
Моим основным ЯП является D. Всегда понимал, что он будет проигрывать C++ из-за сборщика, каких-то высокоуровневых плюшек и т.д. Но никогда не доходили руки проверить насколько. Решил написать простенький классификатор (даже не помню метод как называется) и проверить. Результат меня приятно удивил: версия C++ отработала за 5.47 сек, версия D — за 5.55 сек. «0.08 сек при обработке файла в 74Мб это не так уж и много» — подумал я. Но, на всякий случай, решил попробовать собрать код на D с помощью gdc (dmd как frontend, gnu backend) и тут уже в душу закрались сомнения, что я всё сделал правильно: код отработал за 4.01 сек, что более чем на 20% быстрее версии на С++. Решил собрать с помощью ldc2 (dmd frontend, llvm backend): 2.92(!!) сек. Тут я решил разобраться.
Первым делом запустил valgrind --tool=callgrind для C++ версии. Как и следовало ожидать на чтение файла уходит бОльшая часть времени.
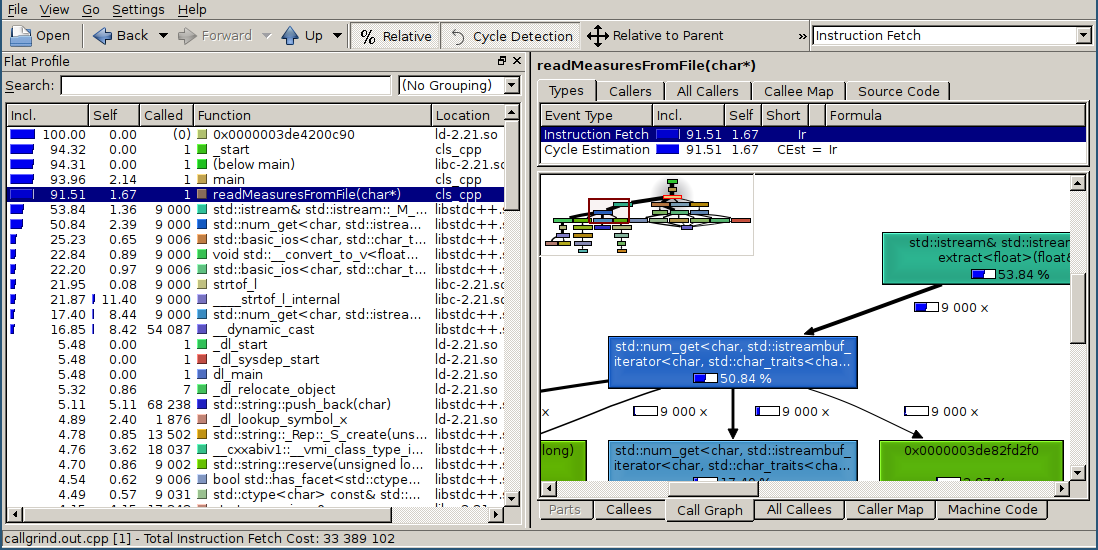
К сожалению, для версии dmd valgrind не смог отработать и завершился ошибкой illegal hardware instruction, видимо ребята из DigitalMars наколдовали с асемблером сильно, но для gdc и ldc2 всё сработало, как для версии С++.

Хоть и valgrind не demangle'ит имена D функций, зато есть маленький хак: callgrind.out.NNN пропускаем через этот инструмент и получаем нормальные имена (не все, но большую часть). И прошу прощения за gdb, версия 7.9.1-13.fc22 полностью поддерживает demangle D кода.
Осознал я, что рано радоваться, нужно выяснить время выполнения непосредственно алгоритма. И раз уж на то пошло, попробовать различные варианты алгоритма:
- минимальный — создаются классификаторы, точки в классах не сохраняются
- с сохранением точек и слиянием классов (изначальный алгоритм с изначальной настройкой плодил много классов)
Пара слов по поводу алгоритма: я не ставил задачи написать хороший классификатор и правильно его настроить, просто тестовый код.
Результаты в секундах, в скобочках отношение к С++ коду:
| c++ g++ | d dmd | d gdc | d ldc2 | rust rustc | |
|---|---|---|---|---|---|
| 1 | 0.577 | 1.797 (3.11) | 0.999 (1.73) | 0.583 (1.01) | 0.546 (0.933) |
| 2 | 0.628 | 2.272 (3.617) | 1.217 (1.937) | 0.898 (1.429) | 0.52 (0.935) |
Второй вариант алгоритма активней использует сборщик мусора (который я никак не настраивал). Лучший результат выдал, конечно же, ldc2 — в полтора раза медленей С++ при активной сборке мусора, что, в итоге, не так уж и плохо. И даже очень хорошо, если сравнивать полное время выполнения программы: 5.4 сек (с учётом правки тов. roman_kashitsyn 3.4 сек) для C++ против 2.9 сек для D на ldc2.
Естественно, для чистоты эксперимента, код я никак специально не оптимизировал и сделал максимально эквивалентным.
import std.stdio;
import std.math;
import std.format;
import std.datetime;
//version=COLLECT_MEASURES;
//version=MERGE_CLASSES;
struct Measure
{
float x=0, y=0;
auto opBinary(string op)( auto ref const Measure m ) const
if( op == "+" || op == "-" )
{ mixin( "return Measure( x " ~ op ~ " m.x, y " ~ op ~ " m.y );" ); }
auto opBinary(string op)( float m ) const
if( op == "*" || op == "/" )
{ mixin( "return Measure( x " ~ op ~ " m, y " ~ op ~ " m );" ); }
}
unittest
{
auto a = Measure(1,3);
auto b = Measure(4,5);
auto add = a + b;
assert( add.x == 5 && add.y == 8 );
auto dif = a - b;
assert( dif.x == -3 && dif.y == -2 );
auto mlt = a * 3;
assert( mlt.x == 3 && mlt.y == 9 );
auto div = b / 2;
assert( div.x == 2 && div.y == 2.5 );
}
float sqr( float v ) { return v * v; }
float dist( ref const Measure a, ref const Measure b )
{ return sqrt( sqr(a.x - b.x) + sqr(a.y - b.y) ); }
class Class
{
Measure mean;
size_t N;
version(COLLECT_MEASURES)
Measure[] measures;
this( in Measure m )
{
mean = m;
N = 1;
version(COLLECT_MEASURES)
measures ~= m;
}
void append( in Measure m )
{
mean = ( mean * N + m ) / ( N + 1 );
N++;
version(COLLECT_MEASURES)
measures ~= m;
}
void merge( const Class m )
{
mean = ( mean * N + m.mean * m.N ) / ( N + m.N );
N += m.N;
version(COLLECT_MEASURES)
measures ~= m.measures;
}
}
unittest
{
auto cls = new Class( Measure(1,2) );
assert( cls.mean.x == 1 && cls.mean.y == 2 );
assert( cls.N == 1 );
cls.append( Measure(3,4) );
assert( cls.mean.x == 2 && cls.mean.y == 3 );
assert( cls.N == 2 );
}
class Classifier
{
public:
Class[] list;
float ncls_dist;
this( float mdist ) { ncls_dist = mdist; }
void classificate( ref const Measure m )
{
float min_dist = float.max;
Class near_cls;
foreach( i; list )
{
float d = dist( m, i.mean );
if( d < min_dist )
{
min_dist = d;
near_cls = i;
}
}
if( min_dist < ncls_dist ) near_cls.append(m);
else list ~= new Class(m);
}
void mergeClasses()
{
Class[] uniq;
l: foreach( cls; list )
{
foreach( trg; uniq )
if( dist( cls.mean, trg.mean ) < ncls_dist )
{
trg.merge( cls );
continue l;
}
uniq ~= cls;
}
list = uniq;
}
}
Measure[] readMeasuresFromFile( string name )
{
auto file = File( name, "r" );
Measure[] list;
foreach( line; file.byLine() )
{
Measure tmp;
formattedRead( line, "%f %f", &tmp.x, &tmp.y );
list ~= tmp;
}
return list;
}
void main( string[] args )
{
auto measures = readMeasuresFromFile( args[1] );
StopWatch sw;
sw.start();
auto clsf = new Classifier(3);
foreach( m; measures )
clsf.classificate(m);
version(MERGE_CLASSES)
clsf.mergeClasses();
sw.stop();
writeln( "work time: ", sw.peek.nsecs / 1_000_000_000.0f );
foreach( cls; clsf.list )
writefln( "[%f, %f]: %d", cls.mean.x, cls.mean.y, cls.N );
}
#![feature(duration)]
#![feature(duration_span)]
#![feature(append)]
use std::ops::*;
use std::borrow::Borrow;
use std::f32;
use std::cell::RefCell;
use std::fs::File;
use std::io::BufReader;
use std::io::BufRead;
use std::time::Duration;
use std::env;
#[derive(Clone,Copy)]
struct Measure
{
x : f32,
y : f32
}
impl Measure{
#[allow(non_snake_case)]
pub fn new(X:f32,Y:f32) -> Measure{
Measure{
x:X,
y:Y
}
}
}
impl Add for Measure{
type Output = Measure;
fn add(self, rhs:Measure) -> Measure {
Measure{
x: self.x + rhs.x,
y: self.y + rhs.y,
}
}
}
impl Sub for Measure{
type Output = Measure;
fn sub(self, rhs: Measure) -> Measure {
Measure{
x: self.x - rhs.x,
y: self.y - rhs.y
}
}
}
impl Div<f32> for Measure {
type Output = Measure;
fn div(self, rhs: f32) -> Measure {
Measure{
x: self.x / rhs,
y: self.y / rhs
}
}
}
impl Mul<f32> for Measure {
type Output = Measure;
fn mul(self, rhs: f32) -> Measure {
Measure{
x: self.x * rhs,
y: self.y * rhs
}
}
}
#[inline]
fn sqr(v:f32)->f32
{
v * v
}
fn dist (a: & Measure, b: & Measure) -> f32
{
(sqr(a.x - b.x) + sqr(a.y - b.y)).sqrt()
}
#[derive(Clone)]
struct Class
{
mean: Measure,
count: usize,
#[cfg(collect_measures)]
measures: Vec<Measure>
}
impl Class{
#[cfg(collect_measures)]
pub fn new( m: Measure ) -> Class
{
Class{
mean: m,
count: 1,
measures: vec![m.clone()]
}
}
#[cfg(not(collect_measures))]
pub fn new( m: Measure ) -> Class
{
Class{
mean: m,
count: 1,
}
}
#[cfg(collect_measures)]
pub fn append(&mut self, m: Measure){
self.mean = ( self.mean * self.count as f32 + m ) /( self.count + 1)as f32;
self.measures.push(m.clone());
self.count += 1;
}
#[cfg(not(collect_measures))]
pub fn append(&mut self, m: Measure){
self.mean = ( self.mean * self.count as f32 + m ) /( self.count + 1)as f32;
self.count += 1;
}
#[cfg(collect_measures)]
pub fn merge(&mut self, m: &mut Class)
{
self.mean = ( self.mean * self.count as f32 + ((m.mean) * m.count as f32 )) / ( self.count + m.count) as f32;
self.count += m.count;
self.measures.append(&mut m.measures);
}
#[cfg(not(collect_measures))]
pub fn merge(&mut self, m: &mut Class)
{
self.mean = ( self.mean * self.count as f32 + ((m.mean) * m.count as f32 )) / ( self.count + m.count) as f32;
self.count += m.count;
}
}
#[test]
fn test_Measure()
{
let a = Measure::new(1f32,3f32);
let b = Measure::new(4f32,5f32);
let add = a + b;
assert!( add.x == 5f32 && add.y == 8f32 );
let dif = a - b;
assert!( dif.x == -3f32 && dif.y == -2f32 );
let mlt = &a * 3f32;
assert!( mlt.x == 3f32 && mlt.y == 9f32 );
let div = &b / 2f32;
assert!( div.x == 2f32 && div.y == 2.5f32 );
}
#[test]
fn test_Class()
{
let mut cls = Class::new( Measure::new(1f32,2f32) );
assert!( cls.mean.x == 1f32 && cls.mean.y == 2f32 );
assert!( cls.count == 1 );
cls.append( Measure::new(3f32,4f32) );
assert!( cls.mean.x == 2f32 && cls.mean.y == 3f32 );
assert!( cls.count == 2 );
}
struct Classifier
{
list:Vec<RefCell<Class>>,
ncls_dist:f32
}
impl Classifier{
pub fn new(mdist:f32) -> Classifier{
Classifier{
list:Vec::new(),
ncls_dist:mdist
}
}
pub fn classificate(&mut self, m: Measure){
let mut min_dist:f32 = f32::MAX;
let mut near_cls = 0;
let mut index:usize = 0;
for i in self.list.iter()
{
let d = dist( &m, & i.borrow().mean);
if d < min_dist
{
min_dist = d;
near_cls = index;
}
index+=1;
}
if min_dist < self.ncls_dist{
self.list[near_cls].borrow_mut().append(m);
}
else {
self.list.push(RefCell::new( Class::new(m)));
}
}
#[allow(dead_code)]
pub fn merge_classes(&mut self)
{
let mut uniq: Vec<RefCell<Class>>= Vec::new();
for cls in self.list.iter(){
let mut is_uniq = true;
for trg in uniq.iter(){
if dist( &cls.borrow().mean, &trg.borrow().mean) < self.ncls_dist
{
trg.borrow_mut().merge(&mut *cls.borrow_mut());
is_uniq = false;
break;
}
}
if is_uniq
{
uniq.push(RefCell::new(cls.borrow_mut().clone()));
}
}
self.list = uniq;
}
}
fn read_measures_from_file( name: String ) -> Vec<Measure>
{
let mut list:Vec<Measure> = Vec::new();
let f = File::open(name).unwrap();
let mut reader = BufReader::new(&f);
let mut ret_string = String::new();
while let Ok(size ) = reader.read_line( &mut ret_string){
if size > 0
{
let len = ret_string.len() - 1;
ret_string.truncate(len);
let buffer:Vec<&str> = ret_string.split(' ').collect();
let var:f32 = (buffer[0]).parse::<f32>().unwrap();
let var2:f32 = (buffer[1]).parse::<f32>().unwrap();
list.push(Measure::new(var,var2));
}
else{
break;
}
ret_string.clear();
}
return list;
}
fn main()
{
let measures = read_measures_from_file(env::args().skip(1).next().unwrap());
let mut clsf = Classifier::new(3f32);
let d = Duration::span(||{
for i in measures{
clsf. classificate(i);
}
if cfg!(merge_classes){
clsf.merge_classes();
}
});
println!("work time: {}", d.secs() as f64 + d.extra_nanos()as f64 / 1000000000.0f64);
for i in clsf.list{
let i = i.borrow();
println!("[{}, {}]: {}",i.mean.x,i.mean.y, i.count);
}
}
#include <vector>
#include <cmath>
#include <cfloat>
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <cassert>
#include <ctime>
using namespace std;
//#define COLLECT_MEASURES
//#define MERGE_CLASSES
class Measure
{
public:
float x, y;
Measure(): x(0), y(0) {}
Measure( float X, float Y ): x(X), y(Y) {}
Measure( const Measure& m ): x(m.x), y(m.y) {}
Measure operator+( const Measure& m ) const
{ return Measure( x + m.x, y + m.y ); }
Measure operator-( const Measure& m ) const
{ return Measure( x - m.x, y - m.y ); }
Measure operator*( float v ) const
{ return Measure( x * v, y * v ); }
Measure operator/( float v ) const
{ return Measure( x / v, y / v ); }
};
void test_Measure()
{
Measure a(1,3);
Measure b(4,5);
auto add = a + b;
assert( add.x == 5 && add.y == 8 );
auto dif = a - b;
assert( dif.x == -3 && dif.y == -2 );
auto mlt = a * 3;
assert( mlt.x == 3 && mlt.y == 9 );
auto div = b / 2;
assert( div.x == 2 && div.y == 2.5 );
}
inline float sqr( float v ) { return v * v; }
float dist( const Measure& a, const Measure& b )
{ return sqrt( sqr(a.x - b.x) + sqr(a.y - b.y) ); }
class Class
{
public:
Measure mean;
size_t N;
#ifdef COLLECT_MEASURES
vector<Measure> measures;
#endif
Class( const Measure& m ): mean(m)
{
N = 1;
#ifdef COLLECT_MEASURES
measures.push_back(m);
#endif
}
void append( const Measure& m )
{
mean = ( mean * N + m ) / ( N + 1 );
N++;
#ifdef COLLECT_MEASURES
measures.push_back(m);
#endif
}
void merge( const Class& m )
{
mean = ( mean * N + m.mean * m.N ) / ( N + m.N );
N += m.N;
#ifdef COLLECT_MEASURES
measures.insert(measures.end(), m.measures.begin(), m.measures.end());
#endif
}
};
void test_Class()
{
auto cls = Class( Measure(1,2) );
assert( cls.mean.x == 1 && cls.mean.y == 2 );
assert( cls.N == 1 );
cls.append( Measure(3,4) );
assert( cls.mean.x == 2 && cls.mean.y == 3 );
assert( cls.N == 2 );
}
class Classifier
{
public:
vector<Class*> list;
float ncls_dist;
Classifier( float mdist ): ncls_dist(mdist) {}
void classificate( const Measure& m )
{
float min_dist = FLT_MAX;
Class* near_cls;
for( auto i = list.begin(); i != list.end(); ++i )
{
float d = dist( m, (*i)->mean );
if( d < min_dist )
{
min_dist = d;
near_cls = *i;
}
}
if( min_dist < ncls_dist ) near_cls->append(m);
else list.push_back( new Class(m) );
}
void mergeClasses()
{
vector<Class*> uniq;
l: for( auto cls = list.begin(); cls != list.end(); ++cls )
{
bool is_uniq = true;
for( auto trg = uniq.begin(); trg != uniq.end(); ++trg )
{
if( dist( (*cls)->mean, (*trg)->mean ) < ncls_dist )
{
(*trg)->merge( **cls );
delete (*cls);
is_uniq = false;
}
if( !is_uniq ) break;
}
if( is_uniq ) uniq.push_back( *cls );
}
list = uniq;
}
~Classifier()
{
for( auto i = list.begin(); i != list.end(); ++i )
delete *i;
}
};
vector<Measure> readMeasuresFromFile( char* name )
{
ifstream file( name );
vector<Measure> list;
for( string line; getline(file, line); )
{
istringstream in( line );
Measure tmp;
in >> tmp.x >> tmp.y;
list.push_back( tmp );
}
return list;
}
void runTests()
{
test_Measure();
test_Class();
}
int main( int argc, char* args[] )
{
//runTests();
auto measures = readMeasuresFromFile( args[1] );
clock_t start = clock();
auto clsf = new Classifier(3);
for( auto i = measures.begin(); i != measures.end(); ++i )
clsf->classificate( *i );
#ifdef MERGE_CLASSES
clsf->mergeClasses();
#endif
clock_t end = clock();
cout << "work time: " << double(end - start) / CLOCKS_PER_SEC << endl;
for( auto i = clsf->list.begin(); i != clsf->list.end(); ++i )
cout << "[" << (*i)->mean.x << ", " << (*i)->mean.y << "]: " << (*i)->N << endl;
delete clsf;
}
import std.stdio;
import std.string;
import std.exception;
import std.random;
import std.math;
double normal( double mu=0.0, double sigma=1.0 )
{
static bool deviate = false;
static float stored;
if( !deviate )
{
double max = cast(double)(ulong.max - 1);
double dist = sqrt( -2.0 * log( uniform( 0, max ) / max ) );
double angle = 2.0 * PI * ( uniform( 0, max ) / max );
stored = dist * cos( angle );
deviate = true;
return dist * sin( angle ) * sigma + mu;
}
else
{
deviate = false;
return stored * sigma + mu;
}
}
struct vec { float x, y; }
vec randomVec( in vec m, in vec s ) { return vec( normal(m.x, s.x), normal(m.y, s.y) ); }
auto generate( size_t[vec] classes )
{
vec[] ret;
foreach( pnt, count; classes )
{
auto tmp = new vec[]( count );
foreach( i, ref t; tmp )
t = randomVec( pnt, vec(1,1) );
ret ~= tmp;
}
return ret;
}
import std.getopt;
void main( string[] args )
{
uint k;
getopt( args,
"count-multiplier|c", &k
);
enforce( args.length == 2, format( "wrong number of arguments: use %s <output_file>", args[0] ) );
auto f = File( args[1], "w" );
scope(exit) f.close();
auto vs = generate( [ vec(-8,8): 20 * k, vec(4,0) : 10 * k, vec(-6,-8) : 15 * k ] );
foreach( v; vs.randomSample(vs.length) )
f.writeln( v.x, " ", v.y );
}
g++ -O2 -std=c++11 cls.cpp -o cls_cpp && echo "c++ g++ builded"
dmd -O -release cls.d -ofcls_d_dmd && echo "d dmd builded"
ldc2 -O2 -release cls.d -ofcls_d_ldc2 && echo "d ldc2 builded"
gdc -O2 cls.d -o cls_d_gdc && echo "d gdc builded"
rustc -O cls.rs -o cls_rs && echo "rust rustc builded"
Тест 2
g++ -O2 -D COLLECT_MEASURES -D MERGE_CLASSES -std=c++11 cls.cpp -o cls_cpp && echo "c++ g++ builded"
dmd -O -version=COLLECT_MEASURES -version=MERGE_CLASSES -release cls.d -ofcls_d_dmd && echo "d dmd builded"
ldc2 -O2 -d-version COLLECT_MEASURES -d-version MERGE_CLASSES -release cls.d -ofcls_d_ldc2 && echo "d ldc2 builded"
gdc -O2 -fversion=COLLECT_MEASURES -fversion=MERGE_CLASSES cls.d -o cls_d_gdc && echo "d gdc builded"
rustc -O --cfg collect_measures --cfg merge_classes cls.rs -o cls_rs && echo "rust rustc builded"
DMD64 D Compiler v2.067.1
GNU gdb (GDB) Fedora 7.9.1-13.fc22
LDC — the LLVM D compiler (0.15.2-beta1)
rustc 1.3.0-nightly (cb7d06215 2015-06-26)
PS. В языках Rust и Go не силён, если кто-нибудь захочет написать эквивалентный код (для полноты эксперимента) буду рад вставить результаты сюда.
UPD: спасибо тов. I_AM_FAKE за код на Rust
Комментарии (33)

ik62
26.06.2015 18:45Не сталкивались ли с какими-либо косяками при использовании не-dmd компилятора?

deviator Автор
26.06.2015 19:10Единственный косяк, который мне приходилось отлавливать не косяк по сути. Версия dmd всегда свежее версий frontend'ов gdc и ldc2. Но dmd я пользуюсь как основным, так что не могу полностью гарантировать, что их нет.


biziwalker
26.06.2015 21:16deviator а не могли бы вы предоставить сгенерированную выборку? К сожалению, нет возможности сгенерировать выборку с помощью вашего генератора на D. Но есть интерес в реализации алгоритма на Rust.
PS: думаю Rust будет немного медленее, чем C++ из-за безопасности кодаdeviator Автор
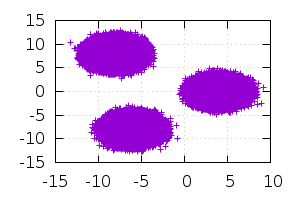
27.06.2015 03:47Было бы очень классно. Выборку я думаю всю предоставлять не имеет смысла, во-первых из-за того, что она 74Мб, во-вторых из-за того, что она тривиальна: 3 набора 2-мерных точек, каждый из которых это реализация нормального распределения с заданным мат. ожиданием и дисперсией (на картинке в начале). Точки в файл записаны в случайном порядке. Мат. ожидания и количество точек задаются в функции main генератора.
небольшой фрагмент выборки-4.67215 -8.07063
-6.56169 -7.13031
-5.94033 -7.09787
-6.47569 -7.6819
-7.40864 -7.69549
-6.89396 -8.54811
-5.08555 -6.72476
-5.13537 -8.38572
-5.59292 -7.04139
-5.62399 -8.811
-6.64349 -7.68353
-6.42634 -9.9467
-7.0504 -8.40296
-4.95483 -9.32353
-4.46654 -9.13888
-8.7821 10.3502
-7.89502 7.76488
-8.334 8.59684
-8.47567 8.01326
-8.11803 9.81281
-8.74283 8.56988
-7.37152 6.98727
-7.24001 7.85616
-6.90632 8.52209
-7.86361 6.87816
-7.54269 6.49742
-8.38692 7.54622
-8.26923 9.62765
-10.4273 7.98343
-6.39929 7.61442
-8.49307 7.86102
-9.80588 8.37838
-7.35485 5.89452
-8.84699 7.78655
-8.74931 9.02794
3.51376 -0.501566
4.47393 -0.988967
2.29637 -0.731235
4.14499 -1.06795
3.62683 -1.55822
4.29838 1.80077
4.33734 -0.0835588
4.81545 -0.525413
4.64983 0.865473
4.77081 -0.460162
withkittens
27.06.2015 14:33Выложите, может быть, всё-таки ваш набор, для честности эксперимента? :)
Или, по крайней мере, скажите, с каким--count-multiplierвызывался генератор выборки.
А я тоже попробую написать версию на Rust.withkittens
27.06.2015 16:07+1Ладно, методом тыка обнаружилось, что
--count-multiplier? 100k. :)deviator Автор
27.06.2015 16:24да, ровно 100000
withkittens
27.06.2015 19:25С настройками как у вас, у меня получается ?54 класса с кол-вом точек от 1 до 342k в каждом из классов. Так и должно быть?
withkittens
27.06.2015 20:07Добавил слияние классов:
Одна точка куда-то упрыгала. :/work time: 678 ms 1 [ -6.000168, -8.001228]: 500000 2 [ -8.000780, 7.999724]: 1999999 3 [ 3.999540, 0.001314]: 1000000 4 [ -5.164976, 2.950943]: 1
Исходники:
sample-generator — github.com/miot/rust-sample-generator
classifier — github.com/miot/rust-classifierdeviator Автор
27.06.2015 21:48тов I_AM_FAKE напсал намного раньше чем Вы, просто я смог выложить это только сейчас. И у Вас нет сохранения набора точек в классах.
withkittens
27.06.2015 22:38Да мне не жалко.
Сохранения набора точек действительно пока нет.
Потестировал код на C++ (компилятор VC14). Чтение файла почему-то неимоверно долгое, я не особо умею в C++, не знаю, почему так:
> Measure-Command { .\classifier.exe | Out-Default } work time: 0.763 [-6.47555, -8.13266]: 86511 [-7.83235, 7.7918]: 342133 [3.79797, 0.0411202]: 183674 [-5.38868, -8.48608]: 73634 ... Days : 0 Hours : 0 Minutes : 1 Seconds : 13 Milliseconds : 321 Ticks : 733214153 TotalDays : 0.000848627491898148 TotalHours : 0.0203670598055556 TotalMinutes : 1.22202358833333 TotalSeconds : 73.3214153 TotalMilliseconds : 73321.4153
Непосредственно классификация на C++ оказалась медленнее (и это без слияния!). Хотя я уверен, что можно ускориться.
biziwalker
27.06.2015 21:30+1Rust версия: github.com/biziwalker/rust-habr261201 на предоставленной выборке из 45 позиций
% g++ -std=c++11 -O3 -o ./target/release/cpp-habr ./src/main.cpp % cargo build --release % ./target/release/rust-habr input.txt work time: PT0.000006164S [-5.928793, -8.112186]: 15 [-8.200232, 8.078455]: 20 [4.092769, -0.32508284]: 10 % ./target/release/cpp-habr input.txt work time: 1.8e-05 [-5.92879, -8.11219]: 15 [-8.20023, 8.07845]: 20 [4.09277, -0.325083]: 10biziwalker
27.06.2015 21:50Получается Rust оказался почти в 3 раза быстрее C++ — что-то здесь не чисто! Код на C++ приводил к индентичному на Rust, единственное это я не реализовал ту фичу заложенную автором, которая включается с помощью #define COLLECT_MEASURES. А так на равных условиях, с отключенными фичами, Rust оказался быстрее. И всетаки надо сравнивать на одинаковом железе и с нормальными выборками. Предлагаю автору ( deviator ) этим заняться и сделать свои выводы кто кого быстрее в этой гонке.

mx2000
28.06.2015 00:32+1«безопасность» кода в Rust проверяется на стадии компиляции, что никак не отражается на эффективности конечного бинарника.
deviator Автор
28.06.2015 00:41Всего не знаю, но, мне кажется, что на C++ вообще нет такой безопасности.
biziwalker
28.06.2015 09:13Сталкивался на простых тестах сортировки с тем, что в Rust есть инструкции проверки на доступность элемента в массиве. Скорость просела в 1.5 раза по сравнению с C на сортировке вставками. Но благо Rust позволяет писать unsafe код, если хочется выжить максимум :)

NCrashed
27.06.2015 23:04+4Решил поиграться с Haskell.
Платформа: Fedora 21 x64
Входная выборка получена генератором с параметром `100000`.
DMD 2.067.1: 2.85267 s
GHC 7.8.4 (обычный бекэнд): 2.462 s
GHC 7.8.4 (llvm): 2.382 s
Main.hs{-# LANGUAGE DeriveGeneric #-} {-# LANGUAGE BangPatterns, MultiParamTypeClasses, TypeFamilies, FlexibleContexts #-} module Main where import Criterion import Criterion.Main import Control.DeepSeq import GHC.Generics (Generic) import qualified Data.ByteString.Char8 as BS import qualified Data.Vector.Unboxed as V import Data.ByteString.Read import Data.Maybe import qualified Data.Vector.Generic as G import qualified Data.Vector.Generic.Mutable as M import Control.Monad data Measure = Measure {-# UNPACK #-} !Float {-# UNPACK #-} !Float deriving (Generic) instance NFData Measure instance Num Measure where (Measure x1 y1) + (Measure x2 y2) = Measure (x1+x2) (y1+y2) (Measure x1 y1) - (Measure x2 y2) = Measure (x1-x2) (y1-y2) (Measure x1 y1) * (Measure x2 y2) = Measure (x1*x2) (y1*y2) abs = undefined signum = undefined fromInteger i = Measure (fromIntegral i) (fromIntegral i) instance Fractional Measure where (Measure x1 y1) / (Measure x2 y2) = Measure (x1/x2) (y1/y2) fromRational = undefined sqr :: Float -> Float sqr x = x*x dist :: Measure -> Measure -> Float dist (Measure x1 y1) (Measure x2 y2) = sqrt $ sqr (x1 - x2) + sqr (y1 - y2) data Class = Class !Measure !Int deriving (Generic) instance NFData Class instance Show Class where show (Class (Measure x y) i) = "[" ++ show x ++ ", " ++ show y ++ "]: " ++ show i newClass :: Measure -> Class newClass m = Class m 1 append :: Class -> Measure -> Class append (Class mean n) m = Class newMean (n+1) where newMean = ( mean * fromIntegral n + m ) / fromIntegral ( n + 1 ) merge :: Class -> Class -> Class merge (Class mean1 n1) (Class mean2 n2) = Class mean3 (n1+n2) where mean3 = ( mean1 * fromIntegral n1 + mean2 * fromIntegral n2 ) / fromIntegral ( n1 + n2 ); classificate :: Float -> V.Vector Measure -> V.Vector Class classificate nclsDist ms = V.foldl' go V.empty ms where go :: V.Vector Class -> Measure -> V.Vector Class go acc m | V.null acc = V.singleton $ newClass m | otherwise = if minDist < nclsDist then newCls else (newClass m) `V.cons` newCls where newCls = acc `V.unsafeUpd` [(nearClsI, nearCls `append` m)] (nearCls, nearClsI, minDist) = sortByDist acc m sortByDist :: V.Vector Class -> Measure -> (Class, Int, Float) sortByDist cs m = out $ V.ifoldl' checkDist (0, maxFloat) cs where maxFloat :: Float maxFloat = 1/0 out :: (Int, Float) -> (Class, Int, Float) out (i, d) = (V.unsafeIndex cs i, i, d) checkDist :: (Int, Float) -> Int -> Class -> (Int, Float) checkDist acc@(_, mdist) i (Class mean _) = if curDist < mdist then (i, curDist) else acc where curDist = dist m mean readMeasures :: BS.ByteString -> V.Vector Measure readMeasures = V.fromList . catMaybes . fmap (go . BS.words) . BS.lines where go [a, b] = do (x, _) <- signed fractional a (y, _) <- signed fractional b return $!! Measure x y go _ = Nothing main :: IO () main = defaultMain [ env (fmap readMeasures $ BS.readFile "data") $ \measures -> bench "classificate" $ nf (classificate 3) measures ] -- | Алтернативная main функция для проверки правильности реализации main2 :: IO () main2 = do measures <- fmap readMeasures $ BS.readFile "data" print $ measures `deepseq` V.length measures let classes = classificate 3 measures print $ classes `deepseq` V.length classes putStrLn $ unlines $ fmap show $ V.toList classes -- | Далее идет boilerplate для реализации Unboxed векторов для кастомных типов newtype instance V.MVector s Measure = MV_Measure (V.MVector s (Float,Float)) newtype instance V.Vector Measure = V_Measure (V.Vector (Float,Float)) instance V.Unbox Measure instance M.MVector V.MVector Measure where {-# INLINE basicLength #-} {-# INLINE basicUnsafeSlice #-} {-# INLINE basicOverlaps #-} {-# INLINE basicUnsafeNew #-} {-# INLINE basicUnsafeReplicate #-} {-# INLINE basicUnsafeRead #-} {-# INLINE basicUnsafeWrite #-} {-# INLINE basicClear #-} {-# INLINE basicSet #-} {-# INLINE basicUnsafeCopy #-} {-# INLINE basicUnsafeGrow #-} basicLength (MV_Measure v) = M.basicLength v basicUnsafeSlice i n (MV_Measure v) = MV_Measure $ M.basicUnsafeSlice i n v basicOverlaps (MV_Measure v1) (MV_Measure v2) = M.basicOverlaps v1 v2 basicUnsafeNew n = MV_Measure `liftM` M.basicUnsafeNew n basicUnsafeReplicate n (Measure x y) = MV_Measure `liftM` M.basicUnsafeReplicate n (x,y) basicUnsafeRead (MV_Measure v) i = uncurry Measure `liftM` M.basicUnsafeRead v i basicUnsafeWrite (MV_Measure v) i (Measure x y) = M.basicUnsafeWrite v i (x,y) basicClear (MV_Measure v) = M.basicClear v basicSet (MV_Measure v) (Measure x y) = M.basicSet v (x,y) basicUnsafeCopy (MV_Measure v1) (MV_Measure v2) = M.basicUnsafeCopy v1 v2 basicUnsafeMove (MV_Measure v1) (MV_Measure v2) = M.basicUnsafeMove v1 v2 basicUnsafeGrow (MV_Measure v) n = MV_Measure `liftM` M.basicUnsafeGrow v n instance G.Vector V.Vector Measure where {-# INLINE basicUnsafeFreeze #-} {-# INLINE basicUnsafeThaw #-} {-# INLINE basicLength #-} {-# INLINE basicUnsafeSlice #-} {-# INLINE basicUnsafeIndexM #-} {-# INLINE elemseq #-} basicUnsafeFreeze (MV_Measure v) = V_Measure `liftM` G.basicUnsafeFreeze v basicUnsafeThaw (V_Measure v) = MV_Measure `liftM` G.basicUnsafeThaw v basicLength (V_Measure v) = G.basicLength v basicUnsafeSlice i n (V_Measure v) = V_Measure $ G.basicUnsafeSlice i n v basicUnsafeIndexM (V_Measure v) i = uncurry Measure `liftM` G.basicUnsafeIndexM v i basicUnsafeCopy (MV_Measure mv) (V_Measure v) = G.basicUnsafeCopy mv v elemseq _ (Measure x y) z = G.elemseq (undefined :: V.Vector Float) x $ G.elemseq (undefined :: V.Vector Float) y z newtype instance V.MVector s Class = MV_Class (V.MVector s (Float, Float, Int)) newtype instance V.Vector Class = V_Class (V.Vector (Float, Float, Int)) instance V.Unbox Class instance M.MVector V.MVector Class where {-# INLINE basicLength #-} {-# INLINE basicUnsafeSlice #-} {-# INLINE basicOverlaps #-} {-# INLINE basicUnsafeNew #-} {-# INLINE basicUnsafeReplicate #-} {-# INLINE basicUnsafeRead #-} {-# INLINE basicUnsafeWrite #-} {-# INLINE basicClear #-} {-# INLINE basicSet #-} {-# INLINE basicUnsafeCopy #-} {-# INLINE basicUnsafeGrow #-} basicLength (MV_Class v) = M.basicLength v basicUnsafeSlice i n (MV_Class v) = MV_Class $ M.basicUnsafeSlice i n v basicOverlaps (MV_Class v1) (MV_Class v2) = M.basicOverlaps v1 v2 basicUnsafeNew n = MV_Class `liftM` M.basicUnsafeNew n basicUnsafeReplicate n (Class (Measure x y) ni) = MV_Class `liftM` M.basicUnsafeReplicate n (x,y,ni) basicUnsafeRead (MV_Class v) i = (\(x,y,ni)->Class (Measure x y) ni) `liftM` M.basicUnsafeRead v i basicUnsafeWrite (MV_Class v) i (Class (Measure x y) ni) = M.basicUnsafeWrite v i (x,y, ni) basicClear (MV_Class v) = M.basicClear v basicSet (MV_Class v) (Class (Measure x y) ni) = M.basicSet v (x,y,ni) basicUnsafeCopy (MV_Class v1) (MV_Class v2) = M.basicUnsafeCopy v1 v2 basicUnsafeMove (MV_Class v1) (MV_Class v2) = M.basicUnsafeMove v1 v2 basicUnsafeGrow (MV_Cla
mt_
28.06.2015 14:09С моей точки зрения, заголовок некорректен.
В данном конкретном случае нужно говорить не о сравнении языков, а о сравнении скорости функций ввода-вывода двух конкретных реализаций библиотек. Это по большей части.
Являясь профессионалом в D, вы подготовили сравнительно оптимальный код D и «просто работающий» код С++. После чего получили те результаты, которые получили. Что они действительно показывают — вопрос отдельный. Но уж точно не «сравнение производительности двух языков».withkittens
28.06.2015 14:56а о сравнении скорости функций ввода-вывода двух конкретных реализаций библиотек
Таблица в статье не включает ввод-вывод.mt_
28.06.2015 17:06К сожалению, автор не привёл профилирование версии без ввода-вывода, но судя по результатам общего профилирования, в версии для С++ не связанные с парсингом файла вызовы даже не попали на первую страницу. Всё что мы там видим — это библиотечные вызовы и загрузка данных. Единственный вопрос вызвал dynamic_cast, но его нет и в исходниках автора.
А вот интересующие нас вызовы в D вполне заметны по времени, начинаясь примерно с 5,8%.
То есть сравнение «мутное» даже без парсинга файла. Почему? Надо разбираться. Я навскидку скажу, что очень много new/delete вызовов в цикле. То есть мы по сути тестируем скорость менеджера памяти для конкретной реализации runtime library С++. Стандартный менеджер, действительно, не самый быстрый. Я, например, пользуюсь фреймворком U++, где этот менеджер по умолчанию свой, более быстрый.
В D тоже может быть более эффективный менеджер памяти, особенно вкупе с необходимостью иметь быстрый мусоросборщик.
Но это лишь предположение — чтобы сказать точно, нужно профилировать версии без парсинга.

kraidiky
28.06.2015 15:20+7Как-то раз в бородатом детстве в 1993-ом кажется году мы решили писать компьютерную игрушку и для этого решили сравнить производительность трёх языков, на которых умели писать. Borland C++ 4.0, Turbo Pascal 7.0 и Fortran 77. Тестировались две нужные нам задачи — Умножение вектора на матрицу и отрисовывание треугольника стандартными инструментами в режиме EGA.
Довольно быстро выяснилось, что рисование у C и Pascal шло с одинаковой скоростью, потому как использовало одну и ту же библиотеку egavga.bgi, Расчёты на С были примерно вдвое быстрее, за счёт разнообразных проверок на переполнение, которые в Паскале по умолчанию были включены, а в C по умолчанию выключены. Но это можно было исправить директивами компилятора. А вот с фортраном началось самое интересное:
Первый замер был про умножение на матрицу. Когда фортран показал результат в 10000 раз быстрее у нас закралось подозрение. Сначала мы пытались найти ошибку, но потом сдались. Дизасемблирование показало, что отимизатор смекнул, что результаты вычислений внутри цикла не используются и посчитал умножения и суммирования только один раз, для значения переменной цикла в последнем цикле.
Тогда вместо того чтобы внутри цикла делать просто умножения и сложения мы заставили его ещё и суммировать переменную цикла. Когда фортран показал результаты в 10000 раз быстрее, мы сразу полезли в дизасемблер и к величайшему нашему удивлению обнаружили, что фортран суммирование переменной цикла в цикле успешно заменил на формулу подсчёта арифметической прогрессии. Сказать, что мы были в шоке — ничего не сказать.
Следующие пол часа ушли на подбор такой формулы для замеров, в которой оптимизатор фортрана ничего не смог бы упростить. Задачка оказалось нетривиальной, потому что на глазах у удивлённых школьников фортран выносил общий множитель за скобку, заранее умножал друг на друга константы и делал ещё несколько не менее интеллектуальных операций потрясая наше воображение. Когда мы таки смогли его обмануть выяснилось, что по скорости он от C по скорости не отличается.
Когда мы заставили фортран нарисовать закрашенный треугольник 256 цветами, и он показал результаты ровно в 16 раз лучше egavga.bgi мы уже даже не удивились. В EGA было всего 16 цветов. Рисование цветом 17 было то же самое, что рисование цветом 1. Уж не знаю как Fortran77 дозрел до этой идеи, но он треугольник перерисовал только 16 раз разными цветами, и на этом покинул цикл. Пришлось каждый следующий треугольник рисовать сдвигая одну из вершин на 1 пиксель. Результаты оказались примерно такие же как у конкурентов.
В общем по результатам всей этой истории у меня осталось два выводы:
1) Нет большой разницы на каком из нормальных компиляторов писать, если не лениться.
2) Оптимизатор в фортране написан сошедшими на землю богами.biziwalker
28.06.2015 15:48Особенно верно, если учесть, что у большинства современных языков на бэкенде LLVM или GCC
roman_kashitsyn
Решая задачки на hackerrank, я тоже заметил, что ввод-вывод в D работает ощутимо шустрее, чем в C++.
Однако, кажется, в вашей C++-реализации происходит довольно много лишней работы.
Вместо
Вполне можно было написать что-то вроде
Так можно избежать большого количества копий строк.
deviator Автор
Согласен, мой косяк.
FoxCanFly
Просто ifstream — не лучшее решение, если нужна максимальная скорость работы с вводом/выводом.
roman_kashitsyn
> Просто ifstream — не лучшее решение, если нужна максимальная скорость работы с вводом/выводом
Это верно. На игрушечных задачках я в основном использовал cin/cout с sync_with_stdio(false).
На хабре уже было исследование на эту тему. Старый добрый <cstdio> быстр, но не всегда удобен на практике.
std.stdio в D мне нравится одновременно простотой и эффективностью. Не нужно думать, где сколько букв l нужно писать в строке формата, компилятор сам может вставить правильный код. Ну и он бросает исключения в случае ошибок, не нужно смотреть коды возврата / флажки.
0xd34df00d
Когда мне надо было прочитать файл с корреляционной таблицой на 3.5, кажется, гигабайта из кучи строк формата
ENTITY_1 ENTITY_2 <integer>то
cstdio(fscanf, в частности) был медленнее процентов на 10-15, чемifstream— в конце концов, на каждой строке файла надо форматную строку"%s %s %f"ещё распарсить, в то время как на C++ знание о формате заложено в структуру и последовательность вызововoperator>>.Судя по профайлеру, в
ifstreamжралось феерически много времени на какую-то возню с локалями, избавиться от которой мне так и не удалось.В итоге открывал файл через
mmapи писал самопальный токенайзер с парсером чисел (благо, не надо обрабатывать отрицательные числа, и т. п.). В итоге на непосредственно чтение файла стало тратиться совсем мало времени, большинство из которого было внутриmemchr, и выигрыш в скорости был где-то процентов 35 — с 90 секунд до 50 время чтения упало.deviator Автор
Возможно, а что сейчас принято использовать на С++ для ввода?
FoxCanFly
Большинству хватает fstream — редко когда нужна максимальная скорость ввода вывода файлов. Кому нужна — есть много альтернативных библиотек, вроде даже тот же QFile быстрее. Ну и пишут свои велосипеды с системными read()/write()
BalinTomsk
file mapping