

Изображение: Martinoflynn.com
Чаще всего правила корреляции строятся на основе нормализованных событий. Таким образом, нормализация событий и то, насколько корректно она выполнена, напрямую влияет на точность правил корреляции.
Проблемы, возникающие при нормализации событий, мы сформулировали в первой статье (тут), а пути их решения предложили в последующих статьях (тут и тут). Теперь обобщим ранее описанное и сформируем общий подход к нормализации событий.
Для начала напомним, какие инструменты уровня нормализации мы выработали:
- Универсальная схема полей, необходимая для хранения данных, извлекаемых из событий. Ее особенности:
- Она учитывает наличие в событии сущностей: Субъект, Объект, Источник и Передатчик событий, а также Ресурс.
- Обеспечивает корректную нормализация в случаях, когда в событии присутствуют сущности уровней сети и приложений, и когда в нем есть более одного Субъекта и/или Объекта.
- Позволяет явно выявить и сохранить структуру самого процесса взаимодействия Субъекта и Объекта
- Система категоризации событий, способная отразить семантику IТ- или ИБ-события.
Методология нормализации событий
Вся методология нормализации событий состоит из трех шагов:
- Экспертная оценка события.
- Определение схемы взаимодействия.
- Определение категории события.
Чтобы было проще понять, как работает инструмент, выберем событие и подробно рассмотрим все шаги нормализации согласно нашей методологии.
Пусть у нас есть источник — СУБД Oracle Database со следующей сетевой адресацией:
- IP: 10.0.0.1;
- Hostname: myoracle;
- FQDN: myoracle.local.
С данного источника агент SIEM выгружает следующее событие:

Шаг 1. Экспертная оценка события
В самом начале процесса нормализации события важно понять, о чем это событие. Достаточно проговорить его суть про себя. Если эксперт, из исходного, еще не нормализованного, события не понимает, о каких процессах, протекающих на источнике, идет речь, — с большой вероятностью он некорректно его нормализует. Тогда о какой корректной работе правил корреляции может идти речь?
Проблема с тем, насколько эксперт корректно интерпретирует событие, вполне реальна. К примеру, можно ли не эксперту понять, что означает следующее событие?
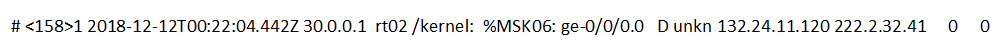
Если в исходном примере суть можно уловить из текста самого события, то в данном случае нужно хорошо понимать, с каким источником вы работаете и в каких случаях он генерирует подобное событие. Иногда даже приходится разворачивать отдельный стенд с источником, чтобы в полном объеме воспроизвести ситуацию, в которой он отправляет в SIEM сложное и тяжело интерпретируемое событие.
Вернемся к исходному примеру с событием от СУБД Oracle Database. На этом этапе эксперт должен размышлять так:
«Я как эксперт считаю, что исходное событие описывает процесс отзыва роли одним пользователем у другого в СУБД Oracle Database».
Шаг 2. Определение схемы взаимодействия
Предыдущий шаг позволяет убедиться, что мы можем понять хотя бы общий смысл события. Теперь детально разберем, как выделить сущности и определить схему их взаимодействия.
По этой методологии для каждой схемы взаимодействия нужно описать правила распределения ключевых идентификаторов сущностей по полям нормализованного события. При этом, определены правила для:
- Сущностей сетевого уровня;
- Сущностей прикладного уровня.
Важно помнить, что есть схемы, в которых Субъект равен Объекту и равен Источнику. Для таких схем необходимо явно определить правила заполнения полей всех трех сущностей. Если этого не сделать, то, на уровне правил корреляции или поиске событий начнутся проблемы и появится дополнительная логика для корректной интерпретации пустых полей. Об этом – в статье, посвященной схемам взаимодействий.
Посмотрим работу этого шага методологии на исходном примере:
- Схема взаимодействия на сетевом уровне: полная схема прямого сбора, без передатчика.
- Схема взаимодействия на прикладном уровне: взаимодействие через ресурс.
Для данных схем могут быть определены следующие правила нормализации:
- Сущности сетевого уровня:
- Субъект:
- Поле: src.ip = <пусто>
- Поле: src.hostname = alex_host
- Поле: src.fqdn = <пусто>
- Объект:
- Поле: dst.ip = 10.0.0.1
- Поле: dst.hostname = myoracle
- Поле: dst.fqdn = myoracle.local
- Источник (совпадает с Объектом):
- Поле: event_source.ip = 10.0.0.1
- Поле: event_source.hostname = myoracle
- Поле: event_source.fqdn = myoracle.local
- Передатчик:
- Поле: forwarder.ip = <пусто>
- Поле: forwarder.hostname = <пусто>
- Поле: forwarder.fqdn = <пусто>
- Канал взаимодействия:
- Поле: interaction.id = 2342594
- Субъект:
- Сущности прикладного уровня (коллекция элементов):
- Субъект:
- Поле: subject[1].name = “Alex”
- Поле: subject[1].type = “account”
- Объект:
- Поле: object[1].name = “Bob”
- Поле: object[1].type = “account”
- Ресурс:
- Поле: resource[1].name = “MYROLE”
- Поле: resource[1].type = “role”
- Субъект:
Шаг 3. Определение категории события
После того, как были выявлены все ключевые сущности события, необходимо описать суть самого процесса, отраженного в событии, и переложить ее на язык нормализации. Для этих целей служит система категоризации событий. Система категоризации событий была подробно рассмотрена в отдельной статье, теперь посмотрим, как она работает на практике.
Для того чтобы унифицировать нормализацию, система категоризации определяет следующие правила:
- Для каждой категории каждого уровня IT- и ИБ-событий экспертом формируется справочник со списком той информации, которую необходимо найти в исходном событии и нормализовать.
- Если событию была назначенная какая-либо категория, эксперт, в соответствии со справочником, обязан найти требуемую информацию и нормализовать ее.
- Каждая категория определяет набор полей схемы нормализованного события, которые должны быть заполнены.
Таким образом, выбранная для события категория устанавливает прямое соответствие между:
- семантикой события;
- важной информацией, которую необходимо извлечь из события, согласно проставленной категории;
- набором полей схемы нормализованного события, в которые данную информацию необходимо «положить».
Этот подход позволяет из категории любого события четко понять, какие данные в каких полях нормализованного события находятся.
Если при поддержке новых источников выясняется, что из событий определенной категории необходимо дополнительно извлечь еще какую-то важную информацию, то она заносится в справочник. В этом случае нужно:
- определить правила заполнения полей схемы события;
- провести ревизию нормализации для событий данной категории всех ранее поддержанных источников;
- добавить новую информацию в ранее нормализованные события.
Таким образом поддерживается консистентность вносимых изменений. Рассмотрим на исходном примере.
Согласно системе категоризации, данное событие имеет следующие категории:
- Система категоризации: IT-событий
- Категория первого уровня (Level 1): User and Rights
- Категория второго уровня (Level 2): User
- Категория третьего уровня (Level 3): Manipulation
Справочник для этой категории выглядит так:
- При нормализации событий категории «User and Rights» важно понять:
- Если использовалось повышение привилегий, то от чьего имени реализуется процесс.
- Поле: subject[i].assign
- Были ли действия успешными.
- Поле: result.status
- Каков код возврата.
- Поле: result.status.code
- Если использовалось повышение привилегий, то от чьего имени реализуется процесс.
- При нормализации событий категории «User» важно понять:
- Есть ли информация о ip-адресе, имени хоста или fqdn машины пользователя.
- Поля: src.ip, src.hostname, src.fqdn
- Поля: dst.ip, dst.hostname, dst.fqdn
- Под какой учетной записью подключался пользователь.
- Поля: subject[i].name, object[i].name
- Есть ли информация о его учетной записи в ОС.
- Поля: subject[i].osname, object[i].osname
- Есть ли информация о доменной учетной записи.
- Поля: subject[i].domain, object[i].domain
- Есть ли информация о приложении пользователя.
- Поля: subject[i].application, object[i].application
- Есть ли информация о ip-адресе, имени хоста или fqdn машины пользователя.
- При нормализации событий категории «Manipulation» важно понять:
- Тип операции.
- Поле: interaction.type
- Что изменили.
- Поле: object[i].name, object[i].type — при изменении в учетных записях
- Поле: resource[i].name, resource[i].type — при изменении в ресурсах
- На что изменили.
- Поле: object[i].modify
- Поле: resource[i].modify
- Если операция была над ресурсом, кто его владелец.
- Поле: resource[i].owner
- Тип операции.
Этот справочник мы привели для демонстрации принципа его формирования, поэтому он не претендует на точность и полноту.
В итоге событие, нормализованное по данной методологии, выглядит так:

Пример нормализованного события на третьем шаге методологии.
Выводы
Опыт показывает, что зачастую к ложным срабатываниям правил корреляции приводят именно ошибки нормализации и отсутствие единых правил нормализации. Теперь у нас есть подход, который позволяет, если не избавиться, то хотя бы минимизировать влияние проблемы.
Итак, подытожим — подход включает в себя три шага:
- Шаг 1. Эксперт старается понять общую суть явления, описанного в исходном событии.
- Шаг 2. Эксперт выделяет основные сущности сетевого и прикладного уровня в событии: Субъект, Объект, Источник, Передатчик, Ресурс, Канал взаимодействия. Выделяет их в событии и определяет схему взаимодействия этих сущностей. Каждая схема формирует правила размещения данных сущностей по полям нормализованного события — схемы. Подробно об этом было написано в статье, посвященной схемам взаимодействия сущностей.
- Шаг 3. Эксперт определяет категорию первого, второго и третьего уровней. Для каждой категории создает справочник, включающий описание данных, которые важно найти в событии при его нормализации, информацию о том, в какие поля нормализованного события необходимо «положить» найденные данные.
Теперь от построения правил корреляции «работающих из коробки» нас отделяет лишь проблема постоянного изменения самих сущностей — активов. У них меняются адреса, вводятся новые активы, выводятся из эксплуатации старые, переключаются ноды кластера, а виртуальные машины переезжают из одного ЦОД в другой и, порой, даже со сменой адресации. Как победить эти проблемы, мы поговорим в следующей статье цикла.
Цикл статей:
Глубины SIEM: корреляции «из коробки». Часть 1: Чистый маркетинг или нерешаемая проблема?
Глубины SIEM: корреляции «из коробки». Часть 2. Схема данных как отражение модели «мира»
Глубины SIEM: корреляции «из коробки». Часть 3.1. Категоризация событий
Глубины SIEM: корреляции «из коробки». Часть 3.2. Методология нормализации событий (Данная статья)
Комментарии (12)

mzhevnerev
19.12.2018 20:36В том же примере с Ораклом получается, что поле src.ip пустое (хотя пора бы уже научится резолвить хосты). А в других событиях оно может быть заполненным.
Или же вообще отсутствовать информация о сорс хосте
А в некоторых случаях — собираться из нескольких РАЗНЫХ событийVirtual77
20.12.2018 12:56Вот на счет резолвить, тут слишком растяжимое понятие, некоторые SIEM (не буду показывать пальцем все и так знают на букву А) резолвингом убивают DNS сервера, и приходится забивать костыли в виде отдельных кеширующих DNS и затягиванием гаек на тайминги резолвинга при обновлении активов, так что лед очень тонкий.
Либо имеем актуальные активы и захлебывающийся DNS либо работающий DNS и слегка актуальные активы.nvnikolai Автор
20.12.2018 12:58На пути обогащения много таких проблем :) каждый вендор выкручивается как может… или не выкручивается :)
mzhevnerev
19.12.2018 20:37И для того, чтобы корреляция в итоге учитывала эти варианты, «эксперты» должны делать нормализацию и категоризацию исходя из того, какие поля будут (и должны в идеале быть заполнены) использоваться в корреляции. И при необходимости не вешать категории на исходные события, а заполнять их на уровне обогащения, корреляции и т.д.
В этом случае и с поиском будет намного проще :)nvnikolai Автор
19.12.2018 20:56В данном подходе категория отражает суть исходного события. Суть может быть определена на этапе нормализации (даже с пропущенными данными)
Категория определяет правила заполнения нужных полей. Но что делать с пропущенными данными (src.ip — действительно такой случай)? Восполнить такие пропуски можно обогащением (когда это возможно, но это далеко не всегда так). Т.о. зачем дотягивать категоризацию до обогащения?
mzhevnerev
19.12.2018 21:08Для того, чтобы во всех событиях одинаковой категории была вся необходимая информация (мой любимый пример с стартом\завершением vpn-сессий)
Когда мы ищем события определенной категории — хочется иметь всю информацию в событии, а не собирать ее каждый раз из разных
Когда мы делаем правило по категории событий — хочется быть уверенным, что в любом событии в этой категории будет вся необходимая информация. Как раз чтобы на этом уровне реализовывать логику детекта, а не очередной парсинг и исправление ведорских (тут я про тех, кто логи в продуктах создает) особенностейnvnikolai Автор
19.12.2018 21:15Как и писал выше в методологии, действительно есть дырка: она ничего не говорит о том как и где достать недостающие в событии данные.
mzhevnerev
19.12.2018 21:18А дьявол, как говорится, в деталях :)
И в данном случае они именно тут. Ибо если смотреть не на событие как оно есть, а на событие как оно могло бы быть — то можно и аудит где-то сделать другой. И категории вешать позже :)nvnikolai Автор
19.12.2018 21:28В этих словах есть правда… Следующая статья будет про использование данных об активах. Эта задача схожу с обогащением. Там постараюсь тему восполнения недостающих данных затронуть.
Спасибо за фидбек, момент с обогащением от меня ускользнул :(
mzhevnerev
На самом деле основная проблема в плохо работающей корреляции как раз в том, что вендоры пытаются нормализовывать и категоризировать события отдельно друг от друга.
Не учитывая информацию, которая могла бы быть необходима для соответствующих корреляционных правил.
nvnikolai Автор
Да, верно, в этом тоже есть большая проблема. К сожалению я ее не затронул в этой статье.
Видится, что для ее решения надо выработать какой-то отраслевой стандарт. Этот цикл статей — робкая попытка начать наводить порядок хотя бы в рамках одной компании/вендоре. Если выработанные практики можно будет масштабировать, будет успех. На отраслевой стандарт, я пока не замахиваюсь. Здесь ключевое слово "пока" :)