

Пришлось мне недавно решать задачку по оптимизации поиска дубликатов изображений.
Существующее решение работает на довольно известной библиотеке, написанной на Python, — Image Match, основанной на работе «AN IMAGE SIGNATURE FOR ANY KIND OF IMAGE» за авторством H. Chi Wong, Marshall Bern и David Goldberg.
По ряду причин было принято решение переписать всё на Kotlin, заодно отказавшись от хранения и поиска в ElasticSearch, который требует заметно больше ресурсов, как железных, так и человеческих на поддержку и администрирование, в пользу поиска в локальном in-memory кэше.
Для понимания того, как оно работает, пришлось с головой погружаться в «эталонный» код на Python, так как оригинальная работа порой не совсем очевидна, а в паре мест заставляет вспомнить мем «как нарисовать сову». Собственно, результатами этого изучения я и хочу поделиться, заодно рассказав про некоторые оптимизации, как по объёму данных, так и по скорости поиска. Может, кому пригодится.
Disclaimer: Существует вероятность, что я где-то напортачил, сделал неправильно или не оптимально. Ну что уж, буду рад любой критике и комментариям. :)
Как оно работает:
- Изображение преобразуется к 8-битному чёрно-белому формату (одна точка — это один байт в значении 0-255)
- Изображение обрезается таким образом, чтобы отбросить 5% накопленной разницы (подробнее ниже) с каждой из четырёх сторон. Например, чёрную рамку вокруг изображения.
- Выбирается рабочая сетка (по умолчанию 9x9), узлы которой будут служить опорными точками сигнатуры изображения.
- Для каждой опорной точки на основании некоторой области вокруг неё рассчитывается её яркость.
- Для каждой опорной точки рассчитывается насколько она ярче/темнее своих восьми соседей. Используется пять градаций, от -2 (сильно темнее) до 2 (сильно ярче).
- Вся эта «радость» разворачивается в одномерный массив (вектор) и обзывается сигнатурой изображения.
Схожесть двух изображений проверяется следующим образом:
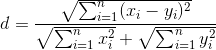
Чем меньше d — тем лучше. По факту, d<0.3 — это практически гарантия идентичности.
Теперь более подробно.
Шаг первый
Думаю, что про преобразование в grayscale рассказывать особого смысла нет.
Шаг второй
Допустим, у нас есть такая картинка:

Видно, что тут присутствует чёрная рамка по 3 пикселя справа и слева и по 2 пикселя сверху и снизу, которая нам в сравнении совсем не нужна
Граница обрезания определяется по такому алгоритму:
- Для каждого столбца рассчитываем сумму абсолютных разностей соседних элементов.
- Обрезаем слева и справа такое количество пикселей, вклад которых в общее накопленное различие менее 5%.

Аналогичным же образом поступаем и для столбцов.
Важное уточнение: если размеры получившегося изображения недостаточны для осуществления шага 4, то обрезания не делаем!
Шаг третий
Ну тут совсем всё просто, делим картинку на равные части и выбираем узловые точки.

Шаг четвёртый
Яркость опорной точки рассчитывается как средняя яркость всех точек в квадратной области вокруг неё. В оригинальной работе используется следующая формула для расчёта стороны этого квадрата:

Шаг пятый
Для каждой опорной точки вычисляется разность её яркости с яркостью её восьми соседей. Для тех точек, у которых не достаёт соседей (верхний и нижний ряды, левая и правая колонка), разница принимается за 0.
Далее эти разницы приводятся к пяти градациям:
| x-y | Значение | Описание |
|---|---|---|
| -2..2 | 0 | Идентичны |
| -50..-3 | -1 | Темнее |
| < -50 | -2 | Сильно темнее |
| 3..50 | 1 | Ярче |
| >50 | 2 | Сильно ярче |
Получается примерно вот такая матрица:
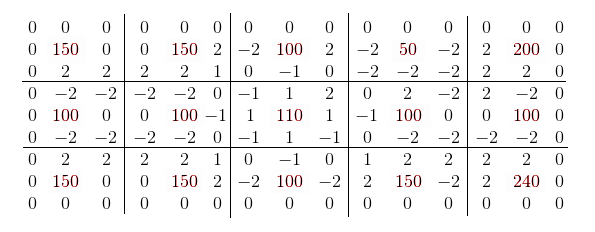
Шаг шестой
Думаю в пояснениях не нуждается.
А теперь про оптимизации
В оригинальной работе справедливо указывается, что из получившейся сигнатуры можно совершенно спокойно выкинуть нулевые значения по краям матрицы, так как они будут идентичны для всех изображений.
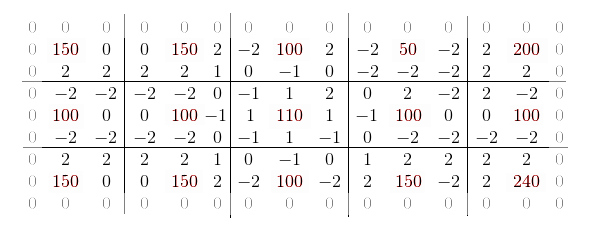
Однако если внимательно посмотреть, то видно, что для любых двух соседей их взаимные градации будут равны по модулю. Следовательно, на самом то деле, можно смело выкинуть четыре дублирующихся значения для каждой опорной точки, сократив размер сигнатуры в два раза (без учёта боковых нулей).
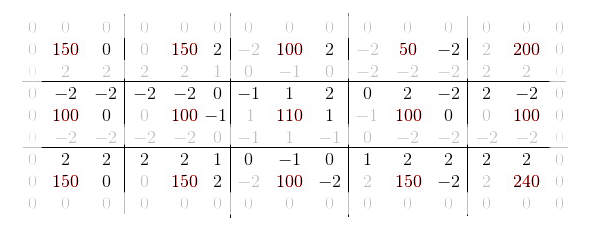
Очевидно, что при расчете суммы квадратов, для каждого x обязательно будет присутствовать равный по модулю x' и формулу расчета нормы можно записать примерно так (не углубляясь в переиндексацию):
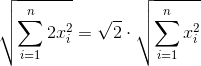
Это справедливо как для числителя, так и для обоих слагаемых знаменателя.
Далее в оригинальной работе замечается, что для хранения каждой градации достаточно трёх бит. То есть, например, в Unsigned Long влезет 21 градация. Это довольно большая экономия на размере, но, с другой стороны, добавляет сложности при расчёте суммы квадратов разницы двух сигнатур. Надо сказать, что идея эта меня чем-то очень зацепила и не отпускала пару дней, пока однажды вечером не озарило, как можно и
Используем для хранения такую схему, по 4 бита на градацию:
| Градация | Храним как |
|---|---|
| -2 | 0b1100 |
| -1 | 0b0100 |
| 0 | 0b0000 |
| 1 | 0b0010 |
| 2 | 0b0011 |
Да, в один Unsigned Long влезет всего 16 градаций, против 21, но зато массив разницы двух сигнатур будет вычисляться одним xor'ом и 15 сдвигами вправо с вычислением количества выставленных бит на каждой итерации сдвига. Т.е.
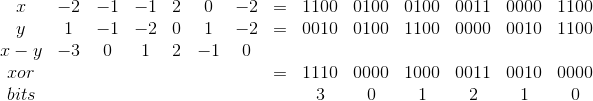
Знак нам безразличен, так как все значения будут возводиться в квадрат.
Кроме того, если заранее определить пороговое значение дистанции, значения больше которой нам не интересны, то, немного поплясав вокруг формулы расчёта, можно вывести довольно легковесное фильтрующее условие по простому количеству выставленных бит.
Более подробно про оптимизацию этого алгоритма, с примерами кода, можно прочитать в предыдущей статье. Отдельно рекомендую почитать комментарии к ней — хабровчанин masyaman предложил несколько довольно интересных способов по расчету, в том числе и с упаковкой градаций в трёх битах, с использованием битовой магии.
Собственно, всё. Спасибо за внимание. :)
Комментарии (25)

aamonster
20.05.2019 12:17Устойчивость к кропу проверяли? Вызывает некоторые сомнения, особенно при наличии выраженной текстуры на изображении.

rjhdby Автор
20.05.2019 12:38Да, конечно, можно с ходу набросать довольно много вариантов, как обмануть алгоритм, и беспощадный кроп — один из них.
Ярко выраженная текстура, в общем случае, не должна помешать, так как для узловых точек мы берем среднее по некоторой области.
lavilav
20.05.2019 13:05Использую perceptual hash, в бОльшей степени работает нормально, но поиск среди миллионов изображений достаточно медленный, при том, что изначально загружаю базу в память.
Алгоритм достаточно устойчив к мусору, но есть нюансы с размером. часто промахи

avallac
20.05.2019 15:37+1Данная тема для меня близка и интересна. Есть несколько вопросов. Как я вижу, ваш метод неустойчив к кропу и поворотам. Почему не используете ключевые точки и дескрипторы? Там множество хороших алгоритмов. Какая нагрузка на ваш поисковой движок? (Количество изображений/запросов в секунду).
Моя реализация устойчива к кропу/ресайзу/ватермаркам/поворотам. База 100M на 3х древних серверах (порядка сдвоенного Xeon E5430), ищет порядка 2 картинки в секунду.lavilav
20.05.2019 15:40вы делали для себя или это продукт?
avallac
20.05.2019 15:47+1Это личный пет проект, который я никак не могу выложить в опен сурс.
У меня есть презентация:
www.youtube.com/watch?v=gD7dSBcL9AIrjhdby Автор
20.05.2019 16:16Вот самое интересное то и не рассказали! :D
Спасибо, очень интересно было посмотреть.avallac
20.05.2019 16:35Нуууу да, меня уже поругали. Я с эту тему еще рассказывал на DevFest, там как раз все внутренние части описаны. И про дерево и про борьбу с коллизиями. Но организаторы так и не выложили видео :(
vagran
21.05.2019 08:30В Вашей презентации один момент упущен. Упомянуто только расстояние Хэмминга между дескрипторами. Хотя метрика расстояния зависит от типа дескриптора, которые бывают бинарные и векторные. У бинарных по сути каждый бит является вектором, и поэтому сравнение побитовое. У векторных каждый вектор уже более одного бита, чаще всего один байт, и используется Эвклидово расстояние между ними и соответствующие индексы, например, FLANN.
rjhdby Автор
20.05.2019 15:48Почему не используете ключевые точки и дескрипторы?
Как я ответил выше — этот алгоритм был выбран довольно давно и не мной. Моей задачей было переписать реализацию для большего соответствия требованиям компании. Собственно поэтому про ключевые точки и дескрипторы я прокомментировать не смогу. Sad, but true.
Моя реализация устойчива к кропу/ресайзу/ватермаркам/поворотам.
А можно на нее посмотреть?
avallac
20.05.2019 15:52+1Постом выше я скинул ссылку на мой рассказ по этой теме. Если хотите пощупать поближе, пишите в личку :)

Arseny_Info
20.05.2019 21:00Кажется, что сейчас использовать классическое компьютерное зрение, а не deep learning — чаще плохая идея.
В качестве бейзлайна можно достать дескрипторы картинок из любой предобученной сети (например, какой-нибудь resnet, обученный на imagenet), сложить их в какую-то структуру для быстрого поиска похожих (например, github.com/spotify/annoy) и быстро искать. По точности будет явно не хуже, скорость поиска — тоже, а главное достоинство — когда точности перестанет хватать, можно будет переобучить сетку на своих данных и добиться точности, близкой к идеальной.

david_mz
21.05.2019 10:56Как вы сами, по своей базе, оцениваете качество этого алгоритма? Навскидку кажется, что большие классы изображений он вообще не должен уметь различать. Например, текстовые скриншоты или текстуры (когда картинка «в среднем» равномерно-серая, и все N точек одной яркости) или типичные плохо снятые пейзажи, в которых верх очень яркий, а низ очень тёмный.
rjhdby Автор
21.05.2019 11:46Вот исходная научная работа, там довольно подробно разобраны теоретические аспекты алгоритма.
С текстовыми скриншотами есть определенные проблемы — если не поднимать порог, то ложно-позитивные срабатывания бывают, хотя и редко. Но это довольно специфическая область.
Germanjon
1.Одинаковые изображения разного размера (длина-ширина) корректно сравниваются?
2. Остаётся вопрос корректности приведения к чёрно-белому формату. В данном случае ярко-белое снежное поле и голубое небо могут оцениваться как одинаковое изображение. Возможно, имеет смысл делать четыре проверки векторов — «Чёрно-белые» и по каждому из цветов RGB.
Aquahawk
Это же не сколько про сравнение, сколько про получение хеша от изображения, чтобы потом, найдя схожие хеши можно было провести нормальное сравнение, уже обратившись к картинкам.
rjhdby Автор
arandomic
Не сравнивали с другими perceptual hash алгоритмами?
Т.е. подготовить набор изображений и их искаженных версий и сравнить вашу реализацию с другими по количеству false positive/false negative ошибок. Ну и по скорости обработки большого количества фотографий.
Например с blockhash?
rjhdby Автор
Скажем так, выбирал не я и было это давно. :)
Возможно я и проведу такое сравнение, но, с очень большой долей вероятности, делать это придется в свободное от работы время, поскольку качество текущей реализации соответствует рабочим ожиданиям.
По скорости — в конце статьи есть ссылка на предыдущую, с "попугаями". В контейнере на локальном буке поиск по 10М изображений отрабатывает за ~1.5 секунды. Ищет хорошо (на тестовом наборе нашла все, что нужно и ничего, что не нужно)
sgjurano
1.5 секунды на поиск? Это очень много, faiss позволяет получить время поиска порядка 50 ms при поиске по миллиардному индексу, hnsw справится за единицы ms (хотя строиться миллиардный индекс будет пару недель).
rjhdby Автор
Довольно глупо меряться абстрактными попугаями, полученными в разных условиях и на коде, писанном с разными вводными и ограничениями.
sgjurano
Целью моего комментария было указать интересующимся на куда более продвинутые технологии, чтобы после прочтения вашей статьи не возникало ощущение, что это лучший из возможных результатов.