
На простом решении Юрий не остановился, а дополнительно провел доклад, в котором раскрыл тему понятия «деплой кода», рассказал про классические и альтернативные решения масштабного деплоя кода на PHP, проанализировал их производительность и презентовал самописную систему деплоя MDK.
Понятие «деплой кода»
В английском языке термин «deploy» означает приведение войск в состояние боевой готовности, а по-русски мы иногда говорим «залить код в бой», что означает то же самое. Вы берете код в уже скомпилированном или в исходном, если это PHP, виде, загружаете на серверы, которые обслуживают пользовательский трафик, и после, магией каким-то образом, переключаете нагрузку с одной версии кода на другую. Все это входит в понятие «деплой кода».
Процесс деплоя обычно состоит из нескольких этапов.
- Получение кода из репозитория, каким угодно способом: clone, fetch, checkout.
- Сборка — build. Для PHP-кода фаза сборки может отсутствовать. В нашем случае это, как правило, автогенерация файлов переводов, заливка статических файлов на CDN и некоторые другие операции.
- Доставка на конечные серверы — deployment.
После того, как все собрано, наступает фаза непосредственно деплоя — заливка кода на продакшн-серверы. Именно об этой фазе на примере Badoo и пойдет речь.
Старая система деплоя в Badoo
Если у вас есть файл с образом файловой системы, то как его смонтировать? В Linux нужно создать промежуточное Loop-устройство, привязать к нему файл, и после этого уже это блочное устройство можно смонтировать.
Loop-устройство — это костыль, который нужен в Linux, чтобы смонтировать образ файловой системы. Есть ОС, в которых этот костыль не требуется.

Как происходит процесс деплоя с помощью файлов, которые мы тоже называем для простоты «лупами»? Есть директория, в которой находится исходный код и автоматически сгенерированное содержимое. Берем пустой образ файловой системы — сейчас это EXT2, а раньше мы использовали ReiserFS. Монтируем пустой образ файловой системы во временную директорию, копируем туда все содержимое. Если нам не нужно, чтобы на продакшн что-то попадало, то копируем не все. После этого размонтируем устройство, и получаем образ файловой системы, в котором находятся нужные файлы. Дальше архивируем образ и заливаем на все серверы, там разархивируем и монтируем.
Другие существующие решения
Для начала давайте поблагодарим Ричарда Столмана — без его лицензии не существовало бы большинства утилит, которые мы используем.

Способы деплоя PHP-кода я условно разделил на 4 категории.
- На основе системы контроля версий: svn up, git pull, hg up.
- На основе утилиты rsync — в новую директорию или «поверх».
- Деплой одним файлом — не важно каким: phar, hhbc, loop.
- Специальный способ, который подсказал Расмус Лердорф — rsync, 2 директории и realpath_root.
У каждого способа есть как плюсы, так и минусы, из-за которых мы от них отказались. Рассмотрим эти 4 способа подробнее.
Деплой на основе системы контроля версий svn up
Я выбрал SVN не случайно — по моим наблюдениям, в таком виде деплой существует именно в случае SVN. Система достаточно легковесная, позволяет легко и быстро провести деплой — просто запускаете svn up и всё готово.
Но у этого способа есть один большой минус: если вы делаете svn up, и в процессе обновления исходного кода, когда из репозитория приходят новые запросы, они будут видеть состояние файловой системы, которой не существовало в репозитории. У вас будет часть файлов новых, а часть старых — это неатомарный способ деплоя, который не подходит для высокой нагрузки, а только для небольших проектов. Несмотря на это, я знаю проекты, которые все равно так деплоятся, и у них пока все работает.
Деплой на основе утилиты rsync
Есть два варианта, как это сделать: заливать файлы с помощью утилиты напрямую на сервер и заливать «поверх» — обновлять.
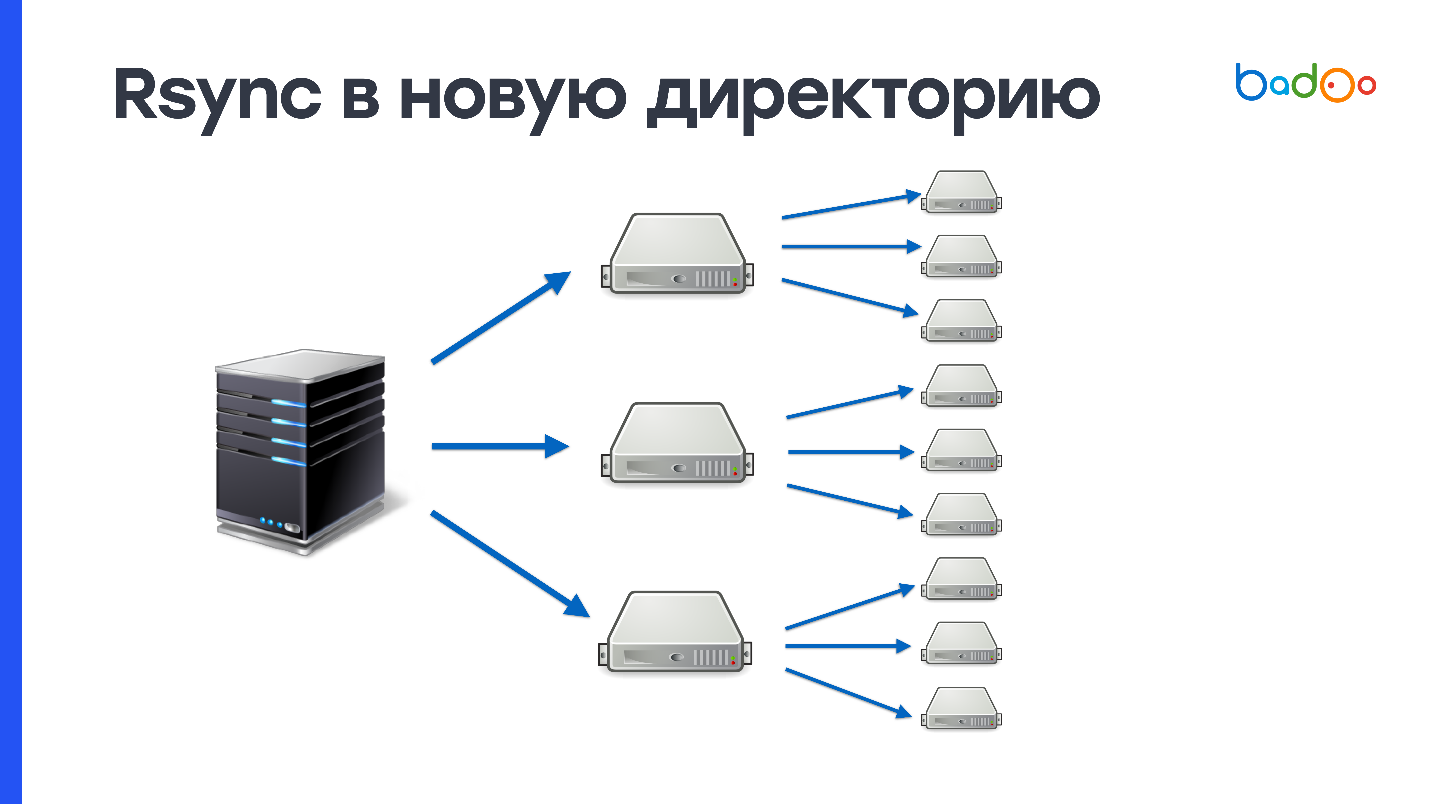
rsync в новую директорию
Поскольку вы сначала целиком заливаете весь код в директорию, которой еще не существует на сервере, и только потом переключаете трафик, этот способ атомарный — никто не видит промежуточного состояния. В нашем случае создание 150 000 файлов и удаление старой директории, в которой тоже 150 000 файлов, создает большую нагрузку на дисковую подсистему. У нас весьма активно используются жесткие диски, и сервер где-то в течение минуты не очень хорошо себя чувствует после такой операции. Поскольку у нас 2000 серверов, то требуется 2000 раз залить 900 Мб.
Эту схему можно улучшить, если сначала залить на какое-то количество промежуточных серверов, например, 50, и потом уже с них доливать на остальные. Так решаются возможные проблемы с сетью, но проблема создания и удаления огромного количества файлов никуда не исчезает.
rsync «поверх»
Если вы использовали rsync, то знаете, что эта утилита умеет не только заливать директории целиком, но и обновлять существующие. Отправка только изменений — это плюс, но поскольку мы заливаем изменения в ту же самую директорию, в которой обслуживаем боевой код, то там тоже будет существовать какое-то промежуточное состояние — это минус.
Отправка изменений работает так. Rsync составляет списки файлов на стороне сервера, с которого осуществляется деплой, и на принимающей стороне. После этого считает stat от всех файлов и отправляет весь список на принимающую сторону. На сервере, с которого идет деплой, считается разница между этими значениями, и определяется, какие файлы нужно послать.
В наших условиях на этот процесс уходит примерно 3 Мб трафика и 1 секунда процессорного времени. Кажется, что это немного, но у нас 2000 серверов, и на все получается не меньше одной минуты процессорного времени. Не такой уж это и быстрый способ, но однозначно лучше, чем отправка целиком через rsync. Осталось как-то решить проблему с атомарностью и будет почти идеально.
Деплой одним файлом
Какой бы одиночный файл вы бы не заливали, это относительно просто сделать с помощью BitTorrent или утилиты UFTP. Один файл проще распаковать, можно атомарно заменить в Unix, и легко проверить целостность файла, сгенерированого на билд-сервере и доставленного на конечные машины, посчитав MD5 или SHA-1 суммы от файла (в случае rsync вы не знаете, что находится на конечных серверах).
Для жестких дисков последовательная запись это большой плюс — на незанятый винчестер файл на 900 Мб запишется за время порядка 10 секунд. Но все равно нужно записывать эти самые 900 Мб и передавать их по сети.
Лирическое отступление про UFTP
Эта Open Source утилита изначально создавалась для передачи файлов по сети с большими задержками, например, через сеть на основе спутниковой связи. Но UFTP оказалась пригодной и для заливки файлов на большое количество машин, потому что работает по протоколу UDP на основе Multicast. Создается один Multicast-адрес, на него подписываются все машины, которые хотят получить файл, и свичами обеспечивается доставка копий пакетов на каждую машину. Так мы перекладываем нагрузку по передаче данных на сеть. Если ваша сеть это выдержит, то этот способ работает намного лучше, чем BitTorrent.
Вы можете попробовать эту Open Source утилиту у себя на кластере. Несмотря на то, что она работает по протоколу UDP, у нее есть механизм NACK — negative acknowledgement, который заставляет переотправлять потерянные при доставке пакеты. Это надежный способ деплоя.
Варианты деплоя одним файлом
tar.gz
Вариант, который сочетает в себе недостатки обоих подходов. Мало того, что вы должны записать 900 Мб на диск последовательно, после этого вам нужно случайным чтением-записью еще раз записать те же 900 Мб и создать 150 000 файлов. По производительности этот способ еще хуже, чем rsync.
phar
PHP поддерживает архивы в формате phar (PHP Archive), умеет отдавать их содержимое и инклюдить файлы. Но не все проекты легко поместить в один phar — нужна адаптация кода. Просто так код из этого архива не заработает. Кроме того, в архиве нельзя поменять один файл (Юрий из будущего: в теории все-таки можно), требуется перезалить архив целиком. Также несмотря на то, что phar-архивы работают с OPCache, при деплое кеш нужно сбрасывать, потому что иначе будет оставаться мусор в OPCache от старого phar-файла.
hhbc
Этот способ нативен для HHVM — HipHop Virtual Machine и его использует Facebook. Это что-то вроде phar-архива, но в нем лежат не исходные коды, а скомпилированный байт-код виртуальной машины HHVM — интерпретатора PHP от Facebook. В этом файле запрещено что-либо менять: нельзя создавать новые классы, функции и некоторые другие динамические возможности в этом режиме отключены. За счет этих ограничений виртуальная машина может использовать дополнительные оптимизации. Как утверждает Facebook, это может принести до 30% к скорости исполнения кода. Наверное, для них это хороший вариант. Здесь также нельзя поменять один файл (Юрий из будущего: на самом деле можно, потому что это sqlite-база). Если вы хотите поменять одну строчку, нужно передеплоить весь архив заново.
Для этого способа запрещено использовать eval и динамические include. Это так, но не совсем. Eval использовать можно, но если он не создает новые классы или функции, а include нельзя делать из директорий, которые находятся вне этого архива.
loop
Это наш старый вариант, и у него есть два больших преимущества. Первое — он выглядит, как обычная директория. Вы монтируете loop, и для кода все равно — он работает с файлами, как на develop-окружении, так и на production-окружении. Второе — loop можно смонтировать в режиме чтения и записи, и поменять один файл, если нужно все-таки что-то срочно поменять на продакшн.
Но у loop есть минусы. Первый — он странно работает с docker. Об этом расскажу чуть позже.
Второй — если вы используете symlink на последний loop в качестве document_root, то у вас возникнут проблемы с OPCache. Он не очень хорошо относится к наличию symlink в пути, и начинает путать, какие версии файлов нужно использовать. Поэтому OPCache приходится сбрасывать при деплое.
Еще проблема — требуются привилегии суперпользователя, чтобы монтировать файловые системы. И нужно не забывать их монтировать при старте/рестарте машины, потому что иначе будет пустая директория вместо кода.
Проблемы с docker
Если вы создаете docker-контейнер и пробрасываете внутрь него папку, в которой смонтированы «лупы» или другие блочные устройства, то возникает сразу две проблемы: новые точки монтирования внутрь docker-контейнера не попадают, и те «лупы», которые находились на момент создания docker-контейнера, нельзя отмонтировать, потому что они заняты docker-контейнером.
Естественно, это вообще несовместимо с деплоем, потому что количество loop-устройств ограничено, и непонятно, как новый код должен попадать в контейнер.
Мы пробовали делать странные вещи, например, поднимать локальный NFS-сервер или монтировать директорию по SSHFS, но у нас это по разным причинам не прижилось. В результате в cron мы прописали rsync от последнего «лупа» в настоящую директорию, и она раз в минуту выполняла команду:
rsync /var/loop/<N>/ /var/www/Здесь
/var/www/ — это директория, которая продвинута в контейнер. Но на машинах, где есть docker-контейнеры, нам не нужно часто запускать PHP-скрипты, поэтому то, что rsync неатомарный, нас устраивало. Но все равно этот способ очень плохой, конечно. Хотелось бы сделать систему деплоя, которая хорошо работает с docker.rsync, 2 директории и realpath_root
Этот способ предложил Расмус Лердорф, автор PHP, а он-то знает, как деплоить.
Как сделать атомарный деплой, причем в любом из способов, о которых я рассказал? Берете symlink и прописываете его в качестве document_root. В каждый момент времени symlink указывает на одну из двух директорий, и вы делаете rsync в соседнюю директорию, то есть в ту, в которую код не указывает.
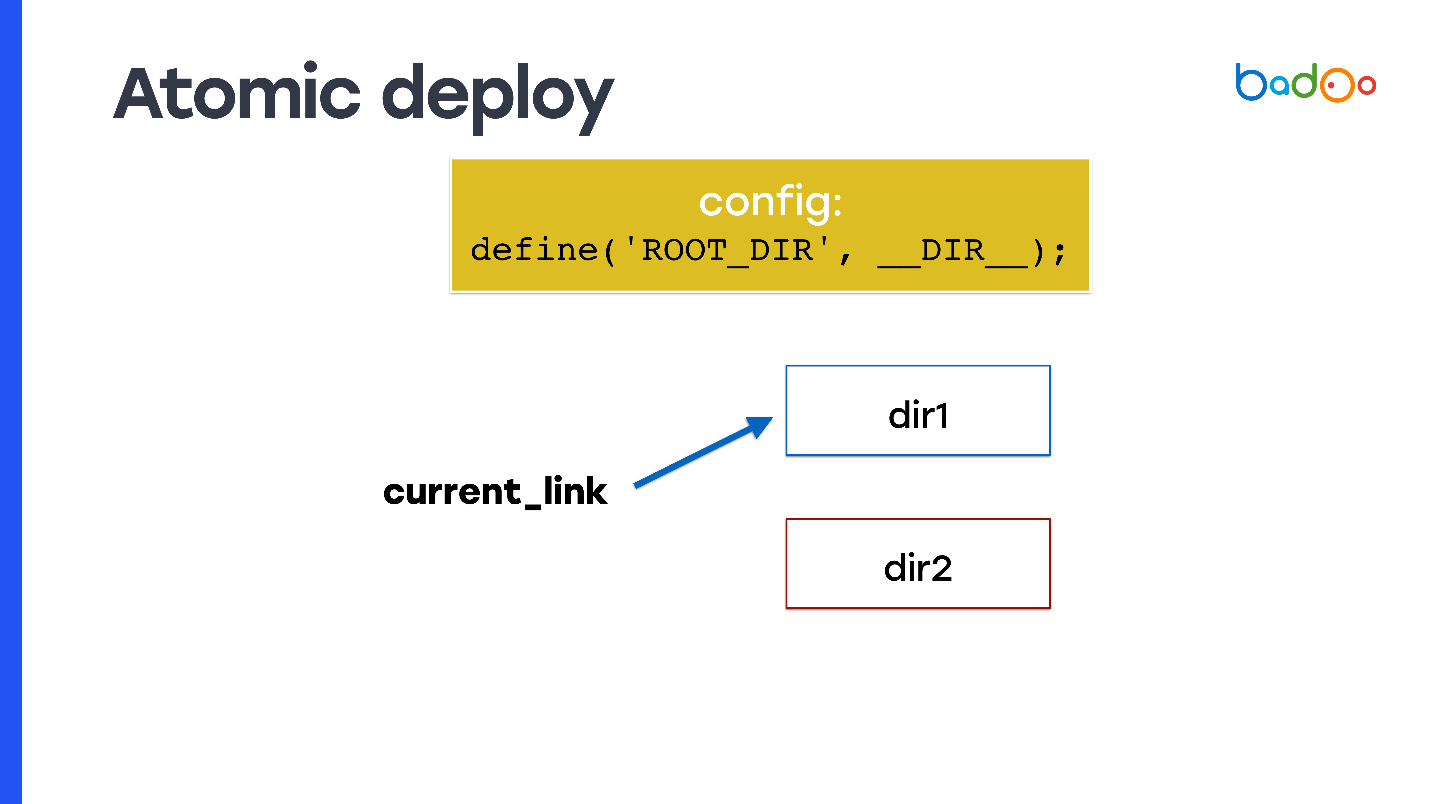
Но возникает проблема: PHP-код не знает, в какой из директорий он был запущен. Поэтому вам нужно использовать, например, переменную, которую вы пропишете где-нибудь в начале в config — она будет фиксировать, из какой директории был запущен код, и из какой нужно инклюдить новые файлы. На слайде она называется
ROOT_DIR.Используйте эту константу при обращении ко всем файлам внутри кода, который вы используете на продакшне. Так вы получите свойство атомарности: запросы, которые приходят до того, как вы переключили symlink, продолжают инклюдить файлы из старой директории, в которой вы ничего не меняли, а новые запросы, которые пришли уже после переключения symlink, начинают работать из новой директории и обслуживаться новым кодом.

Но это нужно прописывать в коде. Не все проекты к этому готовы.
Rasmus-style
Расмус предлагает вместо ручной модификации кода и создания констант немножко модифицировать Apache или же использовать nginx.
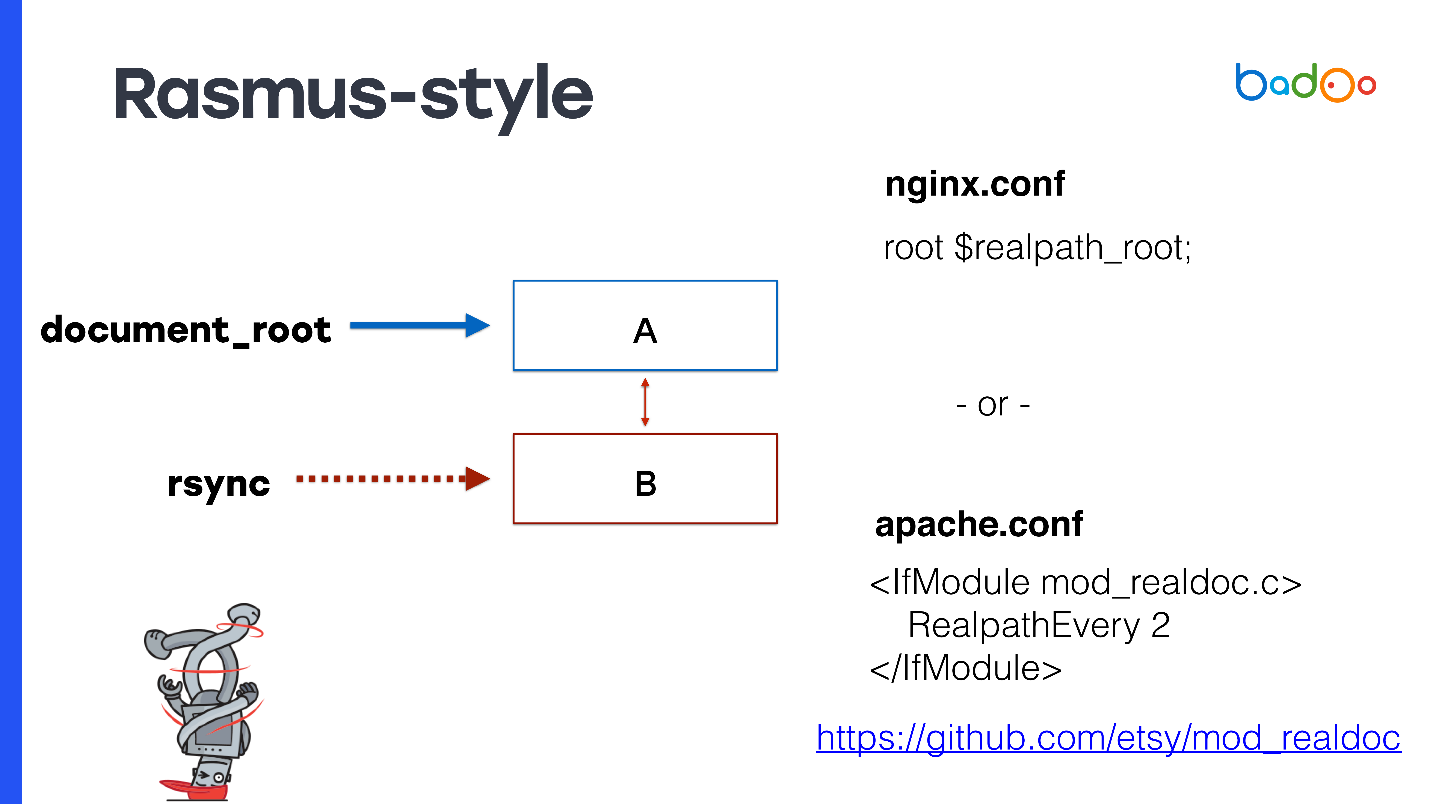
В качестве document_root указываете симлинк на последнюю версию. Если у вас nginx, то можно прописать
root $realpath_root, для Apache потребуется отдельный модуль с настройками, которые можно видеть на слайде. Это работает так — когда приходит запрос, nginx или Apache раз в какое-то время считают realpath() от пути, избавляя его от симлинков, и передают этот путь в качестве document_root. В этом случае document_root будет всегда указывать на обычную директорию без симлинков, и ваш PHP-код может не задумываться о том, из какой директории его вызывают.У этого способа интересные плюсы — в OPCache PHP приходят уже настоящие пути, они не содержат symlink. Даже самый первый файл, на который пришел запрос, уже будет полноценным, и не будет никаких проблем с OPCache. Поскольку используется document_root, то это работает с любым PHP-проектом. Вам не нужно ничего адаптировать.
Не требуется fpm reload, не нужно сбрасывать OPCache при деплое, из-за чего сильно нагружается сервер процессора, потому что должен распарсить все файлы заново. В моем эксперименте сброс OPCache примерно на полминуты повышал потребление процессора в 2-3 раза. Хорошо бы его переиспользовать и этот способ позволяет это делать.
Теперь минусы. Поскольку вы не переиспользуете OPCache, и у вас 2 директории, то нужно хранить по копии файла в памяти под каждую директорию — под OPCache требуется в 2 раза больше памяти.
Есть еще ограничение, которое может показаться странным — нельзя деплоиться чаще, чем раз в max_execution_time. Иначе будет та же проблема, потому что пока идет rsync в одну из директорий, еще могут обрабатываться запросы из нее.
Если вы используете Apache по какой-то причине, то нужен сторонний модуль, который также написал Расмус.
Расмус говорит, что система хороша и я тоже её вам рекомендую. Для 99% проектов она подойдет, причём как для новых проектов, так и для существующих. Но, конечно же, мы не такие и решили написать своё решение.
Новая система — MDK
В основном наши требования ничем не отличаются от требований для большинства веб-проектов. Мы всего лишь хотим быстрый деплой на стэйджинге и продакшн, малое потребление ресурсов, переиспользование OPCache и быстрый откат.
Но есть еще два требования, которые, возможно, отличаются от остальных. Прежде всего это возможность применять патчи атомарно. Патчами мы называем изменения в одном или нескольких файлах, которые что-то правят на продакшене. Мы хотим это делать быстро. В принципе, с задачей патчей система, которую предлагает Расмус, справляется.
Также у нас есть CLI-скрипты, которые могут работать по несколько часов, и они все равно должны работать с консистентной версией кода. В таком случае приведенные решения, к сожалению, нам либо не подходят, либо мы должны иметь очень много директорий.
Возможные решения:
- loop xN (-staging, -docker, -opcache);
- rsync xN (-production, -opcache xN);
- SVN xN (-production, -opcache xN).
Здесь N — это количество выкладок, которые происходят за несколько часов. У нас их может быть десятки, что означает необходимость расходовать очень большое количество места под дополнительные копии кода.
Поэтому мы придумали новую систему и назвали ее MDK. Расшифровывается как Multiversion Deployment Kit — многоверсионный инструмент для деплоя. Мы его сделали, исходя из следующих предпосылок.
Взяли архитектуру хранения деревьев из Git. Нам же нужно иметь консистентную версию кода, в которой работает скрипт, то есть нужны снапшоты. Снапшоты поддерживаются LVM, но там они реализованы неэффективно, экспериментальными файловыми системами, наподобие Btrfs и Git. Мы взяли реализацию снапшотов из Git.
Переименовали все файлы из file.php в file.php.<version>. Поскольку все файлы у нас хранятся просто на диске, то если мы хотим хранить несколько версий одного и того же файла, должны добавить суффикс с версией.
Я люблю Go, поэтому для скорости написали систему на Go.
Как работает Multiversion Deployment Kit
Мы взяли идею снапшотов у Git. Я ее немножко упростил и расскажу, как она реализована в MDK.
В MDK есть два типа файлов. Первый — карты. На картинках ниже обозначены зеленым и соответствуют директориям в репозитории. Второй тип - непосредственно файлы, которые лежат там же, где и обычно, но с суффиксом в виде версии файла. Файлы и карты версионируются на основании их содержимого, в нашем случае просто MD5.
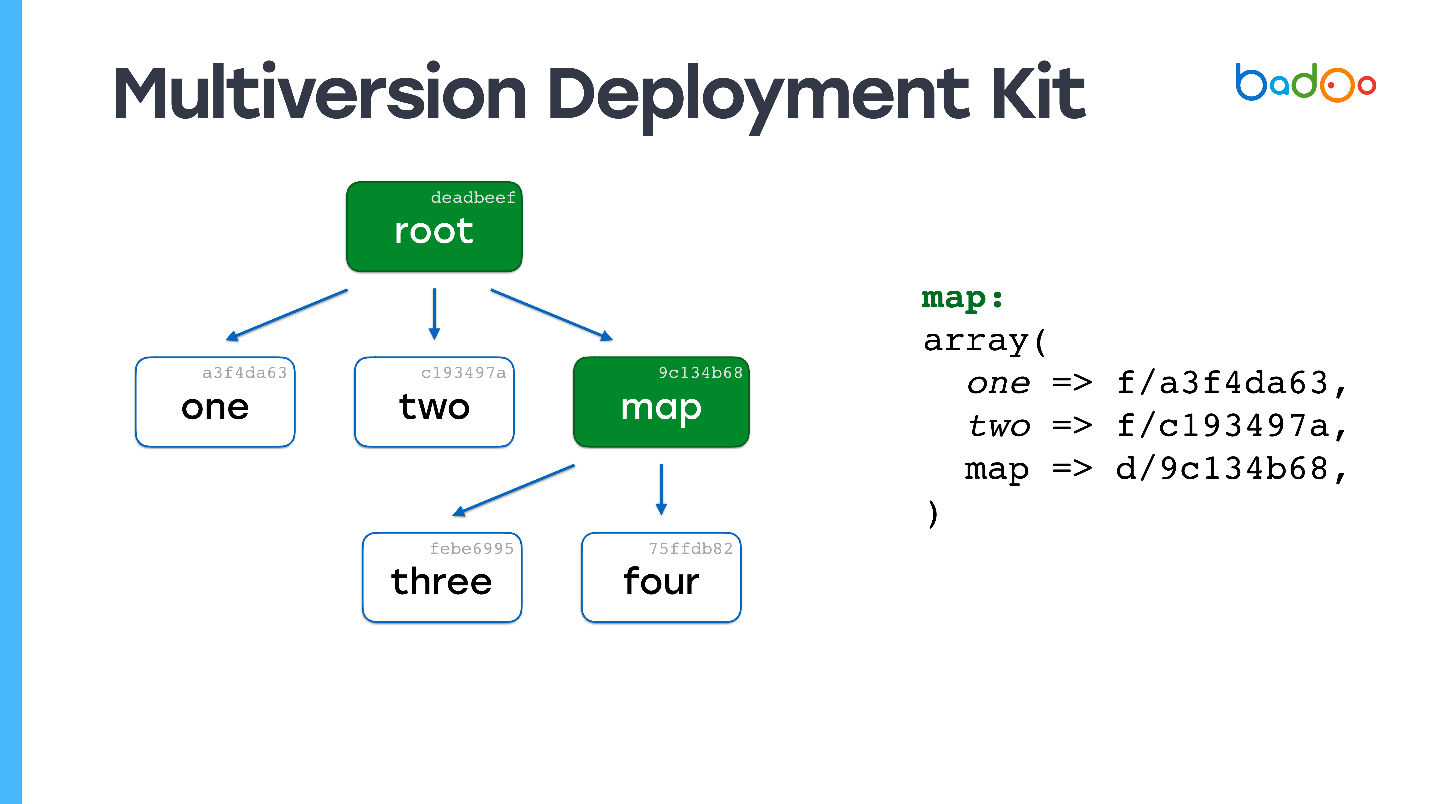
Допустим, у нас есть некоторая иерархия файлов, в которой корневая карта ссылается на определенные версии файлов из других карт, а они, в свою очередь, ссылаются на другие файлы и карты, и фиксируют определенные версии. Мы хотим поменять какой-то файл.

Возможно, вы уже видели подобную картинку: меняем файл на втором уровне вложенности, и в соответствующей карте — map*, обновляется версия файла three*, модифицируется ее содержимое, меняется версия — и в корневой карте тоже меняется версия. Если мы что-то меняем, то получаем всегда новую корневую карту, но все файлы, которые мы не меняли переиспользуются.
Ссылки остаются на те же файлы, что и были. Это основная идея создания снапшотов любым способом, например, в ZFS это реализовано примерно так же.
Как MDK лежит на диске

На диске у нас есть: symlink на самую свежую корневую карту — код, который будет обслуживаться из веба, несколько версий корневых карт, несколько файлов, возможно, с разными версиями, и во вложенных директориях лежат карты для соответствующих директорий.
Предвижу вопрос: "И как же этим обрабатывать веб-запрос? На какие файлы будет приходить пользовательский код?"
Да, я вас обманул — есть и файлы без версий, потому что если вам приходит запрос на index.php, а у вас его нет в директории, то сайт работать не будет.

У всех PHP-файлов есть файлы, которые мы называем заглушками, потому что они содержат две строчки: require от файла, в котором объявлена функция, которая умеет с этими картами работать, и require от нужной версии файла.
<?php
require_once "mdk.inc";
require mdk_resolve_path("a.php");
Сделано это так, а не симлинками на последнюю версию, потому что, если из файла a.php вы заинклюдите b.php без версии, то, поскольку написано require_once, система запомнит, с какой корневой карты она начала, будет использовать именно ее, и получать согласованную версию файлов.
Для остальных файлов у нас есть просто symlink на последнюю версию.
Как деплоить с помощью MDK
Модель очень похожа на git push.
- Посылаем содержимое корневой карты.
- На принимающей стороне смотрим, каких файлов не хватает. Поскольку версия файла определяется содержимым, нам не нужно скачивать его второй раз (Юрий из будущего: за исключением случая, когда случится коллизия укороченного MD5, что всё-таки один раз произошло в продакшене).
- Запрашиваем недостающий файл.
- Переходим ко второму пункту и дальше по кругу.
Пример
Допустим, есть файл с именем «one» на сервере. Присылаем к нему корневую карту.

В корневой карте прерывистыми стрелками отмечены ссылки на файлы, которых у нас нет. Мы знаем их имена и версии, потому что они находятся в карте. Запрашиваем их у сервера. Сервер присылает, и оказывается, что один из файлов — это тоже карта.
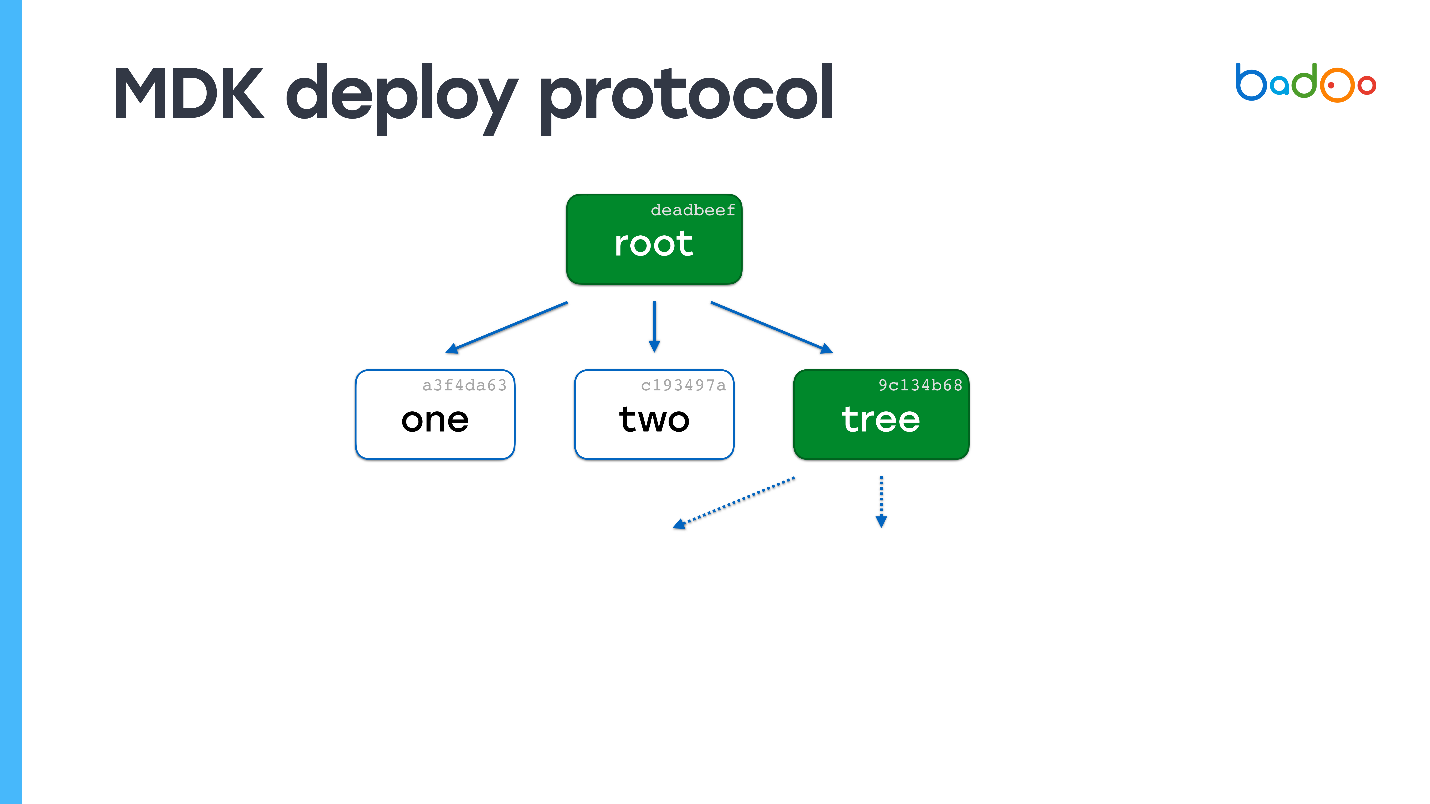
Смотрим — у нас вообще ни одного файла нет. Опять запрашиваем файлы, которых не хватает. Сервер их присылает. Больше карт не осталось — процесс деплоя завершен.
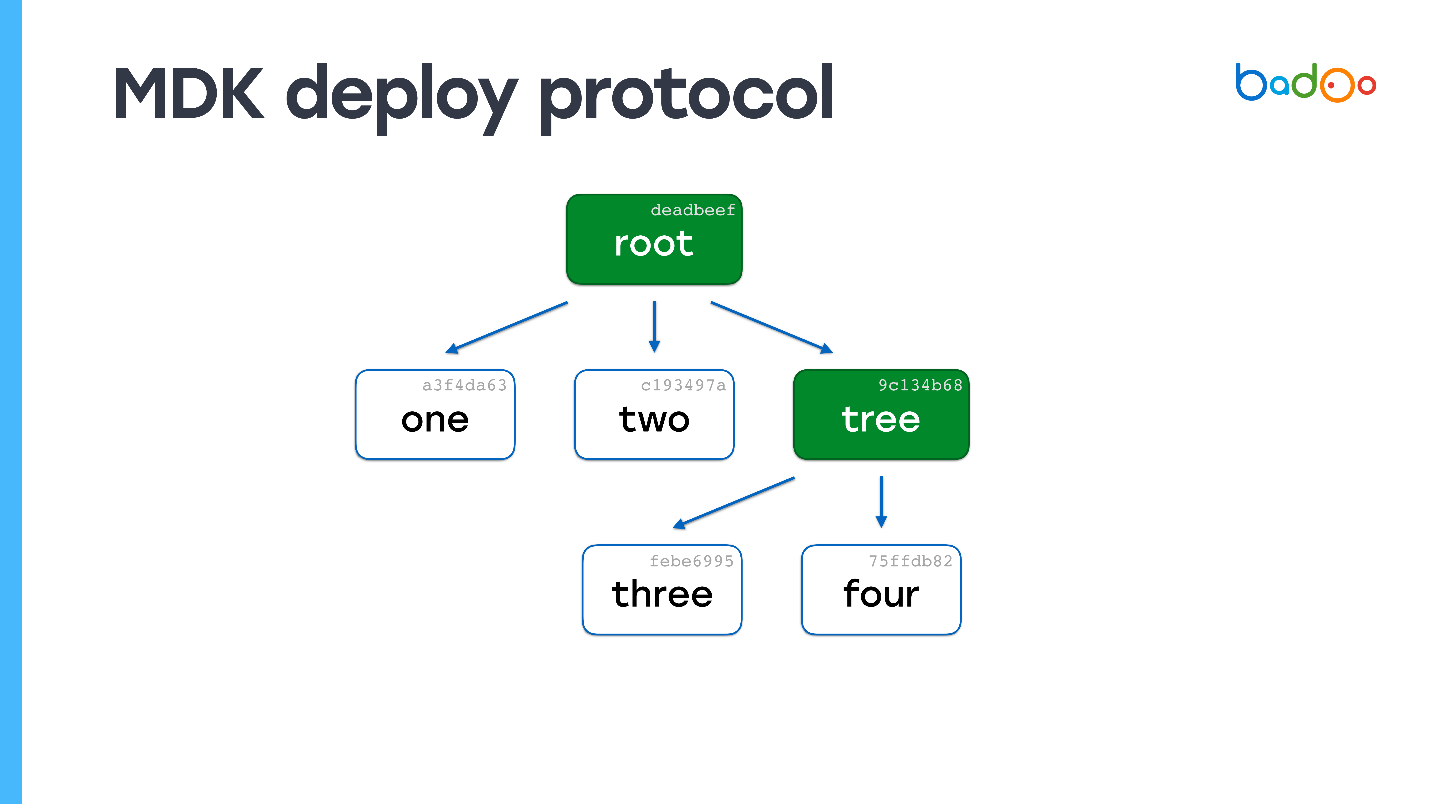
Можно легко догадаться, что будет, если файлов 150 000, а изменился один. Увидим в корневой карте что не хватает одной карты, пойдем по уровню вложенности и получим файл. По вычислительной сложности процесс почти не отличается от копирования файлов напрямую, но при этом сохраняется консистентность и снапшоты кода.
У MDK минусов нет:) Он позволяет быстро и атомарно деплоить небольшие изменения, а скриптам работать сутками, потому что мы можем оставлять все файлы, которые деплоили в течение недели. Они будут занимать вполне адекватное количество места. Также можно переиспользовать OPCache, а CPU почти ничего не ест.
Мониторить достаточно сложно, но можно. Все файлы версионируются по содержимому, и можно написать cron, который будет проходить по всем файлам и сверять имя и содержимое. Также можно проверять, что корневая карта ссылается на все файлы, что в ней нет битых ссылок. Более того, при деплое проверяется целостность.
Можно легко откатить изменения, потому что все старые карты на месте. Мы можем просто перекинуть карту, там сразу будет все что нужно.
Для меня плюс то, что MDK написана на Go — значит, быстро работает.
Я опять вас обманул, минусы все же есть. Чтобы проект работал с системой, требуется существенная модификация кода, но она проще, чем может показаться на первый взгляд. Система очень сложная, я бы не рекомендовал ее реализовывать, если у вас нет таких требований, как у Badoo. Также все равно рано или поздно кончается место, поэтому требуется Garbage Collector.
Мы написали специальные утилиты, чтобы редактировать файлы — настоящие, а не заглушки, например, mdk-vim. Вы указываете файл, она находит нужную версию и ее редактирует.
MDK в цифрах
У нас на стэйджинге 50 серверов, на которых мы деплоимся за 3-5 с. По сравнению со всем, кроме rsync, — это очень быстро. На продакшн мы деплоимся порядка 2 минут, небольшие патчи — 5-10 с.
Если вы по какой-то причине потеряли вообще всю папку с кодом на всех серверах (чего никогда не должно случиться :)) то процесс полной заливки идет около 40 минут. У нас это случилось один раз, правда ночью в минимум трафика. Поэтому никто не пострадал. Второй фейл был на паре серверов в течение 5 минут, так что это не достойно упоминания.
Система не в Open Source, но если вам интересно, то пишите в комментариях — может быть выложим (Юрий из будущего: система всё ещё не в Open Source на момент написания этой статьи).
Заключение
Слушайте Расмуса, он не врет. По моему мнению, его способ rsync совместно с realpath_root — лучший, хотя «лупы» тоже работают вполне неплохо.
Думайте головой: посмотрите то, что нужно именно вашему проекту, и не пытайтесь создать космический корабль там, где достаточно «кукурузника». Но если все-таки у вас требования похожи, то и система, похожая на MDK, вам подойдет.
Мы решили вернуться к этой теме, которая обсуждалась на HighLoad++ и, возможно, тогда не получила должного внимания, потому что была лишь одним из многих кирпичиков достижения высокой производительности. Но теперь у нас есть отдельная профессиональная конференция PHP Russia, полностью посвященная PHP. И вот тут уж оторвемся по полной. Обстоятельно поговорим и про производительность, и про стандарты, и про инструменты — много про что, включая рефакторинг.
Подпишитесь на Telegram-канал с обновлениями программы конференции, и увидимся 17 мая.
Комментарии (15)

necromant2005
29.04.2019 21:01+2Скажу просто. ТО что написано просто дичь какая-то.
1. Если деплой делать хорошо — тогда лучше blue-green выкатывая тупо новую версию сразу на виртуальные на НОВЫЕ виртуальные машины, так можно и релизить кусками (ака 1% пользователей — 10%… 100%) и так нет проблем с откатом тк все 100% независимое и рабочее
2. Если все плохо судя из того что пишете. То имхо стоит использовать то что люди дааааавно придумали с releases -> symlink to -> current dir дешево сердито и не нужен рут. Да орд кульно но работает стабильно и если вдруг что пошло не так тупо меняем симлинк онбартно на предидущий релиз. Есть 100500 готовых решений для того деплоя просто бери и юзайте.
3. Если все плохо но хочется докер. НА*** маунтить директорию ??? Зачем что за дичь? Почему просто не собрать готовый образ со всем вместе со всеми папками, правами, php-fpm and nginx просто вот такой веб-бокс который можно запустить где угодно хоть локально хоть на проде. Релиз-откат тогда это просто переключение между тегами для образа — дешево -сердито-стабильно.
Релиз это не магия с какими-то танцами с бубном это просто тупой однообразный процесс, причем абсолютно бездумный и он таким и должен быть.
youROCK
29.04.2019 22:131. Неясно, зачем здесь виртуальные машины. Можно обновить 50% машин и будет в целом то же самое — половина трафика будет обслуживаться старым кодом, половина — новым. Для того, чтобы делать так, как вы хотите, особенно с PHP, нужно либо «жить в облаке» (а-ля Amazon или Google Cloud), либо использовать что-нибудь вроде Kubernetes. В то время как это «модные» и «новые» технологии, внедрять их только ради blue-green deployment звучит не очень разумно. Отдельный вопрос есть вообще про полезность blue-green deployment — это не всегда хорошо, когда есть 2 разных версии кода, которые одновременно работают в продакшене.
2. Я ничего не понял, извините
3. Не забывайте про то, что код раскладывался не только на те машины, где вообще стоит Docker (там даже версия ядра может Docker не поддерживать, или поддерживать его весьма старой версии). То есть, схема должна быть совместимой с Docker, но это не значит, что деплой должен осуществляться средствами Docker. Более того, учитывая, как работают слои в Docker, сделать такой же эффективный (в плане потребления места) инкрементальный деплой было бы сложно: самое эффективное, что можно сделать — всё время будет раскладываться разница между «базовым образом» и текущим состоянием, и эта разница будет постоянно расти, а пересоздание образа будет занимать как минимум размер этого образа :), то есть в какой-то момент будет нужно хранить как минимум 2x места. Потребляемое место немаловажно, т.к. кода и всего остального каждый раз деплоится ~1 Гб, и далеко не на всех машинах есть достаточное количество места под большое количество копий директории. Я не говорю, что на эту схему нельзя перейти, но только вопрос — зачем? Эта система делалась не «с нуля», и на всех серверах уже всё было настроено, без докера (потому что делалось давно). «If it ain't broken, don't fix it».
VolCh
29.04.2019 23:432. Это модифицированная версия с двумя директориями, только их неограниченное (в разумных пределах) количество. Давно автоматизировано для ruby и php (типа порта с ruby) как минимум.
i86com
29.04.2019 23:30«У соцсети N есть 2 000 серверов, на которых 150 000 файлов объемом по 900 Мб PHP-кода...
Поскольку у нас 2000 серверов, то требуется 2000 раз залить 900 Мб.
Так уж выходит не «по 900 Мб», а «в сумме на 900 Мб».

tagirb
29.04.2019 23:43Деплой, как уже писали, должен быть максимально простой, даже тупой, и понятный с первого взгляда. А здесь он, какой-то, очень нетривиальный.
У меня сложилось впечатление, что вы проблему решаете не с того конца. Вы пытаетесь усложнением деплоя решить проблемы архитектуру.
Те же долгоиграющие CLI-скрипты, из-за которых, как я понял, весь сыр-бор, можно было бы отделить от обычной веб-серверной нагрузки в отдельный кластер. Тогда, глядишь, и rsync бы подошёл.
Короче, шире надо смотреть на проблемы.

Finesse
30.04.2019 07:55А что насчёт миграций баз и других хранилищ данных во время деплоя? Как обеспечивается согласованность версии структуры данных и кода, который с ней работает, во время деплоя и в случае неудачного деплоя?

slonopotamus
30.04.2019 09:21PHP-код не знает, в какой из директорий он был запущен
Что мешает ему это знать?
youROCK
30.04.2019 10:35Если в пути не было симлинков, то, в целом, ничего, и __DIR__ будет прекрасно работать (хотя часто используют document_root в качестве основы). Если же посередине пути симлинки присутствуют, то __DIR__ в теории (да и на практике тоже) может показывать не тот же путь, по которому действительно был загружен скрипт, если в процессе исполнения запроса симлинк в пути поменял свое значение. Это заодно вызывает артефакты при кешировании опкода — мы наблюдали, как в opcache попадала не та (старая) версия файла. Поэтому лучше избегать симлинков в пути, или использовать realpath_root, или же не полагаться на то, что при изменении симлинка все будет правильно работать
slonopotamus
30.04.2019 13:09Алгоритм:
0. На входе путь до скрипта в котором возможно симлинки
1. Разрезолвить симлинки (man realpath)
2. Вызвать скрипт по полученному пути
3. ???
4. Profit.
pansa
30.04.2019 11:15+1Rsync позволяет синкать на удаленный сервер в новый каталог, заменяя неизмеившиеся файлы хардлинками на уже существующие там. Таким образом получаете обновленный вариант каталога с исходниками, отдельно, и передав только изменения. Это решает проблему нагрузки на диски при большом кол-ве файлов (хотя ссд должен бы справиться, но да ладно). После этой операции можно переключить симлинк или переименовать каталог. Это будет неатомарно, но в свежих линуксах есть сисколл, чтобы обменять имена у двух каталогов за 1 сисколл.
Fafhrd
30.04.2019 11:51Про задачник по хайлоаду можем только мечтать
Зато cookbook по хайлоаду вполне уже можно сделать, будет такой же толстый, как и у perl в своё время ^_^

paramtamtam
30.04.2019 21:24Статья написана здорово, читается легко, но её содержимое (мягко говоря) отталкивает. Складывается стойкое убеждение что решаете проблему не с той стороны — не дроблением монолита на сервисы с независимым деплоем каждого по отдельности по мере необходимости на, скажем, k8s, а пытаетесь закостылять то "что есть", выдавая это за некоторое подобие инновации и "мы разработали деплой кит".
Вот бы статейку о том, как молит дробили, да под каждый конкретный сервис подбирали наиболее подходящий язык/службу/идею — вот этому цены бы не былоyouROCK
30.04.2019 23:25А как вы определили, «с той стороны» решается задача или «не с той»? Дробление на микросервисы — это задача, в целом, отдельная от деплоя, и их можно делать независимо. Я решал достаточно конкретные проблемы, которые были у деплой-системы — необходимость часто применять патчи, но при этом позволять скриптам, которые были работают «долго» (несколько часов), всё ещё работать с консистентной версией кода. Разделение на микросервисы в теории могло бы уменьшить «боль» от этого, но, кажется, решить эту проблему на уровне системы деплоя было бы намного эффективнее в плане затраченных на разработку ресурсов (на деплой было потрачено максимум несколько месяцев, в то время как на распиливание монолита я бы сказал, что ушло бы много человеколет).
webmascon
Не могли бы вы спрятать виде под кат. Вы ломаете rss ленту