
Введение
В предыдущей части рассматривалась принципиальная возможность кодирования при котором, в случае, если можно выделить общую часть у ключа и сообщения, то передавать можно меньше информации чем есть в исходном сообщении.

Позвольте немного расскажу откуда вообще взялась эта тема. Давным-давно от одного хорошего человека- ivlad взял почитать и вот пока никак не отдам (прости пожалуйста) интересную книжку [1], где, написано: «в свою очередь криптография сама может быть разделена на два направления, известные как перестановка и замена».
Соответственно почти сразу появились следующий вопросы:
- т.к. перестановка и замена сохраняют количество информации, то можно ли сделать так, чтобы обойти это ограничение, и передавать информации меньше чем есть в сообщении, — отсюда (из «а не слабо ли») родилась первая часть;
- если задача выглядит решаемой, то есть ли само решение и хотя бы толика математического смысла в нём – этот вопрос и есть тема этой части;
- есть ли во всём этом практический смысл – вопрос пока открыт.
Что общего у ворона и письменного стола?
Загадка Кэрролла в заголовке дана как иллюстрация проблемы, которую необходимо решить. А именно: определить пару функций — кодирования и — декодирования, удовлетворяющих следующим условиям:
- –объём передаваемой информации по Шеннону меньше объёма информации в исходном сообщении
- – функция декодирования, применённая к закодированному сообщению, позволит однозначно восстановить исходное сообщение.
Здесь – объём информации по Шеннону [2] (в предположении, что все символы встречаются равновероятно, что в общем случае неверно, но для используется для простоты изложения) в сообщении , — ключ, – закодированное сообщение.
Для того, чтоб упростить себе дальнейшие рассуждения давайте ограничимся в дальнейшем сообщениями, которые можно привести в числовую форму, что с одной стороны нас не особо ограничивает (т.к. любому символу можно присвоить соответствующий числовой код), а с другой позволит воспользоваться математикой в нужном объёме.
Итак, рассмотрим сначала для примера два числа и и, воспользовавшись основной теоремой арифметики [4] (любое натуральное можно разложить на произведение простых) найдём следующие параметры:
- Наименьший общий делитель и – , его простые делители ,
- Частное и его простые делители , которое обозначим как ,
- Разложение числа на простые множители: ,
- Разложение числа на простые множители: .
Запишем всё это в табличном виде, где синим помечена общая часть информации между ключом и сообщением, жёлтым — информация уникальная для ключа, оранжевым – уникальная для сообщения:
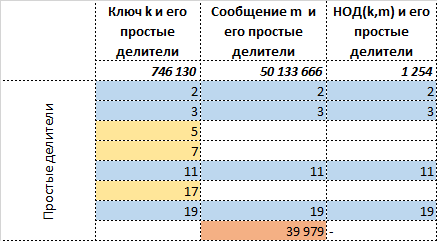
Сразу же становится видно, что представляет из себя общую часть между ключом и сообщением , которая есть и у отправителя и у получателя. Таким образом, в идеале конечно, а не в реальности, достаточно передать информацию об:
- уникальной для сообщения информации — том, что не относится к т.е. , а именно ,
- самом , но так, чтобы его нельзя было бы восстановить.
Пометим теперь позиции простых делителей общие с простыми делителями , единицами, а остальные, кроме, может быть ведущей позиции – нулями.
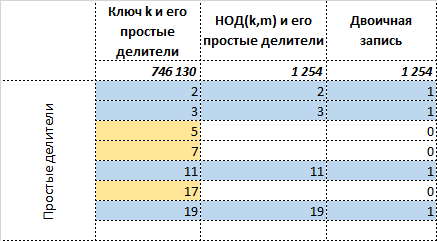
Получившееся число в достаточной степени характеризует , позволяя тем самым восстановить исходное сообщение. Т.е. получив на вход два числа необходимо сделать достаточно простое обратное преобразование:
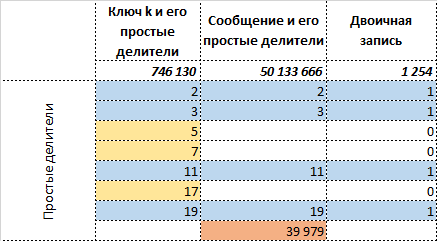
Если теперь оценить длину исходного сообщения в двоичном виде и сообщения , то видно, что можно получить экономию длины сообщения в бита, то же самое и с количеством информации бит, бита. Здесь функция — длина числа в двоичном виде.

Таким образом, выражаясь словами из известного анекдота «в Шотландии есть как минимум одна овца, черная как минимум с одной стороны» [3].
Итак, что на данный момент имеем — данный способ кодирования подходит, но только для пар чисел, имеющих в разложении одинаковые делители. В противном случае, если, например, взять в качестве ключа и в качестве сообщения простые числа, то очевидным образом мы ничего сократить не сможем, а только увеличим и длину сообщения, как и количество передаваемой информации, а это вовсе не то, чего добивались. Эта же ситуация повторяется и в случае когда, например, или же т.к. экономия будет либо минимальной либо будет отсутствовать в принципе.
Что делать…
для того, чтобы повысить вероятность успеха при таком способе кодирования?
В общем-то если внимательно посмотреть на ключ, то видно, что он неплохо делится на простые числа , что сделано специально для успешности операции нахождения . Так как такая операция негативно может повлиять на количество используемых ключей, то определяя порядок следования простых множителей и сделав его частью ключевой информации, получим, хоть и не радикальное, но увеличение количества вариантов кодирования, что положительным образом отразиться на количестве ключей. Использовав вместо ключа не число , а пару , где второе число отражает порядок перемножения и определяет значение .
Следующая проблема, которую предстоит эффективно решить – соотношение частот появления простых чисел и степеней двойки, -легко заметить, что эффективность кодирования степенями двойки довольно быстро падает с ростом длины (см. график соответствующих последовательностей если есть один общий простой делитель) и зависит в основном от количества делителей ключа и их значений.
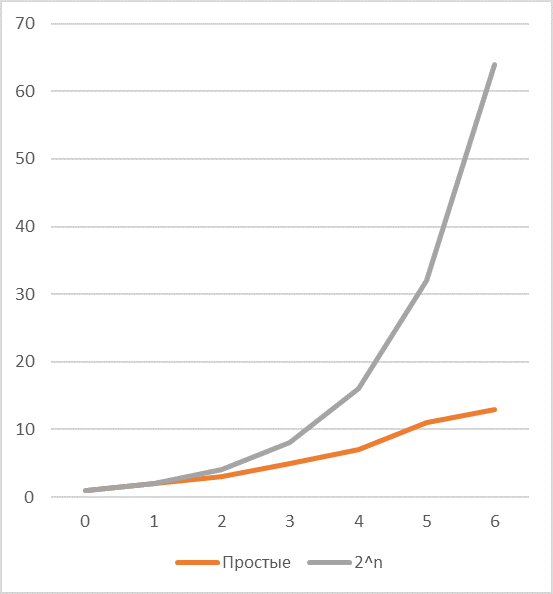
В случае если, общих делителей два и один из них, например, равен , то возможности по экономии возрастают весьма заметно.
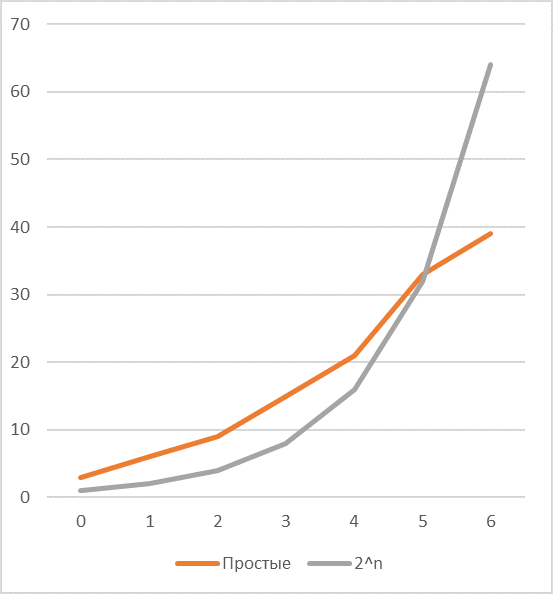
Что означает, что для эффективного кодирования необходимо придумать более эффективный способ кодирования .
То есть тему есть смысл прокапывать дальше.
Пример
Как обычно выложены на github [5] – используется Excel т.к. он есть у многоих и нет необходимости думать о совместимости. В файле две закладки:
- «Тест» — сами вычисления и т.к. в них довольно активно используется функция Excel «СЛУЧМЕЖДУ()» и числа ключа и сообщения могут оказаться взаимно простые, то придётся несколько раз встать в какую либо ячейку и нажать
enterдля того, чтобы получить искомую экономию (результаты в строчках 31-36); - «Пример 1» – приведены примеры готовых вычислений, т.к. случайность в excel не оставляет им шанса на повторение.
Ссылки
- Сингх Саймон. Книга шифров. Тайная история шифров и их расшифровки. М. Астрель 2007.
- https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F
- http://www.gaelic.ru/Biblioteka/Folklore/anekdoty.htm
- https://ru.wikipedia.org/wiki/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D0%BD%D0%B0%D1%8F_%D1%82%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%B0%D1%80%D0%B8%D1%84%D0%BC%D0%B5%D1%82%D0%B8%D0%BA%D0%B8
- https://github.com/rumiantcev/nod_code
Комментарии (23)

Zolg
02.01.2018 18:16Не пытаетесь ли вы изобрести
велосипедсжатие с использованием словаря ?Rumyantsev Автор
02.01.2018 19:23Нет, скорее подмечаю как найти и использовать общую часть у двух ну почти случайных чисел.
eviom
02.01.2018 19:58На самом деле не совсем корректно рассматривать сжатие, не фиксировав (нетривиальное) вероятностное пространство над сообщениями, ведь без этого мы никак не сможем сравнивать алгоритмы сжатия. Конечно можно сказать, что все сообщения заданной длины равновероятны, но тогда мы принципиально не сможем ничего сжать.
Rumyantsev Автор
02.01.2018 20:55Если начинать сравнивать, то да. Просто хотелось сначала показать, что в самом сложном случае, когда берутся два почти случайные числа, можно, найдя общую информацию её не передавать. А так как Вы верно заметили, что реальные сообщения не случайны, то дальше хочется заняться уже переложением этой темы на практику.
Zolg
02.01.2018 23:14можно, найдя общую информацию
объявить ее словарем (имеющимся у обоих сторон) и
её не передавать
заменив на ссылки на словарь
Остальная часть повествования, извините, танцы с бубном и наведение тени на плетень.
Rumyantsev Автор
03.01.2018 00:20Да и не претендую я на словарное кодирование — давно изобрели
Так, то сама идея-то простая: т.к. ключ тоже содержит информацию, то давайте ей воспользуемся, чтобы не передавать её, а дальше НОД — только способ излечения общей части достаточно универсальный, чтобы не сильно думать о словаре.
Ingref
03.01.2018 10:03Возможен ли такой вариант?
Простые делители ключа k: 2,3,5,11,19
Простые делители сообщения m: 2,3,11,19, 39 979
НОД(k,m): 2,3,11,19
Двоичная запись общих делителей: 1,1,0,1,1
Простые делители ключа k: 2,3,7,11,19
Простые делители сообщения m: 2,3,11,19, 39 979
НОД(k,m): 2,3,11,19
Двоичная запись общих делителей: 1,1,0,1,1
То есть, при разных комбинациях простых делителей передаваемая двоичная часть получается одинаковой и восстановить сообщение невозможно. Или я ошибаюсь и такого не может быть?Rumyantsev Автор
03.01.2018 11:01Передаваемая часть действительно будет одинаковой, в обоих случаях

Но т.к. ключ известен двум сторонам, то восстановить полученную информацию можно полностью т.к получив 11011 мы в обоих случаях восстанавливаем НОД(k,m)=1254 =[2,3,11,19].
Другое дело, что если ключ долго не менять, то поигравшись сообщениями (мы-то знаем делители сообщения) и понаблюдав за каналом, его можно и восстановить.
Ingref
03.01.2018 18:11Спасибо, теперь понял! Интересный алгоритм получается. В теории, если в качестве ключа взять очень большой объём разнообразной информации, то экономия будет всё больше и больше. Остаётся только найти грань, за которой ресурсы, затрачиваемые на обработку большого ключа, оправдывают экономию при передаче информации.
И, я так понимаю, отличие от алгоритма со словарём в том, что не нужно тратить время и ресурсы на составление словаря. Но зато надо их тратить на выделение информации из ключа.Rumyantsev Автор
03.01.2018 18:19Вы правы. Но есть надежда на то, что поиск простых делителей довольно отработанный хоть и не очень быстрый алгоритм — делим на всё подряд до корня из числа с оценкой O(n^{0.5})
AC130
1) Поясните пожалуйста, каким именно образом вы считали кол-во информации?
2) Откуда взялась привязка к НОД(m, k)? Почему нельзя просто взять фиксированный список простых чисел (в общем случае независящий от ключа) и отмечать единичками разложение по этому списку? С учётом того что получателю сообщение неизвестно, ему и НОД неизвестен, и большой разницы между НОД(m, k) и НОД(m, r), где r — выбранное случайно число, нет (коль вы всё равно этот НОД передаёте)
3) Что вы предлагаете делать если в разложении m некое простое число встретится, к примеру, дважды?
Rumyantsev Автор
День добрый!
eviom
Все-таки скорее просто в длину, а не в ее двоичный логарифм.
Rumyantsev Автор
Вы правы — без учёта особенностей языка(частотность букв)-нет большого смысла разделять. Если получится подать получше — тогда, надеюсь, будет.
eviom
Тут особенности языка не причем: у Вас просто логарифм лишний для равновероятного случая.
AC130
eviom
AC130
Как будет минимизироваться c_0? Если мы не используем список множителей из ключа, а используем свой список множителей, то c_0 и c_1 не зависят от ключа, а зависят только от списка множителей.
По остальным вопросам мне всё понятно, спасибо большое!
Rumyantsev Автор
кол-во информации в одном символе при условии равновероятного появления [0,1] = 1/2*log_2(2) = 1/2 соотв. если сообщение длины n, то кол-во информации n/2;
меньше т.к. из перечня ключей выкидываются, например [2,2,2,3,3,5] =360 — они не привносят доп. простых множителей относительно [2,3,5] = 30, а длину с_1 увеличивают.
Разложение на множители:
с_1 и с_2
получается если подставить в ячейки с5 и d5 в приложенном excel
AC130
Почему этот ключ выкидывается? Если мы не используем список множителей из ключа, а используем свой список множителей, то c_0 и c_1 не зависят от ключа, а зависят только от списка множителей.
По остальным вопросам мне всё понятно, спасибо большое!
Rumyantsev Автор
Не то, чтобы выкидывается — просто если сопоставлять его простые делители [2,2,2,3,3,5] и то чем это может кодироваться [1,2,4,8,16,32,64], то не очень выгодно в разрядах получается. Т.е. выгодно, только если НОД(k,m) будет больше 64 иначе ни одного разряда сэкономить не получится.
Deosis
То есть в однобитном сообщении содержится полбита информации?
Rumyantsev Автор
Не совсем так — то, что написал касалось сообщений длины n, где надо учитывать вероятность появления каждого символа, для сообщений длины 1 лучше говорить о собственной информации ссылка т.к. там всё детерминировано.