
(Этюд для программистов или заявка на Интернет-поиск нового типа)

Программа, делающая из мухи слона (далее программа МС), показала, что неориентированный граф существительных с заданным количеством букв хоть и содержит тысячи вершин, но при этом довольно «тощий» (т.е. имеет сравнительно не много ребер) и до полного графа ему далеко (см. Пример 1). Вслед за Чарлзом Уэзереллом (Charles Wetherell), автором широко известной книги «Этюды для программистов», выбрал жанр этюда, чтобы представить различные способы представления таких графов. (И сделать из этого выводы для автоматизации выбора представления – вплоть, может быть, до Интернет-поиска нового типа).
Пример 1. Характеристики графа существительных длиной 8 букв.
«Представлять представления» — звучит, мягко говоря, шероховато, однако такая шероховатость, на мой взгляд, наиболее соответствует жанру этюда, намечающего несколько различных вариаций (по выражению Уэзерелла). Намечающего, но не предлагающего окончательного полного решения на все возможные случаи. На второстепенных чисто технических деталях реализации останавливаться не будем и, чтобы не перегружать ими этюд, буду приводить только наиболее значимые для сути фрагменты кода. Как и в упомянутой программе МС (в том числе и по соображениям повторного использования кода), буду использовать старый ОО Pascal Delphi-7, надеясь, что столь простой и широко известный язык наиболее легок для восприятия и при желании легко переводим на более современные универсальные языки программирования. Не буду останавливаться и на основах теории графов – их, как и прочие, используемые ниже, понятия и термины можно уточнить в Википедии – в некоторых случаях буду приводить ссылки. Но при этом полностью отказываюсь от ответственности за правильность вики-статей: в каждой статье согласно вики-правилам должны быть ссылки на авторитетные источники, эти источники и надо использовать для окончательного уточнения.
Стоит также отметить, что «тощие» графы, о которых пойдет речь, бывают нужны не только для игр со словами, но и для более серьезных задач. Например, в компьютерной (математической) органической химии молекулы химических веществ представляют в виде графа, в котором вершины соответствуют атомам, а химические связи – ребрам. Такое представление (иногда называемое формально-логическим подходом) соответствует классической структурной теории органической химии, традиционно использующей структурные формулы и шаростержневые модели. И хотя каждый современный химик точно знает, что атомы не похожи на шарики, а связи между ними не похожи на стерженьки, эти модели продолжают широко и успешно применяться в химии. Скелеты органических молекул в основном состоят из четырехвалентного углерода, таким образом, степени вершин представляющих их графов не будут превосходить четырех. Правда, возможны исключения, так, в графе молекулы ферроцена вершина, соответствующая атому железа, будет иметь степень 10. Единственным полным графом будет углеродный скелет циклопропана, остальные будут сильно неполными. Для постоянной высокообъемной работы с графами этот этюд вряд ли будет полезен, однако надеюсь, что он может оказаться небесполезным для решения ситуативных задач типа игр. И в любом случае данный простой пример позволит проиллюстрировать идею интеллектуального решения проблемы выбора представления (в том числе и с применением ИИ).
Как и в программе МС, будем в каждом из наших представлений искать кратчайший путь между заданной парой вершин графа. Начнем с определения класса TGraph:
Защищенные (protected) абстрактные методы будут нужны для замены из потомков. Например:
Отметим, что в используемых динамических массивах индексация начинается с нуля, в то время как во многих книгах по теории графов нумерация вершин и ребер начинается с единицы. Так как нам не требуется, чтобы граф был связный, при вводе (о котором будет сказано ниже) можно допустить изолированную нулевую вершину по умолчанию и вводить граф с первой вершины из книги.
Представление графа с помощью матрицы смежности (adjMatrix), пожалуй, одно из наиболее часто встречающихся и универсальных представлений. В общем случае этой матрицей можно представить ориентированный граф, в котором ребру (v,u) соответствует элемент adjMatrix[v,u]=true (при инициализации во все элементы записывается false). Такой граф можно определить следующим образом:
Этот же класс можно использовать и для неориентированных графов. В этом случае ребру неориентированного графа, инцидентного паре вершин (v,u), будут соответствовать ребра (v,u) и (u,v) орграфа. Так мы и будем поступать. Поэтому метод «добавить ребро» (addEdgeA) определим так:
Если ребер относительно немного, то матрица смежности будет разреженной. Работа с такими матрицами подробно рассмотрена в книге С.Писсанецки, Технология разреженных матриц, М.: Мир, 1988. Здесь мы не будем пытаться применить довольно изощренные приемы, описанные там, а просто «уполовиним» эту матрицу, используя только ее нижнюю треугольную подматрицу – т.к. мы не рассматриваем графов с петлями, то и главная диагональ нам не нужна. Определим еще один класс:
для которого можно использовать следующий метод инициализации:
В этом случае и метод «добавить ребро» (addEdgeA) будет выглядеть иначе, чем для орграфа:
Аналогично по-разному реализуются методы isEdgeA:
А теперь подумаем, как быть с очень большими графами – например, в миллион вершин? – Даже треугольная матрица смежности таких размеров может оказаться великовата! Сделаем следующие определения:
Учитывая, что мы работаем с «тощими» графами, в которых ребер сравнительно немного, будем запоминать пару вершин, инцидентных ребру, в векторе ребер edges:
Такой подход соответствует одному из наиболее экономных представлений графа в виде списка смежности. В частности, он очень удобен для ручного ввода графов. Можно использовать следующий формат для записи ребра:
где v,u – инцидентные ребру вершины.
Записи делаются в строку и разделяются друг от друга запятыми. Даже в простых случаях бывает удобнее ввести строку:
чем набирать матрицу смежности 3х3.
Однако, как часто бывает, экономия на объеме памяти может обернуться большими затратами времени, если программа будет непосредственно работать с вектором ребер edges. Действительно, в методе isEdgeA может потребоваться перебор всех ребер. Можно, конечно, отсортировать этот вектор и вести поиск делением пополам, однако при небольших степенях каждой вершины можно использовать более быстрый метод. В вектор nbVertex запишем соседей каждой вершины. Число соседей для вершины соответствует ее степени, поэтому соседи нулевой вершины будут записаны следующим образом:
Далее аналогично будут записаны соседи первой вершины и т.д. Индекс для каждого первого соседа каждой вершины будем запоминать в векторе nbStart:
Такую индексацию осуществляет метод, использующий вспомогательный вектор nbCount:
Метод isEdgeA для пары вершин (v,u) потребует перебора не более чем deg(v) элементов nbVertex:
Отметим, что такой поиск можно вести независимо с нескольких позиций в заданных пределах, поэтому если в нашем очень большом графе будут попадаться вершины с большими степенями, то поиск можно легко распараллелить. В некоторых алгоритмах может потребоваться добавлять и удалять ребра. Это легко сделать в вышеприведенных представлениях, но не в последнем случае, что, очевидно, является его минусом. Однако для нашей цели – поиска кратчайшего пути — добавлять и удалять ребра не потребуется.
Перейдем к поиску кратчайшего пути. Использованный алгоритм BFS является классическим, подробно описан во многих книгах, пересказанных в Википедии, поэтому опустим его описание, а приведем реализацию:
Описанные классы для трех различных представлений графов были реализованы в отдельном модуле, для отладки и тестирования (а также для демонстрации в данном этюде) которого написана программа – назовем ее программа Т. Снимок экрана с окном этой программы приведен на рисунке.
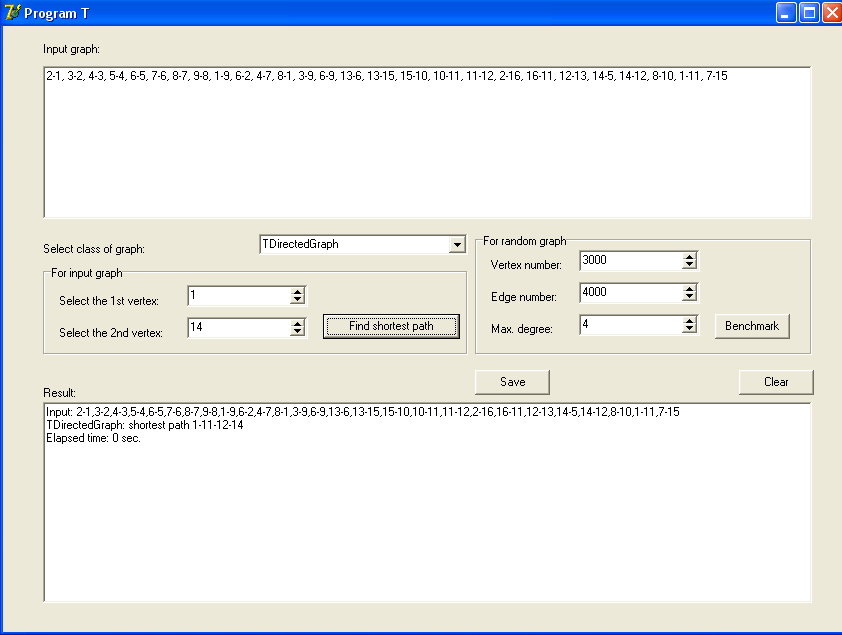
В поле Input graph можно набрать список смежности графа в описанном выше формате. В поле Result программа выводит сообщения и результат работы. Этот вывод можно сохранить в текстовой файл кнопкой Save, а поле можно очистить кнопкой Clear. Выпадающий список Select class of graph позволяет выбрать одно из описанных представлений. Их немного и можно было бы заполнить его от руки во время разработки (in design time), но не исключено, что в дальнейшем добавятся другие представления, поэтому пусть заполнение списка происходит во время выполнения программы (in run time). Для этого сделаем следующий простой обработчик события создания основной формы:
С созданными здесь графами (dg, ug, bg) и будет дальше работать программа. Парсинг и трансляция списка смежности тривиальны, поэтому не будем тратить внимание читателей на их описание. Перейдем лучше ко второму основному тесту программы – поиску кратчайшего пути между случайной парой вершин (тестовые вершины) в случайном графе с заданными пользователем параметрами. Для генерации такого графа добавим следующий простой метод в наш родительский класс. Параметры метода – число вершин и максимальная степень вершины:
Для копирования сгенерированного графа можно использовать следующий простой метод:
Поиск тестовых вершин также не стал усложнять (для подробных не этюдных исследований в Интернете можно найти много хороших процедур генерации случайных графов):
Константу maxGen взял равной 10, а дальше как повезет – не все генерации оказываются подходящими. Приведу один из типичных результатов:
В других выдачах разница по времени еще меньше, но в целом видится тенденция
где – время.
Таким образом, можно предположить, что, с одной стороны, смена представления (из числа использованных) может особо не сказаться на скорости, но, с другой стороны, для конкретной задачи и для ожидаемого вида графов стоит испытать разные представления. Специально подчеркнул слово «предположить», т.к. приведенные результаты выглядят слишком нестрогими для более категоричных рекомендаций. Другая задача может показать качественно иные результаты. Вероятно, невозможно сделать выбор какого-либо одного представления на все случаи. В связи с этим появляется следующая мысль. Обычно программы, вроде описанной программы Т, используются при разработке библиотеки и на стадии окончательного тестирования, но до пользователей они не доходят. В то же время во многих больших библиотеках можно встретить функции, которые делают то же самое, но с данными разной структуры и разными методами. Думаю, что в таких случаях будет очень полезно, если разработчики будут прикладывать к библиотекам инструменты, помогающие пользователю сделать осознанный и обоснованный выбор. Следующим прогрессивным шагом может быть программа, которая, получив от пользователя параметры на генерацию нужных тестов, будет делать выбор алгоритмов и структур данных на основании результатов этих тестов и давать пользователю рекомендации по применению ресурсов библиотеки. В зависимости от задачи и от возможностей поддержки тесты могут не только генерироваться, но и загружаться из локальной БД, с сайта поддержки или в результате глобального поиска по Интернету. В тестовой выборке могут оказаться графы с особенностью, не очевидной заказчику. Испытания автоматом учтут такую особенность. Это будет интеллектуальное (AI, может быть AI+естественный интеллект) решение проблемы выбора представления, отмеченное в заголовке этого этюда.
Дальше – больше. Сейчас, чтобы найти нужную библиотеку, мы набираем в поисковике что-то вроде «поиск кратчайшего пути в графе». Далее надеемся на чудо, которое поможет из сотни тысяч ссылок найти наиболее подходящую для нашего случая. Если библиотеки будут снабжены Т-программами со стандартизированным сетевым протоколом (возможно, понадобятся новые протоколы), то пользователь мог бы послать на поисковик набор тестов, и серверы Т-программ выполнили бы эти тесты. Поисковик проанализировал бы результаты и дал в ответе на запрос ссылки на библиотеки, наиболее подходящие для данного случая. При этом, рассылая запросы, поисковик может учитывать результаты похожих предыдущих запросов. Это будет поиск нового типа. Сейчас библиотеки получают рейтинги по количеству скачиваний, а в случае такого поиска будут получать рейтинги по удовлетворению тестовых задач пользователей. Рейтинги будут сильно дифференцированы: в одной группе запросов будет приоритет максимальной производительности, а в другой экономии памяти, а в третьей может быть дополнительное требование ссылок только на бесплатные библиотеки и т.д. Конечно, сравнение результатов, полученных на разных серверах, будет очень приблизительным, даже с применением поправочных коэффициентов на вычислительные возможности сервера. Окончательное сравнение из предварительно отобранных вариантов нужно будет делать на клиентском компьютере.
Сейчас в Интернете можно найти кучу всевозможных online калькуляторов и конверторов форматов файлов – так что возникает впечатление, что можно что угодно online посчитать и конвертировать. Но это сервис противоположной направленности на результат, а не на выбор для последующего offline применения.
В заключение стоит отметить, что представлений графов предложено гораздо больше, чем те, что были описаны выше. Например, представление бинарных деревьев (очень «тощие» графы) с помощью ссылок подробно описано в классических работах Вирта. Можно в восемь раз увеличить вместимость, определив:
где каждому ребру будет соответствовать 1 бит и, таким образом, 8 ребер пакуются в один байт. В руководствах сказано, что максимальную производительность обеспечивает тип Cardinal (4 байта), поэтому может быть целесообразной и такая структура данных:
Примером такого подхода может служить работа Комоско Л.Ф., Бацын М.В., Быстрый алгоритм для решения задачи о раскраске графа с использованием битовых операций, Труды 38-й конференции «Информационные технологии и системы — 2014», Н. Новгород: ИППИ РАН, 2014, C. 432. Битовое представление графа с использованием инструкции bsf (bit scan forward) CPU позволило получить среднее ускорение программы почти в 17 раз. Много разнообразных представлений графов используется для GPU (см. например).
Отдельная важная тема — это представление графов с помощью множеств:
Действительно: понятие множество – основное для современной математики и было бы естественно столь же широко использовать его в программировании. В том числе и для графов. Однако здесь появляются трудности, так, например, в Delphi максимальная мощность множества (maxVertNum) сильно ограничена. Поэтому для больших графов понадобится специальная техника представления больших множеств. Кроме того, нет удобной эффективной процедуры выбора следующего за указанным элемента множества. Этот недостаток существует со времен Виртовского Паскаля, кажется, только в безнадежно устаревшем Pascal 8000 для OS 360/370 было сделано расширение – оператор цикла forall:
Этот оператор позволял заменить стандартную громоздкую конструкцию перебора элементов множества:
В случае очень небольших множеств для выбора следующего элемента возможна табличная реализация, а для множеств большего размера – несложная ассемблерная процедура.
Программа, делающая из мухи слона (далее программа МС), показала, что неориентированный граф существительных с заданным количеством букв хоть и содержит тысячи вершин, но при этом довольно «тощий» (т.е. имеет сравнительно не много ребер) и до полного графа ему далеко (см. Пример 1). Вслед за Чарлзом Уэзереллом (Charles Wetherell), автором широко известной книги «Этюды для программистов», выбрал жанр этюда, чтобы представить различные способы представления таких графов. (И сделать из этого выводы для автоматизации выбора представления – вплоть, может быть, до Интернет-поиска нового типа).
Start for word length 8
6016 words loaded from dictionary file: ..\Dictionary\ORF3.txt
Graph was made: edges number = 871Пример 1. Характеристики графа существительных длиной 8 букв.
«Представлять представления» — звучит, мягко говоря, шероховато, однако такая шероховатость, на мой взгляд, наиболее соответствует жанру этюда, намечающего несколько различных вариаций (по выражению Уэзерелла). Намечающего, но не предлагающего окончательного полного решения на все возможные случаи. На второстепенных чисто технических деталях реализации останавливаться не будем и, чтобы не перегружать ими этюд, буду приводить только наиболее значимые для сути фрагменты кода. Как и в упомянутой программе МС (в том числе и по соображениям повторного использования кода), буду использовать старый ОО Pascal Delphi-7, надеясь, что столь простой и широко известный язык наиболее легок для восприятия и при желании легко переводим на более современные универсальные языки программирования. Не буду останавливаться и на основах теории графов – их, как и прочие, используемые ниже, понятия и термины можно уточнить в Википедии – в некоторых случаях буду приводить ссылки. Но при этом полностью отказываюсь от ответственности за правильность вики-статей: в каждой статье согласно вики-правилам должны быть ссылки на авторитетные источники, эти источники и надо использовать для окончательного уточнения.
Стоит также отметить, что «тощие» графы, о которых пойдет речь, бывают нужны не только для игр со словами, но и для более серьезных задач. Например, в компьютерной (математической) органической химии молекулы химических веществ представляют в виде графа, в котором вершины соответствуют атомам, а химические связи – ребрам. Такое представление (иногда называемое формально-логическим подходом) соответствует классической структурной теории органической химии, традиционно использующей структурные формулы и шаростержневые модели. И хотя каждый современный химик точно знает, что атомы не похожи на шарики, а связи между ними не похожи на стерженьки, эти модели продолжают широко и успешно применяться в химии. Скелеты органических молекул в основном состоят из четырехвалентного углерода, таким образом, степени вершин представляющих их графов не будут превосходить четырех. Правда, возможны исключения, так, в графе молекулы ферроцена вершина, соответствующая атому железа, будет иметь степень 10. Единственным полным графом будет углеродный скелет циклопропана, остальные будут сильно неполными. Для постоянной высокообъемной работы с графами этот этюд вряд ли будет полезен, однако надеюсь, что он может оказаться небесполезным для решения ситуативных задач типа игр. И в любом случае данный простой пример позволит проиллюстрировать идею интеллектуального решения проблемы выбора представления (в том числе и с применением ИИ).
Как и в программе МС, будем в каждом из наших представлений искать кратчайший путь между заданной парой вершин графа. Начнем с определения класса TGraph:
TGraph = class(TObject)
protected
procedure initA (vNum, eNum : integer); virtual; abstract;
procedure addEdgeA (v,u : integer); virtual; abstract;
function isEdgeA (v,u : integer) : Boolean; virtual; abstract;
private
vertNum : integer; // число вершин
edgeNum : integer; // число ребер
adjMatrix : array of array of Boolean; // матрица смежности
degVector : array of integer; // вектор степеней вершин
predV : array of integer; // вспомогательный вектор вершин для поиска кратчайшего пути
path : array of integer; // путь
pathLen : integer; // длина пути (длина каждого ребра равна 1)
public
testPairV1, testPairV2 : integer; // тестовые вершины
constructor create;
destructor free;
function getVertNum : integer; // возвращает число вершин
function getEdgeNum : integer; // возвращает число ребер
function deg (v : integer) : integer; // возвращает степень вершины
procedure init (vNum, eNum : integer); // инициализировать объект
procedure addEdge (v,u : integer); // добавить ребро (v,u)
function isVertex (v : integer) : Boolean; // true, если 0<=v< vertNum
function isEdge (v,u : integer) : Boolean; // true, если пара вершин (v,u) инцидентны ребру
procedure make (eNum,maxDeg : integer); // генерировать тестовый граф
procedure copy (g : TGraph); // копировать граф из графа g
function BFSsp(v,u : integer) : Boolean; // искать кратчайший путь алгоритмом BFS
procedure getShortestPath (v,u : integer); // записать путь в поле path
function pathToStr {(v : integer)} : string; // преобразовать путь path в строку типа string
function getShortestPathStr (v,u :integer) : string; // вернуть кратчайший путь
function findTestPair : string; // найти пару тестовых вершин
end;Защищенные (protected) абстрактные методы будут нужны для замены из потомков. Например:
procedure TGraph.addEdge (v,u : integer);
begin
addEdgeA (v,u);
end;Отметим, что в используемых динамических массивах индексация начинается с нуля, в то время как во многих книгах по теории графов нумерация вершин и ребер начинается с единицы. Так как нам не требуется, чтобы граф был связный, при вводе (о котором будет сказано ниже) можно допустить изолированную нулевую вершину по умолчанию и вводить граф с первой вершины из книги.
Представление графа с помощью матрицы смежности (adjMatrix), пожалуй, одно из наиболее часто встречающихся и универсальных представлений. В общем случае этой матрицей можно представить ориентированный граф, в котором ребру (v,u) соответствует элемент adjMatrix[v,u]=true (при инициализации во все элементы записывается false). Такой граф можно определить следующим образом:
TDirectedGraph = class(TGraph)
protected
procedure initA (vNum,eNum : integer); override;
procedure addEdgeA (v,u : integer); override;
function isEdgeA (v,u : integer) : Boolean; override;
end;Этот же класс можно использовать и для неориентированных графов. В этом случае ребру неориентированного графа, инцидентного паре вершин (v,u), будут соответствовать ребра (v,u) и (u,v) орграфа. Так мы и будем поступать. Поэтому метод «добавить ребро» (addEdgeA) определим так:
procedure TDirectedGraph.addEdgeA (v,u : integer);
var
i,j : integer;
begin
if not adjMatrix [v,u] then
begin
adjMatrix [v,u] := true;
adjMatrix [u,v] := true;
inc (edgeNum); // увеличить на 1 число ребер
inc(degVector [v]); // увеличить на 1 степень вершины v
inc(degVector [u]); // увеличить на 1 степень вершины u
end;
end;Если ребер относительно немного, то матрица смежности будет разреженной. Работа с такими матрицами подробно рассмотрена в книге С.Писсанецки, Технология разреженных матриц, М.: Мир, 1988. Здесь мы не будем пытаться применить довольно изощренные приемы, описанные там, а просто «уполовиним» эту матрицу, используя только ее нижнюю треугольную подматрицу – т.к. мы не рассматриваем графов с петлями, то и главная диагональ нам не нужна. Определим еще один класс:
TUndirectedGraph = class(TGraph)
protected
procedure initA (vNum,eNum : integer); override;
procedure addEdgeA (v,u : integer); override;
function isEdgeA (v,u : integer) : Boolean; override;
public
procedure clear;
end;для которого можно использовать следующий метод инициализации:
procedure TUndirectedGraph.initA (vNum, eNum : integer);
var
i,j : integer;
begin
degVector := nil;
predV := nil;
path := nil;
vertNum := vNum;
setLength (adjMatrix,vertNum-1);
setLength (degVector,vertNum);
for i:=0 to vertNum-2 do
begin
degVector [i] := 0;
setLength (adjMatrix [i], i+1);
for j := 0 to i do
adjMatrix [i,j] := false;
end;
degVector [vertNum-1] := 0;
end;В этом случае и метод «добавить ребро» (addEdgeA) будет выглядеть иначе, чем для орграфа:
procedure TUndirectedGraph.addEdgeA (v,u : integer);
var
i,j : integer;
begin
if v>u then
begin
i := v-1; // i := max (v,u)-1;
j := u; // j := min (v,u);
end
else
if v<u then
begin
i := u-1;
j := v;
end
else
exit;
if not adjMatrix [i,j] then
begin
adjMatrix [i,j] := true;
inc (edgeNum);
inc(degVector [i]);
inc(degVector [j]);
end;
end;Аналогично по-разному реализуются методы isEdgeA:
function TDirectedGraph.isEdgeA (v,u : integer) : Boolean;
begin
Result := adjMatrix [v,u];
end;
function TUndirectedGraph.isEdgeA (v,u : integer) : Boolean;
begin
if u<v then
Result := adjMatrix [v-1,u]
else
if u>v then
Result := adjMatrix [u-1,v]
else
Result := false;
end;А теперь подумаем, как быть с очень большими графами – например, в миллион вершин? – Даже треугольная матрица смежности таких размеров может оказаться великовата! Сделаем следующие определения:
TEdgeRec = record
v1,v2 : integer;
end;
TBigUndirectedGraph = class(TGraph)
protected
procedure initA (vNum,eNum : integer); override;
procedure addEdgeA (v,u : integer); override;
function isEdgeA (v,u : integer) : Boolean; override;
private
edgeIndex : integer;
edges : array of TEdgeRec;
nbVertex : array of integer; //вектор соседей
nbStart : array of integer; // начало просмотра вектора соседей для заданной вершины
nbCount : array of integer; // вспомогательный счетчик соседей
public
destructor free;
procedure calcNb; //расчет вектора соседей
end;Учитывая, что мы работаем с «тощими» графами, в которых ребер сравнительно немного, будем запоминать пару вершин, инцидентных ребру, в векторе ребер edges:
procedure TBigUndirectedGraph.addEdgeA (v,u : integer);
begin
with edges [edgeIndex] do
begin
v1 := v;
v2 := u;
end;
inc (edgeIndex);
inc(degVector [v]);
inc(degVector [u]);
end;Такой подход соответствует одному из наиболее экономных представлений графа в виде списка смежности. В частности, он очень удобен для ручного ввода графов. Можно использовать следующий формат для записи ребра:
v-uгде v,u – инцидентные ребру вершины.
Записи делаются в строку и разделяются друг от друга запятыми. Даже в простых случаях бывает удобнее ввести строку:
1-2,2-3,3-1чем набирать матрицу смежности 3х3.
Однако, как часто бывает, экономия на объеме памяти может обернуться большими затратами времени, если программа будет непосредственно работать с вектором ребер edges. Действительно, в методе isEdgeA может потребоваться перебор всех ребер. Можно, конечно, отсортировать этот вектор и вести поиск делением пополам, однако при небольших степенях каждой вершины можно использовать более быстрый метод. В вектор nbVertex запишем соседей каждой вершины. Число соседей для вершины соответствует ее степени, поэтому соседи нулевой вершины будут записаны следующим образом:
NbVertex [0], …, nbVertex[deg(0)-1]Далее аналогично будут записаны соседи первой вершины и т.д. Индекс для каждого первого соседа каждой вершины будем запоминать в векторе nbStart:
nbStart[0]=0, nbStart[1]= deg(0),…Такую индексацию осуществляет метод, использующий вспомогательный вектор nbCount:
procedure TBigUndirectedGraph.calcNb;
var
i,n : integer;
begin
n := 0;
for i:=0 to vertNum-1 do
begin
nbStart [i] := n;
nbCount [i] := n;
inc (n, degVector [i]);
end;
for i:=0 to edgeNum-1 do
begin
nbVertex [nbCount[edges [i].v1]] := edges [i].v2;
inc (nbCount[edges [i].v1]);
nbVertex [nbCount[edges [i].v2]] := edges [i].v1;
inc (nbCount[edges [i].v2]);
end;
end;Метод isEdgeA для пары вершин (v,u) потребует перебора не более чем deg(v) элементов nbVertex:
function TBigUndirectedGraph.isEdgeA (v,u : integer) : Boolean;
var
i,n,d : integer;
begin
d := deg (v);
if d>0 then
begin
n := nbStart [v];
for i:=0 to d-1 do
begin
Result := nbVertex[n+i]=u;
if Result then
exit;
end;
end
else
Result := false;
end;Отметим, что такой поиск можно вести независимо с нескольких позиций в заданных пределах, поэтому если в нашем очень большом графе будут попадаться вершины с большими степенями, то поиск можно легко распараллелить. В некоторых алгоритмах может потребоваться добавлять и удалять ребра. Это легко сделать в вышеприведенных представлениях, но не в последнем случае, что, очевидно, является его минусом. Однако для нашей цели – поиска кратчайшего пути — добавлять и удалять ребра не потребуется.
Перейдем к поиску кратчайшего пути. Использованный алгоритм BFS является классическим, подробно описан во многих книгах, пересказанных в Википедии, поэтому опустим его описание, а приведем реализацию:
function TGraph.BFSsp(v,u : integer) : Boolean;
// искать кратчайший путь алгоритмом BFS
var
Qu : array of integer;
first, last : integer;
i,p : integer;
newV : array of Boolean;
begin
p := v;
setLength (predV,vertNum);
setLength (newV,vertNum);
for i:= 0 to vertNum-1 do
newV [i] := true;
setLength (Qu,vertNum);
first := 0;
last := 1;
Qu [last] := p;
newV [p] := false;
while (first<last) and (p<>u) do
begin
inc (first);
p := Qu [first];
for i:=0 to vertNum-1 do
if isEdge (p,i) and newV [i] then
begin
inc (last);
Qu [last] := i;
newV [i] := false;
predV [i] := p;
end;
end;
Result := p = u;
Qu := nil;
newV := nil;
end; // BFSsp
procedure TGraph.getShortestPath (v,u : integer);
var
i,p : integer;
begin
setLength (path,vertNum);
p := u;
i := 0;
path [0] := p;
while p<>v do
begin
inc (i);
p := predV [p];
path [i] := p;
end;
// inc (i);
pathLen := i+1;
setLength (path,pathLen);
end; // getShortestPathОписанные классы для трех различных представлений графов были реализованы в отдельном модуле, для отладки и тестирования (а также для демонстрации в данном этюде) которого написана программа – назовем ее программа Т. Снимок экрана с окном этой программы приведен на рисунке.
В поле Input graph можно набрать список смежности графа в описанном выше формате. В поле Result программа выводит сообщения и результат работы. Этот вывод можно сохранить в текстовой файл кнопкой Save, а поле можно очистить кнопкой Clear. Выпадающий список Select class of graph позволяет выбрать одно из описанных представлений. Их немного и можно было бы заполнить его от руки во время разработки (in design time), но не исключено, что в дальнейшем добавятся другие представления, поэтому пусть заполнение списка происходит во время выполнения программы (in run time). Для этого сделаем следующий простой обработчик события создания основной формы:
procedure TMainForm.FormCreate(Sender: TObject);
begin
dg := TDirectedGraph.create;
ug := TUndirectedGraph.create;
bg := TBigUndirectedGraph.create;
ComboBoxClass.AddItem(dg.ClassName,dg);
ComboBoxClass.AddItem(ug.ClassName,ug);
ComboBoxClass.AddItem(bg.ClassName,bg);
ComboBoxClass.ItemIndex := 0;
end;С созданными здесь графами (dg, ug, bg) и будет дальше работать программа. Парсинг и трансляция списка смежности тривиальны, поэтому не будем тратить внимание читателей на их описание. Перейдем лучше ко второму основному тесту программы – поиску кратчайшего пути между случайной парой вершин (тестовые вершины) в случайном графе с заданными пользователем параметрами. Для генерации такого графа добавим следующий простой метод в наш родительский класс. Параметры метода – число вершин и максимальная степень вершины:
procedure TGraph.make (eNum, maxDeg : integer);
var
n,i,j : integer;
begin
randomize;
n := 0;
repeat
i := random (vertNum); // 1-ая случайная вершина
j := random (vertNum); // 2-ая случайная вершина
if (i<>j)and (deg(i)<maxDeg) and (deg(j)<maxDeg) then
begin
addEdge (i,j);
inc (n);
end;
until n= eNum;
end;Для копирования сгенерированного графа можно использовать следующий простой метод:
procedure TGraph.copy (g : TGraph);
// копировать граф из графа g
var
i,j : integer;
begin
for i:=1 to vertNum-1 do
for j := 0 to i-1 do
if g.isEdge (i,j) then
addEdge (i,j);
end;Поиск тестовых вершин также не стал усложнять (для подробных не этюдных исследований в Интернете можно найти много хороших процедур генерации случайных графов):
function TGraph.findTestPair : string;
var
i,j,maxV1,maxV2 : integer;
maxLen : integer;
begin
maxLen := 0;
maxV1 := 0;
maxV2 := 0;
for i := 1 to maxGen do
begin
testPairV1 := random (vertNum); // 1-ая случайная вершина
j := 0;
repeat
testPairV2 := random (vertNum); // 2-ая случайная вершина
inc (j);
until ((testPairV1<>testPairV2) and (not isEdge (testPairV1, testPairV2)))
or (j=maxGen);
if BFSsp(testPairV1, testPairV2) then
begin
getShortestPath (testPairV1, testPairV2);
if pathLen > maxLen then
begin
maxLen := pathLen;
maxV1 := testPairV1;
maxV2 := testPairV2;
end;
path := nil;
end
end;
testPairV1 := maxV1;
testPairV1 := maxV2;
Result := 'Test vertex pair '+intToStr(testPairV1)+', '+
intToStr(testPairV2)+' Path length '+ intToStr(maxLen);
end;Константу maxGen взял равной 10, а дальше как повезет – не все генерации оказываются подходящими. Приведу один из типичных результатов:
--- Benchmark ---------
Vertex number: 3000 Edge number: 4000 Max degree: 4
TDirectedGraph: Test vertex pair 2671, 853 Path length 12
TDirectedGraph: shortest path 2671-2629-2646-1658-499-2625-354-1027-626-733-2641-853
Elapsed time: 0.0160002149641514 sec.
TUndirectedGraph: shortest path 2671-2629-2646-1658-499-2625-354-1027-626-733-2641-853
Elapsed time: 0.030999630689621 sec.
TBigUndirectedGraph: shortest path 2671-2629-2646-1658-499-2625-354-1027-626-733-2641-853
Elapsed time: 0.0470004742965102 sec.В других выдачах разница по времени еще меньше, но в целом видится тенденция
где – время.
Таким образом, можно предположить, что, с одной стороны, смена представления (из числа использованных) может особо не сказаться на скорости, но, с другой стороны, для конкретной задачи и для ожидаемого вида графов стоит испытать разные представления. Специально подчеркнул слово «предположить», т.к. приведенные результаты выглядят слишком нестрогими для более категоричных рекомендаций. Другая задача может показать качественно иные результаты. Вероятно, невозможно сделать выбор какого-либо одного представления на все случаи. В связи с этим появляется следующая мысль. Обычно программы, вроде описанной программы Т, используются при разработке библиотеки и на стадии окончательного тестирования, но до пользователей они не доходят. В то же время во многих больших библиотеках можно встретить функции, которые делают то же самое, но с данными разной структуры и разными методами. Думаю, что в таких случаях будет очень полезно, если разработчики будут прикладывать к библиотекам инструменты, помогающие пользователю сделать осознанный и обоснованный выбор. Следующим прогрессивным шагом может быть программа, которая, получив от пользователя параметры на генерацию нужных тестов, будет делать выбор алгоритмов и структур данных на основании результатов этих тестов и давать пользователю рекомендации по применению ресурсов библиотеки. В зависимости от задачи и от возможностей поддержки тесты могут не только генерироваться, но и загружаться из локальной БД, с сайта поддержки или в результате глобального поиска по Интернету. В тестовой выборке могут оказаться графы с особенностью, не очевидной заказчику. Испытания автоматом учтут такую особенность. Это будет интеллектуальное (AI, может быть AI+естественный интеллект) решение проблемы выбора представления, отмеченное в заголовке этого этюда.
Дальше – больше. Сейчас, чтобы найти нужную библиотеку, мы набираем в поисковике что-то вроде «поиск кратчайшего пути в графе». Далее надеемся на чудо, которое поможет из сотни тысяч ссылок найти наиболее подходящую для нашего случая. Если библиотеки будут снабжены Т-программами со стандартизированным сетевым протоколом (возможно, понадобятся новые протоколы), то пользователь мог бы послать на поисковик набор тестов, и серверы Т-программ выполнили бы эти тесты. Поисковик проанализировал бы результаты и дал в ответе на запрос ссылки на библиотеки, наиболее подходящие для данного случая. При этом, рассылая запросы, поисковик может учитывать результаты похожих предыдущих запросов. Это будет поиск нового типа. Сейчас библиотеки получают рейтинги по количеству скачиваний, а в случае такого поиска будут получать рейтинги по удовлетворению тестовых задач пользователей. Рейтинги будут сильно дифференцированы: в одной группе запросов будет приоритет максимальной производительности, а в другой экономии памяти, а в третьей может быть дополнительное требование ссылок только на бесплатные библиотеки и т.д. Конечно, сравнение результатов, полученных на разных серверах, будет очень приблизительным, даже с применением поправочных коэффициентов на вычислительные возможности сервера. Окончательное сравнение из предварительно отобранных вариантов нужно будет делать на клиентском компьютере.
Сейчас в Интернете можно найти кучу всевозможных online калькуляторов и конверторов форматов файлов – так что возникает впечатление, что можно что угодно online посчитать и конвертировать. Но это сервис противоположной направленности на результат, а не на выбор для последующего offline применения.
В заключение стоит отметить, что представлений графов предложено гораздо больше, чем те, что были описаны выше. Например, представление бинарных деревьев (очень «тощие» графы) с помощью ссылок подробно описано в классических работах Вирта. Можно в восемь раз увеличить вместимость, определив:
adjMatrix : array of array of Byte;где каждому ребру будет соответствовать 1 бит и, таким образом, 8 ребер пакуются в один байт. В руководствах сказано, что максимальную производительность обеспечивает тип Cardinal (4 байта), поэтому может быть целесообразной и такая структура данных:
adjMatrix : array of array of Cardinal;Примером такого подхода может служить работа Комоско Л.Ф., Бацын М.В., Быстрый алгоритм для решения задачи о раскраске графа с использованием битовых операций, Труды 38-й конференции «Информационные технологии и системы — 2014», Н. Новгород: ИППИ РАН, 2014, C. 432. Битовое представление графа с использованием инструкции bsf (bit scan forward) CPU позволило получить среднее ускорение программы почти в 17 раз. Много разнообразных представлений графов используется для GPU (см. например).
Отдельная важная тема — это представление графов с помощью множеств:
adjMatrix : array [1..maxVertNum] of set of 1.. maxVertNum;
Действительно: понятие множество – основное для современной математики и было бы естественно столь же широко использовать его в программировании. В том числе и для графов. Однако здесь появляются трудности, так, например, в Delphi максимальная мощность множества (maxVertNum) сильно ограничена. Поэтому для больших графов понадобится специальная техника представления больших множеств. Кроме того, нет удобной эффективной процедуры выбора следующего за указанным элемента множества. Этот недостаток существует со времен Виртовского Паскаля, кажется, только в безнадежно устаревшем Pascal 8000 для OS 360/370 было сделано расширение – оператор цикла forall:
forall i in aSet doЭтот оператор позволял заменить стандартную громоздкую конструкцию перебора элементов множества:
for i:=minI to maxI do
if i in aSet thenВ случае очень небольших множеств для выбора следующего элемента возможна табличная реализация, а для множеств большего размера – несложная ассемблерная процедура.