
Work in several GitHub repositories (repos) brings inconveniences. Repos are separated from each other, open and closed issues live in different lists, linked pull requests (PRs) can't be seen until opening an issue — our team works in more than 70 repos, so I learned that hard. And started to write repos tracker on Python. It's close to the final, I'd like to share it (it's completely free), and few tricks I used in progress.
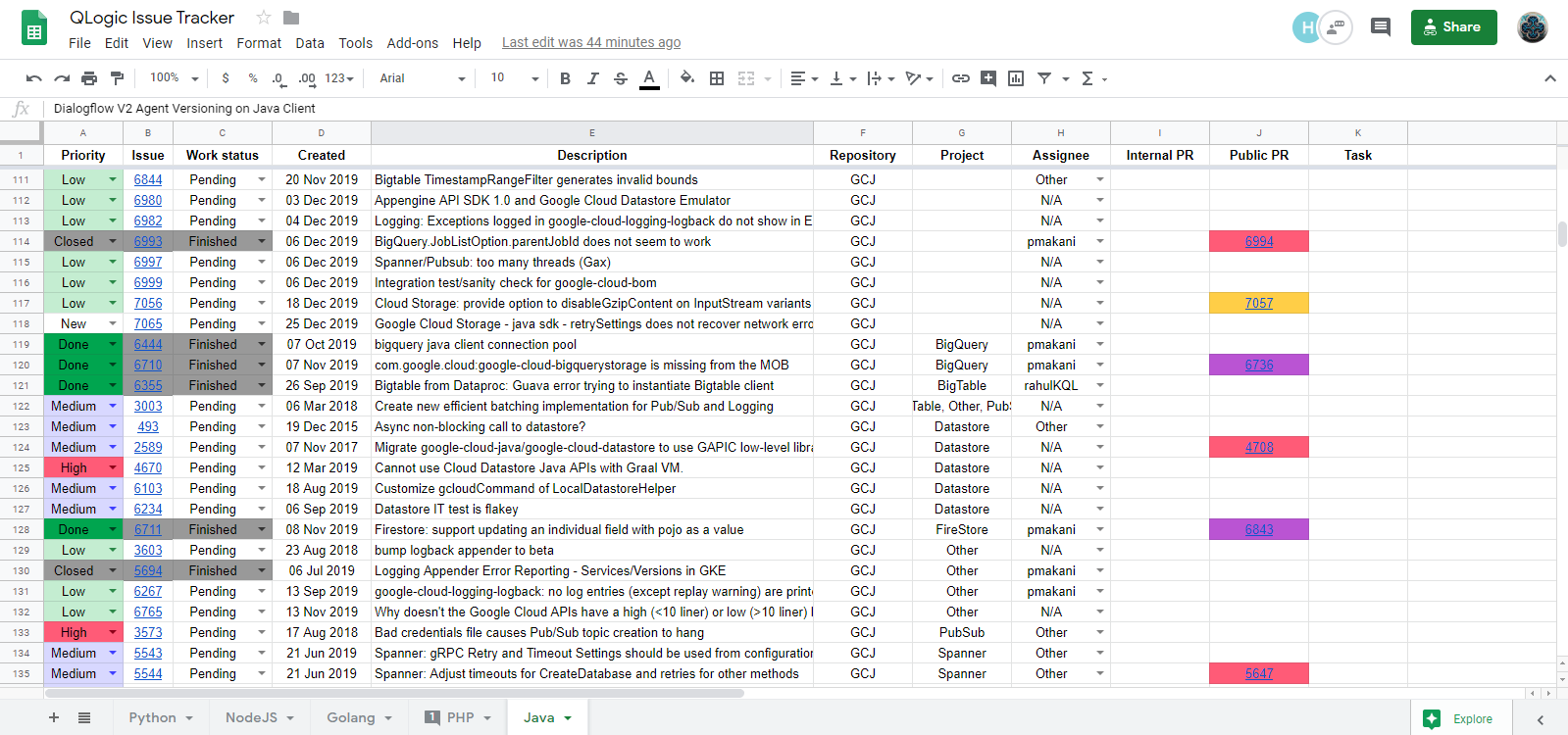
Scraper tracks several GitHub repos in a single Google Sheet (GS) table. You can see all of the opened and done issues, related PRs, priorities, your teammates comments, use coloring, filtering, sorting and other GS functions. That's a good integration, here is how it looks:
There is Spreadsheet() class which contain several Sheet() objects, each of which have it's own configurations, described in config.py. When Scraper updates a sheet, it loads configurations, sees list of repos to track, requests info from GitHub, builds a table and sends it to GS service. Sounds easy, but there were several tough to deal with things, which I've solved mostly with support of my work experience in Google projects, and which I consider as good patterns. Take a pen.
The first problem was large Scraper configurations. You need to describe parameters for every column in your table: alignment, possible values, width, colors, etc. It's not hard to write them, they are intuitive, but when you see them first time… well…
Problem was solved by keeping configurations completely in Python modules. It's much more easier to load py-file than txt (as you'll don't have to parse raw text) or pickle (user will be able to redact configurations in any moment, and you don't need to invent interfaces for such causes). And, of course, py-files can be easily reloaded (to pull new configurations in case they changed) with just a couple of lines:
The second problem is related to big configurations as well. When you have hundreds of lines in configurations, you probably should write docs to teach users to use it. But there is another way: add a completely workable examples with small comments. It's easier for user to understand the program this way, you'll don't have to write large docs, and potentially users will don't have to write their configurations from zero point — they'll be using those you wrote with small changes. They in fact will be able to run the app without writing configurations at all — just to check if it works.
So, examples were written in the separate directory, and original files (for which examples were written) were added into .gitignore. Why? To let users, who're tracking Scraper repo, feel comfortable with their configurations — as files are not be Git-tracked, users can do whatever they want in them, and pull (or push) changes without conflicts.
Scraper can generate a lot of requests for GS service. Processing 200 requests can be slow, it requires to increment socket timeout. To partially deal with this problem such a class was written:
You're instancing Iterator, passing list of requests into it, like:
And Iterator gives you these requests in batches of the given size. It works in one direction, without cycling, thus, it's very primitive, but it's one of the good Python patterns (which is usually out of the table somewhy). And sending requests piece by piece excluded app freezing as well as timeout errors.
Now of unit tests. As Scraper works with two services: GitHub and Google Sheets, and requires two accounts, it's not easy to mock Scraper objects. It requires to write three-five different patches to run method isolated, and that's not an option. The way to solve this problem (the way not all consider, as practise shows) is to use OOP itself. We can inherit real class, override some methods — those, which speak with remote services, and make them return values valid for tests. With this we don't have to write patches again and again. This is what was done in Scraper.
The last thing I'd like to share is not very beautiful. It's a good practise to add GitHub Actions into repo to automate tests and lint checks (and a lot of other stuff) on a PR creation. But Actions in fact can only use code from the repo — nothing more, nothing less.
As you remember, original configuration files were added into .gitignore. That means, there are no such a files in Scraper's repo. But Scraper is using them! And when Action starts, we're getting an ImportError. Sounds like while bringing convenience to users we're brought inconvenience to ourselves. Yes, that's tough to deal with, but Python importing system gives us some magic.
As we already understood, there are no configuration files in the repo, but there are examples for them. And they are completely workable. So, let's do the bad thing, and add examples into Python modules, but with names of the original configurations:
Yes! Now when any Scraper's module will try to import config, it'll get examples.config_example under the hood. Python is okay with it, and Actions are now working! Our only concern is that code is not as cute as it should be, but unit tests is ancillary code in fact, so we can use some freedom.
That's all I have, hope, was useful. Stay wise!
—
Ilya,
QLogic LLC,
Python/Go developer
GitHub acc | Personal page
What is that
Scraper tracks several GitHub repos in a single Google Sheet (GS) table. You can see all of the opened and done issues, related PRs, priorities, your teammates comments, use coloring, filtering, sorting and other GS functions. That's a good integration, here is how it looks:
How does it work, shortly
There is Spreadsheet() class which contain several Sheet() objects, each of which have it's own configurations, described in config.py. When Scraper updates a sheet, it loads configurations, sees list of repos to track, requests info from GitHub, builds a table and sends it to GS service. Sounds easy, but there were several tough to deal with things, which I've solved mostly with support of my work experience in Google projects, and which I consider as good patterns. Take a pen.
Config modules
The first problem was large Scraper configurations. You need to describe parameters for every column in your table: alignment, possible values, width, colors, etc. It's not hard to write them, they are intuitive, but when you see them first time… well…
Problem was solved by keeping configurations completely in Python modules. It's much more easier to load py-file than txt (as you'll don't have to parse raw text) or pickle (user will be able to redact configurations in any moment, and you don't need to invent interfaces for such causes). And, of course, py-files can be easily reloaded (to pull new configurations in case they changed) with just a couple of lines:
import importlib
config = importlib.reload(config)Examples
The second problem is related to big configurations as well. When you have hundreds of lines in configurations, you probably should write docs to teach users to use it. But there is another way: add a completely workable examples with small comments. It's easier for user to understand the program this way, you'll don't have to write large docs, and potentially users will don't have to write their configurations from zero point — they'll be using those you wrote with small changes. They in fact will be able to run the app without writing configurations at all — just to check if it works.
So, examples were written in the separate directory, and original files (for which examples were written) were added into .gitignore. Why? To let users, who're tracking Scraper repo, feel comfortable with their configurations — as files are not be Git-tracked, users can do whatever they want in them, and pull (or push) changes without conflicts.
Batching
Scraper can generate a lot of requests for GS service. Processing 200 requests can be slow, it requires to increment socket timeout. To partially deal with this problem such a class was written:
class BatchIterator:
"""Helper for iterating requests in batches.
Args:
requests (list): List of requests to iterate.
size (int): Size of a single one batch.
"""
def __init__(self, requests, size=20):
self._requests = requests
self._size = size
self._pos = 0
def __iter__(self):
return self
def __next__(self):
"""Return requests batch with given size.
Returns:
list: Requests batch.
"""
batch = self._requests[self._pos : self._pos + self._size] # noqa: E203
self._pos += self._size
if not batch:
raise StopIteration()
return batchYou're instancing Iterator, passing list of requests into it, like:
for batch in BatchIterator(requests):And Iterator gives you these requests in batches of the given size. It works in one direction, without cycling, thus, it's very primitive, but it's one of the good Python patterns (which is usually out of the table somewhy). And sending requests piece by piece excluded app freezing as well as timeout errors.
Manual mocks
Now of unit tests. As Scraper works with two services: GitHub and Google Sheets, and requires two accounts, it's not easy to mock Scraper objects. It requires to write three-five different patches to run method isolated, and that's not an option. The way to solve this problem (the way not all consider, as practise shows) is to use OOP itself. We can inherit real class, override some methods — those, which speak with remote services, and make them return values valid for tests. With this we don't have to write patches again and again. This is what was done in Scraper.
Import hack to make GitHub Actions work
The last thing I'd like to share is not very beautiful. It's a good practise to add GitHub Actions into repo to automate tests and lint checks (and a lot of other stuff) on a PR creation. But Actions in fact can only use code from the repo — nothing more, nothing less.
As you remember, original configuration files were added into .gitignore. That means, there are no such a files in Scraper's repo. But Scraper is using them! And when Action starts, we're getting an ImportError. Sounds like while bringing convenience to users we're brought inconvenience to ourselves. Yes, that's tough to deal with, but Python importing system gives us some magic.
As we already understood, there are no configuration files in the repo, but there are examples for them. And they are completely workable. So, let's do the bad thing, and add examples into Python modules, but with names of the original configurations:
import sys
import examples.config_example
sys.modules["config"] = examples.config_exampleYes! Now when any Scraper's module will try to import config, it'll get examples.config_example under the hood. Python is okay with it, and Actions are now working! Our only concern is that code is not as cute as it should be, but unit tests is ancillary code in fact, so we can use some freedom.
That's all I have, hope, was useful. Stay wise!
—
Ilya,
QLogic LLC,
Python/Go developer
GitHub acc | Personal page