

История машинного обучения началась с середины прошлого века. В то время данная технология была больше областью для научных исследований и экспериментов, а толчок к практическому применению ML дали мощные компьютеры.
Сегодня машинное обучение – это неоспоримый тренд на рынке ИТ. Все больше компаний из разных индустрий создают подразделения Data science, чтобы с помощью машинного обучения находить в накопленных данных новые возможности для роста и повышения эффективности бизнеса. Однако, пока эти инициативы не дают должной отдачи. По статистике 8 из 10 подтвержденных кейсов не переходят в промышленную эксплуатацию.
Скорее всего большинство из вас слышали шутку «самый эффективный способ продуктивизации машинного обучения – это слайды PowerPoint». К сожалению, это не шутка. Зачастую весь процесс выглядит так: бизнес передает выгруженные из бизнес-систем данные и бизнес-кейс. Дата-сайентисты разрабатывают модель машинного обучения в Jupiter Notebook, скриншот графиков помещают на слайд PowerPoint и отправляют бизнес-заказчику. Можно ли использовать полученный слайд в принятии управленческих решений? Скорее нет, так как данные прогноза быстро устаревают, и ситуация в бизнесе за это время может серьезно измениться.
Пытаясь преодолеть все преграды и поставить машинное обучение на поток, большинство компаний инвестируют в инфраструктуру сбора, хранения и обработки больших объемов данных – Data Lake. Безусловно, это необходимый шаг. Но что это меняет с точки зрения бизнеса? Возможно ли принимать решения, опираясь на машинное обучение? Нет, так как между Data Lake и бизнесом пропасть. Очевидно, почему 86% опрошенных компаний верят в то, что бизнес-приложения нового поколения должны быть оснащены машинным обучением.
Мы в компании SAP решили написать серию статей, как с помощью новой платформы SAP Data Intelligence преодолеть существующие сложности и поставить столь мощный инструмент, как машинное обучение, на службу бизнесу. И, если эта тема вам интересна, продолжайте читать :)
Для начала я расскажу вам про первый и очень важный этап разработки любого бизнес-кейса «Поиск и подготовка данных». В последующих статьях рассмотрим этапы «Разработка и обучение моделей», «Интеграция с SAP и non-SAP on-premise и cloud источниками данных в деталях», «Создание сервисов для использования моделей», «Перенос бизнес-кейсов в продуктив», «Мониторинг и эксплуатация бизнес-кейсов» и многое другое.
Разработка бизнес-кейса на основе машинного обучения. Поиск и подготовка данных.
Давайте рассмотрим процесс создания бизнес-кейса (Рис 1).
Изначально идею, как правило, формулирует бизнес. Зачастую он делает это охотно, так как у него есть определённая цель по цифровизации функции в рамках цифровой трансформации всего предприятия. Для сбора, оценки и приоритезации идей можно использовать, например, SAP Innovation Management.
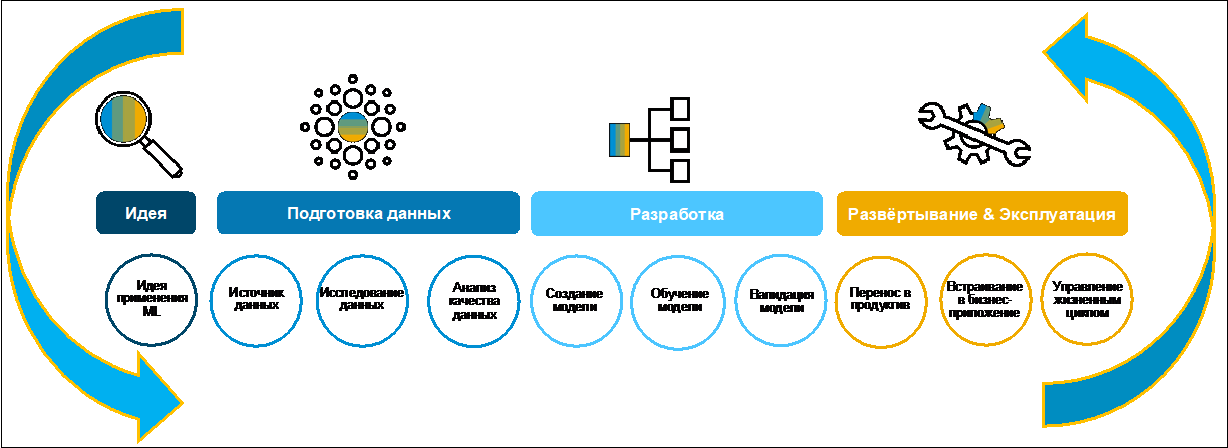
Рисунок 1.
На первом этапе поиска и подготовки данных необходимо понять, есть ли они вообще для разработки бизнес-кейса, где хранятся, в каких форматах и какого они качества. Современный типовой ландшафт включает в себя множество разнородных систем. Данные могут дублироваться в разных приложениях. На поиск нужной информации может уйти много времени. Именно для этого в SAP Data intelligence существенно упрощена эта задача с помощью Каталога метаданных. Давайте рассмотрим, что это такое и как его использовать.
Каталог метаданных
Для использования каталога метаданных необходимо подключить систему-источник к Data Intelligence. Источниками данных для Data Intelligence могут быть on-premise системы SAP ERP, BW, Marketing… и non-SAP MES, Oracle, MS SQL, DB2, Hadoop и многие другие, а также облачные сервисы Amazon, Azzure, Google SCP. Для подключения к источникам данных необходима информация о размещении систем и технические пользователи, созданные в этих системах специально для интеграции с SAP Data Intelligence. На рисунке 2 представлен пример настроенного ландшафта данных в SAP Data Intelligence.

Рисунок 2.
Сразу после настройки в Каталоге метаданных SAP Data Intelligence возможно увидеть информацию, которая хранится в подключенных системах. На рисунке 3 представлен перечень файлов, которые находятся в папке DAT263 в Hadoop, подключенном к SAP Data Intelligence.

Рисунок 3.
Если вы нашли данные, которые необходимы для реализации бизнес-кейса, давайте добавим объекты данных в Каталог с помощью функции публикации. Я буду использовать файл autos_history.csv, который содержит статистику продаж подержанных автомобилей. На рисунке 4 вы видите, как можно опубликовать объект данных и его метаданные в Каталог для быстрого доступа в будущем.

Рисунок 4.
Структуру каталога, уровни иерархии вы можете настраивать в соответствии с вашими требованиями бизнес-кейсов. Например, в моей папке Habr_demo будут собраны все метаданные об объектах, которые мне нужны для этой статьи.
Сформированный Каталог метаданных – это быстрый доступ к данным по бизнес-кейсу. Профилирование и анализ их качества я буду проводить на объектах моей папки в Каталоге метаданных SAP Data Intelligence. Начальный экран каталога метаданных показан на рис. 5.
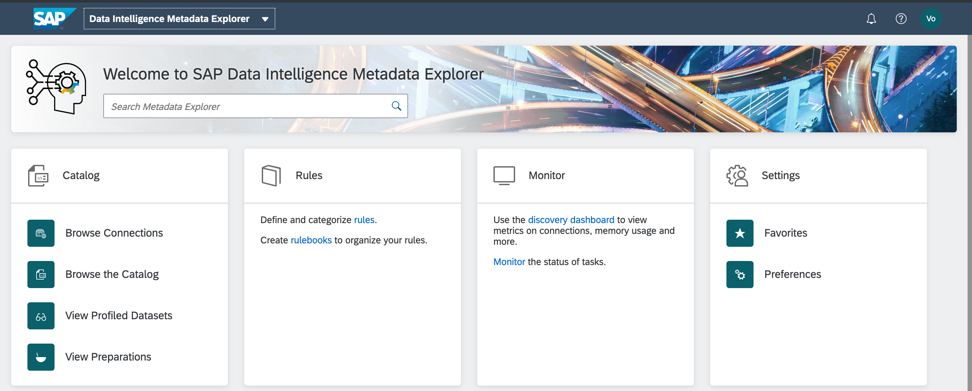
Рисунок 5.
И вот тот самый объект данных, который я опубликовала в папку Habr_demo (Рис.6)
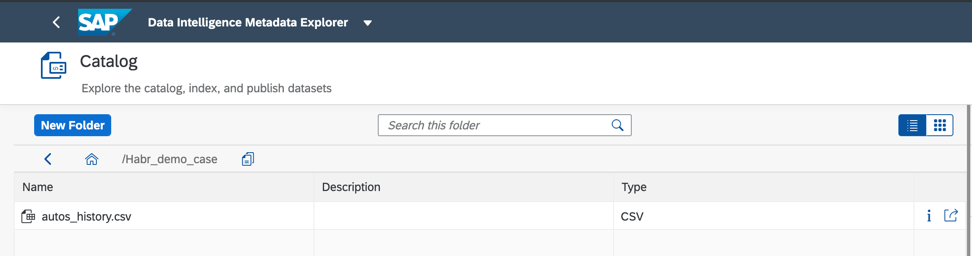
Рисунок 6.
Дополнительно для улучшения и ускорения поиска мы можем в каталоге объектов данных назначить тэги или метки, как это показано на рис. 7.
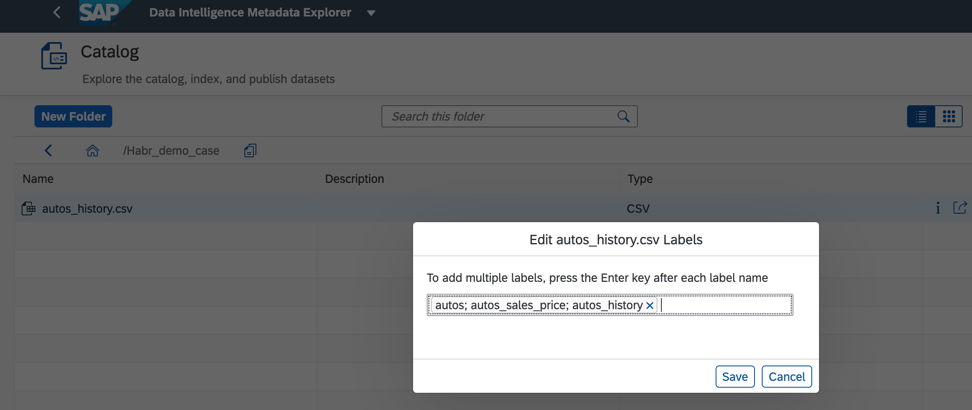
Рисунок 7.
Каталог метаданных позволяет искать объекты по названиям их самих, полей, а также по меткам. Один объект данных может иметь несколько меток. Это удобно, если с ним работают несколько разработчиков, каждый может назначить метку по своему бизнес-кейсу, и по ней быстро находить все необходимое. Также метками можно выделять персональные и конфиденциальные данные, доступ к которым должен быть строго ограничен.
По рассматриваемому дата-сету поиск по метке и по имени поля дает быстрый результат (рис. 8). Согласитесь, это очень удобно!
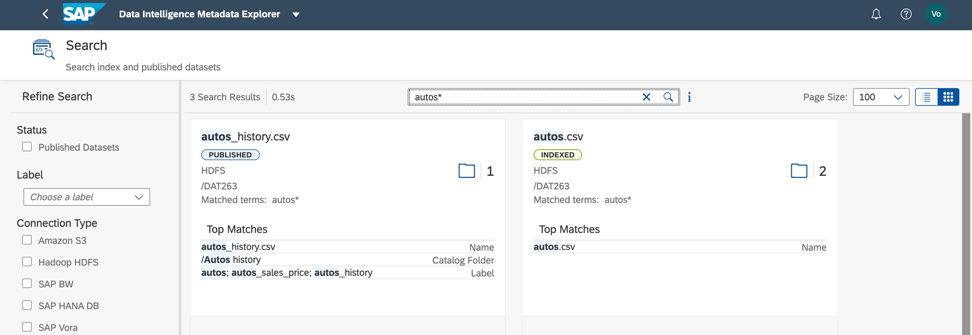
Рисунок 8.
Далее нам нужно понять, чем заполнен наш файл. Для этого мы можем профилировать данные. Запускаем процесс мы также из каталога метаданных и контекстного меню на объекты данных (Рис.9).

Рисунок 9.
В ходе профилирования каталог метаданных прочитает содержимое файла, проанализирует его структуру и заполнение. Результат можно посмотреть в Fact Sheet (рис.10).
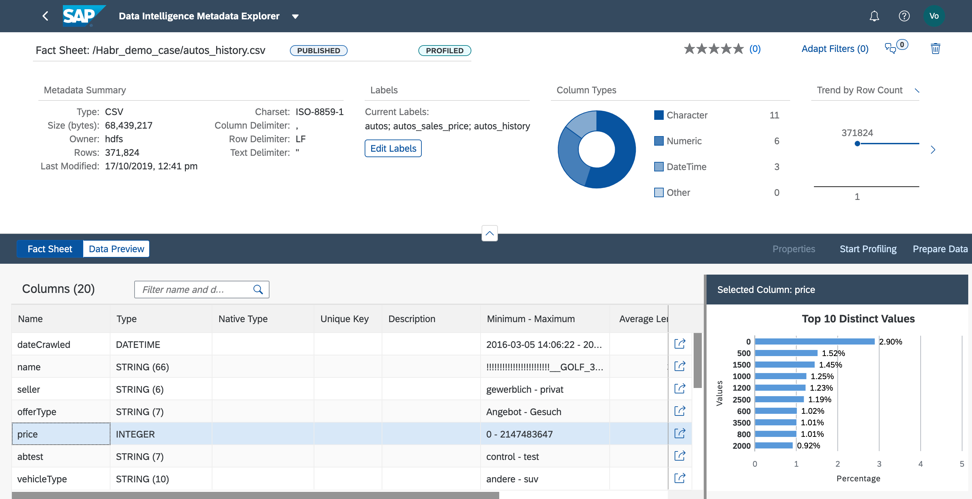
Рисунок 10.
В Fact Sheet мы видим структуру файла и информацию по заполнению полей.
1. В выбранном файле в результате профилирования мы выявили: поле seller имеет одно значение I во всех строчках. Это означает, что это поле мы можем удалить из дата-сета, чтобы не использовать при построении модели машинного обучения, так как оно не будет влиять на результат прогноза (Рис. 11).

Рисунок 11.
2. Анализируя колону price, мы понимаем, что почти 3% данных у нас содержат нулевую цену. Для того, чтобы этот файл использовать в нашем бизнес-кейсе, мы должны заполнить price либо актуальными значениями, либо средним по данному продукту, или мы должны удалить строки с нулевой ценой из файла (Рис.12).
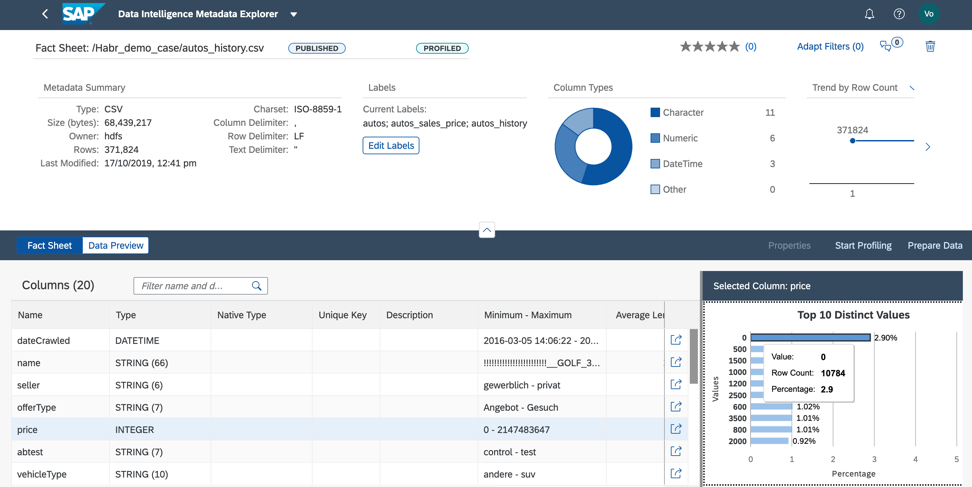
Рисунок 12.
Предобработку данных мы можем сделать двумя способами: в Каталоге метаданных или непосредственно в Jupiter Notebook. Выбор инструмента зависит от того, кто отвечает за предобработку данных для бизнес-кейса. Если аналитик, то я рекомендую использовать визуальный интерфейс подготовки данных, который доступен в Каталоге метаданных. Если подготовкой данных занимается дата-сайентист, то однозначно выбор должен быть в пользу Jupiter Notebook, который также интегрирован в Data Intelligence.
3. Значение поля model хорошо распределены, что позволит нам качественно обучить модель, как на рисунке 13.
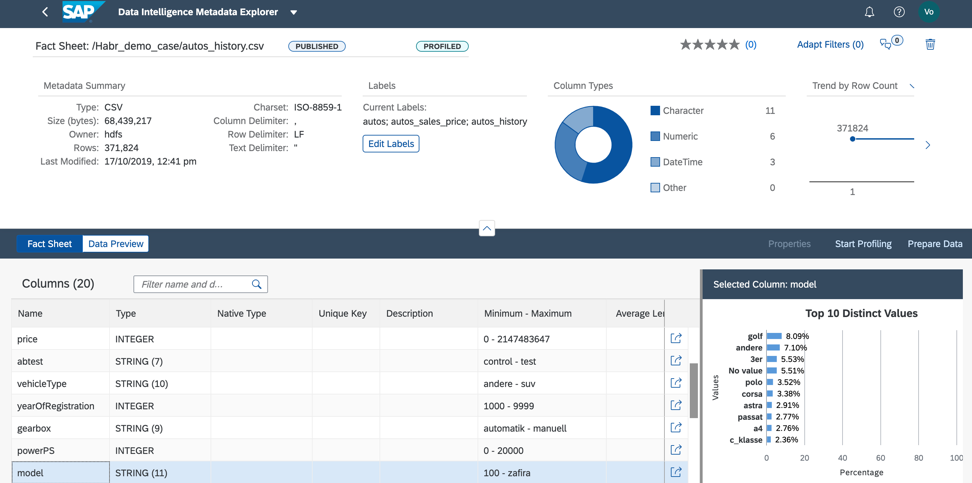
Рисунок 13.
Теперь мы понимаем, какие объекты данных требуются для реализации бизнес-кейса, чем заполнены объекты данных, какую предобработку мы должны провести, чтобы использовать эти данные для реализации, обучения и тестирования модели. Но прежде, чем начать предобработку, необходимо проверить качество данных. Для этого в Каталоге метаданных доступны бизнес-правила. Сразу отмечу, что на текущий момент функциональность бизнес-правил имеет ряд серьезных ограничений. Поэтому более или менее сложную предобработку данных я рекомендую проводить в Jupiter Notebook, который интегрирован в SAP Data Intelligence.
Итак, давайте вернемся к нашему дата-сету и проверим соблюдение минимальных и максимальных порогов по полю price, таким образом мы сможем грубо оценить, есть ли в данных аномалии или некорректные значений. Как вы уже поняли, бизнес-правила настраиваются также в Каталоге метаданных, как на рис. 14а, в. Связь правил и данных настраивается в книге правил (Rulebook). Это позволяет использовать одни и тоже правила для проверки различных данных.
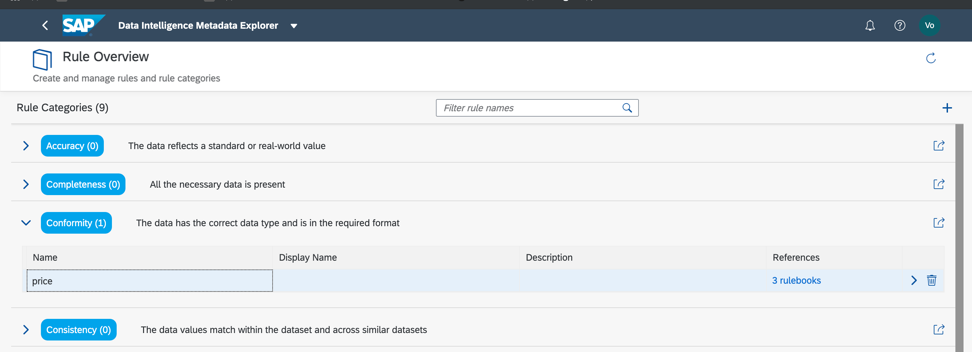
Рисунок 14 а.
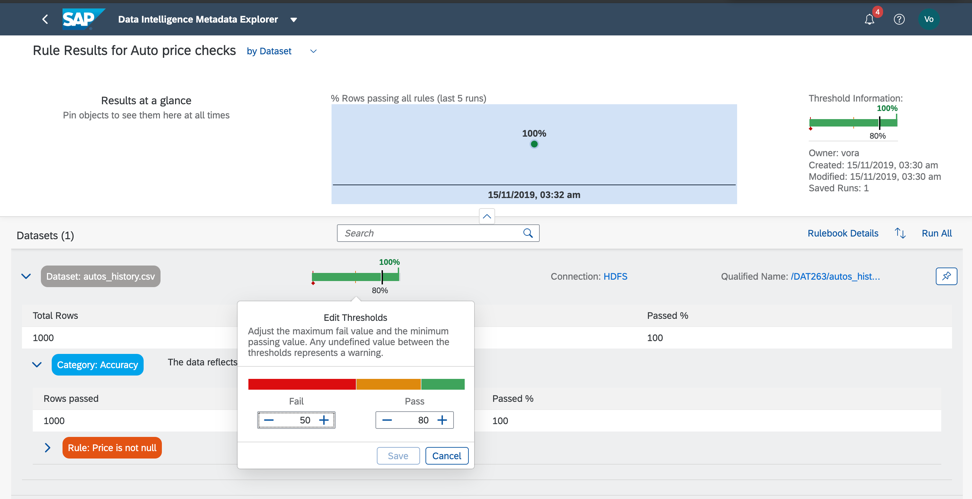
Рисунок 14 в.
Итак, как мы видим, наши данные на 100% корректны.
Но так бывает не всегда. Данные могут быть признаны корректными, если 75% записей соответствует условиям, заданным в правилах.
Повысить качество данных возможно, и прежде всего это делается в учётных системах. Для этого в компании организуют процесс управления данными. Также возможная причина — неверно определенные критерии качества данных.
Резюмируя, хочется сказать о преимуществах и недостатках Каталога метаданных.
На мой взгляд, у него 3 основных преимущества:
- Упрощение доступа к данным.
- Ускорение поиска данных.
- Удобный и понятный интерфейс, который предназначен не только для продвинутых в ИТ или Data Science специалистов, но и для бизнеса, вовлеченного в реализацию и дальнейшее сопровождение бизнес-кейса.
Ну и, конечно, про недостатки. Они очевидны. На текущий момент функциональность Каталога метаданных в SAP Data Intelligence соответствует базовому уровню. Она может быть достаточна для начала использования, но точно функциональность не покрывает все требования, которые предъявляются к решению для управления данными.
И это следствие новизны и комплексности SAP Data Intelligence. SAP много ресурсов инвестирует в совершенствование этого решения. И это вселяет уверенность в том, что в ближайшее время Каталог метаданных превратится в мощный инструмент для управления данными. Появится возможность создавать комплексные бизнес-правила без программирования. А также станет возможным интегрировать SAP Information Steward и SAP Data Hub для целей полноценного функционального покрытия темы управления данными.
В следующей статье расскажем об этапе «Разработки и обучения модели в SAP Data Intelligence». Все самое интересное впереди!
Автор – Елена Ганченко, эксперт SAP CIS
ideological
А что со старой платформой? Есть SAP Predictive Analytics (а внутри ещё Expert Analytics), этот софт вообще работает? Много компаний им пользуются? Какие?
Выглядит как неработающая штуковина с интерфейсом из 90х.
Странные же у вас Дата-сайентисты.
Ещё же и SAP Leonardo ещё. Не многовато ли у вас продуктов для машинного обучения? Может стоит тогда лучше сделать обзор чем отличается весь этот софт друг от друга?