

[UPD 2] Команда Pain Gaming победила OpenAI Five. Матч длился 53 минуты и закончился со счетом 45-41 по фрагам в пользу ботов. Запись игры можно посмотреть на Twitch тут. Начало на 7:38:00
Сегодня вечером, 22 августа, перед началом очередного дня плей-офф The International, в рамках шоу-активностей пройдет первый показательный матч между профессиональными игроками и ботом OpenAI Five. Информация о матчах появилась на официальном сайте Dota 2 в разделе с расписанием игр плей-офф The International. Всего OpenAI сыграет три матча за три дня с про-игроками.
Знаменательно это событие тем, что год назад бот уже «расправился» Даниилом Ишутиным в противостоянии 1x1 solo mid mirror SF, а несколько недель назад одолел «сборную солянку» из комментаторов и бывших про-игроков.
На этот раз разработке компании, которая спонсируется Илоном Маском и другими видными бизнесменами из IT-сектора предстоит встретиться с более серьезным противником: The International ежегодно собирает лучшие команды мира, так что ботам будет непросто. Пока команда разработчиков не сообщала, будут ли действовать все старые ограничения по пикам и механикам, которые были актуальны в игре против людей в начале месяца, но о них стоит напомнить.
- пул из 18 героев в режиме Random Draft (Axe, Crystal Maiden, Death Prophet, Earthshaker, Gyrocopter, Lich, Lion, Necrophos, Queen of Pain, Razor, Riki, Shadow Fiend, Slark, Sniper, Sven, Tidehunter, Viper, или Witch Doctor);
- без Divine Rapier, Bottle;
- без подконтрольных существ и иллюзий;
- матч с пятью курьерами (ими нельзя скаутить и танковать);
- без использования скана.
В комментариях к нашей прошлой публикации на эту тему разгорелось множество споров о методах обучения нейросетей. На этот раз мы принесли немного наглядных материалов о том, как работает бот OpenAI и как это выглядит с точки зрения людей.
Разработчики заявляли, что благодаря серьезным вычислительным мощностям, огромному количеству записей и возможности запускать обучение в несколько потоков, ежедневно OpenAI имитировал до 180 лет непрерывной игры в Dota 2. Очевидно, что обучаемость этого ИИ на многие порядки ниже, даже чем у не самых «умных» животных, не говоря о собаках или высших приматах, к которым относится и человек.
Для обучения OpenAI команда использовала собственную разработку под названием Gym (репозиторий на github, официальная документация). Эта «качалка» совместима с любой публичной библиотекой, например TensorFlow или Theano. В обучении нейросетей в рамках Gym используется классическая петля «агент-среда»:

Разработчики заявляют, что любой желающий может использовать Gym для обучения своей нейросети игре в классические тайтлы для Atari 2600 или другие относительно простые для понимания проекты. Очевидно, что скорость обучения напрямую зависит от объема задействованных в этом ресурсов. В качестве примера разработчики OpenAI научили нейросеть играть в Montezuma’s Revenge.
Но наибольший для нас интерес представляют второй и четвертый этапы — действие и анализ результата (награды за действие). А в контексте Dota 2 уровень вариативности просто зашкаливает, а изначально оцененные ботом действия как «правильные» на длинной дистанции могут привести к проигрышу.
Как команда OpenAI учила ИИ играть в Dota 2 с точки зрения оборудования
К вопросу обучения OpenAI игре в Dota 2 команда разработки подошла более чем серьезно. Полный официальный репорт в блоге проекта вы можете прочитать тут, мы же приведем основные выдержки по технической части и реализации без маркетинга и прочих реверансов.
Наибольший интерес у комментаторов прошлой публикации вызывала мощность, потребляемая нейросетью OpenAI для обучения. Очевидно, что парой Ryzen дело там обойтись не могло, особенно в контексте имитации 180 лет игры в реальные сутки. При этом бот для Dota 2 — это вам не бот для шутера уровня Quake, что очень четко подметил пользователь yea в ответ одному из скептиков:
Мне кажется, вы просто слабо себе представляете размеры тактического простора в доте, потому что слабо знакомы с самой игрой. Нет никаких шансов сделать ботов без привлечения нейросетей, ограничиваясь хоть сколько-нибудь вменяемыми вычислительными ресурсами. Серьезно. Это не Quake, где можно быть полным дубом в плане тактики, компенсируя это нечеловечески быстрыми выстрелами в репу из рельсы. Идеальные в плане реакции и механических скиллов боты, не умеющие играть впятером и не «чувствующие карту», обречены против сколько-нибудь умелых мясных игроков.
Кроме того, дота — игра с неполной информацией, и это кардинально усложняет задачу. Задача «что делать, когда я вижу врага» намного проще, чем задача «что делать, когда врагов не видно» — не только для машин, но и для людей.
Это четко понимали и разработчики OpenAI, так что для обучения ботов были задействованы тысячи виртуальных машин одновременно. Конкретно такие цифры приводит официальный блог проекта для обучения бота 1х1 Solo Mid, способного с некоторыми ограничения победить в миде Даниила Ишутина, и для обучения полноценной команды для игры 5х5:
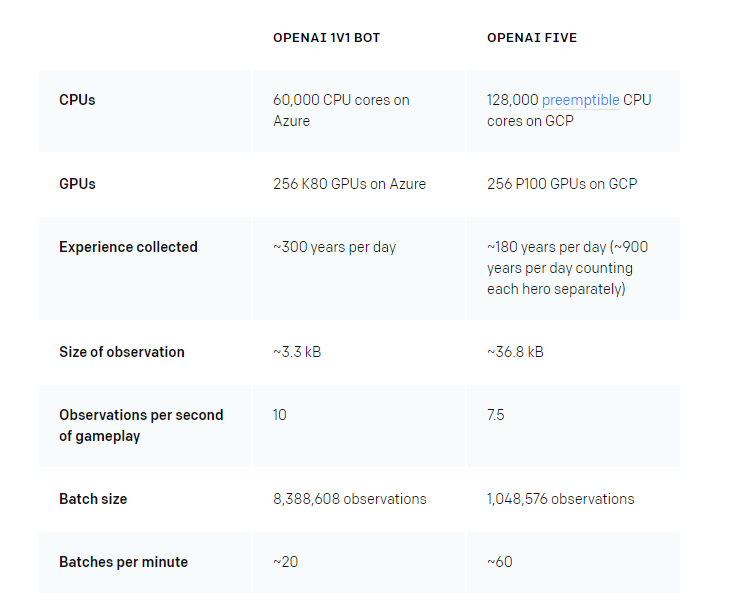
Это не десятичная запятая. Для обучения OpenAI в режиме 5х5 постоянно используется 128 тысяч процессорных ядер Google Cloud. Но и это еще не вся мякотка. Так как в обучении бота OpenAI используется машинное зрение (о котором мы поговорим чуть позже), в этой чудовищной конфигурации фигурирует еще 256 GPU P100 NVIDIA (Tesla accelerator).
Согласно официальной брошюре NVIDIA, P100 обладает следующими характеристиками:

Официальная стоимость одной P100 Tesla 12 GB PCI-E составляет около 5800$, Tesla P100 SXM2 16GB стартует от 9400$. В OpenAI используется как раз старшая модель SXM2. Нужны видеокарты не для отрисовки «графики» на виртуальных машинах, а обработки и вычисления данных, которые постоянно поступают из всех запущенных партий. Для обработки этого потока команде пришлось развернуть целую систему нод, в рамках которой и работают P100 Tesla. Видеокарты обрабатывают и вычисляют полученные данные, чтобы потом выдать усредненный по всем партиям результат и сравнить его с прошлыми показателями OpenAI.
Подобные мощности позволяют имитировать нейросети около 60 партий в минуту, за каждую из которых нейросеть анализирует около 1,04 млн циклов агент-среда, упоминаемых ранее.
Как OpenAI видит игру
Деньги — пыль, если они у вас конечно же есть. Даже самые приблизительные прикидки стоимости одного дня обучения OpenAI вызывают легкий шок, а выделяемого на серверах Google Cloud тепла хватит для отопления небольшого города. Но намного интереснее, как OpenAI «видит» игру.
Понятно, что графическая отрисовка ботам не нужна, но такие мощности используются не просто так. Бот в своих действиях опирается на стандартный API Valve для ботов, через который нейросеть получает поток данных об окружающем пространстве. API нужен для того, чтобы полученные данные прогонять через однослойную LSTM-сеть из 1024 блоков и получать, как итог, краткосрочные решения, которые согласуются с долгосрочными стратегиями, которыми располагает нейросеть.
LSTM-сети определяют приоритет задач для бота «здесь и сейчас», а в согласовании с долгосрочной моделью поведения нейросети выбирается наиболее выгодное действие. Например, боты охотно концентрируются на ласт-хите крипов для заработка золота и опыта, что согласуется с моделью получения долгосрочной выгоды в виде предметов и последующего преимущества по игре.
По информации от разработчиков, все партии происходят с отрисовкой событий на карте с частотой в 30 FPS. Нейросеть OpenAI постоянно анализирует каждый кадр через LSTM, на основе результата которого принимает дальнейшие решения. При этом бот имеет свои приоритеты: самому тщательному анализу подвергаются все возможные взаимодействия с окружением через специально выделенные области «зрения» бота — это квадраты 800х800, поделенные на 64 ячейки 100х100 (за размер взяты значения внутриигровой дальности действия и перемещения, а размер квадрата составляет 8х8). Вот как бот частично «видит» игру на одном конкретном кадре:

Полный конструктор с возможность переключения действий, оценки размера квадратов и прочими возможностями «покрутить настройки» доступен в официальном блоге разработчиков в разделе Model structure
А вот так выглядит визуализация работы LSTM-сети в плане прогнозирования игровых событий в режиме реального времени:
Кроме LSTM и оценки ситуации «здесь и сейчас» бот OpenAI постоянно пользуется сеткой «прогнозирования» и расстановки собственных приоритетов. Вот так это выглядит для людей:

Зеленый квадрат — область наивысшего приоритета и текущего действия бота (атака, перемещение и так далее), Светло-зеленый квадрат обладает меньшим приоритетом, но бот в любой момент может переключиться на этот сектор. Еще два серых квадрата — зоны потенциальной активности, если ничего не изменится.
Посмотреть, как бот «видит» игру и принимает решения на основе этих четырех зон можно увидеть на видеозаписи ниже:
Стоит отметить, что области приоритетов бота не всегда находятся рядом с моделью персонажа. При перетяжке по карте все четыре квадрата легко смещаются за несколько экранов от текущего положения бота, то есть OpenAI анализирует одновременно все игровое пространство на доступность и целесообразность каких-либо действий, а не только один экран.
OpenAI постоянно играет сам с собой. При этом 80% ботов обучаются, а 20% используют уже отработанные тактики и стратегии. Такой подход позволяет нейросети учиться на собственных ошибках, находя уязвимые паттерны в собственно поведении и одновременно закреплять удачные модели поведения.
Уже завтра. Люди-профессионалы против машины
Вместо итога стоит вернуться к теме завтрашнего противостояния между профессиональными игроками и OpenAI.
Пока неизвестны детали, однако с уверенностью можно сказать, что нейросети придется несладко. В отличие от прошлых своих противников, OpenAI столкнется с лучшими из лучших, а возможность маневрирования и командного взаимодействия в рамках шоу-матча позволит людям полностью раскрыть свой потенциал. Формат Solo Mid 1x1, конечно, крайне зрелищный, однако не раскрывает всей сути игры и крайне нетерпим к микро-ошибкам, которые люди зачастую допускают.
Весь вопрос в том, насколько серьезно к этому противостоянию отнесутся профессионалы. При появлении какой-то дополнительной информации публикация будет обновляться.
Комментарии (332)

Desavian
21.08.2018 15:42Вопрос только в ограничениях. Их можно закрутить настолько, что любой суперпрофессионал отлетит без шансов.
Если останется тот же пул героев и те же ограничения и матч будет бо3, то первую игроки сольют, даже ликвиды, а вот вторую и третью уверенно заберут ибо им требуется меньше времени для понимания слабых мест ботов. Если же текущие слабые места, которые были продемонстрированы не уберут — про игроки просто сконтрят по всем фронтам и все.
Танкуете башни вардами? Ловите рики, который будет топориком их чистить, не давая возможности скомпенсировать траты на варды и плевать что он не в мете, против ботов покатит.
Умеете считать урон? Игроки раскидают тучу мгновенных лечилок, которые будут подбирать с земли когда совсем все плохо и когда надо убежать, чтобы бот-снайпер, запулив ультимейт, не прошел бы по урону из-за прожатой меки, лежавшей в курьере…
Пытаетесь зонить и рубить фарм? Игроки вардами заблочат весь лес и будут убивать всех, кто попытается этому помешать… да много чего, против чего не помогут ни тысячи лет игр, ни запредельная реакция…siziyman
21.08.2018 17:07По большому счёту, согласен, маленькая ремарка только — теорию про «танчить башню вардами» уже давно отмели, потому как у вардов максимально низкий приоритет «агрессии» (только для башен или для вообще всего ИИ крипов это тоже работает — не помню) — как и катапульты, башни начинают их обстреливать, только если больше потенциальных целей вообще нет. То есть герои попали бы под удар раньше.
Desavian
21.08.2018 18:01Рискую спалиться как дотер, но попытаюсь объяснить на пальцах суть трикса с вардами.
Если бы приоритет у вардов был равный с крипами — эту штуку во всю бы использовали не только в про играх, но и в обычном ранкеде. Изюминка того, что делали боты, в другом.
Башня имеет строго определенную частоту выстрелов, боты ставили варды таким образом и с такой точностью, что крипы заходили в радиус поражения _сразу_ после выстрела по нему башни, таким образом крипы не получали урона все время, требуемое на ее перезарядку. Объяснил сумбурно, но если пару раз перечитать — станет понятно, почему для подобного требуется чудовищный тайминг и почему это именно прерогатива ботов.
Когда же бот, дождавшись выстрела по варду, заходил в зону поражения, стрелял и выбегал до следующего выстрела, у меня вообще глаза чуть не вытекли, обычный игрок не способен подобное повторить просто из-за скорости реакции «глаз-рука», даже под медикаментами быстрее 0.07-0.08 не выжать, а ведь там надо не только среагировать и кликнуть, но и мышью двинуть. Так что 200мс это слишком быстро для ботов… надо их еще замедлять.Druu
22.08.2018 03:31даже под медикаментами быстрее 0.07-0.08 не выжать, а ведь там надо не только среагировать и кликнуть, но и мышью двинуть. Так что 200мс это слишком быстро для ботов… надо их еще замедлять.
Скорость поворота на 180 градусов сама по себе около 200мс. Так что 0.07-0.08 не нужно, герой команду выполнить не успеет.
Desavian
22.08.2018 09:44Именно, я имел ввиду что даже сведя скорость реакции глаз-рука до биологического минимума, все остальные операции займут больше времени чем общая скорость реакции бота(а ведь он постоянно с такой скоростью работает, а не при пиковых нагрузках). Скорость поворота в доте, кстати, величина не постоянная, модифицируется способностями/вещами и да, боты фейзы под это дело тоже использовали, что нормальному человеку даже в голову бы не пришло.
Druu
22.08.2018 10:08Именно, я имел ввиду что даже сведя скорость реакции глаз-рука до биологического минимума, все остальные операции займут больше времени чем общая скорость реакции бота
Реагировать не надо, надо просто делать последовательность кликов с нужным паттерном. Вы как думаете 16-е ноты в престо играют?
Desavian
22.08.2018 10:22хм) но музыкант _знает_ какой паттерн использовать, а игрок должен его выбрать на основании текущей ситуации, крипы не бегут по одной линии, их порядок не всегда одинаков и прибегают к башне они в разное время.
На самом деле проблема гораздо глубже и объяснять ее тем, кто не знаком с глубокой механикой игры еще сложнее.
Например есть в игре такая вещь как Lotus orb, при использовании которой на цель вещается щит, зеркально отражающий вражеские заклинания. Обычный игрок, даже высокого уровня, может провесить этот щит на себя или союзника когда есть опасность попасть под опасное точечное заклинание. Очень хороший игрок может среагировать и сделать это, когда вражеское заклинание уже летит, чтобы враг не мог среагировать и его отменить. Так вот боты это делают с тем же временем реакции в 200, тут был мат, миллисекунд. Что происходит в результате: игрок выпустил оглушающую стрелу, видит что оппонент сейчас будет оглушен, начинает комплекс дальнейших действий (начать убивать врага, помочь своим игрокам, сбежать, еще что-то). И тут, за 200 миллисекунд до попадания оглушения в противника, на него вешается отражающий щит. И всё, гаплык, человеческой реакции уже ни на что не хватит. Да, обычные игроки могут подобное проинтуичить и сделать, да такие моменты порой выигрывают проигрышные игры. Но боты это делают всегда, в 100, блин, процентах случаев.Druu
22.08.2018 10:34хм) но музыкант знает какой паттерн использовать, а игрок должен его выбрать на основании текущей ситуации, крипы не бегут по одной линии, их порядок не всегда одинаков и прибегают к башне они в разное время.
Мы же рассматриваем тут конкретный хитрый прием? Когда персонаж равномерно, в соответствии с выстрелами товера, вбегает/отбегает. Тут вполне себе конкретный и четкий паттерн, нет?
На самом деле проблема гораздо глубже и объяснять ее тем, кто не знаком с глубокой механикой игры еще сложнее.
Я знаком с механикой игры :)
Так вот боты это делают с тем же временем реакции в 200, тут был мат, миллисекунд.
Не раз делал инстахекс после блинка противника, даже не за 200мс, а за 0. Реакция уровень бог, видимо ;)
А иногда и вовсе инста-глобал сайленсером получается! Не иначе, тахионы в действии, ведь чтобы так сделать — надо нажать сайленс еще до того, как противник блинкнулся.
Наверное, именно по этой причине одно из известных правил — сперва бкб, потом блинк, не наоборот :)
И тут, за 200 миллисекунд до попадания оглушения в противника, на него вешается отражающий щит.
Ну вот возьмем стан свена, у него 0.3 сек анимация, и потом еще прожектайл летит. Уметь в таких случаях среагировать и заэвейдить стан мантой — вобщем-то навык, входящий в инструментарий любого профессионального игрока. Если речь о том, чтобы успеть лотус орб — игрок с такой ответственностью должен с-но следить за ситуацией вокруг своего керри и ожидать подобных вещей. Это его задача.
Но боты это делают всегда, в 100, блин, процентах случаев.
Обсуждаемые боты смоком по герою в шедоу амулете мажут, и кидают по две шрапнели в одно место :)
В общем, ваш тезис, конечно понятен, но длительные анимации большей частью нивелируют описанные вами проблемы. Наиболее сильно они проявляются как раз при том же хексе и других мгновенных кастах — ну как раз потому что они мгновенные. Но такие скилы — вобщем-то исключение.
Desavian
22.08.2018 11:13У ботов нет проблемы «дебил нафиг ты лотус провесил, я ж манту прожал» ))), но это так, отступление. В целом ваша мысль тоже понятна, но я бы аргументированно поспорил про то, что инстакаст абилок слишком мало, чтобы вносить серьезный импакт в разрезе ботов. Тот же раста или лион с полиморфом, идеально оттаймленый ульт табуретки, да епрст)) разработчики сказали что они из пула героев джагу убрали по причине имбовости, так как боты идеально считали прыжки и разводили урон по нескольким целям идеально подходя в радиус прыжков, побоялись что игроки челюсти поднять не смогут после этого. Так что у меня вообще появилась дикая мысль что боты давно умеют играть всем пулом героев, просто разрабы боятся что дота сдохнет как шахматы, если все увидят что умеют боты на самом деле. Я все сильнее начинаю думать что гифка, в которой Лич форсстафит одного врага и прожирает вражеского крипа мидасом, чтобы ульта отскочила в того, кого нужно, была сделана с openai бота.
С другой стороны лично был свидетелем как убивали уходящего крипа, чтобы рики после ульты не мог на него выблинкнуться, так что кто его знает, люди тоже иногда играют на невообразимом уровне.Druu
22.08.2018 11:36У ботов нет проблемы «дебил нафиг ты лотус провесил, я ж манту прожал» )))
Ну, у этих есть, т.к. они не вступают в коммуникацию и не предсказывают действия друг друга. С-но в тех играх что были не раз можно было наблюдать "лишние" действия.
разработчики сказали что они из пула героев джагу убрали по причине имбовости, так как боты идеально считали прыжки и разводили урон по нескольким целям идеально подходя в радиус прыжков
Джагернаут же рандомно цель в радиусе выбирает, чтобы получилось "развести ульту" — это надо героев расставить заранее специально и чтобы они не двигались. Так что какая-то фиговая отмазка. Где вы вообще это прочитали?
Я все сильнее начинаю думать что гифка, в которой Лич форсстафит одного врага и прожирает вражеского крипа мидасом, чтобы ульта отскочила в того, кого нужно, была сделана с openai бота.
Очень маловероятно, что текущие боты смогут так делать хоть когда-нибудь. С-но даже просто толкнуть форсой под ульт для ботов данной архитектуры — уже где-то на границе возможного.
Чтобы делать то, о чем вы говорите, надо сетью определять набор таргетов, а потом подбирать исполнение нужного уже перебором по действиям (или, возможно, другой специальной сетью для "микро").Desavian
22.08.2018 12:22Да уже жалею что не делал подборку тем на реддите, где все это обсуждалось, не думал что на хабре тема появится =(. По поводу джаги, врать не буду, возможно криво перевел, но я так понял что боты считали количество прыжков и скидывали прыгающего юрика на тиммейта, уходя например в инвиз, при этом в радиус прыжков заходил второй толстый игрок, для уменьшения шанса прыжка на третьего. То есть механика то всем известная и всеми используемая, штука была в том, что боты точно считали количество прыжков и распределяли урон с минимальными последствиями для себя, что для игроков возможно только интуитивно и приблизительно, учитывая 400мс времени между ударами.
Druu
22.08.2018 12:27но я так понял что боты считали количество прыжков и скидывали прыгающего юрика на тиммейта, уходя например в инвиз, при этом в радиус прыжков заходил второй толстый игрок, для уменьшения шанса прыжка на третьего.
А, в смысле они от вражеского джаги урон распределяли. Ну вообще не вижу тут ничего особенного, у кого много хп — становится под джагу, у кого мало — отходят :)
Кстати, ульт лича, считай, по той же схеме работает и его можно так же эффективно эвейдить (причем тут боты находятся в более выигрышном положении — т.к. из-за того что ульт летит медленно, можно не только расчитать прыжки, но и успеть подойти/отойти, что в случае джаги из-за скорости может быть просто нереализуемо физически), но лич в пуле.
Desavian
22.08.2018 12:36У лича прожектайл медленнее летит, может с этим что связано, ну да сегодня первый матч, появится куча новой информации и аналитики, будем посмотреть, чему там боты научились.
Druu
22.08.2018 12:49У лича прожектайл медленнее летит, может с этим что связано
Так это как раз дает лишнее преимущество. То, что прожектайл летит медленнее, не поможет людям рассчитать оптимальный разбег — люди что от джаги, что от лича одинаково разбегаются :)
А вот ботам поможет этот "идеальный разбег" исполнить.Desavian
22.08.2018 14:46ну должна же быть причина?:) остальные то абилки джаги ничего уникального из себя не представляют… вард разве что?
Deerenaros
22.08.2018 12:33Вы статью то читали? Боты вполне себе оперируют всеми таргетами, да чёрт, это ну ничерта не проблема: есть конкретное API, тут не надо никакого компьютерного зрения, хотя, по большому счёту, его прикрутить не такая проблема (и к слову, текущая ситуация значительно улучшает положение ботов — по сути у них полтора экрана область действия, тогда как для игроков такой хак по сути — чит).
Ещё вопрос с коммуникацией. Нигде не сказано, что они не общаются, а даже намекают на обратное, но в принципе, даже если этого изначально не предусмотрено, боты вполне могут выработать стратегию — есть манта — не прожимаю орб; да и в принципе создавать более сложные паттерны общения используя доступную игровую механику не является невероятным. Вообще, слабые места ботов разработчики видели и слабо вериться, что они их не пофиксят.
Вы постоянно говорите про архитектуру, но основная проблема в том, что архитектура не статична. Нейросеть — это контейнер, аналоговый вычислитель эмулированный на ПК, если грубо. Какая в него программа заложена определяется обучением. И тут нет никакой магии. Вообще, вспомним AlphaGo: по мере продвижения по турнирной лестнице его возможности росли невероятно, практически полностью устраняя слабые места. Вообще, сама по себе AlphaGo именно что сама придумала огромное число новых паттернов, а в среде го-игроков до сих пор идут разборы матчей с AlphaGo.
По поводу механики игры, тут тоже есть над чем подумать. Неограниченная реакция и потрясающий контроль даёт просто невообразимые тактические возможности. Если человеку приходится полагаться на то, что он видит и свою скорость реакции, то у нейросети таких проблем нет. Если очень грубо, то полноценный запуск всего цикла енва -> обс -> агент -> акт на каждый кадр это тоже самое, что если бы для вас останавливали время 30 раз в секунду. Вообще говоря, это очень сильно.
Да, у нейронных сетей есть проблемы, но Маск, мне кажется, хочет просто продемонстрировать насколько опасен может быть общий ИИ: даже настолько простой, практически на коленке собранный способен демонстрировать практически неоспоримое преимущество перед людьми. Наверняка есть герои, которые будут показывать просто невероятный импакт (зевс, тинкер, шторм — они могут овнить героев противника на раз два, практически закапывая команду противника, а какой-нибудь профет и чен или даже дроу спушить все вышки за 10 минут). Тут дело практически в тотальным контроле своего здоровья, здоровья противника, очень сильной реакции и крайне неожиданные стратегии и тактики. Вообще не могу представить, какую дичь они могут творить с невероятной мобильностью той же фуры или какой-нибудь магины.
Абуз вардов это вершина айсберга. Дота не идеальна, очень далеко не идеальна: вспомните тот же хук нави. В огромном пуле героев найдутся довольно легко крайне неожиданные связки на незапланированных механиках. И не забывайте, что именно этим и занимается нейросеть — это статистика предыдущего опыта. Условно — эффективные и неэффективные стратегии. Эффективные используем, а противника заставляем использовать неэффективные (растрата ресурсов на консумабл — одна из них, брать неметовых героев против которых легко противодействовать к этому же; тысячи их).Druu
22.08.2018 12:46Вы статью то читали? Боты вполне себе оперируют всеми таргетами, да чёрт, это ну ничерта не проблема
Вы видимо не поняли. Боты не работают в стиле: "выбираем наиболее полезный таргет (например — убить персонажа Х) -> расчитываем действия для выполнения (окей, нашли последовательность действий — кинуть ульт, толкнуть форсой, съесть крипа мидасом) -> выполняем", вместо этого боты просто принимают на вход некоторое состояние, прогоняют его через нейросеть и получают действие, которое надо совершить (которое, как показывает обучающая выборка, приводило в итоге к росту вознаграждения). По-этому если бот не оказывался в такой ситуации с поеданием крипа и форсой (или какой-то похожей) — то он никогда ее и не повторит. Он просто не догадается, что такие действия могут привести к какому-то профиту, и, с-но, их не сделает.
Ещё вопрос с коммуникацией. Нигде не сказано, что они не общаются
По-моему, разработчики вполне четко говорили, что боты не общаются.
Да, у нейронных сетей есть проблемы, но Маск, мне кажется, хочет просто продемонстрировать насколько опасен может быть общий ИИ: даже настолько простой, практически на коленке собранный
Чего, прошу прощения? Это одна из самых мощных нейросетей, существующих в мире на данный момент (точнее будет сказать, одна из потребивших наибольшее количество флопсо-часов). Какое простой на коленке собранный?
И Маск там, кстати, уже давно не при делах.Deerenaros
22.08.2018 13:40Вы, наверное, не понимаете к чему я веду. Блин, оперируя "статистическая машина" можно догадаться, что это обычная нейросеть.
Но. Во-первых, там тем не менее под капотом классическая стейтмашина. В том плане, что нейросеть не придумывает варианты, она выбирает из пула вариантов. Эти варианты довольно низкоуровневые, но тем не менее в нейросеть уже заложены понятия позиционирования и таргетирования. И да, текущее состояние (читай, намерения) также учитывается, иначе не работало бы. Во-вторых, вы видимо не понимаете, что такое 180 лет. Черт, да это за один день! Даже если у нейросети очень слабые возможности по абстрагированию, в ней буквально запихиваются данные о тысячах лет игры в доту 2. Хоть кто-нибудь может хотя бы чем-то похожим похвастаться? В-третьих, Маск это, конечно тот человек, про которого говорят 25 часов в сутках, но даже 25 часов это мало, конечно он не участвует настолько интенсивно, все время сжирает тесла и спейсИкс, но тем не менее, он это начинал с определенной целью, он все еще выделяет огромные деньги, так что вряд ли он совсем в неведении. Да и взгляды Маска заразительны. И, в довесок, на коленке в том смысле, что никакой матан не избретался. Условно взяли доту, взяли апи, ограничили игру, чтобы нейросеть была адекватная и залили пожары деньгами. Такой способ пожаротушения не предполагает концептуального развития технологий, а максимум — лишь демонстрирует масштабируемость решения. Не считаю запихивание подмножества доты в огромнейшую нейросеть рокетсайнсом, что, впрочем, нисколько не умаляет значимости.
Druu
22.08.2018 13:52Эти варианты довольно низкоуровневые, но тем не менее в нейросеть уже заложены понятия позиционирования и таргетирования.
Вы что понимаете под "позиционированием и таргетированием" сейчас?
Даже если у нейросети очень слабые возможности по абстрагированию, в ней буквально запихиваются данные о тысячах лет игры в доту 2.
Это ничуть не отменяет того, что редкие, специфические ситуации (вроде толкания форсой с мидасом под ульт) могут не встретиться вменяемое число из а миллион лет.
И, в довесок, на коленке в том смысле, что никакой матан не избретался. Условно взяли доту, взяли апи, ограничили игру, чтобы нейросеть была адекватная и залили пожары деньгами.
Вы вообще осознаете, что, вполне возможно, в мире не существует другой команды разработчиков, которая обладает достаточными знаниями и специфичным опытом, чтобы повторить ваше "на коленке"?
Если бы вы пытались завалить деньгами, мощностями и т.д. — я вам гарантирую, нихрена бы не вышло у вас.Deerenaros
22.08.2018 15:05Я понимаю команды вроде "держись этого этой секции" или "убей этого крипа". Это несколько абстрактнее, чем "иди в эту точку" или "ударь этот таргет". Разъяснять что такое абстракции не надо?
Вы все еще не понимаете масштабы. С моим опытом в 5к часов таких ситуаций было… Не прямо таких, но вообще любых микромоментов было очень много. Да блин, зайдите на дотавтф, там ситуации сплошь и рядом из "ват жаст ай син?", их не просто много, но ооооочень много. Сама по себе дота с её не всегда очевидными механиками это позволяет. А микромоменты очень быстро тренируются за счет того, что они дают много из ничего: не обязательно мидас держать, хотя и вполне может быть, что под него на откате таргета не будет, но есть еще много скилов и предметов, способные ластхитнуть крипа. Да и блинский, я же в принципе не про условного лича с мидасом, а про тысячи возможных абузов, многие из которых наверняка найдут боты. Мгновенная реакция может раскрыть и те, которые или невозможно нами воспроизвести, или ооочень сложно.
Druu
22.08.2018 15:12Я понимаю команды вроде "держись этого этой секции" или "убей этого крипа". Это несколько абстрактнее, чем "иди в эту точку" или "ударь этот таргет". Разъяснять что такое абстракции не надо?
Нету там таких команд. Есть "атака цели Х" (в смысле команда персонажу атаковать, не какая-то абстрактная "атакую!"), "мув в точку Х", "юз предмета Х по цели Y", "юз абилки Х по цели Y". Еще "ничего не делать" есть.
Вы все еще не понимаете масштабы. С моим опытом в 5к часов таких ситуаций было… Не прямо таких, но вообще любых микромоментов было очень много.
Вот именно что каких-то микромоментов было много, но бот от этого не научится. Чтобы научиться — ему надо, чтобы похожих микромоментов было достаточно много для того, чтобы бот из случайных примитивных действий (которые перечислены выше) выбрал последовательность нужных и убедился, что эа последовательность дает значимый ревард, что поднимет в итоге вес конкретных действий.
А микромоменты очень быстро тренируются за счет того, что они дают много из ничего: не обязательно мидас держать, хотя и вполне может быть, что под него на откате таргета не будет, но есть еще много скилов и предметов, способные ластхитнуть крипа
Так вот, для бот они не взаимозаменяемы. Если у бота есть две одинаково действующие абилки, которые ластхитят крипа, но при этом они у него обозначены как разные действия, то бот если научится пользоваться одной — то это ничего ему не даст в плане использования другой. Он никак не догадается, например, проюзать в такой ситуации вторую абилку, если первая будет в кд. До тех пор, пока случайно не попробует это сделать и не получит ревард.
Frankenstine
22.08.2018 15:50Нету там таких команд
Откуда вы знаете, что там есть и чего нет? Исходники видели, что ли?
Он никак не догадается, например, проюзать в такой ситуации вторую абилку, если первая будет в кд.
В статье сказано, что 80% ботов находятся в режиме обучения. В этом режиме они производят действия, которые выбираются (в первом приближении) случайно, и затем происходит оценка эффекта такого рандомного действия. Полезные действия закрепляются и используются в дальнейшем. Таким образом, при симуляции 180 лет игры в сутки, случайным перебором действий бот не только научится юзать вторую абилку, но и найдёт возможные их сочетания, дающие профит.Druu
22.08.2018 15:57Откуда вы знаете, что там есть и чего нет? Исходники видели, что ли?
В статье описано, какую информацию получает бот на вход и какие варианты команд может исполнять. В частности, там, например, текущая анимация дается и время долета прожектайла (оО)
А среди команд — вариации с задержками в n фреймов, то есть бот может решить вместо "сделать действие Х вот прям щас" — "сделать действие Х через 2 фрейма".
В статье сказано, что 80% ботов находятся в режиме обучшения. В этом режиме они производят действия, которые выбираются (в первом приближении) случайно, и затем происходит оценка эффекта такого рандомного действия.
Вам только надо, чтобы сформировалась ситуация, похожая на обсуждаемую, чтобы бот узнал, что в этой ситуации прожимать такие действия — полезно. А если ситуация редкая — то она может и за тысячу лет игры не произойти больше пары раз.
Desavian
22.08.2018 16:53Верно, поэтому на месте разработчиков я бы отпарсил все случаи, когда редкоиспользуемые действия привели к серьезным изменениям и на пару дней задал бы глубокую их проработку ботами… столько бы новых неизведанных уловок появилось. Хотя это… мм… слегка нарушило бы чистоту эксперимента =)
Druu
22.08.2018 17:20Верно, поэтому на месте разработчиков я бы отпарсил все случаи
Да не парсится никаких случаев. Сеть просто играет сама с собой и конец истории.
Hardcoin
22.08.2018 22:27Они разве говорят, что задача — сделать "чистый эксперимент"? Задача — выиграть. Нейросети — это самый простой известный способ, который вообще позволит эту задачу решить (наверное). Мне навскидку кажется, что "парсинг редко используемых действий" — тупиковая ветвь (потому что ревард так и так покажет, что действие хорошее), но если они посчитают, что это выгодно — наверняка сделают.
Hardcoin
22.08.2018 17:02Пространство возможностей не позволяет достигнуть результата случайным перебором. Фишка не просто в случайном действии, а ещё и в окружении. Я не думаю, что там случайный выбор действий.
Druu
22.08.2018 17:28Пространство возможностей не позволяет достигнуть результата случайным перебором.
У них же stohastic policy, то есть сеть выдает на самом деле не действие, а вероятностное распределение на возможных действиях. Потом на конкретном семпле сеть делает конкретное действие (бросая кубик и выбирая в соответствии с указанной вероятностью) и потом апдейтит веса в соответствии с ревардом за это действия так, что вероятность действия увеличивается в том случае, если оно дает больше реварда, с дополнительным рандомом для того чтобы не попасть в локальный оптимум.
В изначальном приближении, полагаю, распределение действий равномерное, то есть чисто случайно выбирается, что делать.Hardcoin
22.08.2018 22:32Согласен. На самой первой итерации — наверняка равномерное.
Но к тому моменту, когда бот смог добраться до вышки — уже нет. Т.е. если он хоть немного обучился, выбор действий всё же отличается от полного перебора. Нельзя сказать, что бот попробует все действия во всех ситуациях.
Druu
23.08.2018 04:13Нельзя сказать, что бот попробует все действия во всех ситуациях.
В случае когда для результата надо сделать несколько последовательных конкретных действий — это еще хуже, т.к. снижается вероятность того, что бот попробует какую-то "необычную" стратегию.
dimm_ddr
23.08.2018 13:46Так вот, для бота они не взаимозаменяемы. Если у бота есть две одинаково действующие абилки, которые ластхитят крипа, но при этом они у него обозначены как разные действия, то бот если научится пользоваться одной — то это ничего ему не даст в плане использования другой.
Насколько я знаю принципы нейросети у бота будет не "вариант 1 — 1я абилка, вариант 2 — 2я абилка", у него скорее всего есть параметры и их больше одного для каждой абилки и что использовать выбирается по ним. То есть если абилка наносит урон — значит бот может ее использовать для того чтобы нанести урон даже если в конкретно этой ситуации и конкретно для этой цели он такого никогда не делал. Не нужно прогонять все возможные сочетания, да и нереально это, как вы и сами говорите. Достаточно определить набор параметров для различных вещей/абстракций и сила бота будет именно в том, насколько сложные абстракции он может образовать.
Druu
23.08.2018 13:54> То есть если абилка наносит урон — значит бот может ее использовать для того чтобы нанести урон
Нет, не так. У бота просто «абилка1», «абилка2», етц.
Hardcoin
22.08.2018 16:46Не считаю запихивание подмножества доты в огромнейшую нейросеть рокетсайнсом
Это так не работало даже на шахматах, не говоря уж о го. И это точно не будет так работать с дотой — слишком большое пространство вариантов. Никакие тысячи лет не помогут, из-за тумана войны. Он
Нейросеть именно что вычленяет варианты и стоит высокоуровневые признаки. Это не то же самое, что просто запомнить все варианты — это абсолютно точно невозможно.
roryorangepants
22.08.2018 12:51Вы постоянно говорите про архитектуру, но основная проблема в том, что архитектура не статична. Нейросеть — это контейнер, аналоговый вычислитель эмулированный на ПК, если грубо.
Вообще-то она как раз статична. Не статичны веса.
Если очень грубо, то полноценный запуск всего цикла енва -> обс -> агент -> акт на каждый кадр это тоже самое, что если бы для вас останавливали время 30 раз в секунду.
Останавливали время 30 раз в секунду… на одну тридцатую секунды. Не забывайте, что ботам надо успеть отреагировать.
даже настолько простой, практически на коленке собранный способен демонстрировать практически неоспоримое преимущество перед людьми
Надеюсь, вы осознаёте, что это не «простой, на коленке собранный ИИ», а state-of-the-art в современном machine learning?
Frankenstine
22.08.2018 15:30они не вступают в коммуникацию и не предсказывают действия друг друга
Вы в этом уверены? Я так полагаю, что все боты находятся под управлением одного инстанса, соответсвенно, все пять ботов в одной игре обладают общей «памятью», глобальной целью и стратегией, то есть вся коммуникация скрыта за единым общим процессом, управляющим всеми ботами одновременно. В частности, любой бот «в курсе» точного кулдауна всех перков любого другого бота и управляющий ими процесс использует сведения о доступности перков, как будто боты постоянно, автоматически, «докладывают» друг другу о применении перков даже когда они не видны тимейтам, и все боты скрупулёзно отсчитывают кулдауны тиммейтов.
Таким образом, помимо стабильной высокой реации, боты имеют преимущество в мгновенной коммуникации за счёт одного общего процесса, обладающего сведениями обо всех управляемых им ботами.Druu
22.08.2018 15:40Вы в этом уверены? Я так полагаю, что все боты находятся под управлением одного инстанса, соответсвенно, все пять ботов в одной игре обладают общей «памятью», глобальной целью и стратегией, то есть вся коммуникация скрыта за единым общим процессом, управляющим всеми ботами одновременно.
Это логичный метод, но так решили почему-то не делать. Не знаю, почему. Возможно, чтобы получить 5в5 бота инкрементально из 1в1 бота, в предлагаемой схеме так бы не получилось.
В частности, любой бот «в курсе» точного кулдауна всех перков любого другого бота и управляющий ими процесс использует сведения о доступности перков
У любого бота есть полный доступ к стейту своих мейтов. То есть так же как игрок видит хп, положение и т.д., так и бот видит. Это просто часть информации, которая идет на вход сети. Но сеть у каждого отдельная и принимает решения независимо.
Кстати, на счет кд, в статье не указано, что они вообще трекаются. Для союзников все же, думаю, трекаются, а вот для врагов, походу, нет. В информацию предоставляемую апи доты это не входит, с-но нужен какой-то отдельный алгоритм трекинга, но он не описан. Так что скорее всего фактор кд противника вообще игнорируется, как не входящий в стейт.Frankenstine
22.08.2018 15:55-1Но сеть у каждого отдельная и принимает решения независимо.
Вот это утверждение требует документального подтверждения. Я таки считаю иначе, потому что если бы это были действительно независимые сети, то в названии не было бы слова Five и не было бы ограничения 5х5, то есть матчи были бы и 8х8, ну, вплоть до максимума на карту. Но мы видим везде только формулу 5х5, что намекает на конструктивную особенность единого управляющего элемента для всей команды в 5 ботов.roryorangepants
22.08.2018 16:02Вот это утверждение требует документального подтверждения.
Using a separate LSTM for each hero and no human data, it learns recognizable strategies.
~180 years per day (~900 years per day counting each hero separately)
Достаточно просто открыть блогпосты OpenAI.Frankenstine
22.08.2018 16:09Отдельная LSTM сеть, которая как мы узнали из статьи, ответственна за поведение бота «здесь и сейчас» (краткосрочные решения), в то же время есть ещё нейросеть, ответственная за долгосрочное планирование игры. И здесь стоит вопрос — какая информация о действиях (статусе) LSTM-управляемых ботов уходит «наверх» и доступна для планирования совместных действий (и, соответственно, опосредственно уходит «вниз» как скрытая коммуникация).
roryorangepants
22.08.2018 16:15Откуда информация про отдельную нейросеть, ответственную за долгосрочное планирование игры?
Frankenstine
22.08.2018 16:24Это я так интерпретирую текст статьи:
API нужен для того, чтобы полученные данные прогонять через однослойную LSTM-сеть из 1024 блоков и получать, как итог, краткосрочные решения, которые согласуются с долгосрочными стратегиями, которыми располагает нейросеть.
roryorangepants
22.08.2018 16:31Это я так интерпретирую текст статьи:
Это вы неправильно интерпретируете текст статьи.
Даже тут я не понимаю, как можно было сделать те выводы, которые вы сделали. А уж в оригинальных постах такого тем более не найти.
Каждый герой управляется одним отдельным инстансом сети.Frankenstine
22.08.2018 17:03Ну, в модели сети действительно отсутствуют связи между ботами, единственное что я там увидел — кулдауны глифов для каждого героя в игре.
Окей, это более-менее честно для людей.
saboteur_kiev
22.08.2018 17:11долгосрочные стратегии это наработанная база самого бота. Можете считать, что у всех ботов общая ДНК, но в конкретной игре — это 5 инстансов.
Druu
22.08.2018 16:04Coordination
OpenAI Five does not contain an explicit communication channel between the heroes’ neural networks. Teamwork is controlled by a hyperparameter we dubbed “team spirit”. Team spirit ranges from 0 to 1, putting a weight on how much each of OpenAI Five’s heroes should care about its individual reward function versus the average of the team’s reward functions. We anneal its value from 0 to 1 over training.https://blog.openai.com/openai-five/
там кстати классные картинки на счет того что бот получает на вход и что возвращает
то есть матчи были бы и 8х8, ну, вплоть до максимума на карту
Я вижу, вы в доту не играете :)
Дота — это только 5в5. Как баскетбол :)
Можно, конечно, играть в баскетбол и не 5в5, так и в доту — есть соло для тренировки, есть какие-то фановые режимы. Но это как бы будет не дота :)Frankenstine
22.08.2018 16:20Я вижу, вы в доту не играете :)
Играл ещё когда она была модом к варкрафту 3 :)
OpenAI Five does not contain an explicit communication channel between the heroes’ neural networks.
Тогда у людей есть шанс коммуникацией компенсировать стабильность реакции ботов.Druu
22.08.2018 16:22Играл ещё когда она была модом к варкрафту 3 :)
И как там было с 8х8 в 5.84b? ;)
Тогда у людей есть шанс коммуникацией компенсировать стабильность реакции ботов.
Один бот имеет практически всю ту же самую инфу, что имеют другие боты. В этом плане с коммуникацией не проблема. Проблема тут в том, что один бот не знает что сделает другой, с-но не может планировать… но! Штука в том что бот не знает и то, что он сам сделает, с-но он и свои действия не может планировать :D
Что, вобщем-то, не мешает.
Elrond16
23.08.2018 12:35+1матчи были бы и 8х8, ну, вплоть до максимума на карту
Играл ещё когда она была модом к варкрафту 3 :)Насколько я помню, в варкрафте 3 было максимум 12 игроков до недавнего патча, и в доте использовались все: 10 слотов для игроков и 2 для Sentinel и Scourge.
saboteur_kiev
22.08.2018 17:10+1Потому что бота, который может управлять конкретным одним игроком, и взаимодействовать с другими игроками при помощи коммуникации, можно затем коммерчески продать той же valve.
Такой бот сможет дополнять команды играя вместе с людьми. Да и просто играть против людей в режиме PvBDruu
22.08.2018 17:32Потому что бота, который может управлять конкретным одним игроком, и взаимодействовать с другими игроками при помощи коммуникации, можно затем коммерчески продать той же valve.
Поверьте, та игра, которую показывает этот бот — это ни то, что люди хотят смотреть, ни то, против чего они хотят играть :)
Так что коммерческая польза сомнительна будет.saboteur_kiev
23.08.2018 15:51Хороший бот — это отличный режим для начинающих, которые хотят научиться играть в MOBA игры, не читая с первой же минуты оскорбления и маты в свой адрес.
bro-dev0
24.08.2018 06:44Нет вы не правы, вард танкует 8 ударов, а вышка не переагривается сама по себе, если поставить четко по таймингу будет фора 8 ударов у крипов, если не четко меньше, причем на 7 ударов там времени секунда где-то, на 6 ударов 2 секунды, так что успеть можно, не говоря о том, что крипы идут линейно и предсказать это просто, так что тут не реакция нефига а просто действие заранее.
realSTAG
21.08.2018 15:42+1Робот же не может навредить человеку. но сколько же людей расстроятся из-за поражения своих любимчиков:) А если серьезно, то это безумно круто. удачи ботам:)
usdglander
22.08.2018 09:25Робот же не может навредить человеку
Это только по Азимову. Джеймс Кэмерон немного другого мнения. ;)Vantela
22.08.2018 09:38Насколько я помню Азимова — все таки может. Просто неумышленно.:)
Помню, например, рассказ где роботу приказали достать важные элементы без которых база на Меркурии(?) загнется. Но роботу не объяснили важность миссии. А ему оказалось «стремно». И он как то не торопился добывать элементы. Не поймали б робота — загнулась бы база вместе с людьми:)Sychuan
22.08.2018 16:42Кажется называется «Хоровод». Там еще несколько рассказов на тему, как не сработают Законы было
Desavian
21.08.2018 15:53и да, все в комментариях что на реддите, что на профессиональных дота ресурсах, сошлись в том что последние игры 5х5 были… были слегка поддавками, как бы не отнекивались игроки, то, как мямлил шейкер про то, что «ну я не кастовал эхо слэм через шифт потому что подумал что лион в стане от фиссуры» четко показывает, что были дополнительные ограничения, о которых мы не знаем. Да что говорить, куча всего уже обговорено, начиная от того шейкера под лионом и заканчивая беготней по-одному всю игру, когда их боты выщелкивали. Если же еще и чейн способностей отсутствовал, всегда давая ботам «окно» для прокаста, это вообще чит)
dmitryredkin
21.08.2018 16:57+1Последняя игра, в которую я играл более-менее, была Q2.
Мне очень интересно следить за противостоянием белковых и кремниевых, и я бы с радостью посмотрел трансляцию…
Но не буду.
Уже пытался смотреть стримы, но всё равно ничего не понятно. Что произошло? Кто выиграл боестолкновение? Кто побеждает? Куда смотреть? А комментаторы только усиливают хаос, говоря на каком-то своем языке. С выражениями типа тех, что в комментариях вышелион в стане от фиссуры
скомпенсировать траты на варды и плевать что он не в мете
Кто-нибудь знает, где можно будет посмотреть игру так, чтобы было понятно простым смертным?siziyman
21.08.2018 17:09Вот это проблема для MOBA (та же, кстати, с которой сталкивается ИИ) — очень большой глоссарий базовых терминов, которые необходимо освоить, чтобы нормально понимать игру.
В общем, увы, нет, если основы не знаете, смотреть трансляцию довольно специфичного события (т.е. массово никто заморачиваться с адаптацией под новичков не станет) смысла нет, скорее всего.dmitryredkin
21.08.2018 17:15Ну естественно, зачем ради нас, не-дотеров, заморачиваться. Нас ведь так мало…
siziyman
21.08.2018 17:20Проблема в том, что на это (для понимания на уровне «перестал теряться раз в 1-2 минуты при спокойном темпе игры и понимаю хотя бы 50% происходящего в более интенсивных ситуациях») реально надо будет угрохать раза в 2-3 больше времени, чем займёт сама игра, и это если довольно интенсивно подавать материал.
Это не столько «зачем заморачиваться ради чёртовых казуалов», сколько «зачем объяснять это им, если 90% не интересно, а кому надо — сами придут».dmitryredkin
21.08.2018 17:31Ну тогда молитесь, чтобы казуалам по прежнему было не интересно. Потому что если вдруг станет, то игра быстренько эволюционирует.
И будут комментаторы быстрые схватки на замедленных повторах анализировать, пока игроки отдыхают.siziyman
21.08.2018 17:36Да ё-моё, мне совсем не жаль, я наоборот за широкую популяризацию разных форм киберспорта. Просто с мобами, особенно дотой, это довольно сложно делать — вникать тяжеловато. Это был единственный посыл — «я совсем не против, чтоб сюда приходили, но пожалуйста, готовьтесь, будет сложновато».
А после матчей комментаторы (а чаще выделенная студия аналитики уже, а не комментаторы) уже давно анализируют матчи, подмечая на повторах наиболее интересные, яркие или ключевые моменты, да. Это замечательно.

BingoBongo
22.08.2018 13:21Я больше скажу — это как с шахматами, если у тебя ниже 1го разряда, то турниры с топовыми игроками можно не смотреть, потому что разрыв слишком большой. Вместо того чтобы чему-то научиться, ты просто сидишь и не понимаешь игру, даже несмотря на комментарии и разбор ходов.
Vantela
22.08.2018 13:44Ну… не скажите.
Турниры турнирам рознь.
На набережной в Ялте одно время (возможно, и сейчас) летными жаркими вечерами собиралась тусовка шахматистов из местного клуба. Ниже 1го разряда у них никого не было. Ну чемпионов мира — тоже. Играли они преимущественно друг с другом, но иногда их можно было уговорить и на игру с прохожим.
Играли блицы. 5 минут на партию каждому игроку.
По началу действительно ничего не понятно. Не успеваешь.
Но некоторое время насмотревшись уже получалось найти ходы лучше чем игроки сыграли и увидеть где кто чего зевнул. И это в «онлайне».
Сам я даже до 3го в лучшие свои времена не дотягивал.BingoBongo
22.08.2018 15:21+1В том и суть, что чемпионов мира не было. Если бы вы находили зевки или более лучшие ходы за Магнуса Карлсена или Владимира Крамника — тогда другое дело :)
Vantela
22.08.2018 15:40Если бы они играли блицы по 20 штук за вечер и так каждый вечер, то думаю ходов по лучше хватило б на всех ;-)
bro-dev0
24.08.2018 06:48Не обязательно быть дотером чтобы понимать, я СК2 люблю смотреть, хотя сам тока компанию играл.
Просто у доты относительно других игр большой порог входа, я вообще удивляюсь как у неё новые игроки появляются.
Stalker_RED
22.08.2018 03:10+1Вот фраза из из eve-online, которая вовсе не MOBA:
На инсте гейта минусовый хуррик, в бубле, в агре.
переводВ непосредственной близости от звёздных врат (то есть на таком расстоянии, что можно невозбранно пропрыгнуть) находится линейный крейсер класса «Хуррикейн», пилот которого является врагом нашей корпорации/альянса, в течение последней минуты совершивший акт агрессии против другого игрока, что не позволяет ему использовать звёздные врата по прямому назначению. Также крейсер находится в антигиперпрыжковом поле, что не позволяет ему использовать генератор гиперпрыжкового поля и уебать нахуй вглубь системы.siziyman
22.08.2018 08:00Ну да, абсолютно, такие вещи очень много в каких играх с активным коммьюнити можно найти.
Просто скажем так, мне сложно представить обстоятельства, в которых кто-то стал бы транслировать EVE Online, ещё и с какими-то жёсткими рамками по времени, потому мобы с их соревновательной составляющей, которую как-то монетизируют и делают публичным развлечением, были более ярким примером. Да и в данном случае речь о Доте шла.fpir
22.08.2018 10:09К тому-ж эпичные зарубы в EVE абсолютно не зрелищный, даже если понимаешь, что происходит. Трансляция экрана игрока-да, для понимающих зрелище захватывающее, но не любого игрока, и не одного игрока. Для «трансляции» боя требуется захват экранов всех участников, ну и переговоры желательны, потом ещё смонтировать-бы.
chupasaurus
22.08.2018 15:23В EVE есть ежегодный турнир альянсов (недавно прошёл 16-й, поговаривают что последний из-за низкой популярности), который по сути представляет собой бой на арене между двумя околосбалансированными по силе кораблей командами. Очень специфичное зрелище, опять же без понимания игры половина движухи на арене будет непонятна.
siziyman
22.08.2018 15:33Окей, спасибо (без сарказма, информация для меня новая, почему бы и нет). Кажется, мою мысль оно в целом подтверждает, я уже сказал, что просто речь идёт об определённом частном случае, о котором я в основном и вёл речь (но ни в коем разе не претендовал на его исключительность).
Wayloren
22.08.2018 08:54Хы, вспомнил времена, когда играл в WoW еще:
«2дд лфг цлк25 гс5.4 трини есть»
tSmoker
21.08.2018 17:16Испытываю те же проблемы в свои 34. Вроде и интересно (человеки пытаются победить роботов) и в целом принцип понятен, но начинаешь смотреть стрим и становится совершенно непонятно, что происходит на экране.
Sonatix
21.08.2018 17:19Сравнение не совсем корректное, но «быстро объясните эти диф. уравнения что бы стало понятно человеку который когда то учил цифры и не хочет во все это вникать». Звучит как то так.
dmitryredkin
21.08.2018 17:231. Совсем не корректное;
2. Не объясните, а покажите, куда смотреть;
3. Думаю, я бы смог.
Вот смотри: нужно, чтобы если вот эту фигульку пропустить вот через это преобразование, получилось бы то же самое, что и вот тут.
Вот, пропускаем, складываем — сходится!
А на С не смотри, оно не важно.siziyman
21.08.2018 17:38Только вот после этого объяснения, показав пару других типов диффуров, вам придётся заново объяснять, как эти преобразования работают на принципиально других аргументах (и работают ли вообще), и какие другие преобразования придётся использовать.
А когда вы смотрите профессиональный матч, никто не станет «играть попроще», чтоб зритель-новичок понял. Люди деньги зарабатывают, наоборот, чем хитрее и тоньше, тем зачастую и лучше.
balexa
21.08.2018 19:17Если бы было соревнование по решению дифуров на скорость, никто бы вам из комментаторов не объснял что такое частное решение и сколько бывает видов характеристического уравнения. Точно так же когда комментаторы на футболе кричат «Гол! А, нет, судья показывает оффсайд» никто вам в прямом эфире каждый раз разжевывать правила футбола не будет. И когда человек играет против компьютера в шахматы, никто вам шахматный учебник не пересказывает, и тем более не разжевывает почему конь может прыгать через фигуры, а слон нет, а король иногда. Подразумевается что вы это и так знаете.
Хотите смотреть игру — учите правила. Ни в одном виде спорта комментаторы не разжевывают термины и правила для тех, кто впервые эту игру увидел. Почему киберспорт должен быть исключением?M_AJ
22.08.2018 07:53Простите, а когда король в шахматах ходит через фигуры?
Druu
22.08.2018 08:20Наверное, рокировка, если делать ее через ладью, а не через короля.
M_AJ
22.08.2018 08:36Ну тут сложно сказать кто через кого ходит, король через ладью, или она через него.
Pariah
22.08.2018 14:51Если быть очень придирчивым, по правилам, рокировка всегда начинается с хода короля, вне зависимости от стороны, в которую выполняется.
Rasalom
21.08.2018 17:38Если нет проблем с английским, то есть стирим от valve для новичков:
www.twitch.tv/dota2ti_newcomer
Orky
21.08.2018 17:46Можно попробовать посмотреть записи с первого интернешенела, там комментаторы именно таким образом рассказывали, что и как, в простой манере.
Desavian
21.08.2018 18:09Очень сложно. Сложно не из-за невозможности описания, а из-за того, что без сокращений и устоявшихся выражений, комментирование будет чудовищно медленным.
Я мог бы вместо
«лион в стане от фиссуры» написать «герой, имеющий возможность выключить противника из игры стоял в оглушении и игрок не рассчитывал, что противник выйдет из оглушения так быстро, поэтому не воспользовался методом, убирающим временной промежуток между способностями и гарантирующим что способность будет исполнена.
Но если каждые 4 слова превращать в 35, описание матча превратится в лютую жесть.
chelovekpauk2002
21.08.2018 20:20Раньше был стрим TI для новичков или тех, кто совсем не разбирается в игре.

shuraosipov
21.08.2018 20:20Есть официальная трансляция для новичков — www.twitch.tv/dota2ti_newcomer.
Стоит отметить, что трансляция только на английском языке.
Vantela
22.08.2018 09:41Это вам не футбол:)
Я долгое время смотрел стримы по Гвинту и таки да. Для непосвященного карточки меняются очень быстро, прочитать текст нереально, а уж комментарии целиком сленговые…Wayloren
22.08.2018 09:48Да что там для непосвященного… Я играл в ХС с ОБТ и до начала 2018. Сейчас, пропустив 2 последних обновления, я захожу на стримы и не знаю, какие картонки что делают.
С Гвинтом попроще, хотя я его тоже забросил. Там банально меньше новых картfpir
22.08.2018 10:15Нагромождение сущностей не делает игру интересней, жаль, что дизайнеры карточных игр до этого никак не дойдут.
Vantela
22.08.2018 10:20Дизайнеры получают несколько другую задачу на вход:)
От них требуют чтобы игра приносила больше денег.
А «интересность» она даже не в первой тройке приоритетов.fpir
22.08.2018 10:26Хотя «интересность» и прибыльность пытаются всеми силами отвязать друг от друга, пока они связанны неразрывно. Поэтому ведьмак взлетел, и гвинт в нём нравиться почти всем, а отдельный гвинт не так что-бы был хитом.
Vantela
22.08.2018 11:36Ведьмак это исключение. Он именно потому и взлетел, что изначально закладывался как интересный. На фоне абсолютного большинства игр нынче, которые делаются как раз на выжимание денег Ведьмак полыхнул сверхновой.
Stormwalker
22.08.2018 13:19Есть трансляция для новичков, если понимаете английский. https://www.twitch.tv/dota2ti_newcomer
Возможно, есть и русский стрим новичковый, но я не слышал.
Smokin
22.08.2018 13:47Лион — имя персонажа
Стан — название эффекта под которое он попал
фиссура — название способности которая накинула этот эффект.
Куда проще? Это даже не сокращение или какие-то мудренные термины, а просто названия которые можно увидеть сыграв разок другой.Desavian
22.08.2018 14:58Правильно) только ситуацию это не объяснит. Потому что объяснить надо не лиона, стан и фиссуру, а почему шейкер не успел дать эхо слем и уехал в полиморф лиона (а для этого надо как минимум знать скилы лиона)
Frankenstine
22.08.2018 16:49Кто-нибудь знает, где можно будет посмотреть игру так, чтобы было понятно простым смертным?
Да нафиг это нам не нужно. Понимаете ли, с тех пор как дота стала отдельной игрой, при взгляде на неё, единственно что я вижу — сплошное мельтещение графических эффектов, поглощающее происходящее. Я просто не увижу то, что происходит, даже если мне это будут объяснять на понятном мне уровне.Femistoklov
22.08.2018 17:50Значит, не одному мне так показалось. После варкрафта действительно было ничего не понятно в замесах, одни огни мелькают. Может, конечно, это только из-за привычки к другой графике.
Druu
22.08.2018 17:53Просто УИ действительно перегружено, и тут ничего не сделаешь, механика такая. Я после первой доты тоже долго привыкал.
vaslobas
23.08.2018 18:48Да ничего не поменялось, как мне кажется. Просто к механике и графике вар3 ты привык уже, вот и кажется всё знакомым. После вар3 увидев мощный замес в дота 1 ты бы тоже офигел и ничего не понял, а потом привыкаешь уже и даже не видишь половину анимаций итд. Мозг как-то отфильтровывает.
PsyHaSTe
24.08.2018 01:00Мозг видит всё, но вместо мусорной графики оценивает «ага, был скастован скилл Х».
После анимаций первого варкрафта было очень тяжело: деревья сливаются друг с другом, ауры нужно прокликивать, многие анимации намного менее контрастные,… Нужно поиграть 20-30 игр чтобы привыкнуть, а после сотни игр начинаешь вычленять исключительно полезную информацию.
PsyHaSTe
22.08.2018 17:22Уже пытался смотреть стримы, но всё равно ничего не понятно. Что произошло? Кто выиграл боестолкновение? Кто побеждает? Куда смотреть? А комментаторы только усиливают хаос, говоря на каком-то своем языке. С выражениями типа тех, что в комментариях выше
Форвард ударяет велосипедом, от чего мяч перелетает бетон и голкипер пропускает хет-трик.
Как вы думаете, ваша жена или любой другой человек незнакомый с футболом многое понял из этой фразы?
Сленг — норма любой специфической сферы деятельности. Для его разжевывания нужно быть погруженным, например играть в футбол, или в данном случае в доту.Arty_Fact
23.08.2018 14:36Я не поклонник футбола, но никогда не слышал подобную фразу от комментаторов. Никто не пропускает хет-трик, его делают. Про бетон и велосипед мне остается только догадываться.
3aBulon
21.08.2018 17:32Почему то не верю в людей.
USBLexus
21.08.2018 21:17Имхо в первом матче у OpenAI будет преимущество в том, что люди будут пытаться изучать манеру игры неизвестного соперника, экспериментировать, а вот во втором и третьем все может измениться в пользу людей
Druu
22.08.2018 03:32Если будут такие же ограничения, то в первом матче преимущество будет в том, что люди в такую доту просто не играют, с-но некоторые решения которые верны в нормальной доте, тут будут ошибочными, и наоборот.
n1ger
23.08.2018 08:12А зря. Команда, которая уже покинула ТИ даже на тех имеющихся ограничениях снесла ботов.
Команды, которые остались думают сделают тоже самое. А если убрать ограничение по персонажам, то там вообще пока что у бота мало шансовDruu
23.08.2018 08:37Вообще говоря, если бы они до этого не видели матч с ботами, то, вполне себе, проиграли бы. Потому что то как они играли с ботами — это сейчас не в мете. А если бы играли метово — маловероятно, что успели бы подстроиться под ботов.
Vantela
23.08.2018 09:08+1Типа давайте запретим кожаным игрокам учиться на чужих
ошибкахиграх?
Это наше эволюционное преимущество. Нефиг:)Druu
23.08.2018 09:12Типа давайте запретим кожаным игрокам учиться на чужих ошибкахиграх?
При чем тут обучение на чужих ошибках? Есть определенные правила проведения спортивных состязаний. Когда Каспаров проиграл DeepBlue то ему никто не предлагал сыграть еще n игр с целью поискать абузы и потом уже сыграть игру по-настоящему. Нет, он проиграл матч, и на этом машина победила человека в шахматы.
Если бы тот АИ, о котором речь, участвовал в конкретном состязании под видом людей, то люди бы у него смогли выиграть? Не смогли бы, т.к. никто бы не дал им в рамках этого состязания сидеть и 6 часов алгоритм вскрывать. Вы в принципе не сможете это сделать против реального игрока. Он просто пошлет вас и не станет с вами играть :)
Vantela
23.08.2018 09:20Вообще то могу. Достаточно посмотреть на ютубчике как он играл с другими противниками ранее ;-)
Druu
23.08.2018 09:24Вообще то могу. Достаточно посмотреть на ютубчике как он играл с другими противниками ранее ;-)
Я вообще думал, этот тот же тред, что про quake и ответил не совсем про то :)
Посмотреть-то в ютубчике вы можете, но это не даст вам больших знаний, чем в случае игры с обычным игроком.
Druu
23.08.2018 09:28Здесь, кстати, еще интересный момент — так же как люди не готовы к игре с ботом так и бот не готов к игре с людьми. То поведение, которое он выучил оптимальным в игре сам с собой, не всегда будет оптимальным в игре против людей.
Конкретный пример: вот в игре с PaiN вихо на аксе не упевал после блинка прожимать колл, т.к. бот всегда успевал отпрыгивать своим блинком. С-но, что выучит бот в игре с самим с собой? нет смысла пытаться поймать героя с блинком при помощи колла акса. И не будет это пытаться сделать в игре с людьми. Хотя люди прекрасно ловятся :)Vantela
23.08.2018 09:43Не уверен. Думаю бот выучит, что надо отпрыгивать.
Потому что положительное закрепление было именно на «отпрыгивание».
А отрицательного закрепления на «попытку блинка» — не было. Значит не должно быть забраковано.
vaslobas
21.08.2018 19:49Если без ограничений, то уверен, что люди порвут ботов. Если с ограничениями, то тут всё зависит исключительно от ограничений.
nlog
21.08.2018 20:21-1Вот когда бот победит про-игрока 1 на 1, тогда поговорим.
Вот когда команда ботов победит 5 на 5, тогда поговорим.
=== Вы находитесь здесь ===
Вот когда команда ботов победит про-игроков 5 на 5, тогда поговорим.
Вот когда команда ботов победит про-игроков 5 на 5 без ограничений, тогда поговорим.
Вот когда команда ботов победит про-игроков 5 на 5 без ограничений и без использования API для ботов, только анализируя аудиовизуальный поток, тогда поговорим.siziyman
21.08.2018 20:52+1Проблема только в том, что они немного в другую игру играют, не в доту, а почти в суровый такой кастом гейм на основе доты.
При этом я мало сомневаюсь, что рано или поздно они научатся людей и в «полноценную» доту рвать, но пока не думаю, что скоро.Vinchi
21.08.2018 20:59Думаю что боты в доте и Лоле уже давно играют.
siziyman
21.08.2018 21:23Написанные заскриптованные боты — да.
Обученные сколько-то «честным» ML, и, как следствие, потенциально превосходящие человека не только реакцией, но и пониманием — точно нет.Satim
22.08.2018 10:09-1Что есть понимание? Понимаем ли мы сами?
Совсем недавно была статья на хабре посвященная данной теме.
habr.com/post/420197siziyman
22.08.2018 11:22В контексте у самого термина «понимание» есть относительно чёткая трактовка — умение делать наблюдения (как позитивные, так и негативные — Х присутствует/Х отсутствует), дополнять, уточнять и обновлять на основе этих наблюдений собственную ментальную модель происходящего в игре, и на основе этих дополнений принимать решения как тактические, так и стратегические, и на основе обратной связи (результат игры или отдельных её моментов) также обновлять модель принятия тактических и стратегических решений.
Пример банальной цепочки вещей, которые человеку приходят с опытом, и формируют маленький кусочек «понимания игры»:
— Мы хотим обладать максимумом информации о действиях и состоянии соперника
— Соответственно, мы хотим организовывать максимальный обзор на карте (ставить варды, например; различия в важности наличия вижена в разных участках карты в принципе и в разных игровых ситуациях оставим за кадром, это немного следующий уровень рассуждений)
— Когда мы имеем условно достаточный уровень обзора, мы можем делать выводы, как видя противника (можно наблюдать, какие действия на карте он производит, и строить прогнозы развития событий, и предпринимать решения — стоит ли пытаться его сейчас убить, например, или его можно условно игнорировать), так и не видя его (если мы видим большУю часть карты, и не видим противника, вполне вероятно, что он осознанно скрылся, и, возможно, предпринимает агрессивные действия, которых надо или избегать, или встретить готовыми всей командой, или предпринять ответную агрессию).
И так вот понемногу, по кирпичикам.
Vinchi
21.08.2018 20:58-2Народ вы читайте сначала весь текст статьи. Играют именно на видеопотока распознавая картинку.
dmitryredkin
21.08.2018 22:36Я конечно не знаю, что такое «официальный API доты для ботов», но сомневаюсь, что в нем — просто картинка.
Логичнее было бы передавать как раз закодированное игровое поле примерно в таком виде, каким его распознает человек.
Druu
22.08.2018 03:33Вот когда команда ботов победит 5 на 5, тогда поговорим.
Боты на 5*5, причем без ограничений на весь пул героев в доте есть уже давным-давно, с разморозкой вас ;)
Вопрос именно в том, насколько они хорошо играют.
n1ger
23.08.2018 08:14Пока на этом уровне и остались. Даже самую слабы команду-участницу ТИ боты не победили :(
PsyHaSTe
23.08.2018 12:03+1Самая слабая команда-участница ТИ это все же топ 20 команд всего мира. Нехило такое «лишь».
n1ger
23.08.2018 14:01Они не топ 20. Паин отобрались с региональных квал. Многие команды из СНГ, Европы и Китая да и тот же регион юго-восток Азии обыграли бы их.
Elrond16
23.08.2018 15:21Не согласен, с приходом w33 они очень неплохо стали играть. В общем рейтинге DPC они заняли 16е место (если не считать дисквала из-за смены состава) и являются одной из 16 команд за этот год с призовым местом на мейджоре.
forcam
22.08.2018 00:12Впечатляет, конечно это просто супер и ничего такого мы еще не видели, просто потому что боты действуют в достаточно сложной среде, но, как мне кажется, дальнейшая разработка это автономные боевые системы, а дота это просто полигон для оттачивания этой технологии. При этом они будут явно умнее всего что мы когда либо видели, люди против такой системы просто бессильны, при равных условиях среды, т.е. если условно у одних и у других одинаковое оружие, такие боты будут выигрывать всегда, потому что их просчет тактики возможно безупречен из-за использования большого количества опыта, они тупо знают что как и когда нужно сделать, что бы действовать максимально эффективно. Всё что такой системе понадобиться, это какой нибудь квантовый компьютер и дальше за счет умения, такие системы при малом количестве боевых единиц, будут творить настоящие чудеса, потому что мастерство, всегда побеждало и будет побеждать количество, а этих ботов можно тренировать бесконечно, чему они смогут научиться, оттачивай они что угодно 10 000 — 100 000 — 1 000 000 лет (компьютерных)?
Hardcoin
22.08.2018 17:22Сильно ли отличается уровень, например, среднего музыканта, который тренировался 10 лет от того, кто тренировался 20? С какого уровня человек достигает предела, выше которого не растет.
Для нейросетей это так же верно. Любая архитектура имеет плато — там хоть сто лет, хоть сто тысяч, а качество расти перестает. Вот и ищут архитектуру, которая с одной стороны хорошо обучается, а с другой — имеет очень высокое плато.
forcam
22.08.2018 21:57Топ игроки Го с вами не согласны, причем в корне, чем сложнее среда, тем больше ИИ доминирует над людьми, это значит, что в Доте они рано или поздно будут без шансов переигрывать людей.
Druu
23.08.2018 04:13Топ игроки Го с вами не согласны, причем в корне, чем сложнее среда, тем больше ИИ доминирует над людьми
У топ игроков го странное мнение, которое опровергается наблюдаемыми фактами.
Мне кажется, топ-игроки го имели ввиду что-то другое, не то, что вы сейчас говорите.
Hardcoin
23.08.2018 11:56Можно пару фамилий? Или вы от их имени говорите?
Конечно ИИ будет переигрывать в доте. Но у конкретной архитектуры есть плато. И её можно хоть сто настоящих лет учить — плато останется. Если плато выше, чем навык людей — будет обыгрывать (если доучить до этого плато). Если плато ниже — будет проигрывать.
Конечно всегда можно взять более крупную архитектуру. У неё плато наверняка будет выше. Просто учить сложнее. Иногда настолько сложнее, что вообще не ясно — как.
Если интересно — посмотрите "график обучения нейронной сети", на них хорошо видно, что сеть постепенно идёт к определенному уровню.
PsyHaSTe
22.08.2018 17:27> Квантовый компьютер
> Роботы-убийцы
> Мы все умрем
Вы точно в правильном месте решили начать писать про конец света и восстание машин?FreeNickname
22.08.2018 21:03Я думаю, forcam не про конец света и восстание машин, а про использование таких роботов человеком.
xkcd.com/1968
RomanPokrovskij
22.08.2018 22:26Тренировка нейронки не бесконенчна, в итоге строится сеть тренирующая сеть (нашу нейронку) и эта тренировка сводится к упрощению внутреннего состояния «нашей нейронки», к отсечению лишних путей и в конце конце все упрощается до аналитического решения (если оно существует). Так действует человеческий мозг. Невозможно бесконечно улучшать законы Ньютона наблюдая за падающим яблоком.
Druu
22.08.2018 03:34По информации от разработчиков, все партии происходят с отрисовкой событий на карте с частотой в 30 FPS. Нейросеть OpenAI постоянно анализирует каждый кадр через LSTM, на основе результата которого принимает дальнейшие решения.
В этом контексте очень интересно, что будет, если скин карты внезапно сменить :)
Кроме того, похоже, можно делать какие-то абузы на стаке анимаций.Druu
22.08.2018 07:31Таки исходя из оригинала боты видят не экранное изображение, а информацию о происходящем в чистом виде, в частности, например:
For example, until recently OpenAI Five’s observations did not include shrapnel zones (areas where projectiles rain down on enemies), which humans see on screen. However, we observed OpenAI Five learning to walk out of (though not avoid entering) active shrapnel zones, since it could see its health decreasing.
еще немаловажная вещь:
We hardcode item and skill builds (originally written for our scripted baseline), and choose which of the builds to use at random. Courier management is also imported from the scripted baseline.
разводка на лайны тоже осуществляется насильно:
At the beginning of each training game, we randomly “assign” each hero to some subset of lanes and penalize it for straying from those lanes until a randomly-chosen time in the game.
так что боты совсем не учатся "сами по себе".
roryorangepants
22.08.2018 08:49разводка на лайны тоже осуществляется насильно:
we randomly “assign” each hero to some subset of lanes and penalize it for straying from those lanes
Как бы это не скриптинг. Просто они включили лайнапы в cost function обучения.Druu
22.08.2018 09:08Как бы это не скриптинг. Просто они включили лайнапы в cost function обучения.
Так и сборки — тоже не скриптинг, это просто способ показать сети, что "так можно", чтобы она вслепую не тыкалась миллион лет, подбирая осмысленные варианты наугад.
Речь просто о том что, получается, боты не на 100% сами все узнают, а получают некоторую внешнюю информацию о том, как играть
"можно собрать такой-то билд по итемам", "можно качать скиллы в таком-то порядке", "можно играть вот такой вот стратегией с расстановкой по лайнам".
Что, вобщем-то, нарушает чистоту эксперимента.roryorangepants
22.08.2018 09:16Так и сборки — тоже не скриптинг, это просто способ показать сети, что «так можно», чтобы она вслепую не тыкалась миллион лет, подбирая осмысленные варианты наугад.
Сборки — это скриптинг. Читайте внимательнее — ботам даётся несколько айтембилдов / скиллбилдов, и они выбирают случайный. ML никаким образом в этом не участвует.
С лайнапами ситуация другая — ботам дают выбранные лайны и включают это в функцию потерь таким образом, чтобы боты меняли линии только тогда, когда это реально выгодно.
Речь просто о том что, получается, боты не на 100% сами все узнают, а получают некоторую внешнюю информацию о том, как играть
«можно собрать такой-то билд по итемам», «можно качать скиллы в таком-то порядке», «можно играть вот такой вот стратегией с расстановкой по лайнам».
Что, вобщем-то, нарушает чистоту эксперимента.
Чем это нарушает чистоту эксперимента? Machine learning — это не про blackbox. Вносить знания о домене в модель — это нормально.ivanrt
22.08.2018 12:00Смотря какая задача у разработчиков. У DeepMind задача на играх научиться чему-то чтобы решить новую область задач с помощью AI. OpenAI похоже главное выиграть пусть с помощью скриптов и готовых алгоритмов.
Druu
22.08.2018 12:16У DeepMind задача на играх научиться чему-то чтобы решить новую область задач с помощью AI. OpenAI похоже главное выиграть пусть с помощью скриптов и готовых алгоритмов.
Ну ок тогда. Мне просто казалось, что у OpeanAI та же задача.
Druu
22.08.2018 12:31Чем это нарушает чистоту эксперимента? Machine learning — это не про blackbox. Вносить знания о домене в модель — это нормально.
Я полагал что поставленной задачей было продемонстрировать эффективность сетей определенного типа на определенных задачах. Если в сеть вносятся какие-то априорные знания о задаче, то это уже ничего не демонстрирует. Сейчас непонятно — если бы так не сделали, то сеть бы ничему не научилась и играть бы не смогла? или это оказало не существенное влияние? Непонятно.
Сборки — это скриптинг. Читайте внимательнее — ботам даётся несколько айтембилдов / скиллбилдов, и они выбирают случайный.
Это делается для эксплоринга, при тренировке, чтобы боты смогли научиться играть с конкретными осмысленными билдами, а не перебирали их рандомно. Непосредственно в игре, естественно, никаких предопределенных билдов нет.
С лайнапами ситуация другая — ботам дают выбранные лайны и включают это в функцию потерь таким образом, чтобы боты меняли линии только тогда, когда это реально выгодно.
Опять же — это тоже делается только в тренировочных играх, чтобы боты больше наиграли с адекватными расстановками по лайнам и потом повторяли это "закрепленное поведение" уже сами.
roryorangepants
22.08.2018 12:55Если в сеть вносятся какие-то априорные знания о задаче, то это уже ничего не демонстрирует.
Кхм, как бы feature engineering никто не отменял даже для нейросетей.
Это делается для эксплоринга, при тренировке, чтобы боты смогли научиться играть с конкретными осмысленными билдами, а не перебирали их рандомно. Непосредственно в игре, естественно, никаких предопределенных билдов нет.
Пруфы? В блоге написано про рандомный выбор среди заскриптованных билдов. То же самое озвучивал на стриме разработчик из OpenAI и говорил, что это одна из вещей, от которых они хотят избавиться в ближайшее время.
Опять же — это тоже делается только в тренировочных играх, чтобы боты больше наиграли с адекватными расстановками по лайнам и потом повторяли это «закрепленное поведение» уже сами.
Эээ, ну да, во время игры никаких cost function уже нет. Вернитесь к исходному аргументу: вы говорили, что лайнапы захардкожены, и боты по линиям разводятся насильно. Я же просто сказал вам, что это не так, и лейнинг является trainable параметром. Другое дело, что в него вносятся некие priors в виде того, что изначально боты распределяются по линиям, а потом уже решают, надо ли менять это.Druu
22.08.2018 13:03Пруфы?
Это написано в разделе про эксплоринг. Нет никакого повода полагать, что это происходит как-то иначе. Но окей, быть может, я понял неверно.
Вернитесь к исходному аргументу: вы говорили, что лайнапы захардкожены, и боты по линиям разводятся насильно. Я же просто сказал вам, что это не так, и лейнинг является trainable параметром.
Я и не говорил что он захардкожен, я говорил о том, что ботам "помогли" выучить некоторое наперед заданное поведение.
roryorangepants
22.08.2018 13:22я говорил о том, что ботам «помогли» выучить некоторое наперед заданное поведение.
Нет, вы дословно сказали, что «разводка на лайны тоже осуществляется насильно», хотя по факту это просто было добавлено в cost function (как, наверняка, и ещё огромное количество других игровых элементов).
Это написано в разделе про эксплоринг. Нет никакого повода полагать, что это происходит как-то иначе. Но окей, быть может, я понял неверно.
Там написано:
We hardcode item and skill builds (originally written for our scripted baseline), and choose which of the builds to use at random. Courier
Мы хардкодим айтембилды и скиллбилды (это изначально было реализовано в рамках нашего заскриптованного бейзлайна) и случайным образом выбираем, какой из билдов использовать.
В интервью же разработчик говорил, что сейчас это заскриптовано, и они хотят в ближайшее время это устранить. Если бы это использовалось только во время обучения, зачем бы это надо было устранять? Так что как раз таки нет никакого повода полагать, что это происходит именно так, как вы описали.Druu
22.08.2018 13:25Нет, вы дословно сказали, что «разводка на лайны тоже осуществляется насильно», хотя по факту это просто было добавлено в cost function (как, наверняка, и ещё огромное количество других игровых элементов).
Если я приставлю вам пистолет к голове и скажу съесть свой галстук, то я тоже "просто добавляю cost function". А вы оп! И едите галстуки теперь!
Если бы это использовалось только во время обучения, зачем бы это надо было устранять?
Резонно. А что за интервью?
roryorangepants
22.08.2018 14:27Резонно. А что за интервью?
Интервью, которое было между картами бейзлайн-матча.
Если я приставлю вам пистолет к голове и скажу съесть свой галстук, то я тоже «просто добавляю cost function». А вы оп! И едите галстуки теперь!
Так с тем же успехом можно сказать, что боты вообще скриптованные. Ведь всё их обучение по большому счёту упирается в удачный reward для обучения.Druu
22.08.2018 14:56Ведь всё их обучение по большому счёту упирается в удачный reward для обучения.
Если у вас стоит ревард только за победу, то никаких проблем. Это же и есть цель игры.
В нашем случае дают еще реварды за голду, уничтожение вышек, убийства, снижают за обратное — но это вещи вполне логично приводят к победе, доту не выиграть, не убивая, вражеских персонажей и не ломая здания. То есть это просто некоторая оптимизация алгоритма, боты к этому в любом случае придут, просто медленнее.
С другой стороны, расстановка по лайнам — это именно навязывание конкретных тактических решений. Таким ведь образом можно и конкретным пикам расставить реварды (или пикам, удовлетворяющим определенным условиям) и вообще любым действиям. Но в таком случае это уже не будет самообучаюшейся сетью, согласитесь.
Hardcoin
22.08.2018 17:30Это тоже, что использовать базу эндшпилей для шахмат. Да, помогли, но это в целом нормально. И, кстати, может снизить качество, если эвристики не идеальны, просто обучать без них сложнее.
Hardcoin
22.08.2018 15:36+1Я полагал что поставленной задачей было продемонстрировать эффективность сетей определенного типа на определенных задачах.
Предположу, что как и в случае AlphaZero, первый этап — это решить задачу в принципе, без ограничений на априорные знания (без нейросетей задача выиграть у про игроков вообще не решается). То есть они не столько демонстрируют, сколько проверяют эффективность.
Slavik_Kenny
22.08.2018 04:00А мне интерестно, все-таки ботЫ, или это играет один бот?
Разница во взаимодействии между персонажами — либо все знают в реальном времени про все, что видят/планируют другие персонажи (один бот), либо это как и у людей — пять разных ботов, которые должны передавать информацию друг другу, тогда им соответственно нужен свой язык для коммуникации.Druu
22.08.2018 04:33А мне интерестно, все-таки ботЫ, или это играет один бот?
Один одинаковый отдельный бот за каждого персонажа.
danfe
22.08.2018 04:44При этом бот для Dota 2 — это вам не бот для шутера уровня Quake
При этом, (почти) обыгрывающие профессионалов боты для Го и Доты 2 есть, а для Quake — нет; лучшее достижении ИИ в кваке на сегодня — это умение играть в недо-CTF на плоских сгенерированных «картах» а-ля Wolf3D. Это по-своему круто и важно, но пока что далеко от настоящего Quake.
Ботов в Quake/UT несложно научить идеально стрелять и доджиться, но лучшие игроки выигрывают не столько благодаря стрельбе (хотя стрелять в кваке, конечно, уметь надо, и желательно, хорошо), а за счет знания карт, умения слушать уровень, предугадывать действия и, наоборот, удивлять соперника. Говорят, мол, Quake неинтересен для ИИ, потому что компьютер всегда перестреляет человека, — имхо, интеллект в кваке проявляется всё-таки в другом, а вещи типа времени реакции, идеального тайминга или меткости как раз имеет смысл гандикапить.Кроме того, дота — игра с неполной информацией
Как и Quake.Druu
22.08.2018 06:04При этом, (почти) обыгрывающие профессионалов боты для Го и Доты 2 есть
Вообще-то, нет.
danfe
22.08.2018 06:14Ну окей, пусть для доты пока нет, но в го AI, кажется, всех победил?
Druu
22.08.2018 06:56Ну окей, пусть для доты пока нет, но в го AI, кажется, всех победил?
В Го, конечно, победил. Но и квейк и дота сильно сложнее Го.
Попробуйте выписать полные правила Го и полные правила доты/кваки и сравнить :)Areso
22.08.2018 10:26Для кваки, где один против всех: убивай всех как можно чаще, умирай как можно реже? По-моему, предельно ясно.
Druu
22.08.2018 10:37Для кваки, где один против всех: убивай всех как можно чаще, умирай как можно реже?
Вы, кажется, забыли описать механику передвижений, как минимум. Понятие трехмерного пространства, скорости, препятствий.
Areso
22.08.2018 11:57К правилам это отношения не имеет. К алгоритмам — имеет, к АИ — имеет, но правила никак не регламентируют.
Druu
22.08.2018 12:22+1К правилам это отношения не имеет.
Конечно, имеет! Правила игры — это описание игрового состояния, возможных действий игрока и того, как действия игрока влияют на игровое состояние.
Например: "вы можете идти вперед, тогда ваш персонаж будет двигаться вперед со скоростью Х, если не упрется в стену, а если упрется — то будет Y, вы можете менять угол обзора, отчего ваш персонаж будет поворачиваться" и т.д.
Это все часть правил.
Hardcoin
22.08.2018 17:37Имеет. Просто в кваке типа обычный физический мир, к которому все привыкли (условно, конечно). Поэтому и правила, что можно делать в этом физическом мире, а что нельзя (ходить сквозь стены, например) — обычно не описывают, это и так ясно. Но боту-то не ясно, он по физический мир не в курсе, ему все эти правила надо рассказать. Ну или он может их сам изучить, случайно тыкаясь.
Vantela
22.08.2018 17:43Представил себе в обычном физическом мире рокет-джамп.
Насколько я понимаю саму суть нейронной сети, что она случайно тыкаясь должна и рокет джампу выучиться. Тем не менее на лицо эпическое отставание от кожаных игроков. Кожаный игрок один раз подсмотрит у более опытного соперника — и готово.Hardcoin
22.08.2018 22:37Не должна. Может, да. Но ей можно это и задать как одно действие и она будет его использовать как одно действие (хотя на практике там несколько действий).
Отставание потому, что у нейросети нет модели реальности, а у нас есть. Эксперименты по one-shot learning ведутся, кстати. Я б на кожаных не стал ставить на отрезке в 20 лет, скажем.
Skerrigan
22.08.2018 10:54убивай всех как можно чаще, умирай как можно реже
А вот чтобы это реализовать, надо декомпизировать еще тучу других «правил» (а затем их всех как-то «объяснить»).
Вы бы знали сколько у меня сил ушло (и лет) на то, чтобы тесты сами разбирались в каких-то простых случаях «сбоев» и не падали от этого (а сами разруливали конфликты на основе кучи правил).
Arty_Fact
22.08.2018 10:55Ага, так и го можно описать одним словом — выиграй.
Только и в го есть правила ходов и набора очков и в кваке. Только в кваке добавляются модификаторы, разное оружие, каждое из которых требуется описать и пр.
Lungo
22.08.2018 10:57По Вашему тогда правила для Доты должны выглядеть так — снеси трон. Тоже предельно ясно. Тут стоит говорить все таки про алгоритмы, а не про правила
JekaMas
22.08.2018 11:04Когда-то я слышал это про шахматы и шашки и го и шахматы.
Druu
22.08.2018 11:10Ну вот смотрите — с победы компьютера в шахматах до победы в го прошло порядка 20 лет, хотя разница в сложности между го и шахматами меньше, чем между го и дотой, квейком, старкрафтом, етц.
То что рано или поздно компьютер победит — никто, наверное, и не сомневается, вопрос в том — когда.JekaMas
22.08.2018 11:16Здравая позиция.
Но сравнивать разницу сложностей шахматы-го, го-dota я бы на глаз не взялся — слишком сильное утверждение, если не подкреплять хотя бы прикидкой на цифрах.
Может статься, что мы говорим о равных шагах нарастающей сложности.PsyHaSTe
22.08.2018 17:38Комбинаторика доты больше на порядки чем го гарантированно. Причем мне даже сложно оценить, насколько. Одно только количество комбинаций героев в игре 11,279,926,456,656. При этом у каждого героя есть несколько вариантов прокачки (около полумиллиона), и 9 слотов для одного (или нескольких из) 130. И это только изначальная установка. Дальше у нас появляются возможности сочетать всех этих геров со всеми умениями со всеми предметами…
JekaMas
22.08.2018 17:56Всего 14 знаков? В го сотня с гаком.
И вопрос был в другом N(го)/N(шахматы) <<? N(дота)/N(го)
Druu
22.08.2018 18:08Всего 14 знаков? В го сотня с гаком.
Это только пики героев. Фактически, эквивалентно первым 15 ходам игры в го, пр-во примерно тоже.
А дальше начинается, с-но, сама дота :)
Femistoklov
22.08.2018 18:01Конечно на порядки, причём я бы даже оценить эти порядки не взялся. Что там сочетания, если первое, бросающееся в глаза — позиционирование на карте во времени. Тут не сотня-другая клеток, и двигаться можно непрерывно, а не по очереди на один шаг.
dimm_ddr
23.08.2018 14:37На самом деле конечно это все равно движение шагами, просто они очень мелкие и человеку кажутся непрерывными. Ну это если придираться.
PsyHaSTe
23.08.2018 15:34Шаги настолько маленькие, что можно рассматривать поле как 100000х100000, что сильно больше поля для того же го. Так что проще считать их условно непрерывными.
dimm_ddr
23.08.2018 15:47Да проще конечно, и с масштабом поля вы скорее всего даже в меньшую сторону промахнулись, мне кажется оно там заметно больше должно быть. Это так, придирка была.
dmitryredkin
22.08.2018 13:20Учитесь читать статьи дальше их завлектельного названия.
По вашей же ссылке разжевано, что сделать снайпера — не проблема. Разработчикам пришлось специльно замедлять реакцию ботов, чтобы игра с людьми имела какой-то смысл.
ЗАДАЧА заключалась в том, чтобы обучить ботов игре в команде: огневая поддержка, распеределение ролей. И это без чатиков! И это удалось, между прочим.
З.Ы. И заметьте, в этом недо-CTF бот видел просто картинку, а не готовое игровое поле, как в Доте.danfe
23.08.2018 07:51Не только статью читал, но и pdf'ку, и не очень понимаю суть вашего
наезданедовольства. :-)
Я не умаляю значение этой работы, еще раз подчеркну: да, это круто, такие исследования я только приветствую (особенно как любитель кваки), и результаты очень интересные и воодушевляющие. Но до уверенного доминирования AI в боевых условиях против лучших квейкеров пока еще далеко.
Разработчикам пришлось специально замедлять реакцию ботов, чтобы игра с людьми имела какой-то смысл.
Да, и это вполне естественно, моторика (рефлексы) у компьютера заведомо лучше. Люди сильнее другим (с. 21):We also performed another study with human players to find out if human ingenuity, adaptivity and teamwork would help humans find exploitative strategies against trained agents. We asked two professional games testers to play as a team against a team of two FTW agents on a fixed, particularly complex map, which had been held out of training. After six hours of practice and experimentation, the human games testers were able to consistently win against the FTW team on this single map by employing a high-level strategy. This winning strategy involved careful study of the preferred routes of the agents on this map in exploratory games, drawing explicit maps, and then precise communication between humans to coordinate successful flag captures by avoiding the agents’ preferred routes.
Вполне ожидаемый результат: на нерандомной карте люди нашли нужный подход к AI и начали систематически выигрывать.
И заметьте, в этом недо-CTF бот видел просто картинку
Да, высококонтрастную картинку 84?84 px.Druu
23.08.2018 08:40Вполне ожидаемый результат: на нерандомной карте люди нашли нужный подход к AI и начали систематически выигрывать.
Скажите, а в игре на чемпионате у игроков тоже была бы возможность "попрактиковаться 6 часиков на конкретной карте" с отслеживанием перемещений ботов, drawing explicit maps и вот этим вот всем? Вы же понимаете, что это чистая метаигра?
danfe
23.08.2018 09:08Конечно: на чемпионатах заранее известный маппул, многим картам 10+ лет, все изучены вдоль и поперек, тщательно взвешены расположение и ротация айтемов, риски той или иной тактики и стиля игры, варианты opening'ов в зависимости от spawn-поинта; в общем, когда и куда бежать, когда и куда стрелять. На малознакомых картах не интересно ни игрокам, ни зрителям.
Druu
23.08.2018 09:15Так а при чем тут известная карта, нужна не известная карта, нужен противник, который согласится с вами 6 часов поиграть и дать возможность узнать его игру. В доте вон, вообще в групповых "страты не палят", ждут плейоффа. Как вы что узнавать собрались?
danfe
23.08.2018 09:45Вы меня запутали. :-) Окей, шестичасовой warmup это нонсенс, согласен, никто так не соревнуется, но и неизвестные карты на соревнованиях не играют. В кваке топ-игроки играют (тренируются) между собой постоянно и хорошо знают сильные и слабые стороны друг друга на той или иной карте (и поэтому их пикают или черкают). Думаю, показательная игра AI против людей в Quake будет проводиться на известных популярных картах, bo7-bo9.
vaslobas
23.08.2018 18:57В доте стратегии не палят, но заранее как каждый игрок играет известно, потому что до этого он уже сыграл очень много публичных игр. Это не игра с неизвестным, а вполне ожидаемые действия ждут от каждого игрока и каждый же команды.
PsyHaSTe
24.08.2018 01:01Только для турниров каждая комнда копит «фишечки», которая она нигде пока не демонстрировала. Вспомнить того же рошана на первом уровне на текущем турнире.
dmitryredkin
23.08.2018 09:291. Послать бота на обычные карты с полным набором оружия — не проблема, АI все равно. Но тогда любой журналист напишет, что роботы учатся убивать людей. Именно поэтому разрабы так старательно избегают военной терминологии. Даже вместо «стрелять» пишут «осалить».
2. Теперь по поводу второго коммента. Естественно! Как я понимаю, именно этого и добивались разрабы. Люди обучались стратегии ботов, а ботам не дали обучиться новой стратегии людей. Итог закономерен.
PsyHaSTe
22.08.2018 17:42Ботов в Quake/UT несложно научить идеально стрелять и доджиться, но лучшие игроки выигрывают не столько благодаря стрельбе (хотя стрелять в кваке, конечно, уметь надо, и желательно, хорошо), а за счет знания карт, умения слушать уровень, предугадывать действия и, наоборот, удивлять соперника. Говорят, мол, Quake неинтересен для ИИ, потому что компьютер всегда перестреляет человека, — имхо, интеллект в кваке проявляется всё-таки в другом, а вещи типа времени реакции, идеального тайминга или меткости как раз имеет смысл гандикапить.
Если бот умеет крутится на 360 градусов десять раз в секунду и всегда стрелять в голову игроку, то вы такую игру выкинете в ту же секунду. На хабре уже были статьи про то, что ботов специально вяжут по рукам и ногам, чтобы мешки с мясом не расстраивались. Пруф.danfe
23.08.2018 06:07Про мешки с мясом всё понятно; кто-то всегда играет на I'm too young to die и вообще преодолевать, так сказать, не любит. Там да, приходится вязать и притуплять. Речь, однако, о более требовательных игроках, условных «разрядниках» среднего уровня. Оказывается, что в какой-то момент суперметкость больше не гарантирует ботам победу. Те же godlike боты UT, у которых aim goes less than 1° off target, 360° field of view without line of sight limitations (meaning it sees the whole map at all times) и всё такое, или лучшие квачные боты (с нулевой реакцией и полным обзором) уверенно обыгрываются средним игроком-человеком.
Хедшотов в классических квейках, кстати, нет (разве что ачивка появилась в QL), пофиг куда попадать. Но даже если у бота, к примеру, 100% RG, ему можно просто не давать брать рельсу. :-)PsyHaSTe
23.08.2018 12:07Речь, однако, о более требовательных игроках, условных «разрядниках» среднего уровня.
Никто не любит проигрывать в 100% случаев, даже самые требовательные игроки. От этого люди выгорают, и ломают себе вещи и части тела.
Те же godlike боты UT, у которых aim goes less than 1° off target, 360° field of view without line of sight limitations (meaning it sees the whole map at all times) и всё такое, или лучшие квачные боты (с нулевой реакцией и полным обзором) уверенно обыгрываются средним игроком-человеком.
Если такие боты проигрывают, значит им подперты костыли в стиле «ты все видишь и супер-точный, но не имеешь права стрелять пока не стрельнет человек». С 100% точностью первый выстрел всегда смертельный, реакцию ботов можно было наблюдать на инте. То есть показалось 3 пикселя головы из-за угла, человек отправляется на перерождение. Конец истории.danfe
23.08.2018 14:10Никто не любит проигрывать в 100% случаев, даже самые требовательные игроки.
Хорошо, никто не любит. Проблема в том, что даже средние игроки выносят самых найтмарных ботов в Quake/UT. Невзирая на стрельбу последних в пиксел. Я не знаю, в каких ботах реализовано описанное вами правило первого выстрела, но те же кудвачные зигоки (3zb2), с которыми я чаще всего играю, точно не церемонятся. Однако и им, и всем прочим это не помогает, ибо тупые и предсказуемые.
С 100% точностью первый выстрел всегда смертельный
Господи, да нет конечно! Если вы бегаете голым, то ССЗБ. Как минимум одну (а лучше две) рельсы надо стараться держать.
реакцию ботов можно было наблюдать на инте.
Простите, какую реакцию, что за инт?PsyHaSTe
23.08.2018 15:36Господи, да нет конечно! Если вы бегаете голым, то ССЗБ. Как минимум одну (а лучше две) рельсы надо стараться держать.
Если мы про 1х1 говорим, то всевидящие боты которые идеально стреляют всегда будут размениваться по ХП в свою пользу и вовремя подпирать павер апы. Если они этого не делают, то скорее всего они специально ослаблены, хотя это и не афишируется.
Простите, какую реакцию, что за инт?
Время реакции на изменение ситуации, на The International, который обсуждается в статье.danfe
23.08.2018 15:59Какой-то минимальный гандикап, скорее всего, есть (случайный разброс в несколько процентов при стрельбе и таймингах), чтобы сделать игру хоть чуть-чуть похожей на настоящую, но сути это не меняет: боты не могут составить конкуренцию более-менее опытному игроку с ?35% LG/RG.
The International, который обсуждается в статье.
А, я думал это из кваки что-то и никак не мог понять, что же. :-/
Desavian
22.08.2018 10:40Тут есть еще один немаловажный момент, на реддите в теме про ограничения дообсуждались до того, что использование Bottle по общему времени обучения превышает _все_ что сделали боты до этого в три раза. То есть обучение использовать одну вещь сложнее, чем обучение 5 ботов разнести 6к ммр солянку в рандом драфте.
Так что не знаю что будет сейчас на турнире, но до полноформатного боя без ограничений имхо еще месяца три-четыре при текущей скорости обучения.roryorangepants
22.08.2018 10:42Тут есть еще один немаловажный момент, на реддите в теме про ограничения дообсуждались до того, что использование Bottle по общему времени обучения превышает _все_ что сделали боты до этого в три раза. То есть обучение использовать одну вещь сложнее, чем обучение 5 ботов разнести 6к ммр солянку в рандом драфте.
Это настолько жёсткое преувеличение, что тут даже говорить нечего.
Возможно, даже ограничение на курьеров сложнее, чем на ботл (из-за того, что боты научились весьма неадекватно абузить наличие пяти неуязвимых курьеров).Druu
22.08.2018 10:47боты научились весьма неадекватно абузить наличие пяти неуязвимых курьеров
Боты как раз в данном случае действуют очень адекватно и логично :)
roryorangepants
22.08.2018 10:52Неадекватно с точки зрения игроков-людей и нормальной доты, где не получится себе нон-стоп носить фласки во время драки.
Desavian
22.08.2018 11:24Будет одна кура — будут ее абузить. Идеальный тайминг, когда в куру засовывается все, что нужно для всех героев во все слоты при этом с минимальным временем стояния курьера на фонтане — даже для про игроков часто является большой проблемой.
roryorangepants
22.08.2018 11:27Абуз курьера был не в том, что боты идеально быстро закупались и клали в неё предметы, а в том, что они безостановочно носили пятью курьерами себе предметы на регенерацию, принося их прямо в замесе и тут же восстанавливая себе здоровье и ману.
Во-первых, с одним курьером они бы банально не могли обеспечить себе такую интенсивность принесения предметов (можно обратить внимание, что большую часть времени было задействовано 1-3 курьера сразу). Во-вторых, с уязвимыми курьерами боты бы не смогли так беспечно носить эту регенерацию в моменты столкновения с игроками.Druu
22.08.2018 11:41Ну тут основная проблема в коммуникации. Крипов боты друг у друга вполне бодро подворовывали, с 1 курьером, не сомневаюсь, мы бы пронаблюдали каноничное "кто куру реюзнул, твари??7?" :)
Так что, чтобы без токсичности — каждому по куре и все довольны :)Pariah
22.08.2018 15:16Про крипов, возможно, это они так уравнивали уровень. Об этом писали в предыдущей статье.
Druu
22.08.2018 15:46Про крипов, возможно, это они так уравнивали уровень. Об этом писали в предыдущей статье.
Были моменты, когда боты замахивались на одного и того же крипа. Успевал убить, конечно, только один.
Desavian
22.08.2018 12:27Кто спорит… без четких ответов разработчиков это всё домыслы… но тогда я не понимаю с чем связан запрет на бутылку и рапиру…
BlackMokona
22.08.2018 12:47Рапира единственный артефакт который может выпадать, а болт крайне своеобразный
Desavian
22.08.2018 13:26да ладно, гем же разрешили, чем он от рапиры отличается? В механике выпадения ессно) а то набегут, скажут что гем урона не прибавляет )
TimsTims
22.08.2018 13:57Совсем скоро обидное слово: "да ты бот" поменяет свой смысл ровно на противоположный...
stanislavskijvlad
22.08.2018 15:04Вот бы популярность доты конвертировать во второй Старкрафт )
Arastas
22.08.2018 15:37Ну пока что у DeepMind конкурировать с людьми, на сколько я знаю, не получается. Максимум речь идёт о решении отдельных задач на микроконтроль. При этом мне не очевидно, чтобы DeepMind как исследовательский коллектив были существенно слабее OpenAI. Так что, возможно, дело в сложности игры.
Отмечу также, что даже начинающие игроки (серебряная лига) без особых проблем обыгрывают встроенный ИИ на максимальной сложности.Druu
22.08.2018 15:50Про ск, кстати, интересный момент — с одной стороны, игра, вроде, сложнее, т.к. очень большое количество юнитов, с другой стороны — в ск сильно больший уклон в сторону тактических элементов и краткосрочных обжективов, а боты из сабжа как раз отлично справляются в тактике, но полные нули стратегически. То есть как раз в случае ск они зашли бы, по логике, лучше.
Возможно, тут проблема в инкрементальности — опенАИ сперва выкатили бота 1в1, и это было как бы осмысленно, сейчас вот пул с 16 героями, и это тоже воспринимается ок, хоть и понятно, что "не дота". Плюс захардкоженные билды.
но как это было бы в старкрафте? сделать бота зерга, который будет играть только рабами и зерлингами и при этом в захордкоженных бо? Ну даже не смешно, это никто не будет всерьез обсуждать.Arastas
22.08.2018 16:01Я видел ваше сообщение в параллельной теме, но не стал тогда комментить. :)
Мне совсем не очевидна справедливость Вашего тезиса, что sc2 стратегически проще доты. Где вы проводите раздел между тактическими задачами и стратегическими?
Во второму вопросу: можно показывать убедительное микро, можно показать игру бота против встроенного ИИ.
Druu
22.08.2018 16:16Мне совсем не очевидна справедливость Вашего тезиса, что sc2 стратегически проще доты. Где вы проводите раздел между тактическими задачами и стратегическими?
Это вопрос хороший, т.к. разница тут где-то там же, где несколько зерен становятся кучей :)
Я провожу водораздел где-то в области многошавости — например, план "сделаю забегание/дроп, чтобы нанести урон экономике", это что-то тактическое, т.к. конкретное действие и конкретный результат, сразу. Или: "пойдем и погангаем этого персонажа" — это тоже что-то тактическое. А вот если: "там много контроля, одному из коров не хватает 1к до бкб, значит, он должен пойти пофармить на него, значит надо создать спейс, фармить он будет вот тут, сюда на подходе ставим один вард, а сами будет разводить грязь здесь, значит, здесь ставим второй, собрались, пошли" — то вот это уже ближе к стратегии. Многоходовочка :)
Опять же, количество разных бо и вообще, скажем так "условно работающих стратегий" в старкрафте на порядок меньше. С-но и выбор стратегический (как играть в общем) существенно уже.
Во второму вопросу: можно показывать убедительное микро, можно показать игру бота против встроенного ИИ.
Ну, убедительное микро зерлингами вс танков показывали и без нейросетей :)
Arastas
22.08.2018 16:43Я всё-же не соглашусь, но не хочу уходить в детали. Мне кажется, что вы доту знаете лучше, чем sc2. :)
Ну, убедительное микро зерлингами вс танков показывали и без нейросетей :)
Именно! Пусть теперь AI этому сам обучится, для разных карт и рельефов! Чем не вызов?
BingoBongo
22.08.2018 15:51DeepMind в Старкрафт уже играет www.youtube.com/watch?v=St5lxIxYGkI
Arastas
22.08.2018 15:55Мой тезис был: "у DeepMind конкурировать с людьми, на сколько я знаю, не получается". Я не увидел, чтобы видео по ссылке ему противоречило. Я что-то пропустил?
WinPooh73
22.08.2018 16:39А если ИИ не будет знать, что делать, он примется в задумчивости «шевелить пальцами», как компонентный робот из рассказа Азимова «Как поймать кролика».
tSmoker
22.08.2018 16:51Не совсем по теме, но может кто в курсе, как там дела у ДипМайнда и StarCraft2?
forcam
22.08.2018 18:2422 августа искусственный интеллект OpenAI сыграет первый матч против профессиональной команды.
Матч состоится перед началом встречи Team Liquid и PSG.LGD, в 2 часа ночи по Москве. Пока составы команд и формат мероприятия неизвестен.
Интересный скрин с оф сайта OpenAI ( openai.com/five )

BingoBongo
22.08.2018 18:38В 2 ночи и в 23 уже назначены матчи: www.dota2.com/international/schedule/6/0/?l=russian. Так понимаю, где-то между ними стоит ждать.
Druu
23.08.2018 13:00Давайте все же будем корректными — бот еще не умеет играть в доту. Ни на сколько ммр.
Этот график — то же самое, что если бы бот играющий в го на поле в 6-6 вместо 19-19 кого-то там обыгрывал и ему бы ставили соответствующее звание.
Pusk1
22.08.2018 19:39-1Посмотрел, как OpenAI разорвал в клочья людей в предыдущей битве. Думаю, что у белковых особей крайне мало шансов, особенно в первой игре. Наверняка играть будут те, кто вылетел из основного турнира. Времени на разработку тактических уловок именно против ботов у них будет немного.
forcam
22.08.2018 20:47+1По прошлой игре сказать что-то сложно, потому что там была солянка и играли они совершенно не сыграно, многие моменты там были интересные, но сказать, что-то определенное можно будет только сегодня.
Frank59
23.08.2018 07:01кто смотрел? какой результат?
Druu
23.08.2018 07:13Ожидаемый — люди заабузили непонимание ботом лейта, затянули и выиграли.
Курьеров, кстати, пофиксили, сейчас он один, уязвимый. Бот два раза отдал его :)n1ger
23.08.2018 08:22Ну и ещё люди не абузили, а использовали то, что называется макро игра.
По микро было видно — бот красавчик, чего стоят ветра на акса перед агром после блинка. А вот момент там где боты бьют рошана, а акс сносит им сторону и они игнорят — это странно. И таких макро проигранных ситуаций было очень многоDruu
23.08.2018 08:35Ну и ещё люди не абузили, а использовали то, что называется макро игра.
Ну, да, абузили не совсем верное слово. Просто выбрали ту стратегию, которая хороша против этих ботов.
И таких макро проигранных ситуаций было очень много
Ну, игроки тоже там не раз замисплеили.
tSmoker
23.08.2018 09:56Не спал пол ночи, болел за «наших». Перед игрой OpenAl посмотрел два матча на вылет «живых людей» и в целом происходящее на экране становится понятным на уровне — «вот наши, а вот не наши, тут вот большой замес и размен 2:3 это плохо, а тут 2:1 это хорошо, какие-то деньги (или их дельта) обозначается рядом со счетом фрагов и чем их больше тем соответственно лучше».
Игра с ботом оказалась довольно длинной — чуть не час. И в какой-то момент в середине игры казалось, что боты доминируют и исход ясен, но очередные «качели» и люди вырвались вперёд.
Очень жаль конечно.
Но надеюсь разработчики на этот (и следующие два) матча включат ботам галочку «сделать максимальные выводы из прошедшего матча». Ну и то, что боты между собой не общаются это конечно приводит к ошибкам откровенным.
Жаль игры поздно (или рано) очень. До конца недели так и не высплюсь.Superl3n1n
23.08.2018 10:00Игра в записи, для любопытныхdanfe
23.08.2018 17:39Спасибо за ссылку, посмотрел с удовольствием; хотя в доте ничего не понимаю, но кастеры молодцы, было приятно послушать. Жаль, конечно, что ничего похожего по размаху и качеству для кваки нынче не проводится. :-(
Desavian
23.08.2018 11:15Мда, я рассчитывал что в первой игре люди не успеют так быстро адаптироваться. А ведь пейны — первые вылетевшие с турнира еще в квалификациях, хоть и не сказал бы что худшие =( куровень тех же ликвидов значительно выше.
з.ы. нет, не описка =)
а если серьезно, по ночной игре стало четко понятно, без коммуникации ботов — шансов победить команду из топ 20 нынешних весьма мало. Даже аутсайдеры в виде пейнов поняли что боты ничерта не знают про сплитпуш и виха просто разводил как детей их =((
Плюс система ревардов требует переделки, она должна быть динамической, а тут, судя по тому что боты не сделали синхронный тп с рошана чтобы отбить акса — он статический и не учитывает изменение обстановки. То есть если на момент начала атаки на рошана ревард был максимальный, никакие внешние действия не могли его сбросить и отменить атаку ботов… что выглядит весьма странно.
Резюмируя, надеялся на гораздо лучший результат от ботов. Оказалось, что при резком повышении уровня игры людей, все обучение ботов разваливается. Ну… будем посмотреть что в следующем матче будет, возможно поиграют с теми, кто вылетел уже в финальной стадии… предполагаю NewbeePsyHaSTe
23.08.2018 12:12Плюс система ревардов требует переделки, она должна быть динамической, а тут, судя по тому что боты не сделали синхронный тп с рошана чтобы отбить акса — он статический и не учитывает изменение обстановки. То есть если на момент начала атаки на рошана ревард был максимальный, никакие внешние действия не могли его сбросить и отменить атаку ботов… что выглядит весьма странно.
Она, конечно же, динамическая, но боты решили, что рошан важнее. Собственно многие мясные команды приняли то же решение. Хотя ни одна из них не дошла бы до TI, это верно. Не забывайте, что решение отдать рошана за барак могло быть выигрышным, «странным ходом» по аналогии с альфа го. Просто боты зашли в лейт где и умерли, не потому, что отдали барак, а потому что кастовали по 5 скиллов в одного саппорта, после чего оставались беззащитными против снайпера.
Резюмируя, надеялся на гораздо лучший результат от ботов. Оказалось, что при резком повышении уровня игры людей, все обучение ботов разваливается. Ну… будем посмотреть что в следующем матче будет, возможно поиграют с теми, кто вылетел уже в финальной стадии… предполагаю Newbee
Не думаю, что 480 миллионов сыгранных за сегодня игр сильно улучшат игру ботов, так что более сильный ньюби ботов и так уделают. Скорее имеет смысл собирать более слабую команду, например из комментаторов или зрителей.Druu
23.08.2018 13:06Просто боты зашли в лейт где и умерли, не потому, что отдали барак, а потому что кастовали по 5 скиллов в одного саппорта, после чего оставались беззащитными против снайпера.
Странно, кстати, что пейны в принципе не абузили байты, т.к. то, что боты принципиально не могут в менеджмент ресурсов было достаточно очевидно по предыдущим играм.
Причем проблема это скорее всего архитектурная, будет интересно, как с ней справятся (если справятся).
По идее им надо очень существенно подправлять все реварды, как в плюс так и минус, ну и еще увеличивать долгосрочные реварды. Проблема в том, что это плохо влияет на сходимость, кроме того, тонкий тюнинг ревардов в итоге может перейти просто в аналог рукописного алгоритма...
Desavian
23.08.2018 13:57Я бы реально профессионального дота игрока бы пригласил, чтобы он прописал базовые настройки с которых боты начали бы обучаться. Ну в скольких матчах отдача сыра и аегиса личу помогла выиграть чтобы боты эту шизу сотворили?
Druu
23.08.2018 15:26А что писать в настройках? "никогда не отдавать аегис и сыр личу"? Так могут быть ситуации, где это разумно.
Desavian
23.08.2018 15:41Нет) Аегис — возрождает персонажа после смерти, поэтому его надо отдать персонажу, который после смерти может внести максимальный импакт и тогда аегис не будут отдавать личу, который после ульты нафиг не вперся, ликану, который без ульты мало что представляет и т.п. Сыр будут отдавать тем, кто ввиду достаточной подушки хп/брони может не умереть мгновенно и успеть его съесть
Druu
23.08.2018 15:49Нет) Аегис — возрождает персонажа после смерти, поэтому его надо отдать персонажу, который после смерти может внести максимальный импакт и тогда аегис не будут отдавать личу
А что если в данный момент его может забрать только лич? Остальные в стане стоят, допустим? Или лич крадет аегис с блинка и потом умирает отдавая его офк, но при этом аегис не достается противнику.
PsyHaSTe
23.08.2018 15:40Ну в скольких матчах отдача сыра и аегиса личу помогла выиграть чтобы боты эту шизу сотворили?
Это ваш белковый мозг говорит, что отдавать аегис личу плохо. А может быть без этого сыра игра была бы проиграна на 5 минут раньше? Если бы альфа го проиграл, то все бы винили тот «странный» ход в этом, хотя на самом деле сейчас нам всем очевидно, что он был выигрышным.
Отдача аегиса личу это «questionable at best..» ©, но никто в мире не скажет, что это плохое (или хорошее) решение. Просто один из факторов, и никакого понимания, помог он ботам или проиграл — нет. Все, что можно сказать, что текущая мета считает, что сыр должен получать кери персонаж. Не более того.Desavian
23.08.2018 16:12я скажу) отдача аегиса личу, если это не кража из-под носа оппонента, это ВСЕГДА плохо. Потому что лич это герой, который после раскаста теряет 80% своей эффективности и его оживление несет исключительно мало пользы.
Причем тут текущая мета? Кери персонаж — это персонаж который тащит в лейте игру. Будет кери лич — будут ему давать аегис…PsyHaSTe
23.08.2018 18:05я скажу) отдача аегиса личу, если это не кража из-под носа оппонента, это ВСЕГДА плохо.
просто нет.
Причем тут текущая мета? Кери персонаж — это персонаж который тащит в лейте игру. Будет кери лич — будут ему давать аегис…
А вот бот считает, что через 2 минуты возрожденный лич накинет броню и это зарешает игру.vaslobas
23.08.2018 19:09Как Лич зарешает игру в лейте?
PsyHaSTe
24.08.2018 01:01Кинет броню в нужный момент, я вроде написал.
vaslobas
24.08.2018 01:38И что броня изменит? Наврятли броня что-то может изменить.
Druu
24.08.2018 06:58Конечно, может — ваш керри вместо того, чтобы умереть, останется в живых на 200хп после стана, включит сатаник и развалит команду противника :)
vaslobas
24.08.2018 13:17Так может сразу отдать сыр и аегис Керри, чтобы он и сыр прожал и реснулся тут же на месте?
И наличие у Керри сыра и аегиса сильно охлаждает пыл соперников, потому что они понимают какой геморрой убить два раза Керри.PsyHaSTe
24.08.2018 13:56Иметь фуллового кора (от сатаника) и саппорта строго лучше, чем фуллового кора (после аеги) и дохлого саппорта.
MINYSMOAL
23.08.2018 15:45До матча разработчики говорили, что боты вообще не забирали рошана, только в супер исключительных ситуациях.
Видимо, научили забирать, а кому отдавать аегис и сыр пока нет)
forcam
23.08.2018 19:28Ну вы же сами понимаете что тут до банального просто, боты не умеют расставлять приоритеты, потому что в лейте играли 1% игр, но для 1% игр, такая игра более чем достойная. Поэтому банально, если им создадут условия для тренировки лейта, они справяться и в нём. И да, с вардами была полная беда, если бы они их хотя бы по ключевым точкам ставили (тупо по вариативному шаблону) — они бы на порядок лучше сыграли и не факт, что пэйн в этом случае выиграл бы. Там был момент, когда действительно стояли варды, так они в этом случае просто без шансов «вырезали». Когда у них был хороший обзор (вижн) — они действовали очень хорошо.
vaslobas
23.08.2018 20:09Война за варды это чуть ли не отдельная дисциплина. Она тоже очень вариативна и сложна.
Пока у ботов с этим полный провал.
forcam
23.08.2018 23:02Мне кажется надо выделять три отдельные ветки развития, вардная война, лейтовая война и начальная стадия и всех их развивать параллельно, тогда и толк будет, они то могут дать им определенные условия, вот и вперед.
PsyHaSTe
24.08.2018 01:03Сложно дать ботам преимущество, не выплеснув с этим ребенка и не заскриптовав его нафиг. У нас уже есть скриптованые боты, нужно, чтобы они сами поняли, что варды полезны и как их надо ставить. Только так можно получить качественно новое понимание игры, как в случае с альфа го.
Druu
24.08.2018 07:00Проблема с лейтом серьезнее, чем вы полагаете. В лейте гораздо большее значение принимают факторы с отложенными последствиями — это и покупка итемов, и менеджмент ресурсов. А эти боты наперед смотреть не умеют.
Аналогично с вардами — последствия установки варда в конкретном месте очень отложены и ситуативны.
PsyHaSTe
23.08.2018 12:09Но надеюсь разработчики на этот (и следующие два) матча включат ботам галочку «сделать максимальные выводы из прошедшего матча». Ну и то, что боты между собой не общаются это конечно приводит к ошибкам откровенным.
Сильно сомневаюсь, что это возможно. Так что это 1 проигранная игра из скольких там триллионов сыгранных? Ей могут поставить очень сильные весы, но все равно сильного влияния она оказать не может на обучение бота.
Hardcoin
23.08.2018 12:51Позднюю игру боты не могут. Неправильные предметы и неверный размен (нельзя качать вражеского керри). В следущей их вынесут как котят на этом. Керри фармится, потом забирает всех ботов.
Но игра крутая. Тоже не ожидал, что кремниевые так облажаются, на середине игры думал, что победят (когда к соперникам наверх зашли).
Druu
23.08.2018 13:09Позднюю игру боты не могут. Неправильные предметы
У них предметы заскриптованные из гайдов, как выше выяснили. Тут вообще трудно каких-то успехов в лейте ожидать, с таким-то подходом.
Druu
23.08.2018 13:05Игра с ботом оказалась довольно длинной — чуть не час. И в какой-то момент в середине игры казалось, что боты доминируют и исход ясен, но очередные «качели» и люди вырвались вперёд.
Очень жаль конечно.Здесь над понимать, что нельзя сказать, что боты доминировали в середине. У ботов был выбор героев, который очень силен в середине игры из-за мощного прокаста, и просадка людей в этот момент была логичной, задача людей в этот момент не была выигрывать игру — она была затянуть игру, перевести ее в позднюю стадию не отдав критического преимущества. Более того — это был исходный план на игру в принципе. Иными словами — игра изначально шла по плану людей и никуда от этого плана не отклолнялась, в том числе и в середине. Ну а дальше просто по времени:
30 минута: все вроде плохо, боты жмут людей со всех сторон
31 минута: снайпер покупает бкб (предмет, который дает при использовании временную неуязвимость к магии — что делает прокаст ботов малоэффективным)
33 минута: акс покупает бкб
35 минута: пейны зажимают ботов на их базе, резво убивают гирокоптера за вышкой, ну и в этот момент игра закончилась. Оставшиеся 15 минут — пейны просто развлекались.Desavian
23.08.2018 16:03Боты вообще не доминировали, как только выяснилось что у ботов макроигры нет, любая партия длиннее 30 минут резко понижает их шансы выиграть, а уж пикнуть что-то в расчете на лейт смогут не только пейны.
Druu
23.08.2018 16:07Ну это все было вобщем-то очевидно еще с предыдущих игр, пейны-то не просто так лейт взяли :)
Посмотрим, может, завтра что-нибудь подкрутят в быстром темпе.
lechebu
23.08.2018 10:31Информация о матчах появилась на официальном сайте Dota 2 в разделе с расписанием игр плей-офф The International. Всего OpenAI сыграет три матча за три дня с про-игроками. Первая игра состоится примерно в 18:30-19:00 по МСК (точное время пока не указано).
Судя по информации на приведенном сайте, игры OpenAI будут проходить каждый день после 2-х игр турнира. Если так, то время игр — ближе к 1:00-2:00 по МСКCrossover Автор
23.08.2018 10:32Расписание было изменено уже через сутки после публикации статьи. Форс-мажор.
Pusk1
23.08.2018 11:11Посмотрел матч. OpenAI ничего не смог сделать со снайпером, который ко второй половине игры стал очень силён. На 25-й минуте люди переломили игру. В первой половине AI выглядел более сильно. При другом наборе персонажей успех проф. игроков не гарантирован.
PsyHaSTe
23.08.2018 12:14Вроде бы игры ботов и длятся 20-30 минут, так что то, что бот тупо не знает как играть дальше сильно заметно по игре. Остаются заскриптованные билдордеры и фарм. Напоминает мою среднестатистическую команду людей :)
vaslobas
23.08.2018 19:18Снайпер это лейт, персонаж который раскрывается в поздней игре. Вначале он крайне слаб и уязвим. Его оберегают, холят и лелеят его команда поддержки, чтобы он раскачался и зарешал. Это тактика
стара как миризвестна примерно с момента появления доты как карты к вар3. Пока боты не поймут, что лейта нужно всяческих харасить ака убивать/не давать качаться, а будут самозабвенно убивать сапортов, то проигрывать они будут практически всегда.
Druu
24.08.2018 07:01При другом наборе персонажей успех проф. игроков не гарантирован.
Сегодня сыграли с обратным пиком :)
В итоге развал был еще сильнее, хоть и менее надежный, несмотря на то, что играла более слабая команда.
tSmoker
23.08.2018 11:13Ну вот то, что победа людей не выглядела такой однозначной, еще больше подогревает интерес к предстоящим двум матчам.
forcam
23.08.2018 11:32Ну боты еще сыры, но показывают очень приличный уровень,
1) разрабам нужно сделать установку вардов хотя бы по ключевым точкам, а дальше что бы боты сами решали куда им этим варды более выгодно ставить
2) после 25ой минуты боты почти не играли, что и создало проблему, суть тут скорее всего в том, что к 25ой минуте одна из сторон получает слишком сильное преимущество, следовательно как такого лейта не получается.
мне кажется допилят и будет очень весело)
JTG
23.08.2018 11:47+1ветра на акса перед агром после блинка
А напишите кто-нибудь, пожалуйста, статью по итогам всех матчей с разбором «для чайников» :)devlev
23.08.2018 12:03-1Присоединяюсь)

friday13ant
23.08.2018 17:08Описание механики игры, способностей героев и предметов можно почитать здесь.
ru.dotawiki.org/wiki/Heroes
ru.dotawiki.org/wiki/Items
Эти описания для версии DOta 2 7.04, текущая версия 7.18. Но значительных изменений нет, в каждой минорной версии немножко меняют параметры способностей героев и стоимость предметов и количество маны на заклинания.
Примеры вот здесь dota2plusz.ru/patchs
Последний крупный патч 7.08 — где переработали таланты героев. Дота еще и очень динамичная игра, в Valve должно быть целое подразделение аналитиков и BigData с показателями матчей, % выигрыша героев, которые постоянно анализируют и дорабатывают игровой процесс.PsyHaSTe
23.08.2018 18:06Все актуальные механики можно посмотреть здесь: https://liquipedia.net/dota2/Portal:Game_Mechanics
PsyHaSTe
23.08.2018 12:17Ветра — eul, который дает 2.5 секунды неуязвимости. Кастуется мгновенно на себя или противника.
Агр — скилл, вынуждающий ближайших противников атаковать танка (как правило, с включенным артефактом возвращения урона, так что противник убивает сам себя). Особенность — время активации после нажатия 0.25 секунды.
Блинк — телепортация на короткое расстояние.
Соответственно, суть в том, что герой телепортировавшись на короткое расстояние нажимает агр. На людей это действует ибо среагировать за 0.25 секунды можно только если ты ОЧЕНЬ сконцентрирован и у тебя неплохой класс игры. У бота же реакция ограничена 200мс, соответсвенно он всегда успевал использовать предмет на себя (eul) и избежать нападения.
Tsimur_S
23.08.2018 12:22использовать предмет на себя (eul)
На Акса.Tsimur_S
23.08.2018 12:32youtu.be/O68pmEklZAI?t=807 типичный пример, акс блинканулся из инвиза и попал в ветра.
PsyHaSTe
23.08.2018 12:491. когда акс был под бкб — еул на себя
2. когда был блинк (на тх) — то блинкаут себя :)
friday13ant
23.08.2018 16:56Концовку драки, кстати, боты провели очень неплохо и тактически размотали команду людей.
Death Propet после смерти выкупилась. Тайд блинканулся к Снайперу, его зафиксировали Атосом (Road of Atos) на 2 секунды. Акса (Axe) еще раз подняли в воздух EUL-ом, чтобы выключить его из битвы. Лич по ходу битвы даже восстановил здоровье из своего шрайна.
MINYSMOAL
23.08.2018 12:33Очень слабо отыграли. Линии проиграли. Но потом камбекнули за счет того, что люди сначала не понимали, что если бот нападает значит он точно уверен, что вы труп, т.е. файты принимать не надо. Да и надо сказать, люди тоже не совсем ответственно играли. Боты кроме супер таймингов на способности и предметы ничего не показали.
В общем будь там хороший призовой за матч для мотивации людей и какие-нибудь ликвид/псж, боты отлетели бы за 20 минут без шансов.
Rad1calDreamer
23.08.2018 16:29как и ожидалось. Даже самая слабая команда TI, а там кроме Вихи вообще мало кто в кнопки жать толком умеет, уделала железяк. Посмотрим за следующей серией
friday13ant
23.08.2018 17:10-1Интересно какие сферы применения OpenAI 5 вы видите в реальной жизни и бизнес-задачах?
Hardcoin
23.08.2018 17:33+1Это же исследовательская работа. Какие сферы применения есть у мышек, которых гоняли по лабиринту?
forcam
24.08.2018 07:40Второй день игры с ботами (вторая игра с новой командой ПРО игроков):
www.twitch.tv/videos/300912622
c 07:14:10
Desavian
24.08.2018 07:45мда, во второй игре выпустили бывших продотеров(ок, нынешних тренеров команд… но это совсем не текущий уровень), очень зря =( проигрыш текущим топам никого бы не удивил, а опускать планку в расчете на выигрыш и все равно сливать — весьма странно… Причем это не сыгранная команда как пейны… а сборная солянка.
Ботов подкрутили, весьма заметно, но начались другие проблемы, лучше всего видно на 21:03 когда бот на аксе лепит ульту в полностью живого лича при том, что он и так гарантированно умирал от вд и снайпера… причем дальше это продолжается… на 37:20 например… есть мнение что снятие ботов с ручника, на котором они стояли в первой игре, как-то поломало систему ревардов по использованию способностей.Druu
24.08.2018 08:24мда, во второй игре выпустили бывших продотеров(ок, нынешних тренеров команд… но это совсем не текущий уровень), очень зря =( проигрыш текущим топам никого бы не удивил, а опускать планку в расчете на выигрыш и все равно сливать — весьма странно… Причем это не сыгранная команда как пейны… а сборная солянка.
Так тут уже планку надо опускать до аматуров, потому что просто все после первой августовской игры поняли как этих ботов выигрывать в макро, а пейны вчера подтвердили это практикой. единственный вариант для ботов побеждать — это либо снос на скиле до лейта (то есть надо против них сажать людей, которые просто не смогут продержаться в мидгейме, ну либо завтра если будет сильная команда они могут попробовать не идти в лейт а попытаться вытащить мид в игру ботов, закономерно сольют), либо удачный залет мясных мешков в лейте, когда отдадутся коры без байбека и боты успеют пронести пару лайнов.
Ботов подкрутили, весьма заметно,
Это вы по каким критериям определили?
Точно так же они играют, как и играли. С-но еще пару десятков игр и можно будет предсказывать их расстановку обжективов наперед (уж больно он примитивен на данный момент), выполняя классический абуз кремниевого дебила.
есть мнение что снятие ботов с ручника, на котором они стояли в первой игре, как-то поломало систему ревардов по использованию способностей.
Никто ботов ниоткуда не снимал, они и до этого не расчитывали ресурсы.
Desavian
24.08.2018 08:32Ну я видел косу некра для спасения, это можно объяснить, но бесполезную ульту акса в фулл хп героя раньше не замечал, с вардами получше стало, не верю что за одну игру так наладилось, боты научились биться в двух разных файтах, которые идут рядом, не отвлекаясь друг на друга как в самом начале было. Возможно я и не прав и это просто так сложилось, но разница заметна.
Druu
24.08.2018 08:40А как вы вообще видите "снятие с ручника"? :)
У вас есть сеть которая полтора года уже тренируется, можно подкрутить или заскриптовать какой-то явный момент, но научить за день абстрактному навыку, которому не получилось научить за полтора года — это нереально.
Тем более, как вообще (чисто гипотетически) учить, например, "расставлять варды"? Сети же сами с собой играют, сами выбирают, как будет проходить игра. Вы не можете им сказать: "тренируйтесь варды ставить, сволочи", они сами, если захотят :)forcam
24.08.2018 08:44Они играют 4 млн игр в день, разрабы, по моим прикидкам им только векторы раздают, а те уже под эти векторы развиваются. Если честно парочка вардов прямо впечатлила, там возле рошика они были очень хорошими) В любом случае, вторая игра мне больше понравилась чем первая и я часто думал, а чем реально они отличаются от людей и особой разницы не увидел, если убрать всякие косяки типа ульты в фул хп и иногда кривого вардинга, то вполне себе достойно. Я думаю с таким прогрессом как мы наблюдаем, через год их уже никто не выиграет.
Druu
24.08.2018 08:59Они играют 4 млн игр в день, разрабы, по моим прикидкам им только векторы раздают, а те уже под эти векторы развиваются.
Ну вот смотрите, сеть наиграла 2 миллиарда игр, вы теперь хотите чтобы она все это забыла и быстро поправилась за 4 миллиона? :) Это же всего 1% от всего "опыта".
а чем реально они отличаются от людей и особой разницы не увидел, если убрать всякие косяки типа ульты в фул хп и иногда кривого вардинга, то вполне себе достойно.
Отсутствием стратегии они отличаются :)
ульты в фуллхп и вардинг как раз мелочи, просто люди (если это нормальная команда) имеют план на минуту вперед и на 10 и на 30 и до конца игры. И это прослеживается в игре, начиная с пиков. А боты — выполняют сиюминутные обжективы. Вот сейчас хочется снести вышку — идут сносят вышку, после этого им кажется что хорошо бы убить героя Х — идут убивать героя Х. Но все это не складывается в какой-то последовательный план. Просто выполняются какие-то действия, которые хороши в данный момент. При этом сами они выполняются очень хорошо, то есть если боты идут сносить вышку или убивать героя — они делают это прекрасно.
Я думаю с таким прогрессом как мы наблюдаем, через год их уже никто не выиграет.
Вы не забывайте, что это не дота пока, пул всего 16 героев. Я уже выше приводил в пример с го с 8-8 клеток вместо оригинального 19-19.
forcam
24.08.2018 09:56Я не спорю про стратегию, тут вы бесспорно правы, но эволюция такова, что боты разрабатывают все более сложные схемы, что бы действовать, именно тем и хороша дота, что она способна помочь в создании намного более сложных стратегий чем раньше. Прикол в том, что боты переняли опыт из прошлой игры и учатся они очень быстро, как по мне, если конечно это не костыли, типа навязанных шаблонов поведения. В любом случае это самые «умные» боты, из тех что пока создало человечество)
Druu
24.08.2018 10:12что боты разрабатывают все более сложные схемы
Ну, этого мы как раз пока не увидели. Как играли в лоб, так и играют.
Прикол в том, что боты переняли опыт из прошлой игры
С чего вы взяли? Боты ничего не перенимали. Более того — эта игра вообще на ботов никак не влияла с вероятностью чуть менее чем наверняка. Для этого боты должны играть в режиме обучения, что смысла не имеет, т.к. одна игра на миллиарды — это просто ничто.
Tsimur_S
24.08.2018 12:34можно увеличить штрафные коэффициенты нейронок в разы во время игр с людьми.
Druu
24.08.2018 08:30ок, нынешних тренеров команд
Кстати, тренеры команд макро могут понимать намного лучше игроков (особенно уж товарищи вроде ксяо8) и гораздо быстрее адаптироваться. Учитывая, что это именно то, в чем боты слабы — не факт что именно против ботов такая команда будет слабее (хотя она безусловно слабее в рамках человеческой доты) :)
Desavian
24.08.2018 10:08Да кто спорит, я к тому что в данный момент нужен вау эффект, а он достигается прежде всего именно эффектностью. В прошлом году кастрированный вариант solomid всех шокировал и заставил сильно думать при том что ограничений там был миллион, потому что реально было видно что про игроки не могут, как это называется, «втащить на скиле и микро сраную железяку» (с) не помню кто сказал из ютуберов.
А сейчас что? Сейчас зрители видят весьма посредственную команду ботов, которая хоть и весьма неплохо играет, но шансов имеет совсем чуть-чуть. Да и искусственное затягивание игры тоже на руку не играет… ну не будете же вы спорить что в первой игре только виха иногда включался на полную чтобы совсем в поддавки не играть? Или вторая игра когда игроки отдались на хг, они в этот момент превратились из бывших суперпро, некоторые из которых брали 1 место на интернешенале в бригаду 3к ммр паберов, которые вместо сноса сторон дерутся посреди базы оппонентов. Это слишком хорошо видно и играет не на руку опенаи =((
Резюмируя — я бы дал в закрытом режиме участникам турнира поиграть с ботами и взял бы еще год на подготовку, для демонстрации текущего уровня хватило бы того матча с аматорами не умеющими через шифт блинк/эхослем делать. Затем на крупных турнирах (мажорах) делал бы шоу матчи с определенными ограничениями и постепенно расширяемым пулом героев и уже на ТИ19 влепил бы готовую команду без ограничений, которая разметала бы весь пул проигроков.
А сейчас они тупо убили весь хайп =( надеюсь не бросят затею и через год выкатят чудо.Druu
24.08.2018 10:13Да кто спорит, я к тому что в данный момент нужен вау эффект, а он достигается прежде всего именно эффектностью.
Нужен кому и зачем?
А сейчас они тупо убили весь хайп =( надеюсь не бросят затею и через год выкатят чудо.
Если они попытаются через год "выкатить чудо" — это провал проекта. Сейчас им надо уменьшить пул героев, убрать из игры консумаблы, варды, ограничить итемы и обучать сеть в таком стиле.
ну не будете же вы спорить что в первой игре только виха иногда включался на полную чтобы совсем в поддавки не играть?
Ну там просто кроме вихи игроки такие себе :)
Desavian
24.08.2018 11:02Вау эффект нужен чтобы поддерживать интерес к тематике 3И (норм, надо застолбить название для игрового искусственного интеллекта =)) Вы же не будете спорить что все AI проекты, включая AlphaGO вылезают на публику и хайпятся не просто так? Ну сидели бы у себя в лабораториях, звали бы периодически мастеров ГО и тренировались… так нет… Значит есть цель… не знаю, допустим популяризации или привлечения инвесторов или еще чего… а для этого сейчас нужен хайп, кто бы не говорил обратное =)
По поводу дальнейшего развития опенаи… им надо как-то развивать макро… как это сделать если игры бот-бот длятся в среднем 24 минуты — представляю с трудом, возможно просто наигрывая миллиарды игр боты, хм, «поймут» как играть не только в микро, но и в макро, но я не вижу насколько надо усложнить систему ревардов, чтобы подобное стало возможным.Druu
24.08.2018 12:08По поводу дальнейшего развития опенаи… им надо как-то развивать макро… как это сделать если игры бот-бот длятся в среднем 24 минуты
Проблема-то не в этом. У них за 42 секунды происходит уполовинивание реварда. Иными словами — если действие не окупилось в ближайшие минуты, то бот его считает бесполезным.
vaslobas
24.08.2018 13:31Я не смотрел игру, но если человек не через шифт делает блинк и ульту, то на это тоже не интересно смотреть. Это даже не уровень паб игр, а уровень каких-то совсем новичков.
Pusk1
24.08.2018 12:16Во второй игре всё стало понятно уже на 10-й минуте. China Stars отлично подготовились к этой игре. Боты собрались в одну неэффективную кучу на миде, проиграв опыт на других линиях. Третью игру даже смотреть не буду. Надеюсь, что проект не забросят и придумают новые технологии обучения. Или просто подкрутят ботов, чтобы не лезли на рожон слишком рано.
tSmoker
Не хватает голосовалки с прогнозом. Ставлю на OpenAl.
Crossover Автор
Хорошее замечание, прикрутили голосование.
BingoBongo
PsyHaSTe
В этот раз если поставят сыгранную команду, хотя бы одну из тех, что еще не покинули турнир, то боты по проиграют, как мне кажется. Если опять наберут игроков, которые пусть и входят в топ мира, но не играли на про сцене давно, то бот наверняка их размажет, как это было месяц назад.
Druu
Угу, ребята, небось, уже бодро пропивают с горя кровно заработанные призовые и тут бац, играйте с ботами -.-
n1ger
Взяли команду которая уже проиграла на турнире. И все равно бот проиграл.
PsyHaSTe
В общем, как я и предполагал. Сыгранная команда, которая не делала глупостей и не отдавалась по одному смогла пережить первые полчаса игры, после которой обучение ботов остановилось и они уже не знали, что делать. Ребятам понадобилось 2-3 залета чтобы понять, что бота на реакции поймать нельзя, и если время каста агра 0.25 секунды, то всегда человек успеет прожать еул или дагер. Поэтому в конце можно видеть как залет происходит исключительно после инстахексов лиона или когда спасительные артефакты в кд.
BingoBongo
С учетом того, что люди взяли в команду снайпера — их стратегия была понятна еще до начала тайма. Вспомним 4х часовую игру, где команда несколько часов держалась без 2х линий www.youtube.com/watch?v=JonbjtOExLg.
bro-dev0
Интересно еще почему не абузили остановку анимации на аксе это популярный трюк в пабе, а на про сцене тем более должны были знать, делаешь вид что кастуешь а в последний момент стоп, если бот так триггерил на начало анимации, на этом можно было вообще все замесы выигрывать.