
Привет всем Хаброрезидентам!
Открываем блог компании РДТЕХ первым постом с лайф-хаками для разработчиков. Надеемся, что кто-нибудь из читателей ими воспользуется.
Лайф-хаки были придуманы в ходе работы над проектом по переливке данных из одной системы в другую для последующего построения отчётов в одном из ведущих банков РФ.
Используемые технологии:
Система источник данных – RDBMS Oracle (версия 11.2.0.4.0)
Система приёмник данных – RDBMS Oracle (версия 11.2.0.4.0)
Интеграционная шина – Informatica (версия 10.1.1)
В ходе реализации крупного интеграционного проекта мы столкнулись со следующими проблемами:
1. Неэффективное использование SQ [Source Qualifier] в Informatica Power Center
При использовании SQ [Source Qualifier] в Informatica Power Center выявилось ограничение на количество вводимых символов. Максимально допустимое количество символов — 32767. Пример нерационального использования Source Qualifier указан на рисунке ниже:
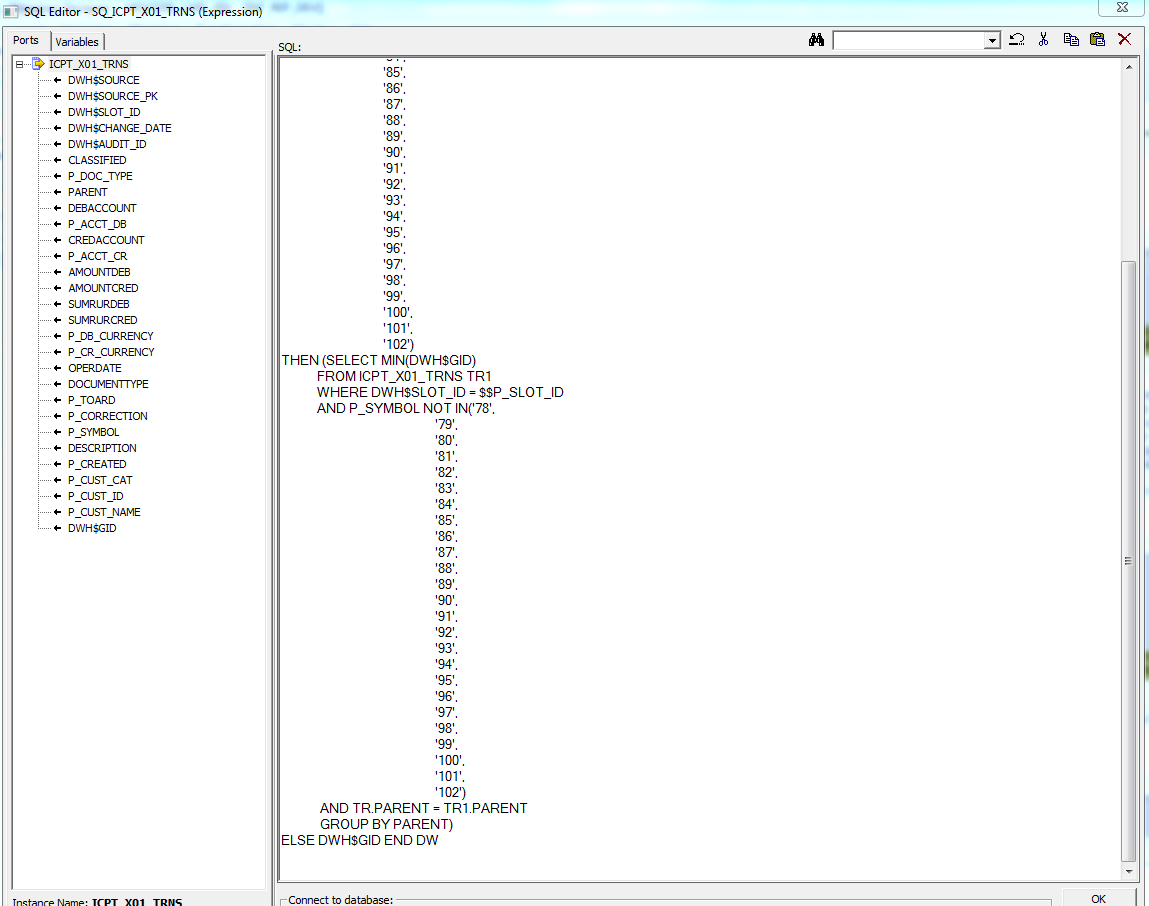
Рисунок 1 Скриншот из SQ Informatica Power Center
Данный скриншот показывает, что пробелы съедают символьное пространство, вследствие чего сложные SQL-запросы полностью не вписываются (т.е. они обрезаются при их вставке в Source Qualifier).
На рисунке ниже представлено корректное использование Source Qualifier (изменения выделены красным маркером):
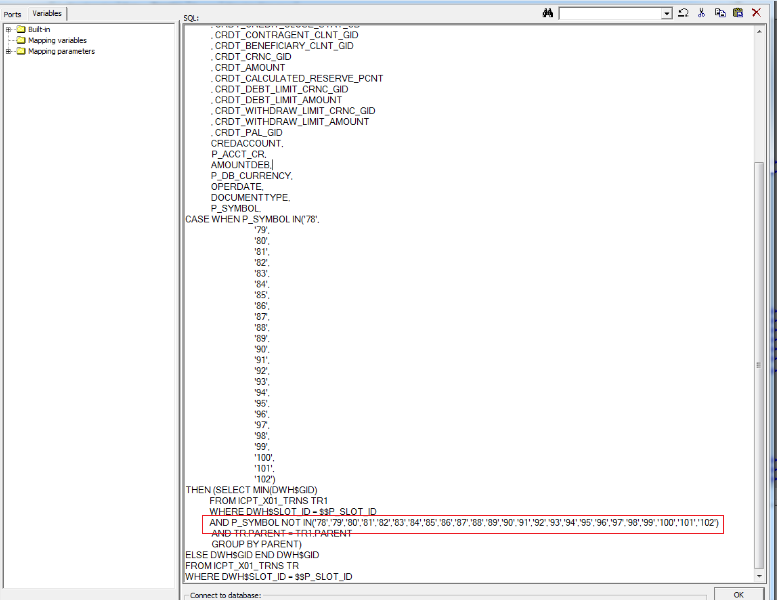
Рисунок 2 Скриншот из SQ Informatica Power Center с изменённым запросом
Переход на следующую строку и выравнивание стоило N-е количество символов, убрав которые, мы смогли уместить весь SQL-код.
2. Некорректное преобразование бесконечно больших чисел
Бесконечно большие числа прогружались в базу Oracle в следующем формате:
1267650600228230000000000000000
А должны были загружаться в формате:
1267650600228229401496703205376
Т.е. значения округлялись, начиная с определённого разряда числа.
Мы предлагаем следующее решение:
В ходе разработки маппингов в Informatica Power Center формат поля (например, string) сразу проставляется на определенном этапе для значений, которые точно будут приходить большими, при этом:
Если подводить итог об использовании инструмента, то можно выделить следующие плюсы:
И немного минусов для объективности картины:
Открываем блог компании РДТЕХ первым постом с лайф-хаками для разработчиков. Надеемся, что кто-нибудь из читателей ими воспользуется.
Лайф-хаки были придуманы в ходе работы над проектом по переливке данных из одной системы в другую для последующего построения отчётов в одном из ведущих банков РФ.
Используемые технологии:
Система источник данных – RDBMS Oracle (версия 11.2.0.4.0)
Система приёмник данных – RDBMS Oracle (версия 11.2.0.4.0)
Интеграционная шина – Informatica (версия 10.1.1)
В ходе реализации крупного интеграционного проекта мы столкнулись со следующими проблемами:
1. Неэффективное использование SQ [Source Qualifier] в Informatica Power Center
При использовании SQ [Source Qualifier] в Informatica Power Center выявилось ограничение на количество вводимых символов. Максимально допустимое количество символов — 32767. Пример нерационального использования Source Qualifier указан на рисунке ниже:
Рисунок 1 Скриншот из SQ Informatica Power Center
Данный скриншот показывает, что пробелы съедают символьное пространство, вследствие чего сложные SQL-запросы полностью не вписываются (т.е. они обрезаются при их вставке в Source Qualifier).
На рисунке ниже представлено корректное использование Source Qualifier (изменения выделены красным маркером):
Рисунок 2 Скриншот из SQ Informatica Power Center с изменённым запросом
Переход на следующую строку и выравнивание стоило N-е количество символов, убрав которые, мы смогли уместить весь SQL-код.
2. Некорректное преобразование бесконечно больших чисел
Бесконечно большие числа прогружались в базу Oracle в следующем формате:
1267650600228230000000000000000
А должны были загружаться в формате:
1267650600228229401496703205376
Т.е. значения округлялись, начиная с определённого разряда числа.
Мы предлагаем следующее решение:
В ходе разработки маппингов в Informatica Power Center формат поля (например, string) сразу проставляется на определенном этапе для значений, которые точно будут приходить большими, при этом:
- Если мы используем формат decimal и если значения у нас могут иметь до 28 символов, то нужно в свойствах workflow в Workflow Manager включить Properties > «Enable high precision» > «Yes».
- Если мы используем формат double, при этом в данный атрибут могут приходить значения, превышающие 15 символов (например, 20), то значение будет обрываться до 15 значащих цифр и проставлять ноль (0) в остальные (т.е. последние 5 символов будут нулевые). В таком случае лучше проставлять формат string и увеличить размер до нужного (например, string20).
Если подводить итог об использовании инструмента, то можно выделить следующие плюсы:
- инструмент удобен для переливки большого объёма данных, исчисляемого терабайтами (например, до 25-30 tb), особенно если требуется их переложить с минимальным количеством преобразований (практически один-в-один);
- возможность автоматической «протяжки» атрибутов (опция Propagate Attributes), а также «подсветки» внутри маппинга (откуда и куда тянутся данные);
- возможность выбора режима работы как ETL-инструмента, так и ELT-инструмента (зависит от конкретного IT-проекта).
И немного минусов для объективности картины:
- отсутствие «сложной» логики преобразования данных;
- с точки зрения support-а самого инструмента и понимания логики работы отдельных трансформаций он уступает некоторым конкурентам (например, Oracle Data Integrator).
Geckelberryfinn
Вообще, обычно хорошей практикой считается не использовать в коннекторах ETL джобов
сложных SQL запросов. Это уменьшает читаемость дизайна процесса и перекладывает решение вопросов производительности на плечи СУБД. Тогда бы и не возникало необходимости убирать whitespaces из запроса, так как вы бы использовали lookup-датасеты или таблицы вместо списка кодов в запросе. Что также было бы неплохим решением, так как, допущу, этот список может использоваться во многих процессах переливки.