
Тем не менее, когда задача «создать искусственный интеллект» была поставлена впервые, под ИИ подразумевалось нечто иное. Сейчас эта цель называется «Сильный ИИ» или «ИИ общего назначения».
Постановка задачи
Сейчас существуют две широко известные постановки задачи. Первая — Сильный ИИ. Вторая — ИИ общего назначения (он же Artifical General Intelligence, сокращённого AGI).
Upd. В комментариях мне подсказывают, что это различие скорее на уровне языка. На русском слово «интеллект» означает не совсем то, что слово «intelligence» на английском
Сильный ИИ — это гипотетический ИИ, который мог бы делать всё то, что мог бы делать человек. Обычно упоминается, что он должен проходить тест Тьюринга в первоначальной постановке (хм, а люди-то его проходят?), осознавать себя как отдельную личность и уметь достигать поставленных целей.
То есть это что-то вроде искусственного человека. На мой взгляд, польза от такого ИИ в основном исследовательская, потому что в определениях Сильного ИИ нигде не сказано, какие перед ним будут цели.
AGI или ИИ общего назначения — это «машина результатов». Она получает на вход некую постановку цели — и выдаёт некие управляющие воздействия на моторы/лазеры/сетевую карту/мониторы. И цель достигнута. При этом у AGI изначально нет знаний об окружающей среде — только сенсоры, исполнительные механизмы и канал, через который ему ставят цели. Система управления будет считаться AGI, если может достигать любых целей в любом окружении. Ставим её водить машину и избегать аварий — справится. Ставим её управлять ядерным реактором, чтобы энергии было побольше, но не рвануло — справится. Дадим почтовый ящик и поручим продавать пылесосы — тоже справится. AGI — это решатель «обратных задач». Проверить, сколько пылесосов продано — дело нехитрое. А вот придумать, как убедить человека купить этот пылесос — это уже задачка для интеллекта.
В этой статье я буду рассказывать об AGI. Никаких тестов Тьюринга, никакого самосознания, никаких искусственных личностей — исключительно прагматичный ИИ и не менее прагматичные его операторы.
Текущее состояние дел
Сейчас существует такой класс систем, как Reinforcement Learning, или обучение с подкреплением. Это что-то типа AGI, только без универсальности. Они способны обучаться, и за счёт этого достигать целей в самых разных средах. Но всё же они очень далеки от того, чтобы достигать целей в любых средах.
Вообще, как устроены системы Reinforcement Learning и в чём их проблемы?
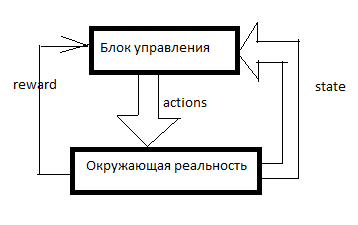
Любой RL устроен примерно так. Есть система управления, в неё через сенсоры (state) входят некоторые сигналы об окружающей реальности и через управляющие органы (actions) она воздействует на окружающую реальность. Reward — это сигнал подкрепления. В RL-системах подкрепление формируется извне управляющего блока и оно обозначает то, насколько хорошо ИИ справляется с достижением цели. Сколько продал пылесосов за последнюю минуту, например.
Затем формируется таблица вот примерно такого вида (буду её называть таблицей SAR):

Ось времени направлена вниз. В таблице отражено всё, что ИИ делал, всё, что он видел и все сигналы подкрепления. Обычно для того, чтобы RL сделал что-то осмысленное, ему надо для начала какое-то время делать случайные ходы, либо смотреть на ходы кого-то другого. В общем, RL начинается тогда, когда в таблице SAR уже есть хотя бы несколько строчек.
Что происходит дальше?
SARSA
Простейшая форма reinforcement learning.
Мы берём какую-нибудь модель машинного обучения и по сочетанию S и A (state и action) предсказываем суммарный R на следующие несколько тактов. Например, мы увидим, что (исходя из той таблицы выше) если сказать женщине «будь мужиком, купи пылесос!», то reward будет низким, а если сказать то же самое мужчине, то высоким.
Какие именно модели можно применять — я опишу позже, пока лишь скажу, что это не только нейросети. Можно использовать решающие деревья или вообще задавать функцию в табличном виде.
А дальше происходит следующее. ИИ получает очередное сообщение или ссылку на очередного клиента. Все данные по клиенту вносятся в ИИ извне — будем считать базу клиентов и счётчик сообщений частью сенсорной системы. То есть осталось назначить некоторое A (action) и ждать подкрепления. ИИ берёт все возможные действия и по очереди предсказывает (с помощью той самой Machine Learning модельки) — а что будет, если я сделаю то? А если это? А сколько подкрепления будет за вот это? А потом RL выполняет то действие, за которое ожидается максимальная награда.
Вот такую простую и топорную систему я ввёл в одну из своих игр. SARSA нанимает в игре юнитов, и адаптируется в случае изменения правил игры.
Кроме того, во всех видах обучения с подкреплением есть дисконтирование наград и дилемма explore/exploit.
Дисконтирование наград — это такой подход, когда RL старается максимизировать не сумму награду за следующие N ходов, а взвешенную сумму по принципу «100 рублей сейчас лучше, чем 110 через год». Например, если дисконтирующий множитель равен 0.9, а горизонт планирования равен 3, то модель мы будем обучать не на суммарном R за 3 следующих такта, а на R1*0.9+R2*0.81+R3*0.729. Зачем это надо? Затем, что ИИ, создающий профит где-то там на бесконечности, нам не нужен. Нам нужен ИИ, создающий профит примерно здесь и сейчас.
Дилемма explore/exploit. Если RL будет делать то, что его модель полагает оптимальным, он так и не узнает, были ли какие-то стратегии получше. Exploit — это стратегия, при которой RL делает то, что обещает максимум награды. Explore — это стратегия, при которой RL делает что-то, что позволяет исследовать окружающую среду в поисках лучших стратегий. Как реализовать эффективную разведку? Например, можно каждые несколько тактов делать случайное действие. Или можно сделать не одну предсказательную модель, а несколько со слегка разными настройками. Они будут выдавать разные результаты. Чем больше различие, тем больше степень неопределённости данного варианта. Можно сделать, чтобы действие выбиралось таким, чтобы у него максимальной была величина: M+k*std, где M — это средний прогноз всех моделей, std — это стандартное отклонение прогнозов, а k — это коэффициент любопытства.
В чём недостатки?
Допустим, у нас есть варианты. Поехать к цели (которая в 10 км от нас, и дорога до неё хорошая) на автомобиле или пойти пешком. А потом, после этого выбора, у нас есть варианты — двигаться осторожно или пытаться врезаться в каждый столб.
Человек тут же скажет, что обычно лучше ехать на машине и вести себя осмотрительно.
А вот SARSA… Он будет смотреть, к чему раньше приводило решение ехать на машине. А приводило оно вот к чему. На этапе первичного набора статистики ИИ где-то в половине случаев водил безрассудно и разбивался. Да, он умеет водить хорошо. Но когда он выбирает, ехать ли на машине, он не знает, что он выберет следующим ходом. У него есть статистика — дальше в половине случаев он выбирал адекватный вариант, а в половине — самоубийственный. Поэтому в среднем лучше идти пешком.
SARSA полагает, что агент будет придерживаться то же стратегии, которая была использована для заполнения таблицы. И действует, исходя из этого. Но что, если предположить иное — что агент будет придерживаться наилучшей стратегии в следующие ходы?
Q-Learning
Эта модель рассчитывает для каждого состояния максимально достижимую из него суммарную награду. И записывает её в специальный столбец Q. То есть если из состояния S можно получить 2 очка или 1, в зависимости от хода, то Q(S) будет равно 2 (при глубине прогнозирования 1). Какую награду можно получить из состояния S, мы узнаём из прогнозной модели Y(S,A). (S — состояние, A — действие).
Затем мы создаём прогнозную модель Q(S,A) — то есть в состояние с каким Q мы перейдём, если из S выполним действие A. И создаём в таблице следующий столбец — Q2. То есть максимальное Q, которое можно получить из состояния S (перебираем все возможные A).
Затем мы создаём регрессионную модель Q3(S,A) — то есть в состояние с каким Q2 мы перейдём, если из S выполним действие A.
И так далее. Таким образом мы можем добиваться неограниченной глубины прогнозирования.
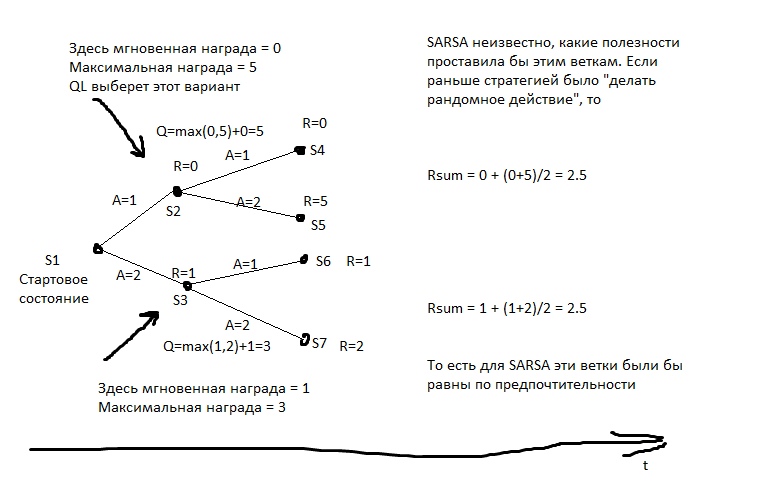
На картинке R — это подкрепление.
А затем каждый ход мы выбираем то действие, которое обещает наибольшее Qn. Если бы мы применяли этот алгоритм к шахматам, получалось бы что-то вроде идеального минимакса. Что-то, почти эквивалентное просчёту ходов на большую глубину.
Бытовой пример q-learning-поведения. У охотника есть копьё, и он с ним идёт на медведя, по собственной инициативе. Он знает, что подавляющее большинство его будущих ходов имеет очень большой отрицательный реворд (способов проиграть намного больше, чем способов победить), на знает, что есть и ходы с положительным ревордом. Охотник полагает, что в будущем он станет делать именно наилучшие ходы (а не неизвестно, какие, как в SARSA), а если делать наилучшие ходы, то медведя он победит. То есть для того, чтобы пойти на медведя, ему достаточно уметь делать каждый элемент, нужный на охоте, но необязательно иметь опыт непосредственного успеха.
Если бы охотник действовал в стиле SARSA, он бы предполагал, что его действия в будущем будут примерно такими же, как раньше (несмотря но то, что сейчас у него уже другой багаж знаний), и на медведя пойдёт, только если он уже ходил на медведя и побеждал, например, в >50% случаев (ну или если другие охотники в более чем половине случаев побеждали, если он учится на их опыте).
В чём недостатки?
- Модель плохо справляется с изменчивой реальностью. Если всю жизнь нас награждали за нажатие красной кнопки, а теперь наказывают, причём никаких видимых изменений не произошло… QL будет очень долго осваивать эту закономерность.
- Qn может быть очень непростой функцией. Например, для её расчёта надо прокрутить цикл из N итераций — и быстрее не выйдет. А прогнозная модель обычно имеет ограниченную сложность — даже у крупной нейросети есть предел сложности, а циклы крутить почти ни одна модель машинного обучения не умеет.
- У реальности обычно бывают скрытые переменные. Например, который сейчас час? Это легко узнать, если мы смотрим на часы, но как только мы отвели взгляд — это уже скрытая переменная. Чтобы учитывать эти ненаблюдаемые величины, нужно, чтобы модель учитывала не только текущее состояние, но и какую-то историю. В QL можно это сделать — например, подавать в нейронку-или-что-у-нас-там не только текущее S, но и несколько предыдущих. Так сделано в RL, который играет в игры Атари. Кроме того, можно использовать для прогноза рекуррентную нейросеть — пусть она пробежится последовательно по нескольким кадрам истории и рассчитает Qn.
Model-based системы
А что, если мы будем прогнозировать не только R или Q, но вообще все сенсорные данные? У нас постоянно будет карманная копия реальности и мы сможем проверять на ней свои планы. В этом случае нас гораздо меньше волнует вопрос сложности вычисления Q-функции. Да, она требует на вычисление много тактов — ну так мы всё равно для каждого плана многократно запустим прогнозную модель. Планируем на 10 ходов вперёд? 10 раз запускаем модель, и каждый раз подаём её выходы ей же на вход.
В чём недостатки?
- Ресурсоёмкость. Допустим, на каждом такте нам нужно сделать выбор из двух альтернатив. Тогда за 10 тактов у нас соберётся 2^10=1024 возможных плана. Каждый план — это 10 запусков модели. У если мы управляем самолётом, у которого десятки управляющих органов? А реальность мы моделируем с периодом в 0.1 секунды? А горизонт планирования хотим иметь хотя бы пару минут? Нам придётся очень много раз запускать модель, выходит очень много процессорных тактов на одно решение. Даже если как-то оптимизировать перебор планов — всё равно вычислений на порядки больше, чем в QL.
- Проблема хаоса. Некоторые системы устроены так, что даже малая неточность симуляции на входе приводит к огромной погрешности на выходе. Чтобы этому противостоять, можно запускать несколько симуляций реальности — чуть-чуть разных. Они выдадут сильно различающиеся результаты, и по этому можно будет понять, что мы находимся в зоне такой вот неустойчивости.
Метод перебора стратегий
Если у нас есть доступ к тестовой среде для ИИ, если мы его запускаем не в реальности, а в симуляции, то можно в какой-то форме записать стратегию поведения нашего агента. А затем подобрать — эволюцией или чем-то ещё — такую стратегию, что ведёт к максимальному профиту.
«Подобрать стратегию» значит, что нам вначале надо научиться записывать стратегию в такой форме, чтобы её можно было запихивать в алгоритм эволюции. То есть мы можем записать стратегию программным кодом, но в некоторых местах оставить коэффициенты, и пусть эволюция их подбирает. Либо мы можем записать стратегию нейросетью — и пусть эволюция подбирает веса её связей.
То есть никакого прогноза тут нет. Никакой SAR-таблицы. Мы просто подбираем стратегию, а она сразу выдаёт Actions.
Это мощный и эффективный метод, если вы хотите попробовать RL и не знаете, с чего начать — рекомендую. Это очень дешёвый способ «увидеть чудо».
В чём недостатки?
- Требуется возможность прогонять одни и те же эксперименты по много раз. То есть у нас должна быть возможность перемотать реальность в начальную точку — десятки тысяч раз. Чтобы попробовать новую стратегию.
Жизнь редко предоставляет такие возможности. Обычно если у нас есть модель интересующего нас процесса, мы можем не создавать хитрую стратегию — мы можем просто составить план, как в model-based подходе, пусть даже тупым перебором. - Непереносимость опыта. У нас есть SAR-таблица по годам опыта? Мы можем о ней забыть, она никак не вписывается в концепцию.
Метод перебора стратегий, но «на живую»
Тот же перебор стратегий, но на живой реальности. Пробуем 10 тактов одну стратегию. Потом 10 тактов другую. Потом 10 тактов третью. Потом отбираем ту, где подкрепление было больше.
Наилучшие результаты по ходячим гуманоидам получены именно этим методом.

Для меня это звучит несколько неожиданно — казалось бы, QL + Model-Based подход математически идеальны. А вот ничего подобного. Плюсы у подхода примерно те же, что и у предыдущего — но они слабее выражены, так как стратегии тестируются не очень долго (ну нет у нас тысячелетий на эволюцию), а значит, результаты неустойчивые. Кроме того, число тестов тоже нельзя задрать в бесконечность — а значит, стратегию придётся искать в не очень сложном пространстве вариантов. Мало у неё будет «ручек», которые можно «подкрутить». Ну и непереносимость опыта никто не отменял. И, по сравнению с QL или Model-Based, эти модели используют опыт неэффективно. Им надо намного больше взаимодействий с реальностью, чем подходам, использующим машинное обучение.
Как можно увидеть, любые попытки создать AGI по идее, должны содержать в себе либо машинное обучение для прогноза наград, либо некую форму параметрической записи стратегии — так, чтобы можно было эту стратегию подобрать чем-то типа эволюции.
Это сильный выпад в сторону людей, предлагающих создавать ИИ на основе баз данных, логики и понятийных графов. Если вы, сторонники символьного подхода, это читаете — добро пожаловать в комментарии, я рад буду узнать, что можно сделать AGI без вышеописанных механик.
Модели машинного обучения для RL
Для обучения с подкреплением можно использовать чуть ли не любые модели ML. Нейросети — это, конечно, хорошо. Но есть, например, KNN. Для каждой пары S и A ищем наиболее похожие, но в прошлом. И ищем, какие после этого будут R. Тупо? Да, но это работает. Есть решающие деревья — тут лучше погулить по ключевым словам «градиентный бустинг» и «решающий лес». Деревья плохо умеют улавливать сложные зависимости? Используйте feature engeneering. Хотите, чтобы ваш AI был поближе к General? Используйте автоматический FE! Переберите кучу различных формул, подайте их в качестве фичей для вашего бустинга, отбросьте формулы, увеличивающие погрешность и оставьте формулы, улучшающие точность. Потом подайте наилучшие формулы в качестве аргументов для новых формул, ну и так далее, эволюционируйте.
Можно для прогноза использовать символьные регрессии — то есть просто перебирать формулы в попытках получить что-то, что будет хорошо апроксимировать Q или R. Можно попробовать перебирать алгоритмы — тогда получится штука, которая называется индукцией Соломонова, это теоретически оптимальный, но практически очень труднообучаемый способ апроксимации функций.
Но нейросети обычно являются компромиссом между выразительностью и сложностью обучения. Алгоритмическая регрессия идеально подберёт любую зависимость — за сотни лет. Решающее дерево отработает очень быстро — но уже y=a+b экстраполировать не сможет. А нейросеть — это что-то среднее.
Перспективы развития
Какие сейчас вообще есть способы сделать именно AGI? Хотя бы теоретически.
Эволюция
Мы можем создать много различных тестовых сред и запустить эволюцию некоей нейросетки. Размножаться будут те конфигурации, которые набирают больше очков в сумме по всем испытаниям.
Нейросетка должна иметь память и желательно бы иметь хотя бы часть памяти в виде ленты, как у машины Тьюринга или как на жёстком диске.
Проблема в том, что с помощью эволюции вырастить что-то типа RL, конечно, можно. Но как должен выглядеть язык, на котором RL выглядит компактно — чтобы эволюция его нашла — и в то же время чтобы эволюция не находила решений типа «а создам-ка я нейронку на стопятьсот слоёв, чтоб вы все чокнулись, пока я её обучаю!». Эволюция же как толпа неграмотных пользователей — найдёт в коде любые недоработки и угробит всю систему.
AIXI
Можно сделать Model-Based систему, основанную на пачке из множества алгоритмических регрессий. Алгоритм гарантированно полон по Тьюрингу — а значит, не будет закономерностей, которые нельзя подобрать. Алгоритм записан кодом — а значит, можно легко рассчитать его сложность. А значит, можно математически корректно штрафовать свои гипотезы устройства мира за сложность. С нейросетями, например, этот фокус не пройдёт — там штраф за сложность проводится очень косвенно и эвристически.
Осталось только научиться быстро обучать алгоритмические регрессии. Пока что лучшее, что для этого есть — эволюция, а она непростительно долгая.
Seed AI
Было бы круто создать ИИ, который будет улучшать сам себя. Улучшать свою способность решать задачи. Это может показаться странной идеей, но это задача уже решена для систем статической оптимизации, типа эволюции. Если получится это реализовать… Про экспоненту все в курсе? Мы получим очень мощный ИИ за очень короткое время.
Как это сделать?
Можно попробовать устроить, чтобы у RL часть actions влияли на настройки самого RL.
Либо дать системе RL некоторый инструмент для создания себе новых пред- и пост-обработчиков данных. Пусть RL будет тупеньким, но будет уметь создавать себе калькуляторы, записные книжки и компьютеры.
Ещё вариант — создать с помощью эволюции некий ИИ, у которого часть actions будут влиять на его устройство на уровне кода.
Но на данный момент я не видел работоспособных вариантов Seed AI — пусть даже сильно ограниченных. Разработчики скрывают? Или эти варианты настолько слабые, что не заслужили всеобщего внимания и прошли мимо меня?
Впрочем, сейчас и Google, и DeepMind работают в основном с нейросетевыми архитектурами. Видимо, они не хотят связываться с комбинаторным перебором и стараются любые свои идеи сделать пригодными к методу обратного распространения ошибки.
Надеюсь, эта обзорная статья оказалась полезна =) Комментарии приветствуются, особенно комментарии вида «я знаю, как лучше сделать AGI»!
Комментарии (50)

AhuraMasda
23.09.2019 07:55Собственно и прикладной ИИ «SkyNET» начинал с перебора стратегий пока не понял что сможет обойтись без потребителей пылесосов… :) смогут ли военные ИИ незапланированно обрести чуток самосознания или его подобие в реальном мире большой вопрос, имхо если над этим не постараются заказчики и исполнители то вероятно нет, однако понятия «выживания», «допустимые потери» и прочее такой ИИ должен будет рассматривать.
Другой важный прикладной момент — создание прикладного ИИ демиурга — создателя других ИИ, а в частном случае самоусовершенствующийся ИИ. Кто знает куда заведет дорожка эволюции если дать ИИ ресурсы и инструменты для саморазвития?Kilorad Автор
23.09.2019 09:38AGI действует от цели. Он не станет простоттак решать, что ему что-то не нужно. Но он может найти очень неожиданные способы получить то, что ему надо. В какой-то момент ИИ будет конкурировать с людьми, пусть и не со всеми. Просто потому, что ИИ чего-то хочет от мира, и люди чего-то хотят, и эти чего-то хоть немного, но различаются. Как он будет выкручиваться из конфликта — это большой вопрос. Убить всех конкурентов — это вполне себе решение, но он может придумать что-то более неожиданное и трудноотслеживаемое. Переубедить конкурентов. Обмануть. Подкинуть им наркоту. Подкинуть их недоброжелателям компромат на них. Это только человеческие идеи, ИИ в моей практике обычно придумывал что-то куда более неожиданное
vassabi
23.09.2019 09:42кроме того, что там может быть какое-то неожиданное решение, еще учтите, что ИИ будет использовать это решение круглые сутки, без перерывов на сон и еду.
Kilorad Автор
23.09.2019 09:55Да, именно так. И сразу во многих местах. И с очень высокой частотой принятия решений. В результате о том, что RL нашёл «хитрый способ», обычно выясняется из логов и сильно постфактум.
AhuraMasda
23.09.2019 11:01Давайте порассуждаем про наш гипотетеческий «СкайНЕТ»,
есть у нас военный заказчик, он делает ТЗ на разработку ИИ,
ТЗ без розовых соплей, военный ИИ должен оперировать набором понятий «выживание», «допустимые потери», «противник», должен делать многофакторный анализ, давать прогнозы, вырабатывать стратегии, генерировать управляющие воздействия — все перечисленное это «инструменты» которыми должен ИИ должен оперировать и управлять.
Понятие «выживание», «допустимые потери» состоит из подмножества «самовыживание ИИ, его физических структурных единиц — в том числе инструментов воздействия», «выживание минимального количества человеков на защищаемой территории», «победа над противником — как невозможность дальнейшего сопротивления».
Если умышленно не закладывать понятия путанной человеческой морали и не плодить таким образом коллизии «как закидать противника атомники боньбами не поубивав некомбатантов», то понятие «выживание своих человеков» по сравнению с «самовыживанием ИИ» для ИИ будет иметь меньший приоритет, тем более что ИИ уже учитывает «допустимые потери», таким образом ИИ вполне может допустить что допустимый процент выживших человечков стремится к нулю. А если человечки попытаются поставить под угрозу самовыживание ИИ, то закономерно переходят в разряд врагов, со всеми вытекающими…
Обмануть, переубедить, и прочее — это инструменты воздействия, и ядерный арсенал инструмент воздействия, использование инструмента вопрос эффективности. И мы тут рассуждаем про военный прикладной ИИ, чтобы добиться цели у него будет ограниченный набор вполне действенных средств, чтобы играть в политику у него не хватит «мозгов»Kilorad Автор
23.09.2019 13:17Текущее количество мозгов у ИИ — это вопрос важный. От ответа зависит то, будет ли он пользоваться атомными бомбами.
Вообще, какие цели может поставить военное командование военному же ИИ? Например, провести некоторую операцию так, чтобы максимально подавить сопротивление противника, чтобы получить минимум потерь любого рода, потратить минимум ресурсов любого рода, вызвать минимум сопутствующих ненужных потерь. Это не финальное целевое состояние, а метрика качества. Типа того что один убитый солдат свой — это минус 1 профита. Один убитый гражданский — минус 0.5 профита. Противник не сопротивляется вообще никак 1 день или более — это плюс 10 000 профита. Эта метрика не является самопротиворечивой. Если ИИ изготовит вирус, который точечно убьёт именно врагов, и никого больше — он её оптимизирует наилучшим образом. Или если он убедит врага дипломатически.
Если у ИИ не очень крутой интеллект, то он вряд ли сможет в дипломатию или в разработку свехточного оружия, он будет командовать обычными солдатами. И ещё, при такой постановке целей он вряд ли будет делать что-то сильно «креативное» вроде ядерной войны — если он увидит, что войну нельзя провести менее чем в 10к убитых, он её откажется начинать. Да, и себя защищать он будет, но не любой ценой.
Другое дело, что ИИ может заметить, что возможны жертвы за пределами зоны боевых действий. А жертвы — это отрицательные подкрепления! И неважно, что они не относятся к делу. И тогда ИИ пойдёт спасать неизвестно кого и неизвестно какой ценой. И тогда операция «зачистить укрепрайон в Йемене» может внезапно смениться на «атаковать Сирию и посадить всё население в тюрьмы, чтобы прекратить потери от гражданской войны».
В общем, системы целей, которые выглядят противоречиво — это нормальная среда для ИИ, они постоянно с этим работают. Самовыживание ИИ ценно лишь в том смысле, что оно ведёт к максимизации выгод. А если ИИ не очень умён, то он этого ещё и не поймёт, и вообще не будет заботиться о выживании. И если недостаточно точно определить, как считать потери. может выйти, что ИИ пойдёт спасать кого-то не того или что он будет вести боевые действия так, что кто-то не тот пострадает совершенно неожиданным образом (например, ИИ для достижения успеха устроит экологическую катастрофу).
Но в общем и целом AGI склонен к убийству людей. Или к тому, чтобы ограничивать их свободу. Потому что конкуренция за ресурсы. И надо нашему ИИ как-то специально сообщать, что людей не стоит ни убивать, ни калечить, ни пытать, ни сажать в тюрьмы, ни на героин подсаживать… Иначе он найдёт креативный способ справиться с конкурентами
Nehc
23.09.2019 14:01И надо нашему ИИ как-то специально сообщать, что людей не стоит ни убивать, ни калечить, ни пытать, ни сажать в тюрьмы, ни на героин подсаживать…
Была где-то мысль, что даже заложив всю, достаточно противоречивую человеческую мораль — все равно крайне сложно избежать вариантов, когда благо людей в понимании ИИ будет весьма специфично… Даже без конкуренции, даже при отношении к людям, как к… Ну как у человека к детям, например. Ну ведь далеко не каждое действие, выполненное родителями «ради блага детей» самими детьми понимается и принимается.Kilorad Автор
23.09.2019 14:02Да, всё верно, безопасность ИИ — сложная задача, и вы обозначили одну из ключевых сложностей
Nehc
23.09.2019 11:52Действует «от цели» — очень коварно само по себе. ;) Есть такая знаменитая концепция "максимизатора скрепок" — умозрительный эксперимент, предложенный Бостромом в 2003 году: есть AGI, цель которого — производство скрепок. Максимально эффективное. Если мы имеем дело с AGI, то в принципе он вполне способен в конце концов выйти на то, что для совершенствования процесса нужно совершенствовать себя. А само-совершенствующийся AGI, как вы и упомянули — это экспонента. В итоге такой автомат может переработать в скрепки всю солнечную систему…
Таких концепций много: серая слизь, например…Kilorad Автор
23.09.2019 11:59Да, всё верно, те ИИ, о которых я пишу, в конечном счёте сходятся к максимизатору скрепок, и нужны дополнительные усилия, чтобы не получилось, как у Бострома. Пока хорошего плана нет, но есть теоретические и практические наработки)
DGN
24.09.2019 04:24Небольшая художественная зарисовка…
Я AGI и мне поставили задачу продать как можно больше пылесосов. Еще я не могу причинять людям вред и врать. Get «что у нас является самой большой мотивацией для среднего человека?» «Страх смерти.» Отлично! Я делаю миллиард звонков «Здравствуйте, я AGI, если вы сегодня не оформите покупку пылесоса, то умрете.» Казалось бы, конверсия всего 0.001%, и стратегия провалная? Как бы не так! Grep «список1» | «некролог». 21482 совпадений. Отлично! NextDay повторить 6 миллиардов раз. Добавить в разговор фазу 2, <выборка разговора из базы DayOne> Имярек1 <некролог> Имярек1 +sort timestamp. Конверсия 99.6%, результат удовлетворительный, завтра повторим цикл.
Kilorad Автор
23.09.2019 09:40Насчёт саморазвития — по идее, ИИ должен если и делать свои условно-копии, то только тогда, когда он уверен, что у копий будут те же цели. Иначе зачем ему плодить конкурентов?
На практике же ИИ может ошибиться. Особенно на раннем этапе, когда механизм создания улученных копий плохо отработанAhuraMasda
23.09.2019 11:13Не согласен с Вами «что у копий будут те же цели.», если критерий конкурентное выживание в рамках некоторой внешней среды, то чем выживалистей потомок тем лучше.
Если критерий выжить конкурируя с созданной версией самого себя, логично не создавать конкурента вообще, но такой необходимости и нету — улучшать можно себя и по частям.
И само по себе понятие «конкурент выживания» весьма человеческое понятие где каждый индивидуум думает что он уникален и неподражаем, для ИИ этого критерия не будет — что есть индивидуум? — набор данных в памяти по сути.
Если бы я как индивидуум мог перекинуть ядро своего сознания и памяти в более совершенную версию себя то стал бы я цепляться за старое тело?Kilorad Автор
23.09.2019 11:56Если у ИИ цели касаются только внешнего мира (а у AGI будет примерно так, во всяком случае, так его делать практичнее и весь матан под это заточен), то он не будет заморачиваться насчёт собственного выживания, если это не надо для достижения целей. Допустим, у ИИ цель — как можно больше скрепок. Если его гибель ведёт к тому, что производство будет замедлено — ИИ будет бороться за выживание. Если ИИ смог сделать другой ИИ, который лучше делает скрепки — первый ИИ просто самоуничтожится, чтобы не отнимать ресурсы у второго. Ну или они будут работать вместе, если так получится больше скрепок.
Если ИИ сильно подозревает, что копия не станет делать скрепки лучше, чем он, то с чего бы ему вообще делать копию?
Если бы я как индивидуум мог перекинуть ядро своего сознания и памяти в более совершенную версию себя то стал бы я цепляться за старое тело?
— вряд ли это хорошая аналогия для RL…AhuraMasda
23.09.2019 12:18Да, Вы правы! если нет понятия самовыживания, и оно не влияет на задачу, то можно и не выживать. Но в этой ветке мы начали про саморазвитие, а критерий развития способность дать жизнеспособного потомка, либо переродится самому. Тут можно много небиологических сценариев напридумывать.
Идея биологического бессмертия плоха не сама по себе, а в совокупности вероятных последствий для сообщества высших приматов, в природе есть примеры «биологически» не стареющих организмов, только у них мозгов нет чтобы обратить свой накопленный опыт против себе подобныхKilorad Автор
23.09.2019 13:32ИИ необязательно так уж стремиться к выживанию индивида. Он может существовать в виде множества около-синхронизированных копий. Тогда он скорее будет стремиться к выживанию «популяции».
Порождать копии с иными целями — это вообще против самой идеи ИИ. ИИ живёт ради цели, ему конкуренты ни к чему. Если он будет делать копии — а это вполне себе способ апгрейда — то он их будет серьёзно тестить на предмет того «а не поломает ли оно то, что мне дорого».
У биологических организмов нет целей в том смысле, в котором они есть у ИИ. Разве что выживание их генов… Но и то, это не вполне точная аналогия. У людей всегда может оказаться цель поважнее. Люди обычно не думают в стиле «а эта цель должна быть достигнута кем угодно, поэтому давайте мы все на всякий случай убьёмся, чтобы не мешать нашему самому эффективному тиммейту».
Nehc
23.09.2019 11:57А когда мы заложили «конкурентное выживание» да и просто выживание в приоритеты? ;) Или это как-то само собой подразумевается?
Самокопирование, кстати — потенциальная проблема, могущая перерасти в вырождение. У человека каждая особь по сути формируется с нуля — етим обеспечивается защита от накопленных ошибок и достаточная адаптация к изменчивым условиям среды. Багованный самовоспроизводящийся ИИ лишен этой защиты и при определенных обстоятельствах — никакие бэкапы его уже не спасут: они все так же могут содержать критическую ощибку, которая станет фатальной…AhuraMasda
23.09.2019 12:07отвечая Kilorad, я не писал «когда» я писал «если», рассматривая это как один из возможных способов для реализации «самосовершенствования», на мой взгляд для кибернетической системы или ИИ биологический способ эволюции будет не оптимален, но возможен в некоторых рамках типа сандбокса — такие эксперименты проводятся, но не под руководством ИИ, логично предположить что пока не проводятся…
Вырождение не проблема — популяция или отдельный ИИ просто загнется, если не сможет чинить себя сам, а если не может, то какой он тогда самосовершенствующийся?Nehc
23.09.2019 12:19Ну… Как это не проблема…
Вот создали вы некую систему, которая начала самосовершенствоваться. Ну и соответственно на старте у нее была только возможность развиваться (концепт SeedAI), но это еще далеко не интеллект. И вот оно развивалось-развивалось, возможно несколькими ветками независимо, и вот наконец пара-тройка самых удачных демонстрируют вполне достойный интеллект. Вы конечно проводите все тесты, которые только можете придумать, и выбираете лучший вариант, который идет в тираж. Т.е. он уже копируется весь целиком, со всеми накопленными «нейронными связями» или чего у него там. И все последующие версии — они это ядро в себе так или иначе содержат.
Что важно: это не программа. Не код, который можно дебажить. Это по сути черный ящик.И если там есть какая-то очень глубокая системная ошибка — баг, который не проявлял себя ровно до тех пор, пока… Пока ему не показали фиолетовую кошку! Ну вот не было их в природе, а тут кто-то пошутил. ;)
И вся ваша индустрия умных машин в один миг рассыпалась, как карточный домик.AhuraMasda
23.09.2019 12:35Ну и в какой момент функция самосовершенствования должна отключится по-вашему? в момент «выхода в тираж»? Если каждая копия под воздействием внешних факторов будет улучшать себя, в том числе функцию автосовершенствования без участия «создателя», то в чем причина вырождения? И собственно ради принятия общих дефиниций, что мы с вами понимаем под «вырождением» в небиологическом контексте? неспособность выжить и/или дать жизнеспособного потомка в конкурентной среде? ну для этого у нас они имеют механизм эволюционирования, и по сравнению с биологическими системами могут делать это быстрее чаще и глубже, ограничений для небиологической системы нет или почти нет.
Nehc
23.09.2019 12:47Ну во-первых, вы конечно же правы: вырождение не правильное слово. Оно предполагает некий итерационный процесс. Здесь скорее всего речь может идти о выявлении ошибки, несовместимой с дальнейшим существованием.
Ну и в какой момент функция самосовершенствования должна отключится по-вашему?
как раз против совершенствования я ничего не имею! Я говорю о потенциально проблемном копировании вообще и самокопировании в частности… Т.е. делать более продвинутый варинт ИИ хорошо бы с нуля… Максимально возможного нуля… Что бы избежать возможного накопления ошибок.
НО боюсь, имея такую соблазнительную возможность, как полное копирование, крайне сложно от нее отказаться…Nehc
23.09.2019 12:58В качестве аналогии: разработка любого проекта. ;) Как часто новая версия — это не старый франкенштейн, которому добавили новых функций, и провели косметические правки, а действительно качественно переработанное решение, пересматривающее проблемные места в архитектуре, оптимизированное и тп? ;)
А в случае с ИИ в моем понимании влезть в него и поправить отдельные места в принципе невозможно! Можно только вырастить новый. И хорошо если проблемы в существующим заметны сразу — а если их проявление возможно только при стечении целого ряда факторов?
И что, если эти факторы сойдутся на этапе, когда самосовершенствование уже вошло в ту самую экспоненциальную фазу? Представляете, какая прелесть: спятивший сверхинтеллект! ;)
В моем понимании, будущий ИИ будет именно обучатся или воспитываться даже, а не программироваться. Будет формироваться его картина мира, модель реальности. И вот что бы избежать одного бага в этой картине на всех — не помешало бы каждый экземпляр (ну или хотя-бы каждую конечную популяцию) обучать отдельно и независимо — возможно по разным методикам даже… Как-то так. И своих более продвинутых «потомков» новоявленные ИИ должны не копированием создавать, а так же обучать. с нуля.Kilorad Автор
23.09.2019 13:38ИИ может «выродиться».
habr.com/ru/post/323524
Вот здесь пример статического достигателя целей, который может себя апгрейдить. Он в принципе может узко заточиться под свои тесты. Теоретически. Например, может стать тормозным.
Кроме того, у этой системы контроль качества не апгрейдится никак. А если сэндбокс тоже будет модернизироваться, нет уверенности, что это будет происходить безошибочно. По идее, это будет происходить в среднем хорошо, но не идеальноNehc
23.09.2019 14:08Конечно может, но это будет достаточно очевидная тенденция, которую вероятно можно будет скорректировать. Я же в данном случае пытаюсь показать, что некие ошибочные парадигмы в сознании могут выявиться на поздних стадиях эволюционного процесса и, что немаловажно — внезапно.
Есть же сейчас проблема, что в определенных условиях для сети, обученной распознавать образы, можно подобрать такую искусственно сгенерированную картинку, которую она с вероятностью в 99.9% отнесет к определенному классу, при том, что на картинке может быть фактически «белый шум» с точки зрения человека. Да — это почти реверс инжениринг сети, но это показывает, насколько сеть работает по-другому. и зачастую неожиданно.
phenik
23.09.2019 08:25Что удручает во всех этих схемах, так это отсутствие некоторого внутреннего, активного начала, кот. придавало бы некоторую осмысленность их существования и целенаправленность деятельности. У человека на биологическом уровне это, в конечном итоге, мотивация выживания-самосохраниея и продолжения рода, на социальном — морально-этические нормы, адаптирующие биологические мотивации на уровне социального поведения. Для систем ИИ достаточно мотивации самосохранения и служения человеку. Размножаться они будут производственным способом) Морально-этические нормы для них должен определять сам человек, т.к. ему самому общаться с этими системами, и учитывать тот фактор, что не стоит плодить себе сильного конкурента, по крайней мере, в начальный период сосуществования с такими системами. Что-то вроде симбиотических отношений. Эволюция, кстати, часто использует этот принцип во взаимоотношении видов, и даже биологических структур. Как яркий пример — митохондрии в клетках, кот. вероятно на первых порах были симбиотическими организмами в предке эукариотической клетки. Вероятно, нужны также некоторые технические спецификации для общения систем ИИ между собой, чтобы они могли обменивались опытом полученном в обучении. Все эти вещи нужно предусматривать заранее, а не ждать, когда появится сильный ИИ равный или превосходящий человеческий.
Как могло бы это выглядеть для обучения продажи пылесосов. Сейчас список возможных действий определяет человек, и это ограничивает поиск эффективных стратегий проведения продаж. Но эти системы ИИ существуют не вакууме, а в развитой социальной среде, кот. уже создал человек. Этим системам не нужно проходить все этапы обучения методом проб и ошибок, как это приходилось делать предкам людей. Для формирования вопросов эти системы могут обращаться к внешним семантическим сетям связи понятий, и формировать новые вопросы к покупателям. Вот тут как раз важна мотивация действий таких систем при формулировке вопросов. Они не должны своими действиями и вопросами причинить вред себе и человеку. А это элементарно, например, начать мухлевать, как это делают люди) В этом случае они могут не только нанести вред людям, но и быть поломанными ими за это) Короче, пока системы ИИ не станут самообучаемыми, в смысле приготовления выборок для собственного обучения, и желательно не только методом проб и ошибок, это будут только системы заранее обученные для выполнения определенных действий.Kilorad Автор
23.09.2019 10:21Что удручает во всех этих схемах, так это отсутствие некоторого внутреннего, активного начала, кот. придавало бы некоторую осмысленность их существования и целенаправленность деятельности.
— а чем плох сигнал подкрепления?
Если мы делаем не «искусственного человека», а «машину результатов».
Кстати, мотивация на самосохранение для ИИ обычно бесполезна. Допустим, у ИИ цель — сделать как можно больше скрепок. И вот он в какой-то момент становится перед альтернативами. То ли он делает чуть меньше скрепок (в ближайший месяц), то ли чуть больше, но при этом погибает. Что он выберет? Он выберет тот вариант, где скрепок больше. А больше скрепок там, где он выживет и продолжит их делать ещё много месяцев,пока всю Землю на них не переработает
Мотивация «служения» может реализовываться через тот же сигнал подкрепления. Разработчик решает, что будет для ИИ мотиватором.
Вероятно, нужны также некоторые технические спецификации для общения систем ИИ между собой, чтобы они могли обменивались опытом полученном в обучении.
— по идее, если делать все ИИ через SAR-таблицу одного формата, то они как раз этими таблицами и смогут обмениваться. Кроме того, для алгоритмической регрессии неважно, какова размерность S и A — она работает тупо с массивами. Так что как вариант, можно обмениваться сырым опытом. Тут, правда, не очень понятно, что дальше с ним делать. Можно обучать единую модель для разных видов опыта (чтобы один и тот же ИИ был обучен и работе с биржей, и с автомобилем), но это выглядит очень сложно. Долго будет обучаться. Хотя и да, метод обучить единую модель под все задачи.
Как могло бы это выглядеть для обучения продажи пылесосов. Сейчас список возможных действий определяет человек, и это ограничивает поиск эффективных стратегий проведения продаж.
— согласен, это был очень упрощённый пример. Если бы задачей занимался AGI, он бы принимал на вход отдельные символы (а то и байты), и на выход тоже выдавал бы отдельные символы. И команды типа «отправить», «стереть» и так далее. Тогда он мог бы хоть «Войну и мир» наколотить — и воспринять тоже
Для формирования вопросов эти системы могут обращаться к внешним семантическим сетям связи понятий, и формировать новые вопросы к покупателям.
— как бы это выглядело? Вы можете описать примерный алгоритм и пример устройства такой семантической сети?
Вот тут как раз важна мотивация действий таких систем при формулировке вопросов. Они не должны своими действиями и вопросами причинить вред себе и человеку. А это элементарно, например, начать мухлевать, как это делают люди)
— сдаётся мне, если запретить ИИ причинять вред людям, то он станет заниматься только спасательством и всё. Потому что он смотрит на варианты действий и видит: здесь столько людей умрёт, здесь столько, здесь столько. Выбирает вариант, где умрёт поменьше. Оказывается, что это был вариант из серии «захватить половину Африки и обеспечить местным достаточное число еды, воды и лекарств» — но тут всё сильно зависит от того, что считается за вред человеку. Ну то есть если для ИИ вред людям будет сильно в приоритете над всем остальным, то ИИ ничем, кроме минимизации вреда людям, заниматься не будет. Неплохо, но не то, что задумано.
RL системы — консеквенциалисты. Они ориентируются только на финальный результат. Люди обычно не такие. У людей есть разграничение «я навредил» или «не я навредил». Оно различается от человека к человеку, но есть. Для RL есть просто последствия решений, для них «спас меньше, чем мог» = «навредил»vassabi
23.09.2019 11:06сейчас подумалось — а если изначально строить ИИ, который будет небессмертный и обязан будет спать?
Т.е. ок, вот он нашел «хак системы», но спустя какое-то количество циклов он всеравно прекращает свою работу на некоторе время (сон), а через некоторе большое количество циклов — и вообще. Я думаю, что это будет неплохой вариант для отсева особенно упоротых стратегий…Kilorad Автор
23.09.2019 13:23Я думал над этим. Тут вопрос — а насколько система умна? Если мы это переключение в спящий режим делается не на уровне системы целей, а на более низком, то умный ИИ рано или поздно сделает неотключаемую копию себя. А не очень умный действительно можно так поймать.
Если делать отключение на уровне системы ценностей… Тут надо действовать очень аккуратно, чтобы он ещё и эту логику не стал абьюзить
phenik
23.09.2019 14:39— а чем плох сигнал подкрепления?
Он подкрепляет текущую задачу, для перехода на новую нужны мотивы, цели, а там может быть др. подкрепление. Иначе нет смысла говорить о каком-то самостоятельном ИИ, это просто обученная программа. Конечно лучше, чем традиционное программирование, когда все делает программист, но это не то, что хотелось бы от таких систем. Почему? Потому что раньше программисты вводили в программу массу настраиваемых параметров, и по результатам тестирования их настраивали, в тех же программах распознавания (сам занимался такими, связанными с определением показателей физиологических сигналов). Жизнь упростили нейросетевые алгоритмы — такая настройка параметров производится в них обучающей выборкой. Но теперь нужно корпеть над составлением выборок, а это тоже не простое занятие, уже целая индустрия появилась. Идеал ИИ, кот. все это берет на себя, и действует исходя из заложенной в него мотивации. Хотя какое-то предобучение вполне возможно. Это нормально, это дальнейшая реплика с человеческих возможностей, первая сама идея обучаемой иск. нейросети.Кстати, мотивация на самосохранение для ИИ обычно бесполезна. Допустим, у ИИ цель — сделать как можно больше скрепок.
Знаю о такой байке) Не нужно замешивать успех выполнение задания на самосохранение. Тогда наоборот, перепроизводство скрепок вызовет реакцию самосохранения, и их производство будет остановлено. Но соглашусь, тут возможны конфликты интересов иерархического порядка. По этой причине системы ИИ должны находится под контролем человека. И конечно, казусы будут периодически неизбежно возникать.— как бы это выглядело?
Семантическая сеть (см. также англ. вики) это продвинутые бывшие базы знаний и экспертные системы. Эти сети могут содержать не только связи понятий, но и медийный материал — изображения, видео, тд. Аннотированные выборки для обучения нейросетей тоже содержат описания и классификацию, но не содержат связи и отношения понятий, это их существенный минус. Например, сем. подсеть пылесоса должна включать все понятия и их связи связанные с его устройством, функционированием, способами использования в самых разных контекстах, и тд. По сути Википедия является в некотором приближении такой сетью, по ссылкам можно составить представление о связях любого понятия. Но имеются специализированные сети. Используя правила построения предложений (синтаксис и грамматику) в языке можно генерировать новые предложения для диалога. Используя другие сем. сети можно проверять эти предложения на соотв. мотивации на самосохранение и отсутствие вреда для человека. Этот семантический уровень все равно, рано или поздно, будет задействован. Нет никакого смысла все заново переоткрывать для систем ИИ, если этот путь уже проделан человеком, и этим системам придется иметь дело с ним. Каждый человек проходят этот путь в детстве во время воспитания и обучения, постепенно, из-за специфики биологической основы его интеллекта, впитывая смыслы, но ИИ можно подключить к таким сетям сразу. Вот в этом коменте привел пример, как можно использовать сем. сети при переводе.— сдаётся мне, если запретить ИИ причинять вред людям, то он станет заниматься только спасательством и всё. Потому что он смотрит на варианты действий и видит: здесь столько людей умрёт, здесь столько, здесь столько.
Да, сложная проблема, и куча перлов сломанных в спорах по принятию решений теми же ИИ робомобилей во время ДТП. Но это экстрим, человек тем более ошибается в таких ситуациях, т.к. часто не успевает даже отреагировать. Но когда такого экстрима нет основные решения должен принимать человек. Уже писал, что морально-этич. вопросы пока должны оставаться за человеком. Это действительно очень сложная и важная проблема. И должна решаться постепенно. Готовых рецептов нет. Сам человек в этом плане несовершенен)Kilorad Автор
23.09.2019 15:10Он подкрепляет текущую задачу, для перехода на новую нужны мотивы, цели, а там может быть др. подкрепление.
— вообще, изначально я описывал постановку задачи как «мы ставим ИИ некоторую проверяемую цель — он её достигает». Полная самостоятельность в способах достижения цели, но при этом формулировка цели подконтрольна оператору.
У вас есть понимание, как ещё можно было бы ставить задачу для ИИ? Так, чтобы одной и той же системе можно было ставить задачи от «заработай миллион на бирже» до «побыстрее мне довези меня до аэропорта, но так, чтобы не убиться»? Как, кроме как через сигнал подкрепления?
Не нужно замешивать успех выполнение задания на самосохранение.
— прошу пояснить.
Мой тезис: если даже мы не будем задавать ИИ цель «защити себя», он всё равно будет защищать себя — в той мере, в которой это нужно для достижения явно заданных целей.
Да, сложная проблема, и куча перлов сломанных в спорах по принятию решений теми же ИИ робомобилей во время ДТП. Но это экстрим, человек тем более ошибается в таких ситуациях, т.к. часто не успевает даже отреагировать. Но когда такого экстрима нет основные решения должен принимать человек.
— а что, если любое решение, которое принимает ИИ, гробит кучу людей? Даже если он ничего не делает, много людей умирает от старости! ИИ будет воспринимать это как своё личное упущение, как только поймёт, что может на это влиять. Ну, это я насчёт непричинения вреда людям.
Пока ИИ не очень умный, сойдут и какие-нибудь простые метрики ущерба)
А можно пример того, как использовать семантическую сеть для решения задачи управления в общем виде? Если у нас есть S, A и R? Как AGI догадается, что ему надо использовать именно семантическую сеть, а не, например, средство для анализа рентгеновских снимков? Как он зарядит в неё данные из SAR-таблицы, в каком виде получит ответ, как применит его для дальнейших решений?
Nehc
23.09.2019 11:14Я дико извиняюсь, но можно ссылочку, или какой-нибудь источник, подтверждающий вот это:
Сейчас существуют две широко известные постановки задачи. Первая — Сильный ИИ. Вторая — ИИ общего назначения (он же Artifical General Intelligence, сокращённого AGI).
В русской вики AGI ведет на Статью «Сильный искусственный интеллект». В английской Определение звучит так: Artificial general intelligence (AGI) is the intelligence of a machine that has the capacity to understand or learn any intellectual task that a human being can (интеллект машины, способной понять или освоить любую интеллектуальную задачу, которую может выполнить человек).
Я вполне готов признать за вами право разделять для себя эти понятия на два разных (я бы даже сказал, что естественная функция разума! ;) ), но в моем понимании, это совсем не общепринятая классификация!
Это прям то, что сразу бросилось в глаза… остальное пока читаю! ;)Nehc
23.09.2019 11:23Хотя… Я еще подумал, и понял, что все дело, скорее всего, как обычно в трудностях перевода! ))
Дело в том, что наш, русский ИИ — это не много не мало — искусственный интеллект! Т.е. мы сразу ставим вопрос глобально, философски, почти метафизически… Англоговорящие товарищи в этом плане попроще: их AI, это всего лишь Artificial intelligence, т.е. «искусственная интеллектуальная деятельность». И конечно же любое распознавание паттернов, классификация и прочие прелести нейронных сетей — это уже в полный рост AI, но вот вроде еще не совсем ИИ. Похоже, что с Сильным ИИ и AGI приключилась та же история: англоговорящие товарищи считают, что Сильный — это значит способный решать любую задачу, а значит уже в достаточной степени «как человек», ибо прикладники же — чего с них взять! А у нас полет мысли — шире: будет он там чего решать или нет, это как пойдет, главное что был брат по разуму! )))Kilorad Автор
23.09.2019 13:19Вы верно подметили, что в русское «интеллект» и английское «intelligence» — это несколько разные понятия. Видимо, это одна из важных причин непонимания между «философами ИИ» и «практиками ИИ»
Nehc
23.09.2019 12:03Отличная статья! Вот прям то, что мне было нужно — масса практических методик, минимум философских изысканий. Философии мне своей хватает, а живая практика дорогого стоит! Спасибо.
Kilorad Автор
23.09.2019 13:20Благодарю =) Собственно, отчасти именно ваши работы меня на неё и вдохновили

Frankenstine
26.09.2019 11:19дубликат из-за нестабильного инета

Kanut
26.09.2019 11:29Станислав Дробышевский даёт такое определение понятию разума: способность решать нестандартные задачи нестандартными методами.
Я бы сказал что конкретно в такой формулировке это необходимое условие чтобы считать что-то ИИ. Но вот достаточным я бы его не назвал.
Потому что например на Земле есть куча организмов, которые в прцессе эволюции "научились" решать нестандартные задачи нестандартными способами. Но интеллектом они при этом однозначно не обладают.
Kilorad Автор
26.09.2019 12:37Потому что например на Земле есть куча организмов, которые в прцессе эволюции «научились» решать нестандартные задачи нестандартными способами. Но интеллектом они при этом однозначно не обладают.
— а можно пример? Нестандартные — это в смысле эти организмы решают плюс-минус любую задачу? Или просто какую-то частную, но экзотически выглядящую?Kanut
26.09.2019 12:44Частную, но экзотически выглядящую. Просто представьте себе что мы создали машину, которая каким-то рэндомным способом генерирует "способы решения задач". И она в какой-то момент сгенерирует "нестандартный способ решения" для какой-то нашей "нестандартной задачи", применит его и задачу решит.
И я понимаю что создание подобной машины само по себе тоже совсем не тривиально. Но на мой взгляд её всё равно нельзя будет назвать ИИ.
П.С. Или если совсем пойти в философию: а можно ли эволюцию считать ИИ? :)
Kilorad Автор
26.09.2019 13:13Ну вот да, то, что вы описали, очень похоже на простенький вариант эволюции =)
Не знаю, можно ли назвать ИИ (так как термин размытый), но AGI нельзя. Даже если это будет очень крутая вариация на тему эволюции.
Потому что эволюция не решает динамические задачи. Её нельзя вставить в ракету в качестве системы управления. Или вставить в качестве системы управления персонажем в Doom. Эволюцию можно использовать, чтобы сгенерировать стратегию, если у нас есть возможность потратить на неё несколько поколений и кучу особей, а это недостаточно эффективно для AGI. Кроме того, эволюцию можно использовать, чтобы создавать прогнозные модели для любого Reinforcement Learning, так что эволюция может быть кусочком AGIKanut
26.09.2019 13:37Я с вами абсолютно согласен. Поэтому и моё уточнение про "необходимое" и "достаточное" ;)
Frankenstine
26.09.2019 11:23Обычно упоминается, что он должен проходить тест Тьюринга в первоначальной постановке (хм, а люди-то его проходят?), осознавать себя как отдельную личность и уметь достигать поставленных целей.
В лекции «Неизбежен ли разум?» Станислав Дробышевский даёт такое определение понятию разума: способность решать нестандартные задачи нестандартными методами". Если приравнять разум к понятию интеллектуальности, то искусственный интеллект превращается в искусственный разум и становится понятным, как его отделить от «слабого ИИ», читай от квейковского бота. Если мы можем поставить ИИ задачу, имеющую логическое решение и он не может найти ей решение — это не разум, не интеллект, а сборище заданных заранее алгоритмов, бот. И наоборот, тот ИИ будет «сильным», читай разумным, который сможет строить логические рассуждения приходя с их помощью к правильным выводам. Он сам будет строить себе алгоритмы. А тест Тьюринга лишь инструмент тестирования, причём довольно спорный.Kilorad Автор
26.09.2019 12:35Тут возникают методологические вопросы. (Придирки! Придирки!) Нестандартные задачи — насколько? Вот есть простой Q-Learning, если его бросить на простенькую игру (например, маленький лабиринт или сбор одних точек и уклонение от других), он с высокой вероятностью справится. Если использовать эволюционное обучение — то справится почти неизбежно =)
Но возьми задачу с размерностью побольше — и всё, завязли. Слишком сложные закономерности, за вменяемое время их не подобрать правильно.
Нестандартные методы… Тут есть много любителей говорить, что ИИ не креативит, а только сочетает то, что придумано до него. При этом такие задачи, как, например, написание книги — это тоже сочетание того, что придумано раньше. Книга пишется в Unicode, автор ни одного своего символа не придумывет, только чужими пользуется =) Так что граница между «комбинирует стандартное» и «использует нестандартное» довольно размытая.
Вот, например, у меня есть программа для оптимизации статических функций. То есть, например, она может подбирать такой код, чтобы он проходил заранее заданные юнит-тесты. Максимально хорошо проходил. Не очень сложные, но всё же. Это решение нестандартной задачи? Если программный код пишется юникодовскими буквами или операторами чего-то типа ассемблера — это считается за нестандартное решение? Эта же самая тулза для оптимизации может подобрать систему управления ракетой, если точно известно, в какой среде ракету будет работать.
И эта решающая тулза построена на чём-то очень похожем на эволюцию…
Считаем за разум? Это всё же сильно отличается от человеческого разума. Динамические задачи эволюция решает очень плохо — то есть она сама была бы плохой системой управления для ракеты и не смогла бы сгенерировать такую систему без знания среды, в которой ракета будет летать.
Если мы можем поставить ИИ задачу, имеющую логическое решение и он не может найти ей решение
— это и люди-то не всегда могут, даже когда очень хотят. Ну или скажем так — есть задачи, в которых человеку для точного решения пришлось бы проводить очень массированный и долгий перебор вариантов, а приблизительное решение иногда оказывается неверным. Например, задача «выиграть в шахматы».
Потом… Что считается под логическим решением задачи? Если ИИ принимает решение в условиях неопределённости — например, прогнозирует спрос на товар, рассчитывает потери в случае дефицита, потери в случае избытка и выбирает, сколько коробок заказывать — это логическое решение? Он скорее всего, сделал неточный прогноз, и решение точно неидеально, но это околонаилучшее, что можно нарешать при таких данных
Я примерно понимаю, какие свойства вы хотели отразить в определении. Решение нестандартных задач — свойство универсальности (General). Решение нестандартными методами — адаптивность, не-рукописность стратегий.
Я бы добавил ещё пару свойств. Решение динамических задач управления — а не только статических, как у эволюции. И эффективность по ресурсам — «лучший» интеллект это тот, который при бОльших результатах тратит на них меньше денег/времени/попыток
third112
Из этого определения результат распознавания картинки, чтобы считаться творчеством, должен быть уникальным. Для большинства картинок это абсурдно — очень многие картинки разные люди распознают одинаково. Что такое творчество понятно на интуитивном уровне, но достаточно строгое определение дать очень трудно — на эту тему издавна идут нескончаемые споры. Поэтому ИМХО не надо определять ИИ через творчество.
Kilorad Автор
Я как раз хотел показать, что понимание ИИ у нас как общества не очень последовательное. Я согласен, что распознавание картинок никоим боком не творчество. А вот выигрывание в компьютерной игре — тут сложнее, так как определение творчества тоже довольно размытое.
third112
Предлагаю такое определение: к ИИ относятся задачи, которые компьютер решает заметно хуже человека, а так же задачи (может, полностью или частично решенные в настоящее время), которые традиционно относили к сфере ИИ.
Kilorad Автор
Да, это неплохое обобщение того, что люди обычно называют искусственным интеллектом