
Исходное изображение и результат:

Слева: исходный скан на 300 DPI, 7,2 МБ PNG / 790 КБ JPG. Справа: результат с тем же разрешением, 121 КБ PNG [1]
Примечание: описанный здесь процесс более-менее совпадает с работой приложения Office Lens. Есть другие аналогичные программы. Я не утверждаю, что придумал нечто радикальное новое — это просто моя реализация полезного инструмента.
Если торопитесь, просто посмотрите репозиторий GitHub или перейдите в раздел результатов, где можно поиграться с интерактивными 3D-диаграммами цветовых кластеров.
Мотивация
По некоторым из моих предметов нет учебников. Для таких студентов я люблю устраивать еженедельные «переписывания», когда они делятся своими конспектами с остальными и проверяют, насколько усвоили материал. Конспекты выкладываются на веб-сайте курса в формате PDF.
На факультете есть «умный» копир, который сразу сканирует в PDF, но результат такого сканирования… менее чем приятен. Вот некоторые примеры сканирования домашней работы студента:

Как будто случайным образом копир выбирает одно из двух: или бинаризацию знака (символы x), или преобразование в ужасные JPEG-блоки (символы квадратного корня). Очевидно, такой результат можно улучшить.
Общее представление
Начнём со сканирования такой прекрасной страницы студенческого конспекта:

Оригинальный PNG на 300 DPI весит около 7,2 МБ. Изображение в JPG с уровнем сжатия 85 занимает около 790 КБ2. Поскольку PDF — обычно просто контейнер для PNG или JPG, то при конвертации в PDF вы не сожмёте файл ещё сильнее. 800 килобайт на страницу это довольно много, и ради ускорения загрузки я бы хотел бы получить что-то ближе к 100 КБ3.
Хотя этот студент очень аккуратно ведёт конспект, результат сканирования выглядит немного неряшливо (не по его вине). Заметно просвечивается обратная сторона листа, что и отвлекает читателя, и мешает эффективному сжатию JPG или PNG по сравнению с ровным фоном.
Вот что выдаёт программа
noteshrink.py:
Это крошечный файл PNG размером всего 121 КБ. Знаете, что мне нравится больше всего? Кроме уменьшения размера, конспект стал и разборчивее!
Основы цвета и процесса обработки
Вот шаги для создания компактного и чистого изображения:
- Определить цвет фона исходного отсканированного изображения.
- Изолировать передний план, установив порог по другим цветам.
- Преобразовать в индексированный PNG, выбрав небольшое количество «репрезентативных цветов» на переднем плане.
Прежде чем углубиться в тему, полезно вспомнить, как цветные изображения хранятся в цифровом виде. Поскольку в глазу человека три типа цветочувствительных клеток, мы можем восстановить любой цвет, изменяя интенсивность красного, зелёного и синего света4. В результате получается система, которая присваивает цветам точки в трёхмерном цветовом пространстве RGB5.

Хотя истинное векторное пространство допускает бесконечное число непрерывно изменяющихся значений интенсивности, для хранения в цифровом виде мы дискретизируем цвета, обычно выделяя по 8 бит каждому из каналов: красному, зелёному и синему. Однако если рассматривать цвета как точки в непрерывном трёхмерном пространстве, то становятся доступны мощные инструменты для анализа, как показано далее в описании процесса.
Определение цвета фона
Поскольку основная часть страницы — чистая, то можно ожидать, что цветом бумаги станет самый часто встречающийся цвет на отсканированном изображении. И если бы сканер всегда представлял каждую точку чистой бумаги как одинаковый триплет RGB, у нас не было бы проблем. К сожалению, это не так. Случайные изменения в цвете возникают из-за пыли и пятен на стекле, цветовых вариаций самой бумаги, шума на сенсоре и т.д. Таким образом, реальный «цвет страницы» может распределяться по тысячам различных значений RGB.
Исходное отсканированное изображение имеет размер 2081?2531, общая площадь 5 267 011 пикселей. Хотя можно рассмотреть все пиксели, но гораздо быстрее взять репрезентативную выборку исходного изображения. Программа
noteshrink.py по умолчанию берёт 5% исходного изображения (более чем достаточно для скана 300 DPI). Но давайте посмотрим на еще меньшее подмножество из 10 000 пикселей, выбранных случайным образом из исходного изображения:
Оно мало похожа на реальный скан — здесь нет текста, но распределение цветов практически идентично. Оба изображения в основном серовато-белые, с горсткой красных, синих и тёмно-серых пикселей. Вот те же 10 000 пикселей, отсортированные по яркости (то есть по сумме интенсивности каналов R, G и B):

Если смотреть издалека, то нижние 80-90% изображения кажутся одним и тем же цветом, но при ближайшем рассмотрении заметно довольно много вариаций. На самом деле на изображении чаще всего встречается цвет со значением RGB (240, 240, 242), и он представлен всего на 226 из 10 000 пикселей — не более 3% от общего количества.
Поскольку мода представляет настолько малый процент выборки, то возникает вопрос, насколько точно она соответствует распределению цветов. Проще определить фоновый цвет страницы, если сначала уменьшить глубину цвета. Вот как выглядит выборка, если снизить глубину с 8 до 4 бит на канал, обнулив четыре наименее значимых бита:

Теперь чаще всего встречается значение RGB (224, 224, 224), которое составляет 3623 (36%) выбранных точек. По сути, уменьшив глубину цвета, мы сгруппировали похожие пиксели в «корзины» большего размера, что облегчило поиск явного пика6.
Здесь определённый компромисс между надёжностью и точностью: небольшие корзины обеспечивают лучшую точность цветов, но большие корзины гораздо более надёжны. В конце концов, для выбора цвета фона я остановился на 6 битах на канал, что показалось оптимальным вариантом между двумя крайностями.
Выделение переднего плана
После того, как мы определили цвет фона, нужно выбрать пороговое значение (threshold) для остальных пикселей по степени близости к фону. Естественный способ определить сходство двух цветов — вычислить евклидово расстояние между их координатами в пространстве RGB. Но этот простой метод неправильно сегментирует некоторые цвета:

Вот таблица с цветами и евклидовым расстоянием от фона:
| Цвет | Где найден | R | G | B | Расстояние от фона |
|---|---|---|---|---|---|
| белый | фон | 238 | 238 | 242 | — |
| серый | просвечивается с обратной страницы | 160 | 168 | 166 | 129,4 |
| чёрный | чернило на лицевой странице | 71 | 73 | 71 | 290,4 |
| красный | чернило на лицевой странице | 219 | 83 | 86 | 220,7 |
| розовый | вертикальная линия слева | 243 | 179 | 182 | 84,3 |
Как видите, тёмно-серый цвет от просвечивающихся чернил, которые нужно классифицировать как фон, на самом деле находится дальше от белого цвета страницы, чем розовый цвет линии, которую мы хотим классифицировать как передний план. Любой порог в евклидовом расстоянии, который сделает розовый цвет передним планом, обязательно включит в себя и просвечивающиеся чернила.
Можно обойти эту проблему, перейдя из пространства RGB в пространство Hue-Saturation-Value (HSV), которое преобразует куб RGB в цилиндр, показанный здесь в разрезе7.

В цилиндре HSV радуга цветов распределена по окружности внешнего верхнего края; значение hue (цветовой тон) соответствует углу на окружности. Центральная ось цилиндра переходит от чёрного внизу до белого вверху с серыми оттенками посредине — вся эта ось имеет нулевую насыщенность или интенсивность цвета, а у ярких оттенков на внешней окружности насыщенность 1,0. Наконец, значение цвета value характеризует общую яркость цвета, от чёрного внизу до ярких оттенков вверху.
Итак, теперь пересмотрим теперь на наши цвета в модели HSV:
| Цвет | Значение цвета | Насыщенность | Разница с фоном по значению | Разница с фоном по насыщенности |
|---|---|---|---|---|
| белый | 0,949 | 0,017 | — | — |
| серый | 0,659 | 0,048 | 0,290 | 0,031 |
| чёрный | 0,286 | 0,027 | 0,663 | 0,011 |
| красный | 0,859 | 0,621 | 0,090 | 0,604 |
| розоый | 0,953 | 0,263 | 0,004 | 0,247 |
Как и следовало ожидать, белый, чёрный и серый значительно различаются по значению цвета, но имеют аналогичные низкие уровни насыщенности — значительно меньше красного или розового. С помощью дополнительной информации в модели HSV можно успешно пометить пиксель как принадлежащий переднему плану, если он соответствует одному из критериев:
- значение цвета отличается более чем на 0,3 от фона или
- насыщенность отличается более чем на 0,2 от фона
Первый критерий забирает чёрные чернила от ручки, а второй — красные чернила и розовую линию. Оба критерия успешно убирают с переднего плана серые пиксели просвечивающихся чернил. Для разных изображений можно использовать разные пороги насыщенности/значения цвета; для дополнительной информации см. раздел с результатами.
Выбор набора репрезентативных цветов
Как только мы изолировали передний план, то получили новый набор цветов, соответствующих отметкам на странице. Давайте визуализируем его — но на этот раз будем рассматривать цвета не как набор пикселей, а как 3D-точки в цветовом пространстве RGB. Результирующая диаграмма выглядит слегка «скученной», с несколькими полосами связанных цветов.

Интерактивная диаграмма по ссылке
Теперь наша цель — преобразовать исходное 24-битное изображение в индексированный цвет, выбрав небольшое количество цветов (в данном случае восемь) для представления всего изображения. Во-первых, это уменьшает размер файла, потому что цвет теперь определяется всего тремя битами (так как 8=2?). Во-вторых, полученное изображение становится более визуально сплочённым, потому что похожим цветным чернильным точкам, вероятно, будет назначен одинаковый цвет в итоговом изображении.
Для этого используем метод на основе данных со «скученной» диаграммы, упомянутой выше. Если выбрать цвета, соответствующие центрам кластеров, то получим набор цветов, точно представляющих исходные данные. С технической точки зрения мы решаем проблему квантования цвета (которая сама по себе является частным случаем векторного квантования) с помощью кластерного анализа.
Для этой работы я выбрал конкретный методологический инструмент — метод k-средних. Его цель — найти набор средних значений или центров, которые минимизируют среднее расстояние от каждой точки до ближайшего центра. Вот что получится, если выбрать семь различных кластеров в нашем наборе данных8.

Здесь точки с чёрными контурами соответствуют цветам переднего плана, а цветные линии соединяют их с ближайшим центром в пространстве RGB. Когда изображение преобразуется в индексированный цвет, каждый цвет переднего плана заменяется цветом ближайшего центра. Наконец, большие окружности показывают расстояние от каждого центра до самого дальнего связанного цвета.
Прибамбасы и навороты
Кроме установки пороговых значений цвета и насыщенности, в программе
noteshrink.py есть несколько других примечательных особенностей. По умолчанию она увеличивает яркость и контрастность палитры, изменяя минимальные и максимальные значения интенсивности на 0 и 255, соответственно. Без этого восьмицветная палитра нашего отсканированного образца выглядела бы так:
Отрегулированная палитра более яркая:

Есть опция для принудительной смены фона на белый после изоляции цветов переднего плана. Для дальнейшего уменьшения размеров файла
noteshrink.py может автоматически запускать инструменты оптимизации PNG, такие как optipng, pngcrush и pngquant.На выходе программа выдаёт такие PDF-файлы с несколькими изображениями, используя программу конвертации от ImageMagick. В качестве дополнительного бонуса
noteshrink.py автоматически сортирует имена файлов численно в порядке возрастания (а не в алфавитном порядке, как glob в консоли). Это полезно, когда ваша тупая программа сканирования9 выдаёт на выходе названия файлов вроде scan 9.png и scan 10.png, а вы хотите, чтобы страницы в PDF были по порядку.Результаты
Вот еще несколько примеров вывода программы. Первый (PDF) отлично смотрится с дефолтными пороговыми значениями:
Визуализация цветовых кластеров:

Для следующего (PDF) понадобилось снизить порог насыщенности до 0,045, потому что серо-голубые линии слишком тусклые:
Цветовые кластеры:

Наконец, пример сканирования миллиметровки (PDF). Для неё я установил пороговое значение 0,05, потому что контраст между фоном и линиями слишком мал:

Цветовые кластеры:

Все вместе четыре PDF-файла занимают около 788 КБ, в среднем около 130 КБ на каждую страницу.
Выводы и будущая работа
Я рад, что удалось создать полезный инструмент, который можно использовать в подготовке PDF-файлов с конспектами для моих курсов. Кроме того, мне действительно понравилось готовить эту статью, особенно потому что она побудила меня попытаться улучшить важные 2D-визуализации, которые демонстрируются в статье Википедии о квантования цвета, а также наконец-то изучить three.js (очень забавный инструмент, буду использовать его снова).
Если я когда-нибудь вернусь к этому проекту, то хотелось бы поиграть с альтернативными схемами квантования. На этой неделе мне пришла в голову идея использовать спектральную кластеризацию на графе ближайших соседей в наборе цветов — мне показалось, я придумал интересную новую идею, но потом нашёл статью 2012 года, где предлагается именно такой подход. Ну ладно.
Ещё можете попробовать EM-алгоритм для формирования гауссовой модели смеси, которая описывает распределение цветов. Не уверен, что это часто делали в прошлом. Другие интересные идеи: попытка кластеризации в «перцептивно однородном» цветовом пространстве вроде L*a*b*, а также попытка автоматически определять оптимальное количество кластеров для данного изображения.
С другой стороны, нужно разобраться с другими темами для блога, так что я пока оставлю этот проект и предлагаю вам посмотреть репозиторий
noteshrink.py на GitHub.Примечания
1. Образцы конспектов представлены с великодушного разрешения моих студентов Урсулы Монаган и Джона Ларкина. ^
2. Показанное здесь изображение в реальности уменьшено до 150 DPI, чтобы страница загружалась быстрее. ^
3. Единственное, что наш копир хорошо делает, так это уменьшает размеры PDF до 50-75 КБ на страницу для документов такого типа. ^
4. Красный, зелёный, и голубой являются первичными цветами в аддитивной модели. Учитель рисования в начальной школе мог сказать вам, что основные цвета — красный, жёлтый и синий. Это ложь [метод упрощения сложных концепций в системе образования — примеч. пер.]. Однако есть три субтрактивных основных цвета: жёлтый, пурпурный и циан. Аддитивные основные цвета относятся к сочетаниям света (который излучают мониторы), тогда как субтрактивные цвета относятся к сочетаниям пигмента в чернилах и красках. ^
5. Изображение пользователя Maklaan в Wikimedia Commons. Лицензия: CC BY-SA 3.0 ^
6. Посмотрите в Википедии диаграмму с распределением чаевых как ещё один пример, почему полезно увеличение размера «корзины». ^
7. Изображение пользователя SharkD в Wikimedia Commons. Лицензия: CC BY-SA 3.0 ^
8. Почему k=7, а не 8? Потому что нам нужно восемь цветов в конечном изображении, а мы уже установили цвет фона… ^
9. Да, я смотрю на тебя, Image Capture из Mac OS… ^
Комментарии (47)

Mishootk
15.03.2018 16:49Из того что хочется получить от подобных программ:
1. Автодоворот картинки (при наличии регулярных ориентиров, например линейки, клеток, полей, краев листа, отверстий для сшивателя).
2. Выделение разметки (поля, линейки, клетки) и их автоприглушение, т.е. они должны остаться, но замениться неградиентным (единичным) цветом, слабым, неотвлекающим, но воспроизводимым при печати.
KvanTTT
15.03.2018 20:20- Автодоворот картинки (при наличии регулярных ориентиров, например линейки, клеток, полей, краев листа, отверстий для сшивателя).
Думаю материал моей статьи "Автоматическое выравнивание горизонта на фотографиях" поможет в этом.


Akon32
15.03.2018 16:56В своё время использовал для конспектов djvu — примерно 60кб на станицу A4 @ 400dpi. Там более продвинутое сжатие, и эта статья создаёт впечатление довольно примитивного велосипеда.
Однако png более распространён чем djvu, так что программка наверняка будет полезна.
P.S. надо бы попробовать выходные картинки сжать djvu.
Akon32
15.03.2018 17:12+1Забавно, djvu позволяет сжать примеры со ~120кб до ~40кб в нормальном качестве (20..110кб в разных вариантах), но дичайше искажает цвета (часть надписей фиолетовая, когда в оригинале они красные и синие).

diversenok
15.03.2018 22:09Это, вероятно, потому, что слой с цветами имеет меньший dpi. Вот, например, сжал страницу из статьи со 121 до 88 КБ. Из них 60 КБ ушло на маску текста и 25 КБ на цвета. Притом, если маска здесь 600 dpi, то цвета всего-то 50 dpi. Можно заметить как цвета с текста местами переползли на фоновую сетку. Но для сжатия конспектов с потерями не такой уж страшный эффект.
Картинка со сравнением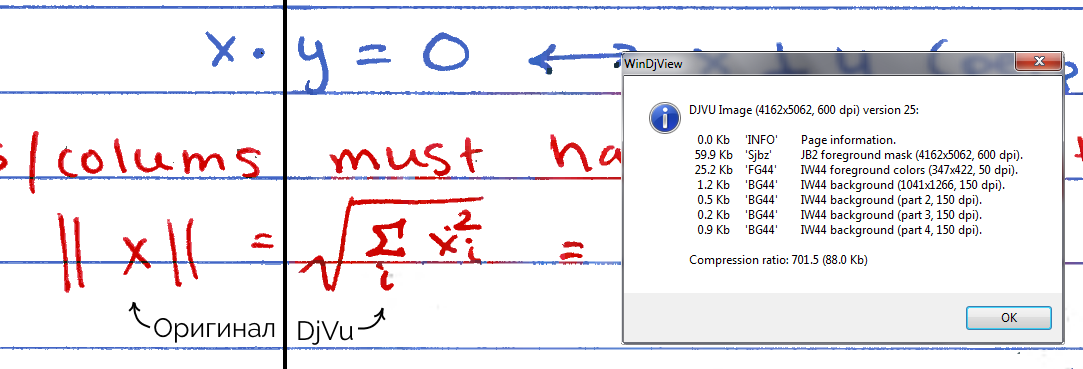
Картинка кликабельна. Если кто хочет поэкспериментировать — сжимал я это в DjVu Small в режиме «Drawn 200».
zartarn
16.03.2018 08:48Это же малоцветка, всего 8 цветов. Лучше другим профилем жать. Конечно вес уже не сильно меньше чем PNG, но качество лучше. (у djvu сегментатор все же под машинописный текст, а тут все делится на оч большие блоки, плюс много одних и тех же букв снова и снова добавлены в словарь)
Заголовок спойлера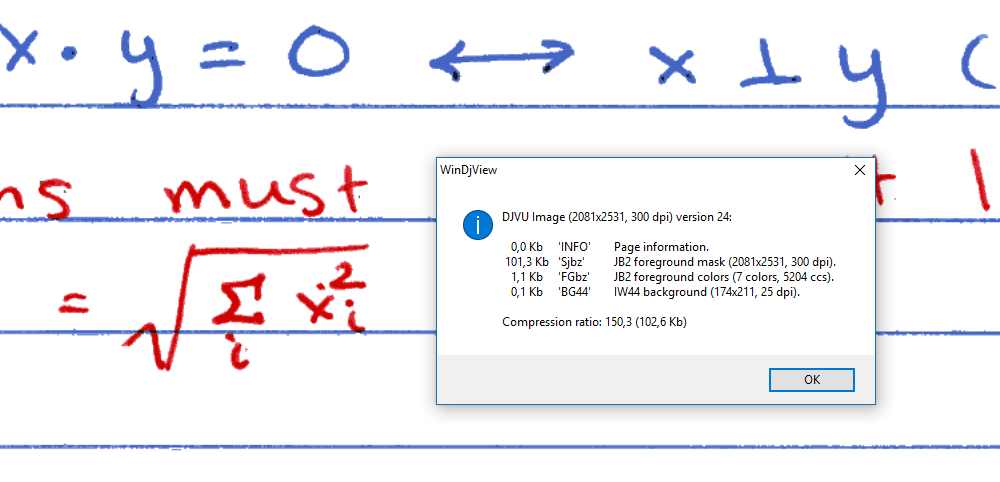
klirichek
15.03.2018 18:43+1Весь конструктивный смысл DjVu — выделить в изображении условные "слои" (исходя из того, что это не фотография, а именно скан распечатанного текстового документа). И потом пожать разные картинки разными методами.
В плюсе получаем малый размер файла.
Это всё давно известно, формат был крайне актуален >10 лет назад, поскольку на тот момент был практически безальтернативным.
Очевидное: ровно так же "по слоям" можно разложить банальный PDF. Вопрос только в том, как поделить на эти самые слои изначальный скан. И второй большой вопрос — чем пожать эти самые слои (у djvu свой собственный формат сжатия для разных целей, даже несколько!).
И вот нынче ситуация весьма поменялась. Jbig + Jpeg2000, упакованный в PDF = практически аналог (по эффективности сжатия) djvu, при этом с наиболее очевидной плюшкой в виде поддержки этого самого pdf практически в каждом утюге.
Я в своё время тоже использовал djvu.
А сейчас отлаживаю скрипт, который перепаковывает djvu в pdf с сохранением всех оригинальных плюшек, насколько это возможно. (помимо упомянутой "слоистости" сейчас уже копируется структура (оглавление), а также скрытый OCR-слой (если есть)).
Эффективность (для сравнения): 600-страничный 1-битный (ч/б) скан в современном pdf занимает 18.5Мб против 16.5Мб в djvu. И при этой разнице в размерах он гоораздо удобнее!
DonAgosto
15.03.2018 20:24Емнип, DjVu максимально эффективен для сканов печатных страниц, т.к. может сжимать за счет «словаря» картинок отдельных символов. Например, если на странице встречается 1000 букв «а» (очевидно набранных одним шрифтом), то в итоговый файл будет включена только одна «картинка» «а» и перечень координат на странице для остальных 999.
klirichek
16.03.2018 19:55Это лишь одна из технологий. Фон жмётся продвинутым аналогом jpeg, символьные изображения "распознаются" в словарь, причём сам словарь тоже внутри себя древовидный — например, букву "й" вполне способен сохранить не картинкой, а ссылкой на букву "и" + галочку. Кроме того, каждую букву (символ) на странице можно раскрасить в собственный цвет, и эта информация тоже очень эффективно жмётся.
Наконец, сам словарь создаётся не для каждой страницы, а для целой группы (в djvu мне в основном встречается 1 словарь на 10 страниц).
Идея такого "словарного" сжатия не нова; просто создатели djvu быстро "слепили" компрессор и начали продавать, пока никто не предложил аналог. А в то же время "гуру" создавали спецификацию для "официального" компрессора, работающего на этой идее (повезло, что lizardtech не догадались запатентовать эту идею как таковую). В итоге спецификация получилась очень большой и сложной, так что вариантов хоть какой-то реализации пришлось ждать несколько лет.
В наше время jbig-сжатие (то самое "официальное" сжатие со словарём, аналогичное djvu) уже реализовано; более того, это один из "стандартных" вариантов для pdf, поэтому поддерживается на каждой железке, понимающей соответствующую версию формата. Поэтому сейчас альтернатива есть, и она уже очень неплоха.
Иными словами — в pdf в наше время есть стандартный кодек, построенный на тех же принципах "словарного" сжатия, что и djvu. С очень близким коэффициентом сжатия. (просто подавляющее большинство интересующихся уже успокоились на том, что pdf не умеет хорошо сжимать. И очень многие просто не в курсе, что уже довольно давно, как МОЖНО!)
diversenok
16.03.2018 20:11Это очень хорошо, что pdf поддерживает такие вещи, но для меня, например, более важен практический вопрос: а какими программами всё это можно организовать? С djvu я знаю пару таких, которые самостоятельно разобьют скан на слои и сожмут. Есть что-нибудь похожее с pdf'ом?
klirichek
18.03.2018 06:27Именно о них и речь. Готовых "под ключ" я не нашёл.
Но нашёл, во-первых, pdfbeads (он создаёт "слоистый" pdf из заранее подготовленных картинок). + скрипт на ЛОРе для пережатия djvu (там автор взял jpeg2000 + CCIT4). Всё, что нужно — это скрестить этих "ежа и ужа". Чтоб не быть голословным: вот оригинал, вот результат. Но аппетит приходит во время еды — захотелось заодно переносить другую информацию, вроде меню навигации и OCR-слоя. Плюс — разобраться с многоцветными сканами djvu (где каждому "символу" назначается отдельный цвет — это тоже вполне жмётся в pdf, но pdfbeads делает это вроде как чрез тот же CCIT4, а хочется и это тоже переместить в jbig, если получится).
zartarn
16.03.2018 09:13У PDF есть свои проблемы. Просто текст в Jpeg2000 и потом CS неплохо (но не без проблем). А вот если еще иллюстрации малоцветные, или многоцветные, тут начинается свистопляска. PDF не дает возможности как то повлиять на их кодирование.
Я лучше чтоб некосноязычить, процитирую.
из темы Scan Tailor с руборда(цитирую часть, по ссылке больше) forum.ru-board.com/topic.cgi?forum=5&topic=32945&start=1780#15
Результаты (все — 300 DPI):
Растровый PDF JPEG — 475 КБ — качество сжатия* — JPEG 50%.
Растровый PDF JPEG2000 — 481 КБ — качество сжатия* — JPEG2000 25%, размер частей — 1024.
Adobe ClearScan — 219 КБ — качество сжатия* картинок — JPEG 50%, текст векторизован.
FineReader PDF MRC — 335 КБ — качество сжатия* картинок — JPEG2000 25%, бинарная маска — 600 DPI.
DjVu — 195 КБ — качество сжатия* картинок в IW44 примерно равно 82 по шкале LizardTech или 34 по шкале DjVu Libre, бинарная маска — 600 DPI.
* У JPEG, JPEG2000, IW44 — разные шкалы качества, ибо это разные алгоритмы. Например JPEG2000 50% будет намного превосходить по качеству и размеру JPEG 50%. Я подобрал параметры так, чтоб размер JPEG и JPEG2000 был одинаков.
Явный победитель по параметру качество/размер с большим отрывом — DjVu.
По порядку качества:
1) Djvu, FineReader PDF MRC — примерно равны по качеству. Лучшее качество из всех.
При просмотре текст и линие четкие, гладкие. Символы (буквы) точно соответсвуют исходнику — засечки букв не повреждены и не укорочены, толщина деталей символов точна.
Картинки в хорошем качестве, качество сжатия можно регулировать. (хоть без потерь вывести, в PDF — JPEG2000 — lossless, в DjVu — IW44 — качество бэкграунда 100 (LizardTech)).
Сегментирование регулироемое. (В PDF FR — анализ и коррекция областей в самом FR, В DjVu — метод раздельных сканов. Но FR лучше, он позволяет сегментировать и текст на самих картинках. Для DjVu очень ограничено — недостаток инструментов, хотя с соответсвующим инструментом возможно.)
2) Растровый PDF JPEG2000. При просмотре текст и линие гладкие, но уже не такие четкие, но достаточно хорошие. В местах с текстом вокруг символов есть еле заметные артефакты сжатия на фоне, но они столь незначительны, что не влияют на восприятие. Картинки в хорошем качестве.
Сегментация не требуется.
3) Adobe ClearScan.
При просмотре текст и линие четкие и гладкие. Но! Символы не соответсвуют исходнику — засечки букв повреждены и укорочены, толщина деталей букв неточна, есть ужирнения в некоторых местах букв, символы заметно искажены и потеряли детали из-за сильной аппроксимации (приближения, по-другому сглаживания), необходимой для векторизации. Символы кажутся расплытыми, у всех символов с округлыми границами («О», «C» и т.п.) видны острые грани, на крупных символах это особенно критично и заметно даже при 100% масштабе!
Картинки в среднем качестве, заметны артефакты сжатия JPEG (квадратики), настроить качество сжатия и выбрать более лучший JPEG2000 нельзя.
Сегментирование полностью нерегулироемое. Это означает, что надежда полностью на автоматический сегментатор от Adobe. Т. к. сегментирование задача еще нерешенная и сложная, автомат дает много искажений. Простые картинки вроде графиков, диаграм, геометрических фигур, стрелок, даже элементов в формулах и т. п. очень часто повреждаются до неузнаваемости. Нераспознаные сегментатором картинки идут в фон, где сильно даунсэмплится и сжимаются, становясь размытыми, полностью теряя качество. В дополнение картинки и формулы вообще могут пропасть (уйти за границу страницы), правда это можно откорректировать вручную, если заметить. Если фон предварительно не почистить, то даже небольшой мусор в бекграунде расплывается до больших размеров и становится заметным. Отдельно в этом режиме нельзя отключить автоматическую геометрическую коррекцию и поворот, которая иногда полностью искажает правильную страницу. И на примере видно, что тире в самом начале текста забрало в бекграунд и размыло — то есть потеря качества текста.
4) Растровый PDF JPEG. При просмотре текст и линии размыты из-за сильных артефактов сжатия. В местах с текстом вокруг символов есть заметные артефакты сжатия на фоне, фон поврежден и замусорен. Картинки в среднем качестве, заметны артефакты сжатия JPEG.
Сегментация не требуется.
Как видно, оптимальный размер дает только DjVu и PDF ClearScan. Когда задача сегментации сложна или вообще ручной труд не рационален (временные документы), подходит и PDF JPEG2000 или однослойный (Photo или псевдо) DjVu (IW44), но не PDF с JPEG, который все до сих пор юзают по неграмотности, делая большую ошибку.
ClearScan интересная технология, но на данный момент для практического использования не доработана. Нужна возможность ручной сегментации, настройки качества сжатия и даунсемпла изображений и бекграунда, возможность отключать автоматическую коррекцию геометрии и исправления багов вроде переноса элементов за границы страницы.
Максимум она годится для исправления исправления сильно деградированых документов или старых книг, с последующим экспортом в картинки в 600 DPI и ручным исправлением всех возникших косяков графическим редактором (их обычно очень много на научной литературе, проверено много раз).
Так что DjVu с нормальными ручными настройками (без даунсемпла бекраунда или даунсемплом его только до 300 DPI, предварительной обработкой исходника и апсемплом до 600DPI интерполяцией, чтобы текст был гладкий (бинарная маска должна быть 600DPI)) и метод раздельных сканов — лучшее, что есть на сегодня.
klirichek
16.03.2018 20:03Что значит "не даёт повлиять"?
PDF поддерживает слои! Поэтому никто не мешает жать аналогично djvu- фон с низким разрешением в jpeg2000 (кто там будет разглядывать отсканированную текстуру бумаги?). Текст (битмап) — в jbig. Один слой поверх другого.
В формате как таковом ограничений нет. Ограничения в инструментах: разделять надо уметь!
Я почему взялся за перепаковку — потому что там всё УЖЕ разделено, просто нужно извлечь из оригинального djvu эти самые слои, и пожать их правильными кодеками в pdf. Получается файл практически того же размера, но при этом существенно более дружественный ко многим устройствам.
Вот если брать свежий скан и искать программу с единственной кнопкой "сделать правильно" — там да, борьба производителей. А если потратить время и разметить вручную, то проблема качестве практически исчезает.zartarn
16.03.2018 22:12Вы настолько поспешно судите, что даже спойлер мой не открыли. Там тест был на разбитом на сегменты сканы, почищеном, приведеном в порядок. Приплели сюда какую то одну кнопку (DjVu по одной кнопке из сканов получится кака ничем не лучше, а то и хуже чем PDF).
А еслиб прошли по ссылке, увидели бы, что автор поста, разработчик Scan Tailor Advanced. Эти тесты он делал, потому что сам изначально топил за PDF, и хотел написать даже свой PDF компрессор «по технологии MRC скорее всего c Multi-COS/CCC сегментацией». Но отказался от этого дела (если интересны мотивы и аргументы «до» и «после», можите в теме найти: «версия для печати» и ищите сообщения от «4lex4». (изначально его аргументация совпадала с вашей, там даже больше плюсов перечислялось)
Я делаю PDF, только если у меня полностью LaTeX\исходники на руках, или распознал всю книгу вычитал и плевать на типографику. Если же работа идет со сканами, по вес/качество/скорость — выигрывает DjVu. Даже при условии уже вычещеных файлов, разбитые на малоцвет и иллюстрации (SknKromsator или SkanTailor), собранный DjVu будет сделан быстрее, проще, более контролируемый в процессе и в читалках работать не так тормознуто как PDF, чем из этих же файлов сделанный PDF.
Да и каким софтом PDF собирать? У вас есть на примете хороший некомерческий которым удобно пользоваться? Если есть поделитесь, интересно послушать, я про такой не слышал.
А InDesign — это «по воробьям из пушки» (и то потом куча телодвижений еще надо сделать чтоб получить качественный выходной файл).
Я не хейтю формат, я много разных пробовал, и остановился в итоге на: fb2 — худлит, PDF — из исходников, DjVu — из сканов.
П.С.: про контроль, есть DjVu Small Mod — там есть предустановленные профили, уже подогнанные под конкретные случаи. Но программа работает с кодером, которому можно задавать просто чуть ли не любые параметры. Только тут уже разбираться долго и сложно. в DSM уже оч оптимальные профиле с возможностью доводки.
П.П.С.: Я с последними сканам сам хотел сделать вариант DjVu и PDF, но после очистки и подготовки сканов, увидел, что создать PDF это потребует усилий и времени не меньше чем я потратил уже на эти 800 страниц :).klirichek
18.03.2018 06:17Ну речь снова о том же — софт для создания pdf не очень хорошо умеет делить материал на эти самые слои. Создатели djvu постарались в этом плане лучше.
Сейчас пытаться сделать что-то подобное — это по сути переизобретать алгоритмы djvu (не алгоритмы сжатия, а именно алгоритмы сегментирования). И именно это собственно и есть тема вашей ветки форума.
Но! — и я снова возвращаюсь к той же теме — никто не мешает воспользоваться результатом работы софта djvu и сделать на его основе pdf. Не "тупо распечатать на ps-принтер", а именно распаковать слои и каждый пережать соответствующим кодеком (jpeg2000, jbig). Элементарные воркеры для этого давно есть (unix-way), нужно только собрать скрипт.
zartarn
18.03.2018 11:45Сейчас пытаться сделать что-то подобное — это по сути переизобретать алгоритмы djvu (не алгоритмы сжатия, а именно алгоритмы сегментирования)
Собственно CS это и есть попытка это сделать. В чемт о удачная, а в чем то оч проблемная.
Собственно из за многих мелочей от этой идеи и отказались в пользу DjVu.
«тупо распечатать на ps-принтер»
Я это никогда и не считал за «сделать PDF» :) Это прото PDF как контейнер для тяжелых картинок получится.
Остальное в лс.
Judgman
15.03.2018 18:14Мдаа, вот это препод.
У нас преподаватель максимум — написал программу для тестирования, которая сохраняет результат в текстовый файл, который потом ручками можно поправитьMarui
15.03.2018 19:07Сложное давать нельзя. Сложное оскорбляет чувства неосиляторов.
Простое давать нельзя. Простое оскорбляет чувство осиляторов.
На кого ориентироваться преподавателям? Идите к местный кружок олимпиадников. Там это всё будет.
akryukov
16.03.2018 10:01Сформируйте программу и идите по ней. Помогайте неосиляторам чем можете, но не задерживайтесь на темах больше чем запланировали. Дайте сложные необязательные задания, чтобы занять осиляторов.
DSolodukhin
15.03.2018 18:37Автору безусловно респект и уважуха, проделана хорошая работа.
Со сканами рукописного текста никогда не работал, не приходилось, но для сканов книг мне очень понравился Scantailor — умеет в очистку изображения от шума, автоповорот изображения, выравнивание текста (например, при сканировании разворота книги текст, расположенный близко к переплету искажается) и т.д. Плюс ко всему свободное и кросплатформенное ПО.Tsvetik
15.03.2018 19:52К сожалению, ST больше не обновляется и умеет хорошо «чистить» только ЧБ изображения.
Описанный автором алгоритм очень хорошо бы встроился в ST для обработки цветных сканов

UksusoFF
15.03.2018 21:06Жаль что без GUI.
Есть вот еще несколько программ для похожего, но они уже давно не развиваются:
http://scantailor.org
https://ru.wikipedia.org/wiki/ScanKromsatorzartarn
16.03.2018 23:14ST — сейчас активно разивается форк STA (тема на руборде общая) github.com/4lex4/scantailor-advanced
SK — пилится, разработчик принимает багрепорты, но релизы крайне редко (всё на руборде).

Color
15.03.2018 23:31Они там что, гуманитариев естественным наукам обучают, или просто тетради в клетку не завезли?

Faramant
16.03.2018 11:21Уже давно применяю такой финт в программе IrfanView:
- Открываю в ней полноцветный скан.
- Уменьшаю количество цветов до 16 (Decrease color dept).
- Редактирую полученную палитру, заменив самый светлый цвет на чисто белый (Palette -> Edit palette...).
- Сохраняю в PNG.
advan20092
16.03.2018 13:31Пишу в Myscript nebo. Можно сразу распознавать или оставить рукописный текст. Есть поиск по рукописному тексту, каталогизация и прочие радости. Статья конечно крутая, но актуальность данной технологии все же под вопросом.
Z-StyLe
16.03.2018 15:21А если представленный в качестве примера в статье PNG весом 123,7кб отправить в TinyPNG, то получится и вовсе малый размер — 113,9 кб.
dinisoft
18.03.2018 14:57И никого не смутило содержание самих сканов?
Обратная матрица не равна транспанировонной.




Meklon
Крайне полезная штука, спасибо.