
В мире опен сорс есть огромное количество технологий, подходов, паттернов, тулзов и аппов, которые юзает очень много компаний. Как превратить используемое ПО или технологию в конкурентное преимущество? Предлагаю рассмотреть на примере Redis Cluster — как мы прокладывали наш путь.
Начало
Стоит начать с того, что Redis — это, по сути, очень удобная штука. В двух словах, Redis — это персистентное key-value хранилище в памяти, со своим блэкджеком и куртизантками. Чаще всего его сравнивают с устаревшим Memcached, который не умеет делать почти ничего из того, что умеет делать Redis.
Преимущества Redis:
- очень очень быстрая скорость доступа к данным. Это же мемчик.
- смешанные типы данных, хеши. По одному ключу (ивент), мы можем сторить кучу инфы (юзер айди, тип ивента, время, токен, сессию). Это могут быть байты, килобайты, мегабайты данных.
- дженерик TTL. Нам не нужно удалять то, что мы положили в Redis. Внутренний механизм сам удалит ключ, TTL которого пришел. Это невероятно удобно.
- унарные операции, инкременты, декременты — все это отрабатывает не моментально, а просто невероятно моментально. Соответственно, в Redis удобно и легко реализовывать комплексные прогресс бары, ивенты, класть кастомные данные, которые изменяются с разных мест системы.
- персистентность и бин-лог. Есть возможность периодически флашить все данные на диск, обеспечивая высокую доступность данных, и почти нивелируя их потерю.
Получается, что Redis — это такая «серебряная пуля», абсолютно для всех кейсов, подходов и практик? Ну, такое. Скорее нет, чем да.
Например, проблемы, которые очень очень мешают жить:
- стенделон. По факту, на данный момент, дефолтная инсталляция Redis — это стенделон. Это значит, что если у нас есть Single point of Failure, то у нас невероятно плохая архитектура, т.к. в случае падения Redis — вся система перестанет работать.
- флаш на диск. Это очень затратная операция, с высокой нагрузкой на IO, на мемчик. И ладно даже на железо — но наш сервис же невероятно тупит, ведь Redis должен зафиксировать все что у него там есть, и сделать большой Flush из быстрой памяти на медленный диск. В этот момент латенси на всех сервисах возрастает до секунд.
Вывод очевиден — Redis ускоряет продукт, ускоряет разработку, и его однозначно, нужно использовать, но… есть проблемы.
Redis Cluster
Там же есть Redis Cluster! Скажете Вы, но я бы попросил не спешить. На самом деле, у Redis есть 2 типа кластеризации:
- Redis Sentinel — для старых версий
- Redis Cluster — для новых версий
Redis Sentinel — это очень примитивная штука, которая выстраивает древовидную структуру из Ваших стенделон редисок, и называет это кластером. Никакого шардинга, балансировки, ничего. И тем более, это работает для старых версий Redis, если не ошибаюсь, ниже 3.0.
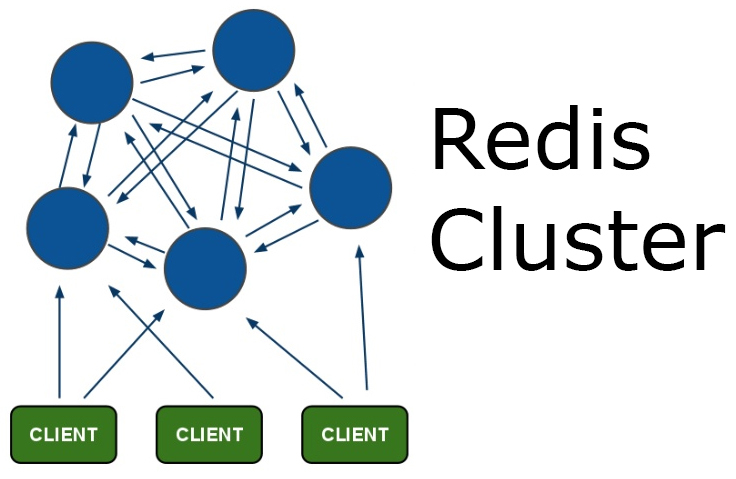
Redis Cluster — это штука повеселее, тут уже есть шардинг, репликация, отказоустойчивость, мастера-слейвы, разные там штуки прикольные и все такое. Это уже однозначно похоже на нормальный кластер, но все равно юзать это таким, как оно есть — не получится.
Почему это не работает
Для того, чтобы понять почему это не работает, нужно понять, как это работает внутри.
Во первых, сам процесс создания Redis Cluster из стенделон нод — это дикость и унижение, в том виде, в котором это есть сейчас. В нашем 2017 году все привыкли к дискаверингу, провижинингу и репорту типа «я все сделал, тут уже кластер, все ок!» — но реалии таковы, что в сорсах Redis есть скрипт, написанный на рубях, который занимается тем, что принимает как аргументы инстансы редиски, и потом соединяет их в кластер. Доверяете ли вы подобным штукам? Думаю да, доверяли, лет 100500 назад.
Окей, у нас есть кластер. Теперь немного теории: внутри кластера есть такие штуки, как hash slots. По сути, слот — это число, которое подразумевает набор данных, за которые ответственна конкретная нода кластера. Всего существует 16384 слота, которые равномерно делятся между всеми мастерами.
Кстати, о мастерах. По умолчанию Redis Cluster может состоять не менее чем из трех нод, и все это будут мастера. Соответсвенно, они поделят слоты между собой.
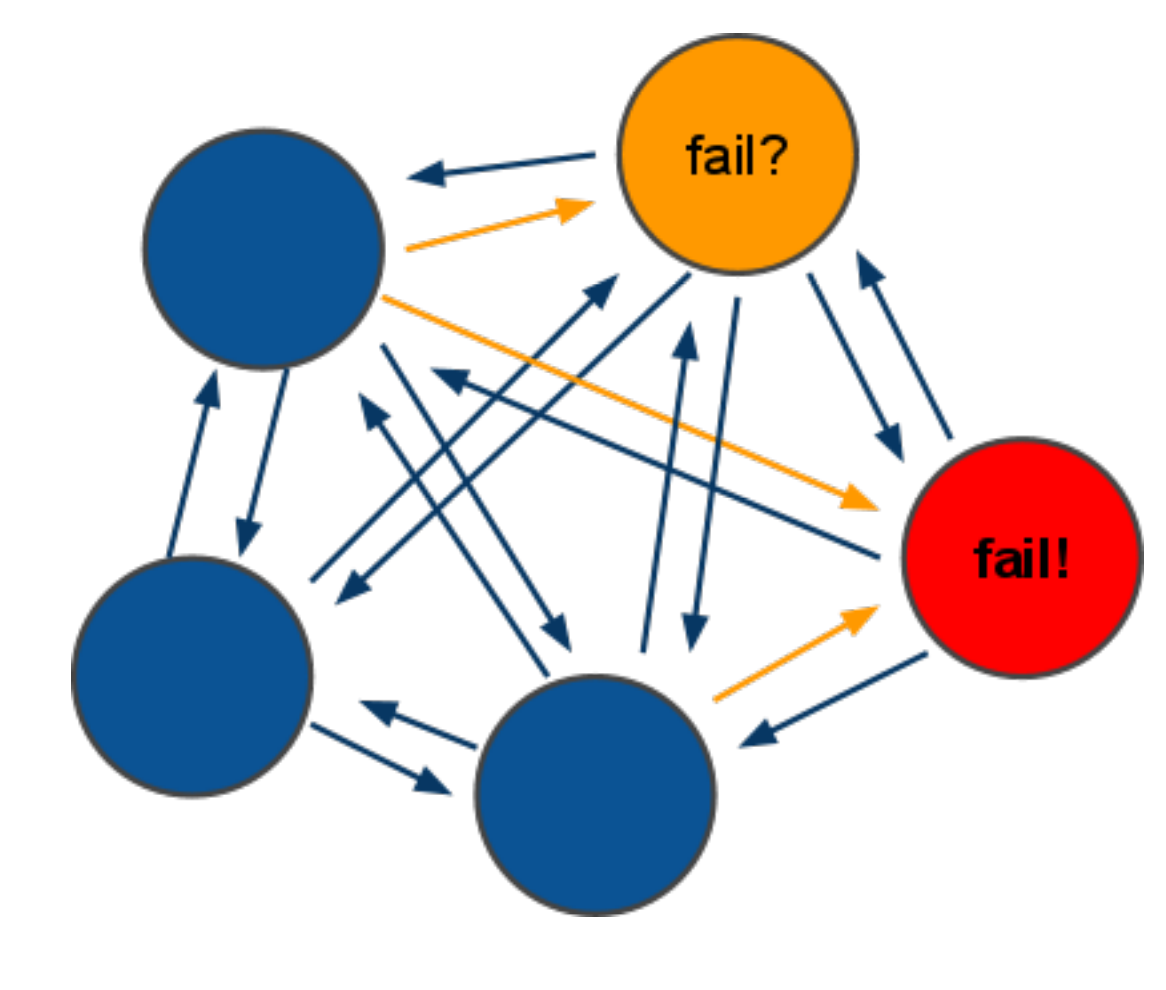
Второй нюанс использования кластера — это невероятная хрупкость. Например, у нас из кластера с 3 нодами отвалилась одна нода. Логичным решением было бы продолжить работать — у нас же есть 66,6% данных, но все совсем не радужно. В дефолтной конфигурации будет ответ 'CLUSTER IS DOWN' по запросу любого, даже живого ключа.
Если рассматривать кластер побольше, например из 6 нод (3 мастера и 3 слейва) — ситуация повторяется. Пока происходит автоматический промоутинг слейва в мастера после падения, ответ аналогичен — 'CLUSTER IS DOWN'. А это — секунды, хотя эта задержка зависит от количества данных в кластере.
Третья проблема — это клиенты. Точнее, коннекторы в апликейшнах. Если взять предыдущий кейс, когда у нас идет промоутинг кластера — все клиенты отвалятся с socket error, или connection timeout, или с чем-то похожим, потому что держат коннект ко всем мастерам в кластере. Это тоже нужно доделывать.
Четвертый, и один из самых неприятных, нюанс — это изменение набора команд. Стандартные команды, которые работают по вайлдкардам — не работают, и это не удивительно. Это нужно переделывать по всему проекту, учить апликейшн работать как со стенделоном так и с кластером. По факту — это самая длинная и затратная часть имплементации Redis Cluster.
Как заставить это работать
Первый нюанс с провижинингом мы исправить не в состоянии, разве что сделать LWRP для Chef, и провижинить это как-то более нормально. По сути, примерно так мы и сделали.
А вот второй и третий — это уже наша компетенция!
Исправить 'CLUSTER IS DOWN' при отсутствии части слотов очень легко и просто — достаточно добавить параметр конфигурации:
cluster-require-full-coverage noПроблему с клиентами, которые отваливаются можно решить, потратив немного времени. В нашем проекте используется 2 языка — PHP и Java, поэтому нам нужно было делать два раза одну и ту же работу. Общий алгоритм сводится к таким степам:
- Получаем на клиенте 'CLUSTER IS DOWN' — во время пересборки кластера
- Кетчим эту ошибку, сохраняем существующую нерабочую слотмапу.
- Ретраим конекшн, определенное количество раз, и ждем новую слотмапу.
- Когда слотмапа изменилась — вычитываем наше значение и радуемся.
Изменение слотмапы будет означать, что кластер перешел в рабочее состояние, и наши данные уже похвалит какой-то слейв, и он готов с ними работать.
Ни для кого не будет секретом, если я скажу, что в кластере с 6+ нод, смысла флашить данные на диск нет никакого. Соответственно, если отключить персистентность — все будет работать очень и очень быстро.
Результат

Что же получилось в результате?
- Мы достигли отличных показателей TTFB (так как теперь не боимся хранить сессии в Redis).
- У нас получился, наверное лучший в мире прогресс лоадер — там самая актуальная информация (актуальнее некуда!)
- Мы не боимся за данные, которые кладем в Redis Cluster и спим спокойно.
- SLA и User Experience намного улучшился из-за быстрой отзывчивости многих частей апликейшна
Вот такой интересный путь у нас получился.
А как Вы используете общедоступные инструменты?
Комментарии (25)
selivanov_pavel
31.01.2017 20:19+1> с 6+ нод, смысла флашить данные на диск нет никакого
По две ноды на хеш слот, даже если это разные ДЦ — вполне могут выйти из строя одновременно, или уйти в ребут из-за человеческой ошибки. Нельзя ли включить сохранение на диск на слейвах, а на мастерах выключить?
mukolaich
01.02.2017 12:01Отличная идея! Но есть нюанс: к примеру, из кластера вылетел мастер, а слейв (тот, который флашит на диск) стал мастером, и теперь он тормозит весь кластер :/
У редиса есть один юз кейс, про который очень часто забывают - в нем нельзя хранить мега важную инфу, потеря которой чревата (деньги, балансы, файлы, сообщения которые должны быть доставлены).
В нашем случае, если упадет один мастер и его реплика — у нас останется 66,6% данных, и самое худшее, что произойдет — юзера внезапно разлогинит. Кеши и разные другие штуки мы нагенерим, процессы перезапустим.
И еще момент — если у нас балансировка между ДЦ, мы наверное с ними подписывали контракты и гарантии SLA, и если оба ДЦ падают в одно время — наверное ничего работать не будет, не только редиски.


Makeomatic
31.01.2017 22:13+1Данные потерять очень легко. Чтобы вашей машине с редисом не было плохо — убедитесь что на железке есть хотя бы 2 ядра — на мейн тред и форк под рдб или aof rewrite, а так же половина свободной памяти (иначе негде будет делать слепок данных для рерайта или снепшота) — не будет проблем с латенси. Помимо этого можно сменить конфигурацию персистности на append only file с синком раз в секунду и снэпшот ночью когда нагрузки нет. Тогда вероятность потерять данные значительно ниже.
BasilioCat
01.02.2017 09:09+1не нужен никакой двойной объем памяти, CoW существует с незапамятных времен. Форк процесса редиса наследует его память в состоянии «снапшота», и просто записывает ее на диск, упаковывая в более компактный формат хранения
Makeomatic
01.02.2017 09:12попробуйте засунуть 70гб данных в редис на машине со 100 гб и потом сделайте BGSAVE, может быть, память забивается по какой-то другой причине, поправьте меня если это так, но по моему опыту цпу на форке 100% (понятно — надо это все пожать) и память тоже забивается абсолютно вся, потом адские свопы на диск… в общем страх

Fortop
01.02.2017 11:12Самая печаль, что и на двойном объёме памяти оно тупит при сохранении на диск.
В смысле сильно возрастает время отклика для приложения
tgz
31.01.2017 23:04А еще мастер после восстановления не переезжает обратно. Никаких приоритетов нет. В итоге может оказаться что 2 мастера в одной машине/стойке и выход ее из строя гарантированно кладет кластер. То что слевы вот они рядом живые и здоровые никого не волнует.

guyfawkes
31.01.2017 23:41Можно перевести на человеческий фразу про «сохраняем существующую нерабочую слотмапу»?
mukolaich
01.02.2017 12:14Конечно.
Инициализируете переменную, в которую сохраняете значение хеша от команды 'CLUSTER SLOTS'.
Суть в том, чтобы на стороне апликейшна дождаться, когда пересоберется кластер (поменяется слотмапа), и продолжить работу, как ни в чем не бывало.guyfawkes
01.02.2017 14:25Спасибо. Скажите, вы замеряли, как долго приходится ожидать, насколько много запросов не завершаются в разумные сроки? Не лучшим ли бывает закончить запрос с какой-нибудь ошибкой и предложить клиенту повторить его?
mukolaich
01.02.2017 15:04На запрос существует таймаут (as you wish), а на нашем наборе данных (гигабайты в кластере) пересборка и промутинг занимает примерно 2 секунды.
Само собой, если это аффектит клиента — это маленький таймаут и ошибка типа «Ooops! Internal server error», если это процесс в бэкграунде — таймаут больше, и рестарт в случае таймаута.

Sovigod
01.02.2017 10:23У Sеntinel было преимущество. Можно читать с localhost сколько угодно. А в Кластере чтение ограниченно скоростью сетевого интерфеса.
Бывали случаи, когда популярный на чтение ключ увеличивался в размерах ( до 1-2Мбайт). Как вы с таким боролись? Sеntinel это переживал вообще без осечек.

dorsett
01.02.2017 10:23+1Редис популярен, но для себя давно выбрал Aerospike, умеет работать с ссд как с рамом, есть автокластеринг и по скорости он побыстрее.
например:
http://stackoverflow.com/questions/24482337/how-is-aerospike-different-from-other-key-value-nosql-databasesmukolaich
01.02.2017 12:05Если есть деньги, то Вы очень правильно выбрали. Aerospike — это очень хорошее продакшн решение.
Кстати, у них есть community edition — 1 инстанс Aerospike.
GarudaJI
01.02.2017 10:23-1За пересказ редис кластер туториала спасибо, но больше интересуют как фейловер тестировали при отключении и мастера и слейва владеющего слотами, так что часть ключей становится не доступна? Как на лету переназначали слоты на живые ноды? Потому как из моего опыта на версию 3.2.1 что-ли руби скрипты работали через раз выдавая невразумительную ошибку.

sk123
02.02.2017 08:13Хотелось бы узнать, чем ваше решение лучше (или может быть хуже) чем использование Riak (https://habrahabr.ru/post/75202/).

IvanPonomarev
02.02.2017 10:35+1Спасибо за статью! Мы как раз сейчас в development-е работаем с single instance Redis-а, а в продакшн придётся, по-видимому, поднимать кластер.
Несколько вопросов:
1) О какой нагрузке в вашем случае идёт речь (например, в одновременных подключениях / в запросах в секунду)? (интересует граница, за которой сингл-инстанс с записью на диск становится неприменим)
2) Итак, я правильно понимаю, что минимальная осмысленная конфигурация кластера — 6 нод: 3 мастера/3 слейва и при сбое мастера он автоматом переконфигурируется для использования соответствующего слейва в качестве мастера?
3) А как выглядит подключение к кластеру в Java-коде, допустим? (Какой драйвер используете, кстати?) В качестве параметра подключения указывается массив IP-адресов?
mukolaich
02.02.2017 15:47Постараюсь ответить на Ваши вопросы:
1) К сожалению, метрику по количеству запросов в секунду мы не снимали, но могу сказать, что это сотни конекшнов (в зависимости от нагрузки), которые постоянно что-то пишут, или читают, или слушают канал. По идее, чтобы упереться в ограничение, связанное с IO, необходимо специально начудить (по делофту, если Redis is busy, он скипает операцию записи, и продолжает писать/читать).
2) Абсолютно правильно.
3) Используем форкнутый и допиленный Jedis — https://github.com/xetorthio/jedis
Реализация всех клиентов к кластеру Redis очень похожа: задается массив IP (у нас это Consul, который знает где какие редиски), и клиент загребает всю инфу про кластер с первой по списку рабочей ноды. И дальше, соответсвенно, работает уже со своей информацией о кластере.

gnomeby
02.02.2017 22:36Надеюсь преимущества Redis описаны не в сравнении с мемкешем, ибо их всего два: персистенность и возможность манипулировать структурами в значениях.
Ну и есть так же заморачиваться на отказоустойчивость, то можно мемкеш для сессий приготовить ничуть не хуже.
Nyaon
В сторону https://github.com/twitter/twemproxy и https://github.com/Netflix/dynomite смотрели? В своё время на них было легче поднять шардирование. Из профита — обычные клиенты продолжают работать, плюс не во всех либах есть пайплайны с кластер-режимом.
selivanov_pavel
Интересное, надо пощупать. Мы сейчас просто через haproxy отдаём тот редис, которого сентинелы выбрали мастером.
mukolaich
Абсолютно согласен, это было отличное решение в свое время. Нам не подошло из-за одного нюанса — латенси на чтении.
Если мы идем в редиску через прокси, или балансер — то теряем очень много времени на доступе по сети (сотни миллисекунд), это при том, что сам редис вычитывает у себя значение из мема за единицы миллисекунд.
Второй момент — на балансер переносится Single point of failure. Т.е. раньше было — падает редиска и ничего не работает, теперь стало — падает балансер и ничего не работает.
Получается, нужно докручивать дополнительную логику (keepalived, lvs etc.) — и опять же, учить клиентов.
В общем — получается очень дорого.
selivanov_pavel
Если поднять такую проксю на каждом клиенте, то и латенси сильно не увеличится, и single point of failure не образуется