

SQL пробуждается и наносит ответный удар силам тьмы — NoSQL
С самого начала компьютерной эры человечество собирает экспоненциально растущие объемы данных, и вместе с этим растут требования к системам хранения, обработки и анализа данных. Из-за этого в последнее десятилетие разработчики ПО отказались от SQL как от устаревшей технологии, которая не могла масштабироваться вместе с растущими объемами данных — и в результате появились базы данных NoSQL: MapReduce и Bigtable, Cassandra, MongoDB и другие.
Однако сейчас SQL возрождается. Все основные поставщики облачных услуг предлагают популярные управляемые сервисы реляционных баз данных: Amazon RDS, Google Cloud SQL, база данных Azure для PostgreSQL (запущена буквально в этом году) и другие. Если верить компании Amazon, ее совместимая с PostgreSQL и MySQL база данных Aurora стала «самым быстрорастущим сервисом в истории AWS». Не теряют популярности и SQL-интерфейсы поверх платформ Hadoop и Spark. А в прошлом месяце поддержку SQL запустила и Kafka. Авторы статьи скромно признаются, что и сами разрабатывают новую базу данных временных рядов, которая полностью поддерживает SQL.
В этой статье мы попробуем разобраться, почему маятник качнулся назад в сторону SQL и чего ждать специалистам по разработке и анализу баз данных.
Переведено в Alconost
Часть 1. Новая надежда
Чтобы понять, почему SQL возвращается, давайте вернемся в самое начало и разберемся, почему эта технология вообще появилась.

Как и все хорошие истории, наша начинается в 70-е
Эта реляционная база данных родилась в подразделении IBM Research в начале 70-х гг. В то время языки запросов основывались на сложной математической логике и не менее сложной нотации. Два свежеиспеченных кандидата наук, Дональд Чемберлин и Раймонд Бойс, впечатлились реляционной моделью данных, но при этом увидели, что используемый язык запросов будет препятствовать ее распространению. Они решили разработать новый язык запросов, который, по их словам, будет «более удобным для пользователей, не прошедших курс математики или компьютерного программирования».

Языки запросов до SQL (пп. А, Б) в сравнении с SQL (источник)
Просто представьте себе: еще не было ни Интернета, ни персональных компьютеров, «Cи» только-только вышел в свет, а два молодых специалиста в области вычислительных систем уже поняли, что «успех компьютерной отрасли в большей степени зависит от развития категории пользователей, а не категории обученных компьютерных специалистов». Им нужен был язык запросов, который читается так же легко, как английский, но при этом дает возможность администрировать базы данных и работать с ними.
В результате появился SQL, впервые представленный миру в 1974 году, и в следующие несколько десятилетий он станет очень популярным. Поскольку в отрасли ПО обосновались реляционные базы данных (например, System R, Ingres, DB2, Oracle, SQL Server, PostgreSQL, MySQL и многие другие), SQL широко распространился как язык взаимодействия с БД и стал общепринятым в экосистеме, которая становилась все более конкурентной.
(К сожалению, Раймонду Бойсу не удалось увидеть успех SQL: он умер от аневризмы мозга через месяц после одного из первых докладов по SQL — в возрасте всего 26 лет; у него остались жена и маленькая дочь.)
Некоторое время казалось, что SQL выполнил свою задачу и все идет хорошо… Но тут появился Интернет.
Часть 2. NoSQL наносит ответный удар
Разрабатывая SQL, Чемберлин и Бойс не знали, что в Калифорнии работают над другим перспективным проектом, который впоследствии широко распространится и станет угрожать существованию SQL. Этот проект — ARPANET, дата его рождения — 29 октября 1969 г.

Создатели сети ARPANET (не все), которая в итоге превратилась в современный Интернет (источник)
Некоторое время SQL вел спокойное существование — пока в 1989 году еще один инженер не изобрел Всемирную паутину.

Физик, изобретший Интернет (источник)
Веб и Интернет росли и распространялись, как сорняк, бесчисленными способами меняя привычный мир, но у специалистов по базам данных появилась вполне конкретная головная боль: новые источники, генерирующие данные в гораздо больших объемах и намного быстрее, чем раньше.
С ростом сети Интернет разработчики ПО обнаружили, что реляционные базы данных не могут справиться с такой нагрузкой. Произошло возмущение в Силе, как будто миллионы баз данных вскрикнули от ужаса и так же внезапно умолкли, перегруженные.
Затем два новых интернет-гиганта совершили прорыв — разработали собственные распределенные нереляционные системы, предназначенные для решения проблемы с возрастающими объемами данных: MapReduce (публикация 2004 г.) и Bigtable (публикация 2006 г.) от компании Google и Dynamo (публикация 2007 г.) от компании Amazon. Упав на благодатную почву, опубликованные статьи дали хороший урожай нереляционных баз данных: Hadoop (на основе статьи по MapReduce, 2006 г.), Cassandra (авторы вдохновлялись статьями по Bigtable и Dynamo, 2008 г.), MongoDB (2009 г.) и др. Новые системы были написаны преимущественно с чистого листа, поэтому они тоже не использовали SQL, что привело к росту «движения NoSQL».
Творение компаний Google и Amazon распространилось, похоже, гораздо шире, чем предполагали сами авторы. И понятно, почему так случилось: NoSQL-системы были в новинку; они обещали масштабирование и мощь; казалось, что это — быстрый путь к успешной разработке. И тут начали вылезать проблемы.

Разработчик, поддавшийся искушению NoSQL. Не делайте так.
Вскоре разработчики обнаружили, что отсутствие SQL на самом деле существенно ограничивает. У каждой базы данных NoSQL был собственный уникальный язык запросов, а это означало следующее: нужно было изучать больше языков (и обучать своих коллег); подключать эти базы данных к приложениям было сложнее, что заставляло писать тонны неустойчивого связующего кода; отсутствие сторонней экосистемы — а значит, компаниям приходилось разрабатывать собственные инструменты для визуализации и работы с БД.
Языки NoSQL только появились, поэтому их нельзя было назвать полными и завершенными: в реляционных БД, к примеру, многие годы работали над добавлением в SQL необходимых функций (JOIN, например). Такая незрелость означала бо?льшую сложность на уровне приложения. Отсутствие операторов JOIN также приводило к денормализации, итогом чего было «раздувание» данных и недостаток гибкости.
Некоторые базы данных из лагеря NoSQL добавили собственные SQL-подобные языки запросов — например, CQL в БД Cassandra. И часто становилось только хуже: использование интерфейса, который почти совпадает с чем-то более распространенным, по факту требовало больше умственных усилий, ведь в этом случае заранее неизвестно, какие из знакомых функций поддерживаются, а какие — нет.

SQL-подобные языки запросов — это как «Праздничный спецвыпуск» для «Звездных войн». Избегайте подражания. (И ни в коем случае не смотрите «Праздничный спецвыпуск».)
Кое-кто из специалистов уже на раннем этапе видел проблемы в NoSQL (например, ДеВитт и Стоунбрейкер — в 2008 г.). С течением времени к ним присоединялось все больше разработчиков ПО, которые прочувствовали эти проблемы на собственном горьком опыте.
Часть 3. Возвращение SQL
Соблазнившись поначалу «темной стороной», разработчики ПО вскоре узрели свет и понемногу начали возвращаться к SQL.
Сначала поверх платформ Hadoop и (чуть позже) Spark появились SQL-интерфейсы, благодаря чему в отрасли под «NoSQL» начали понимать «не только SQL» (хорошая попытка, ага).
Затем появились NewSQL — «новые SQL», масштабируемые базы данных с полной поддержкой SQL. Одной из первых масштабируемых БД с оперативной обработкой транзакций (OLTP) стала H-Store (публикация 2008 г.) Массачусетского технологического института и Брауновского университета. И снова не обошлось без разработок Google: своей первой статьей про Spanner (публикация 2012 г., среди авторов есть и создатели MapReduce) компания возглавила движение в сторону георепликационных БД с SQL-интерфейсом, и за ней последовали другие пионеры — например, CockroachDB (2014 г.).
В это же время начало возрождаться сообщество PostgreSQL: появились важные улучшения, например, тип данных JSON (2012 г.), а также винегрет из новых функций — в версии PostgreSQL 10: улучшенная встроенная поддержка секционирования и репликации, поддержка полнотекстового поиска для JSON и многое другое (вышла в октябре этого года). Другие разработчики, например, CitusDB (2016 г.) и авторы этих строк (TimescaleDB, выпущена в этом году) нашли новые способы масштабирования PostgreSQL для специализированных рабочих нагрузок.

Дорога, по который мы шли, разрабатывая TimescaleDB, очень похожа на путь отрасли в целом. В ранних внутренних версиях TimescaleDB имела собственный SQL-подобный язык запросов «ioQL» — да, темная сторона соблазнила и нас: казалось, что собственный язык запросов — это огромное преимущество. Поначалу это не казалось сложным, но вскоре мы поняли, что работы на самом деле предстоит намного больше, чем мы ожидали: например, нужно было определиться с синтаксисом, разработать «соединители», обучить этому языку пользователей и т. д. А еще обнаружилось, что мы — в собственноручно разработанном языке! — постоянно ищем правильный синтаксис для запросов, которые можем спокойно выразить через SQL.
Таким образом, однажды мы поняли, что разрабатывать собственный язык запросов — бессмысленно. Это привело нас к переходу на SQL и оказалось одним из лучших сделанных нами технологических решений: нам открылся совершенно новый мир. Сегодня нашей БД нет еще и 5 месяцев, а пользователи уже могут применять ее в работе и сразу «из коробки» иметь множество замечательных возможностей: инструменты визуализации (Tableau), соединители для популярных ORM, множество инструментов и вариантов резервного копирования, руководства и подсказки по синтаксису и т. д.
Не обязательно верить на слово нам — давайте посмотрим, что делает Google.

Более десятка лет компания Google находится, без сомнений, на переднем крае разработок в области разработки баз данных и соответствующей инфраструктуры. Поэтому следует уделять пристальное внимание тому, что они делают.
Взглянув на вторую крупную публикацию Google по БД Spanner, которая вышла совсем недавно (Spanner: Becoming a SQL System — «Spanner становится SQL-системой», май 2017 г.), вы обнаружите, что она подтверждает выводы, к которым мы пришли самостоятельно.
К примеру, инженеры Google начал надстраивать свою систему над Bigtable, но обнаружили, что отсутствие SQL создает сложности:
«Эти системы давали некоторое преимущество как базы данных, однако им не хватало многих традиционных функций БД, на которые часто полагаются разработчики приложений. Ключевой пример — отсутствие продуманного языка запросов, из-за чего разработчикам приложений для обработки и агрегирования данных приходилось писать сложный код. В итоге мы решили превратить Spanner в полнофункциональную SQL-систему, в которой выполнение запросов тесно связано с другими архитектурными особенностями БД (например, строгая согласованность и глобальная репликация)».
Далее в статье они подробнее обосновывают переход от NoSQL к SQL:
«У исходного API-интерфейса базы данных Spanner были методы NoSQL для точечного поиска и поиска по диапазонам отдельных и перемежающихся (англ. «interleaved») таблиц. Методы NoSQL упрощали запуск системы и по-прежнему удобны в простых задачах поиска, однако у SQL есть значительные преимущества при записи более сложных шаблонов доступа к данным и вычислениях на данных».
В статье также рассказывается, что переход на SQL не остановился на проекте Spanner, а по сути распространился на остальные технологии компании, где сегодня общий диалект SQL используется в нескольких системах:
«SQL-ядро БД Spanner использует «стандартный SQL» совместно с несколькими другими системами Google, в число которых входят и внутренние (среди них — F1 и Dremel), и внешние системы (например, BigQuery)…
Для пользователей внутри компании такой подход снижает барьер при работе с несколькими системами. Разработчик или специалист по анализу данных, который пишет SQL-запросы в Spanner, может использовать свои навыки в системе Dremel, не беспокоясь о тонкостях синтаксиса, обработке NULL и т. д.».
Успех такого подхода говорит сам за себя. Сегодня Spanner является платформой для основных систем Google, в числе которых AdWords и Google Play, и при этом «потенциальные клиенты облачных платформ в подавляющем большинстве заинтересованы в использовании SQL».
Весьма примечательно, что компания Google, которая помогла родиться движению NoSQL, сегодня возвращается в лоно SQL. (Поэтому кое-кто задался вопросом: «Разработчики Google сбили отрасль «больших данных» с истинного пути на 10 лет?»)
Будущее отрасли обработки данных: SQL как узкое место
В компьютерных сетях существует такое понятие, как «узкое место».
Эта идея возникла для решения главной задачи, которую можно сформулировать следующим образом. Возьмем какое-либо сетевое устройство и представим себе своеобразный «пирог» из слоев оборудования снизу и слоев программного обеспечения сверху. Сетевые устройства могут быть самыми разными; так же бывает и множество различных приложений и ПО. Задача состоит в том, чтобы ПО имело возможность подключаться к сети, какое бы оборудование не использовалось; а сетевое оборудование должно знать, как обрабатывать запросы сети, независимо от ПО.
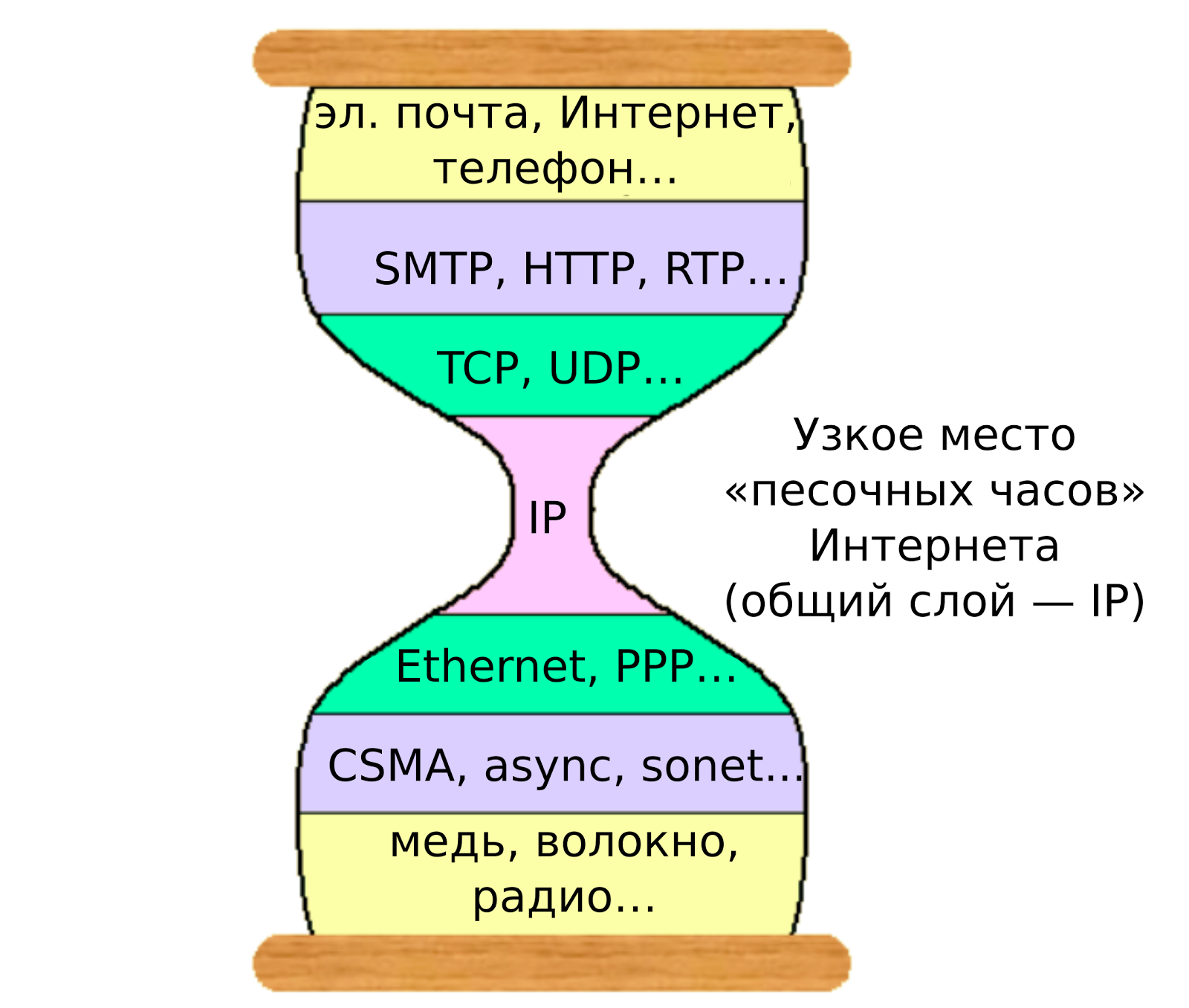
«Узкое место» сетевых технологий (источник)
В сетях узкое место — протокол IP: он выступает в качестве общего интерфейса между сетевыми протоколами низкого уровня, предназначенными для локальной сети, и прикладными и транспортными протоколами высокого уровня. (Вот одно неплохое разъяснение.) И, если упрощать, этот интерфейс стал общепринятым для компьютерных систем: он позволяет объединять сети и обмениваться данными между устройствами. И эта «сеть сетей» превратилась в многогранный, полный различной информации Интернет, каким мы его знаем сегодня.
Авторы этой статьи полагают, что SQL стал узким местом в анализе данных.
Мы живем в эпоху, когда данные становятся «самым ценным ресурсом в мире» (The Economist, май 2017 г.). В результате мы имели удовольствие наблюдать «кембрийский взрыв» специализированных БД (OLAP, базы данных временных рядов, БД для документов, графов и т. д.), инструментов обработки данных (Hadoop, Spark, Flink), шин передачи данных (Kafka, RabbitMQ) и т. д. Появилось и большое число приложений, которые работают на такой инфраструктуре данных, будь то сторонние инструменты визуализации (Tableau, Grafana, PowerBI, Superset), веб-фреймворки (Rails, Django) или специально разработанные приложения, использующие БД.
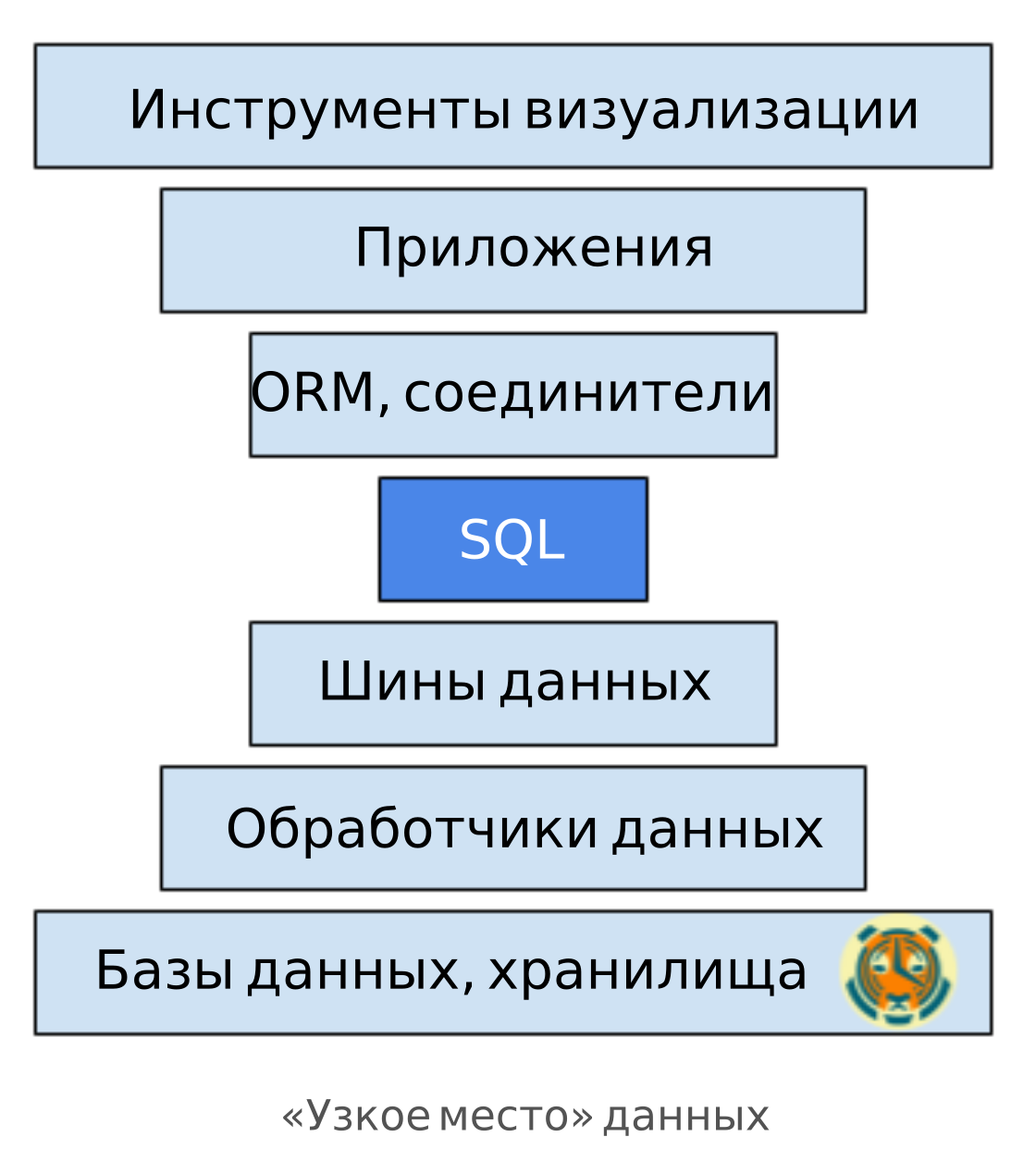
Как и в случае компьютерных сетей, у нас есть сложный «пирог» с инфраструктурой в самом низу и приложениями вверху. Как правило, чтобы этот пирог работал, нам приходится писать много связующего кода. Но такой код ненадежен: его нужно старательно поддерживать.
Необходим общий интерфейс, который позволит частям этого пирога друг с другом взаимодействовать. Лучше всего — что-то, что уже является стандартом в отрасли. Что-то, что позволит менять местами различные слои с минимальными усилиями.
И здесь как раз самое место для SQL: как и IP, SQL — это общий интерфейс.
Но SQL все же универсальнее протокола IP: данные приходится анализировать и людям, а запросы на языке SQL, как и было задумано, могут быть прочитаны человеком.
Безупречен ли SQL? Нет. Но именно этот язык знаком большинству специалистов по базам данных. Конечно, где-то уже ведутся работы над интерфейсом, в большей степени ориентированным на естественный язык, но к чему будут подключаться такие системы? К SQL.
Таким образом, на самой вершине пирога есть еще один слой, и этот слой — мы.
SQL возвращается
SQL возвращается — и главная причина этого не в том, что писать связующий код для подключения NoSQL-инструментов надоедает. И не в том, что обучать специалистов множеству новых языков — это сложно. И не в том, что стандарты должны быть продуманными.
Главная причина в том, что наш мир полон данных: они окружают нас, связывают нас. Когда-то мы для их обработки полагались на собственные органы чувств и нервную систему. Теперь же и наши аппаратные системы и ПО становятся достаточно умными, чтобы помогать нам. Мы хотим лучше понимать окружающий мир, и для этого собираем все больше и больше данных — поэтому сложность систем хранения, обработки, анализа и визуализации этих данных будет только расти.

Мастер обработки данных Йода
У нас есть выбор: жить в мире хрупких систем и миллионов интерфейсов — или вернуться к SQL и восстановить нарушенное равновесие Силы.
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 68 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
Подробнее: https://alconost.com
Комментарии (89)

wert_lex
18.10.2017 12:50Тот редкий момент, когда пропустив половину истории получается не укорочённая версия, а совсем другая история и другие выводы.
Особенно доставило, что про джойны(которые в случае острой необходимости довольно прямо лепятся поверх любого kv-хранилища) есть, а про распределенные транзакции, в которые все реляционки очень бодро упираются — нет.
Кстати, и мое ощущение от обратного движения в сторону реляционных бд вовсе не в том, что они прям сильно лучше стали, а в том, что хайпа про «моему уютному бложику не прожить без шардирования и репликации» поубавилось. Ну и виртуализация стоит теперь дешевле чашки кофе и расти вертикально теперь сильно проще и дешевле.
algotrader2013
18.10.2017 20:38А почему вдруг стало проще расти вертикально? Тактовая частота не растет уже лет 10 (еще и падать начала у многоядерных E5 к примеру, из годам в год), системы с больше, чем четырьмя сокетами стоят космических денег (правда, может intel scalable family исправит ситуацию, хз). С облаками так вообще, надо уметь горизонтально масштабировать.
Из реальной практики, была задача год назад, где надо хорошую однопоточную производительность на серверном железе обеспечить. Взяли e5-2643v4 (3.4 GHz частота, максимум, что есть на рынке). На домашних дешевых процессорах куда веселее цифры, увы.wert_lex
18.10.2017 23:41Потому что инстанс с терабайтом озу стоит семь баксов в час?
Есть ощущение, что это очень сильно уменьшает потребность в горизонтальном масштабировании.algotrader2013
19.10.2017 00:15Да, посмотрел, есть такое. Заодно приятно удивлен, что в облаке можно арендовать систему с 4 * E7-8880V3, не знал.

maxru
19.10.2017 11:34А зачем вы упираетесь в тактовую частоту?
Я вот сравнивал core i7-2600 6-летней давности и порезанный core i5-2.0 из макбука — они по производительности на ядро идут нога-в-ногу уже (отличаясь по тестам ровно в два раза по multi-core, что соответствует разнице в количестве ядер). При этом i5 в 10 (десять!) раз энергоэффективнее.

yashanet
18.10.2017 13:01-1подключать NoSql базы данных к приложениям было сложнее, что заставляло писать тонны неустойчивого связующего кода;
— Java + MongoDb = просто добавить три строки кода(депенденси), все работает и устойчивоmaxru
19.10.2017 11:40Это наверное потому, что связующий код уже написали за вас.

saboteur_kiev
19.10.2017 14:03+1Вы хотите предложить всем писать собственный связующий код с sql базами?

fediq
18.10.2017 13:04"Narrow waist" не надо переводить как "узкое место". "Узкое место" в техническом сленге носит ярко выраженный негативный оттенок, ближайший аналог в английском это "bottleneck". Узкое место — это плохо, его надо или ликвидировать, или обойти.
Автор же имел ввиду скорее позитивное явление, что IP выступает как общее связующее звено для разнообразнейших транспортно-прикладных протоколов и способов организации передачи данных. Это просто закономерный исторический факт, как и то, что все программисты говорят друг с другом на английском.
fediq
18.10.2017 13:08Забавно, что как сетевики пытаются съехать с IPv4 на IPv6, так и программисты тяготеют к созданию локальных коммьюнити. Выглядит так, будто "narrow waist" это вынужденная мера, от которой при необходимости попытаются избавиться.
Надо ли адаптировать SQL как "narrow waist" в данных, когда там и так справляются многообразием технологий и языков? Получается, вопрос весьма дискуссионный.

optimizer
18.10.2017 15:11нас учили, что есть три модели данных: иерархические, сетевые (более гибкие), и реляционные (более удобные и которые вытеснили остальные). И насколько я понимаю, то что сейчас называется документоориентированными системами это и есть иерархические системы представления данных (MongoDB, CouchDB..), т.е хорошо забытое старое

Yo1
18.10.2017 16:41но все такие есть еще один подход, который правда базой не назвать. из парадигмы бигдата. k-v хранилище с табу на update/delete. в value храниться сложный объект (например avro-parquet). учитывая, что это все заморочено ради параллельной обработки, то все таки это нечто новое и мало похожее на все, что было ранее.

musicriffstudio
18.10.2017 17:24+1это и есть иерархическая бд
Yo1
18.10.2017 18:47ничего общего. иерахические это ничем не примечательны. одна нода, нафигация по иерархии, update/delete, блокировки, транзакции и прочее. то о чем я говорю из другого мира. тысячи нод и просто файлики, никаких транзакций, update/delete, блокировок и прочего. в файликах просто ключь-значение. это и не субд даже, это подход.
musicriffstudio
18.10.2017 19:03+2если данные хранятся в иерархии то это и есть иерархическая бд. Как не называй по-красивей.
Yo1
18.10.2017 19:49во первых k-v хранилище не иерархия, во вторых если я натолкаю в dbf таблички ссылку на парент, фокспро не превратиться в иерархическую субд.
там все реально по другому. суть иерархической субд — нафигация по индексу, суть того о чем я говорю противоположна. там зачастую читают абсолютно все данные начала времен.musicriffstudio
18.10.2017 21:02+1этому «по-другому» тридцать лет в обед.
Yo1
18.10.2017 21:4630 лет назад никому в голову не приходило читать параллельно с тысячи нод принципиально все данные, абсолютно все субд тогда доставали данные по индексу и соревновались методиках сокращения кол-ва чтений. что иерархические, что рсубд.
musicriffstudio
18.10.2017 21:59да они и сейчас так работают.
Yo1
18.10.2017 22:08да, они работают ровно так же как и 30 лет назад. что рсубд, что нафигационные. поэтому подход читать в параллель все без разбору, не разбираясь нужно или не нужно выглядит чем-то новым. 30 лет назад о таком никто и помыслить не мог.
musicriffstudio
19.10.2017 08:02+1иерархические бд (т.е. то что сейчас называют ноСКЛ) появились раньше реляцоннных. И все принципы работы остались теми же что и 30-40 лет назад.
Никакого волшебного колдунства нет.

Igelko
19.10.2017 22:23не совсем так. Каноничный пример иерархической БД — это файловая система.
В ней можно легко создать папку для пользователя и в неё положить все его просмотренные сайты.
Документные СУБД всё же отдельный класс с ограничением на размер документа. т.е. нельзя будет всю историю одного человека запихать в один документ.
brickerino
18.10.2017 17:58-4Вам нужно отзеркалить КДПВ. Обычно все хорошие бегут направо, все плохие налево. На вашей картинке Рэй готовится погибнуть от меча товарища с ушами.
Scf
18.10.2017 20:29+1После длительного увлечения NoSQL, я начинаю задумываться о том же. Колоночные NoSQL со всей их спецификой (гиганские объемы данных, данные очень регулярны, потери отдельных строк не важны) имеют права на жизнь, но для всего остального проще использовать SQL
- современные SQL базы не медленны — постгрес на слабой машине тянет тысячи запросов по денормализованной таблице в секунду
- с большим кол-вом данных проблем тоже нет
- в 21 веке не нужно уродовать структуру и индексы для аналитических запросов — данные просто экспортируются в любимую колоночную СУБД или индексатор
- шардинг средствами современных технологий легко реализуется на стороне клиента
- с availability сложнее, но значительно проще, чем раньше
И помимо этого, SQL базы дают транзакции, мощный язык запросов, качественные атомарные бэкапы, проверенный временем мониторинг, аудит и средства восстановления после аварий.
voe
18.10.2017 22:22а как добавление sql иниерфейса связано со смертью nosql хранилищь? то что им добавили sql интерфейс их не сделало реляционными базами данными
johnnymmc
18.10.2017 23:02Как минимум понятие NoSQL теряет смысл. На сколько я понимаю в принципе, грубо говоря (в каждой конкретной реализации свои нюансы, конечно) NoSQL-база — это база со скромным индексированием (индексируется только первичный ключ) и без SQL в качестве языка запросов. SQL в NoSQL добавили (т.е. уже оксюморон), индексированием в «обычных» СУБД можно управлять достаточно гибко, индексировать и нормализовывать всё никто не заставляет, возможность оперировать данными, храняшимися в форматах XML и JSON уже давно можно. Осталось добавить в стандартную поставку классических СУБД HTTP-интерфейсы и всё, со стороны приложения никакой принципиально разницы уже нет, разница останется только на уровне реализации конкретных хранилищь.
fediq
19.10.2017 00:04Для SQL РСУБД само собой подразумевается наличие ACID. С этим у NoSQL все очень плохо, поддержку ACID заявляют только мифический Google Spanner, глюкавый OrientDB и ныне почивший FoundationDB. Языковая обертка совсем не спасает — SQL в NoSQL используют почти исключительно для OLAP.
В другую сторону, для NoSQL часто подразумевается почти линейная масштабируемость и shared-nothing. С этим у классических РСУБД все очень плохо — транзакционный движок это нерасширяемый SPOF, мастер-мастер репликация это безнадежно, универсальное шардирование не совместимо с контролем строгости внешних ключей и т.п.
johnnymmc
19.10.2017 00:27Для SQL РСУБД само собой подразумевается наличие ACID.
Спорное утверждение. В общем, конечно, как бы да, но строго говоря не обязательно, ACID — это всего лишь фича, которая может быть, а может отсутствовать. Сам, например, прекрасно живу с энджином Aria (улучшенный MyISAM) в некоторых bigdata (но не hiload) проектах с MariaDB — вполне себе классический SQL, но без ACID и шурует достаточно быстро по сравнению с InnoDB на больших таблицах.
А вообще ваши доводы, конечно, ясны, всё так, да.
wert_lex
19.10.2017 13:28На заре хайпа про NoSQL у этой аббревиатуры было еще одно значение — Not Only SQL. Что идеологически гораздо более правильно, но вот только про хорошие примеры SQL + что-то ещё в одном флаконе мне неизвестно.
Igelko
19.10.2017 22:29NoSQL-база — это база со скромным индексированием (индексируется только первичный ключ)
Для документных СУБД это неверно, можно навесить любые индексы, если это требуется.
McAaron
20.10.2017 18:09NoSQL — это отсутствие SQL. А что там индексируется или не индексируется, это вопрос отдельный. Никто не мешает создавать и поддерживать любые индексы. SQL — это просто язык запросов.
johnnymmc
18.10.2017 22:27Мне кажется «А. Версия в реляционной алгебре» выглядит в сто раз лучше, чем «В. Версия в Sequel (SQL)». Давно мечтаю о таком языке запросов, как в этой версии А. Ради такой лаконичности определённо стоит изучить несколько специальных значков и добавить их в раскладку клавиатуры (благо это в наше время очень легко). Особенно если учитывать, что в наше время «пользователи, не прошедшие курс математики или компьютерного программирования» запросы всё-равно не пишут, а работают исключительно через создаваемые для них программистами GUI.
johnnymmc
18.10.2017 22:43Блин, прямо восторг от варианта A, вот смотрю и прямо «кипятком ссу». Хочу-хочу. Можно такую нотацию к каким-то современным СУБД прикрутить как-то? И нет, я ни разу не математик.

proman1968
18.10.2017 22:54Так о чем же в итоге статья — о языке запросов SQL или о реляционной модели хранения данных, в которой этот язык применяется. Spanner, к примеру, не реляционка, но при этом использует SQL.
А мы вот, например в своей NoSql СУБД используем модифицированные XQuery и XUpdate, и очень довольны. Запросы проще и выразительней чем SQL на порядки. Пользователи легко осваивают язык за пару недель. Прикручивали SQL, но разработчики не приняли после XQuery, не стали развиваить.Igelko
19.10.2017 22:45Наверное, стоит разделить слой хранения данных и слой DML.
В Oracle, строго говоря, данные хранятся не в плоской таблице, а в дереве, но это не делает его NoSQL СУБД. Слой хранения может быть разным — может быть на одном узле как в MySQL, может быть на распределенном block storage, как в Aurora, может быть размазан по многим узлам, как в CockroachDB или Spanner. Значение имеет всё же интерфейс взаимодействия.
И реляционная модель ни слова не говорит про хранение — это логическая модель данных, не физическая, которая просто утверждает, мы можем оперировать с данными как с множествами кортежей, и можем пользоваться булевой алгеброй для задания предиката, применение которого вернет множество нужных элементов.
Запросы проще и выразительней чем SQL на порядки
модифицированный XQueryа можно пример, пожалуйста? Интересно стало.
Просто всегда думал, что XML — это не тот язык, который могут писать живые люди.

stalkerg
19.10.2017 10:48-1SQL увы часто слишком высокоуровневый и трудный для оптимизации язык.
Он никак не описывает взаимодействие с индексами или какой алгоритм джойна или выборки использовать. В общих случаях и небольших нагрузках всё может быть хорошо, но дальше начинаются танцы с бубном над оптимизатором. Да и для многих случаев разбор и оптимизация занимает больше времени чем сама выборка данных.
Ну и сам по себе SQL не очень знаком с транзакциями и изоляциями.Scf
19.10.2017 12:55Всё есть, пусть и специфичное для базы. Хинты, select for update, WITH ROWLOCK и т.п.
stalkerg
20.10.2017 02:29Я говорю про то что в стандарте SQL этого нету, и в такой БД как Postgres то же нету. Мы же сейчас про язык, а не про конкретные хаки вашей СУБД. Хаки я и сам знаю, только не легче от них от перехода одной бд к другой.
andreylartsev
19.10.2017 15:44+1Он так и задуман, чтобы переложить на автоматический оптимайзер всю сложность с оптимизацией по правильному доступу к данным. Иногда не работает — верно, и тогда сделать почти ничего нельзя. Но тогда нужно просто брать другой инструмент )
Igelko
19.10.2017 21:57Вот здесь я склонен немного не согласиться, потому что
или часто правильно написанный +0 при джойне в Firebird,
или грамотно подсунутый хинт индекса в MySQL,
или грамотно построенный индекс для MS SQL,
или грамотно переписанный запрос с использованием фишечек (оконные функции, CTE) в PostgreSQL,
или переписывание запроса на (о ужас :-) ) хранимую процедуру PL/SQL с простой линейной логикой (привет, Oracle),
способны исправить любую глупость оптимизатора.
И это всё тоже остаётся в рамках SQL (за исключениме хранимых процедур разве что).
Проблема в другом — эти решения применимы только для конкретного движка СУБД, т.е. имеем примерно такую же фигню как с NoSQL — для эффективной работы с каждым хранилищем данных приходится как-то по-особенному приседать — писать запросы, продумывать структуру таблиц, что развеивает миф о возможности существования всемогущего, одинакового для всех БД, языке.
stalkerg
20.10.2017 02:42Ну вот хотелось бы стандартизированного инструмента (языка) для существующих СУБД.
Ведь сделали же webassembly для веба и SPIRV для шейдеров, почему бы не сделать SQL Asembler? Некое промежуточное представление, которое было бы немного ниже текущего SQL но всё ещё сохраняло бы переносимость.
musicriffstudio
19.10.2017 18:03Ну и сам по себе SQL не очень знаком с транзакциями и изоляциями.
Ужас какой. Абсолютное непонимание предмета обсуждения.
Хинт
— важные данные, например зарплату всех здесь отметившихся, считают в реляционных бд у всех
— всякую ерунду типа постов о котиках в фейсбуке могут хранить в других субд
да и сам фейсбук, кстати, важные для него данные (связи между пользователями чтоб показывать им рекламу и зарабатывать) хранит в переделанной МайСКЛstalkerg
20.10.2017 02:17Ужас какой. Абсолютное непонимание предмета обсуждения.
Давайте не будем об этом зарание :)
Я прекрасно понимаю о чём речь. Правда корень нашего с вами недопонимания в том, что я говорю про стандарт SQL в котором хинтов нету, ну и к примеру Postgres где их то же принципиально нету.
Igelko
19.10.2017 22:02Прошу меня извинить, но уровни изоляции — это то, что выбито гвоздями в SQL-92. Это стандарт.
Его в том или ином виде полностью поддерживают почти все движки. Да, немножко со своими странностями, но тем не менее. Если СУБД не поддерживает уровни изоляции и транзакции, то это какое-то недоразумение, а не полноценная СУБД. SQLite в расчет не берем — это встраиваемая записная книжка с SQL-синтаксисом.stalkerg
20.10.2017 02:27Я скорее про реализацию, толку от языка, который если хочется чего то предсказуемого по скорости, приходится писать под каждую СУБД свой запросс?
Даже тут https://ru.wikipedia.org/wiki/%D0%A3%D1%80%D0%BE%D0%B2%D0%B5%D0%BD%D1%8C_%D0%B8%D0%B7%D0%BE%D0%BB%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8_%D1%82%D1%80%D0%B0%D0%BD%D0%B7%D0%B0%D0%BA%D1%86%D0%B8%D0%B9 немного написанно про то что в мало каких СУБД это уровни реализованны строго по стандарту…
Есть же вроде устойчивое мнение что Read committed в Postgres это Repeatable read в Oracle.
И вы зря про SQLite это очень мощная СУБД и наглядный пример как можно использовать язык SQL (особенно их "компидятор" запроссов). И по колличеству инсталяций + работающего софта это наверная самая популярная СУБД в мире.
Igelko
20.10.2017 14:50Конечно, посчитать все андроид-девайсы — будет самой популярной :-)
Я скорее к тому, что в SQLite нет как таковой необходимости иметь уровни изоляции — это по дизайну встраиваемая БД для локального применения в рамках одного процесса.
Там нет и хранимых процедур, и многопользовательского доступа по примерно тем же причинам. Это просто библиотека (не СУБД) с SQL-like синтаксисом. Очень полезная в хозяйстве, надо сказать. Отдельно хочется похвалить автора за его любовь к автотестам.stalkerg
22.10.2017 05:37Если я правильно помню, то хранимок нету и в MySQL/MariaDB и это никакого отношения к SQL не имеет. А так наверное да, но это всёравно применение SQL языка.
Igelko
22.10.2017 10:19в MySQL и MariaDB есть хранимые процедуры.
Кривые, косые, но есть. Тоже не от хорошей жизни они там появились =)
Я имел ввиду, что SQLite нельзя назвать "взрослой" клиент-серверной СУБД, которая умеет работать с большим объёмом данных и большим числом одновременных клиентов.

caballero
19.10.2017 13:01+2По моему NoSQL просто занял ту нишу для которой он предназначен. Какое то время это был модный тренд, как часто бывает в ИТ. Просто потому что разрабы постоянно ищут какую то серебряную пулю, которая одним махом решит проблемы разработки.
Накинулись на NoSQL но чуда, как обычно, не произошло и все стало на свои места.
stalkerg
20.10.2017 02:48Собственно если так подумать, то главная претензия к самому языку это отсуствие вменяемого синтаксиса (точно не как в новом стандарте) для доступа к сложным иерархиям внутри одного поля (документа). Если бы это было, то и Эластиксёрч с Монгой можно было бы перевести на этот язык.
ЗЫ хотя если так подумать, к примеру вложенные группировки в Эластике явно выглядят приятнее чем нагромождение которое будет в SQL.caballero
20.10.2017 10:40Думаю дело не в языке а в реляционных отношениях между данными. Природа данным мало изменилась с 70х годов. изменилось только количество. Просто добавилась ниша для nosql в виде огромного количества мелких не связанных глубокими реляциями (и не требующих, соответственно, витиеватых выборок) данных.
Кеширование, сообщения в соцсетях и месенжерах и т.д. Собственно и есть ниша NoSQl.

potan
19.10.2017 13:51SQL (и SPARQL) позволяют сформировать очень сложные запросы, которые долго выполняются и тормозят другие запросы. Если ограничиться простыми запросами, то SQL по производительности не особо уступает NoSQL решениям. Основная проблема — заставить себя (и коллег) ограничиться простыми запросами.
caballero
20.10.2017 10:49+1это типа заставить всех вместо компьютеров пользоваться калькуляторами. Если данные(бизнес-сущности) по своей природе сложные и находятся объективно в реляционных отношениях а заказчик требует мудрёный репорт, то то никуда не денешься. Разве что, в разумных пределах, денормализовать данные заплатив за это увеличением их объема.
geminirff
19.10.2017 15:16Ну, а все-таки, что теперь будет? Обновленный и расширенный новый стандарт SQL, с поддержкой агрегатов (тип CUBE), и что-то для работы иерархиями, или шире … с графами? Может какое-то обобщение с MDX, или GraphQL?
SQL остаётся хорошим для статической модели данных. Там же где данные ненормализованные, либо очевидно, что модель будет и должна меняться, он излишне строгий.
McAaron
19.10.2017 15:16Любой SQL всегда работает поверх набора внутренних методов доступа к данным — поверх не-SQL. При этом слой SQL потребляет огромное количество вычислительных ресурсов, как паямти, так и процессора. В документации самого оракла говорится, что использование SQL безусловно оправдано только в случае динамической базы данных — когда схема (структура кортежей и отношений) непостоянна и меняется в процессе работы приложения. В случае же статической схемы данных в каждом конкретном случае нужно рассматривать применение SQL только в том случае, если требуется быстро выпустить приложение, невзирая при этом на производительность. По их словам производительность не-SQL решений (NoSQL, BDB) обычно в десять и более раз выше, чем SQL, при этом затраты на разработку вырастают всего лишь в разы.
Так что не-SQL пока ничто не грозит, как никогда и не грозило.kalininmr
19.10.2017 22:44+1однако тот же postgresql кое где даже немножко быстрее большинкства nosql решений.
например в класическом доступе по индексу.stalkerg
20.10.2017 02:53Как минимум они делают разные вещи внутри этого доступа. Собственно prepare statement не от хорошей жизни появился так что SQL имеет существенный оверхед особенно если в нём перечисленно много "таблиц".
kalininmr
20.10.2017 04:38в nosql со «много таблиц» не очень гладко, да и с хитрыми индексами.
stalkerg
20.10.2017 04:53Но это не результат отказа от SQL, а скорее ориентированность на их ниши.
На самом деле встроить SQL парсер и написать к нему оптимизатор это не такое простое занятие, куда проще (не факт что лучше) использовать JSON который повторяет ваши внутрении абстракции.kalininmr
21.10.2017 11:42если сравнивать такиеже элементарные запросы какие возможны в nosql — то парсер моментально отоабатывает.
а вот оптимизатор и планировщик могут подзадуматся.
поэтому подготовленые запросы есть и хранимые процедуры.
и опять же план запроса в большинстве sql систем кешируется
McAaron
20.10.2017 18:17Ну да, всегда есть тормознутые тривиальные решения.
Тем неменее, большинство NoSQL на порядок (SiC!!!) быстрее, чем SQL при решении 90% наиболее распространенных задач. Если быть точнее, то если в приложении нет оператора altertable, имеет смысл подумать — а какого тут делает SQL? Реально вопрос только в затратах на разработку — на SQL дешевле и к программисту требования на уровне плинтуса.musicriffstudio
20.10.2017 21:34и к программисту требования на уровне плинтуса
— скорей наоборот, сам ноСКЛ (т.е. возврат к примитивным хранилищам доскльных времён) появился только потому что реляционная алгебра слишком сложна в освоенииMcAaron
21.10.2017 09:16Не только лишь все могут реляционную алгебру? Хе-хе…
Движок любой базы данных работает не с реляционной алгеброй, а с аддами-делитами, гетами-путами, установкой в позицию ключа и некстами-превисами (т.н. курсоры). Это элементарные операции над базами данных «ключ-значение». А как вы эти пары в своем кластере устроите, и какие модели хранения этих пар выберете, зависит либо напрямую от программиста, либо от того слоя, который лежит между уровнем SQL и движком. Пока этот самый уровень проигрывает по производительности результата живому программисту в конкретных приложениях не просто вчистую, а с кратным отрывом. И сближения не видно.musicriffstudio
21.10.2017 10:22Не только лишь все могут реляционную алгебру?
да
Оракл и прочие потратили миллионы индусочасов на то чтобы дать программисту возможность использовать только реляционную алгебру и не думать о блоках чтения и пр.
Может ли получиться так что «этот самый уровень проигрывает по производительности результата живому программисту в конкретных приложениях не просто вчистую, а с кратным отрывом»?
Советую прочитать
habrahabr.ru/company/mailru/blog/266811
и подумать (правильный ответ: «ни малейшего шанса»)
McAaron
21.10.2017 09:31Реляционная модель — это всего лишь модель поверх кластера баз данных «ключ-значение».
Сравнение [SQL vs. non-SQL] это как бы аналог сравнения [C vs. assembler] с той разницей, что слой автоматической трансляции [C --> assembler] реализован, не побоюсь этого слова, почти совершенным образом, а слой автоматической трансляции [SQL --> non-SQL] — как иногда говорят, представляет собой «наивную реализацию».
potan
20.10.2017 12:36При большом объеме данных трансформация запроса в план низкоуровневых операций занимает принебрежимо мало времени. Все равно все упрется в обработку данных или ввод/вывод.
Если объем небольшой, а запросов много, проблема появляется. Но это не самый типичный случай.
Igelko
19.10.2017 23:16У меня к SQL есть пара претензий.
Сложность отладки и тестирования. Каждое условие в запросе — это по сути if, который создает минимум две ветки, которые нужно протестировать.
Т.е. даже на честную отладку самого обычного запроса нужно проверить минимум 2^(n+k) инвариантов, где n — это количество сравнений полей, а k — это количество входных параметров запроса.
Поведение с NULL. Мне конечно все говорят, что это норма, такова жизнь и вотэтовсё, но чёрт подери, это ещё сильнее ухудшает (1), делая мне 3^(n+k), и при этом всё начинает очень весело стрелять в рантайме, вываливая этот NULL, то туда, то сюда, когда кто-то внезапно сменит
inner joinнаleft join, просто потому что так стало надо.
- Протекающие абстракции слоя хранения и оптимизатора запросов.
Знание SQL не освобождает от ответственности написания эффективных запросов. В каждом движке есть свои заморочки, как данные эффективно запрашивать и для того, чтобы работать действительно грамотно, надо точить запрос под каждый движок отдельно.
На рынке работодателю не слишком интересно знаешь ты SQL или нет, куда важнее, работал ли ты с конкретной СУБД. Неофиты в каком-то движке имеют привычку писать совершенно по-другому и поливать тоннами ругани СУБД, когда она ведёт себя неожиданным образом, и это будет продолжаться, пока человек не разберётся, как СУБД данные хранит и как работают планировщик/оптимизатор/исполнитель запроса. Увы, не существует единого стандарта SQL, который будет абсолютно одинаково эффективно работать на всех рантаймах. И никогда не будет существовать, потому что есть требования обратной совместимости. // никогда не прощу ораклу, что у них NULL и пустая строка — это одно и тоже.
В случае, когда я делаю закат солнца вручную (пишу джойны, аггрегации, подзапросы прямо в коде приложения, делаю руками выборку, вотэтовсё), я могу это легко контролировать — сделать декомпозицию на несколько простых, часто чистых, функций, каждую из которых обложить тестами и комбинировать уже готовые абстрагированные блоки, контролируя таким образом сложность, как алгоритмическую, так и тестирования.
// опустим сложный вопрос эффективности работы со слоем хранения.
В случае с SQL запросы быстро разрастаются сами собой из-за кажущейся простоты и необходимости быстро напилить фичу. Они выглядят компактно и создаётся иллюзия, что ты точно знаешь, как он работает и что вернёт. На самом деле это не так.Yo1
20.10.2017 00:01В случае, когда я делаю закат солнца вручную (пишу джойны, аггрегации, подзапросы прямо в коде приложения, делаю руками выборку, вотэтовсё), я могу это легко контролировать — сделать декомпозицию на несколько простых, часто чистых, функций, каждую из которых обложить тестами и комбинировать уже готовые абстрагированные блоки, контролируя таким образом сложность, как алгоритмическую, так и тестирования.
в 80х годах прошлого века от этого подхода отказались в пользу cost based optimizator. это то же самое, что в сезон отпусков проложить маршрут через центр города, а потом весь год терять 3 часа в пробках, которые более сообразительная молодежь объезжает, потому что маршрут выбирает в зависимости от дорожных условий.
самое главное преимущество SQL — он не указывает как достать данные. это декларативный язык.stalkerg
20.10.2017 02:39cost based optimizator
После чего результат стал крайне нестабильным т.к. зависит от собранной статистики и её качества. А что происходит если вам нужно много Join это вообще кромешный адъ. Собственно коррелацию между таблицами вообще может быть не получится эффективно сделать так как это слишком много доп. информации хранить надо.
Igelko
20.10.2017 15:04Потом пришли разработчики и потребовали хранимых процедур и писали по сути императивный код, чтобы БД периодически не выдавала "Ну у вас и запросы" и не зависала наглухо.
Потом пришёл веб, и юзеров стало так много, что один сервер БД стал загибаться и логика поехала в приложение, где разработчики по сути закатывали солнце вручную.
Потом пришли разработчики и потребовали ORM, потому что SQL — это слишком сложно и продолжили закатывать солнце вручную на толстых аппликейшн серверах, используя БД просто как тупую хранилку данных.
А потом дырявая абстракция cost based оптимизатора начала протекать и через ORM.
А потом...
SQL не очень хорош, и я бы его ставил в ряд с каким-нибудь JS по причинам появления багов, но лучше пока не сделали. Так и живём.
Yo1
21.10.2017 13:06видимо вы в весьма глухом месте живете, у нас вот SQL абстракция никуда не потекла, а лишь захватила еще и наши хадупы, гнусно посмеявшись на бесплодными попытками чем либо заменить. spark на хадупах — все тот же sql, все тот же cost based оптимизатор. ничего лучше так никто и не предложил
Igelko
21.10.2017 20:15На нынешнем проекте у меня оракл и хранимые процедуры, потому что нельзя просто так и взять и правильно написать запрос, который сделает то, что надо и как надо. Если писать то, что нам надо чистыми запросами, оптимизатор встаёт в позу и начинает выдавать совершенно наркоманские планы. И статистика тут ни при чём. А много простых запросов — это лишние раундтрипы между сервером приложений и БД, лишние заморочки с транзакционностью и код в аппсервере начинает выглядеть ужасно.
SQL побеждает, потому что немалое значение имеет также скорость реализации.
Отчасти потому взлетели далеко не лучшие языки программирования вроде PHP и JS — на них просто накидать поделку, которая будет хоть как-то работать.
SQL-запрос, делающий нужное, в среднем легко накидать. Непросто его поддерживать, изменять и сделать эффективным.
И в спарке побеждает SQL вовсе не потому, что нельзя оптимизировать запросы лучше автомата, просто так намного быстрее написать хоть какой-то работающий код. А руками оптимизировать, если автоматика с ума сходить начинает, можно и потом, когда деньги будут.
Так что да, автоматические планировщики и оптимизаторы лучше. Но не потому что они работают быстрее, чем написанный и отлаженный вручную код, а потому что они сильно ускоряют начальную разработку.
Yo1
21.10.2017 21:21+1побеждает потому, что практика показала то что все альтернативы в итоге сильно проигрывают. при разработке оптимальным ожидается одно, при запуске оказывается оптимально данные достать по другому, через какое-то время даные распухают не равномерно и оптимум уже третий. переписывая в третий раз, люди начинуют понимать силу деклативного языка и начинают от вендоров требовать прикрутить SQL. к хадупам уже прикрутили, in memory grids аля apache ignite тоже по сути SQL уже прикручен.
musicriffstudio
21.10.2017 22:21На нынешнем проекте у меня оракл и хранимые процедуры, потому что нельзя просто так и взять и правильно написать запрос, который сделает то, что надо и как надо
я бы посоветовал вашему начальству нанять нормального ораклиста.Igelko
22.10.2017 10:39Не было бы нормальных людей, шарящих в СУБД, мы бы за хранимые процедуры даже не стали бы браться. Писали бы всё на аппсервере. Другое дело, что с большинство ораклом раньше не работали.
Есть у нас хороший ораклист. Целый один. Но скорость развития проекта просто не та, при которой он бы успевал что-то сделать.
И ещё живых ораклистов за вменяемые деньги найти — это огромная проблема.
И нет, нельзя написать запрос так, чтобы он был одновременно читабельным, поддерживаемым и при этом всегда делал что надо, в условиях, когда нужно регулярно менять что-то в схеме, добавлять/убирать возврат каких-то полей, когда поля скачут из not null в nullable итд.
Обычные запросы в таких условиях очень быстро превращается в убористую кашу с десятком джойнов и вложенных запросов, которая завешивает и оптимизатор, и ораклиста.
Тупые хранимые процедуры с последовательной логикой работают просто чудесно на этом фоне. И никаких вопросов с транзакционностью.
McAaron
21.10.2017 09:51самое главное преимущество SQL — он не указывает как достать данные. это декларативный язык.
К сожалению, за это приходится платить производительностью приложения. Особенно это заметно, если на базе данных сидит много клиентов — универсальный сервер всегда проигрывает сугубо заточенному. Именно поэтому кобыла и сегодня живее всех живых.

andd3dfx
20.10.2017 08:27Спрячьте ваши анимашки под спойлеры — читать мешает

dedmagic
21.10.2017 11:36Спасают инструменты разработчика в браузере – статью можно читать только после удаления всего мельтешащего ))))

sumanai
21.10.2017 14:39Я спасаюсь при помощи дополнения Firefox Toggle animated GIFs, правда оно, как и многое другое хорошее и светлое, отвалится при обновлении на 57 версию.
andd3dfx
21.10.2017 22:16-1Конечно же я умею ими пользоваться, но стоит ли статья того, чтобы еще возиться с блокировкой анимашек для ее комфортного прочтения?

PaulMaly
20.10.2017 21:58Считаю, что главная проблема NoSQL, а лучше сказать НЕ реляционных документных БД, в том, что этот тип БД имеет узкую специализацию. Чтобы использовать различные типы БД по назначению достаточно внимательно вчитаться в их основную характеристику. Очевидно что реляционные БД лучше подходят для нормализованных данных со схемой и связями. Документные БД для документов, т.е. не нормализованных данных без связей и схемы. Графовые БД для графов и т.д.
Однако зачастую, в проект берут какую-нибудь MongoDB, потому что это стильно-модно-молодежно и начинают лабать коллекции со схемами и связами, с сложными выборками. Вот и получается что забивают гвозди микроскопом.
Duduka
Великолепный репортаж из параллельной вселенной: «баз до 70х не было, SQL и noSQL появились на голом месте, целая история суперкомпьютеров ориентированных на обработку баз данных и упор на централизацию знаний вышвырнули из реальности, истории с затыком IBM на естественные языки и COBOL не было, и кодасил к nosql никак не относится...» и как там во вселенной самопроизвольных вспышек и озарений?!
А у нас все иначе, озарений не было, был исторический процесс, войны моделей и стандартов, война инженерии с маркетингом, и окончательная победа маркетинга и виртуализации реальности.