

Внезапная лошадь из работы «Spatial Memory for Context Reasoning in Object Detection» (представлена на ICCV 2017)
У нас есть несколько новостей, но скучно писать просто о конкурсе, в котором можно выиграть камеру для дома или о вакансии нашей облачной команды. Поэтому начнем мы с информации, которая будет интересна всем (ок, почти всем – речь пойдет о видеоаналитике).
Недавно завершилась крупнейшая конференция по технологиям компьютерного зрения – International Conference on Computer Vision 2017. На ней команды ученых и представители исследовательских подразделений различных корпораций представили разработки по улучшению фото, генерации изображений по описанию, заглядыванию за угол с помощью анализа света, etc. Мы расскажем о нескольких интересных решениях, которые могут найти применение в области видеонаблюдения.
Фотографии качества «зеркалок» на мобильных устройствах

Матрицы камер видеонаблюдения и смартфонов совершенствуются год от года, но, кажется, никогда не догонят зеркальные фотоаппараты. И причина одна – физические ограничения мобильных устройств.
Исследователи из Швейцарского федерального технологического института в Цюрихе представили алгоритм, который преобразует изображение, полученное на камеру не самого высокого качество, грамотно «выправляя» детали и цвета. Алгоритм не может создать на снимке то, чего там нет, но он может помочь улучшить фотографии не только с помощью настройки яркости и контрастности.
Обработка фотографий происходит с использованием свероточной нейросети, которая улучшает как цветопередачу, так и резкость изображения. Сетка обучалась на объектах, которые были сфотографированы одновременно на камеру смартфона и на цифровой фотоаппарат. Понимая, какое качество является оптимальным для условного объекта, сетка стремится изменить параметры снимка так, чтобы максимально точно соответствовать «идеальному» образу.
Сложная функция восприятия ошибок изображения сочетает в себе данные о цвете, тональности и текстуре. Исследование показывает, что улучшенные изображения демонстрируют качество, сопоставимое с фотографиями, полученными с помощью зеркальных фотокамер, в то время как сам метод может применяться к любым типам цифровых камер.
Текущую версию работы алгоритмов улучшения качества изображения можно протестировать на сайте phancer.com – достаточно просто загрузить любой снимок.
Создание фотореалистичных изображений с нуля

Большая команда ученых – 7 человек на двух континентах из Ратгерского университета, Лихайского университета, Китайского университет Гонконга и исследовательского подразделения Baidu Research – предложила способ использования сеток для создания фотореалистичных изображений на основе текстовых описаний. Чем-то способ похож на работу настоящего художника, который создает картину на основе образов в своей голове – сначала на холсте появляется грубый эскиз, а потом всё больше и больше точных деталей.
Компьютер сначала делает первую попытку создать изображение, основываясь на текстовом описании заданных объектов (и базе знаний известных ему изображений), а затем отдельный алгоритм оценивает получившуюся картину и вносит предложения по улучшению изображения. На входе, к примеру, есть «зеленая птица», база цветов и база известных птиц. Существует большое количество изображений, которые правильно соответствуют данному текстовому описанию – и в этом кроется одна из проблем.
Для генерации изображений по текстовым описаниям используется несколько сложенных генеративно-состязательных сетей (SGAN). GAN Stage-I набрасывает примитивный эскиз и добавляет основные цвета объектов, основываясь на данных текстового описания. GAN Stage-II принимает результаты Stage-I и текстовые описания в качестве входных данных и генерирует изображения с высоким разрешением и фотореалистичными деталями. GAN Stage-II способен исправлять дефекты и добавлять интересные детали. Образцы, созданные StackGAN, более правдоподобны, чем те, которые генерируются другими существующими подходами.
Поскольку GAN Stage-I генерирует наброски для объектов и для фона, GAN Stage II требуется только сфокусироваться на деталях и исправить дефекты. GAN Stage-II учится обрабатывать текстовую информацию, которую не взял в работу GAN Stage-I, и рисует более подробную информацию об объекте.
Обработка сложных взаимосвязанных событий в видео
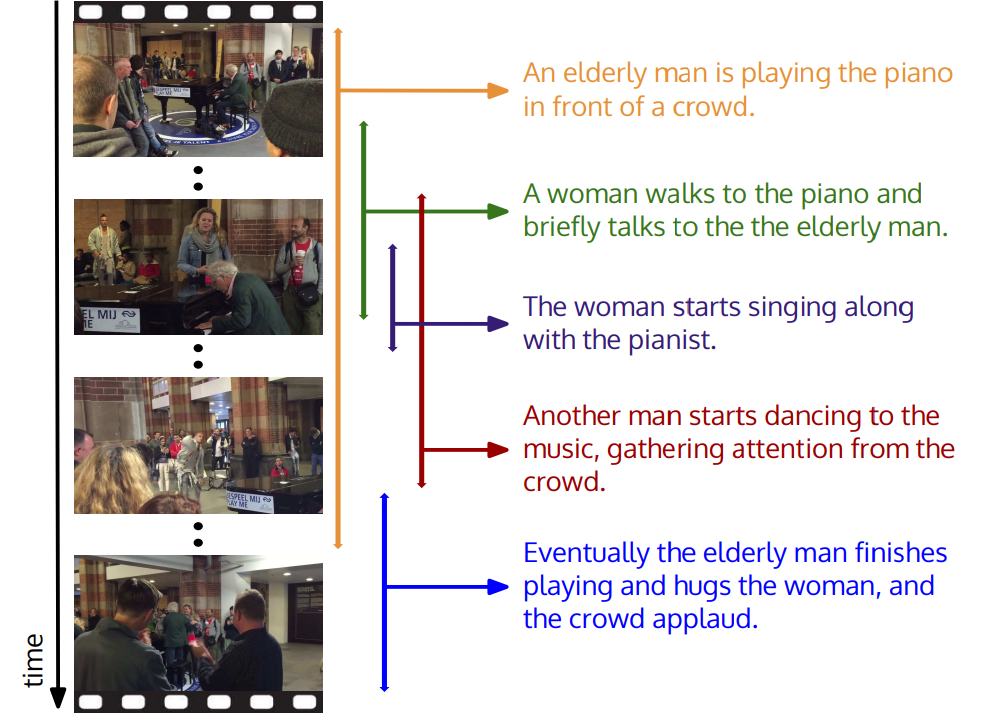
В Стэндфордском университете задумались, что в роликах происходит слишком много событий. Например, в ролике «человек играет на пианино», видео может также содержать «танцующего человека» или «аплодирующую толпу людей». В новом исследовании предложена модель, которая позволяет идентифицировать все события и дать им описание на естественном языке.
Модель основана на базе пространственно-временных описаний. Фактически, компьютер сначала обучался на тысячах роликах, содержащих подробные описания контекста.
Интересно, что в DeepMind для решения похожей задачи пошли другим путем и стали соотносить видеоряд со звуком, чтобы распознавать объекты без предварительного понимания того, что находится в кадре. Алгоритм Google состоит из трех частей: первая нейросеть обрабатывает изображения, взятые из видео, вторая – аудио, соответствующие этим изображениям, третья часть учится соотносить изображения с определенным звуком.
Подобные технологии в видеонаблюдении могут использоваться для удобного и быстрого поиска по архиву данных.
Описание изображений на естественном языке

Какое из двух описаний верхней фотографии кажется вам более человеческим: «Корова, стоящая в поле с домами» или «Серая корова, идущая по большому зеленому полю перед домами»? Последнее, наверное. Но компьютеры не имеют никакого естественного понимания того, что заставляет человека интуитивно выбирать правильный (с нашей точки зрения) вариант.
В проекте «Towards Diverse and Natural Image Descriptions via a Conditional GAN» одна нейронная сеть создает описание сцены на изображении, в то время как другая сравнивает это описание с созданными человеком и оценивает элементы, которые лучше соответствуют нашему собственному стилю речи.
Была предложена система, включающая несколько генеративных состязательных нейросетей, одна из которых подбирала описание к изображению, а вторая оценивала, насколько хорошо описание соответствует визуальному контенту. Удалось добиться такого уровня распознавания объектов и взаимосвязей между ними, что контекст обрабатываемых событий не имел никакого значения. Хотя система никогда не видела корову, пьющую молоко через соломинку, она сможете распознать это изображение, потому что имеет представление, как выглядит корова, молоко, соломинка, и что значит «пить».
Камера заглядывает за угол

Несколько лет назад инженеры и физики из Шотландии создали камеру, которая позволяла в буквальном смысле заглянуть за угол и отслеживать движения людей и объектов, находящихся за ним.
Решение представляло собой набор из двух приборов – «фотонной пушки», которой ученые обстреливали пол и стену, расположенные на противоположной стороне от угла, и специальной светочувствительной матрицы на базе лавинных фотодиодов, способных распознавать даже одиночные фотоны.
Фотоны из луча пушки, отражаясь от поверхности стены и пола, сталкиваются и отражаются от поверхности всех предметов, которые находятся за стеной. Часть из них попадает в детектор, отразившись еще раз от стены, что позволяет, опираясь на время движения луча, определять положение, форму и вид того, что прячется за углом.
Система работала крайне медленно – на формирование начального изображения уходило около трех минут. Кроме того, результат выдавался в виде изображения 32 на 32 пикселя, что фактически не позволяло разглядеть на картинке ничего, кроме грубого силуэта.
Было несколько попыток улучшить качество, однако решение пришло с неожиданной стороны. Специалисты MIT и Google Research предложили смотреть за угол с помощью отраженного света. Посмотрев ОЧЕНЬ внимательно на свет, который виден под разными углами, можно составить представления о цвете и пространственном расположении скрытых за углом объектов.
Это выглядит как сцена из американского процедурала. Для новой системы обработки изображений не требуется никакого специального оборудования, она будет работать даже с камерой смартфона, используя лишь отраженный свет для обнаружения объектов или людей и для измерения их скорости и траектории – всё в режиме реального времени.
Большинство объектов отражают небольшое количество света на земле в вашей прямой видимости, создавая нечеткую тень, которая называется «полутень». Используя видео полутени, система «CornerCameras» может сшить ряд изображений, избавляясь от лишнего шума. Несмотря на то, что объекты на самом деле не видны на камеру, можно увидеть, как их движения влияют на полутень, чтобы определить, где они находятся и куда они идут.
***
Если вас заинтересовали эти проекты, есть свои идеи или хотите познакомиться с нашими разработками – приходите сами или приводите друзей. Нам нужны новые люди в команду Cloud для работы над продуктами на базе облачного видеонаблюдения и компьютерного зрения.
За успешную рекомендацию после оформления разработчика в штат – дарим iPhone X. А если разработчик с нами будет еще и на пейнтбол ходить, то за рекомендацию еще и защитное стекло для айфона! ;) Подробнее о вакансии (откликнуться там же).
И последнее на сегодня: до 19 ноября (включительно) заходите по ссылке. Нужно ответить на один вопрос, оставить свою почту, кинуть ссылку на конкурс в любую соцсетку и ждать – генератор случайных чисел, основанный на энтропии атмосферных шумов, выберет нескольких участников, которых мы наградим домашней Wi-Fi камерой Oco2.
SADKO
phancer.com — тьфу, сначала мне показалось что она просто рассчитывает и применяет кривые по уму, исправляя экспозицию, но стоило загрузить нормально экспонированный снимок, как стало очевидно, что она тупо жарит цвета в тёплый оттенок, вне зависимости, от того надо оно или нет. Никакого понижения шума и повышения резкости, которого стоило бы ожидать от свёрточной сети нет и в помине, только разгон контраста и цвета, причём тупой.
Простая по канальная нормализация динамического диапазона от расчётных уровней даст результат лучше…
… и почему-то меня это не удивляет, вспоминается анекдот про трактор, танк и нейросеть