
Самый удивительный аспект состоит в том, что ядро Windows практически не меняется в зависимости от всех этих архитектур и SKU. Ядро динамически масштабируется в зависимости от архитектуры и процессора, на котором оно работает, так, чтобы пользоваться всеми возможностями оборудования. Конечно, в ядре присутствует определённое количество кода, связанного с конкретной архитектурой, однако его там минимальное количество, что позволяет Windows запускаться на разнообразных архитектурах.
В этой статье я расскажу об эволюции ключевых частей ядра Windows, которые позволяют ему прозрачно масштабироваться от чипа NVidia Tegra низкого потребления, работающего на Surface RT 2012 года, до гигантских монстров, работающих в дата-центрах Azure.
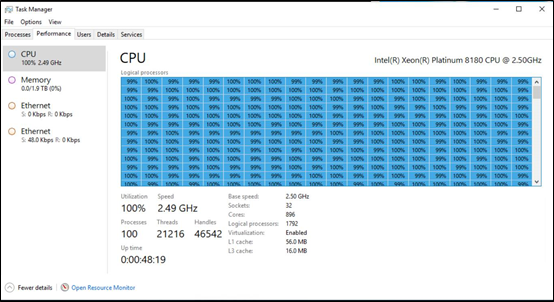
Менеджер задач Windows, работающий на пререлизной машине класса Windows DataCenter, с 896 ядрами, поддерживающими 1792 логических процессора и 2 Тб памяти
Эволюция единого ядра
Перед тем, как обсудить детали ядра Windows, сделаем небольшое отступление в сторону рефакторинга. Рефакторинг играет ключевую роль в увеличении случаев повторного использования компонентов ОС на различных SKU и платформах (к примеру, клиент, сервер и телефон). Базовая идея рефакторинга – позволить повторно использовать одни и тем же DLL на разных SKU, поддерживая небольшие модификации, сделанные специально под нужный SKU, не переименовывая DLL и не ломая работу приложений.
Базовая технология рефакторинга Windows – мало документированная технология под названием "наборы API". Наборы API – это механизм, позволяющий ОС разъединять DLL и место их применения. К примеру, набор API позволяет приложениям для win32 продолжать пользоваться kernel32.dll, притом, что реализация всех API прописана в другой DLL. Эти DLL с реализацией также могут отличаться у разных SKU. Посмотреть наборы API в деле можно, запустив обход зависимостей на традиционной Windows DLL, например, kernel32.dll.
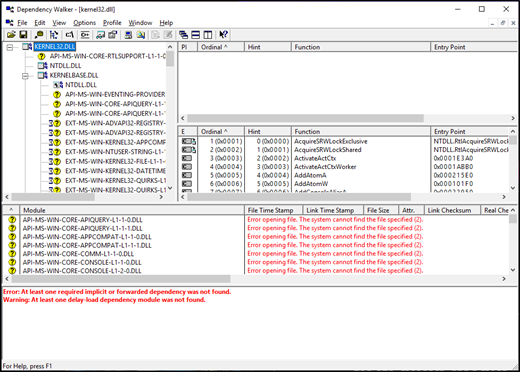
Закончив это отступление по поводу строения Windows, позволяющего системе максимизировать повторное и совместное использование кода, перейдём к техническим глубинам запуска ядра по планировщику, являющегося ключом к масштабированию ОС.
Компоненты ядра
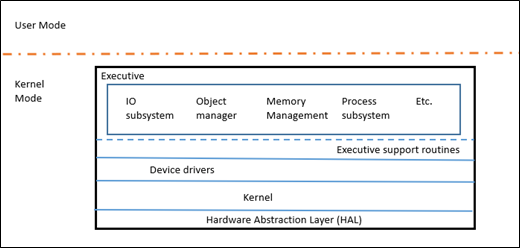
Windows NT – это, по сути, микроядро, в том смысле, что у него есть своё core Kernel (KE) с ограниченным набором функций, использующее исполняемый уровень (Executive layer, Ex) для выполнения всех политик высокого уровня. EX всё ещё является режимом ядра, так что это не совсем микроядро. Ядро отвечает за диспетчеризацию потоков, синхронизацию между процессорами, обработку исключений аппаратного уровня и реализацию низкоуровневых функций, зависящих от железа. Слой EX содержит различные подсистемы, обеспечивающие набор функциональности, который обычно считается ядром – IO, Object Manager, Memory Manager, Process Subsystem, и т.д.
Чтобы лучше представить себе размер компонентов, вот примерное разбиение по количеству строк кода в нескольких ключевых каталогах дерева исходников ядра (включая комментарии). В таблицу не вошло ещё много всего, относящегося к ядру.
| Подсистемы ядра | Строк кода |
|---|---|
| Memory Manager | 501, 000 |
| Registry | 211,000 |
| Power | 238,000 |
| Executive | 157,000 |
| Security | 135,000 |
| Kernel | 339,000 |
| Process sub-system | 116,000 |
Более подробная информация об архитектуре Windows содержится в серии книг “Windows Internals”.
Планировщик
Подготовив таким образом почву, давайте немного поговорим о планировщике, его эволюции и том, как ядро Windows умеет масштабироваться на такое количество различных архитектур с таким большим количеством процессоров.
Поток – это базовая единица, исполняющая программный код, и именно её работу планирует планировщик Windows. Решая, какой из потоков запустить, планировщик использует их приоритеты, и в теории, поток с наивысшим приоритетом должен запускаться на системе, даже если это означает, что потокам с более низким приоритетам времени не останется.
Проработав квантовое время (минимальное количество времени, которое может работать поток), поток испытывает уменьшение динамического приоритета, чтобы потоки с высоким приоритетом не могли работать вечно, душа всех остальных. Когда для работы пробуждается другой поток, ему повышают приоритет, рассчитанный на основе важности события, из-за которого произошло ожидание ( например, приоритет сильно повышается для находящегося на переднем плане интерфейса пользователя, и несильно – для завершения операций ввода/вывода). Поэтому поток работает с высоким приоритетом, пока он остаётся интерактивным. Когда он становится связанным преимущественно с вычислениями (CPU-bound), его приоритет падает, и к нему возвращаются уже после того, как другие потоки с высоким приоритетом получат своё процессорное время. Кроме того, ядро произвольным образом увеличивает приоритет готовых потоков, не получивших процессорного времени за определённый промежуток, чтобы предотвратить их вычислительное голодание и подправить инверсию приоритетов.
У планировщика Windows изначально была одна очередь готовности, из которой он выбирал следующий, наивысший по приоритету поток для запуска. Однако с началом поддержки всё большего количества процессоров, единственная очередь превратилась в узкое место, и примерно в районе выхода Windows Server 2003 планировщик поменял работу и организовал по одной очереди готовности на процессор. При переходе на поддержку нескольких запросов на один процессор единую глобальную блокировку, защищающую все очереди, делать не стали, и разрешили планировщику принимать решения на основе локальных оптимумов. Это означает, что в любой момент в системе работает один поток с наивысшим приоритетом, но не обязательно означает, что N самых приоритетных потоков в списке (где N – число процессоров) работают в системе. Такой подход оправдывал себя, пока Windows не начала переходить на CPU с низким энергопотреблением, например, на ноутбуки и планшеты. Когда на таких системах поток с наивысшим приоритетам не работал (например, поток переднего плана интерфейса пользователя), это приводило к заметным глюкам интерфейса. Поэтому в Windows 8.1 планировщик перевели на гибридную модель, с очередями для каждого процессора для потоков, связанных с этим процессором, и разделяемой очередью готовых процессов для всех процессоров. Это не сказалось на быстродействии заметным образом благодаря другим изменениям в архитектуре планировщика, например, рефакторингу блокировки базы данных диспетчера.
В Windows 7 ввели такую вещь, как динамический планировщик со справедливыми долями (Dynamic Fair Share Scheduler, DFSS); это в первую очередь касалось терминальных серверов. Эта особенность пыталась решить проблему, связанную с тем, что одна терминальная сессия с высокой загрузкой CPU могла повлиять на потоки в других терминальных сессиях. Поскольку планировщик не учитывал сессии и просто использовал приоритет для распределения потоков, пользователи в разных сессиях могли повлиять на работу пользователей в других сессиях, задушивая их потоки. Также это давало несправедливое преимущество сессиям (и пользователям) с большим количеством потоков, поскольку у сессии с большим количеством потоков было больше возможностей получить процессорное время. Была сделана попытка добавить в планировщик правило, по которому каждую сессию рассматривали на равных с другими по количеству процессорного времени. Подобная функциональность есть и в ОС Linux с их абсолютно честным планировщиком (Completely Fair Scheduler). В Windows 8 эту концепцию обобщили в виде группы планировщика и добавили в планировщик, в результате чего каждая сессия попадала в независимую группу. Кроме приоритетов для потоков, планировщик использует группы планировщика как индекс второго уровня, принимая решение по поводу того, какой поток запускать следующим. В терминальном сервере все группы планировщика имеют одинаковый вес, поэтому все сессии получают одинаковое количество процессорного времени вне зависимости от количества или приоритетов потоков внутри групп планировщика. Кроме того, такие группы также используют для более точного контроля над процессами. В Windows 8 рабочие объекты (Job) были дополнены так, чтобы поддерживать управление процессорным временем. При помощи специального API можно решать, какую часть процессорного времени может использовать процесс, должно это быть мягкое или жёсткое ограничение, и получать уведомления, когда процесс достигает этих ограничений. Это похоже на управление ресурсами в cgroups на Linux.
Начиная с Windows 7, в Windows Server появилась поддержка более 64 логических процессоров на одном компьютере. Чтобы добавить поддержку такому большому количеству процессоров, в системе ввели новую категорию, «процессорная группа». Группа – неизменный набор логических процессоров количеством не более 64 штук, которые рассматриваются планировщиком как вычислительная единица. Ядро при загрузке определяет, какой процессор к какой группе отнести, и у машин с количеством процессорных ядер менее 64 этот подход практически невозможно заметить. Один процесс может разделяться на несколько групп (например, экземпляр SQL-сервера), единственный поток в один момент времени может выполняться только в рамках одной группы.
Но на машинах, где число ядер CPU превышает 64, Windows начала демонстрировать новые узкие места, не дававшие таким требовательным приложениям, как SQL-сервер, масштабироваться линейно с ростом количества ядер процессора. Поэтому, даже при добавлении новых ядер и памяти, замеры скорости не показывали её существенного увеличения. Одной из главных проблем, связанных с этим, был спор по поводу блокировки базы диспетчера. Блокировка базы диспетчера защищала доступ к объектам, работу которых необходимо было запланировать. Среди этих объектов – потоки, таймеры, порты ввода/вывода, другие объекты ядра, подверженные ожиданию (события, семафоры, мьютексы). Под давлением необходимости разрешения таких проблем, в Windows 7 была проделана работа по устранению блокировки базы диспетчера и замене её на более точные подстройки, например, пообъектную блокировку. Это позволило таким замерам производительности, как SQL TPC-C, продемонстрировать рост скорости на 290% по сравнению с предыдущей схемой на некоторых конфигурациях. Это был один из крупнейших взлётов производительности в истории Windows, случившихся благодаря изменению единственной особенности.
Windows 10 принесло другую инновацию, внедрив наборы процессоров (CPU Sets). CPU Sets позволяют процессу разделять систему так, что процесс может распределиться на несколько групп процессоров, не позволяя другим процессам пользоваться ими. Ядро Windows даже не даёт прерываниям устройств пользоваться процессорами, входящими в ваш набор. Это гарантирует, что даже устройства не смогут исполнять свой код на процессорах, выданных группе вашего приложения. Это похоже на низкотехнологичную виртуальную машину. Понятно, что это мощная возможность, поэтому в неё встроено множество мер безопасности, чтобы разработчик приложения не допустил больших ошибок, работая с API. Функциональность наборов CPU используется в игровом режиме (Game Mode).
Наконец, мы приходим к поддержке ARM64, появившейся у Windows 10. Архитектура ARM поддерживает архитектуру big.LITTLE, гетерогенную по своей природе – «большое» ядро работает быстро и потребляет много энергии, а «малое» ядро работает медленно и потребляет меньше. Идея в том, что малозначительные задачи можно выполнять на малом ядре, экономя таким образом батарею. Для поддержки архитектуры big.LITTLE и увеличения времени работы от батареи при работе Windows 10 на ARM, в планировщик добавили поддержку гетерогенной планировки, учитывающую пожелания приложения, работающего с архитектурой big.LITTLE.
Под пожеланиями я имею в виду то, что Windows старается качественно обслуживать приложения, отслеживая потоки, выполняющиеся на переднем плане (или те, которым не хватает процессорного времени), и гарантируя их выполнение на «большом» ядре. Все фоновые задачи, сервисы, другие вспомогательные потоки выполняются на малых ядрах. Также в программе можно принудительно отметить маловажность потока, чтобы заставить его работать на малом ядре.
Работа от чужого имени [Work on Behalf]: в Windows довольно много работы на переднем плане осуществляется другими сервисами, работающими в фоне. К примеру, при поиске в Outlook сам поиск проводится фоновым сервисом Indexer. Если мы просто запустим все сервисы на малом ядре, пострадает качество и скорость работы приложений на переднем плане. Чтобы при таких сценариях работы она не замедлялась на архитектурах big.LITTLE, Windows отслеживает вызовы приложения, поступающие к другим процессам, чтобы выполнять работу от их имени. В таком случае мы выдаём приоритет переднего плана потоку, относящемуся к сервису, и заставляем его выполняться на большом ядре.
На этом позвольте закончить первую статью о ядре Windows, дающую обзор работы планировщика. Статьи со сходными техническими подробностями о внутренней работе ОС последуют позже.
Комментарии (34)

Crandel
01.11.2018 16:23-12Менеджер задач Windows, работающий на пререлизной машине класса Windows DataCenter, с 896 ядрами, поддерживающими 1792 логических процессора и 2 Тб памяти
Это типа причина для гордости?
Manufacturer: IBM
Cores: 2,282,544
Memory: 2,801,664 GB
Processor: IBM POWER9 22C 3.07GHz
Operating System: RHEL 7.4
Manufacturer: IBM
Cores: 1,572,480
Memory: 1,382,400 GB
Processor: IBM POWER9 22C 3.1GHz
Operating System: Red Hat Enterprise LinuxAlozar
01.11.2018 16:45Не принижая Linux и не восхваляя Windows, хочется уточнить.
Какой дистрибутив linux там используется? Эти суперкомпьютеры физически являются одним компьютером или кластером, где количество ядер в каждом отдельном компьютере «разумное»?FRAGIL3
01.11.2018 17:10+3Так дистрибутив же написан: в обоих примерах RHEL
По первому суперкомпьютеру инфа с вики следующая:
«4608 серверов IBM Power Systems AC922 <...>. В состав этих серверов входит 9216 22-ядерных процессоров IBM POWER9 и 27 648 графических процессоров NVIDIA Tesla V100[9].
<...>
Каждый узел содержит более 500 Гб когерентной памяти (High Bandwidth Memory и DDR4 SDRAM), которая адресуется всеми CPU и GPU, плюс 800 Гб энергонезависимой памяти, которая может использоваться как пакетный буфер или расширенная память. Процессоры и видеокарты подключаются с использованием шины NVLink. Это позволяет использовать гетерогенную вычислительную модель.»
А вот можно ли отнести это к компьютеру или к кластеру, не знаюunclejocker
02.11.2018 11:10+3Это всетаки много отдельных серверов, соедененных в целое быстрой шиной. Подозреваю, что использовать это целое как целое может только специально написанный софт. А приведенная на скриншоте система — хотя, конечно, физически это набор блэйдов на интерконнекте, но логически и с точки зрения ОС — это один сервер «кусочком» и использовать все ядра и память может любое win приложение. Подозреваю что и linux на него тоже можно поставить без заметных проблем, если конечно linux поддерживает 1700+ процессоров.
Crandel
01.11.2018 17:16+2Какой дистрибутив linux там используется? Эти суперкомпьютеры физически являются одним компьютером или кластером, где количество ядер в каждом отдельном компьютере «разумное»?
В цитате же все сказано. Дистрибутив Red Hat Enterprise Linux. Более подробную информацию можно найти здесь. Точно также, как и в азуре линукс управляет кластером из множества стоек. Или вы думали, что в азуре один системник с процессором на 896 ядер?
Вот так, приблизительно, должен выглядеть снимок htop
Gordon01
01.11.2018 23:17Раньше на эту тему еще была шутка: да, Linux поддерживает 4096 процессоров, но можно ли проигрывать YouTube в полноэкранном режиме?
В итоге стало можно, если перекомпилять ядро и добавить туда патчи от анестезиолога, то наконец-то можно будет смотреть YouTubetimdorohin
02.11.2018 03:31chromium-vaapi, стоковый CFS в ядре и Celeron с частотой 1.1ГГц (новый нетбук) — 1080p60 без лагов и тормозов.
Вините криворуких разрабов, которые постоянно ломают аппаратное ускорения в браузерах…Gordon01
02.11.2018 08:53+3Это шутка минимум десятилетней давности, еще когда видео на ютубе проигрывалось через флеш, а BFS только появился
xkcd.com/619timdorohin
02.11.2018 16:04Вот только в каждой шутке есть доля шутки, и эта — не исключение. Запустите 1080p60 (Именно 60! c 30 к/с проблемы как-бы нет) и пожалуйста, i7 2630qm уже изображает умирающего. Немного помогает переброс хрома на дискретку. Еще немного — отключение композитора.
А как подключаешь vaapi — волосы становятся гладкими и шелковистыми даже на задавленном целероне…Gordon01
02.11.2018 17:21Я на днях удалил Linux и проверить уже, увы, не смогу (
Но в последнее время проблем не было, хотя не знаю, процом видео декодилось или дискреткой. У меня настольный комп всегда был с дискретной нвидией и проприетарным драйвером
ISergius
03.11.2018 10:06i3 7100, встроенное видео, Kubuntu 18, Firefox 63, монитор 4k. Видео 1080р60 в utube проигрывается плавно, нагрузка на процессор ~40%. 1440p60 на том же видео — тоже все плавно, загрузка процессора выше, порядка ~80%. А вот 2160p60 уже не тащит.
speshuric
02.11.2018 23:07+1Считать суперкомпьютер за один компьютер на уровне ОС не вполне честно. Там и RHEL заметно допилен и память неоднородна от слова "совсем", и FS совсем свои. А 32-сокетный монстр — это еще "почти честный" моносервер (Intel: Configure native 4- and 8-socket CPU configurations and extend to up to 32-socket systems via third-party OEM node controllers).
Crandel
02.11.2018 23:23-1Считать суперкомпьютер за один компьютер на уровне ОС не вполне честно. Там и RHEL заметно допилен и память неоднородна от слова "совсем", и FS совсем свои. А 32-сокетный монстр — это еще "почти честный" моносервер (Intel: Configure native 4- and 8-socket CPU configurations and extend to up to 32-socket systems via third-party OEM node controllers).
Считать можно все, что угодно. В азуре тоже не один камень на 900 ядер, а стоят кластеры, объединенные в гетерогенное вычислительное устройство
deathadmin
01.11.2018 20:18+1Конечно, в ядре присутствует определённое количество кода, связанного с конкретной архитектурой, однако его там минимальное количество, что позволяет Windows запускаться на разнообразных архитектурах.
Но исходников нам не покажут…deathadmin
01.11.2018 21:16-3Потому что в оригинальной статье нет ничего про «минимальное количество кода».
The most amazing aspect of all this is that the core of Windows, its kernel, remains virtually unchanged on all these architectures and SKUs. The Windows kernel scales dynamically depending on the architecture and the processor that it’s run on to exploit the full power of the hardware. There is of course some architecture specific code in the Windows kernel, however this is kept to a minimum to allow Windows to run on a variety of architectures.
ad1Dima
02.11.2018 09:38+4Но исходников нам не покажут…
Windows Research Kernel — исходники ядра XP (но там не всё) доступно примерно с 2007 года для образовательных учреждений.
voidptr0
01.11.2018 20:40-1После прочтение возникли сумбурные мысли.
1. Ядру Linux всегда ставили в недостаток майнфреймовое происхождение. А судя из статьи, планировщик Windows начал на каком-то этапе ориентироваться (где-то явно или не явно) на реализации планировщиков в Linux.
2. Учитывая наращивание количества ядер в новых процессорах даже для десктопов, мне вопрос балансировки и распределения нагрузки на ядра не кажется таким уж далеким от обычного пользователя.r0mik
01.11.2018 21:20простите, кто ставил?
линукс — абсолютный лидер во всех топ-ах (TOP100,TOP500). и как-то я такую картину наблюдаю все время, сколько смотрю на нее (лет 15 точно).
хотя и виндовс там был на задворках. интенсивно продвигаемый майкрософтом. впрочем, позже они о нем забыли и сейчас там его нет совсем...
ой, пардон. чушь написал. не правильно понял…
maisvendoo
01.11.2018 22:30+5Ядру Linux всегда ставили в недостаток майнфреймовое происхождение.
Что? История происхождения ядра Linux, изложенная самим создателем в книге «Just for fun» говорит о том, что происхождение этого ядра ну очень «писишное» — писалось под 386 процессор, причем сам Линус говорил о том, что сомневается, что оно будет работать где-то ещё. Время решило иначе, но факт остается фактомvoidptr0
03.11.2018 20:53Ну, давайте поспорим сами с собой. Или с тем, что мы говорили ранее. Сейчас очень интересно забывать историю, или хотя бы говорить, что это было не так. Как минимум стоит вспомнить: «habr.com/post/62811»
robotobor
02.11.2018 18:421. Это скорее всего не проблема, так как под сервер и под десктоп, я думаю, планировщик можно сконфигурировать перед компиляцией ядра. А вот Winda корнем целилась в десктоп, поэтому и терминальные сессии особо не учитывали при архитектуре планировщика, потом одумались.
voidptr0
03.11.2018 20:58>терминальные сессии особо не учитывали при архитектуре планировщика, потом одумались.
Блин, а о чем. Они когда поняли, что Винда это не только «пыщь-пышь», а люди начали его пихать в серьезные приложения, и эти люди с большими деньгами стали задавать неудобные вопросы.
kovserg
01.11.2018 23:19+7На сегодня она поддерживает архитектуры x86, x64,
На сегодня уже часть x86 архитектур не поддерживаются.
Наборы API – это механизм, позволяющий ОС разъединять DLL и место их применения. К примеру, набор API позволяет приложениям для win32 продолжать пользоваться kernel32.dll, притом, что реализация всех API прописана в другой DLL
Это не механизм разъединения, это лютый геморой который они будут еще долго разгребать. Все эти ms-core-… просто указатели на другие библиотеки им даже запрещено запускаться. Нафига надо было так делать манифестом и базой данных это было не решить. Понадобилось родить эту жуть. А потом в составе больших продуктов необходимо поставить vcredist всех версий иначе не работает. При этом для удобста на сайте микрософта эти библиотеки имеют одинаковые имена vcredist.
Например FreeLibrary находиться в kernel32.dll он будет ссылаться на api-ms-win-core-libraryloader-l1-1-1.dll или api-ms-win-core-libraryloader-l1-2-0.dll или еще куда. Но в итоге всё равно попадёт в kernel32 так загрузчику глубоко фиолетово. Но без файла api-ms-win-core-libraryloader-*.dll не запуститься. Что мешало просто запись в реестре сделать, зачем еще эту гору файлов таскать? Что быстрее загрузить 1 файл и сотню отдельных? Да и в старых виндах гарантировано не запустится. Так что все эти api-set больше похожы один из механизмов запланированного устаревания софта.AnarchyMob
02.11.2018 18:43+2Помнится мне в Windows CE функции из kernel.dll и user32.dll были в одной core.dll и приходилось мучиться с .NET интеропом. Унификация api это всегда хорошо, api sets это подобие .NET Standard...
pfihr
02.11.2018 10:41-5Не вопрос, исходники публикуете в опенсорс, мы читаем и восхищаемся, вносим свои баги, а Билл нас за это поносит. А без статья просто демонстрация неприкрытого хвастовства, рассчитанная точно не на специалистов, а скорее на продавцов и любителей потратить чужие деньги.
VlK
02.11.2018 11:41+5Признаться, статья в контексте других действительно легкопортируемых операционных систем звучит скучно.
> ls ~/var/linux/arch/
alpha/ arm/ blackfin/ cris/ h8300/ ia64/ m32r/ metag/ mips/ nios2/ parisc/ riscv/ score/ sparc/ um/ x86/
arc/ arm64/ c6x/
Да и код закрыт, что миру с того, что кто-то где-то чем-то хвастается?
RollNoir
02.11.2018 15:32-2Очень интересная и познавательная статья. Но как это часто бывает с майками, они теоритическую масштабируемость плохо накладывают на практическую из-за больших разбежек по возможным сценариям работы, поэтому усредняют до одной математической модели сценарии работы на 2х ядрах с HT и на 8ми ядрах с HT. Не сочтите за хвастовство, просто хотел бы поделиться, что это не пустые слова — мы учли такие моменты при разработке своего софта ещё в 2014ом году и поэтому в отличии от игрового режима Microsoft, наш игровой режим не уменьшает производительность у пользователей независимо от конфига. Кому интересно, может ознакомится подробнее здесь

vilgeforce
«Исполняемый» и «исполнительный» — разные вещи