
Согласно требованиям Google Play, apk-файл приложения должен быть не более 50 МБ, так же можно прикрепить два файла дополнения .obb по 2 гигабайта. Механизм простой, но сложный при эксплуатации, поэтому лучше всего уложиться в 50 МБ и возрадоваться. И в этом нам помогут целых два архивных формата Zip и 7z.
Давайте рассмотрим их работу на примере уже готового тестового приложения ZipExample.
Для тестов была создана sqlite база данных test_data.db. Она содержит 2 таблицы android_metadata — по традиции и my_test_data с миллионом строчек:
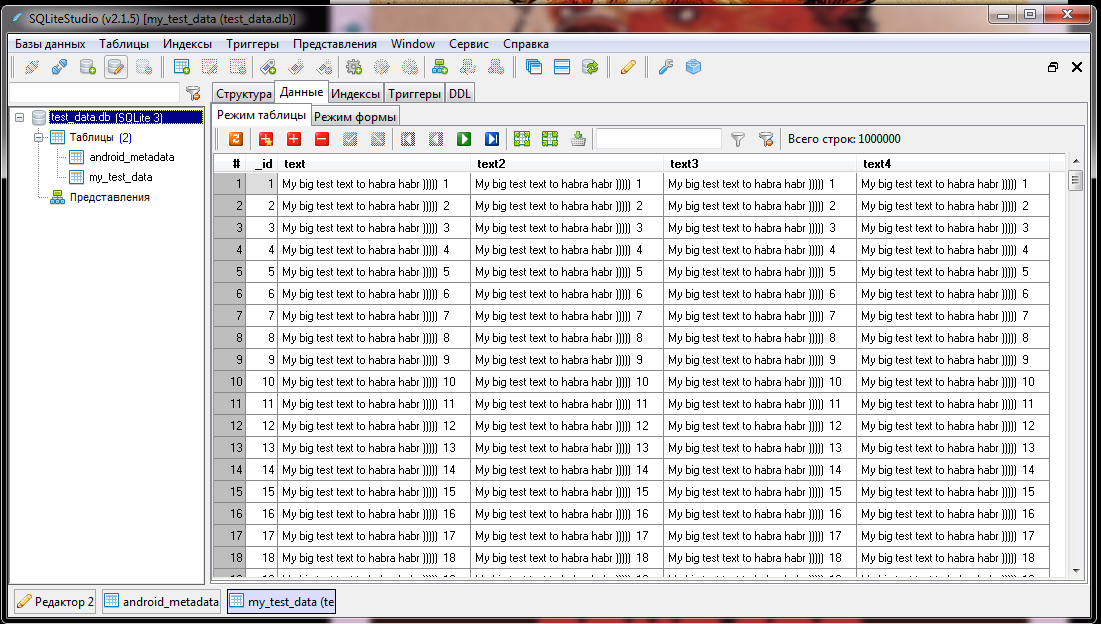
Размер полученного файла составляет 198 МБ.
Сделаем два архива test_data.zip (10.1 МБ) и test_data.7z (3.05 МБ).
Как очевидно, файлы БД sqlite очень хорошо сжимаются. По опыту могу сказать, что чем проще структура базы, тем лучше сжимается. Оба этих файла располагаются в папке assets и в процессе работы будут разархивированы.
Внешний вид программы представляет собой окно с текстом и двумя кнопками:

Вот метод распаковки zip архива:
public void onUnzipZip(View v) throws IOException {
SimpleDateFormat sdf = new SimpleDateFormat(" HH:mm:ss.SSS");
String currentDateandTime = sdf.format(new Date());
String log = mTVLog.getText().toString() + "\nStart unzip zip" + currentDateandTime;
mTVLog.setText(log);
InputStream is = getAssets().open("test_data.zip");
File db_path = getDatabasePath("zip.db");
if (!db_path.exists())
db_path.getParentFile().mkdirs();
OutputStream os = new FileOutputStream(db_path);
ZipInputStream zis = new ZipInputStream(new BufferedInputStream(is));
ZipEntry ze;
while ((ze = zis.getNextEntry()) != null) {
byte[] buffer = new byte[1024];
int count;
while ((count = zis.read(buffer)) > -1) {
os.write(buffer, 0, count);
}
os.close();
zis.closeEntry();
}
zis.close();
is.close();
currentDateandTime = sdf.format(new Date());
log = mTVLog.getText().toString() + "\nEnd unzip zip" + currentDateandTime;
mTVLog.setText(log);
}
Распаковывающим классом тут является ZipInputStream он входит в пакет java.util.zip, а тот в свою очередь в стандартную Android SDK и поэтому работает «из коробки» т.е. ничего отдельно закачивать не надо.
Вот метод распаковки 7z архива:
public void onUnzip7Zip(View v) throws IOException {
SimpleDateFormat sdf = new SimpleDateFormat(" HH:mm:ss.SSS");
String currentDateandTime = sdf.format(new Date());
String log = mTVLog.getText().toString() + "\nStart unzip 7zip" + currentDateandTime;
mTVLog.setText(log);
File db_path = getDatabasePath("7zip.db");
if (!db_path.exists())
db_path.getParentFile().mkdirs();
SevenZFile sevenZFile = new SevenZFile(getAssetFile(this, "test_data.7z", "tmp"));
SevenZArchiveEntry entry = sevenZFile.getNextEntry();
OutputStream os = new FileOutputStream(db_path);
while (entry != null) {
byte[] buffer = new byte[8192];//
int count;
while ((count = sevenZFile.read(buffer, 0, buffer.length)) > -1) {
os.write(buffer, 0, count);
}
entry = sevenZFile.getNextEntry();
}
sevenZFile.close();
os.close();
currentDateandTime = sdf.format(new Date());
log = mTVLog.getText().toString() + "\nEnd unzip 7zip" + currentDateandTime;
mTVLog.setText(log);
}
И его помощник:
public static File getAssetFile(Context context, String asset_name, String name)
throws IOException {
File cacheFile = new File(context.getCacheDir(), name);
try {
InputStream inputStream = context.getAssets().open(asset_name);
try {
FileOutputStream outputStream = new FileOutputStream(cacheFile);
try {
byte[] buf = new byte[1024];
int len;
while ((len = inputStream.read(buf)) > 0) {
outputStream.write(buf, 0, len);
}
} finally {
outputStream.close();
}
} finally {
inputStream.close();
}
} catch (IOException e) {
throw new IOException("Could not open file" + asset_name, e);
}
return cacheFile;
}
Сначала мы копируем файл архива из asserts , а потом разархивируем при помощи SevenZFile . Он находится в пакете org.apache.commons.compress.archivers.sevenz; и поэтому перед его использованием нужно прописать в build.gradle зависимость: compile 'org.apache.commons:commons-compress:1.8'.
Android Stuodio сама скачает библиотеки, а если они устарели, то подскажет о наличии обновления.
Вот экран работающего приложения:
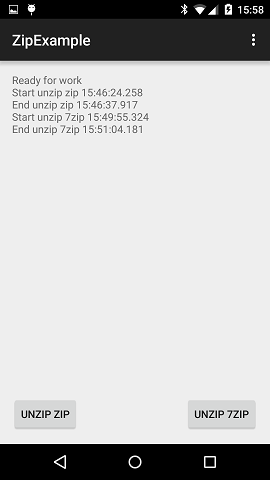
Размер отладочной версии приложения получился 6,8 МБ.
А вот его размер в устройстве после распаковки:
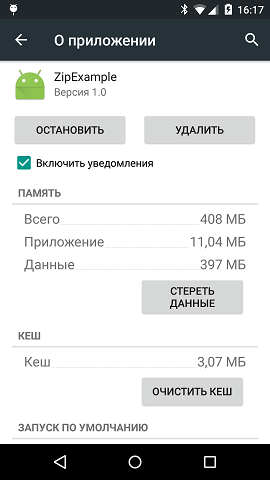
Внимание вопрос
В заключении хочу сказать, что распаковка архивов занимает продолжительное время и поэтому нельзя его делать в основном (UI) потоке. Это приведет к подвисанию интерфейса. Во избежание этого можно задействовать AsyncTask , а лучше фоновый сервис т.к. пользователь может не дождаться распаковки и выйти, а вы получите ошибку (правда если не поставите костылей в методе onPostExecute).
Буду рад конструктивной критике в комментариях.
Комментарии (10)

DigitalSmile
13.08.2015 18:04+4Мне кажется у Вас небольшая проблема с исходными данными.
Судя по скриншоту у Вас почти одинаковые строчки в базе, а насколько мне помнится алгоритмы 7z и zip по умолчанию используют словарное сжатие, поэтому у вас со 198Мб порезалось до 3/10. Боюсь с реальными данными все не будет столь радужно…
Тем не менее спасибо за статью.
petrovichtim
14.08.2015 09:43Вот база реального проекта размер 158 Мб, 15 таблиц и примерно 300 000 записей во всех таблицах, архив Zip — 44,7 Мб, архив 7z — 19,6 Мб
DigitalSmile
14.08.2015 13:35Спасибо за цифры.
А не пробовали другие алгоритмы сжатия использовать? Было бы интересно глянуть на результаты по сжатию различными алгоритмами.petrovichtim
14.08.2015 13:37Другие алгоритмы пробовал, но особого прироста уровня сжатия не заметил.

KamiSempai
14.08.2015 00:20+1Хм. Все ZipEntry распаковываются в один файл. Если в архиве будет больше одного файла они сольются в один.
Приведенный пример не совсем корректен. Под каждый ZipEntry нужно создавать отдельные файлы. А еще ZipEntry бывают директорией и это тоже нужно учитывать.petrovichtim
14.08.2015 09:35-1Все верно у ZipEntry есть свойство isDirectory(). Еще можно было рассказать про размер буфера копирования, т.к. его теоретически можно оптимизировать, но на стеке рассказали что овчинка выделки не стоит.
KamiSempai
14.08.2015 10:21+1Если все верно, почему в статье я этого не вижу? И я не про свойство isDirectory. В статье есть более существенный недостаток о котором я написал выше. Кстати, у 7z такая же проблема.
KamiSempai
14.08.2015 12:17Заглянул в доки org.apache.commons.compress.archivers.sevenz. До чего же однобоко они сделали работу с 7z. Почему нельзя было сделать чтение из InputStreem как и в остальных случаях?
HotIceCream
Не совсем верно. Android Studio проверяет обновления только определенных библиотек.
Тут подробнее: stackoverflow.com/questions/31502189/how-does-android-studio-know-about-new-dependency-versions/31635666#31635666
Для того, что бы проверить актуальность библиотек можно воспользоваться плагином: github.com/ben-manes/gradle-versions-plugin
petrovichtim
Спасибо, буду знать.