

Когда мы перестаем контролировать размер таблицы — обслуживание и обеспечение доступности данных становится нетривиальной задачей. Я с такой проблемой столкнулся уже в продакшне, данных с каждым днем становится больше, таблица не влезает в память, сервера отвечают долго, но решение было найдено.
Привет, Хабр! Меня зовут Алмаз и сейчас я хочу поделиться методом, который помог мне реализовать секционирование.
Секционирование в PostgreSql
Секционирование (или как еще называют — партицирование) — процесс разбиение одной большой логической таблицы на несколько меньших физических секций. Это то, что поможет нам управлять нашими данными.
Пример: у нас есть таблица “sales”, которая секционирована по интервалу один месяц, а эти секции могут быть разбиты на еще более мелкие подсекции по регионам.
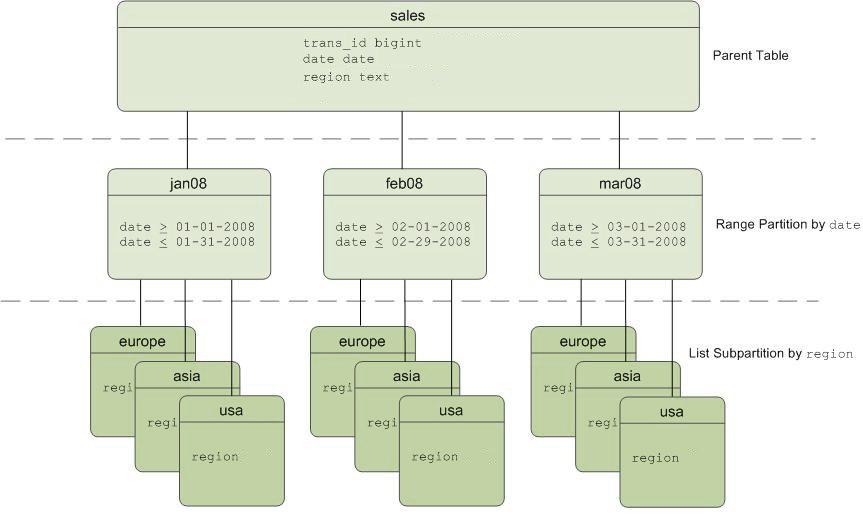
Схема секционированной таблицы “sales”
Минусы этого подхода:
— Усложняется структура базы данных. Каждая секция в определениях базы — это таблица, хоть и является частью одной логической сущности.
— Преобразовать существующую таблицу в секционированную и наоборот нельзя.
— Нет полной поддержки в версии Postgres 11.
Плюсы:
+ Быстродействие. В определенных случаях мы можем работать с ограниченным набором секций, не перебирая всю таблицу, даже поиск по индексу для больших таблиц будет медленнее. Повышается доступность данных.
+ Массовая загрузка и удаление данных командами ATTACH/DETACH. Это избавляет нас от накладных расходов в виде VACUUM-а. что позволяет более эффективно сопровождать базу данных.
+ Возможность указать TABLESPACE для секции. Это дает нам возможность выносить данные в другие разделы, но все же мы работаем в рамках одного инстанса и метаданные главного каталога будут содержать информацию о секциях.(не путать с шардингом)
2 пути к реализации секционирования в PostgreSql:
1. Наследование таблиц (INHERITS)
Когда, создавая таблицу, мы говорим «наследуйся от другой (родительской) таблицы». При этом добавляем ограничения для управления данными в таблице. Этим мы поддерживаем логику разбиения данных, но это логически разные таблицы.
Тут нужно отметить расширение разработанное компанией Postgres Professional pg_pathman, которое реализует секционирование, также через наследование таблиц.
CREATE TABLE orders_y2010 (
CHECK (log_date >= DATE '2010-01-01)
) INHERITS (orders);
2. Декларативный подход (PARTITION)
Таблица определяется как секционированная декларативно. Данное решение появилось в 10 версии PostgreSql.
CREATE TABLE orders (log_date date not null, …)
PARTITION BY RANGE(log_date); Я выбрал декларативный подход. Это дает большое преимущество — нативность, больше фич поддерживается ядром. Рассмотрим развитие PostgreSQL в данном направлении:

Источник
Но PostgreSql продолжает развиваться, и в 12 версии есть поддержка ссылок на секционированную таблицу. Это большой прорыв.
Мой путь
Учитывая вышесказанное, был написан скрипт на PL/pgSQL, который создает секционированную таблицу на основе существующей и “перекидывает” все ссылки на новую таблицу. Тем самым мы получаем секционированную таблицу на основе существующей и продолжаем работать с ней как с обычной таблицей.
Скрипт не требует дополнительных зависимостей и выполняется в отдельной схеме, которую создает сам. Также записывает логи повтора и отмены действий. Данный скрипт решает две основные задачи: создает секционированную таблицу и реализует внешние ссылки на нее через констрейнт триггеры.
Требование к скрипту: PostgreSql v.:11 и выше.
Сейчас пройдемся более детально по скрипту. Интерфейс очень прост:
есть две процедуры, которые делают всю работу.
1. Главный вызов — на этом этапе мы не меняем основную таблицу, но все необходимое для секционирования будет создано в отдельной схеме:
call partition_run(); 2. Вызов отложенных задач, которые были запланированы во время основной работы:
call partition_run_jobs(); Работа может быть запущена в несколько потоков. Оптимальное количество потоков близка к количеству секционируемых таблиц.
Входные параметры для скрипта (_pt record)

Скрипт изнутри, основные действия:
— Создаем секционированную таблицу
perform _partition_create_parent_table(_pt); — Создаем секции
perform _partition_create_child_tables(_pt); — Копируем данные в секции
perform _partition_copy_data(_pt); — Добавим ограничения (job)
perform _partition_add_constraints(_pt); — Восстановим ссылки на внешние таблицы
perform _partition_restore_referrences(_pt); — Восстановим триггеры
perform _partition_restore_triggers(_pt); — Создаем событийный триггер
perform _partition_def_tr_on_delete(_pt); — Создаем индексы (job)
perform _partition_create_index(_pt); — Заменяем вьюхи, ссылки на секцию (job)
perform _partition_replace_view(_pt); Время работы скрипта зависит от многих факторов, но основные — это размер целевых таблиц, количества отношений, индексы и характеристики сервера. В моем случае таблица 300Gb секционировалась меньше чем за час.
Результат
Что мы получили? Посмотрим на план запроса:
EXPLAIN ANALYZE
select * from “sales” where dt BETWEEN '01.01.2019'::date and '14.01.2019'::date 
Результат из секционированной таблицы мы получали быстрее и использовали меньше ресурсов нашего сервера по сравнению с запросом к обычной таблице.
В данном примере обычная и секционированные таблицы находятся на одной базе и имеют около 200М записей. Это хороший результат, учитывая то, что мы, не переписывая прикладной код, получили ускорение. Запросы по другим индексам также работают хорошо, но следует помнить: всегда, когда мы можем определить секцию, результат будет в несколько раз быстрее, т.к. PostgreSql умеет отбрасывать лишние секции на этапе планирования запроса (set enable_partition_pruning to on).
Итог
Мне удалось реализовать секционирование на таблицах, которые имеют множество связей и обеспечить целостность базы данных. Скрипт не зависит от конкретных структур данных и может быть переиспользован.
PostgreSQL — самая современная в мире реляционная база данных с открытым исходным кодом!
Всем спасибо!
Ссылка на исходник
Комментарии (20)

kirovilya
24.12.2019 11:58в 12 версии есть поддержка ссылок на секционированную таблицу. Это большой прорыв
Как оказалось, не такой уж и большой, т.к. в этом случае первичный ключ секционируемой таблицы должен содержать поле, по которому поисходит секционирование. А это очень печально.
kibermat Автор
24.12.2019 12:10Это справедливо и для 11 версии. Можете уточнить?
kirovilya
24.12.2019 13:15что уточнить? на собственном опыте проверили на PG 12.
в PG 11 нельзя было создать первичный ключ без ключа секционирования, а PG 12 просто появилась возможность ссылаться на такой ключ (создавать внешний ключ).
вот еще пруф fragland.dev/a-guide-to-table-partitioning-with-postgresql-12kibermat Автор
24.12.2019 13:29Это было далеко не просто, но в целом вы правы. Первичный ключ содержит ключ секционирования, не вижу в этом проблемы.
Это может быть сложно, если вы не знаете правила по которому можно определить этот ключ.kirovilya
24.12.2019 13:34Сложно, когда в рабочей схеме БД решили сделать секционирование таблицы — придется менять не только эту таблицу, но и структуру таблиц, ссылающихся на нее (добавлять во внешние ключи поле, не относящееся к этим таблицам), менять логику их заполнения и обращения к ним.
Проще тогда попытаться сделать FK на триггерах…
Другими словами, мы отбросили эту идею в долгий ящик.kibermat Автор
24.12.2019 13:40Спасибо за ответ. Я ещё не реализовал у себя нативную поддержку FK 12 версии. Использую решение на триггерах.

grufos
26.12.2019 18:20Как вы решили у себя проблему создания новых секций?
Мы создали такой «job», на основе pg_cron, который 1 раз в день (у нас секционирование по 1 дню используется) добавляет новую секцию к таблице.
Kwisatz
Не будет ли вам трудно у «обычной» таблицы создать индекс по дате и провести тест еще разок? Если бы вы explain analyze приложили, было бы вообще шикарно.
kibermat Автор
Analyze к «обычной» таблице


Analyze к секционированной
Надеюсь, на скринах будет видно
Melkij
Замечательно видно что вы тестируете в неравных условиях. См. actual rows.
kibermat Автор
Все верно замечено, исправил.
Kwisatz
Вот только разница в 22 раза это все равно очень много и не объясняется секционированием. Разные конфигурации бд?
kibermat Автор
Да, нужно ориентировать на цифры в статье см. таблицу в разделе Результат. Отклонения от этого объясняется разными конфигурациями сервера.
Kwisatz
Цифры в статье тоже слишком большие, не должно быть такого прироста. Поэтому я и спрашиваю.
kibermat Автор
Секционирование не является решением, которая способна дать профит для любой базы. Могут быть случаи, когда это отразится плохо на производительности. Для принятия такого решения нужно оценить все риски, если вы не получаете желаемого результата, то возможно это не то что вам нужно.
Kwisatz
Слишком общие не подкрепленные у вас заявление, ответ ради ответа. Я в курсе всех особенностей, а вот ваши цифры все равно выглядят завышеными.
Kwisatz
Сначала пришел в ужас от разницы в 220 раз, потом заметил, что во втором случае 0 строк, не пойдет)