
Сегодня мы будем измерять производительность разных реализаций функции toupper, ведь именно этим и занимаются по вторникам.
Вообще-то мне нет никакого дела до функции toupper, просто я недавно писал другой пост и мне нужен был какой-то общий сюжетный стержень, а toupper кажется вполне интересным и безобидным кандидатом в бенчмарки. Я старался выбрать что-то максимально простое, что не увело бы меня в сторону, но так уж получилось, что в этом тесте я столкнулся со странной проблемой.
Этот пост будет небольшим – более обстоятельная статья на первоначальную, возможно более интересную тему ожидается в скором времени. Если захотите воспроизводить результаты вместе со мной, то исходный код можете взять на github.
Итак, рассмотрим три реализации функции toupper, которая переводит в верхний регистр символы некоторого массива, состоящего из элементов типа char, – а именно, принимает массив в качестве аргумента и непосредственно изменяет его элементы так, что все строчные буквы обращаются в прописные.
В первой реализации мы просто вызываем функцию toupper [1] стандартной библиотеки C и выполняем цикл в стиле C:
Во второй реализации используем более современный подход с заменой «сырого» цикла на std::transform:
Наконец, в третьей реализации используем специальный алгоритм, работающий с ASCII- символами. Он проверяет, входит ли символ в диапазон a – z, и в случае успешной проверки подставляет эту же букву в верхнем регистре, вычитая из кода символа число 32 [2]:
Выглядит просто, правда?
Теперь измерим скорость работы этих реализаций на моём ноутбуке с процессором Skylake i7-6700HQ на компиляторе gcc 5.5 с настройками по умолчанию. Результаты даны в виде точечной диаграммы [3]:
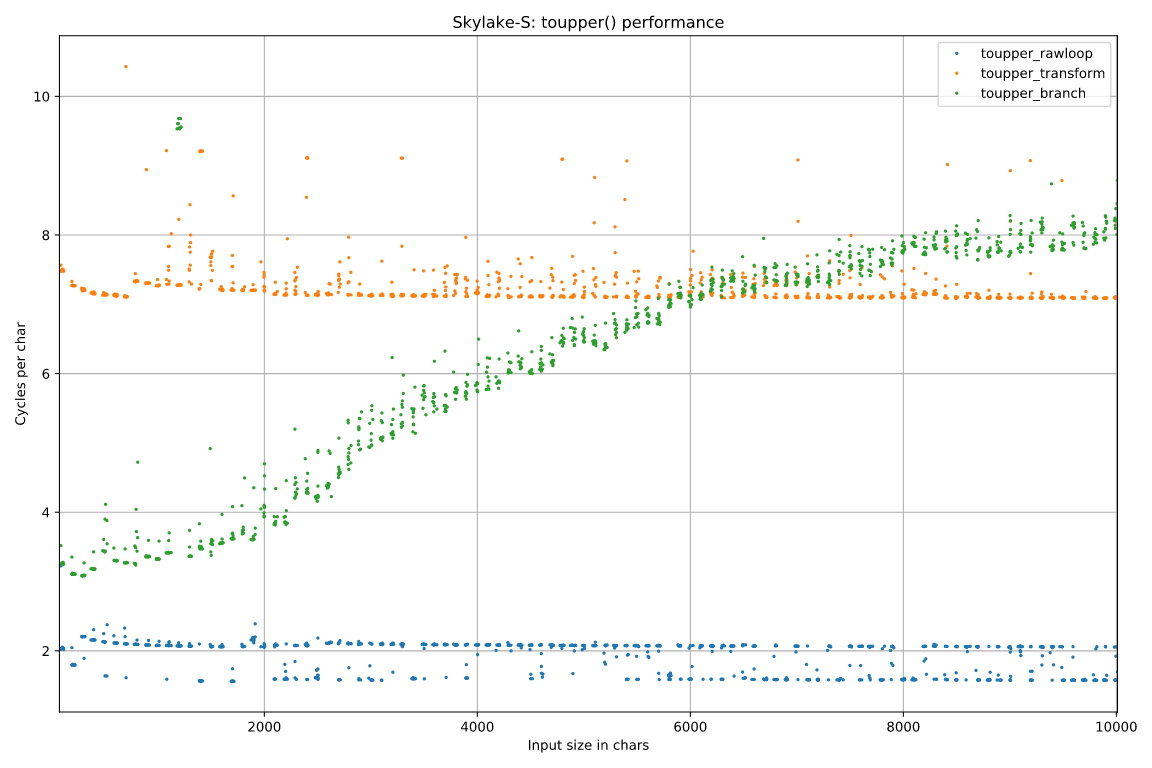
Сразу разберёмся с тремя вопросами, которые неактуальны для нашей задачи.
Во-первых, посмотрите на график алгоритма с ветвлением (показан зелёным). Он значительно изменяется в зависимости от размера входных данных – другие два графика остаются практически ровными. На самом деле это всего лишь артефакт тестирования. Входные ASCII-символы выбираются случайным образом [4], поэтому решающим фактором в случае третьей реализации оказывается работа алгоритма предсказания ветвления. При малом количестве данных он целиком заучивает последовательность элементов по мере выполнения итераций, поэтому количество промахов невелико и скорость работы высокая, как показано в этой заметке. По мере роста размера последовательности данных алгоритм предсказания запоминает все меньше и меньше, пока наконец не начинает промахиваться с каждой прописной буквой (0,27 промахов на символ), и тогда график выравнивается.
Во-вторых, обратите внимание на группу зелёных пятнышек слева вверху, соответствующих намного более низким скоростям варианта с ветвлением toupper_branch:

Это не единичный артефакт: такие пятнышки появлялись при нескольких запусках. При этом их нельзя воспроизвести, если тестировать алгоритм только конкретно на этих размерах данных – они всплывают, только когда тест прогоняется по всем размерам. Но и в этом случае они появляются не всегда. Я не стал особо вникать, но могу предположить, что это связано с какими-то конфликтами имён или псевдонимов в алгоритме предсказания ветвления или при отображении физических страниц памяти размером 4 кБ на виртуальные (хотя рандомизация виртуального адресного пространства у меня была выключена).
В-третьих, реализация toupper_rawloop (показана синим) на графике выглядит как две отдельных линии: одна чуть выше отметки 2 тактов на символ, а другая – на уровне 1,5 тактов на символ. Эти две линии появлялись во всех тестировщиках. Более быстрый вариант, со скоростью 1,57 символов на такт, на самом деле тормозится на портах загрузки: чтение данных на портах 2 и 3 происходит со скоростью 1,54 микрооперации на такт, поэтому они будут заняты на 98%. Причину же более медленного «режима» я установить не смог.
Пока я разбирался с этим вопросом, быстрый «режим» внезапно исчез и остался только медленный. Возможно, процессор смекнул, что я пытаюсь сделать, и тайно скачал обновление для микрокода, чтобы убрать противоречие, но у меня (пока ещё) есть доказательство – векторное изображение с графиками.
Что же нас тогда интересует в этом примере?
А интересует нас то, что версия с «сырым» циклом в 3-4 раза быстрее версии с std::transform: 1,5-2 такта на символ против 7 с небольшим тактов на символ.
В чём же тут дело? Меня подвели стандартные алгоритмы? У std::transform есть какой-то изъян?
Не совсем. Точнее, вовсе нет.
Оказывается, такие результаты появляются, когда функции компилируются в разных файлах. Если поместить их в один и тот же файл, то производительность у них становится одинаково низкой.
И нет, выравнивание тут не при чём.
Но это ещё не всё: быстрая версия с «сырым» циклом, будучи скомпилированной в отдельном файле, замедляется, если к нему просто подключить заголовочный файл <algorithm>. Да, всё верно: достаточно подключить этот файл, который никогда не используется и не генерирует никакого кода в итоговом объектном файле, и скорость «сырого» цикла упадёт в 3-4 раза. Напротив, версия с std::transform разгоняется до предела, если скопировать и вставить реализацию std::transform из файла <algorithm>, а сам этот файл не подключать.
На этом странности не заканчиваются (больше их не будет, обещаю): подключение файла <algorithm> не всегда приводит к описанному эффекту. Падение скорости происходит, если <algorithm> подключается раньше, чем <ctype.h>, но если поменять их местами – то нет:
Медленный код:
Быстрый код:
Собственно, у меня эта аномалия проявлялась (в другом проекте), когда clang-format автоматически сортировал подключаемые заголовочные файлы и помещал <algorithm> в самое начало списка, где ему и место (отсюда и кликбейт-заголовок статьи).
Естественно, мы должны были рано или поздно окунуться в листинг ассемблера. Не будем оттягивать этот неприятный момент.
Ниже показаны быстрая и медленная версии функций [5], малые циклы снабжены аннотациями:
<algorithm> подключается первым:
<algorithm> подключается вторым:
Главное отличие состоит в том, что в медленной версии функция toupper просто вызывается в цикле, тогда как в быстрой версии вызовы функции вовсе отсутствуют, а есть только поиск по таблице соответствия [6], т.е. тело функции std::toupper подставляется на место вызова.
Если посмотреть на исходный код библиотеки glibc, мы найдём там реализацию функции toupper:
Как мы видим, toupper определена как extern inline функция, которая сначала проверяет, что размер char-символа умещается в один байт [7], а затем ищет символ в таблице соответствия, возвращаемой функцией __ctype_toupper_loc(). Эта функция возвращает локальный указатель потока (типа const int **), который, в свою очередь, указывает на таблицу соответствия, из которой в ответ на запрос по нашему символу возвращается его версия в верхнем регистре [8].
Теперь понятно, что происходит в листинге. В быстрой версии алгоритма компилятор подставляет тело функции toupper, но не может подставить вызов функции __ctype_toupper_loc() [9]. Этот вызов, однако, объявлен как __attribute__((const)), а это значит, что возвращаемое значение зависит только от аргументов (которых здесь нет). Компилятор знает, что эта функция каждый раз возвращает одно и то же значение, и поэтому выносит её вызов за пределы цикла, а в самом цикле остаётся только несколько операций чтения, связанных с обращением к таблице соответствия, записью нового значения в буфер и управлением циклом.
В медленной же версии вызов toupper() остаётся в теле цикла. Сам цикл короче на одну команду, но, разумеется, теперь ещё приходится выполнять и весь код внутри функции toupper. На моей системе это выглядит так:
Поскольку это невстроенный вызов, программа совершает больше работы. Происходит не менее пяти последовательных операций обращения к памяти (так называемая погоня за указателями, pointer chasing). В быстрой версии из них остаются только две, так как все остальные выносятся за пределы цикла. Задержка между вызовом функции и выходом из неё должна быть около 25 тактов, а у нас выходит примерно 7 тактов – это означает, что процессор смог распараллелить вызов, что весьма неплохо, учитывая обстоятельства.
Почему так получается?
В длинной цепи подключаемых файлов заголовочные файлы C++, такие как <algorithm>, включают, в свою очередь, файл <bits/os_defines.h>, в котором содержится следующая строка:
Когда наконец подключается файл <ctype.h>, из-за этой директивы код, в котором toupper определена как extern inline, не может быть включён:
Обратите внимание, что при подключении <ctype.h> C++-версия toupper никогда не определяется в качестве макроса – максимум как extern inline – так как определения макросов в конце защищены проверкой !defined __cplusplus и поэтому никогда не вступят в силу.
В общем, я не знаю наверняка, должен ли __NO_CTYPE в данном случае исключать объявленные как extern inline тела функций tolower и toupper, но именно это и происходит – а отсюда и существенное падение скорости нашего цикла. В заключение могу сказать, что если вы включаете <cctype> вместо <ctype.h> (т.е. C++-версию заголовочного файла C, которая помещает функции в пространство имён std::), то и в этом случае код будет работать медленно, потому что <cctype> в конечном итоге включает и <bits/os_defines.h>.
Так ли это всё важно? Да нет.
Функция toupper не годится для серьёзной работы с символами разных языков, так что если вам нужно обрабатывать только ASCII-символы, то можете написать собственную более быструю реализацию. Если же требуется серьёзная работа с текстом, то, скорее всего, вы будете использовать UTF-8 и придётся применять какой-нибудь ICU, чтобы поддерживались региональные настройки, либо подождать, пока в C++ не появится поддержка Юникода (ждать, возможно, придётся долго). Так что заявление «clang-format может вызвать 4-кратное падение производительности» годится разве что в качестве кликбейт-заголовка.
Наблюдается ли этот эффект во всех версиях libc? Да, почти во всех, однако и тут всё не так просто.
Показанные выше результаты точно справедливы для gcc 5.5 и glibc 2.23, поскольку именно этими версиями пользовался я, но в новых версиях творится нечто странное (начиная примерно с glibc 2.27). Там включение <algorithm> перед <ctype.h> по-прежнему даёт тот же эффект, но теперь ещё проблемы создаёт и <stdlib.h> [10]: если его включить перед <ctype.h>, производительность также упадёт, чего не наблюдается в более ранних версиях. Очевидно, что в более новых версиях файл <stdlib.h> также содержит определение __NO_CTYPE. По крайней мере, теперь уже не получится свалить вину на сортировку clang-format – здесь она как раз может помочь решить проблему (если в списке подключаемых файлов отсутствуют другие проблемные файлы).
Я разместил отчёт об ошибке в libc, так что, наверно, конкретно этот баг починят, но можно не сомневаться, что ошибки, связанные с порядком подключения заголовочных файлов, будут донимать нас и дальше.
У меня на сайте нет системы комментирования, но я работаю над этим (т.е. периодически ною, что трудно сделать комментарии на статическом сайте).
А пока обсудить эту статью можно на сайте Hacker News или lobste.rs.
Спасибо пользователю ufo с Hacker News, который указал, что необязательно использовать лямбда-функцию, чтобы приспособить std::toupper для использования в std::transform, а также Джонатану Мюллеру, который объяснил, что лямбда-функция всё-таки нужна.
Примечание. Эта статья была впервые опубликована на сайте "Performance Matters". Перевод статьи размещаются здесь с разрешения автора.
Вообще-то мне нет никакого дела до функции toupper, просто я недавно писал другой пост и мне нужен был какой-то общий сюжетный стержень, а toupper кажется вполне интересным и безобидным кандидатом в бенчмарки. Я старался выбрать что-то максимально простое, что не увело бы меня в сторону, но так уж получилось, что в этом тесте я столкнулся со странной проблемой.
Этот пост будет небольшим – более обстоятельная статья на первоначальную, возможно более интересную тему ожидается в скором времени. Если захотите воспроизводить результаты вместе со мной, то исходный код можете взять на github.
Итак, рассмотрим три реализации функции toupper, которая переводит в верхний регистр символы некоторого массива, состоящего из элементов типа char, – а именно, принимает массив в качестве аргумента и непосредственно изменяет его элементы так, что все строчные буквы обращаются в прописные.
В первой реализации мы просто вызываем функцию toupper [1] стандартной библиотеки C и выполняем цикл в стиле C:
void toupper_rawloop(char* buf, size_t size) {
for (size_t i = 0; i < size; i++) {
buf[i] = toupper(buf[i]);
}
}Во второй реализации используем более современный подход с заменой «сырого» цикла на std::transform:
void toupper_transform(char* buf, size_t size) {
std::transform(buf, buf + size, buf, ::toupper);
}Наконец, в третьей реализации используем специальный алгоритм, работающий с ASCII- символами. Он проверяет, входит ли символ в диапазон a – z, и в случае успешной проверки подставляет эту же букву в верхнем регистре, вычитая из кода символа число 32 [2]:
void toupper_branch(char* buf, size_t size) {
for (size_t i = 0; i < size; i++) {
char c = buf[i];
if (c >= 'a' && c <= 'z') {
buf[i] = c - 32;
}
}
}Выглядит просто, правда?
Теперь измерим скорость работы этих реализаций на моём ноутбуке с процессором Skylake i7-6700HQ на компиляторе gcc 5.5 с настройками по умолчанию. Результаты даны в виде точечной диаграммы [3]:
Сразу разберёмся с тремя вопросами, которые неактуальны для нашей задачи.
Во-первых, посмотрите на график алгоритма с ветвлением (показан зелёным). Он значительно изменяется в зависимости от размера входных данных – другие два графика остаются практически ровными. На самом деле это всего лишь артефакт тестирования. Входные ASCII-символы выбираются случайным образом [4], поэтому решающим фактором в случае третьей реализации оказывается работа алгоритма предсказания ветвления. При малом количестве данных он целиком заучивает последовательность элементов по мере выполнения итераций, поэтому количество промахов невелико и скорость работы высокая, как показано в этой заметке. По мере роста размера последовательности данных алгоритм предсказания запоминает все меньше и меньше, пока наконец не начинает промахиваться с каждой прописной буквой (0,27 промахов на символ), и тогда график выравнивается.
Во-вторых, обратите внимание на группу зелёных пятнышек слева вверху, соответствующих намного более низким скоростям варианта с ветвлением toupper_branch:
Это не единичный артефакт: такие пятнышки появлялись при нескольких запусках. При этом их нельзя воспроизвести, если тестировать алгоритм только конкретно на этих размерах данных – они всплывают, только когда тест прогоняется по всем размерам. Но и в этом случае они появляются не всегда. Я не стал особо вникать, но могу предположить, что это связано с какими-то конфликтами имён или псевдонимов в алгоритме предсказания ветвления или при отображении физических страниц памяти размером 4 кБ на виртуальные (хотя рандомизация виртуального адресного пространства у меня была выключена).
В-третьих, реализация toupper_rawloop (показана синим) на графике выглядит как две отдельных линии: одна чуть выше отметки 2 тактов на символ, а другая – на уровне 1,5 тактов на символ. Эти две линии появлялись во всех тестировщиках. Более быстрый вариант, со скоростью 1,57 символов на такт, на самом деле тормозится на портах загрузки: чтение данных на портах 2 и 3 происходит со скоростью 1,54 микрооперации на такт, поэтому они будут заняты на 98%. Причину же более медленного «режима» я установить не смог.
Пока я разбирался с этим вопросом, быстрый «режим» внезапно исчез и остался только медленный. Возможно, процессор смекнул, что я пытаюсь сделать, и тайно скачал обновление для микрокода, чтобы убрать противоречие, но у меня (пока ещё) есть доказательство – векторное изображение с графиками.
Что же нас тогда интересует в этом примере?
А интересует нас то, что версия с «сырым» циклом в 3-4 раза быстрее версии с std::transform: 1,5-2 такта на символ против 7 с небольшим тактов на символ.
В чём же тут дело? Меня подвели стандартные алгоритмы? У std::transform есть какой-то изъян?
Не совсем. Точнее, вовсе нет.
Оказывается, такие результаты появляются, когда функции компилируются в разных файлах. Если поместить их в один и тот же файл, то производительность у них становится одинаково низкой.
И нет, выравнивание тут не при чём.
Но это ещё не всё: быстрая версия с «сырым» циклом, будучи скомпилированной в отдельном файле, замедляется, если к нему просто подключить заголовочный файл <algorithm>. Да, всё верно: достаточно подключить этот файл, который никогда не используется и не генерирует никакого кода в итоговом объектном файле, и скорость «сырого» цикла упадёт в 3-4 раза. Напротив, версия с std::transform разгоняется до предела, если скопировать и вставить реализацию std::transform из файла <algorithm>, а сам этот файл не подключать.
На этом странности не заканчиваются (больше их не будет, обещаю): подключение файла <algorithm> не всегда приводит к описанному эффекту. Падение скорости происходит, если <algorithm> подключается раньше, чем <ctype.h>, но если поменять их местами – то нет:
Медленный код:
#include <algorithm>
#include <ctype.h>Быстрый код:
#include <ctype.h>
#include <algorithm>Собственно, у меня эта аномалия проявлялась (в другом проекте), когда clang-format автоматически сортировал подключаемые заголовочные файлы и помещал <algorithm> в самое начало списка, где ему и место (отсюда и кликбейт-заголовок статьи).
Естественно, мы должны были рано или поздно окунуться в листинг ассемблера. Не будем оттягивать этот неприятный момент.
Ниже показаны быстрая и медленная версии функций [5], малые циклы снабжены аннотациями:
<algorithm> подключается первым:
toupper_rawloop(char*, unsigned long):
push rbp
push rbx
lea rbp, [rdi+rsi]
sub rsp, 8
test rsi, rsi
je .L1
mov rbx, rdi
.L5:
movsx edi, BYTE PTR [rbx] ; читаем char-символ из *buf
add rbx, 1 ; buf++
call toupper ; вызываем toupper(c)
mov BYTE PTR [rbx-1], al ; сохраняем результат в buf[-1]
cmp rbp, rbx ; проверяем buf == buf_end
jne .L5 ;
.L1:
add rsp, 8
pop rbx
pop rbp
ret<algorithm> подключается вторым:
toupper_rawloop(char*, unsigned long):
test rsi, rsi
je .L7
push rbp
push rbx
mov rbp, rsi
mov rbx, rdi
sub rsp, 8
call __ctype_toupper_loc
lea rsi, [rbx+rbp]
mov rdi, rbx
.L4:
; читаем char-символ из buf
movsx rcx, BYTE PTR [rdi]
; читаем адрес таблицы соответствия для toupper
; (по указателю из __ctype_toupper_loc)
mov rdx, QWORD PTR [rax]
; buf++
add rdi, 1
; ищем результат toupper в таблице,
; используя считанный символ в качестве индекса
mov edx, DWORD PTR [rdx+rcx*4]
mov BYTE PTR [rdi-1], dl ; сохраняем результат
cmp rsi, rdi ; проверяем buf == end_buf
jne .L4 ;
add rsp, 8
pop rbx
pop rbp
.L7:
rep retГлавное отличие состоит в том, что в медленной версии функция toupper просто вызывается в цикле, тогда как в быстрой версии вызовы функции вовсе отсутствуют, а есть только поиск по таблице соответствия [6], т.е. тело функции std::toupper подставляется на место вызова.
Если посмотреть на исходный код библиотеки glibc, мы найдём там реализацию функции toupper:
__extern_inline int
// __NTH – это макрос, показывающий, что функция не бросает исключений
__NTH (toupper (int __c))
{
return __c >= -128 &&
__c < 256 ?
(*__ctype_toupper_loc ())[__c] : __c;
}Как мы видим, toupper определена как extern inline функция, которая сначала проверяет, что размер char-символа умещается в один байт [7], а затем ищет символ в таблице соответствия, возвращаемой функцией __ctype_toupper_loc(). Эта функция возвращает локальный указатель потока (типа const int **), который, в свою очередь, указывает на таблицу соответствия, из которой в ответ на запрос по нашему символу возвращается его версия в верхнем регистре [8].
Теперь понятно, что происходит в листинге. В быстрой версии алгоритма компилятор подставляет тело функции toupper, но не может подставить вызов функции __ctype_toupper_loc() [9]. Этот вызов, однако, объявлен как __attribute__((const)), а это значит, что возвращаемое значение зависит только от аргументов (которых здесь нет). Компилятор знает, что эта функция каждый раз возвращает одно и то же значение, и поэтому выносит её вызов за пределы цикла, а в самом цикле остаётся только несколько операций чтения, связанных с обращением к таблице соответствия, записью нового значения в буфер и управлением циклом.
В медленной же версии вызов toupper() остаётся в теле цикла. Сам цикл короче на одну команду, но, разумеется, теперь ещё приходится выполнять и весь код внутри функции toupper. На моей системе это выглядит так:
lea edx,[rdi+0x80] ; edx = rdi + 0x80
movsxd rax,edi ; дополнение нулями переменной c
cmp edx,0x17f ; проверяем, что c входит в диапазон от -128 до 255
ja 2a ; если нет, завершаем работу
mov rdx,QWORD PTR [rip+0x395f30] ; считываем индекс локального
; хранилища потока
mov rdx,QWORD PTR fs:[rdx] ; обращаемся к локальному хранилищу
; потока по данному индексу
mov rdx,QWORD PTR [rdx] ; разыменовываем указатель на
; локальное хранилище потока
mov rdx,QWORD PTR [rdx+0x48] ; считываем текущую таблицу для toupper
mov eax,DWORD PTR [rdx+rax*4+0x200] ; считываем c из таблицы
2a:
retПоскольку это невстроенный вызов, программа совершает больше работы. Происходит не менее пяти последовательных операций обращения к памяти (так называемая погоня за указателями, pointer chasing). В быстрой версии из них остаются только две, так как все остальные выносятся за пределы цикла. Задержка между вызовом функции и выходом из неё должна быть около 25 тактов, а у нас выходит примерно 7 тактов – это означает, что процессор смог распараллелить вызов, что весьма неплохо, учитывая обстоятельства.
Почему так получается?
В длинной цепи подключаемых файлов заголовочные файлы C++, такие как <algorithm>, включают, в свою очередь, файл <bits/os_defines.h>, в котором содержится следующая строка:
// Эта директива не даёт функции isanum и др. воспроизводиться
// в качестве макросов.
#define __NO_CTYPE 1Когда наконец подключается файл <ctype.h>, из-за этой директивы код, в котором toupper определена как extern inline, не может быть включён:
#if !defined __NO_CTYPE
# ifdef __isctype_f
__isctype_f (alnum)
// и т.д. и т.п.
__isctype_f (xdigit)
# elif defined __isctype
# define isalnum(c) __isctype((c), _ISalnum)
# define isalpha(c) __isctype((c), _ISalpha)
// и т.д. и т.п.
# endif
// нас интересует вот эта часть
# ifdef __USE_EXTERN_INLINES
__extern_inline int
__NTH (tolower (int __c))
{
return __c >= -128 && __c < 256 ? (*__ctype_tolower_loc ())[__c] : __c;
}
__extern_inline int
__NTH (toupper (int __c))
{
return __c >= -128 && __c < 256 ? (*__ctype_toupper_loc ())[__c] : __c;
}
# endif
// вот здесь tolower определена в качестве макроса
# if __GNUC__ >= 2 && defined __OPTIMIZE__ && !defined __cplusplus
# define tolower(c) __tobody (c, tolower, *__ctype_tolower_loc (), (c))
# define toupper(c) __tobody (c, toupper, *__ctype_toupper_loc (), (c))
# endif /* Optimizing gcc */
#endif /* Not __NO_CTYPE. */Обратите внимание, что при подключении <ctype.h> C++-версия toupper никогда не определяется в качестве макроса – максимум как extern inline – так как определения макросов в конце защищены проверкой !defined __cplusplus и поэтому никогда не вступят в силу.
В общем, я не знаю наверняка, должен ли __NO_CTYPE в данном случае исключать объявленные как extern inline тела функций tolower и toupper, но именно это и происходит – а отсюда и существенное падение скорости нашего цикла. В заключение могу сказать, что если вы включаете <cctype> вместо <ctype.h> (т.е. C++-версию заголовочного файла C, которая помещает функции в пространство имён std::), то и в этом случае код будет работать медленно, потому что <cctype> в конечном итоге включает и <bits/os_defines.h>.
Так ли это всё важно? Да нет.
Функция toupper не годится для серьёзной работы с символами разных языков, так что если вам нужно обрабатывать только ASCII-символы, то можете написать собственную более быструю реализацию. Если же требуется серьёзная работа с текстом, то, скорее всего, вы будете использовать UTF-8 и придётся применять какой-нибудь ICU, чтобы поддерживались региональные настройки, либо подождать, пока в C++ не появится поддержка Юникода (ждать, возможно, придётся долго). Так что заявление «clang-format может вызвать 4-кратное падение производительности» годится разве что в качестве кликбейт-заголовка.
Наблюдается ли этот эффект во всех версиях libc? Да, почти во всех, однако и тут всё не так просто.
Показанные выше результаты точно справедливы для gcc 5.5 и glibc 2.23, поскольку именно этими версиями пользовался я, но в новых версиях творится нечто странное (начиная примерно с glibc 2.27). Там включение <algorithm> перед <ctype.h> по-прежнему даёт тот же эффект, но теперь ещё проблемы создаёт и <stdlib.h> [10]: если его включить перед <ctype.h>, производительность также упадёт, чего не наблюдается в более ранних версиях. Очевидно, что в более новых версиях файл <stdlib.h> также содержит определение __NO_CTYPE. По крайней мере, теперь уже не получится свалить вину на сортировку clang-format – здесь она как раз может помочь решить проблему (если в списке подключаемых файлов отсутствуют другие проблемные файлы).
Я разместил отчёт об ошибке в libc, так что, наверно, конкретно этот баг починят, но можно не сомневаться, что ошибки, связанные с порядком подключения заголовочных файлов, будут донимать нас и дальше.
Комментарии
У меня на сайте нет системы комментирования, но я работаю над этим (т.е. периодически ною, что трудно сделать комментарии на статическом сайте).
А пока обсудить эту статью можно на сайте Hacker News или lobste.rs.
Благодарности
Спасибо пользователю ufo с Hacker News, который указал, что необязательно использовать лямбда-функцию, чтобы приспособить std::toupper для использования в std::transform, а также Джонатану Мюллеру, который объяснил, что лямбда-функция всё-таки нужна.
- Да, функция toupper(3) из заголовочного файла <ctype.h> непригодна для работы с большинством не-ASCII символов, т.к. не умеет обрабатывать символы размером больше одного байта, но для нашей задачи она подойдёт, так как мы будем передавать ей строки только из ASCII-символов.
- В таблице ASCII символы нижнего и верхнего регистра очень удобно расположены – на расстоянии 32 позиций друг от друга, а это означает, что переводить символы из одного регистра в другой можно просто вычитая или прибавляя 32. Вообще, если бы мы знали наверняка, что все входные данные – это буквы ASCII, мы могли бы без всяких проверок сбрасывать 5-й бит (например, c&0b11011111), чтобы превратить любую прописную букву в строчную, в то время как на строчных буквах это никак не отразилось бы. Но наверняка мы не знаем, поэтому приходится проверять, является ли символ буквой, чтобы случайно не сломать небуквенные символы типа char.
- Её следовало бы назвать точечной диаграммой с добавлением «шума» в расположение точек. По сути, это обычная точечная диаграмма, в которой на оси x отложен интересующий нас параметр (размер входных данных), а на оси y – скорость работы (такты на символ – чем ниже значение, тем выше скорость). Главная особенность этой диаграммы заключается в том, что для каждого значения параметра на оси x выборка производится несколько раз: в данном случае тест повторяется 10 раз для каждого размера массива.
- А именно, символы выбираются случайно и равномерно из диапазона [32, 127], поэтому условие в функции будет верным примерно в 27% случаев.
- Оба листинга относятся к реализации с «сырым» циклом и отличаются лишь порядком подключения файлов <algorithm> и <ctype.h>. Генерируемый исходный код одинаков для всех реализаций – и в быстром, и в медленном вариантах. Например, реализация с std::transform даст такой же медленный ассемблерный код, если подключить файл <algorithm>, и такой же быстрый код, если скопировать только определение функции, а файл не подключать.
- Однако этот быстрый цикл работает медленнее, чем мог бы, потому что указатель на таблицу соответствия считывается излишне много раз (mov rdx, QWORD PTR [rax]) внутри цикла. Этот указатель может быть разным в зависимости от региональных настроек, но он не обновляется во время выполнения цикла и поэтому его можно было бы вынести за пределы цикла. Должно быть, компилятор считает, что оснований для этого недостаточно, так как мы пишем в массив из элементов типа char, а они в принципе могут использоваться в качестве псевдонимов для [rax] т.е. указателя на таблицу. Как бы там ни было, даже __restrict__ тут не поможет. А вот в другой версии цикла, где просто складываются значения toupper и в массив ничего не пишется, эта оптимизация применяется – указатель считывается за пределами цикла.
- Эта проверка не отражается в подставляемом ассемблерном коде, поскольку компилятор и так знает, что значения типа char всегда находятся в диапазоне [-128, 255]. Проверка нужна только потому, что API функции toupper© принимает значение типа int, а не char, чтобы пользователь мог передать ей любое привычное число типа int, тогда как таблицы соответствия рассчитаны только на значения типа char, так что проверка помогает избежать чтения за пределами буфера.
- Кстати, это объясняет, почему процедуры std::toupper не зависят от размера входных данных: они не используют ветвлений (кроме проверок диапазона, которые замечательно предсказываются), а используют не зависящую от ветвлений таблицу соответствия. ?
- Подставить этот вызов не получится даже при очень большом желании: тело функции недоступно в заголовочном файле.
- Я ни в коем случае не придираюсь к stdlib.h (или к <algorithm>, если уж на то пошло) – вполне возможно, что многие другие заголовочные файлы C и все заголовочные файлы C++ также вызывают это поведение, просто я не тестировал их. Я подключал stdlib.h только ради определения size_t.
Примечание. Эта статья была впервые опубликована на сайте "Performance Matters". Перевод статьи размещаются здесь с разрешения автора.
vgavro
не хочу показаться занудой, но по-моему чуть ли не в каждом лифте написано, что сортировка инклудов может изменить работу программы и в clang-format в случае автоформатирования ее настоятельно рекомендуют отключать.
myxo
Может быть и так, но я, например, не думал что это может аффектить не только компилируемость/корректность программы, но и производительность. Не то чтобы это какой-то нетривиальный вывод, просто не думал в этом ключе.