в смысле ТТ-формата, то можем потыкать в некие подмножества и восстановить весь тензор. Естественно, тогда эффект может быть огромным. Вы сможете считать тензоры, число элементов в которых формально больше, чем число атомов во Вселенной. Причем делаться это будет на ноутбуке. Целиком никто никогда не посчитает, но тем не менее.
Существуют, как я сказал, эффективные эмпирические алгоритмы.
Самое серьезное направление исследований — решение оптимизационных задач, к которым сводится большинство практических. Когда у вас есть некий функционал, неизвестный объект может быть проиндексирован d-индексами. d-индекс введен либо естественным образом, либо искусственны. Это отдельная тема. Можно брать вектор длины 2d и превращать его в тензор 2х2х2х2. И у него будут малые ранги, даже если взятый вектор состоит просто из значений одномерной функции. Такова одна из красивых вещей. Можно искусственно делать тензоры, вводить виртуальные размерности в данные, где их не было, и получать малые ранги.
Даже если исходный функционал был квадратичным — например, если мы хотим приближенно решить какую-то линейную систему или найти собственный вектор, — то в результате ограничений на ранги мы получаем невыпуклую задачу, которую надо как-то решать.
Но у нас есть очень специальный формат. Это совершенно открытая тема. Возникает специальное многообразие, возникает риманова геометрия. Такое надо уметь делать, но мы много чего умеем делать, и у нас есть программы, которые такие алгоритмы реализуют. Минимизация функционала с ограничением — достаточно много задач можно так сформулировать.
Есть два пакета: ttpy для Python и TT-Toolbox для MATLAB. Документированы они фигово, но все же работают, и все алгоритмы, которые есть у нас, имеются и там. Базовые, продвинутые, придуманные нами и не только нами.
О примерах применений. Так как я одной ногой ощущаю себя в численном анализе, в решении дифференциальных интегральных уравнений, то на самом деле речь идет об одной из областей, где машинное обучение не представлено практически никак и имеет безумно плохую репутацию. Если ты скажешь человеку, который занимается решением уравнений в частных производных, что хочешь что-то делать нейронными сетями, он будет плеваться. Репутация более-менее понятная. Наверное, за этим стоит фундаментальная проблема: в таких уравнениях нужно получать решения с высокой точностью. Нужны значения 10-6 или 10-8. Для задач классификации нейронные сети — блестящая идея, а вот для задач регрессии — не всегда удачная. Как это можно было бы применить — совершенно отдельная тема, совершенно пустая. Успешных примеров мало, и людей, которые этим занимаются, тоже не так много. Я пытаюсь и то, и то делать, в надежде, что что-то замечательное придумается. Посмотрим.
Есть ощущение, что можно что-то задействовать, но требуется серьезная доработка. Нельзя взять условный TensorFlow и применить. Мы взяли, применили — ничего не работает, надо думать. Когда что-то не работает, это замечательная ситуация. Значит, ты должен понять, почему оно не работает.
Тем не менее, тензоры хорошо работают в этом случае. Есть теорема. Мы их формально дискретизируем в задачу на сетке из 260 виртуальных ячеек и строим решение на ноутбуке за несколько секунд. Там возникает куча всяких проблем. Мы берем трехмерный кубик, разбиваем его на n3 ячеек, а n = 2d, то есть 220, то есть миллион на миллион на миллион. И все перечисленное мы превращаем в 2х2х2х2, 60-мерный тензор. Вот эту штуку мы и ищем.
На самом деле, число параметров очень маленькое: 2 на d, которое 60, и на ранг, который 50. Формально мы решаем задачу, где очень много неизвестных.
Отдельный вопрос, зачем это нужно. Есть применение, связанное, например, с многомасштабным моделированием, когда есть очень маленькие масштабы и формально их надо разрешать. Тогда делать это можно в режиме черного ящика.
Дальше есть пример, когда ТТ был применен напрямую к нейронным сетям. Это TensorNet, работа Саши Новикова и группы Дмитрия Ветрова, работа с NIPS прошлого года. Просто вместо полносвязного слоя взят слой, который имеет вот такую структуру. У нас получается нелинейный структурированный слой, но при этом число параметров падает в огромное количество раз, а точность меняется несильно.
Можно сжимать и сверточные слои. Была у нас работа с группой Виктора Лемпицкого. Он сегодня будет читать блестящую лекцию, всем рекомендую.
Там мы ТТ не применяли, применили каноническое разложение. Сверточный слой можно представить как свертку с четырехмерным тензором, который мы просто засунули в ПО, считающее малоранговые аппроксимации. Оказалось, что можно восемь раз сжать. Там есть детали, напрямую оно не сработало, но результат следующий: можно действительно сжать восемь раз, и без особой потери точности.
Вот пример из биологии. Что мне нравится в таких вещах: можно применять практически один и тот же код в биологии, в машинном обучении, в химии, да еще и не зная предметного языка, а переводя всё на язык многомерных массивов и запуская черный ящик. Конечно, этому ящику требуется доработка, но всё же примеров применения в совершенно разных областях у нас уже достаточно много. Речь идет о неком биологическом цикле, где задача шестимерная. Он возникает, когда медведь спит — ему нужно быстро выработать энергию, чтобы прогреться. Это футильный бесполезный цикл, работа группы Кристофа Шваба из Цюриха. Владимир Козеев, который был студентом нашей кафедры ЭВМ, когда я там работал. Есть метод Монте-Карло, решающий некое стохастическое дифференциальное уравнение. 1500 ядер — 105 секунд. В MATLAB это все считалось тысячу секунд. Хорошее ускорение.
Считали колебательные состояния молекул. Было 12 степеней свободы, 12-мерная задача, примерно 3012 формальных неизвестных. По сравнению с некоторыми хитрыми и достаточно сложными химическими методами удалось добиться ускорения в десятки раз.
Недавняя работа на воркшопе с Сашей Новиковым под гордым названием Exponential Machines, где в качестве фич мы выбираем x1, x2, всевозможные подмножества, которых 2d. Мы запихнули их в тензор 2х2х2х2 и сказали: пусть он будет малого ранга. Работает. Дальше возникает оптимизация по этому тензору, надо всё делать, но работает.
Последний пример связан с рекомендательными системами. Мой аспирант Женя Фролов, большой эксперт в рекомендательных системах, может часами про них говорить. Часто поговорить ему о них не с кем, поэтому если кто-то интересуется рекомендательными системами — напишите ему, пожалуйста. Недавно нашу статью приняли на RecSys. Он создал некий фреймворк для рекомендательных систем под названием Polara. Там мы тензоры применили к классической задаче построения рекомендаций, где у вас есть пользователи, фильмы и рейтинг. В этой области есть некая проблема: все современные методы рекомендаций не учитывают негативный фидбек. Здесь пример: человек говорит, что ему не нравится фильм «Лицо со шрамом», а ему SVD рекомендует посмотреть еще «Крестного отца». «История игрушек» ему бы больше понравилась. Статья написана очень хорошо. Идея такая: вместо рассмотрения матрицы «пользователь — фильм» мы рассматриваем матрицу «пользователь — фильм — рейтинг» и пишем единицу, если пользователь поставил фильму оценку. В каком-то смысле рейтинги становятся выровненными. Мы к указанному трехмерному тензору уже строим факторизацию, делаем практически то, что делается стандартно, и получаем что-то вроде парадигмы: если вам не нравится это, вам, возможно, понравится нечто другое. Мы можем давать осмысленные рекомендации на основе одного негативного фидбека, что достаточно сложно.
Есть классы задач, когда у вас имеется экспоненциальная точность — то есть когда ошибка по числу параметров бывает экспоненциальной. Есть надежный набор алгоритмов. Можно вложить и сказать, что это тоже deep learning. В данной работе товарища из Израиля как раз говорится, что речь идет про arithmetic circuit. Но для него есть надежный набор алгоритмов, можно считать.
У нас есть страничка, проект на GitHub, можно писать и спрашивать. Всё, спасибо.
Поделиться с друзьями
Комментарии (5)

sergehog
31.10.2016 17:42Что еще кроме компрессии дает такое представление? Можно ли теперь быстро решить уравнение вида Ax = b, где A это тензор?
Что если у меня другая задача — есть матрица которую можно рассматривать как тензор большой размерности. Имеет ли смысл рассматривать ее как тензор чтоб решить уравнение как выше?



zabavinv
01.11.2016 00:38Все круто, но матричные вычисления сложны для ПК. Наткнулись на очень серьезные проблемы. пришлось искать другой подход для работы с матрицами и нашли однако :)
BelBES
Тут стоит заметить, что сжимать то свертки можно путем того-же разложения Таккера, но после этого надо долго и нудно дотренировывать сеть, т.к. без файнтюнинга качество просадает ну ооочень сильно.
з.ы. а какую именно сетку в 8 раз можно пожать только за счет разложения? Вроде бы для самых ходовых типа Vgg-16, GoogLeNet, AlexNet etc. в лучшем случае раз в 5 получается пожать.