
Хабр, привет! Наш выпускник 4-го набора программы «Специалист по большим данным» Кирилл Данилюк поделился своим исследованием, которое он выполнил в качестве финального проекта в одном из курсов. Вся документация и описание есть на его гитхабе. Здесь же мы приводим перевод его отчета. Осторожно — лонгрид.
Многие люди, работающие в сферах, связанных с данными, слышали о Kaggle – платформе для проведения соревнований по наукам о данных. Сегодня на Kaggle представлены более 600 тыс. data scientist'ов и множество широко известных компаний. Компания описывает свою проблему, задает метрики качества, публикует набор данных, который мог бы помочь ее решить, а участники находят оригинальные способы решения поставленной компанией задачи.
Данное соревнование Kaggle предоставлено компанией Allstate – крупнейшей публичной компанией США в сфере персонального страхования жизни и имущества. В данный момент Allstate занимается разработкой автоматических методов предсказания стоимости (тяжести) страховых требований и обратилась к сообществу Kaggle с просьбой продемонстрировать свежие идеи и новые подходы к решению этой проблемы.
Компания стремится улучшить качество своих услуг по обработке страховых требований и опубликовала набор данных о произошедших в домашних хозяйствах несчастных случаях (каждое домашнее хозяйство представлено вектором анонимизированных признаков) с указанием численной оценки стоимости страхового требования. Наша задача состояла в том, чтобы предсказать тяжесть возможного страхового требования для нового домохозяйства.
На Kaggle также доступны еще несколько связанных с данной задачей наборов данных:
• Соревнование Allstate по предсказанию страховых требований — более раннее соревнование Allstate, целью которого было предсказать страховые платежи на основе характеристик застрахованного транспортного средства. Набор данных этого соревнования предоставляет возможность погрузиться в область страхования.
• Соревнование по оценке потерь от огня – соревнование, проведенное Liberty Mutual Group и направленное на предсказание ожидаемых потерь от огня для формирования условий страховых контрактов. Это еще один пример набора данных из сферы страхования, который помог нам получить понимание подходов к решению задач предсказания в страховой индустрии.
Отдельно отмечу, что исходный набор данных является высоко анонимным (как в части названий признаков, так и в части значений). Этот аспект усложняет как понимание значения признаков, так и затрудняет обогащение набора данных из внешних источников. Участники соревнования по-разному пробовали обогатить и интерпретировать исходные данные, однако успех их попыток остаётся спорным. С другой стороны, в данном наборе данных, по всей видимости, отсутствует утечка данных, которая возникает, когда в тренировочных данных остается дополнительная информация. Такая информация может сильно коррелировать с целевой переменной и приводить к необоснованно точным предсказаниям. За последнее время от таких утечек пострадало достаточно большое число соревнований Kaggle.
В нашем распоряжении находится набор данных, содержащий записи по страховым требованиям клиентов компании Allstate. Каждая запись содержит как категориальные, так и непрерывные признаки. Целевая переменная представляет собой численную оценку потерь, вызванных данным страховым требованием. Все признаки сделаны максимально анонимными: мы не знаем ни настоящих названий признаков, ни их истинных значений.
Наша цель – построить модель, которая сможет правильно предсказать будущие потери на основе заданных значений признаков. Очевидно, что это задача регрессии: целевая переменная численная. Также это задача обучения с учителем: целевая переменная явно определена в тренировочном наборе данных, и нам необходимо получить ее значения для каждой записи тестового набора.
Компания Allstate проделала большую работу по очистке и предобработке данных: предоставленный набор данных в очень высокой степени очищен и (после небольшой дополнительной обработки) может быть передан большому числу алгоритмов обучения с учителем. Как мы увидим в части отчета, посвященной исследованию данных, задание компании Allstate особо не позволяет генерировать новые признаки или заниматься препроцессингом имеющихся фич. С другой стороны, этот датасет подталкивает к использованию и тестированию различных алгоритмов машинного обучения и ансамблей — как раз то, что нужно для дипломного проекта.
Я применил следующий подход к проекту Allstate:
1. Исследовать набор данных, понять значение данных, признаков и целевой переменной, и найти в данных простые взаимосвязи. Этот этап выполнен в файле Data Discovery notebook.
2. Произвести необходимую предобработку данных и обучить несколько различных алгоритмов машинного обучения (XGBoost и многослойный перцептрон). Получить базовые результаты. Эти задачи решены в файлах XGBoost и MLP.
3. Настроить модели и добиться заметного улучшения результатов по каждой из них. Этот этап также осуществлен в файлах XGBoost и MLP.
4. Обучить ансамбль используя технику наложения моделей (стэкинг) с использованием предыдущих моделей как базовых предикторов. Получить итоговые результаты, которые будут значительно лучше предыдущих. Этот этап реализован в файле Stacking notebook.
5. Кратко обсудить результаты, дать оценку итоговой позиции в турнирной таблице соревнования и найти дополнительные пути ее улучшения. О результатах мы поговорим ниже в данном отчёте и в последней части файла Stacking notebook.
Платформа Kaggle требует от компании, проводящей соревнование, четко определить метрику, по которой могут соревноваться участники. Компания Allstate выбрала в качестве такой метрики MAE. MAE (средняя абсолютная ошибка) – очень простая и очевидная метрика, которая напрямую сравнивает предсказанные и истинные значения.
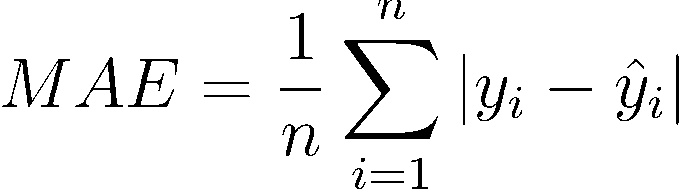
Эта метрика задана и не может быть изменена, т.к. является частью условий соревнования. Тем не менее, я считаю ее хорошо подходящей к данной задаче. Во-первых, MAE (в отличие от MSE или среднеквадратичной ошибки) не дает большого штрафа за неверную оценку выбросов (в датасете присутствует несколько выбросов с аномально высокими значениями потерь). Во-вторых, MAE проста для понимания: значения ошибки выражаются в тех же измерениях, что и сама целевая переменная. Вообще говоря, MAE – хорошая метрика для новичков в науках о данных. Ее легко вычислить, просто понять и трудно неправильно интерпретировать.
Для полного ознакомления с этим этапом вы можете обратиться к файлу Data Discovery.
Вся обучающая выборка состоит из 188318 элементов, индексированных с помощью переменной uid. Индекс для работы с данными не несёт дополнительной информации, т.к. это просто нумерация, начиная с «1» с некоторыми пропущенными значениями. Мы не собираемся использовать для предсказания тестовый набор без индекса (она необходима для отправки результатов на Kaggle), однако стоит отметить, что тестовый набор данных организован так же, как и тренировочный. Очевидно, обучающая и тестовая выборки были получены из одного набора данных разбиением процедурой, например, train_test_split из пакета sklearn.
Основные результаты данной части проекта следующие:
• Набор данных содержит 130 различных признаков (без учета индекса id и целевой переменной loss). С учетом размеров набора данных, это вполне разумное число признаков. Мы едва ли могли бы столкнуться здесь с «проклятием размерности».
• 116 признаков категориальные, 14 численные. Вероятно, нам нужно будет закодировать эти 116 признаков, так как большинство алгоритмов машинного обучения не могут корректно обрабатывать категориальные переменные. Способы такого кодирования и различия между ними мы обсудим позднее.
• Во всем наборе данных нет ни одного пропущенного значения. Такой факт лишь подтверждает, что компания Allstate предоставила данные с высокой степенью предварительной обработки, чтобы сделать их доступными и простыми в использовании.
• Большинство категориальных признаков (72 или 62%) бинарные (да/нет; мужчина/женщина), но их значения записаны просто как «A» и «B», поэтому мы никак не можем догадаться об их значении. 3 признака принимают три различных значения, 12 признаков – 4 различных значения.
• Численные признаки уже отмасштабированы в диапазоне от 0 до 1, стандартные отклонения для всех них близки к 0.2, средние значения составляют порядка 0.5, поэтому и для этих признаков мы не можем сделать никаких предположений об их значении.
• По всей видимости, некоторые численные признаки раньше были категориальными до их преобразования в численные с помощью LabelEncoder или схожей процедуры.
• Построив гистограммы различных признаков, можно убедиться, что ни один из них не подчиняется нормальному закону распределения. Можно попробовать снизить асимметрию распределения этих данных (в случае scipy.stats.mstats.skew > 0.25), однако даже после такого преобразования добиться распределения, близкого к нормальному, не удастся.
• Целевая переменная также распределена не нормально, хотя и может быть простым логарифмическим преобразованием приведена к распределению, близкому к нормальному.
• Целевая переменная содержит несколько выбросов с аномально высокими значениями (очень серьезные происшествия). В идеальном случае мы хотели бы, чтобы наша модель умела идентифицировать и правильно предсказывать такие выбросы. В то же время мы можем легко на них переобучиться, если не будем достаточно осторожны. Ясно, что здесь необходим некоторый компромисс.
• Обучающая и тестовая выборки имеют сходные распределения данных. Это идеальная характеристика разбиения на обучающую и тестовую выборки, которая сильно упрощает кросс-валидацию и позволяет нам принимать информированные решения о качестве моделей, используя кросс-валидацию на тренировочном наборе данных. Это значительно упростило участие в соревновании Kaggle, однако не будет полезно для выполнения дипломного проекта.
• Несколько непрерывных признаков сильно коррелированы (корреляционная матрица отображена на рис. 1 ниже). Это приводит к основанной на данных мультиколлинеарности в этом наборе данных, что может радикально снизить предсказательную способность линейных регрессионных моделей. Частично эту проблему можно решить с помощью L1 или L2 регуляризации.
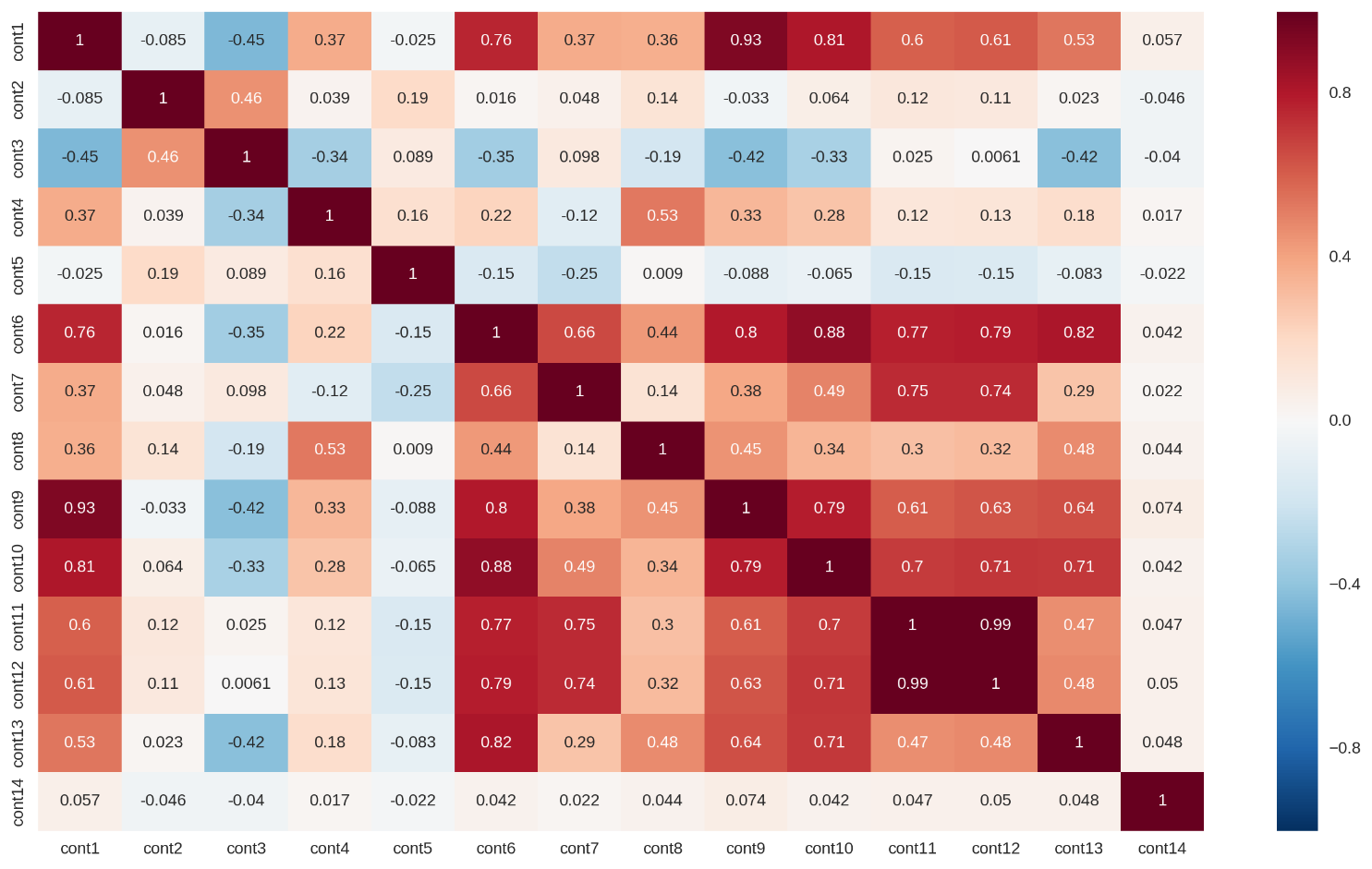
Рисунок 1: Корреляционная матрица для непрерывных признаков
Я покажу одну визуализацию для того, чтобы продемонстрировать важную черту этого набора данных – высокую степень анонимности, предварительной обработки данных.
Ниже приведены гистограммы 14 непрерывных признаков, помеченных как cont#. Как видно из рис. 1, распределения данных могут иметь множественные пики, и функции плотности распределений не близки к гауссовским. Мы могли бы попытаться снизить коэффициент асимметрии данных, но применение алгоритмов нормализации (например, преобразования Бокса-Кокса) мало что дало для данного набора данных.
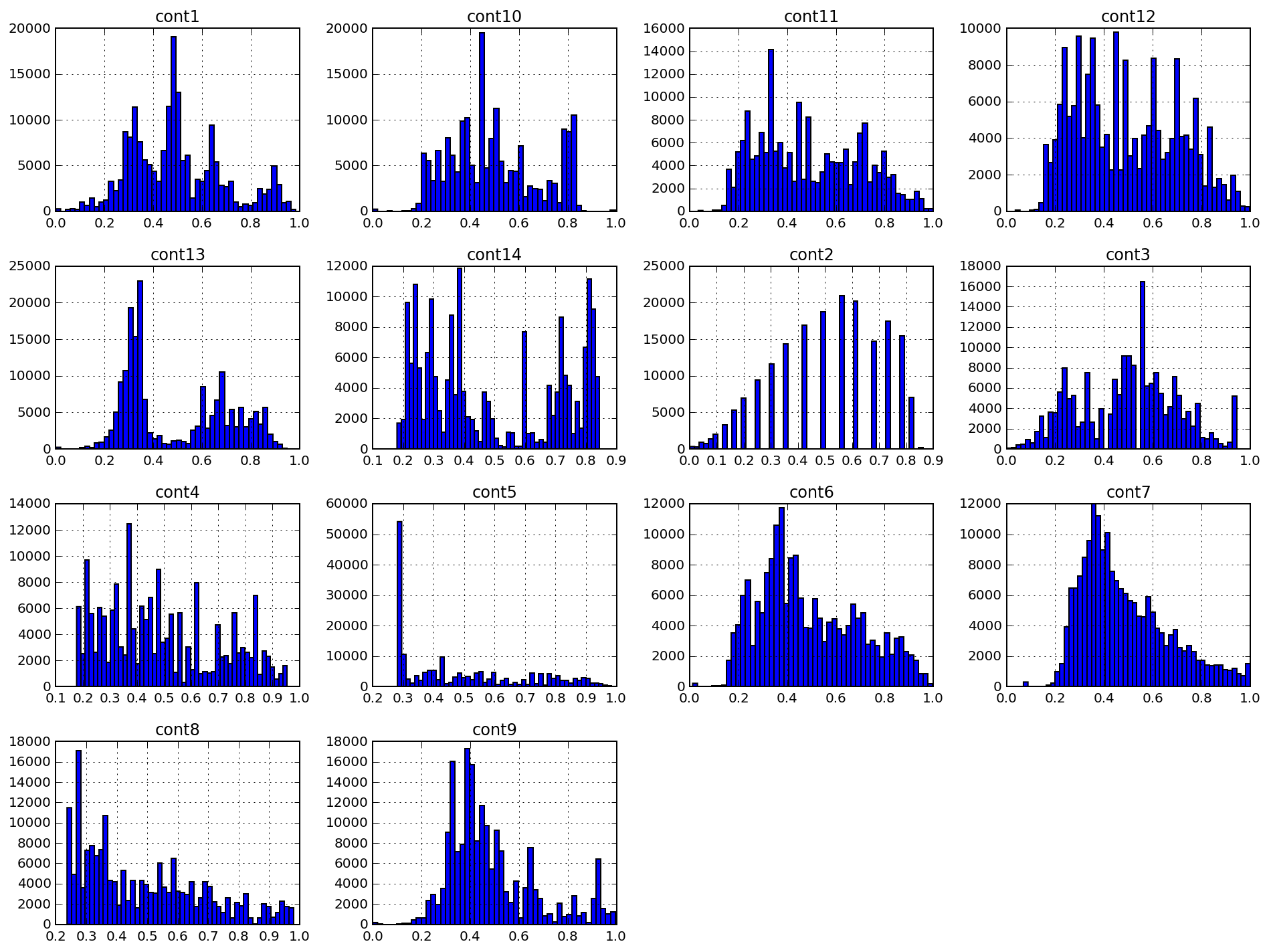
Рисунок 2: Гистограммы непрерывных признаков
Особенно интересен признак cont2. Этот признак был, по всей видимости, получен из категориального и может отражать возраст или возрастную категорию. К сожалению, я не углублялся в изучение этого признака: на мой проект он никакого влияния не оказал.
Этот раздел гораздо подробнее раскрыт в двух следующих документах: XGBoost notebook и MLP notebook.
XGBoost. Одна из причин моего интереса к проекту — это возможность попробовать метод бустинга над деревьями и, в частности, XGBoost. Де-факто этот алгоритм стал своеобразным стандартным швейцарским ножом для множества соревнований Kaggle благодаря его масштабируемости, гибкости и впечатляющей предсказательной силы.
XGBoost подходит для задач обучения с учителем, сходных с той, которую мы имеем (четко определенные тренировочный набор данных и целевая переменная). Ниже мы опишем принципы работы алгоритма XGBoost.
XGBoost, в сущности, является вариацией бустинга — ансамблевого мета-алгоритма машинного обучения, применяемого для снижения смещения и дисперсии в обучении с учителем, и семейства алгоритмов машинного обучения, которые превращают слабые модели в более сильные. Источник: Википедия. Изначально, идеи бустинга уходят корнями в поставленный Kearns и Valiant вопрос о том, могут ли «слабые» обучающиеся алгоритмы, которые дают результаты чуть лучше случайного гадания в PAC (вероятно приблизительно правильной) модели, быть “усилены” до “сильного” обучающегося алгоритма произвольной точности. Источник: Краткое введение в бустинг (Yoav Freund и Robert E. Schapire). Утвердительный ответ на этот вопрос был дан R.E.Schapire в его статье Сила слабой обучаемости, которая привела к разработке множества алгоритмов бустинга.
Как видно, основополагающим принципом бустинга является последовательное применение слабых алгоритмов обучения. Каждый последующий слабый алгоритм пытается уменьшить смещение всей модели, объединяя, таким образом, слабые алгоритмы в мощную ансамблевую модель. Можно привести множество различных примеров алгоритмов и методов бустинга, таких как AdaBoost (адаптивный бустинг, который подстраивается под слабые алгоритмы обучения), LPBoost и градиентный бустинг.
XGBoost, в частности, является библиотекой, реализующей схему градиентного бустинга. Модели градиентного бустинга строятся поэтапно, точно так же, как и при использовании других методов бустинга. Этот метод бустинга обобщает слабые обучающиеся алгоритмы, допуская оптимизацию произвольной дифференцируемой функции потерь (функции потерь с вычислимым градиентом).
XGBoost, как разновидность бустинга, включает оригинальный основанный на решающих деревьях алгоритм машинного обучения, пригодный для работы с разреженными данными; теоретически обоснованная процедура позволяет работать с весами различных элементов в обучении деревьев. Источник: XGBoost: масштабируемая система бустинга над деревьями (Tianqi Chen, Carlos Guestrin)
Можно привести ряд достоинств алгоритма XGBoost:
• Регуляризация. Как будет показано в разделе, посвященному модели многослойного перцептрона, при использовании других алгоритмов легко можно получить переобученную модель. XGBoost предоставляет очень надежные готовые к использованию средства регуляризации вместе с набором параметров для настройки этого процесса. Перечень этих параметров включает: gamma (минимальное уменьшение функции потерь, необходимое для дальнейшего деления дерева), alpha (вес для L1-регуляризации), lambda (вес для L2-регуляризации), max_depth (максимальная глубина дерева), min_child_weight (минимальная сумма весов всех наблюдений, требующаяся для дочернего объекта).
• Реализация параллельных и распределенных вычислений. В отличие от многих других алгоритмов бустинга, обучение здесь может производиться параллельно, тем самым сокращая время обучения. XGBoost работает действительно быстро. По утверждению авторов вышеупомянутой статьи, «система работает более чем в 10 раз быстрее существующих популярных решений уже на одном компьютере и может быть масштабирована на миллионы экземпляров в распределенном или ограниченном по памяти окружении».
• Встроенная кросс-валидация. Кросс-валидация является необходимым условием оценки качества полученной модели, и в случае с XGBoost ее процесс работы с ней крайне прост и понятен.
MLP. Вторая модель, которую мы строим – полносвязная нейронная сеть прямого распространения или многослойный перцептрон. Так как наша конечная цель – построить ансамбль (stacking) базовых регрессоров (и мы определились с типом первого из них — XGBoost), мы должны найти другой «тип» обобщающего алгоритма, который будет иначе исследовать наш набор данных.
Это то, когда имеют в виду, когда говорят, что обобщающие алгоритмы нулевого уровня должны «покрывать пространство». Wolpert, Обобщение наложением.
Путем добавления большего числа слоев и большего числа элементов внутри каждого слоя нейронная сеть может улавливать очень сложные нелинейные связи в данных. Универсальная теорема аппроксимации утверждает, что нейронная сеть прямого распространения может аппроксимировать любую непрерывную функцию в евклидовом пространстве. Таким образом, многослойный перцептрон является очень мощным алгоритмом моделирования. Многослойные перцептроны легко подвержены переобучению, но в нашем распоряжении есть все необходимые инструменты для того, чтобы снизить влияние этого фактора: случайное выключение активации нейронов (dropout), L1-L2 регуляризация, нормализация пакетов (batch normalization) и т.д. Мы также можем обучить несколько сходных нейронных сетей и усреднить их предсказания.
Сообщество, занимающееся глубоким обучением, разработало высококачественное программное обеспечение для обучения и оценки моделей, основанных на искусственных нейронных сетях. Мои модели построены на базе TensorFlow, библиотеки для тензорных вычислений, разработанной Google. Чтобы упростить построение моделей, я принял решение использовать Keras, высокоуровневый внешний интерфейс для TensorFlow и Theano, который берет на себя большую часть стандартных операций, необходимых для построения и обучения нейронных сетей.
GridSearch и Hyperopt. Данные методы применяются для отбора моделей и настройки гиперпараметров. В то время как GridSearch (поиск по сетке) исчерпывающим образом перебирает все возможные комбинации параметров, Hyperopt либо выбирает заданное число кандидатов из пространства параметров с заданным распределением, либо использует форму байесовской оптимизации. Вместе с обоими этими методами отбора мы используем для оценки производительности моделей технику кросс-валидации. Мы используем кросс-валидацию с разбиением на k частей (k-fold) с тремя или пятью частями в зависимости от вычислительной сложности модели.
Наложение моделей (stacking). Мы комбинируем предсказания двух из наших моделей (XGBoost и многослойный перцептрон) для построения финального предсказания, используя метарегрессор. Данный метод называется наложением (stacking) и интенсивно используется на Kaggle (часто чрезмерно). Идея стэкинга в том, чтобы разбить обучающую выборку на k частей и обучать каждый из базовых регрессоров на k-1 частях, делая предсказания на оставшейся части. В итоге, мы получаем обучающую выборку с предсказаниями регрессора (out-of-fold), имея при этом реальные значения целевой переменной. Далее, мы обучаем метамодель на этих данных, используя предсказания каждого регрессора как признак для метамодели, а истинные значения — как целевой признак.
Обученной метамодели мы подаём на вход предсказания регрессоров для тестовой выборки и получаем уже финальные предсказания, в которых обученная модель учитывает характерные ошибки каждого регрессора. Реализация данного этапа детально раскрыта в файле Stacking notebook.
Первый результат был задан компанией Allstate: они обучили ансамблевую модель случайного леса и получили результат MAE=1217.52141. Этот результат легко превзойти даже простой моделью XGBoost, и большинству участников это удалось.
Я также установил для себя несколько критериев, когда обучал модели. Нижней границей для меня выступала производительность простой модели данного класса. Для XGBoost такой результат был установлен на MAE=1219.57, он достигается простой моделью из 50 деревьев без какой-либо оптимизации или настройки гиперпараметров. Я взял стандартные значения гиперпараметров (предложенные в статье от Analytics Vidhya), оставил небольшим количество деревьев и получил этот стартовый результат.
Для многослойного перцептрона в качестве базового результата была выбрана производительность двухслойной модели с маленьким числом элементов в ее скрытом слое (128) с функцией активации ReLU, стандартной инициализацией весов и оптимизатором Adam GD: MAE=1190.73.
В данном дипломном проекте я избегал сложных baseline-моделей, так как понимаю, что все результаты должны быть воспроизводимыми. Я также участвую в этом соревновании Kaggle, однако обучение всех моих используемых в соревновании моделей, большинство из которых представляет собой комбинации и использует большое число алгоритмов, точно потребует от читателя слишком много времени. В соревновании Kaggle я надеюсь превзойти результат MAE=1100.
Я уже упоминал, что этот датасет уже был хорошо подготовлен и предварительно обработан, например, непрерывные признаки были отмасштабированы в интервал [0,1], категориальные признаки были переименованы, их значения были превращены в числа. Фактически, в части предобработки здесь осталось не так много того, что можно было бы еще сделать. Однако некоторая работа еще должна быть проделана для того, чтобы можно было обучать корректные модели.
Предварительная обработка целевой переменной
Наш целевой признак имеет экспоненциальное распределение, которое может понизить качество регрессионных моделей. Как известно, регрессионные модели лучше всего работают тогда, когда целевая переменная распределена нормально.
Чтобы решить эту проблему, мы просто применяем к целевой переменной loss логарифмическое преобразование: np.log(train['loss']).
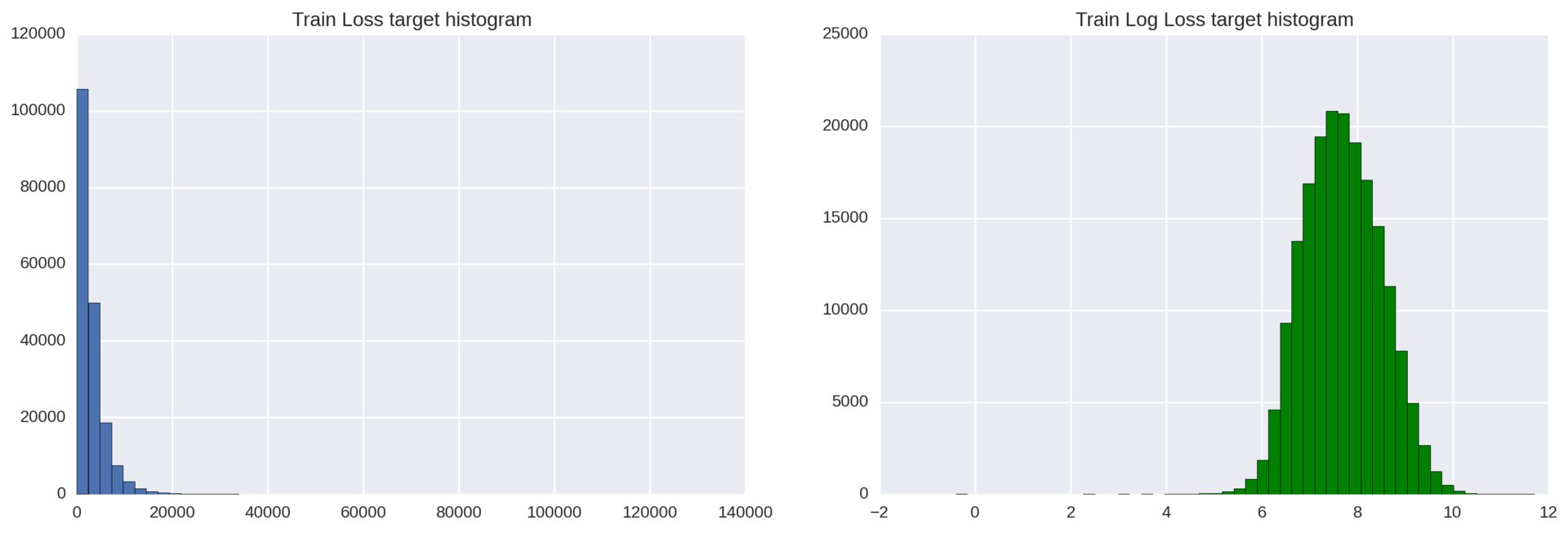
Рисунок 3: Гистограммы распределения целевой переменной до и после логарифмического преобразования
Полученный результат можно улучшить: слева от основного колокола распределения лежат несколько отклоняющихся наблюдений. Чтобы избавиться от этих выбросов, мы можем сдвинуть все значения переменной loss на 200 пунктов вправо (loss+200) и затем взять от них логарифм.
Кодирование категориальных переменных
Большинство алгоритмов машинного обучения не могут напрямую работать с категориальными переменными. XGBoost здесь не является исключением, так что нам нужно будет преобразовать наши категориальные переменные в численные. Здесь можем выбрать одну из двух стандартных стратегий: кодирование меток (label encoding) или прямое кодирование (one-hot encoding). Какую стратегию использовать – вопрос достаточно спорный, однако здесь следует рассмотреть несколько факторов:
Прямо кодирование (one-hot encoding) – это базовый способ работы с категориальными признаками. Он выдает разреженную матрицу, где каждый новый столбец представляет одно возможное значение какого-либо одного признака. Так как у нас 116 категориальных переменных, и переменная cat116 принимает 326 значений, мы можем получит разреженную матрицу с огромным количество нулей. Это приведет к более длительному обучению, увеличит затраты памяти и может даже ухудшить итоговые результаты. Другой недостаток прямого кодирования – потеря информации в тех случаях, когда имеет значение порядок категорий.
Кодирование меток (label encoding), с другой стороны, просто нормализует столбец входных данных так, что он содержит только значения между 0 и числом классов-1. Для многих алгоритмов регрессии это не слишком хорошая стратегия, однако XGBoost может справляться и справляется с таким преобразованием очень хорошо.
Для XGBoost мы будем использовать LabelEncoder и нормализуем входные данные. Для многослойного перцептрона нам нужно будет создавать фиктивные переменные, таким образом, наш выбор здесь – one-hot encoding.
Как было упомянуто ранее, наша методология реализации машинного обучения будет подразделяться на два раздела:
• Обучение, настройка и кросс-валидация базовых моделей (моделей нулевого уровня): XGBoost и многослойного перцептрона в предположении, что мы уже произвели предварительную подготовку данных, которая для этих двух моделей немного различается. Разница будет в кодировании признаков (прямое или кодирование меток) и (к сожалению) в отсутствии логарифмического преобразования целевой переменной для модели многослойного перцептрона. Итогом этой части будут две настроенные модели, результаты которых будут отвечать установленным критериям.
• Обучение и валидация модели уровня 1, то есть, наложения моделей. Итогом этого раздела станет новая метамодель, дающая результаты лучшие, чем каждая из базовых моделей нулевого уровня, которые мы обучили ранее.
Теперь пришло время дать детальный обзор каждого из разделов.
Раздел 1. Модели нулевого уровня: обучение, настройка, кросс-валидация
Методология обучения модели XGBoost (адаптированный вариант руководства по настройке XGBoost от Analytics Vidhya):
1. Обучим неглубокую и простую модель с параметрами num_boost_round=50, max_depth=5 и получим базовый результат MAE=1219.57. Такой результат мы установим в качестве нижней границы и будем улучшать его с помощью настройки модели.
2. Чтобы облегчить оптимизацию гиперпараметров, мы реализуем собственный класс XGBoostRegressor, построенный над XGBoost. Такой класс, по большому счёту, необязателен для работы модели, однако даст нам ряд преимуществ (мы сможем использовать собственную функцию потерь и минимизировать эту функцию вместо максимизации) при использовании поиска по сетке GridSearchCV, реализованного в scikit-learn.
3. Мы определим и зафиксируем скорость обучения и количество деревьев, которые будут в каждом следующем переборе по сетке. Поскольку наша задача состоит в том, чтобы за минимальное время получить неплохой результат, мы поставим небольшое число деревьев и высокую скорость обучения: eta=0.1, num_boost_round=50.
4. Настроим параметры max_depth и min_child_weight. Эти гиперпараметры рекомендуется настраивать совместно, т.к. увеличение max_depth приводит к возрастанию сложности модели (и увеличивает вероятность переобучения). В то же самое время min_child_weight выступает регуляризирующим параметром. Мы получаем следующие наилучшие параметры: max_depth=8, min_child_weight=6. Это улучшает результаты с MAE=1219.57 до MAE=1186.5.
5. Настроим gamma, параметр регуляризации.
6. Настроим соотношение числа признаков и элементов обучающей, которое будет использоваться в каждом из деревьев: colsample_bytree, subsample. Мы получаем следующую оптимальную конфигурацию: subsample=0.9, colsample_bytree=0.6 и улучшаем наши результаты до MAE=1183.7.
7. Наконец, добавим больше деревьев (увеличим параметр num_boost_round) и снизим интенсивность обучения eta. Мы также выработаем практическое правило для понимания связи между этими двумя гиперпараметрами. Наша финальная модель использует 200 деревьев, имеет eta=0.07 и итоговый результат MAE=1145.9.
Пример процесса настройки параметров модели с использованием Grid Search показан на рисунке 4 ниже (подробности вы найдете в этом файле):
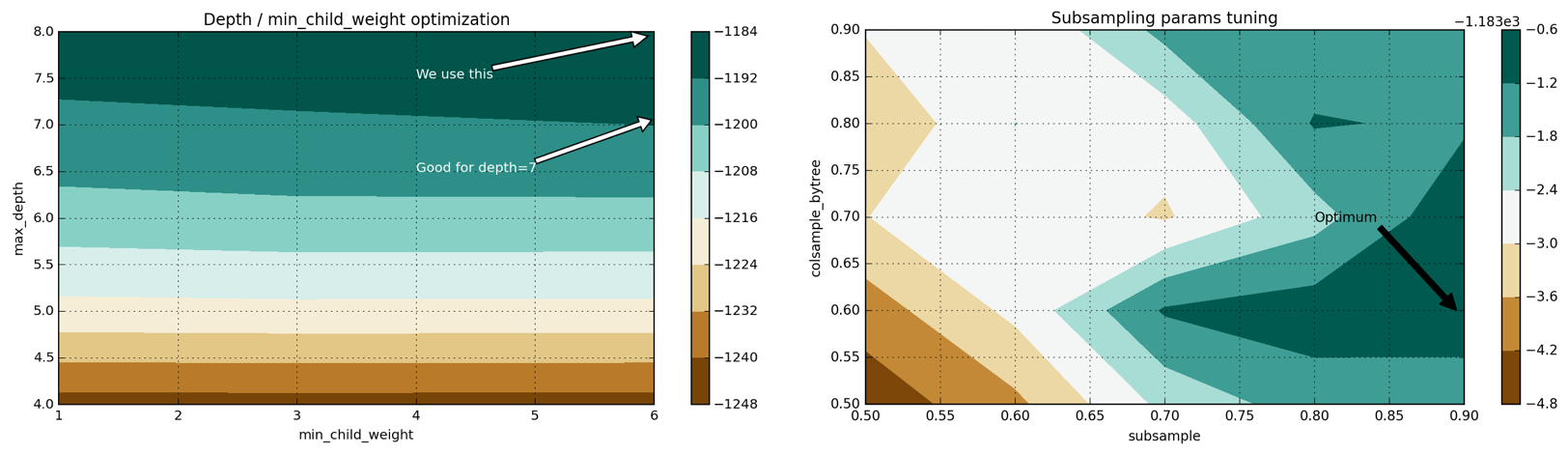
Рисунок 4: двумерные пространства гиперпараметров для пар max_depth–min_child_weight и colsample-subsampling
Методология обучения модели многослойного перцептрона:
1. Начнем с простого и построим базовую модель с единственным скрытым слоем (двухслойную), функцией активации ReLU и оптимизатором Adam, реализующим метод градиентного спуска. Такие неглубокие модели трудно переобучить, они быстро обучаются и дают хорошие начальные результаты. В терминах компромисса между смещением и дисперсией они представляют собой смещенные модели, однако стабильны и дают достойный результат MAE=1190.73 для такой простой модели.
2. Используем кросс-валидацию с разбиением на k частей (k-fold) для измерения производительности более глубоких моделей и для визуализации переобучения. Обучим трехслойную модель, покажем, что она легко подвержена переобучению.
3. Добавим в трехслойную модель регуляризацию: выключение нейронов (dropout) и раннюю остановку (early stopping). Определим несколько возможных конфигураций для последующего ручного тестирования: эти конфигурации отличаются числом скрытых элементов и вероятностью выключения нейронов. Обучим эти модели, рассмотрим и сравним их результаты, полученные на кросс-валидации, и выберем лучшую. В действительности при таком подходе мы не получим никаких улучшений: результаты по сравнению с двухслойной моделью лишь ухудшатся. Такой исход может быть вызван ручным (и тем самым неточным) подходом к регуляризации многослойного перцептрона. Мы просто определяем некоторые разумные интенсивности выпадения для слоев, но нет никакой гарантии того, что выбранные интенсивности будут оптимальными.
4. Введем в работу Hyperopt, чтобы осуществлять поиск в пространстве гиперпараметров автоматизированным и более интеллектуальным способом (будем использовать tpe.suggest, деревья оценивающих алгоритмов Парзена). Запустим несколько итераций Hyperopt на многочисленных конфигурациях гиперпараметров с различными выпадением нейронов, составом слоев и числом скрытых элементов. Наконец, мы выясним, что лучше всего использовать четырехслойную архитектуру (три скрытых слоя) с оптимизатором adadelta, нормализацией пакетов (batch normalization) и выпадением нейронов.
Финальная архитектура многослойного перцептрона:

Рисунок 5: финальная архитектура многослойного перцептрона
Результат этой модели на кросс-валидации составил: MAE=1150.009.
Раздел 2. Обучение модели первого уровня
К настоящему моменту мы обучили и настроили модели нулевого уровня: XGBoost и многослойный перцептрон. В этом разделе мы составим набор данных из создаваемых при кросс-валидации предсказаний моделей нулевого уровня (для которых известны истинные значения) и тестовой выборки предсказаний моделей нулевого уровня, которые будут использованы для итоговой оценки качества метамодели.
Для полного ознакомления с процессом построения ансамбля моделей обратитесь, пожалуйста, к этому файлу.
Методология построения ансамбля, которую я использовал, описана ниже:
• Шаг 1. Новое обучение и генерация отложенного набора данных. Поскольку мы не отправляем результаты на Kaggle и не «пробиваем лидерборд», мы должны будем разбить обучающую выборку на две части: обучение и тест. Обучающая подвыборка будет использоваться для генерации предсказаний моделей нулевого уровня на кросс-валидации с разбиением на k частей (k-fold), тогда как отложенный набор данных будет применяться лишь для финальной оценки производительности двух моделей нулевого уровня и метамодели.
• Шаг 2: Разбиение. Разобьем обучающую выборку на k частей, которые будут использоваться для обучения моделей нулевого уровня.
• Шаг 3: Предсказания на кросс-валидации. Обучим каждую модель нулевого уровня на K-1 частях, построим предсказания для оставшейся части. Повторим этот процесс для всех K частей. В конце мы получим предсказания для всей тестовой выборки (для которой у нас также есть метки).
• Шаг 4: Обучение на всей выборке. Обучим каждую из моделей нулевого уровня на всем обучающем наборе данных и получим предсказания для тестового набора. Составим из полученных предсказаний новый набор данных, в котором каждый из признаков является предсказанием одной из моделей нулевого уровня.
• Шаг 5: Обучение модели первого уровня. Обучим модель первого уровня на полученный при кросс-валидации предсказаниях, используя соответствующие им метки из обучающей выборки как метки для модели уровня 1. После этого, используя наш комбинированный набор данных предсказаний моделей нулевого уровня, мы получим финальные предсказания модели первого уровня.
В качестве модели первого уровня мы выбираем линейную регрессию: метамодель легко подвержена переобучению (да и, честно говоря, в самом соревновании мало что работало лучше простой линейной регрессии как метамодели). Данное наложение сработало очень хорошо и значительно улучшило полученные результаты. После кросс-валидации моделей нулевого уровня и финальной ансамблевой модели на скрытом наборе данных мы получили следующие результаты:
Результат наложения моделей MAE=1136.21 заметно лучше результата лучшей из моделей нашего ансамбля. Конечно, этот результат может быть еще улучшен, однако в данном проекте мы идем на компромисс между увеличением предсказательной способности модели и снижением времени обучения.
Пояснение: этот набор результатов был вычислен на отложенной выборке, не через кросс-валидацию. Таким образом, мы не имеем права напрямую сравнивать результаты, полученные на кросс-валидации, с результатами на отложенном наборе данных. Тем не менее, отложенный набор данных имеет, как ожидается, распределение, близкое к распределению всего набора данных. Вот почему мы можем утверждать, что наложение действительно улучшило достигнутые нами показатели.
В качестве заметки на полях, было бы любопытно узнать, с какими весами вошли в наложение наши модели нулевого уровня. В линейной регрессии финальное предсказание – это просто линейная комбинация весов и исходных предсказаний:
Чтобы оценить наши результаты, мы обучим и произведем валидацию наших финальных моделей (отдельных и ансамбля) на различных подвыборках набора данных. Таким образом мы сможем увидеть, насколько стабильны наши модели и могут ли они давать устойчивый результат вне зависимости от начальной обучающей выборки. Для достижения этих целей мы обобщим наложение моделей из документа Stacking notebook до класса modules/stacker.py, который позволяет быстро вызывать процедуры оценки наших моделей с различными сидами (чтобы модели немного отличались друг от друга).
Мы обучим наши модели нулевого и первого уровней с 5 разными сидами и запишем результаты в таблицу. Затем мы используем метод pd.describe для получения агрегированной статистики по производительности каждой из моделей. Наиболее характерными метриками здесь будут среднее (mean) и стандартное отклонение (std):

Как можно видеть, наши модели достаточно стабильные (стандартное отклонение низкое) и ансамбль всегда превосходит любую другую модель. Его самый низкий результат лучше самого лучшего результата самой лучшей из индивидуальных моделей (MAE=1132.165 против MAE=1136.59).
Еще одно пояснение: Я старался внимательно обучать и валидировать модели, однако здесь все еще может быть пространство для утечек информации, которые остались незамеченными. Все модели демонстрируют улучшение результатов, которое могло быть вызвано одной такой утечкой (но мы обучили только пять моделей, параметр seed=0 мог просто дать худшие результаты). Тем не менее, итоговые выводы остаются валидными: усреднение нескольких наложений, обученных с различными сидами, улучшает итоговые результаты.
Наши базовые результаты: MAE=1217.52 (модель случайного леса от компании Allstate) и MAE=1190.73 (MAE простого многослойного перцептрона). Наша финальная модель улучшила первый результат на 7.2% и на 5.1% — второй.
Чтобы измерить значимость этих результатов, добавим каждый из базовых результатов в таблицу результатов, полученной в предыдущем разделе, и выясним, могут ли наши базовые результаты быть названы аномальными. Так, если базовые результаты можно рассматривать как выбросы, разница между нашими финальными и базовыми результатами будет значимой.
Чтобы произвести этот тест, мы можем вычислить показатель IQR (интерквартильный размах), который используется для выявления аномалий и выбросов. Затем мы вычислим третью квантиль данных (Q3) и используем формулу Q3 + 1.5 * IQR для установления верхней границы результатов. Значения выше этой границы считаются выбросами. При проведении этого теста мы ясно видим, что оба базовых результата оказываются выбросами. Таким образом, мы можем сказать, что наше наложений моделей значительно превосходит базовые контрольные точки.
На выходе получим:
Давайте абстрагируемся от деталей и взглянем на проект как на единое целое. Мы обучали и оптимизировали две основные модели: XGBoost и многослойный перцептрон. Мы сделали ряд шагов, начиная от самой простой из возможных моделей и заканчивая настроенной, более устойчивой и сложной моделью. После этого мы создали предсказания на кросс-валидации для нашей модели уровня 1, линейной регрессии, и использовали технику стэкинга для объединения предсказаний моделей нулевого уровня. Наконец, мы сделали валидацию производительности стэкинга и обучили пять его вариаций. Усредняя результаты этих пяти моделей, мы получили финальный результат: MAE=1129.91.
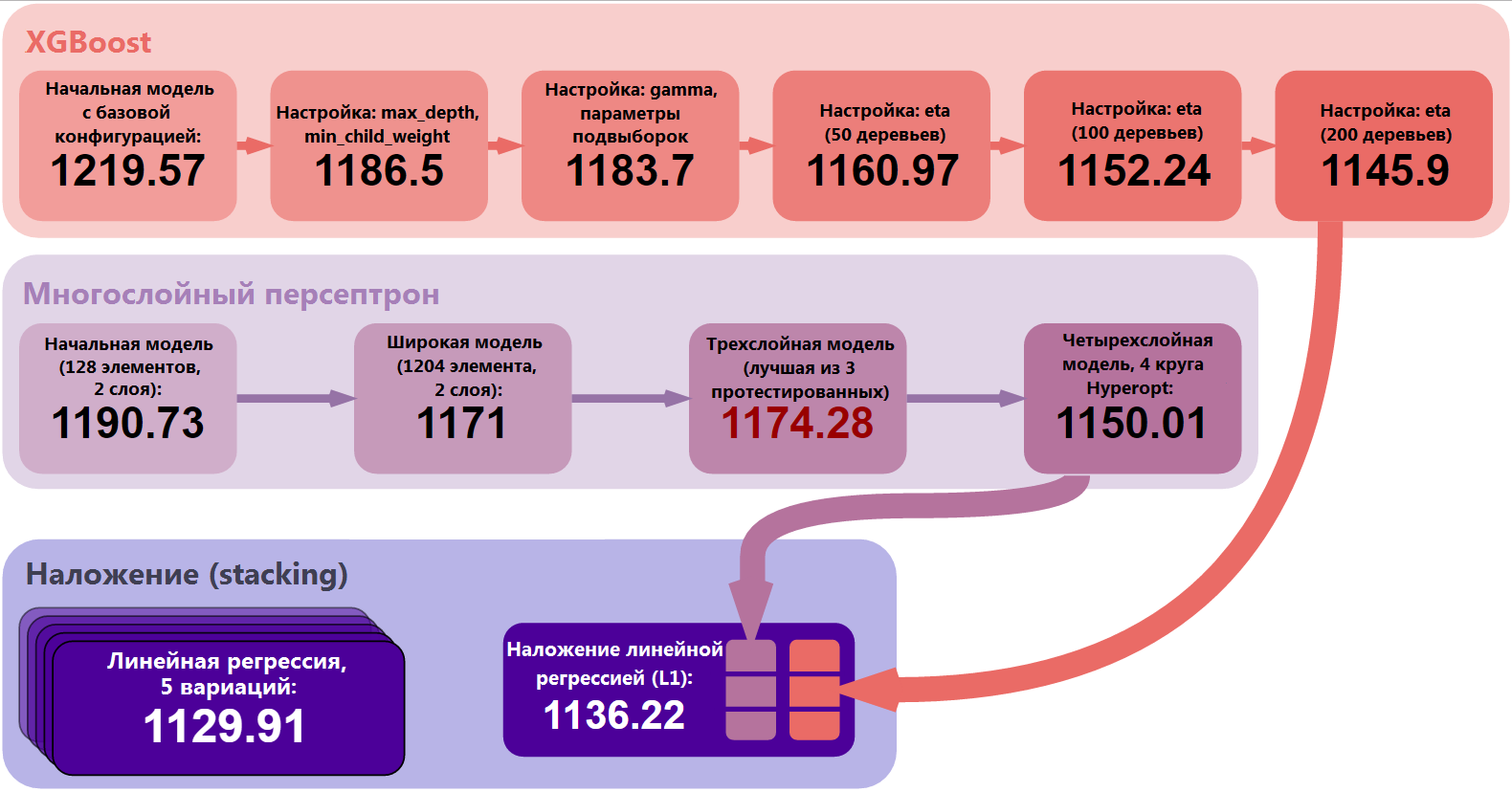
Рисунок 6: Основные этапы улучшения результатов
Конечно, мы могли бы включить в нулевой уровень и большее число моделей, или могли бы сделать их ансамбль более сложным. Один из возможных путей – обучить несколько полностью различных ансамблей и скомбинировать их предсказания (например, как линейную комбинацию) на новом уровне, уровне 2.
Полное решение задачи
Идеей данного проекта было работать с набором данных, в котором не требуется создания новых признаков. Иметь такой набор данных очень приятно, т.к. это позволяет сосредоточиться на алгоритмах и их оптимизации, а не на предварительной обработке данных и внесении в них изменений. Конечно, мне хотелось испытать в действии XGBoost и нейронные сети, и выбранный набор данных мог дать хорошую базовую оценку качества моей модели в сравнении с результатами других участников Kaggle.
Даже с приведенными в проекте слабыми моделями мы получили значительное превышение базовых результатов: на 7.2%. Мы сравнили базовые результаты с финальными и убедились в том, что финальные результаты действительно являются значимым улучшением.
Трудности
Данный проект не был тривиальным. Хотя я и не демонстрировал никаких особенных или креативных подходов к набору данных, таких как создание новых признаков, понижение размерности или обогащение данных, вычислительная сложность требуемых для Kaggle моделей оказалась выше той, что я ожидал.
Главной проблемой в Allstate Claims Severity стала воспроизводимость вычислений. Для ее обеспечения нужно было выполнить ряд предварительных требований: процесс получения результата должен был быть ясным, вычисления – детерминированными (или хотя бы с ограниченными колебаниями) и воспроизводимыми за разумное время на любом современном оборудовании. В результате я сильно понизил сложность моих действующих моделей и полностью исключил некоторые техники (например, я исключил технику бэггинга (bagging) для XGBoost и многослойного перцептрона, хотя после применения бэггинга эти модели показывают заметно лучшие результаты).
Этот проект был выполнен преимущественно на инфраструктуре Amazon Web Services: я использовал экземляры p2.xlarge с GPU-вычислениями для многослойного перцептрона (GPU NVIDIA Tesla K80, 12 Гб памяти GPU) и экземляры c4.8xlarge с CPU-вычислениями для XGBoost (36 vCPU, 60 Гб памяти). В моем проекте есть несколько разделов, которые требуют тяжелых вычислений:
• Поиск по сетке. Перебор по всем сеткам в разделе XGBoost занимает достаточно много времени. На обычном компьютере вычисление всего необходимого для XGBoost может потребовать от одного до двух часов.
• Кросс-валидация моделей многослойного перцептрона. К сожалению, не существует никакого волшебного средства ускорения кросс-валидации в обучении многослойного перцептрона. Для оценки качества модели кросс-валидация — надёжный способ, избегать его не стоит, но при этом следует запастись достаточным количеством времени.
• Оптимизация гиперпараметров. Это определенно самая тяжелая часть всех вычислений. Перебор различных комбинаций гиперпараметров и поиск подходящей с помощью Hyperopt занимает много часов.
• Генерация предсказаний на кросс-валидации для многослойного перцептрона и XGBoost.
Лучшим способом воспроизведения моих результатов было бы сначала запустить заранее обученные модели и затем пересчитать некоторые наиболее легкие их них.
Проект оставляет обширное пространство для будущих улучшений. Ниже я размышляю над тем, какие ещё способы улучшений можно использовать.
Предварительная обработка данных
1. Я сначала начал работать над моделью многослойного перцептрона, и только потом обнаружил прием с логарифмированием целевой переменной. В результате мои многослойные перцептроны были обучены без логарифмической трансформации. Конечно же, можно и нужно логарифмировать целевую переменную и заново обучить все модели многослойного перцептрона.
2. Перспективным способом преобразования целевой переменной было бы сдвинуть ее на 200 пунктов вправо (прибавить 200 ко всем значениям). Если мы сделаем такой сдвиг и затем возьмем логарифм, мы избавимся от выбросов в левой части функции плотности распределения целевой переменной. Тем самым мы сделаем ее распределение более близким к нормальному.
XGBoost
1. Обучить более сложную модель XGBoost, добавляя больше деревьев и в то же самое время уменьшая параметр eta. Моя рабочая модель использует 28 тыс. деревьев и eta=0.003, что было определено с помощью процедуры поиска по сетке.
2. Используйте early_stopping_rounds вместо num_boost_round, чтобы остановить обучение и избежать переобучения модели. В этом случае задайте eta маленьким числом и num_boost_round очень большим (до 100 тыс.). Нам нужно понимать, что в таком случае придётся готовить валидационную выборку. В результате наша модель получит меньше данных для обучения, и ее производительность может упасть.
3. Запустите процедуру поиска по сетке на других значениях гиперпараметров. Скажем, можно было бы протестировать значения colsample_bytree между 0 и 0.5, которые часто приносят хорошие результаты. Идея здесь состоит в том, что в пространстве гиперпараметров существует несколько локальных оптимумов и нам следовало бы найти несколько из них.
4. Объедините несколько моделей XGBoost, обученных с разными значениями гиперпараметров. Мы можем сделать такое объединение путем усреднения результатов моделей, смешивания (blending) и наложения (stacking).
Многослойный перцептрон
1. Используйте технику бэггинга (bagging) для усреднения нескольких многослойных перцептронов одной и той же модели. Наша модель стохастическая (например, потому, что мы используем выпадение нейронов = dropout), поэтому бэггинг сгладит ее работу и улучшит предсказательную способность.
2. Попробуйте более глубокую архитектуру сети, другие конфигурации элементов и значения гиперпараметров. Можно протестировать другие оптимизаторы, работающие по методу градиентного спуска, изменить число слоев, число элементов в каждом слое — вся мощь Hyperopt в наших руках.
3. Скомбинируйте несколько различных многослойных перцептронов (скажем, обучите двухслойную, трехслойную и четырехслойную нейронную сеть), использую любую из известных вам техник. Эти модели буду по-разному охватывать пространство данных и обеспечат улучшения по сравнению с базовыми результатами.
Кросс-валидация
Вместо использования простой кросс-валидации с разбиением на 3 части (иногда мы использовали разбиение на 5 частей), мы можем перейти к кросс-валидации на 10 частей. Такая кросс-валидация больше подходит для соревнований Kaggle, но почти точно позволит улучшить наши результаты (у нас будет больше данных для обучения).
Стэкинг
1. Можно добавить в ансамбль больше моделей нулевого уровня. Во-первых, мы можем просто обучить больше многослойных перцептронов и моделей XGBoost, но они должны отличаться друг от друга. Например, мы можем обучить эти модели на различных поднаборах данных, для некоторых из них мы можем по-разному предварительно обработать данные (loss). Во-вторых, мы можем ввести полностью другие модели: LightGBM, алгоритм k ближайших соседей, факторизационные машины (FM) и т.д.
2. Другая идея – добавить второй уровень как новый слой наложения. В результате мы получаем двухуровневый стэкинг: у нас всё ещё есть регрессоры нулевого уровня (L0), на out-of-fold предсказаниях которых мы обучаем несколько разных метамоделей первого уровня (L1). Затем, мы просто берём линейную комбинацию предсказаний метамоделей (L2) — и получаем финальную оценку.
3. Попытаться воспользоваться PCA — методом главных компонент, который был рассмотрен в ноутбуке про исследование данных. Здесь есть несколько идей. Во-первых, полученные компоненты можно подмешать к out-of-fold предсказаниям, на которых будет обучаться линейная регрессия (L1), чтобы добавить в метамодель дополнительную информацию. Во-вторых, можно отобрать из всех признаков только те, которые имеют высокий вес, а остальные отбросить как шум. Иногда это тоже помогает улучшить качество полученной модели.
Описание конфигурации, на котором выполнялся весь проект, здесь
Отчет по дипломному проекту «Предсказание тяжести страховых требований для компании Allstate»
Часть 1. Описание проекта
Общий обзор проекта
Многие люди, работающие в сферах, связанных с данными, слышали о Kaggle – платформе для проведения соревнований по наукам о данных. Сегодня на Kaggle представлены более 600 тыс. data scientist'ов и множество широко известных компаний. Компания описывает свою проблему, задает метрики качества, публикует набор данных, который мог бы помочь ее решить, а участники находят оригинальные способы решения поставленной компанией задачи.
Данное соревнование Kaggle предоставлено компанией Allstate – крупнейшей публичной компанией США в сфере персонального страхования жизни и имущества. В данный момент Allstate занимается разработкой автоматических методов предсказания стоимости (тяжести) страховых требований и обратилась к сообществу Kaggle с просьбой продемонстрировать свежие идеи и новые подходы к решению этой проблемы.
Компания стремится улучшить качество своих услуг по обработке страховых требований и опубликовала набор данных о произошедших в домашних хозяйствах несчастных случаях (каждое домашнее хозяйство представлено вектором анонимизированных признаков) с указанием численной оценки стоимости страхового требования. Наша задача состояла в том, чтобы предсказать тяжесть возможного страхового требования для нового домохозяйства.
На Kaggle также доступны еще несколько связанных с данной задачей наборов данных:
• Соревнование Allstate по предсказанию страховых требований — более раннее соревнование Allstate, целью которого было предсказать страховые платежи на основе характеристик застрахованного транспортного средства. Набор данных этого соревнования предоставляет возможность погрузиться в область страхования.
• Соревнование по оценке потерь от огня – соревнование, проведенное Liberty Mutual Group и направленное на предсказание ожидаемых потерь от огня для формирования условий страховых контрактов. Это еще один пример набора данных из сферы страхования, который помог нам получить понимание подходов к решению задач предсказания в страховой индустрии.
Отдельно отмечу, что исходный набор данных является высоко анонимным (как в части названий признаков, так и в части значений). Этот аспект усложняет как понимание значения признаков, так и затрудняет обогащение набора данных из внешних источников. Участники соревнования по-разному пробовали обогатить и интерпретировать исходные данные, однако успех их попыток остаётся спорным. С другой стороны, в данном наборе данных, по всей видимости, отсутствует утечка данных, которая возникает, когда в тренировочных данных остается дополнительная информация. Такая информация может сильно коррелировать с целевой переменной и приводить к необоснованно точным предсказаниям. За последнее время от таких утечек пострадало достаточно большое число соревнований Kaggle.
Постановка задачи
В нашем распоряжении находится набор данных, содержащий записи по страховым требованиям клиентов компании Allstate. Каждая запись содержит как категориальные, так и непрерывные признаки. Целевая переменная представляет собой численную оценку потерь, вызванных данным страховым требованием. Все признаки сделаны максимально анонимными: мы не знаем ни настоящих названий признаков, ни их истинных значений.
Наша цель – построить модель, которая сможет правильно предсказать будущие потери на основе заданных значений признаков. Очевидно, что это задача регрессии: целевая переменная численная. Также это задача обучения с учителем: целевая переменная явно определена в тренировочном наборе данных, и нам необходимо получить ее значения для каждой записи тестового набора.
Компания Allstate проделала большую работу по очистке и предобработке данных: предоставленный набор данных в очень высокой степени очищен и (после небольшой дополнительной обработки) может быть передан большому числу алгоритмов обучения с учителем. Как мы увидим в части отчета, посвященной исследованию данных, задание компании Allstate особо не позволяет генерировать новые признаки или заниматься препроцессингом имеющихся фич. С другой стороны, этот датасет подталкивает к использованию и тестированию различных алгоритмов машинного обучения и ансамблей — как раз то, что нужно для дипломного проекта.
Я применил следующий подход к проекту Allstate:
1. Исследовать набор данных, понять значение данных, признаков и целевой переменной, и найти в данных простые взаимосвязи. Этот этап выполнен в файле Data Discovery notebook.
2. Произвести необходимую предобработку данных и обучить несколько различных алгоритмов машинного обучения (XGBoost и многослойный перцептрон). Получить базовые результаты. Эти задачи решены в файлах XGBoost и MLP.
3. Настроить модели и добиться заметного улучшения результатов по каждой из них. Этот этап также осуществлен в файлах XGBoost и MLP.
4. Обучить ансамбль используя технику наложения моделей (стэкинг) с использованием предыдущих моделей как базовых предикторов. Получить итоговые результаты, которые будут значительно лучше предыдущих. Этот этап реализован в файле Stacking notebook.
5. Кратко обсудить результаты, дать оценку итоговой позиции в турнирной таблице соревнования и найти дополнительные пути ее улучшения. О результатах мы поговорим ниже в данном отчёте и в последней части файла Stacking notebook.
Метрики
Платформа Kaggle требует от компании, проводящей соревнование, четко определить метрику, по которой могут соревноваться участники. Компания Allstate выбрала в качестве такой метрики MAE. MAE (средняя абсолютная ошибка) – очень простая и очевидная метрика, которая напрямую сравнивает предсказанные и истинные значения.
Эта метрика задана и не может быть изменена, т.к. является частью условий соревнования. Тем не менее, я считаю ее хорошо подходящей к данной задаче. Во-первых, MAE (в отличие от MSE или среднеквадратичной ошибки) не дает большого штрафа за неверную оценку выбросов (в датасете присутствует несколько выбросов с аномально высокими значениями потерь). Во-вторых, MAE проста для понимания: значения ошибки выражаются в тех же измерениях, что и сама целевая переменная. Вообще говоря, MAE – хорошая метрика для новичков в науках о данных. Ее легко вычислить, просто понять и трудно неправильно интерпретировать.
Part 2. Анализ
Изучение данных
Для полного ознакомления с этим этапом вы можете обратиться к файлу Data Discovery.
Вся обучающая выборка состоит из 188318 элементов, индексированных с помощью переменной uid. Индекс для работы с данными не несёт дополнительной информации, т.к. это просто нумерация, начиная с «1» с некоторыми пропущенными значениями. Мы не собираемся использовать для предсказания тестовый набор без индекса (она необходима для отправки результатов на Kaggle), однако стоит отметить, что тестовый набор данных организован так же, как и тренировочный. Очевидно, обучающая и тестовая выборки были получены из одного набора данных разбиением процедурой, например, train_test_split из пакета sklearn.
Основные результаты данной части проекта следующие:
• Набор данных содержит 130 различных признаков (без учета индекса id и целевой переменной loss). С учетом размеров набора данных, это вполне разумное число признаков. Мы едва ли могли бы столкнуться здесь с «проклятием размерности».
• 116 признаков категориальные, 14 численные. Вероятно, нам нужно будет закодировать эти 116 признаков, так как большинство алгоритмов машинного обучения не могут корректно обрабатывать категориальные переменные. Способы такого кодирования и различия между ними мы обсудим позднее.
• Во всем наборе данных нет ни одного пропущенного значения. Такой факт лишь подтверждает, что компания Allstate предоставила данные с высокой степенью предварительной обработки, чтобы сделать их доступными и простыми в использовании.
• Большинство категориальных признаков (72 или 62%) бинарные (да/нет; мужчина/женщина), но их значения записаны просто как «A» и «B», поэтому мы никак не можем догадаться об их значении. 3 признака принимают три различных значения, 12 признаков – 4 различных значения.
• Численные признаки уже отмасштабированы в диапазоне от 0 до 1, стандартные отклонения для всех них близки к 0.2, средние значения составляют порядка 0.5, поэтому и для этих признаков мы не можем сделать никаких предположений об их значении.
• По всей видимости, некоторые численные признаки раньше были категориальными до их преобразования в численные с помощью LabelEncoder или схожей процедуры.
• Построив гистограммы различных признаков, можно убедиться, что ни один из них не подчиняется нормальному закону распределения. Можно попробовать снизить асимметрию распределения этих данных (в случае scipy.stats.mstats.skew > 0.25), однако даже после такого преобразования добиться распределения, близкого к нормальному, не удастся.
• Целевая переменная также распределена не нормально, хотя и может быть простым логарифмическим преобразованием приведена к распределению, близкому к нормальному.
• Целевая переменная содержит несколько выбросов с аномально высокими значениями (очень серьезные происшествия). В идеальном случае мы хотели бы, чтобы наша модель умела идентифицировать и правильно предсказывать такие выбросы. В то же время мы можем легко на них переобучиться, если не будем достаточно осторожны. Ясно, что здесь необходим некоторый компромисс.
• Обучающая и тестовая выборки имеют сходные распределения данных. Это идеальная характеристика разбиения на обучающую и тестовую выборки, которая сильно упрощает кросс-валидацию и позволяет нам принимать информированные решения о качестве моделей, используя кросс-валидацию на тренировочном наборе данных. Это значительно упростило участие в соревновании Kaggle, однако не будет полезно для выполнения дипломного проекта.
• Несколько непрерывных признаков сильно коррелированы (корреляционная матрица отображена на рис. 1 ниже). Это приводит к основанной на данных мультиколлинеарности в этом наборе данных, что может радикально снизить предсказательную способность линейных регрессионных моделей. Частично эту проблему можно решить с помощью L1 или L2 регуляризации.
Рисунок 1: Корреляционная матрица для непрерывных признаков
Обзорная визуализация
Я покажу одну визуализацию для того, чтобы продемонстрировать важную черту этого набора данных – высокую степень анонимности, предварительной обработки данных.
Ниже приведены гистограммы 14 непрерывных признаков, помеченных как cont#. Как видно из рис. 1, распределения данных могут иметь множественные пики, и функции плотности распределений не близки к гауссовским. Мы могли бы попытаться снизить коэффициент асимметрии данных, но применение алгоритмов нормализации (например, преобразования Бокса-Кокса) мало что дало для данного набора данных.
Рисунок 2: Гистограммы непрерывных признаков
Особенно интересен признак cont2. Этот признак был, по всей видимости, получен из категориального и может отражать возраст или возрастную категорию. К сожалению, я не углублялся в изучение этого признака: на мой проект он никакого влияния не оказал.
Алгоритмы и методика анализа данных
Этот раздел гораздо подробнее раскрыт в двух следующих документах: XGBoost notebook и MLP notebook.
XGBoost. Одна из причин моего интереса к проекту — это возможность попробовать метод бустинга над деревьями и, в частности, XGBoost. Де-факто этот алгоритм стал своеобразным стандартным швейцарским ножом для множества соревнований Kaggle благодаря его масштабируемости, гибкости и впечатляющей предсказательной силы.
XGBoost подходит для задач обучения с учителем, сходных с той, которую мы имеем (четко определенные тренировочный набор данных и целевая переменная). Ниже мы опишем принципы работы алгоритма XGBoost.
XGBoost, в сущности, является вариацией бустинга — ансамблевого мета-алгоритма машинного обучения, применяемого для снижения смещения и дисперсии в обучении с учителем, и семейства алгоритмов машинного обучения, которые превращают слабые модели в более сильные. Источник: Википедия. Изначально, идеи бустинга уходят корнями в поставленный Kearns и Valiant вопрос о том, могут ли «слабые» обучающиеся алгоритмы, которые дают результаты чуть лучше случайного гадания в PAC (вероятно приблизительно правильной) модели, быть “усилены” до “сильного” обучающегося алгоритма произвольной точности. Источник: Краткое введение в бустинг (Yoav Freund и Robert E. Schapire). Утвердительный ответ на этот вопрос был дан R.E.Schapire в его статье Сила слабой обучаемости, которая привела к разработке множества алгоритмов бустинга.
Как видно, основополагающим принципом бустинга является последовательное применение слабых алгоритмов обучения. Каждый последующий слабый алгоритм пытается уменьшить смещение всей модели, объединяя, таким образом, слабые алгоритмы в мощную ансамблевую модель. Можно привести множество различных примеров алгоритмов и методов бустинга, таких как AdaBoost (адаптивный бустинг, который подстраивается под слабые алгоритмы обучения), LPBoost и градиентный бустинг.
XGBoost, в частности, является библиотекой, реализующей схему градиентного бустинга. Модели градиентного бустинга строятся поэтапно, точно так же, как и при использовании других методов бустинга. Этот метод бустинга обобщает слабые обучающиеся алгоритмы, допуская оптимизацию произвольной дифференцируемой функции потерь (функции потерь с вычислимым градиентом).
XGBoost, как разновидность бустинга, включает оригинальный основанный на решающих деревьях алгоритм машинного обучения, пригодный для работы с разреженными данными; теоретически обоснованная процедура позволяет работать с весами различных элементов в обучении деревьев. Источник: XGBoost: масштабируемая система бустинга над деревьями (Tianqi Chen, Carlos Guestrin)
Можно привести ряд достоинств алгоритма XGBoost:
• Регуляризация. Как будет показано в разделе, посвященному модели многослойного перцептрона, при использовании других алгоритмов легко можно получить переобученную модель. XGBoost предоставляет очень надежные готовые к использованию средства регуляризации вместе с набором параметров для настройки этого процесса. Перечень этих параметров включает: gamma (минимальное уменьшение функции потерь, необходимое для дальнейшего деления дерева), alpha (вес для L1-регуляризации), lambda (вес для L2-регуляризации), max_depth (максимальная глубина дерева), min_child_weight (минимальная сумма весов всех наблюдений, требующаяся для дочернего объекта).
• Реализация параллельных и распределенных вычислений. В отличие от многих других алгоритмов бустинга, обучение здесь может производиться параллельно, тем самым сокращая время обучения. XGBoost работает действительно быстро. По утверждению авторов вышеупомянутой статьи, «система работает более чем в 10 раз быстрее существующих популярных решений уже на одном компьютере и может быть масштабирована на миллионы экземпляров в распределенном или ограниченном по памяти окружении».
• Встроенная кросс-валидация. Кросс-валидация является необходимым условием оценки качества полученной модели, и в случае с XGBoost ее процесс работы с ней крайне прост и понятен.
MLP. Вторая модель, которую мы строим – полносвязная нейронная сеть прямого распространения или многослойный перцептрон. Так как наша конечная цель – построить ансамбль (stacking) базовых регрессоров (и мы определились с типом первого из них — XGBoost), мы должны найти другой «тип» обобщающего алгоритма, который будет иначе исследовать наш набор данных.
Это то, когда имеют в виду, когда говорят, что обобщающие алгоритмы нулевого уровня должны «покрывать пространство». Wolpert, Обобщение наложением.
Путем добавления большего числа слоев и большего числа элементов внутри каждого слоя нейронная сеть может улавливать очень сложные нелинейные связи в данных. Универсальная теорема аппроксимации утверждает, что нейронная сеть прямого распространения может аппроксимировать любую непрерывную функцию в евклидовом пространстве. Таким образом, многослойный перцептрон является очень мощным алгоритмом моделирования. Многослойные перцептроны легко подвержены переобучению, но в нашем распоряжении есть все необходимые инструменты для того, чтобы снизить влияние этого фактора: случайное выключение активации нейронов (dropout), L1-L2 регуляризация, нормализация пакетов (batch normalization) и т.д. Мы также можем обучить несколько сходных нейронных сетей и усреднить их предсказания.
Сообщество, занимающееся глубоким обучением, разработало высококачественное программное обеспечение для обучения и оценки моделей, основанных на искусственных нейронных сетях. Мои модели построены на базе TensorFlow, библиотеки для тензорных вычислений, разработанной Google. Чтобы упростить построение моделей, я принял решение использовать Keras, высокоуровневый внешний интерфейс для TensorFlow и Theano, который берет на себя большую часть стандартных операций, необходимых для построения и обучения нейронных сетей.
GridSearch и Hyperopt. Данные методы применяются для отбора моделей и настройки гиперпараметров. В то время как GridSearch (поиск по сетке) исчерпывающим образом перебирает все возможные комбинации параметров, Hyperopt либо выбирает заданное число кандидатов из пространства параметров с заданным распределением, либо использует форму байесовской оптимизации. Вместе с обоими этими методами отбора мы используем для оценки производительности моделей технику кросс-валидации. Мы используем кросс-валидацию с разбиением на k частей (k-fold) с тремя или пятью частями в зависимости от вычислительной сложности модели.
Наложение моделей (stacking). Мы комбинируем предсказания двух из наших моделей (XGBoost и многослойный перцептрон) для построения финального предсказания, используя метарегрессор. Данный метод называется наложением (stacking) и интенсивно используется на Kaggle (часто чрезмерно). Идея стэкинга в том, чтобы разбить обучающую выборку на k частей и обучать каждый из базовых регрессоров на k-1 частях, делая предсказания на оставшейся части. В итоге, мы получаем обучающую выборку с предсказаниями регрессора (out-of-fold), имея при этом реальные значения целевой переменной. Далее, мы обучаем метамодель на этих данных, используя предсказания каждого регрессора как признак для метамодели, а истинные значения — как целевой признак.
Обученной метамодели мы подаём на вход предсказания регрессоров для тестовой выборки и получаем уже финальные предсказания, в которых обученная модель учитывает характерные ошибки каждого регрессора. Реализация данного этапа детально раскрыта в файле Stacking notebook.
Критерии для оценки результатов
Первый результат был задан компанией Allstate: они обучили ансамблевую модель случайного леса и получили результат MAE=1217.52141. Этот результат легко превзойти даже простой моделью XGBoost, и большинству участников это удалось.
Я также установил для себя несколько критериев, когда обучал модели. Нижней границей для меня выступала производительность простой модели данного класса. Для XGBoost такой результат был установлен на MAE=1219.57, он достигается простой моделью из 50 деревьев без какой-либо оптимизации или настройки гиперпараметров. Я взял стандартные значения гиперпараметров (предложенные в статье от Analytics Vidhya), оставил небольшим количество деревьев и получил этот стартовый результат.
Для многослойного перцептрона в качестве базового результата была выбрана производительность двухслойной модели с маленьким числом элементов в ее скрытом слое (128) с функцией активации ReLU, стандартной инициализацией весов и оптимизатором Adam GD: MAE=1190.73.
В данном дипломном проекте я избегал сложных baseline-моделей, так как понимаю, что все результаты должны быть воспроизводимыми. Я также участвую в этом соревновании Kaggle, однако обучение всех моих используемых в соревновании моделей, большинство из которых представляет собой комбинации и использует большое число алгоритмов, точно потребует от читателя слишком много времени. В соревновании Kaggle я надеюсь превзойти результат MAE=1100.
Часть 3. Методология
Предварительная обработка данных
Я уже упоминал, что этот датасет уже был хорошо подготовлен и предварительно обработан, например, непрерывные признаки были отмасштабированы в интервал [0,1], категориальные признаки были переименованы, их значения были превращены в числа. Фактически, в части предобработки здесь осталось не так много того, что можно было бы еще сделать. Однако некоторая работа еще должна быть проделана для того, чтобы можно было обучать корректные модели.
Предварительная обработка целевой переменной
Наш целевой признак имеет экспоненциальное распределение, которое может понизить качество регрессионных моделей. Как известно, регрессионные модели лучше всего работают тогда, когда целевая переменная распределена нормально.
Чтобы решить эту проблему, мы просто применяем к целевой переменной loss логарифмическое преобразование: np.log(train['loss']).
Рисунок 3: Гистограммы распределения целевой переменной до и после логарифмического преобразования
Полученный результат можно улучшить: слева от основного колокола распределения лежат несколько отклоняющихся наблюдений. Чтобы избавиться от этих выбросов, мы можем сдвинуть все значения переменной loss на 200 пунктов вправо (loss+200) и затем взять от них логарифм.
Кодирование категориальных переменных
Большинство алгоритмов машинного обучения не могут напрямую работать с категориальными переменными. XGBoost здесь не является исключением, так что нам нужно будет преобразовать наши категориальные переменные в численные. Здесь можем выбрать одну из двух стандартных стратегий: кодирование меток (label encoding) или прямое кодирование (one-hot encoding). Какую стратегию использовать – вопрос достаточно спорный, однако здесь следует рассмотреть несколько факторов:
Прямо кодирование (one-hot encoding) – это базовый способ работы с категориальными признаками. Он выдает разреженную матрицу, где каждый новый столбец представляет одно возможное значение какого-либо одного признака. Так как у нас 116 категориальных переменных, и переменная cat116 принимает 326 значений, мы можем получит разреженную матрицу с огромным количество нулей. Это приведет к более длительному обучению, увеличит затраты памяти и может даже ухудшить итоговые результаты. Другой недостаток прямого кодирования – потеря информации в тех случаях, когда имеет значение порядок категорий.
Кодирование меток (label encoding), с другой стороны, просто нормализует столбец входных данных так, что он содержит только значения между 0 и числом классов-1. Для многих алгоритмов регрессии это не слишком хорошая стратегия, однако XGBoost может справляться и справляется с таким преобразованием очень хорошо.
Для XGBoost мы будем использовать LabelEncoder и нормализуем входные данные. Для многослойного перцептрона нам нужно будет создавать фиктивные переменные, таким образом, наш выбор здесь – one-hot encoding.
Реализация и усовершенствование моделей
Как было упомянуто ранее, наша методология реализации машинного обучения будет подразделяться на два раздела:
• Обучение, настройка и кросс-валидация базовых моделей (моделей нулевого уровня): XGBoost и многослойного перцептрона в предположении, что мы уже произвели предварительную подготовку данных, которая для этих двух моделей немного различается. Разница будет в кодировании признаков (прямое или кодирование меток) и (к сожалению) в отсутствии логарифмического преобразования целевой переменной для модели многослойного перцептрона. Итогом этой части будут две настроенные модели, результаты которых будут отвечать установленным критериям.
• Обучение и валидация модели уровня 1, то есть, наложения моделей. Итогом этого раздела станет новая метамодель, дающая результаты лучшие, чем каждая из базовых моделей нулевого уровня, которые мы обучили ранее.
Теперь пришло время дать детальный обзор каждого из разделов.
Раздел 1. Модели нулевого уровня: обучение, настройка, кросс-валидация
Методология обучения модели XGBoost (адаптированный вариант руководства по настройке XGBoost от Analytics Vidhya):
1. Обучим неглубокую и простую модель с параметрами num_boost_round=50, max_depth=5 и получим базовый результат MAE=1219.57. Такой результат мы установим в качестве нижней границы и будем улучшать его с помощью настройки модели.
2. Чтобы облегчить оптимизацию гиперпараметров, мы реализуем собственный класс XGBoostRegressor, построенный над XGBoost. Такой класс, по большому счёту, необязателен для работы модели, однако даст нам ряд преимуществ (мы сможем использовать собственную функцию потерь и минимизировать эту функцию вместо максимизации) при использовании поиска по сетке GridSearchCV, реализованного в scikit-learn.
3. Мы определим и зафиксируем скорость обучения и количество деревьев, которые будут в каждом следующем переборе по сетке. Поскольку наша задача состоит в том, чтобы за минимальное время получить неплохой результат, мы поставим небольшое число деревьев и высокую скорость обучения: eta=0.1, num_boost_round=50.
4. Настроим параметры max_depth и min_child_weight. Эти гиперпараметры рекомендуется настраивать совместно, т.к. увеличение max_depth приводит к возрастанию сложности модели (и увеличивает вероятность переобучения). В то же самое время min_child_weight выступает регуляризирующим параметром. Мы получаем следующие наилучшие параметры: max_depth=8, min_child_weight=6. Это улучшает результаты с MAE=1219.57 до MAE=1186.5.
5. Настроим gamma, параметр регуляризации.
6. Настроим соотношение числа признаков и элементов обучающей, которое будет использоваться в каждом из деревьев: colsample_bytree, subsample. Мы получаем следующую оптимальную конфигурацию: subsample=0.9, colsample_bytree=0.6 и улучшаем наши результаты до MAE=1183.7.
7. Наконец, добавим больше деревьев (увеличим параметр num_boost_round) и снизим интенсивность обучения eta. Мы также выработаем практическое правило для понимания связи между этими двумя гиперпараметрами. Наша финальная модель использует 200 деревьев, имеет eta=0.07 и итоговый результат MAE=1145.9.
Пример процесса настройки параметров модели с использованием Grid Search показан на рисунке 4 ниже (подробности вы найдете в этом файле):
Рисунок 4: двумерные пространства гиперпараметров для пар max_depth–min_child_weight и colsample-subsampling
Методология обучения модели многослойного перцептрона:
1. Начнем с простого и построим базовую модель с единственным скрытым слоем (двухслойную), функцией активации ReLU и оптимизатором Adam, реализующим метод градиентного спуска. Такие неглубокие модели трудно переобучить, они быстро обучаются и дают хорошие начальные результаты. В терминах компромисса между смещением и дисперсией они представляют собой смещенные модели, однако стабильны и дают достойный результат MAE=1190.73 для такой простой модели.
2. Используем кросс-валидацию с разбиением на k частей (k-fold) для измерения производительности более глубоких моделей и для визуализации переобучения. Обучим трехслойную модель, покажем, что она легко подвержена переобучению.
3. Добавим в трехслойную модель регуляризацию: выключение нейронов (dropout) и раннюю остановку (early stopping). Определим несколько возможных конфигураций для последующего ручного тестирования: эти конфигурации отличаются числом скрытых элементов и вероятностью выключения нейронов. Обучим эти модели, рассмотрим и сравним их результаты, полученные на кросс-валидации, и выберем лучшую. В действительности при таком подходе мы не получим никаких улучшений: результаты по сравнению с двухслойной моделью лишь ухудшатся. Такой исход может быть вызван ручным (и тем самым неточным) подходом к регуляризации многослойного перцептрона. Мы просто определяем некоторые разумные интенсивности выпадения для слоев, но нет никакой гарантии того, что выбранные интенсивности будут оптимальными.
4. Введем в работу Hyperopt, чтобы осуществлять поиск в пространстве гиперпараметров автоматизированным и более интеллектуальным способом (будем использовать tpe.suggest, деревья оценивающих алгоритмов Парзена). Запустим несколько итераций Hyperopt на многочисленных конфигурациях гиперпараметров с различными выпадением нейронов, составом слоев и числом скрытых элементов. Наконец, мы выясним, что лучше всего использовать четырехслойную архитектуру (три скрытых слоя) с оптимизатором adadelta, нормализацией пакетов (batch normalization) и выпадением нейронов.
Финальная архитектура многослойного перцептрона:
Рисунок 5: финальная архитектура многослойного перцептрона
Результат этой модели на кросс-валидации составил: MAE=1150.009.
Раздел 2. Обучение модели первого уровня
К настоящему моменту мы обучили и настроили модели нулевого уровня: XGBoost и многослойный перцептрон. В этом разделе мы составим набор данных из создаваемых при кросс-валидации предсказаний моделей нулевого уровня (для которых известны истинные значения) и тестовой выборки предсказаний моделей нулевого уровня, которые будут использованы для итоговой оценки качества метамодели.
Для полного ознакомления с процессом построения ансамбля моделей обратитесь, пожалуйста, к этому файлу.
Методология построения ансамбля, которую я использовал, описана ниже:
• Шаг 1. Новое обучение и генерация отложенного набора данных. Поскольку мы не отправляем результаты на Kaggle и не «пробиваем лидерборд», мы должны будем разбить обучающую выборку на две части: обучение и тест. Обучающая подвыборка будет использоваться для генерации предсказаний моделей нулевого уровня на кросс-валидации с разбиением на k частей (k-fold), тогда как отложенный набор данных будет применяться лишь для финальной оценки производительности двух моделей нулевого уровня и метамодели.
• Шаг 2: Разбиение. Разобьем обучающую выборку на k частей, которые будут использоваться для обучения моделей нулевого уровня.
• Шаг 3: Предсказания на кросс-валидации. Обучим каждую модель нулевого уровня на K-1 частях, построим предсказания для оставшейся части. Повторим этот процесс для всех K частей. В конце мы получим предсказания для всей тестовой выборки (для которой у нас также есть метки).
• Шаг 4: Обучение на всей выборке. Обучим каждую из моделей нулевого уровня на всем обучающем наборе данных и получим предсказания для тестового набора. Составим из полученных предсказаний новый набор данных, в котором каждый из признаков является предсказанием одной из моделей нулевого уровня.
• Шаг 5: Обучение модели первого уровня. Обучим модель первого уровня на полученный при кросс-валидации предсказаниях, используя соответствующие им метки из обучающей выборки как метки для модели уровня 1. После этого, используя наш комбинированный набор данных предсказаний моделей нулевого уровня, мы получим финальные предсказания модели первого уровня.
В качестве модели первого уровня мы выбираем линейную регрессию: метамодель легко подвержена переобучению (да и, честно говоря, в самом соревновании мало что работало лучше простой линейной регрессии как метамодели). Данное наложение сработало очень хорошо и значительно улучшило полученные результаты. После кросс-валидации моделей нулевого уровня и финальной ансамблевой модели на скрытом наборе данных мы получили следующие результаты:
MAE для XGBoost: 1149.19888471
MAE для многослойного перцептрона: 1145.49726607
MAE для наложения моделей: 1136.21813333Результат наложения моделей MAE=1136.21 заметно лучше результата лучшей из моделей нашего ансамбля. Конечно, этот результат может быть еще улучшен, однако в данном проекте мы идем на компромисс между увеличением предсказательной способности модели и снижением времени обучения.
Пояснение: этот набор результатов был вычислен на отложенной выборке, не через кросс-валидацию. Таким образом, мы не имеем права напрямую сравнивать результаты, полученные на кросс-валидации, с результатами на отложенном наборе данных. Тем не менее, отложенный набор данных имеет, как ожидается, распределение, близкое к распределению всего набора данных. Вот почему мы можем утверждать, что наложение действительно улучшило достигнутые нами показатели.
В качестве заметки на полях, было бы любопытно узнать, с какими весами вошли в наложение наши модели нулевого уровня. В линейной регрессии финальное предсказание – это просто линейная комбинация весов и исходных предсказаний:
PREDICTION = 0.59 * XGB_PREDICTION + 0.41 * MLP_PREDICTIONЧасть 4. Результаты
Оценка и валидация моделей
Чтобы оценить наши результаты, мы обучим и произведем валидацию наших финальных моделей (отдельных и ансамбля) на различных подвыборках набора данных. Таким образом мы сможем увидеть, насколько стабильны наши модели и могут ли они давать устойчивый результат вне зависимости от начальной обучающей выборки. Для достижения этих целей мы обобщим наложение моделей из документа Stacking notebook до класса modules/stacker.py, который позволяет быстро вызывать процедуры оценки наших моделей с различными сидами (чтобы модели немного отличались друг от друга).
Мы обучим наши модели нулевого и первого уровней с 5 разными сидами и запишем результаты в таблицу. Затем мы используем метод pd.describe для получения агрегированной статистики по производительности каждой из моделей. Наиболее характерными метриками здесь будут среднее (mean) и стандартное отклонение (std):
Как можно видеть, наши модели достаточно стабильные (стандартное отклонение низкое) и ансамбль всегда превосходит любую другую модель. Его самый низкий результат лучше самого лучшего результата самой лучшей из индивидуальных моделей (MAE=1132.165 против MAE=1136.59).
Еще одно пояснение: Я старался внимательно обучать и валидировать модели, однако здесь все еще может быть пространство для утечек информации, которые остались незамеченными. Все модели демонстрируют улучшение результатов, которое могло быть вызвано одной такой утечкой (но мы обучили только пять моделей, параметр seed=0 мог просто дать худшие результаты). Тем не менее, итоговые выводы остаются валидными: усреднение нескольких наложений, обученных с различными сидами, улучшает итоговые результаты.
Обоснование
Наши базовые результаты: MAE=1217.52 (модель случайного леса от компании Allstate) и MAE=1190.73 (MAE простого многослойного перцептрона). Наша финальная модель улучшила первый результат на 7.2% и на 5.1% — второй.
Чтобы измерить значимость этих результатов, добавим каждый из базовых результатов в таблицу результатов, полученной в предыдущем разделе, и выясним, могут ли наши базовые результаты быть названы аномальными. Так, если базовые результаты можно рассматривать как выбросы, разница между нашими финальными и базовыми результатами будет значимой.
Чтобы произвести этот тест, мы можем вычислить показатель IQR (интерквартильный размах), который используется для выявления аномалий и выбросов. Затем мы вычислим третью квантиль данных (Q3) и используем формулу Q3 + 1.5 * IQR для установления верхней границы результатов. Значения выше этой границы считаются выбросами. При проведении этого теста мы ясно видим, что оба базовых результата оказываются выбросами. Таким образом, мы можем сказать, что наше наложений моделей значительно превосходит базовые контрольные точки.
for baseline in [1217.52, 1190.73]:
stacker_scores = list(scores.stacker)
stacker_scores.append(baseline)
max_margin = np.percentile(stacker_scores, 75) + 1.5*iqr(stacker_scores)
if baseline - max_margin > 0:
print 'MAE =', baseline, 'считается выбросом.'
else:
print 'MAE = ', baseline, 'НЕ считается выбросом.'
На выходе получим:
MAE = 1217.52 считается выбросом. MAE = 1190.73 считается выбросом.Часть 5. Заключение
Визуализация в свободной форме
Давайте абстрагируемся от деталей и взглянем на проект как на единое целое. Мы обучали и оптимизировали две основные модели: XGBoost и многослойный перцептрон. Мы сделали ряд шагов, начиная от самой простой из возможных моделей и заканчивая настроенной, более устойчивой и сложной моделью. После этого мы создали предсказания на кросс-валидации для нашей модели уровня 1, линейной регрессии, и использовали технику стэкинга для объединения предсказаний моделей нулевого уровня. Наконец, мы сделали валидацию производительности стэкинга и обучили пять его вариаций. Усредняя результаты этих пяти моделей, мы получили финальный результат: MAE=1129.91.
Рисунок 6: Основные этапы улучшения результатов
Конечно, мы могли бы включить в нулевой уровень и большее число моделей, или могли бы сделать их ансамбль более сложным. Один из возможных путей – обучить несколько полностью различных ансамблей и скомбинировать их предсказания (например, как линейную комбинацию) на новом уровне, уровне 2.
Анализ проделанной работы
Полное решение задачи
Идеей данного проекта было работать с набором данных, в котором не требуется создания новых признаков. Иметь такой набор данных очень приятно, т.к. это позволяет сосредоточиться на алгоритмах и их оптимизации, а не на предварительной обработке данных и внесении в них изменений. Конечно, мне хотелось испытать в действии XGBoost и нейронные сети, и выбранный набор данных мог дать хорошую базовую оценку качества моей модели в сравнении с результатами других участников Kaggle.
Даже с приведенными в проекте слабыми моделями мы получили значительное превышение базовых результатов: на 7.2%. Мы сравнили базовые результаты с финальными и убедились в том, что финальные результаты действительно являются значимым улучшением.
Трудности
Данный проект не был тривиальным. Хотя я и не демонстрировал никаких особенных или креативных подходов к набору данных, таких как создание новых признаков, понижение размерности или обогащение данных, вычислительная сложность требуемых для Kaggle моделей оказалась выше той, что я ожидал.
Главной проблемой в Allstate Claims Severity стала воспроизводимость вычислений. Для ее обеспечения нужно было выполнить ряд предварительных требований: процесс получения результата должен был быть ясным, вычисления – детерминированными (или хотя бы с ограниченными колебаниями) и воспроизводимыми за разумное время на любом современном оборудовании. В результате я сильно понизил сложность моих действующих моделей и полностью исключил некоторые техники (например, я исключил технику бэггинга (bagging) для XGBoost и многослойного перцептрона, хотя после применения бэггинга эти модели показывают заметно лучшие результаты).
Этот проект был выполнен преимущественно на инфраструктуре Amazon Web Services: я использовал экземляры p2.xlarge с GPU-вычислениями для многослойного перцептрона (GPU NVIDIA Tesla K80, 12 Гб памяти GPU) и экземляры c4.8xlarge с CPU-вычислениями для XGBoost (36 vCPU, 60 Гб памяти). В моем проекте есть несколько разделов, которые требуют тяжелых вычислений:
• Поиск по сетке. Перебор по всем сеткам в разделе XGBoost занимает достаточно много времени. На обычном компьютере вычисление всего необходимого для XGBoost может потребовать от одного до двух часов.
• Кросс-валидация моделей многослойного перцептрона. К сожалению, не существует никакого волшебного средства ускорения кросс-валидации в обучении многослойного перцептрона. Для оценки качества модели кросс-валидация — надёжный способ, избегать его не стоит, но при этом следует запастись достаточным количеством времени.
• Оптимизация гиперпараметров. Это определенно самая тяжелая часть всех вычислений. Перебор различных комбинаций гиперпараметров и поиск подходящей с помощью Hyperopt занимает много часов.
• Генерация предсказаний на кросс-валидации для многослойного перцептрона и XGBoost.
Лучшим способом воспроизведения моих результатов было бы сначала запустить заранее обученные модели и затем пересчитать некоторые наиболее легкие их них.
Улучшения
Проект оставляет обширное пространство для будущих улучшений. Ниже я размышляю над тем, какие ещё способы улучшений можно использовать.
Предварительная обработка данных
1. Я сначала начал работать над моделью многослойного перцептрона, и только потом обнаружил прием с логарифмированием целевой переменной. В результате мои многослойные перцептроны были обучены без логарифмической трансформации. Конечно же, можно и нужно логарифмировать целевую переменную и заново обучить все модели многослойного перцептрона.
2. Перспективным способом преобразования целевой переменной было бы сдвинуть ее на 200 пунктов вправо (прибавить 200 ко всем значениям). Если мы сделаем такой сдвиг и затем возьмем логарифм, мы избавимся от выбросов в левой части функции плотности распределения целевой переменной. Тем самым мы сделаем ее распределение более близким к нормальному.
XGBoost
1. Обучить более сложную модель XGBoost, добавляя больше деревьев и в то же самое время уменьшая параметр eta. Моя рабочая модель использует 28 тыс. деревьев и eta=0.003, что было определено с помощью процедуры поиска по сетке.
2. Используйте early_stopping_rounds вместо num_boost_round, чтобы остановить обучение и избежать переобучения модели. В этом случае задайте eta маленьким числом и num_boost_round очень большим (до 100 тыс.). Нам нужно понимать, что в таком случае придётся готовить валидационную выборку. В результате наша модель получит меньше данных для обучения, и ее производительность может упасть.
3. Запустите процедуру поиска по сетке на других значениях гиперпараметров. Скажем, можно было бы протестировать значения colsample_bytree между 0 и 0.5, которые часто приносят хорошие результаты. Идея здесь состоит в том, что в пространстве гиперпараметров существует несколько локальных оптимумов и нам следовало бы найти несколько из них.
4. Объедините несколько моделей XGBoost, обученных с разными значениями гиперпараметров. Мы можем сделать такое объединение путем усреднения результатов моделей, смешивания (blending) и наложения (stacking).
Многослойный перцептрон
1. Используйте технику бэггинга (bagging) для усреднения нескольких многослойных перцептронов одной и той же модели. Наша модель стохастическая (например, потому, что мы используем выпадение нейронов = dropout), поэтому бэггинг сгладит ее работу и улучшит предсказательную способность.
2. Попробуйте более глубокую архитектуру сети, другие конфигурации элементов и значения гиперпараметров. Можно протестировать другие оптимизаторы, работающие по методу градиентного спуска, изменить число слоев, число элементов в каждом слое — вся мощь Hyperopt в наших руках.
3. Скомбинируйте несколько различных многослойных перцептронов (скажем, обучите двухслойную, трехслойную и четырехслойную нейронную сеть), использую любую из известных вам техник. Эти модели буду по-разному охватывать пространство данных и обеспечат улучшения по сравнению с базовыми результатами.
Кросс-валидация
Вместо использования простой кросс-валидации с разбиением на 3 части (иногда мы использовали разбиение на 5 частей), мы можем перейти к кросс-валидации на 10 частей. Такая кросс-валидация больше подходит для соревнований Kaggle, но почти точно позволит улучшить наши результаты (у нас будет больше данных для обучения).
Стэкинг
1. Можно добавить в ансамбль больше моделей нулевого уровня. Во-первых, мы можем просто обучить больше многослойных перцептронов и моделей XGBoost, но они должны отличаться друг от друга. Например, мы можем обучить эти модели на различных поднаборах данных, для некоторых из них мы можем по-разному предварительно обработать данные (loss). Во-вторых, мы можем ввести полностью другие модели: LightGBM, алгоритм k ближайших соседей, факторизационные машины (FM) и т.д.
2. Другая идея – добавить второй уровень как новый слой наложения. В результате мы получаем двухуровневый стэкинг: у нас всё ещё есть регрессоры нулевого уровня (L0), на out-of-fold предсказаниях которых мы обучаем несколько разных метамоделей первого уровня (L1). Затем, мы просто берём линейную комбинацию предсказаний метамоделей (L2) — и получаем финальную оценку.
3. Попытаться воспользоваться PCA — методом главных компонент, который был рассмотрен в ноутбуке про исследование данных. Здесь есть несколько идей. Во-первых, полученные компоненты можно подмешать к out-of-fold предсказаниям, на которых будет обучаться линейная регрессия (L1), чтобы добавить в метамодель дополнительную информацию. Во-вторых, можно отобрать из всех признаков только те, которые имеют высокий вес, а остальные отбросить как шум. Иногда это тоже помогает улучшить качество полученной модели.
Описание конфигурации, на котором выполнялся весь проект, здесь
Поделиться с друзьями
sergei3000
Его этому всему на вашем курсе научили?
kirilldaniluk
Курс помог, но самообучение тоже никто не отменял. Что-то одно вряд ли научит «всему».