
В качестве «подопытного кролика» я взял следующую задачу:
Есть неупорядоченный массив arr с числами типа uint16_t. Необходимо найти количество вхождений числа v в массив arr.Классическое решение, работающее за линейное время выглядит так:
int64_t cnt = 0;
for (int i = 0; i < ARR_SIZE; ++i)
if (arr[i] == v)
++cnt;
В таком виде бенчмарк показывает следующие результаты:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
Под катом я покажу как его ускорить в 5+ раз.
Тестовое окружение
Для тестов я использовал ноутбук с процессором
Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz. В качестве компилятора был clang version 6.0.0. Для измерения производительности я выбрал libbenchmark от Google. Размер массива я взял 1024 элемента, чтобы не считать классическим способом остаток элементов.Что такое SIMD
SIMD (Single Instruction, Multiple Data) — одиночный поток команд, множественный поток данных. В x86 совместимых процессорах эти команды были реализованы в нескольких поколениях SSE и AVX расширениях процессора. Команд довольно много, полный список от Intel можно посмотреть на странице software.intel.com/sites/landingpage/IntrinsicsGuide. В десктопных процессорах AVX расширения недоступны, поэтому сосредоточимся на SSE.
Для работы с SIMD в C/C++ в код надо добавить
#include <x86intrin.h>Так же компилятору надо сказать, что нужно использовать расширения, иначе будут ошибки вида
always_inline function '_popcnt32' requires target feature 'popcnt', but .... Сделать это можно несколькими путями:- Перечислить все необходимые feature, например
-mpopcnt - Указать целевую архитектуру процессора поддерживающего необходимые feature, например
-march=corei7 - Дать компилятору возможность использовать все расширения процессора, на котором происходит сборка:
-march=native
Что же можно ускорить в коде из 3 строк?
for (int i = 0; i < ARR_SIZE; ++i)
if (arr[i] == v)
++cnt;
Хорошо бы уменьшить количество итераций и проводить сравнение сразу с несколькими элементами за один цикл. Открываем сайт от Intel, выбираем только SSE расширения и категорию «Compare». Первыми в списке идёт семейство функций
__m128i _mm_cmpeq_epi* (__m128i a, __m128i b).
Открываем документацию первой из них и видим:
Compare packed 16-bit integers in a and b for equality, and store the results in dst.То что надо! Осталось только превратить
[]int16_t в __m128i. Для этого используются функции из категорий «Set» и «Load».Итак, функция
_mm_cmpeq_epi16 сравнивает параллельно 8 int16_t чисел в «массивах» a и b, и возвращает «массив» из чисел 0xFFFF — для одинаковых элементов и 0x0000 — для разных: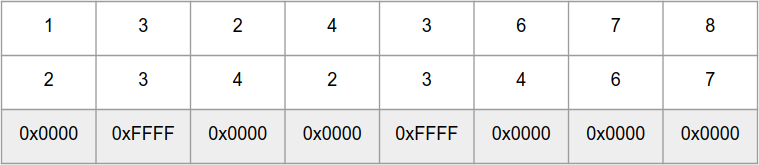
Для быстрого подсчёта количества бит в числе есть функции
_popcnt32 и _popcnt64, которые работают с 32 и 64 разрядными числами соответственно. Но, к сожалению, нет функции которая может привести результат _mm_cmpeq_epi16 к битовой маске, но есть функция _mm_movemask_epi8, которая делает аналогичную операцию для «массива» из 16 int8_t чисел. Но _mm_movemask_epi8 можно использовать для «массива» из 8 int16_t чисел, просто в конце результат надо будет разделить на 2.Теперь есть всё, чтобы приступить к тестированию SIMD.
Вариант 1
int64_t cnt = 0;
// Превращаем искомое значение в "массив" из 8 одинаковых элементов
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
// Для каждого блока из 8 элементов помещаем в переменную для сравнения
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2], arr[i + 1], arr[i]);
// Получаем количество совпадений * 2
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
// Делим на 2
cnt >>= 1;
Бенчмарк показал следующие результаты:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435
Всего лишь в 2 раза быстрее, а я обещал в 5+.
Для того, чтобы понять где могут быть узкие места, придётся опуститься на уровень ассемблера.
--------------- Копирование 8 элементов в sseArr ---------------
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
40133a: 48 8b 05 77 1d 20 00 mov 0x201d77(%rip),%rax # 6030b8 <_ZL3arr>
arr[i + 1], arr[i]);
401341: 48 63 8d 9c fe ff ff movslq -0x164(%rbp),%rcx
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
401348: 66 8b 54 48 0e mov 0xe(%rax,%rcx,2),%dx
40134d: 66 8b 74 48 0c mov 0xc(%rax,%rcx,2),%si
401352: 66 8b 7c 48 0a mov 0xa(%rax,%rcx,2),%di
401357: 66 44 8b 44 48 08 mov 0x8(%rax,%rcx,2),%r8w
40135d: 66 44 8b 4c 48 06 mov 0x6(%rax,%rcx,2),%r9w
401363: 66 44 8b 54 48 04 mov 0x4(%rax,%rcx,2),%r10w
arr[i + 1], arr[i]);
401369: 66 44 8b 1c 48 mov (%rax,%rcx,2),%r11w
40136e: 66 8b 5c 48 02 mov 0x2(%rax,%rcx,2),%bx
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
401373: 66 89 55 ce mov %dx,-0x32(%rbp)
401377: 66 89 75 cc mov %si,-0x34(%rbp)
40137b: 66 89 7d ca mov %di,-0x36(%rbp)
40137f: 66 44 89 45 c8 mov %r8w,-0x38(%rbp)
401384: 66 44 89 4d c6 mov %r9w,-0x3a(%rbp)
401389: 66 44 89 55 c4 mov %r10w,-0x3c(%rbp)
40138e: 66 89 5d c2 mov %bx,-0x3e(%rbp)
401392: 66 44 89 5d c0 mov %r11w,-0x40(%rbp)
401397: 44 0f b7 75 c0 movzwl -0x40(%rbp),%r14d
40139c: c4 c1 79 6e c6 vmovd %r14d,%xmm0
4013a1: 44 0f b7 75 c2 movzwl -0x3e(%rbp),%r14d
4013a6: c4 c1 79 c4 c6 01 vpinsrw $0x1,%r14d,%xmm0,%xmm0
4013ac: 44 0f b7 75 c4 movzwl -0x3c(%rbp),%r14d
4013b1: c4 c1 79 c4 c6 02 vpinsrw $0x2,%r14d,%xmm0,%xmm0
4013b7: 44 0f b7 75 c6 movzwl -0x3a(%rbp),%r14d
4013bc: c4 c1 79 c4 c6 03 vpinsrw $0x3,%r14d,%xmm0,%xmm0
4013c2: 44 0f b7 75 c8 movzwl -0x38(%rbp),%r14d
4013c7: c4 c1 79 c4 c6 04 vpinsrw $0x4,%r14d,%xmm0,%xmm0
4013cd: 44 0f b7 75 ca movzwl -0x36(%rbp),%r14d
4013d2: c4 c1 79 c4 c6 05 vpinsrw $0x5,%r14d,%xmm0,%xmm0
4013d8: 44 0f b7 75 cc movzwl -0x34(%rbp),%r14d
4013dd: c4 c1 79 c4 c6 06 vpinsrw $0x6,%r14d,%xmm0,%xmm0
4013e3: 44 0f b7 75 ce movzwl -0x32(%rbp),%r14d
4013e8: c4 c1 79 c4 c6 07 vpinsrw $0x7,%r14d,%xmm0,%xmm0
4013ee: c5 f9 7f 45 b0 vmovdqa %xmm0,-0x50(%rbp)
4013f3: c5 f9 6f 45 b0 vmovdqa -0x50(%rbp),%xmm0
4013f8: c5 f9 7f 85 80 fe ff vmovdqa %xmm0,-0x180(%rbp)
4013ff: ff
--------------- Подсчёт совпавших элементов ---------------
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
401400: c5 f9 6f 85 a0 fe ff vmovdqa -0x160(%rbp),%xmm0
401407: ff
401408: c5 f9 6f 8d 80 fe ff vmovdqa -0x180(%rbp),%xmm1
40140f: ff
401410: c5 f9 7f 45 a0 vmovdqa %xmm0,-0x60(%rbp)
401415: c5 f9 7f 4d 90 vmovdqa %xmm1,-0x70(%rbp)
40141a: c5 f9 6f 45 a0 vmovdqa -0x60(%rbp),%xmm0
40141f: c5 f9 6f 4d 90 vmovdqa -0x70(%rbp),%xmm1
401424: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0
401428: c5 f9 7f 45 80 vmovdqa %xmm0,-0x80(%rbp)
40142d: c5 f9 6f 45 80 vmovdqa -0x80(%rbp),%xmm0
401432: c5 79 d7 f0 vpmovmskb %xmm0,%r14d
401436: 44 89 b5 7c ff ff ff mov %r14d,-0x84(%rbp)
40143d: 44 8b b5 7c ff ff ff mov -0x84(%rbp),%r14d
401444: f3 45 0f b8 f6 popcnt %r14d,%r14d
401449: 49 63 c6 movslq %r14d,%rax
40144c: 48 03 85 b8 fe ff ff add -0x148(%rbp),%rax
401453: 48 89 85 b8 fe ff ff mov %rax,-0x148(%rbp)
Видно, что очень много команд процессора занимает копирование элементов массива в
sseArr.Вариант 2
Вместо функции
_mm_set_epi16, можно использовать _mm_loadu_si128. Описание функции: Load 128-bits of integer data from unaligned memory into dstНа вход ожидается указатель на память, что намекает на более оптимальное копирование данных в переменную. Проверим:
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]);
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
Бенчмарк показал улучшение в ~2 раза:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435
BM_SSE_COUNT_LOADU 454 ns 454 ns 1548455
Машинный код выглядит так:
auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]);
401695: 48 8b 05 1c 1a 20 00 mov 0x201a1c(%rip),%rax # 6030b8 <_ZL3arr>
40169c: 48 63 8d bc fe ff ff movslq -0x144(%rbp),%rcx
4016a3: 48 8d 04 48 lea (%rax,%rcx,2),%rax
4016a7: 48 89 45 d8 mov %rax,-0x28(%rbp)
4016ab: 48 8b 45 d8 mov -0x28(%rbp),%rax
4016af: c5 fa 6f 00 vmovdqu (%rax),%xmm0
4016b3: c5 f9 7f 85 a0 fe ff vmovdqa %xmm0,-0x160(%rbp)
4016ba: ff
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
4016bb: c5 f9 6f 85 c0 fe ff vmovdqa -0x140(%rbp),%xmm0
4016c2: ff
4016c3: c5 f9 6f 8d a0 fe ff vmovdqa -0x160(%rbp),%xmm1
4016ca: ff
4016cb: c5 f9 7f 45 c0 vmovdqa %xmm0,-0x40(%rbp)
4016d0: c5 f9 7f 4d b0 vmovdqa %xmm1,-0x50(%rbp)
4016d5: c5 f9 6f 45 c0 vmovdqa -0x40(%rbp),%xmm0
4016da: c5 f9 6f 4d b0 vmovdqa -0x50(%rbp),%xmm1
4016df: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0
4016e3: c5 f9 7f 45 a0 vmovdqa %xmm0,-0x60(%rbp)
4016e8: c5 f9 6f 45 a0 vmovdqa -0x60(%rbp),%xmm0
4016ed: c5 f9 d7 d0 vpmovmskb %xmm0,%edx
4016f1: 89 55 9c mov %edx,-0x64(%rbp)
4016f4: 8b 55 9c mov -0x64(%rbp),%edx
4016f7: f3 0f b8 d2 popcnt %edx,%edx
4016fb: 48 63 c2 movslq %edx,%rax
4016fe: 48 03 85 d8 fe ff ff add -0x128(%rbp),%rax
401705: 48 89 85 d8 fe ff ff mov %rax,-0x128(%rbp)
Вариант 3
SSE инструкции работают с выровненной памятью по 16 байт. Функция _mm_loadu_si128 позволяет избежать это ограничение, но если выделять память под массив с помощью функции
aligned_alloc(16, SZ), то можно будет напрямую передавать адрес в SSE инструкцию:int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = *(__m128i *) &allignedArr[i];
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
Такая оптимизация даёт ещё немного прироста производительности:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 2084 ns 2084 ns 333079
BM_SSE_COUNT_SET_EPI 937 ns 937 ns 746435
BM_SSE_COUNT_LOADU 454 ns 454 ns 1548455
BM_SSE_COUNT_DIRECT 395 ns 395 ns 1770803
Это произошло благодаря экономии 3 инструкций:
auto sseArr = *(__m128i *) &allignedArr[i];
40193c: 48 8b 05 7d 17 20 00 mov 0x20177d(%rip),%rax # 6030c0 <_ZL11allignedArr>
401943: 48 63 8d cc fe ff ff movslq -0x134(%rbp),%rcx
40194a: c5 f9 6f 04 48 vmovdqa (%rax,%rcx,2),%xmm0
40194f: c5 f9 7f 85 b0 fe ff vmovdqa %xmm0,-0x150(%rbp)
401956: ff
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
401957: c5 f9 6f 85 d0 fe ff vmovdqa -0x130(%rbp),%xmm0
40195e: ff
40195f: c5 f9 6f 8d b0 fe ff vmovdqa -0x150(%rbp),%xmm1
401966: ff
401967: c5 f9 7f 45 d0 vmovdqa %xmm0,-0x30(%rbp)
40196c: c5 f9 7f 4d c0 vmovdqa %xmm1,-0x40(%rbp)
401971: c5 f9 6f 45 d0 vmovdqa -0x30(%rbp),%xmm0
401976: c5 f9 6f 4d c0 vmovdqa -0x40(%rbp),%xmm1
40197b: c5 f9 75 c1 vpcmpeqw %xmm1,%xmm0,%xmm0
40197f: c5 f9 7f 45 b0 vmovdqa %xmm0,-0x50(%rbp)
401984: c5 f9 6f 45 b0 vmovdqa -0x50(%rbp),%xmm0
401989: c5 f9 d7 d0 vpmovmskb %xmm0,%edx
40198d: 89 55 ac mov %edx,-0x54(%rbp)
401990: 8b 55 ac mov -0x54(%rbp),%edx
401993: f3 0f b8 d2 popcnt %edx,%edx
401997: 48 63 c2 movslq %edx,%rax
40199a: 48 03 85 e8 fe ff ff add -0x118(%rbp),%rax
4019a1: 48 89 85 e8 fe ff ff mov %rax,-0x118(%rbp)
Заключение
Все приведённые ассемблерные листинги были получены после компиляции с -O0. Если включить -O3, то компилятор довольно хорошо оптимизирует код и такого разделения по времени уже не будет:
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_Count 129 ns 129 ns 5359145
BM_SSE_COUNT_SET_EPI 70 ns 70 ns 9936200
BM_SSE_COUNT_LOADU 49 ns 49 ns 14187659
BM_SSE_COUNT_DIRECT 53 ns 53 ns 13401612
#include <benchmark/benchmark.h>
#include <x86intrin.h>
#include <cstring>
#define ARR_SIZE 1024
#define VAL 50
static int16_t *getRandArr() {
auto res = new int16_t[ARR_SIZE];
for (int i = 0; i < ARR_SIZE; ++i) {
res[i] = static_cast<int16_t>(rand() % (VAL * 2));
}
return res;
}
static auto arr = getRandArr();
static int16_t *getAllignedArr() {
auto res = aligned_alloc(16, sizeof(int16_t) * ARR_SIZE);
memcpy(res, arr, sizeof(int16_t) * ARR_SIZE);
return static_cast<int16_t *>(res);
}
static auto allignedArr = getAllignedArr();
static void BM_Count(benchmark::State &state) {
for (auto _ : state) {
int64_t cnt = 0;
for (int i = 0; i < ARR_SIZE; ++i)
if (arr[i] == VAL)
++cnt;
benchmark::DoNotOptimize(cnt);
}
}
BENCHMARK(BM_Count);
static void BM_SSE_COUNT_SET_EPI(benchmark::State &state) {
for (auto _ : state) {
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = _mm_set_epi16(arr[i + 7], arr[i + 6], arr[i + 5], arr[i + 4], arr[i + 3], arr[i + 2],
arr[i + 1], arr[i]);
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
benchmark::DoNotOptimize(cnt >> 1);
}
}
BENCHMARK(BM_SSE_COUNT_SET_EPI);
static void BM_SSE_COUNT_LOADU(benchmark::State &state) {
for (auto _ : state) {
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = _mm_loadu_si128((__m128i *) &arr[i]);
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
benchmark::DoNotOptimize(cnt >> 1);
}
}
BENCHMARK(BM_SSE_COUNT_LOADU);
static void BM_SSE_COUNT_DIRECT(benchmark::State &state) {
for (auto _ : state) {
int64_t cnt = 0;
auto sseVal = _mm_set1_epi16(VAL);
for (int i = 0; i < ARR_SIZE; i += 8) {
auto sseArr = *(__m128i *) &allignedArr[i];
cnt += _popcnt32(_mm_movemask_epi8(_mm_cmpeq_epi16(sseVal, sseArr)));
}
benchmark::DoNotOptimize(cnt >> 1);
}
}
BENCHMARK(BM_SSE_COUNT_DIRECT);
BENCHMARK_MAIN();
Часть 2
Комментарии (93)

nerudo
17.02.2019 12:46+4Хм. А как-то странно долго исследовать производительность на -O0, после чего сделать краткую сноску что будет с -O3, где результат совсем не так впечатляет. Ну и с "-O3 -march=corei7" SSE будет задействован автоматически. А еще можно попробовать взять icc вместо clang…

svistunov Автор
17.02.2019 13:04+1То, что компилятор «додумался» сделать на маленькой программке, совсем не гарантирует того, что он это сделает на большой. Поэтому лучше самому понимать, как писать более оптимальные варианты.
Temtaime
17.02.2019 22:23+3Через год оптимальные варианты станут менее оптимальными из-за нового AVX1024/AVX2048/…
Лучше критичные к производительности части выносить в отдельные функции, которые отдавать компилятору, проверяя выхлоп и делая замеры. Объём программы не влияет на качество оптимизации отдельно взятой функции. Зато код можно будет собрать при необходимости и под старые процессоры и под другие архитектуры.picul
18.02.2019 02:08AVX-512 уже 6 лет, и пока он появился только на ксяонах. Не стоит надеяться на то, что завтра производители подгонят процессоры, послезавтра компиляторы, а к концу недели быдлокод будет летать как фанера над Парижем.
Полностью отдавать действительно критичные части программы компилятору — тоже плохая идея. Компилятор не может правильно расположить данные в памяти и построить качественную архитектуру программы — он всего лишь выдаст код, который от него потребуют. Потребуете что-нибудь не то — оптимизаций не получите.
0xtcnonr
18.02.2019 04:58Через год оптимальные варианты станут менее оптимальными из-за нового AVX1024/AVX2048/…
Это ничего не меняет, это изменит лишь одну константу в нормальном коде, а в хорошем коде вообще само всё заработает.
Лучше критичные к производительности части выносить в отдельные функции, которые отдавать компилятору
Ну да, чтобы он не смог.
Объём программы не влияет на качество оптимизации отдельно взятой функции.
Дело не в объёме программы, а сложности задачи, которая вынесена в ту самую «функцию». С простой может повести, с чем-то более-менее сложным — поможет только чудо.
Зато код можно будет собрать при необходимости и под старые процессоры и под другие архитектуры.
Это итак работает без проблем. Допустим, мой код, который BM_SSE_COUNT_NG_NAIVESUMM — спокойно собирается и под старые процессоры и под другие архитектуры. Для автоматической поддержки AVX2/AVX512/AVX1024/AVX2048/… — там нужно только реализовать обобщённую функцию summ();
Далее можно поменять __vector_size__(16) на __vector_size__(32) и будет не sse, а avx2, на 64 — будет avx512.
И как я уже говорил — она без проблем собирается и для других процессоров/архитектур: godbolt.org/z/muBfnL
Для подобных вещей существуют специальные библиотеки, т.к. компиляторы обобщают не все возможности симдов.
firedragon
18.02.2019 12:45В общем то компиляторы от интела и нвидии они решают.
Даже простая замена g на i добавит процентов 20%.
Плюс вылизанные библиотеки которые нужно уметь использовать.
И выбор инструмента, под каждую задачу.
Не зря проект на С++ собирается ООООЧЕНЬ долгоrotarepo
18.02.2019 20:12+2На CPU может и решают, а на GPU всё значительно хуже. Неоднократно получал кратное ускорение в CUDA просто вдумчиво переписав Сишный код на PTX (это их «ассемблер»). Имхо для эффективного автораспараллеливания надо дорабатывать совремненые ЯВУ, расширять их синтаксис.
TitovVN1974
17.02.2019 13:201) Так как приводится время исполнения кода, контролировалась ли неизменность частоты процессора i7-8750H?
и еще размышления, не в коей мере НЕ замечания:
2) АVX2 — не ускорит по сравнению с SSE?
3) Intel C++/Fortran (IPP, MKL ?) позволят добавить к векторизации автоматическое распараллеливание.
Если Fortran, то дополнительно использовать coarray для данной задачи очень просто.
p.s. просто пятикратное ускорение из за автоматической векторизации и префетча,
встречалось мне на еще P4 на реальной расчетной задаче моделирования.svistunov Автор
17.02.2019 13:351) Да, в соответствии с рекомендацией github.com/google/benchmark#disable-cpu-frequency-scaling
2) AVX нет на десктопных CPU, но думаю, что его использование может ещё ускорить.
3) Распараллеливание — это всё же другой подход, при условии, что все ядра загружены, от распараллеливания не будет выгоды.TitovVN1974
17.02.2019 13:54AVX2 есть на i7-8750H и на большинстве CPU.
Если ядра уже загружены, разумеется.svistunov Автор
17.02.2019 14:03Действительно есть, я был уверен, что он есть только на Xeon'ах:
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp flush_l1d
Значит будет продолжение, с использованием AVX.khim
17.02.2019 14:42Вы с AVX512. перепутали. Вот это чудо есть очень мало где. А AVX и AVX2 — почти везде…
Chugumoto
18.02.2019 08:59если брать всякие целероны и пентиумы, то на них же еще не завезли

IRainman
18.02.2019 17:51Автор явно хочет выжать из конкретного железа максимум:
Перечислить все необходимые feature, например -mpopcnt
Указать целевую архитектуру процессора поддерживающего необходимые feature, например -march=corei7
Дать компилятору возможность использовать все расширения процессора, на котором происходит сборка: -march=native
даже native использует.
Kobalt_x
18.02.2019 10:06AVX-512 на данный момент не так прост, как кажется blog.cloudflare.com/on-the-dangers-of-intels-frequency-scaling
TLDR проц может сильно сбросить частоту.
Nagg
17.02.2019 18:11+4А вы и так использовали AVX — ваши SSE регистры — это AVX регистры на самом деле ;-)
DistortNeo
17.02.2019 18:44+1Именно так. Автор совершенно не обратил внимания, что вместо команд SSE компилятор нагенерил команд AVX (они имеют префикс «v» в мнемокоде).
VerdOrr
17.02.2019 18:46-1SSE — xmm0-15
AVX (256) — ymm0-15
AVX512 — zmm0-31Nagg
17.02.2019 18:59xmm0 на всем современном железе — верхняя часть ymm0, сhange my mind. Отсюда вырастают грабли с vzeroupper
DistortNeo
17.02.2019 19:12Грабли с vzeroupper вылезают из-за вполне естественного желания вендоров не перегружать процессорную логику: не добавлять новые регистры, а расширять старые, не делать отдельные ALU-модули для 128- и 256-битных операций.
Nagg
17.02.2019 19:31Как я понимаю это приводит к небольшому penalty, https://github.com/dotnet/coreclr/pull/20788#discussion_r230869394
DistortNeo
17.02.2019 19:05Конкретно в данном случае — нет. Команды
vpcmpeqw,vpmovmskb— это всё AVX-команды, и работают они с AVX-регистрами. Если в качестве аргумента такой команды передаётся XMM-регистр, а не YMM, то команда просто обнуляет верхнюю половину YMM-регистра. Сделано так было из соображений упрощения внутрипроцессорной логики.

0xd34df00d
17.02.2019 19:10+1Это довольно простая задача, которая скорее упрется в шину памяти.
На похожей по вычислительной нагрузке задаче (побитово обратить несколько мегабайт данных) профита от использования AVX уже не было, да и быстрый расчет на бумажке показал, что упираюсь я в память.
gitKroz
17.02.2019 13:52Подскажите, а можно ли ускорить такое?
Есть массив значений V(alues). Есть массив Q(uery), который содержит индексы массива V. Нужно получить массив R(esult) по следующему правилу: из массива Q выбираем индекс, по нему выбираем значение из V. То есть:
R[i] = V[ Q[i] ]
А в идеале такая цепочка преобразований может быть достаточно длинной, например:
R[i] = V[ A1[ A2[ Q[i] ] ] ]
Есть ли SIMD инструкции, для подобной задачи?TitovVN1974
17.02.2019 14:45Точно не гарантирую, но, IMHO, должны быть.
p.s. тут интуитивно встает вопрос, следует ли считать такое выражение векторно, но поэтапно?
vassabi
17.02.2019 14:55по идее операцию V[ Q[i] ] можно представить в виде квадратной матрицы из нулей и единиц, где единицы будут стоять на тех индексах, откуда берутся значения (т.е. она будет верхне- или нижне- угольной):
R[i] = V[ Q[i] ] --> Rvector = Vmatrix * Qvector
так что цепочки таких преобразований — это цепочки матриц, которые можно умножить и получить ускорение.gitKroz
17.02.2019 15:30Допустим так:
V = (10 20 30) Q = ( 2 3 1) Expected R = (20 30 10) ( 0 1 0 ) R = (10 20 30) x ( 0 0 1 ) = (20 30 10) ( 1 0 0 )
Выражение для https://matrixcalc.org: {{10,20,30}} * {{0,0,1},{1,0,0},{0,1,0}}
Тогда нужен быстрый способ преобразовать 2 в (0 1 0).
vassabi
17.02.2019 18:13нужен быстрый способ преобразовать 2 в (0 1 0).
А чем плоха мемоизация, т.е. создать массив
строка(1) = (1 0 0 ..)
строка(2) = (0 1 0 ..)
строка(3) = (0 0 1 ..)
и брать оттуда? или у вас вектора на миллионы компонент?
UPD: если вопрос просто в ускорении цепочки, то вполне возможно оставить их в виде векторов, потому что две перестановки всегда можно преобразовать в одну по формуле Vba[i] = Va[ Vb[i] ]
т.е. для R[i] = V[ A1[ A2[ Q[i] ] ] ]
это будет R[i] = VA1A2[ Q[i] ] где VA1A2[i] = A2[ A1[ V[i] ] ]
marsianin
17.02.2019 15:02В AVX2 есть инструкции VGATHERDPD/VGATHERQPD/VGATHERDPS/VGATHERQPS, которые как раз делают такой доступ: R[i] = V[Q[i]]
khim
17.02.2019 16:10+3Вот только природу не обманешь: произвольный доступ к памяти дорог. Если у вас будет много этих инструкций — вы никакого ускорения не получите. За исключением случая когда вы читаете буквально чуть не соседние элементы массива — но для таких случаев есть многочисленные шаффлы.
marsianin
17.02.2019 18:48Согласен, при слишком сильно разбросанном доступе gather быстрее не будет. Но при этом процессор будет декодировать только одну инструкцию вместо нескольких. Так что он может потребить чуточку меньше электричества. А вообще, по-хорошему, надо проверять на конкретных задачах, будет ли прирост производительности от использования gather.
rotarepo
17.02.2019 19:43В очень многих случаях эти массивы быстро окажутся в кэше процессора. Да и prefetch никто не отменял.
khim
18.02.2019 00:43prefetch требует предсказуемых паттернов доступа к памяти, плюс свободной шины.
Как тут написали выше: в 90% случаев пользы от этих инструкций нету. Хотя на спор сделать задачу, где они выиграют, конечно, можно…
khim
17.02.2019 16:18А как вы это себе представляете? Ну, на физическом уровне? Доступ в память — штука медленная. Ибо шина памяти у процессора одна и если, не дай бог, придётся идти аж в DIMM, «по большому» — это это сотни тактов процессора.
Соответственно вариантов два:
1. Ваши функции A1, A2, Q — возвращают значение из очень узкого диапазона — и тогда можно использовать разные трюки.
2. Ваши функции A1, A2, Q — бегают по довольно большому диапазону — и тогда вы «убьёте весь кеш»… О какой-то скорости после этого говорить бессмысленно.
Пожалуй единственный случай, когда соответствующие AVX2 инструкции могут быть полезны — это, условно «маппинг bad block'ов». Когда подавляющее большинство обсуждаемых индексов — это последовательности 1, 2, 4,… — но некоторые редкие элементы прыгают куда-то «в сторону»…

Alyoshka1976
17.02.2019 13:56В давние времена, когда SSE3 было новинкой, я разрабатывая ПО для моделирования СТЭ жел. дороги, добился заметного ускорения операций с комплексными числами — использовал в Delphi ассемблерные вставки с SIMD-операциями, например:
//Умножение комплексных чисел function CMul(const X,Y:Complex):Complex; {$IFNDEF SIMD} begin Result:=SetComplex(X.Re*Y.Re-X.Im*Y.Im,X.Im*Y.Re+X.Re*Y.Im); end; {$ELSE} asm movupd XMM0, [EAX]// X.Im X.Re DB $F2,$0F,$12,$12// movddup xmm2, [EDX] XMM2 Y.Re add EDX, $8 DB $F2,$0F,$12,$0A// movddup xmm1, [EDX] XMM1 Y.Im mulpd xmm1, xmm0 //X.Im*Y.Im X.Re*Y.Im mulpd xmm2, xmm0 //Y.Re*X.Im Y.Re*X.Re shufpd xmm1, xmm1, $1 //X.Re*Y.Im X.Im*Y.Im DB $66,$0F,$D0,$D1 //addsubpd xmm2, xmm1 movupd [ECX], xmm2 end; {$ENDIF}
picul
17.02.2019 15:37SSE инструкции работают с выровненной памятью по 16 бит.
Правильно «байт».
И, на счет последнего варианта, не думаю, что это повлияет на быстродействие, но все же хорошим тоном было бы не кастовать к указателю и разыменовывать, а прописать _mm_load_si128.
Кстати, вроде как movemask и popcnt — не самые приятные операции; не пробовали аккумулировать результат SIMD-регистрах, а потом уже комбинировать результат? Я имею в виду что-то вроде следующего:
__m128i accumulator = _mm_setzero_si128( ); auto const value = _mm_set1_epi16( VAL ); for ( size_t i = 0; i < ARR_SIZE; i += 8 ) { auto const current_value = _mm_load_si128( allignedArr + i ); accumulator = _mm_add_epi16( accumulator, _mm_and_si128( _mm_cmpeq_epi16( value, current_value ), _mm_set1_epi16( 0x1 ) ) ); } size_t cnt = _mm_extract_epi16( accumulator, 0 ) + _mm_extract_epi16( accumulator, 1 ) + _mm_extract_epi16( accumulator, 2 ) + _mm_extract_epi16( accumulator, 3 ) + _mm_extract_epi16( accumulator, 4 ) + _mm_extract_epi16( accumulator, 5 ) + _mm_extract_epi16( accumulator, 6 ) + _mm_extract_epi16( accumulator, 7 );
Правда, это можно использовать только для массивов размера <= 2^19, но все же.Nagg
17.02.2019 18:10Кстати, сланг способен оптимизировать простой код по подсчету единиц на popcnt, но когда вы это делаете для массива — он решает что куда быстрее вычислять popcnt векторно вручную
raamid
17.02.2019 15:53Кстати, я тоже как-то увлекался оптимизацией различных алгоритмов, написал метод Гаусса с использованием итераторов, основанных на указателях, но, как показала практика, обогнать оптимизирующий компилятор мне не удалось. Я правда не использовал специальные инструкции, как автор статьи.
Интересно посмотреть сравнение оптимизирующего компилятора и метода, предложенного автором.

neurocore
17.02.2019 16:15Вообще полезно ознакомиться с SIMD. Хоть компилятор и заменяет простейшие случаи, но некоторые алгоритмы приходится разрабатывать самому, как например операция вычисления взвешенной суммы
DistortNeo
17.02.2019 18:41Что интересно: в режиме -O3 код с невыровненным доступом и явным вызовом loadu работает быстрее.
А ответ простой: невыровненный доступ запрещён при использовании команд SSE, но не команд AVX. Автор же, указав соответствующий ключ компилятора, заставил его сгенерить не SSE-команды, а аналогичные AVX-команды.
Поэтому я не удивлюсь, если компилятор соптимизировал этот момент, и для последних двух вариантов сгенерировал идентичный код. Ну а небольшая разница во времени — просто статистическая погрешность.Nagg
17.02.2019 19:02+1на современных камнях вроде бы париться за выравнивание особо не стоит — перфоманс почти не влияет
DistortNeo
17.02.2019 19:15Да, при последовательном доступе совершенно не влияет, выровнено ли чтение или нет.
Но до появления AVX париться приходилось, потому что SSE-команды иначе бросали исключения.
gchebanov
17.02.2019 20:01Добавил вариант(1 c sse, 2 c avx2) где вместо
movemaskделаетсяand(set1_epi16(1)); sum_epi16в цикле, в конце цикла 3 разаhadd+extract_epi16(0)+(avx2 ? extract_epi16(8) : 0). Ускорение уже не в 4(7) раза, а в 6(12.5).
Intel(R) Core(TM) i5-7267U CPU @ 3.10GHz Run on (4 X 3100 MHz CPU s) CPU Caches: L1 Data 32K (x2) L1 Instruction 32K (x2) L2 Unified 262K (x2) L3 Unified 4194K (x1) ------------------------------------------------------------ Benchmark Time CPU Iterations ------------------------------------------------------------ BM_Count 228 ns 227 ns 3088640 BM_SSE_COUNT_SET_EPI 82 ns 81 ns 8573808 BM_SSE_COUNT_LOADU 57 ns 57 ns 11927684 BM_SSE_COUNT_DIRECT 66 ns 65 ns 10831051 BM_SSE_HADD 39 ns 38 ns 18249460 BM_AVX2_COUNT 29 ns 29 ns 24458164 BM_AVX2_HADD 18 ns 18 ns 39366536
UPD
оптимизатор это превратил в (vpcmpeqw+vpsubw) на каждые 16 uint16_t. согласно спеке throughput = 0.5 + 0.33 (предполагаем зависимость). Общее время —(0.5 + 0.33) * 1024 / 16 / 3.2 = 16.6ns, что очень похоже на правду.0xtcnonr
18.02.2019 01:35using int16_vec_t = int16_t __attribute__((__vector_size__(16))); auto vhadd(int16_vec_t a, int16_vec_t b) { return __builtin_ia32_phaddw128(a, b); } auto vhsumm(int16_vec_t v) { v = vhadd(v, v); v = vhadd(v, v); v = vhadd(v, v); return v; } auto summ(int16_vec_t v) { return v[0] + v[1] + v[2] + v[3] + v[4] + v[5] + v[6] + v[7]; } static void BM_SSE_COUNT_NG_HSUMM(benchmark::State &state) { for(auto _: state) { auto cnt = int16_vec_t{} - 1; auto it = (int16_vec_t *)allignedArr, end = (int16_vec_t *)(allignedArr + ARR_SIZE); while(it < end) { cnt += (*it == VAL); ++it; cnt += (*it == VAL); ++it; cnt += (*it == VAL); ++it; cnt += (*it == VAL); ++it; } cnt = -1 - cnt; auto res = vhsumm(cnt)[0]; benchmark::DoNotOptimize(res); } } BENCHMARK(BM_SSE_COUNT_NG_HSUMM); static void BM_SSE_COUNT_NG_NAIVESUMM(benchmark::State &state) { for(auto _: state) { auto cnt = int16_vec_t{}; auto it = (int16_vec_t *)allignedArr, end = (int16_vec_t *)(allignedArr + ARR_SIZE); while(it < end) { cnt += (*it == VAL) & 1; ++it; cnt += (*it == VAL) & 1; ++it; cnt += (*it == VAL) & 1; ++it; cnt += (*it == VAL) & 1; ++it; } auto res = summ(cnt); benchmark::DoNotOptimize(res); } } BENCHMARK(BM_SSE_COUNT_NG_NAIVESUMM);
оптимизатор это превратил в (vpcmpeqw+vpsubw) на каждые 16 uint16_t.
Действительно, гцц осилил превратить превратить второй в подобие первого решения.
согласно спеке throughput = 0.5 + 0.33 (предполагаем зависимость).
Это тут непричём.
Общее время — (0.5 + 0.33) * 1024 / 16 / 3.2 = 16.6ns, что очень похоже на правду.
Абсолютно неверно. Никакие трупуты не складываются, особенно так колхозно.
cnt += (*it == VAL) & 1; ++it;
Это зависимое днище, оно будет упираться в летенси vpsubw, который(очевидно) 1такт. Остальное стоит ноль. Отклонения от 20(вниз) — это лишь следствие реорганизации вычислений.gchebanov
18.02.2019 11:05Это тут непричём.
Неточно выразился, конечно же независимость.
Абсолютно неверно.
Возможно я не прав, но я вижу 64 * 2 + eps инструкций которые выполняются в цикле, причем это суммарно занимает 18 * 3.1 ~= 56 тактов на цикл, причем соотношение сохраняется при росте размера задачи (пока она влезает в L1). Реорганизация вычислений действительно может случатся, я не смотрел как написан libbenchmark (rdtscp?). Но даже rdtscp разрешает реордеринг, который может всё испортить, если компилятор развернет цикл бенчмарка.
Никакие трупуты не складываются, особенно так колхозно
А как они по-вашему должны складываться, как среднее гармоническое?
На работе посмотрю выхлоп IACA, только после этого будет понятно что там на самом деле, а пока мы знаем что ядро умеет делать 2 vpcmpeqw за такт, и 3 vpsubw за такт. Также нет ничего что бы помешало выполнять эти инструкции параллельно (при наличии нужного числа регистров и использовании нужного числа аккумуляторов). Этого уже должно хватать на 5/6 такта на 16 элементов, а если еще и они друг другу не мешают — то и 1/2 такта (во что я лично не верю, т.к. skylake на картинке только 3 INT Vect ALU).
Моя реализация скорее всего упирается в l1i, хотя на 6 итераций я использую 72 байта инструкций, а кеш должен уметь читать 96.
BENCHMARK 4096 (clang)Benchmark Time CPU Iterations ----------------------------------------------------------------------- BM_Count 944 ns 942 ns 708115 BM_ShiftCount 394 ns 392 ns 1748745 BM_SbbCount 454 ns 447 ns 1580556 BM_Sbb2Count 465 ns 460 ns 1572391 BM_SSE_COUNT_NG_HSUMM_ARRAY 183 ns 182 ns 3813966 BM_SSE_COUNT_NG_HSUMM 109 ns 109 ns 6448166 BM_SSE_COUNT_NG_NAIVESUMM_ARRAY 143 ns 140 ns 5204190 BM_SSE_COUNT_NG_NAIVESUMM 149 ns 148 ns 4719780 BM_SSE_COUNT_SET_EPI 320 ns 319 ns 2228249 BM_SSE_COUNT_LOADU 233 ns 233 ns 2998886 BM_SSE_COUNT_DIRECT 236 ns 235 ns 2997461 BM_SSE_HADD 150 ns 149 ns 4609448 BM_AVX2_COUNT 114 ns 114 ns 6065280 BM_AVX2_HADD 77 ns 77 ns 9087605 BM_AVX2_HADD2 76 ns 76 ns 86604720xtcnonr
18.02.2019 19:22cnt += (((int16_vec_t*)allignedArr)[i] == VAL) & 1;
cnt += (((int16_vec_t*)allignedArr)[i + 16] == VAL) & 1;
cnt += (((int16_vec_t*)allignedArr)[i + 32] == VAL) & 1;
cnt += (((int16_vec_t*)allignedArr)[i + 64] == VAL) & 1;
Очевидно, что это неверный код.
Возможно я не прав, но я вижу 64 * 2 + eps инструкций которые выполняются в цикле, причем это суммарно занимает 18 * 3.1 ~= 56 тактов на цикл, причем соотношение сохраняется при росте размера задачи (пока она влезает в L1).
Это попытка подбить неверное представление под результат. Для того, что такого не было — надо взять флоаты, где различия уже более существенны и даже в таком колхозе сложно что-то перепутать.
Реорганизация вычислений действительно может случатся, я не смотрел как написан libbenchmark (rdtscp?). Но даже rdtscp разрешает реордеринг, который может всё испортить, если компилятор развернет цикл бенчмарка.
Я не про это, а про реорганизацию вычислений в теле цикла, которому может(и делает) компилятор.
Этого уже должно хватать на 5/6 такта на 16 элементов, а если еще и они друг другу не мешают — то и 1/2 такта (во что я лично не верю, т.к. skylake на картинке только 3 INT Vect ALU).
Вообще трупут — это очень глупая метрика от интела. Хотя интел нигде не писал 1/4 такта — это скорее всякие таблицы. Но я дам объяснение — man «zero idioms».
По поводу всего остального — считаю, что там всё неверно. У меня сейчас нет времени на «почему?». Как будет — отвечу подробнее.
gchebanov
18.02.2019 23:45Ну если есть 3 параллельных алу, но наверное они зачем-то нужны?
"zero idioms" — Как я понял это про полную элиминацию, у нас же все результаты важны и нужны. Возможно я неправильно представляю себе процессор, и то что я принимал за результат параллельной конвейерной обработки (muops unfused domain) есть всего лишь результат macrofusion. Как будет время поэкспериментирую с uarch-bench + libpfc, должно быть наглядно видно работу muops.
P.S. таблица с портами
Про skylake написано что sub может идти на p0, p1, p5; cmp — p0, p1.
исправленные результатыBM_SSE_COUNT_NG_NAIVESUMM_ARRAY 183 ns 182 ns 3837383 BM_SSE_COUNT_NG_NAIVESUMM_ARRAY 17 ns 17 ns 404348480xtcnonr
19.02.2019 00:05«zero idioms» — Как я понял это про полную элиминацию
Это про то, как add/xor и ещё много чего может иметь трупут 1/4 такта.
BM_SSE_COUNT_NG_NAIVESUMM_ARRAY 18.3 ns 18.3 ns 38331316
BM_SSE_COUNT_NG_NAIVESUMM 35.8 ns 35.8 ns 19558590
Я очень сомневаюсь в том, что подобная разница может существовать. Опять явно что-то не так.

Serge3leo
17.02.2019 20:51Однако зря для сей задачи не рассмотрели варианты параллельного исполнения с помощью Grand Central Dispatch или вручную std::thread(), thrd_create(), pthread_create()…
Часто возникает интересная ситуация, параллельный векторизованый код и параллельный не векторизованый код, при работе в Hyper Threading, работают примерно одинаково в виду того, что ядро одно ж.
Мало того ж, параллельный векторизованый код и паралельный не векторизованый код, и при работе на разных ядрах/процессорах, бывает, просто упирается в производительность ОЗУ.DistortNeo
17.02.2019 21:06+2Задействовать параллелизм для массива длиной 1024 элементов? Накладные расходы всё съедят.
Serge3leo
17.02.2019 21:39Если пул рабочих потоков уже готов и осталось только раздать отрезки вектора, то с GDC даже для 1024 элементов это будет более/менее эффективно. Но если со стартом рабочих потоков, то увы, УПС ;)
DistortNeo
18.02.2019 00:15+1Если потоки спят, то их пробуждение — задача не из быстрых. Да и переключение контекста — очень медленная штука.
Если просто играть в пинг-понг с другим потоком с помощью системных вызовов, то будет порядка 100 тысяч обменов сообщениями в секунду, или 10 мкс на одно сообщение. Это непозволительно много.
Если же рассмотреть ситуацию, когда потоки не засыпают, а крутятся в спинлоках и насилуют адресное пространство атомарными операциями, то и тут всё тоже будет не так радужно: атомарные операции блокируют шину, и чем больше потоков пытается работать с атомарными операциями, тем пропорционально дольше они будут выполняться. То есть один поток зависнет на одной операции на 5 нс, два потока — по 10 нс каждый и т.д. Если в пуле 4 потока, то это задержка каждого минимум на 20 нс до старта, а потом 20 нс на передачу результата, итого +40 нс на накладные расходы в идеальном случае.Serge3leo
18.02.2019 00:51Насчет насилия, потоками в «активном» ожидании, то тот же std::memory_order_acquire не насилует и не блокирует «шину», даже если таковая существует.
Но у Intel есть ещё PAUSE для исключения помех потоков на том же ядре и, даже, есть ещё MONITOR/MWAIT для энергоэффективной и быстрой реализации спинлоков, «барьеров с ожиданием» и т.п. Так что ваш расчёт накладных расходов..., он для процессоров из прошлого века.
Есть Grand Central Dispatch, оригинально, для macOS и FreeBSD, но и, наверняка, можно найти и GPL готовые изделия на тех же технологиях. Там всё не так просто ввиду ряда ограничений на Intel, но решаемо.DistortNeo
18.02.2019 01:22Вы бы изучили матчасть сначала, что ли. Прямо каша какая-то.
то тот же memory_order_acquire не насилует и не блокирует «шину», даже если она существует.
К процессорам x86 это вообще никак не относится, не вводите людей в заблуждение.
Но у Intel есть ещё PAUSE для исключения помех потоков на том же ядре
Это альтернатива NOP, просто более эффективная. Чудес она не делает.
есть ещё MONITOR/MWAIT для энергоэффективной и быстрой реализации спинлоков
Эти операции недоступны в пользовательском режиме. А переключаться в ядро — терять драгоценные наносекунды.
Есть Grand Central Dispatch, оригинально, для macOS и FreeBSD, но и, наверняка, можно найти и GPL готовые изделия на тех же технологиях. Там всё не так просто ввиду ряда ограничений на Intel, но решаемо.
И, собственно, что? Это просто библиотека пользовательского уровня, и чудес она тоже не делает. Избавить от архитектурных ограничений она не сможет.
Serge3leo
18.02.2019 04:27Хм.
Типа у процессоров x86 нет команд LFENCE/SFENCE/MFENCE ?! Или что?то тот же memory_order_acquire не насилует и не блокирует «шину», даже если она существует.
К процессорам x86 это вообще никак не относится, не вводите людей в заблуждение.
В смысле «насилия над „шиной“», то конкретно у Intel работает протокол синхронизации кэш и активное ожидание установки переменной путём её чтения совершенно не тормозит другие ядра и/или процессоры. Другое дело, что эффективная работа с такой переменой предполагает использование std::memory_order_acquire и соответствующей инструкции.
Это альтернатива NOP, просто более эффективная. Чудес она не делает.
А нам и не нужны чудеса. Протокол синхронизации кэш обеспечивает, что код на других ядрах/процессора не тормозится, а PAUSE обеспечивает, что соседний(-ие) HT не практически не замедляются.
Как бы, во-первых, мне известны процессоры на которых они доступны в пользовательском режиме. И, во-вторых, будут новые ж.есть ещё MONITOR/MWAIT для энергоэффективной и быстрой реализации спинлоков
Эти операции недоступны в пользовательском режиме. ...
… А переключаться в ядро — терять драгоценные наносекунды.
Как бы пул рабочих потоков на котором основан Grand Central Dispatch без поддержки ядра ОС не особо осмыслен. И он таковую имеет.
… Это просто библиотека пользовательского уровня, и чудес она тоже не делает. Избавить от архитектурных ограничений она не сможет.
А в части MONITOR/MWAIT, для процессоров в которых они не поддерживаются на пользовательском уровне (или не имеют аналогичных инструкции). Да таких большинство, но Вы преувеличиваете накладные на выход из системного вызова, который использует MONITOR/MWAIT. А спусковой флаг для них можно поднять в пользовательском пространстве ж ;)DistortNeo
18.02.2019 10:02Типа у процессоров x86 нет команд LFENCE/SFENCE/MFENCE ?! Или что?
Есть, но практического смысла в них нет, т.к. в x86 процессорах операции чтения-записи уже упорядочены.
то конкретно у Intel работает протокол синхронизации кэш и активное ожидание установки переменной путём её чтения совершенно не тормозит другие ядра и/или процессоры
Да, не тормозит, но и не блещет производительностью. Одна итерация пинг-понга с другим потоком, в бесконечном цикле копирующем содержимое переменной, у меня занимает 75-90 нс. Это в несколько раз дольше, чем через атомарную операцию. С другой стороны, при большом числе потоков это может дать выигрыш.
Да таких большинство, но Вы преувеличиваете накладные на выход из системного вызова, который использует MONITOR/MWAIT.
В контекте параллельной обработки массива всего из 1024 ячеек — не думаю, что преувеличиваю.
Как бы пул рабочих потоков на котором основан Grand Central Dispatch без поддержки ядра ОС не особо осмыслен. И он таковую имеет.
Тогда, возможно, эта штука представляет интерес. Но, опять же, вы не сможете преодолеть архитектурные ограничения по обмену данными между ядрами.
picul
18.02.2019 14:26Есть, но практического смысла в них нет, т.к. в x86 процессорах операции чтения-записи уже упорядочены.
Эмм, нет. x86 запросто реордерит операции с памятью на уровне процессора, и в реализации многопоточных структур данных эти инструкции необходимы.DistortNeo
18.02.2019 15:04
Если вы для ускорения работы с памятью используете MOVNT*-инструкции, то вам действительно нужно использовать барьеры. В остальных случаях — нет.
picul
18.02.2019 16:02Там написано следующее:
Reads may be reordered with older writes to different locations
Так что реордер все таки есть.
Но я честно говоря думал что load/load и store/store тоже могут реордериться, так что спасибо за прояснение.DistortNeo
18.02.2019 17:11Именно что "… to different locations ..."
То есть побочные эффекты от этого реордера мы не увидим.picul
18.02.2019 18:01preshing.com/20120515/memory-reordering-caught-in-the-act
Тут описано, как можно ощутить этот эффект. Но с тем, что это очень нечастый случай, я согласен.
khim
18.02.2019 18:04Там забавная история. Интел пишет что-то типа такого в своих мануалах: «в существующих процессорах перестановок нет, но в будущем они возможны, так что пишите так, чтобы они не влияли». Давно уже пишет. Лет 15, наверное. Потому что заработчикам ПО на проблемы разработчиков процессора плевать — и они пишут, часто полагаясь не то, что перестановок нет.
За исключением библиотек, поддерживающих мобильник и, соответственно, ARM…
0xtcnonr
18.02.2019 00:57атомарные операции блокируют шину
Какую шину?
То есть один поток зависнет на одной операции на 5 нс, два потока — по 10 нс каждый и т.д.
Почему?
итого +40 нс на накладные расходы в идеальном случае.
Не воспроизводится, вот бенчмарк:
#include <atomic> #include <chrono> #include <thread> constexpr auto n = 1e9; std::atomic<size_t> an = n; namespace chrono = std::chrono; auto start = chrono::high_resolution_clock::now(); void stop() { auto time = chrono::nanoseconds(chrono::high_resolution_clock::now() - start).count(); fprintf(stderr, "%fns/dec\n", time / n); std::exit(0); } void work() { while(true) { if(!an--) stop(); } } int main(int argc, char * argv[]) { size_t threads = (argv[1]) ? std::stoul(argv[1]): 1; while(--threads) std::thread{work}.detach(); work(); }
DistortNeo
18.02.2019 01:32Почему?
Потому что количество атомарных операций пропорционально числу потоков, которым делегируется выполнение задачи. Но несколько атомарных операций параллельно выполняться не может, они выстроятся в очередь.
Какую шину?
См. мануал по префиксу LOCK.
Не воспроизводится, вот бенчмарк:
А вот результат:
F:\Projects\Other\AtomicTest\Release>AtomicTest.exe 5.768351ns/dec F:\Projects\Other\AtomicTest\Release>AtomicTest.exe 2 20.703706ns/dec F:\Projects\Other\AtomicTest\Release>AtomicTest.exe 3 21.045200ns/dec F:\Projects\Other\AtomicTest\Release>AtomicTest.exe 4 21.267553ns/dec
Всё воспроизводится. Вне зависимости от числа потоков время на одну атомарную операцию увеличивается, либо остаётся тем же. Если у нас 3 потока — первый увидит задание через 20 нс, второй — через 40 нс, третий — через 60 нс и т.д. А потом ещё собирать статус об завершении выполнения заданий. Но тут одновременного завершения не будет, поэтому все скорее всего попадут на 5 нс.
JekaMas
18.02.2019 02:14А зачем в этом примере атомарные операции? Мы можем свести все к map-reduce, пусть каждый поток получает свою сумму и затем складываем полученные суммы.
DistortNeo
18.02.2019 02:47А зачем в этом примере атомарные операции?
Для синхронизации между потоками. Откуда потоки узнают, что им пришла задача? Откуда главный поток узнает, что потоки завершили выполнение задачи?
0xtcnonr
18.02.2019 04:15Потому что количество атомарных операций пропорционально числу потоков, которым делегируется выполнение задачи. Но несколько атомарных операций параллельно выполняться не может, они выстроятся в очередь.
В очередь/не очередь — это ничего не меняет, ведь никто не говорил про параллельность. Вы говорили о замедлении, а из очереди замедление никак не следует. К тому же, откуда взялась эта очередь? Пруфы так и не появились.
См. мануал по префиксу LOCK.
От 386го(судя по «шина» — это действительно так)? Можно ссылку?
Всё воспроизводится.
Где? То, что там 6нс — это просто оно долбит в l1d. Это очевидно поведение, чем дальше оно изменяет данные — тем дальше происходит инвалидация. Но всё это к делу не относится.
Вне зависимости от числа потоков время на одну атомарную операцию увеличивается, либо остаётся тем же.
Где у вас было про «остаётся», покажите? Или это попытка задним числом подменить тезис?
Если у нас 3 потока — первый увидит задание через 20 нс, второй — через 40 нс, третий — через 60 нс и т.д. А потом ещё собирать статус об завершении выполнения заданий. Но тут одновременного завершения не будет, поэтому все скорее всего попадут на 5 нс.
У нас три потока. Замедления не обнаружено(вернее не замедления, а линейное падение производительности в зависимости от кол-ва потоков).
В любом случае, всё это выглядит как бред. Что такое 3 потока? Каким образом это на что-то влияет? А если у нас будет 3 потока и три атомика?
В любом случае, эта гипотеза уже была разоблачена выше, т.к. в этом бенчмарке атомик шарит множество тредов и никакой нелепой очереди вида «обновили значение в одном потоке, обновили в другом» — тут нет и не будет. Это базовая семантика атомика — он лишь обновляет ближайшую общую память, а далее ничего никуда не блокируется, а обновляется базовыми механизмами обеспечения когерентности.
DistortNeo
18.02.2019 10:16В очередь/не очередь — это ничего не меняет, ведь никто не говорил про параллельность.
Посмотрите, с чего ветка комментариев началась.
А если у нас будет 3 потока и три атомика?
В этом случае проблем быть не должно, но надо смотреть поведение на различных процессорах. В моём случае при работе с независимыми атомиками в 4 потока уходит по 6 нс на каждый.
marsianin
18.02.2019 11:22LOCK действительно может блокировать шину. Но только если память некэшируемая (чего в прикладном софте не будет), а также если обращение пересекает границу кэшлайна (не бывает в коде на C). А в случае кэшируемой памяти и выровненного обращения в операциях read-modify-write блокируется только кэшлайн, и всё работает на механизмах обеспечения когерентности.
Serge3leo
17.02.2019 21:34+1P.S. Конечно, есть на ноутбуках и AVX/AVX2, но что б за это не думать за возможности конкретного процессорв, у всех компиляторов от clang, до IBM, кроме оптимизаторов/векторизаторов есть ещё и векторные типы а ля OpenC, как расширения языка C.
Типа vector a;… a += (b > c);
P.P.S.
Код ваших примеров немного неоптимален. Ясное дело, popcnt в каждом итерации не нужен же, дешевле суммировать вектора.

amarao
17.02.2019 21:51Чисто формально вы ещё не исчерпали алгоритмические возможности для классических инструкций. Как насчёт того, чтобы грузить int64 и делать сдвиги и сравнение?
Serge3leo
17.02.2019 22:02Месье знает толк в извращениях.
Только если подсчитывать число равных v размера 16-бит в массиве, приводимому к int64_t, то на итерации достаточно одного XOR, четырёх масок и четырёх условных суммирований.
gchebanov
17.02.2019 22:23Что за условное суммирование? У меня векторное решение, но тут log(16bit) >= общему числу элементов в пачке. Странно что даже такая лапша обгоняет тупой иф.
BenchmarkBenchmark Time CPU Iterations ------------------------------------------------------------ BM_Count 211 ns 210 ns 3313500 BM_ShiftCount 100 ns 99 ns 7066068 BM_SSE_COUNT_SET_EPI 83 ns 83 ns 8598664 BM_SSE_COUNT_LOADU 57 ns 57 ns 122654240xtcnonr
17.02.2019 23:33+1Всё это бесполезно, симдовое cmp намного мощнее. Что угодно там колхозь — даже на 64 битных симдах оно будет быстрее.

Antervis
18.02.2019 11:22ускорять код функции с с константными входами это не академично.
А еще, ты несколько недоработал алгоритм. Зачем делать через movemask + popcnt? Для массивов не более 2^18 элементов можно сначала собирать поэлементную сумму:
auto cmp = _mm_cmpeq_epi16(sseVal, sseArr); cmp = _mm_and_si128(cmp, _mm_set1_epi16(1)); sum = _mm_add_epi16(sum, cmp);
а потом, в конце цикла, сделать одно горизонтальное сложение (не забывая про переполнение).
SerKOS
18.02.2019 11:42Добрый день, я рекомендовал бы посмотреть в сторону openmp, прагма #pragma omp simd
Код будет переносимым, трудозатрат меньше, результат обычно такой же0xtcnonr
18.02.2019 19:27трудозатрат меньше, результат обычно такой же
Там 4 строчки кода(пишется за пару минут), можете продемонстрировать «сторону openmp»?SerKOS
18.02.2019 21:28#pragma omp simd reduction (+:count) for (int i = 0; i < N; i++) { if (a[i] == 42) count++; }0xtcnonr
18.02.2019 22:01Чуда не произошло — это самое медленное решение из всех, хуже обычного во много раз.
Шланг написал:
warning: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Wpass-failed=transform-warning]
Судя по выхлопу gcc — он тоже не смог ничего векторизовать, но почему-то об этом не сообщил.SerKOS
18.02.2019 22:22+1Версия g++ 7.3.0
g++ -O3 -fopenmp main.cpp
Все работает и векторизуется0xtcnonr
18.02.2019 22:30Где? godbolt.org/z/TXSP_d
Kobalt_x
19.02.2019 08:25справедливости ради в icc godbolt.org/z/iSxOm0
и clang 7 всё векторизуется
godbolt.org/z/oruzkO и warningов как вы привели выше нет.0xtcnonr
19.02.2019 09:58справедливости ради в icc godbolt.org/z/iSxOm0
Я не вижу тут векторизации.
и clang 7 всё векторизуется
Действительно, в 7 шланге работает, даже в их транковом работает. В моём не работает. godbolt.org/z/usAV3s — тут(восьмая версия) аналогичная проблема. Значит где-то они что-то сломали.
Так же, если переписать цикл нормально:
cnt += (arr[i] == VAL);
Сразу заработала автовекторизация в шланге, а в gcc заработал openmp.
В любом случае — качество этой векторизации не особо высокое.
nizsheanez
Что мешает -О3 дооптимизировать до одинаковых таймингов?
svistunov Автор
Например в варианте BM_SSE_COUNT_LOADU компилятор дополнительно раскрывает цикл на 4 итерации, но не делает это для BM_SSE_COUNT_SET_EPI.
nizsheanez
Понятно что получается разный асемблер. Вопрос — почему он разный. Компилятор «не додумался» или вы «не учли краевой случай который компилятор учел».
khim
Можно посмотреть, но, скорее всего, компилятор увидел число итераций, «понял», что ему придётся в дополнение к развёрнутому циклу ещё сделать пролог и эпилог большей (для обработки не выровнянного случая) и решил, что «овчинка выделки не стоит».
Векторизация и loop unrolling — это пока ближе к чёрной магии, чем к науке. Там тонны эвристик…