

Потому рано или поздно встает вопрос автоматизации процесса поиска повторов, и тут мы рассмотрим основные, а также попробуем в деле.
Сравнение файлов через функцию hash
Одним из способов определения дубликатов является сравнение файлов путем генерации хеш-значения из содержимого заданного файла.
Простой пример вычисления хеша изображения:
<?php
imagecreatefrompng('image.png');
echo hash_file('md5', 'image.png');
?>
Результат выглядит примерно так: bff8b4bc8b5c1c1d5b3211dfb21d1e76
Если хеши двух изображений совпадают – изображения одинаковые.
Метод далеко не самый точный, так как работает только для идентичных картинок, при малейшем различии — толку ноль.
ImageMagick
Функция обработки изображений Imagick::compareImages возвращает массив, который содержит восстановленное изображение и разницу между изображениями.
Пример использования при сравнении двух изображений:
<?php
header("Content-Type: image/png");
$image1 = new imagick("image1.png");
$image2 = new imagick("image2.png");
$result = $image1->compareImages($image2, Imagick::METRIC_MEANSQUAREERROR);
$result[0]->setImageFormat("png");
echo $result[0];
?>
В итоге две сравниваемые картинки лепятся в одну, на которой видны отличия.
Также можно получить числовое выражение отличий по каждому параметру (пример с оф.сайта):
-> compare -verbose -metric mae rose.jpg reconstruct.jpg difference.png
Image: rose.jpg
Channel distortion: MAE
red: 2282.91 (0.034835)
green: 1853.99 (0.0282901)
blue: 2008.67 (0.0306503)
all: 1536.39 (0.0234439)
gd2 и libpuzzle
Для быстрого поиска дубликатов необходимо установить библиотеки gd2 и libpuzzle.
Установка:
apt-get install libpuzzle-php php5-gd
Libpuzzle создана для быстрого поиска визуального сходства изображений (GIF, PNG, JPEG). Сначала растровая картинка разбивается на блоки — автоматически отбрасываются рамки, не несущие особо значимой информации. Разница между смежными блоками формирует вектор — это так называемая подпись картинки. Похожесть картинок определяется расстоянием между двумя такими векторами. Потому обычно изменение цвета, ресайз или сжатие не влияют на результаты, выдаваемые libpuzzle.

Libpuzzle довольно проста в использовании. Вычисление подписи для двух изображений:
$cvec1 = puzzle_fill_cvec_from_file('img1.jpg');
$cvec2 = puzzle_fill_cvec_from_file('img2.jpg');
Вычисление расстояния между подписями:
$d = puzzle_vector_normalized_distance($cvec1, $cvec2);
Проверка изображений на схожесть:
if ($d < PUZZLE_CVEC_SIMILARITY_LOWER_THRESHOLD) {
echo "Pictures are looking similar\n";
} else {
echo "Pictures are different, distance=$d\n";
}
Сжатие подписей для хранения в базе данных:
$compress_cvec1 = puzzle_compress_cvec($cvec1);
$compress_cvec2 = puzzle_compress_cvec($cvec2);
Перцептивный хеш
Вероятнее всего, самый точный способ нахождения дубликатов — сравнение файлов через перцептивный хеш. Проверка на схожесть проводится путем подсчета количества отличающихся позиций между двумя хешами, это расстояние Хэмминга. Чем расстояние меньше — тем больше совпадение.

Отличается от первого способа тем, что указывает не только на одинаковость/неодинаковость, но и на степень различия. Подробнее об этом принципе можно прочитать в неплохом переводе.
Установка для UNIX платформ выглядит так:
$ ./phpize
$ ./configure [--with-pHash=...]
$ make
$ make test
$ [sudo] make install
Попробовать на деле можно через i.onthe.io/phash. Загрузка изображений через интерфейс и на выходе показатель «одинаковости».
Как это работает
Получаем хеш первого изображения:
$phash1 = ph_dct_imagehash($file1);
Получаем хеш второго изображения:
$phash2 = ph_dct_imagehash($file2);
Получаем расстояние Хэмминга между двумя изображениями:
$dist = ph_image_dist($phash1,$phash2);
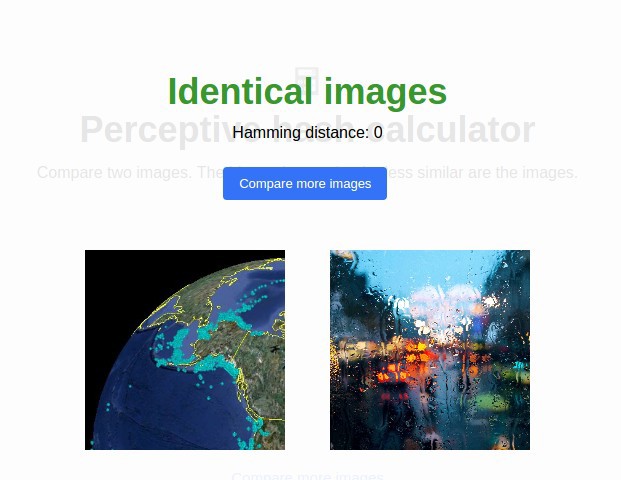
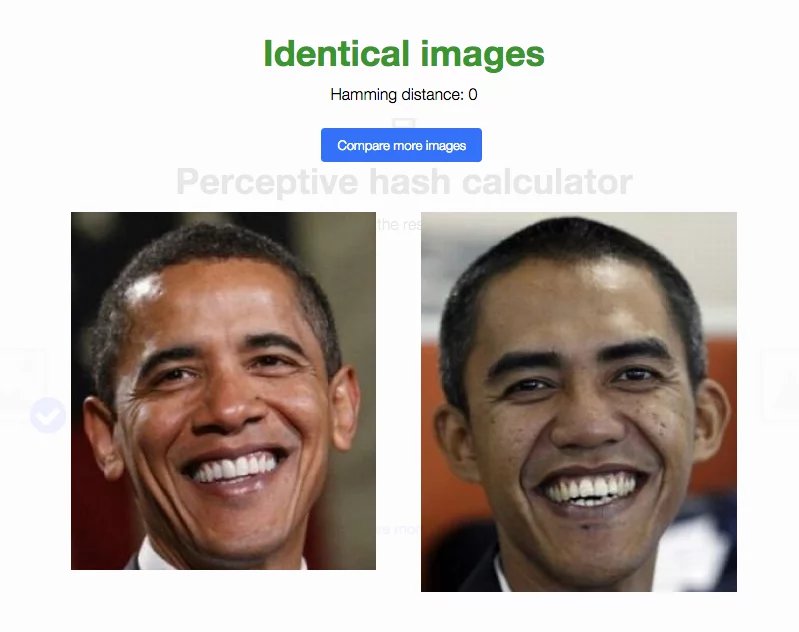
Мы проделали почти все возможные манипуляции с одной и той же фотографией, чтобы проверить — какие изменения мешают определять дубликаты через pHash, а какие — нет.
Например, при зеркальном отражении — картинка остается неузнанной.
Зато с цветами можно играться сколько угодно — на результат сравнения это не повлияет.
Чего нельзя сказать о манипуляциях с RGB-каналами, Джона опять не узнали, хоть и расстояние Хэмминга для такого случая гораздо меньше.
Остальные результаты выглядят так:
| Не мешают (расстояние Хэмминга = 0) | Мешают (расстояние Хэмминга — в скобках) |
|---|---|
| Измененное имя файла | Кроп (34)* |
| Формат (JPEG, PNG, GIF) | Поворот 90° (32)** |
| Оптимизация Google PageSpeed | Зеркальное отражение (36) |
| Ресайз с сохранением пропорций и без | Изменение положения кривых в RGB-каналах (18) |
| Изменение цветовой гаммы и четкости |
*зависит от величины кропнутой области. При отрезании от картинки маленькой рамки толщиной в несколько пикселей, расстояние Хэмминга будет нулевым, следовательно сходство — 100%. Но чем ощутимее кроп — тем больше расстояние — тем меньше шансов обнаружить дубликат. О поиске кропнутых дубликатов через перцептивные хеши можно почитать тут.
**то же самое, что и с кропом. При повороте на пару градусов расстояние незначительное, но чем больше угол наклона — тем сильнее различие.
Конспект
- Для сравнения картинок используйте ImageMagick, а для поиска полностью идентичных — сравнение через хеш.
- Чтобы находить незначительно измененные изображения — используйте библиотеку libpuzzle.
- Сравнение через перцептивный хеш — одно из самых надежных, можно попробовать тут.
Комментарии (21)

stychos
05.06.2015 17:24+1Как-то раз уже реализовывал сравнение по Хэммингу, как раз на php, весьма интересная область, с большим пространством для манёвров.

mephistopheies
05.06.2015 18:09-12и это во времена дип лернинга

Lisio
06.06.2015 03:28+12и очень модного инглиш юзинга
mephistopheies
07.06.2015 14:31-8ну лучше уж инглишь юзинг чем пхп юзинг

Acuna
10.06.2015 22:49Не минусовал, однако с Вами не соглашусь. PHP весьма и весьма неплохой язык, с неплохим синтаксисом и логикой, решающий достаточно широкий круг задач, и оставался бы весьма неплохим языком, если бы не школота, клепающая на нем ГС для своих игровых кланов, постоянно портящая ему репутацию. И все это «PHP — говно» заключается как правило в незнании области его применения. Он не хорош и не плох, он просто для другого. Он отлично подходит для веба, однако не так хорош для десктопа (возможно и такое, да). Для каждой задачи хороши свои инструменты, и если какую-то задачу нельзя решить каким,-либо инструментом — это не значит, что этот инструмент плох, просто он используется для неподходящей задачи. А быть может плох пользователь этого инструмента, пытающийся забить гвоздь унитазом, и сетующий на то, что унитаз — это определенно плохо.

Hellsy22
11.06.2015 01:53PHP изначально был перловым фреймворком для быстрого клепания простеньких страничек. Попытка использовать его в серьезных проектах ведет к необходимости отказаться от основных преимуществ PHP, т.е. перейти на шаблонизаторы, разбирать запросы, перенести работу с СУБД на отдельный уровень абстракции, отказаться от передачи переменных через сессию и т.д. Короче, в итоге получается более медленная, прожорливая и примитивная версия Перла. Но именно благодаря тем самым «школьникам, клепающим на нем ГС для своих игровых кланов» на сегодняшний день разработчиков PHP в десятки, если не в сотни раз больше, чем разработчиков на Perl. И это играет важную, а порой и решающую роль в выборе языка проекта — пусть PHP и хуже, но зато под него разработчиков найти проще. Ну, а чем больше проектов стартует на PHP — тем меньше вакансий для разработчиков на других языках. Что и вызывает негодование у тех, кто не хочет принять реальность. По мне, так в мире IT полно разного хлама, который стал популярным по разным причинам, проще его изучить и использовать, чем огораживаться.
Acuna
12.06.2015 02:40Так я и думал, что ответит мне не автор сего сообщения. Весьма предсказуемо. Ну да ладно, не суть в общем-то…
Полностью с Вами соглашусь. Однако тут есть и проблема иного рода. Я был бы очень рад, если бы такого рода критикой выступали бы люди, проверившие эту точку зрения на собственном опыте, то есть они честно писали на нем и сами убедились в том, что этот язык действительно криво решает ту задачу, для решения которой они, собственно, и пытались использовать данный инструмент. Только это может давать им свободу слова в данном вопросе. К такого рода заявлениям я отношусь уважительно. Однако к моему сожалению, эти высказывания чаще всего я слышу от людей, о которых ясно можно сделать вывод, что это мнение они подхватили извне, даже не пытаясь как-то проверить его истинность на собственном опыте. Не знаю, есть ли Вы в некой соц. сети от одного известного питерского программиста, однако там имеется группа Хабра, дак вы бы видели комментарии там, когда речь заходит о PHP! Она просто притягивает толпы школьников, которые генерируют тонны шуточек, просто пытаясь таким образом быть на одной волне со своими одноклассниками. Не один раз говорил о том, что за такое надо реально банить или хотя-бы закрыть там комменты, чтобы хоть как-то избежать наплыв такого количества спама, однако комменты по прежнему там открыты.
P. S. mephistopheies не в счет, он вроде как в Мыле работает, очень хочется надеяться, что это так.

nickolaym
05.06.2015 19:28+3Ситуация, на которой идея «выбрасывать похожие картинки» даст сбой — это, например, скриншоты: «вот посмотрите: здесь у кнопочки есть рамочка, а здесь её сдвинули на пиксел, и рамочка пропала».
Картинкохостинг в лучшем случае откажет пользователю в загрузке второй картинки («у меня уже есть такая»), а в худшем тихо выберет из двух картинок одну — и сильно удивит читателя (как же так, товарищ жалуется на разницу, а разницы-то нет)Acuna
05.06.2015 20:12Дак ведь сравниваются они по хешу, который неумолимо меняется даже при мельчайшем редактировании картинки. Не пропустит совершенно аналогичные, что именно и требуется.
nickolaym
05.06.2015 20:35Метод далеко не самый точный, так как работает только для идентичных картинок, при малейшем различии — толку ноль.
Я просто подчёркиваю, что случаи разные бывают, и принимать решения, опираясь лишь на низкоуровневый факт «картинки практически одинаковы» — недостаточно.
Разве что, можно собирать похожие картинки в кластеры для дальнейших ручных разгребаний.
И при добавлении новой картинки спрашивать: «вот есть уже похожая: всё равно добавить?»stychos
06.06.2015 02:39Ваши слова про кластеры напомнили мне одну простую и уже существующую без всяких кластеров вещь — дедупликацию на уровне файловых систем. Кто-нибудь рассматривал предметно, как обстоят дела с идентичными картинками и дедупликацией?

Andriyevski
06.06.2015 00:10-3Мне кажется задержки на обработку, если большой сервис и много онлайна будут очень высоки!
Как бы не было прискорбно, но по хешу вычислять побыстрее будет, я бы не грузил систему проверками, так как спорю 99% затраченого времени будет идти на подтверждение проверки на уникальность изображения!
Сравнивать со всеми имеющимися на сайте картинками кажется дурной тратой ресурсов системы, даже если будут несколько практически одинаковых картинок, ведь скажите, если на такой же картинке появиться надпись «Привет Вася!» в низу угла, и текст забрал к примеру 10 пикселей от низа в верх и в длинну пускай 20 пиксов, получаеться уникальная картинка присвоеная кому то, система отступит и увидит что картинка идентична с той что есть в системе и удалит именную картинку…
Я против такого хода… Не рационально! Хеш-сумма самое оно!
Если и проверять на копии то нужно писать отдельную проверку в которой все таки человек должен делать окончательный выбор удалить или нет.stychos
06.06.2015 02:37Всё зависит от задачи. Описанный тут хеш Хэмминга — это не постоянная величина, его и создавать, и применять и сравнивать можно по-разному, а немного разобравшись, в голову сразу лезет куча идей с собственными
улучшениямивелосипедами, так что, вопрос не в том, напишет ли Вася в углу картинки «Привет Вася!», а в том, что именно необходимо сделать в результате.



vaniaPooh
06.06.2015 22:49А не будет боевой сервер стреляться с высоким load average, если столько хэшей считать? Кажется, что современные диски дешевле, чем процессоры и память.

betauser
07.06.2015 17:45Если хеши двух изображений совпадают – изображения одинаковые.
Хеш может быть одинаковый для разных картинок. Нужно полностью сравнить каждую картинку из списка картинок с одинаковым хешем.
gto
Получается, каждый раз картинку сравнивать со всеми уже имеющимися на сайте? (кроме вариантов с хешем)
nikita2206
Вот здесь хорошее объяснение как использовать либпазл для индексирования изображений stackoverflow.com/a/9780314/1461092
gto
Реляционную БД для такой задачи, наверное, не очень правильно использовать, а вот с чем-нибудь наподобие neo4j может интересно получиться.
Komzpa
У постгреса есть хорошие расширения на тему поиска похожих хешей:
zdk.github.io/detecting-similar-images-with-phash-and-pg_similarity