

Но, если у вас стек PostgreSQL, то можете забыть о InfluxDB и всех остальных темпоральных БД. Ставите себе два расширения TimescaleDB и PipelineDB и храните, обрабатываете и проводите аналитику time series данных прямо в экосистеме PostgreSQL. Без внедрения сторонних решений, без недостатков темпоральных хранилищ и без проблем их обкатки. Что это за расширения, в чем их преимущества и возможности, расскажет Иван Муратов (binakot) — руководитель отдела разработки в «Первой Мониторинговой Компании».
Что такое time series данные или временные ряды?
Это данные о процессе, которые собраны в разные моменты его жизни.
Например, местоположение автомобиля: скорость, координаты, направление, или использование ресурсов на сервере с данными о нагрузке на CPU, используемой оперативной памяти и свободном месте на дисках.
Временные ряды имеют несколько особенностей.
- Время фиксации. Любая time series запись имеет поле с меткой времени, в которое было зафиксировано значение.
- Характеристики процесса, которые называются уровнями ряда: скорость, координаты, данные о нагрузке.
- Практически всегда с такими данными работают в append-only режиме. Это значит, что новые данные не заменяют старые. Удаляются только устаревшие данные.
- Записи не рассматриваются отдельно друг от друга. Данные используются только в совокупности по временным окнам, интервалам или периодам.
Популярные решения для хранения данных
На графике, который я взял с сайта db-engines.com, отображена популярность различных моделей хранения данных за последние два года.
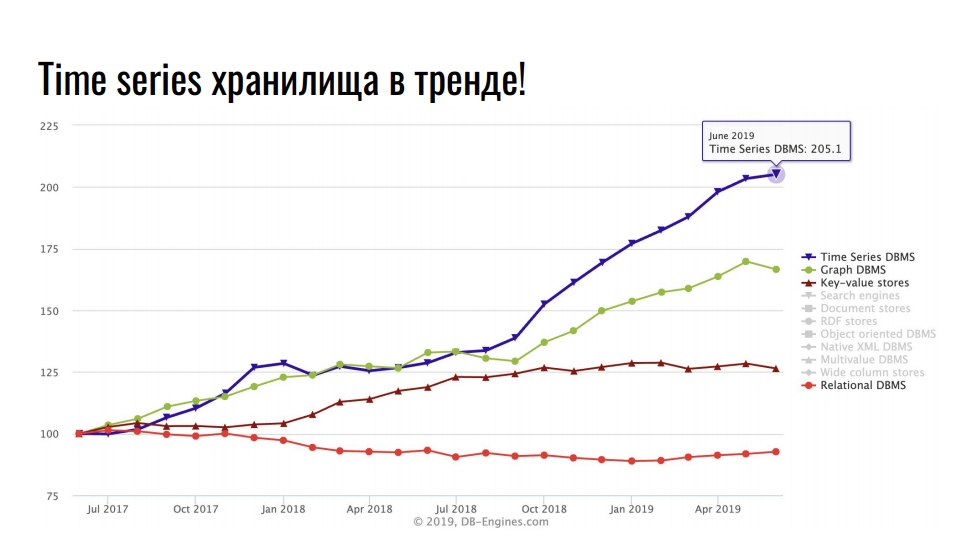
Лидирующую позицию занимают time series хранилища, на втором месте — графовые БД, дальше — key-value и реляционные базы. Популярность специализированных хранилищ связана с интенсивным ростом интеграции информационных технологий: Big Data, социальные сети, IoT, мониторинг highload-инфраструктуры. Кроме полезных бизнес-данных, даже логи и метрики занимают огромное количество ресурсов.
Популярные решения для хранения time series данных
На графике показаны специализированные решения для хранения time series данных. Шкала логарифмическая.
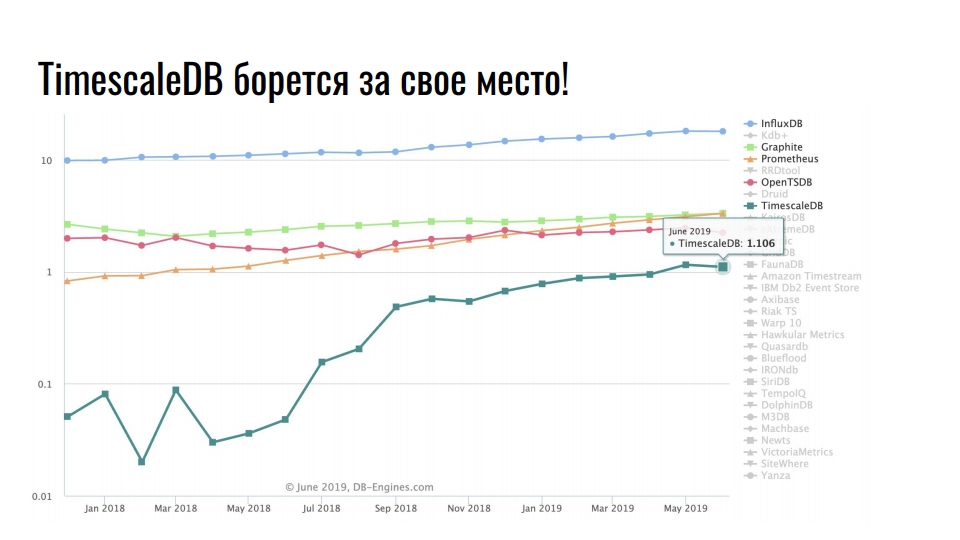
Стабильно лидирует InfluxDB. Все кто сталкивался с time series данными, слышали про этот продукт. Но на графике заметен десятикратный рост у TimescaleDB — расширение к реляционной СУБД борется за место под солнцем среди продуктов, которые изначально разрабатывались под time series.
PostgreSQL это не только хорошая БД, но и расширяемая платформа для разработки специализированных решений.
Postgres, Postgis и TimescaleDB
«Первая Мониторинговая Компания» следит за передвижением транспорта с помощью спутников. Мы отслеживаем 20 000 транспортных средств и храним данные о перемещениях за два года. Суммарно у нас 10 ТБ актуальных телеметрических данных. В среднем, каждое транспортное средство во время движения отправляет 5 телеметрических записей в минуту. Данные отправляются с помощью навигационного оборудования на наши телематические серверы. В секунду они принимают 500 навигационных пакетов.
Некоторое время назад мы решили глобально модернизировать инфраструктуру и переехать с монолита на микросервисы. Новую систему мы назвали Waliot, и она уже в продакшн — 90% всех транспортных средств переведена на нее.
В инфраструктуре поменялось многое, но центральное звено осталось неизменным — это база данных PostgreSQL. Сейчас мы работаем на версии 10 и готовимся к переезду на 11. Кроме PostgreSQL, как основного хранилища, в стеке мы используем PostGIS для геопространственных вычислений, и TimescaleDB для хранения большого массива time series данных.
Почему PostgreSQL?
Почему мы пытаемся использовать реляционную базу для хранения time series, а не
Переход на новое решение — это риски.
Специализированных решений для хранения и обработки time series данных множество. Документации не всегда достаточно, а большой выбор решений не всегда хорошо. Кажется, что разработчики каждого нового продукта хотят писать все с нуля, потому что в предыдущем решении что-то не понравилось. Чтобы понять, что именно не понравилось, придется искать информацию, анализировать и сравнивать. Огромное разнообразие топов, рейтингов и сравнений скорее пугает, чем мотивирует что-то попробовать. Придется тратить много времени, чтобы перепробовать все решения на себе. Мы не можем себе позволить адаптацию только одного решения в течении нескольких месяцев. Это сложная задача, а потраченное время никогда не окупится. Поэтому мы выбрали расширения для PostgreSQL.
На этапе разработки инфраструктуры Waliot мы рассматривали в качестве основного хранилища телеметрических данных InfluxDB. Но когда наткнулись на TimescaleDB и провели над ним тесты, вопросов о выборе не осталось. PostgreSQL с расширением TimescaleDB, позволяет использовать в рамках одного хранилища PostGIS или PipelineDB и другие расширения. Нам не нужно вытаскивать данные, трансформировать, проводить аналитику и перебрасывать их по сети. Все лежит на одном сервере или в кластерной системе — данные не нужно перетаскивать. Все вычисления выполняются на одном уровне.
Недавно Николай Самохвалов, автора аккаунта postgresmen, опубликовал ссылку на интересную статью на тему использования SQL для потоковой обработки данных. Пять из шести авторов статьи участвуют в разработке различных продуктов Apache и работают с потоковой обработкой. Поэтому в статье упоминаются Apache Spark, Apache Flink, Apache Beam, Apache Calcite и KSQL от компании Confluent.
Но интересна не сама статья, а топик на Hacker News, в котором её обсуждают. Автор топика пишет, что на основе статьи, реализовал почти все идеи на базе PostgreSQL 11. Он использовал расширения CitusDB для горизонтального масштабирования и шардирования, PipelineDB для потоковых вычислений и материализованных представлений, TimescaleDB для хранения time series данных и секционирования. Еще он использует несколько Foreign Data Wrappers.
Сумасшедшая смесь из PostgreSQL и расширений к нему еще раз подтверждает, что PostgreSQL не просто СУБД — это платформа.
А когда завезут pluggable storage… Ухх!
Иронично, что исследуя решения, мы нашли Outflux — разработку команды TimescaleDB, которую они опубликовали 1 апреля. Как думаете, что она делает? Это утилита для миграции из InfluxDB в TimescaleDB в одну команду…
Postgres hype!
Нельзя недооценивать силу хайпа! Мы часто шутим, что «разработку двигает хайп», потому что он оказывает влияние на наше восприятия тулинга и инфраструктурных компонентов. На HighLoad++ мы много обсуждаем PostgreSQL, ClickHouse, Tarantool — это хайповые разработки. Только не говорите, что это не влияет на ваши предпочтения и выбор решений для инфраструктуры… Конечно, это не основной фактор, но ведь эффект есть?
Я работаю с PostgreSQL 5 лет. Мне нравится это решение. Практически все мои задачи он решает на ура. Каждый раз, когда у меня что-то с этой базой шло не так, были виноваты мои кривые руки. Поэтому выбор был предопределен.
TimescaleDB VS PipelineDB
Перейдем к расширениям TimescaleDB и PipelineDB. Что говорят о расширениях их создатели?
TimescaleDB — это time series база данных с открытым исходным кодом, которая оптимизирована для быстрой вставки и сложных запросов.
PipelineDB — это высокопроизводительное расширение, которое разработано для выполнения непрерывных SQL-запросов для time series данных.
Кроме работы с time series данными, у них похожа история. Компания Timescale основана в 2015 году, а Pipeline в 2013. Первые рабочие версии появились в 2017 и 2015, соответственно. По два года потребовалось командам, чтобы выпустить минимальную функциональность. Продакшн релизы обоих расширений прошли в октябре прошлого года с разницей в одну неделю. Видимо, торопились друг за другом.
В GitHub куча звезд и форков, в которых как обычно ни одного коммита. Так устроен Open Source, ничего не поделаешь. Но звезд много, у TimescaleDB больше, чем у PipelineDB, и даже больше, чем у самого PostgreSQL.
Кажется, что расширения похожи, но они позиционируют себя по-разному.
TimescaleDB заявляет, что у него вставка миллионов записей в секунду и хранение сотней миллиардов строк и десятков терабайт данных. Расширение быстрее, чем InfluxDB, Cassandra, MongoDB или ванильный PostgreSQL. Поддерживает потоковую репликацию и средства резервного копирования. TimescaleDB — это расширение, а не форк PostgreSQL.
PipelineDB хранит только результат потоковых вычислений, без необходимости хранить сырые данные для их расчетов. Расширение способно на непрерывные агрегации над потоками данных в реальном времени, объединения с обычными таблицами для вычислений в контексте доменной области. PipelineDB — это расширение, а не форк, но изначально он был именно форком.
TimescaleDB
Теперь подробно о расширениях. Начнем с TimescaleDB. С ним я работаю почти 2 года. Затащил его на продакшн еще до релизной версии. Рассмотрим на примерах, как его применять.
Хранилище для метрик инфраструктуры. У нас есть метрики потребления ресурсов Docker-контейнеров, время фиксации метрик, идентификатор контейнера и поля с потреблением ресурсов, например, свободной памятью. Нам необходимо вывести статистику по всем контейнерам со средним количеством свободной памяти окнами по 10 секунд. Запрос, который Вы видите решает данную задачу и TimescaleDB можно использовать в качестве хранилища для метрик инфраструктуры.
SELECT time_bucket(’10 seconds’, time) AS period,
container_id,
avg(free_mem)
FROM metrics
WHERE time > now() - interval ’10 minutes’
GROUP BY period, container_id
ORDER BY period DESC, container_id;period | container_id | avg
-----------------------+--------------+---
2019-06-24 12:01:00+00 | 16 | 72202
2019-06-24 12:01:00+00 | 73 | 837725
2019-06-24 12:01:00+00 | 96 | 412237
2019-06-24 12:00:50+00 | 16 | 1173393
2019-06-24 12:00:50+00 | 73 | 90104
2019-06-24 12:00:50+00 | 96 | 784596Для расчетов. Нам требуется рассчитать количество грузовых авто, которые покинули Краснодар и их общий тоннаж по дням.
SELECT time_bucket(’1 day’, time) AS day,
count(*) AS trucks_exiting,
sum(weight) / 1000 AS tonnage
FROM vehicles
INNER JOIN cities ON cities.name = ’Krasnodar’
WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326))
AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326))
GROUP BY day
ORDER BY day DESC
LIMIT 3;Здесь также используются функции из расширения PostGIS, чтобы вычислить транспорт, который именно покинул город, а не просто двигался в нем.
Мониторинг курса валюты. Третий пример о криптовалютах. Запрос позволяет отобразить, как менялась цена Эфириума относительно Биткоина и американского доллара за последние 2 недели по дням.
SELECT time_bucket(’14 days’, c.time) AS period,
last(c.closing_price, c.time) AS closing_price_btc,
last(c.closing_price, c.time) * last(b.closing_price, c.time)
filter (WHEREb.currency_code = ’USD’) AS closing_price_usd
FROM crypto_prices c
JOIN btc_prices b
ON time_bucket(’1 day’, c.time) = time_bucket(’1 day’, b.time)
WHERE c.currency_code = ’ETH’
GROUP BY period
ORDER BY period DESC;Это все тот же понятный и удобный нам SQL.
Что такого крутого в TimescaleDB?
Почему не использовать встроенные средства секционирования таблиц? И зачем вообще разбивать таблицы? Очевидный ответ — это скорость вставки в такие базы. На графике отображены реальные замеры скорости вставки количества строк в секунду между обычной таблицей ванильного PostgreSQL 10 без секционирования, и гипертаблицей TimescaleDB.
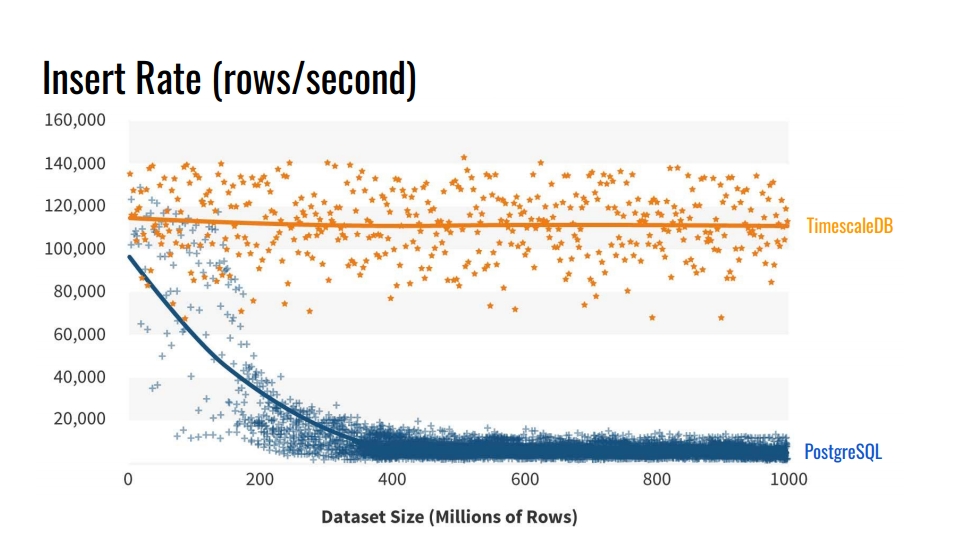
Этот бенчмарк записывает 1 миллиард строк на одной машине, имитируя сценарий сбора метрик с инфраструктуры. Запись содержит время, идентификатор компонента инфраструктуры и 10 метрик. Бенчмарк выполнялся на Azure VM с 8 ядрами и 28 гигабайт оперативки, а также сетевыми SSD дисками. Вставка выполнялась пакетами по 10 тысяч записей.
Откуда такая деградация производительности PostgreSQL? Потому что при вставке нужно обновлять еще и индексы таблиц. Когда они не помещаются в кэш, мы начинаем нагружать диски. Секционирование решает эту проблему, если индексы секции, в которую мы вставляем данные, помещаются в оперативную память.
Посмотрим на следующий график. Здесь сравнивается система декларативного секционирования встроенная в PostgreSQL 10 и гипер-таблица TimescaleDB. По горизонтальной оси количество секций.
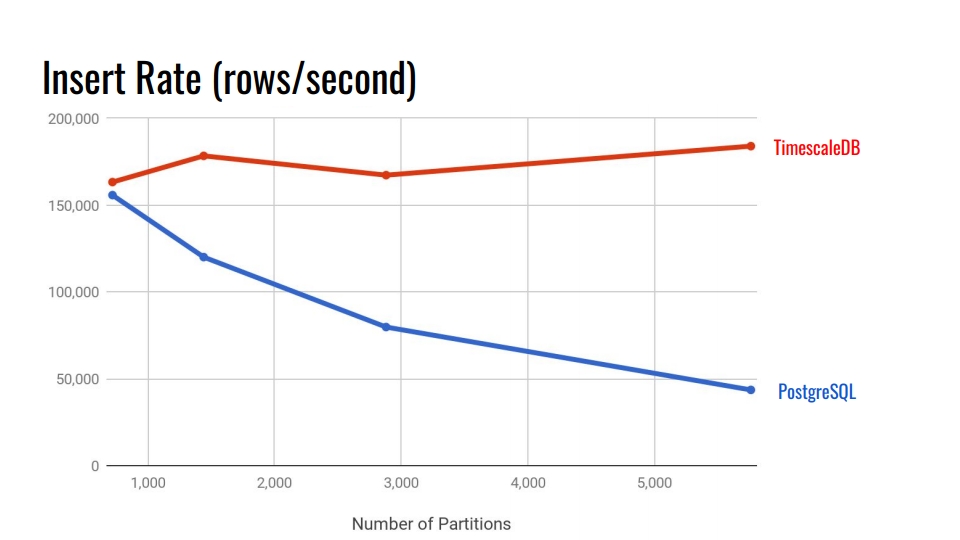
В TimescaleDB деградация незначительна при увеличении количества секций. Разработчики расширения заявляют, что прекрасно справляются с 10 000 секций в одном инстансе PostgreSQL.
В PostgreSQL нативная реализация значительно деградирует уже после 3 000. В целом, декларативное секционирование в PostgreSQL это большой шаг вперед, но он хорошо работает только для таблиц с меньшей нагрузкой. Например, для товаров, покупателей и других сущностей домена, которые поступают в систему не так интенсивно, как метрики.
В 11 и 12 версиях PostgreSQL появится нативная поддержка секционирования и можно попробовать прогнать сравнительные тесты для time series данных с новыми версиями. Но, мне кажется, что TimescaleDB все равно лучше. Все бенчмарки от TimescaleDB можно найти у них на гитхабе и попробовать.
Основные возможности
Надеюсь, у вас уже появился интерес к расширению. Давайте пробежимся по основным возможностями TimescaleDB, чтобы закрепить это чувство.
Секционирование через гипертаблицы. TimescaleDB использует термин «гипертаблица» для таблиц, к которым была применена функция «create_hypertable()». После этого таблица станет родительской для всех наследуемых секций — чанков. Сама родительская таблица не будет содержать никаких данных, а будет точкой входа для всех запросов и шаблоном при автоматическом создании новых секций. Все секции хранятся не в основной схеме ваших данных, а в специальной схеме. Это удобно тем, что мы не видим тысячи этих секции в схеме данных.
Расширение интегрировано в планировщик и исполнитель запросов. Через специальные хуки в PostgreSQL, TimescaleDB понимает, когда обращаются к гипертаблице. TimescaleDB анализирует запрос и перенаправляет запросы только в нужные секции на основе указанных условий в самом SQL-вызове. Это позволяет распараллеливать работу с секциями во время извлечение значительного объема данных.
Расширение не накладывает ограничений на SQL. Свободно можно использовать объединения, агрегаты, оконные функции, CTE и дополнительные индексы. Если вы видели список ограничений для встроенной системы секционирования, вас это должно порадовать.
Дополнительные полезные функции, специфичные для time series данных:
- «time_bucket» — «date_trunс» здорового человека;
- гистограммы — заполнение пропущенных интервалов с помощью интерполяции или последнего известного значения;
- background worker’s — службы, которые позволяют выполнять фоновые операции: очистку старых секций, переорганизацию.
TimescaleDB позволяет остаться в мощнейшей экосистеме PostgreSQL. Это расширение не ломает PostgreSQL, поэтому все High Availability решения, системы резервного копирования, средства мониторинга по-прежнему будут работать. TimescaleDB дружит с Grafana, Periscope, Prometheus, Telegraf, Zabbix, Kubernetes, Kafka, Seeq, JackDB.
В Grafana уже встроена нативная поддержка TimescaleDB в качестве источника данных. Grafana понимает «из коробки», что в PostgreSQL стоит TimescaleDB. Билдер запросов в Grafana на дашбордах понимает дополнительные функции TimescaleDB, такие как «time_bucket», «first», «last». Можно прямо из реляционной базы с этими time series функциями строить графики без гигантских запросов.
В Prometheus реализован адаптер, который позволяет сливать данные с него и использовать TimescaleDB в качестве надежного хранилища данных. Используйте адаптер, чтобы не хранить в Prometheus данные годами.
Также есть Telegraf-плагин. Решение позволяет вообще удалить Prometheus. Данные инфраструктуры сразу передаются в TimescaleDB и читаются через Telegraf.
Лицензии и новости
Не так давно компания перешла к новой модели лицензирования. Основная часть кода открыта под лицензией Apache 2.0. Небольшая часть бесплатна в использовании, но находится под собственной лицензией TSL.
Есть Enterprise-версия с коммерческой лицензией. Не пугайтесь, не все вкусняшки в Enterprise-версии. В основном там автоматизации типа автоматического удаления устаревших чанков, которые можно сделать через простой «cron» и подобные вещи.
Сейчас компания активно работает над кластерным решением. Возможно, оно попадет в Enterprise-версию. Также есть облачная версия для стартапов, которые хотят успеть выйти на рынок, пока не кончились деньги инвесторов.
Из новостей:
- один миллион загрузок за последние полтора года;
- 31 млн долларов инвестиций;
- активное сотрудничество с MS Azure по поводу IoT-решений.
Подытожим
TimescaleDB создан для хранения time series данных. Это мощная система секционирования с минимальными ограничениями, по сравнению с нативными в PostgreSQL.
К сожалению, пока расширение не имеет мультинодовой версии. Если захотите мультимастер или шардироваться, то придется поиграться, например, с CitusDB. Если хотите логическую репликацию, то будет больно. Но с ней всегда больно.
PipelineDB
Теперь поговорим про второе расширение. К сожалению, нам не удалось его как следуют опробовать в бою. Сейчас оно проходит стадию адаптации в нашей системе. Правда, есть одна проблема, о которой я скажу ближе к концу.
Как и в предыдущем случае, начнем с реальных примеров. Так проще понять пользу от расширения и мотивацию его использовать.
Сбор статистики. Представим, что мы собираем статистику посещения нашего веб-сайта. Нам требуется аналитика самых популярных страниц, количества уникальных пользователей и какое-то представление о задержках ресурса. Все это должно обновляться в реальном времени. Но мы не хотим каждый раз трогать таблицу с данными и строить запрос, или обновлять представление поверх таблицы.
CREATE CONTINUOUS VIEW v AS
SELECT url::text,
count(*) AS total_count,
count(DISTINCT cookie::text) AS uniques,
percentile_cont(0.99)
WITHIN GROUP (ORDER BY latency::integer) AS p99_latency
FROM page_views
GROUP BY url;url | total_count | uniques | p99_latency
-----------+-------------+---------+------------
some/url/0 | 633 | 51 | 178
some/url/1 | 688 | 37 | 139
some/url/2 | 508 | 88 | 121
some/url/3 | 848 | 36 | 59
some/url/4 | 126 | 64 | 159На помощь приходит потоковая обработка данных и расширение PipelineDB. Расширение добавляет абстракцию «CONTINUES VIEW». В русском варианте это может звучать как «непрерывное представление». Это представление автоматически обновляется при вставке в таблицу с записями посещений, при этом только на основании новых данных, не читая уже записанные заранее.
Поток данных. PipelineDB не ограничивается только новым типом представления. Предположим, что мы проводим А/Б-тестирование и собираем аналитику в реальном времени об эффективности нового бизнес-решения. Но мы не хотим хранить сами данные о действиях пользователя. Нас интересует только результат — в какой группе больше конверсия.
Чтобы избежать непосредственного хранения сырых данных для потоковых вычислений нам нужна такая абстракция как стримы — поток данных. PipelineDB вводит такую возможность. Вы можете создавать стримы как обычные таблицы. Под капотом это будут «FOREIGN TABLE» на базе очереди ZeroMQ, которую незаметно от нас использует расширение. Данные поступают во внутреннюю очередь ZeroMQ и провоцируют обновление непрерывного представления.
CREATE STREAM ab_event_stream (
name text,
ab_group text,
event_type varchar(1),
cookie varchar(32)
);
CREATE CONTINUOUS VIEW ab_test_monitor AS
SELECT name,
ab_group,
sum(CASE WHENevent_type = ’v’ THEN 1 ELSE 0 END) AS view_count,
sum(CASE WHENevent_type = ’c’ THEN 1 ELSE 0 END) AS conversion_count,
count(DISTINCT cookie) AS uniques
FROM ab_event_stream
GROUP BY name, ab_group;Дальше мы создаем «CONTINUOUS VIEW» на основе данных из ранее созданного стрима. Когда данные будут поступать в стрим, представление будет обновлятся на основе этих данных. После этого данные будут просто отбрасываться, нигде не сохраняясь и не занимая место на дисках. Это позволяет строить аналитику на практически неограниченном количестве данных, загружая их в поток данных PipelineDB и читая результат вычислений из непрерывного представления.
Потоковые вычисления. После того, как мы создали поток данных и непрерывное представление, мы можем работать с потоковыми вычислениями. Это выглядит так.
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie)
SELECT round(random() * 2) AS name,
round(random() * 4) AS ab_group,
(CASE WHENrandom() > 0.4 THEN ’v’ ELSE ’c’ END) AS event_type,
md5(random()::text) AS cookie
FROM generate_series(0, 100000);
SELECT ab_group,
uniques
FROM ab_test_monitor;
SELECT ab_group,
view_count * 100 / (conversion_count + view_count) AS conversion_rate
FROM ab_test_monitor;Первый «SELECT» выдает группу «ab» и число уникальных посетителей. Второй — выдает соотношение между группами — конверсию. Вот и все А/Б-тестирование на пяти SQL-вызовах в реляционной базе.
Представление обновляется динамически. Можно не ждать обработки всего массива данных, а читать промежуточные результаты, которые уже были обработаны. Представления читаются так же, как и обычные в PostgreSQL. Вы также можете объединять представление с таблицами или даже другими представлениями. Никаких ограничений нет.
Топология
В Kafka поступает телеметрия, топик в Kafka отправляет эти данные в PostgreSQL, и мы дальше их агрегируем. Например объединяем с какой-то обычной таблицей и перенаправляем данные в стрим. Дальше он провоцирует обновление соответствующего непрерывного представления, из которого клиенты базы уже могут читать готовые данные.
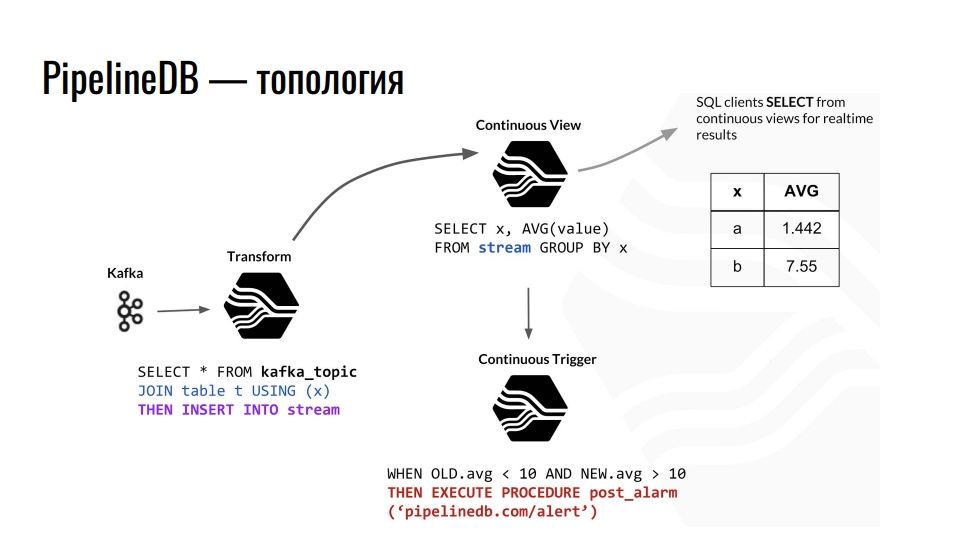
Пример топологии PipelineDB компонентов внутри PostgreSQL. Схема позаимствована из презентации Дерека Нельсона.
Кроме стримов и представлений, расширение предоставляет также абстракцию «transform» — преобразователи или мутаторы. Это представление, но направленное на преобразование входящего потока данных в модифицированный выходящий. С помощью этих мутаторов можно изменять представление данных или фильтровать его. Из мутатора это все попадает в представление «CONTINUOUS VIEW». В нем уже производим запросы для бизнеса. Кто знаком с функциональным программированием должен понимать идею.
В PipelineDB мы можем повесить триггер на наши представления и выполнять действия, например, «alert». При всех этих вычислениях мы нигде не храним сами сырые данные, на основе которых мы все это считаем. Это могут быть терабайты, которые мы загружаем последовательно на сервер с диском в сотню гигабайт. Ведь нас интересует только результат расчетов.
Основные возможности
Расширение PipelineDB сложнее для освоения, чем TimescaleDB. В TimescaleDB мы создаем таблицу, говорим ей, что она гипертаблица, и радуемся жизни, используя несколько дополнительных функций, которые предлагает расширение.
PipelineDB решает проблему потоковых вычислений в реляционных БД. Задача потоковой обработки данных сложнее, чем секционирование с точки зрения интеграции и использования. При этом не у всех есть огромные данные и миллиарды строк. Зачем усложнять инфраструктуру, если есть PipelineDB? Расширение предоставляет собственные реализации представлений, стримов, преобразователей и агрегатов для потоковой обработки. Он также интегрируется в планировщик запросов и исполнитель запросов позволяет реализовать концепцию потоковых вычислений в реляционной БД.
Как и TimescaleDB, расширение PipelineDB не накладывает ограничений на SQL в PostgreSQL. Есть несколько особенностей, например, нельзя объединять два стрима, но это и не нужно.
Поддержка вероятностных структур данных и алгоритмов. Расширение использует «Фильтр Блума» для «SELECT DISTINCT», HyperLogLog для «COUNT (DISTINCT)», и T-Digest для «percentile_count()» прямо в SQL. Это повышает производительность.
Экосистема. Расширение позволяет работать с привычными High Availability решениями, средствами мониторинга и всем остальным, что привычно в PostgreSQL.
Учитывая специфику потоковых вычислений, у PipelineDB есть интеграции с Apache Kafka, и с Amazon Kinesis — сервисом аналитики в реальном времени. Так как PipelineDB это больше не форк, а расширение, то и интеграция с остальным зоопарком тоже должна быть «из коробки». Должна, но мы живем не в идеальном мире, и все стоит проверять.
Лицензии и новости
Весь код под лицензией Apache 2.0. Есть платная подписка на суппорт разных тиров, а также кластерная версия с коммерческой лицензией. На базе PipelineDB компания предоставляет сервис аналитики Stride.
Перед тем, как я начал рассказывать про расширение, я сказал, что есть одно «но». Настало время о нем рассказать. 1 мая 2019 команда PipelineDB анонсировала, что теперь входит в состав Confluent. Эта та компания, которая разрабатывает KSQL — движок для потоковой обработки данных в Kafka с SQL синтаксисом. Сейчас там работает Виктор Гамов, со-основатель подкаста Разбор Полетов.
Что из этого следует? PipelineDB заморозили на версии 1.0.0. Кроме исправления критических багов в нем ничего не планируется. Вследствие поглощения ожидаем убер-интеграцию Kafka с PostgreSQL. Возможно, именно Confluent на базе pluggable storage сделают что-нибудь крутое.
Что делать? Переходить в TimescaleDB. В последней версии сделали свои «CONTINUOUS VIEW» с блэкджеком. Конечно, сейчас функциональность не такая крутая, как в PipelineDB, но это вопрос времени.
Подытожим
PipelineDB создан для высокопроизводительной потоковой обработки данных. Он позволяет выполнять вычисления на больших массивах данных без необходимости сохранять сами данные.
С PipelineDB, когда мы отправляем поток данных в PostgreSQL в стрим, то считаем их виртуальными. Мы не сохраняем данные, а агрегируем, вычисляем и отбрасываем. Можно создать сервер на 200 гигабайт и через стримы прогнать террабайты данных. Мы получим результат, но сами данные будут отброшены.
Если по каким-то причинам вам недостаточно «CONTINUOUS VIEW» из TimescaleDB — попробуйте PipelineDB. Это открытый проект под лицензией Apache. Он никуда не денется, хотя и активно больше не разрабатывается. Но все может изменится, Confluent пока не писали о планах по поводу расширения.
Применение TimescaleDB и PipelineDB
С PostgreSQL и двумя расширениями мы можем хранить и обрабатывать большие массивы time series данных. Применений можно придумать много. Давайте рассмотрим пример из моей предметной области — мониторинг транспорта.

Навигационное оборудование непрерывно отправляет телеметрические записи к нам на серверы. Они парсят различные текстовые и бинарные протоколы в общий формат и отправляют данные в Kafka в специальный топик. Оттуда они попадают через интеграцию с PipelineDB в поток данных телеметрии внутри PostgreSQL. Этот поток обновляет представление для текущего состояния транспортных средств и общей аналитики автопарка, а на базе триггера провоцирует запись телеметрических записей в гипертаблицу TimescaleDB.
С расширениями у нас есть три преимущества.
- Аналитика в реальном времени.
- Хранилище time series данных.
- Снижение объема хранимой телеметрии. С помощью мутатора PipelineDB мы агрегируем данные, например, по одной минуте, вычисляя средние значения.
В Grafana есть встроенная поддержка функций TimescaleDB. Поэтому возможно строить графики по бизнес-метрикам прямо из-коробки, вплоть до треков на карте по координатам. Отдел аналитики будет счастлив.
Чтобы «потрогать» все самому, посмотрите демо на GitHub и запустите Docker-образ — внутри сборка из последнего PostgreSQL, TimescaleDB и PipelineDB.
Итого
PostgreSQL позволяет комбинировать различные расширения, а также добавлять свои типы данных и функции для решения конкретных задач. В нашем случае, использование расширений TimescaleDB и PostGIS практически полностью покрывают потребности в хранении time series данных и гео-пространственных расчетах. С расширением PipelineDB мы можем проводить непрерывные вычисления для различной аналитики и статистики, а использование JSONB-столбцов позволяет хранить в реляционной базе слабоструктурированные данные. Open Source решений хватает с головой — коммерческие решения не используем.
Эти расширения практически не накладывают ограничения на экосистему вокруг PostgreSQL, такие как High Availability решения, системы резервного копирования, средства мониторинга и анализа логов. Нам не нужен MongoDB, если есть JSONB-столбцы, и не нужен InfluxDB, если есть TimescaleDB.
Понравилась история от Ивана и хотите поделиться чем-то подобным? Подавайте заявку до 7 сентября на HighLoad++ в Москве. Программа постепенно наполняется. Кроме кейсов по БД, будут доклады по архитектуре, оптимизации и, конечно, высоким нагрузкам. Подавайте доклад до дедлайна, ждем вас среди докладчиков!
Комментарии (14)

Tatikoma
28.08.2019 17:05Спасибо за подробный обзор!
Посмотрел в гугле сравнение TimescaleDB с ClickHouse. Кажется у последнего производительность повыше и места данные занимают значительно меньше.
Как раз стою перед выбором. Пока не могу понять, что лучше использовать.
Vitaly2606
29.08.2019 09:48+1Главный посыл доклада в том, что не стоит спешить с выбором систем, которые, либо еще сырые (для боевой среды), либо ограничены в функционале (тот же SQL), и в котором Вам еще предстоит разобраться (а это уже месяцы и даже годы изучения и практики, для проф уровня).
Т.е. если у Вас используется в инфраструктуре PostgreSQL и Вы хорошо его знаете, то расширение TimescaleDB это прекрасное дополнение к уже богатому функционалу PostgreSQL.
Очень многое зависит от данных, скорости вставки, периода хранения, и т.п.
Но, в большом количестве случаев, будет достаточно PostgreSQL (с расширением TimescaleDB если это Time series данные).

chemtech
28.08.2019 17:31+1binakot Спасибо за доклад.
Вы смотрели в сторону VictoriaMetrics?
Высокая производительность и низкое потребление ресурсов по сравнению с конкурирующими системами. В некоторых тестах VictoriaMetrics опережает InfluxDB и TimescaleDB при выполнение операций вставки и выборки данных до 20 раз. При выполнении аналитических запросов выигрыш по сравнению с реляционными СУБД PostgreSQL и MySQL может составлять от 10 до 1000 раз.

doom369
28.08.2019 20:15Около полугода назад выбирал хранилище для time series данных. Победил кликхаус. Понятно, что он еще сырой, и там есть свои ньюансы. Но таймскейл вообще не порадовал. Особенно грустно, что нету сжатия из коробки. Единственный вариант — это ZFS. Но это гораздо сложнее (ну для меня точно). Получается, что кликхаус из коробки дает 4-10х сжатие. + у кликхаус сжатие есть уже на уровне драйвера, чего насколько я знаю нету в TimescaleDB. То есть трафик по сети тоже будет 4-10х больше чем у кликхауса. Тоже самое касается и производительности.
Vitaly2606
29.08.2019 10:01+1Да, возможно понадобится использовать ZFS.
Но PostgreSQL(+ext. TimescaleDB) и не конкурируют (пока) с тем же ClickHouse по скорости выполнения аналитических запросов, и тем более по уровню сжатия.
Здесь немного про другое. Про возможность хранения данных (time series в данном примере) в реляционной БД. В той же БД, рядом с обычными таблицами.
При этом, остаётся полноценный SQL, все возможности PostgreSQL, и вся его экосистема.doom369
29.08.2019 10:12Да, я понимаю аргументы за. У нас как раз был такой кейс. У нас был постгрес и аналитика, которая агрегировалась на лету (постгрес отлично справлялся). И вот, понадобилось хроанить сырые данные. А сырых данных 100 ГБ в день. И вот получается, что если использовать постгрес, то надо платить за 3ТБ диски за месяц данных. А если килкхаус, то за 300 ГБ. Такие дела. То есть тут даже за аналитику речь еще не заходит. Просто харнить сырые тайм серии сами по себе в постгресе супер дорого выходит.
Vitaly2606
29.08.2019 10:27Если без сжатия, то да.
Я планирую попробовать ZFS с тем же LZ4 сжатием, и посмотреть результаты.
В будущей версии расширения TimescaleDB появится возможность переноса чанков старше N времени на отдельный tablespace. Т.е. к примеру, горячие данные у Вас на SSD, а более старые на более медленных SAS дисках с ZFS файловой системой (со сжатием).
ukt
28.08.2019 22:12Подскажите, чем решение из топика лучше того же постгреса с табличкой из дататайм и необходимых параметров(координаты гпс, например)?
Vitaly2606
29.08.2019 10:11+1Автоматическое управление секциями/чанками (создание, удаление ...).
Оптимизация под Time series данные — более быстрая вставка. Интеграция с планировщиком запросов PG — оптимизация запросов. К примеру, на уровне планирования запроса отсекаются, и не сканируются ненужные чанки.
Посмотрите внимательнее запись этого доклада)
Почитайте статьи в блоге blog.timescale.com
Посмотрите записи докладов www.youtube.com/channel/UCPmHSkid9IOYbdN1Psh24lg
Почитайте доку docs.timescale.com/latest/main
Найдёте ответ.

worldmind
29.08.2019 10:12В статье об этом написано, стоит почитать, как минимум была речь про скорость вставки.
pawlo16
29.08.2019 18:58При выборе бд для временнЫх рядов руководствуюсь общим подходом к решению дилеммы Sql/NoSql. Если метаданные содержат исключительно независимую атомарную инфу, как то — метрики, логи, аналитика — берём NoSql. Даже если в фирме больше экспертизы по Sql. По факту того, что NoSql проще в деплое и зачастую проще для разработчиков. При этом выбор конкретной noSql субд носит второстепенный характер имхо, если конечно речь не идёт о мегахайлоаде.
Если же в одной из колонок есть бизнес данные, например, серийный номер конечного продукта, с которого снимается рабочий сигнал (а конечный продукт в моём кейсе имеет контролируемые параметры, привязан к партии аналогичных продуктов, в составе которой он выпускается в эксплуатацию и т.д.) — то строго Sql. Поскольку данные в измерении не атомарны, и поддерживать согласованность всё равно придётся так или иначе. Зачем согласовывать вручную, если для этого есть целый Sql — вопрос риторическийworldmind
29.08.2019 19:03Если метаданные содержат исключительно независимую атомарную инфу, как то — метрики
если это метрики мониторинга серверов, то там есть идентификатор сервераpawlo16
29.08.2019 19:59в самих метриках нас не особо волнует то, что связано с сервером. Это уже при детализации может потребоваться.
worldmind
Весьма прикольные штуки, жаль вторая заморозилась.