
В предыдущих постах я описал проблемы, с которыми столкнулся при создании библиотеки для работы с интервалами. Сейчас я опишу вам моё решение: улучшения концепции интервалов, которые позволяют создавать интервалы с ограничителями и бесконечные интервалы, прекрасно вписывающиеся в иерархию стандартной библиотеки без потери производительности.
В конце предыдущего поста я просуммировал недостатки существующих интервалов:
Первая проблема особенно трудная, поэтому начнём с неё.
Для начала, давайте строго определим понятие интервала. В стандарте C++ это слово используется повсюду, но нигде не определяется. Можно понять, что интервал – это нечто, из чего можно извлечь begin и end, пару итераторов, которые устроены так, что до end можно добраться, начав с begin. В терминах моего предложения формализовать эту концепцию можно так:
Также есть улучшения концепции интервала Range, которые называются InputRange, ForwardRange, и т.д. На деле они просто больше требуют от своих итераторов. Ниже показана вся эта иерархия.
Эти концепции являются основой для библиотеки Boost.Range (http://www.boost.org/libs/range)
Если помните, для реализации интервалов как с ограничителем, так и бесконечных, в виде пары итераторов, итератор end должен быть сигнальным. И такой итератор представляет собой больше концепцию, чем физическое положение элемента в последовательности. Можно представлять его, как элемент с позицией «последний + 1» – разница лишь в том, что вы не узнаете, где его позиция, пока не достигнете её. Поскольку тип сигнального итератора такой же, как у обычного, требуется проверка на этапе выполнения программы, чтобы определить, является ли данный итератор сигнальным. Это приводит к медленному сравнению итераторов и неудобным реализациям методов.
Для чего нужны итераторы? Мы увеличиваем их, разыменовываем и сравниваем, так ведь? А что можно сделать с сигнальным итератором? Не особенно много чего. Его позиция не меняется, его нельзя разыменовать, т.к. его позиция всегда «последний + 1». Но его можно сравнить с итератором. Получается, что сигнальный итератор – слабый итератор.
Проблема с интервалами в том, что мы пытаемся превратить сигнальный итератор в обычный. Но он им не является. Так и не будем это делать – пусть они будут другого типа.
Концепция Range требует, чтобы begin и end были одного типа. Если можно их сделать разными, это уже будет более слабая концепция – концепция Iterable. Инкременторы – они как итераторы, только у begin и end разные типы. Концепция:
Естественно, концепция Range входит в концепцию Iterable. Она просто уточняет её, добавляя ограничение на равенство типов begin и end.
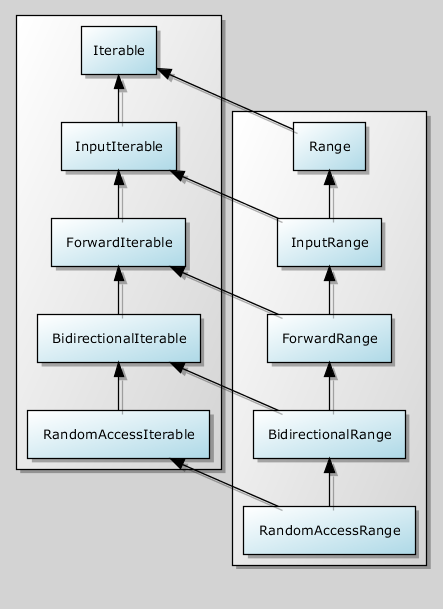
Так выглядит иерархия, если мы рассматриваем интервалы, инкременторы и итераторы, но совершенно не обязательно именно так определять их и в программе. Заметьте, что «интервальность» – т.е., схожесть типов begin и end, ортогональна силе итератора begin. Когда нам надо включать в код моделирование RandomAccessRange, мы можем сказать requires RandomAccessIterable && Range и просто сменить всю концепцию.
Разница между, к примеру, BidirectionalIterable и ForwardIterable в концепции, моделируемой итератором begin из Iterable.
Но постойте – ведь алгоритмы STL не будут работать с инкременторами, потому что им требуется, чтобы у begin и end было один тип. Так и есть. Поэтому я прошерстил весь STL, чтобы проверить, что можно переписать. Например, std::find
Сейчас std::find использует Ranges. Но заметьте, что алгоритм не пытается поменять позицию итератора end. Алгоритм поиска можно легко поменять так, чтобы он работал с Iterables вместо Ranges:
Вот и всё – изменение настолько малое, что его даже заметить трудно.
Так какие алгоритмы C++98 можно приспособить к работе с Iterables вместо Ranges? Оказывается, почти все. Легче перечислить те, которые не поддаются. Это:
Остальные полсотни требуют чисто механического изменения в коде. Определив концепцию Iterable так, как она определяется в Range, мы даём любому алгоритму, работающему с Iterable, возможность точно так же работать и с Ranges. Это полезно и важно – для итераторов написано слишком много кода, чтобы делать для них какую-то несовместимую абстракцию.
И что мы получим? Вернёмся к нашим С-строкам. Я описал класс c_string_range и нашёл, что перебор символов генерит плохой код. Начнём снова, только при помощи range_facade, чтобы построить Iterable вместо Range.
Код получился гораздо проще, чем старый. Всю работу делает range_facade. Итератор и сигнальный итератор реализованы в виде примитивов. Чтобы проверить его, я сгенерил оптимизированный машинный код для следующих функций, одна из которых использует старый класс c_string_range, а другая – новый c_string_iterable:
Даже не зная ассемблера, можно понять разницу.
Код с инкременторами гораздо круче. И он практически идентичен с ассемблером, полученным из итераторов «голого» С.
Но что означает сравнение двух объектов разных типов на эквивалентность?
Немного для непосвященных: N3351 определяет, в каких случаях допустимы сравнения разных типов. Недостаточно, чтобы синтаксис «x==y» был допустим и выдавал булевское значение. Если у х и у будут разные типы, то эти типы должны быть сами по себе EqualityComparable, и у них должен быть общий тип, к которому их можно преобразовать, и он также должен быть EqualityComparable. Допустим, мы сравниваем char и short. Это возможно, поскольку они EqualityComparable, и их можно преобразовать в int, который тоже EqualityComparable.
Итераторы можно сравнивать, а сигнальные итераторы сравниваются тривиальным образом. Сложность в том, чтобы найти для них общий тип. Вообще, у каждого итератора и сигнального есть общий тип, который можно создать так: предположим существование нового типа итератора I, который представляет собой тип-сумму, и содержит либо итератор, либо сигнальный итератор. Когда их сравнивают, он ведёт себя семантически так, будто их обоих сначала преобразовали в два объекта типа I, назовём их lhs и rhs, и затем сравнили по следующей табличке:
Эта табличка напоминает ту, которая получилась при анализе поведения оператора сравнения c_string_range::iterator. Это не случайно – то был особый случай этой, более общей, схемы. Она подтверждает интуитивное заключение, которое вы уже можете заметить, просмотрев два моих класса, c_string_range и c_string_iterable. Один – пара итераторов, другой – пара итератор/сигнальный, но их схема работы схожи. Мы чувствуем, что возможно построить эквивалентный Range из любого Iterable, если пожертвовать небольшой толикой быстродействия. И теперь мы нашли подтверждение этому.
Возможность сравнивать итераторы и сигнальные итераторы напрямую позволяет нам использовать систему типов C++ для оптимизации большой категории итераций, убирая разветвления в операторе сравнения паритетности.
Идея дать разные типы begin и end не нова, и придумал её не я. Я узнал о ней от Дэйва Абрахамса (Dave Abrahams) много лет назад. Недавно сходную идею подал Дитмар Кюэль (Dietmar Kuehl) в списке рассылки Ranges, а в ответ на его письмо Шон Пэрент (Sean Parent) высказал следующее возражение:
Если я правильно его понял, он говорит о существовании трёх параллельных концепций интервалов: IteratorRange, CountedRange и SentinelRange. И эти иерархии не нужно пытаться связать между собой. Алгоритм копирования должен содержать три разные реализации, по одной на каждую концепцию. Тогда придётся утроить порядка 50 алгоритмов – и это слишком много повторения в коде.
Хуже того, некоторые алгоритмы основаны на уточнённых концепциях. Например, в libc++ алгоритм rotate выбирает одну из трёх реализаций, в зависимости от того, передаёте вы ему прямые, двунаправленные или итераторы произвольного доступа. А для включения трёх разных реализаций Iterator, Counted и SentinelRanges потребовалось бы 9 алгоритмов rotate! При всём уважении, это безумие.
В начале поста я привёл список проблем, связанных с интервалами с парными итераторами. Я показал новую концепцию, Iterable, которая занимается вопросами быстродействия, и затронул вопрос сложностей реализации интервалов. Пока я не описал, как эта концепция работает с бесконечными интервалами, о чём мы поговорим в четвёртом, финальном посте.
Весь код можно найти в репозитории на github.
Я хотел бы поблагодарить Эндрю Суттона (Andrew Sutton) за помомщь с синтаксисом Concpets Lite и за объяснение требований концепции EqualityComparable для разных типов и общее улучшение и формализацию многих идей. Статьи стали значительно лучше благодаря его большому вкладу.
Другие статьи цикла
Интервалы в С++, часть 1: Интервалы с ограничителями
Интервалы в С++, часть 2: Бесконечные интервалы
Интервалы в С++, часть 4: к бесконечности и далее
В конце предыдущего поста я просуммировал недостатки существующих интервалов:
- интервалы с ограничителями и бесконечные интервалы генерят плохой код
- им приходится моделировать более слабые концепции, чем они могли бы
- легко можно передать бесконечный интервал в алгоритм, который его не переварит
- их трудно использовать
- интервалы, которые могут быть бесконечными или очень большими, могут вызвать переполнение в difference_type
Первая проблема особенно трудная, поэтому начнём с неё.
Концепция интервалов
Для начала, давайте строго определим понятие интервала. В стандарте C++ это слово используется повсюду, но нигде не определяется. Можно понять, что интервал – это нечто, из чего можно извлечь begin и end, пару итераторов, которые устроены так, что до end можно добраться, начав с begin. В терминах моего предложения формализовать эту концепцию можно так:
using std::begin;
using std::end;
template<typename T>
using Iterator_type =
decltype(begin(std::declval<T>()));
template<typename T>
concept bool Range =
requires(T range) {
{ begin(range) } -> Iterator_type<T>;
{ end(range) } -> Iterator_type<T>;
requires Iterator<Iterator_type<T>>;
};
Также есть улучшения концепции интервала Range, которые называются InputRange, ForwardRange, и т.д. На деле они просто больше требуют от своих итераторов. Ниже показана вся эта иерархия.
Эти концепции являются основой для библиотеки Boost.Range (http://www.boost.org/libs/range)
Проблема 1: Генерация плохого кода
Если помните, для реализации интервалов как с ограничителем, так и бесконечных, в виде пары итераторов, итератор end должен быть сигнальным. И такой итератор представляет собой больше концепцию, чем физическое положение элемента в последовательности. Можно представлять его, как элемент с позицией «последний + 1» – разница лишь в том, что вы не узнаете, где его позиция, пока не достигнете её. Поскольку тип сигнального итератора такой же, как у обычного, требуется проверка на этапе выполнения программы, чтобы определить, является ли данный итератор сигнальным. Это приводит к медленному сравнению итераторов и неудобным реализациям методов.
Концепция инкременторов (Iterable)
Для чего нужны итераторы? Мы увеличиваем их, разыменовываем и сравниваем, так ведь? А что можно сделать с сигнальным итератором? Не особенно много чего. Его позиция не меняется, его нельзя разыменовать, т.к. его позиция всегда «последний + 1». Но его можно сравнить с итератором. Получается, что сигнальный итератор – слабый итератор.
Проблема с интервалами в том, что мы пытаемся превратить сигнальный итератор в обычный. Но он им не является. Так и не будем это делать – пусть они будут другого типа.
Концепция Range требует, чтобы begin и end были одного типа. Если можно их сделать разными, это уже будет более слабая концепция – концепция Iterable. Инкременторы – они как итераторы, только у begin и end разные типы. Концепция:
template<typename T>
using Sentinel_type =
decltype(end(std::declval<T>()));
template<typename T>
concept bool Iterable =
requires(T range) {
{ begin(range) } -> Iterator_type<T>;
{ end(range) } -> Sentinel_type<T>;
requires Iterator<Iterator_type<T>>;
requires EqualityComparable<
Iterator_type<T>, Sentinel_type<T>>;
};
template<typename T>
concept bool Range =
Iteratable<T> &&
Same<Iterator_type<T>, Sentinel_type<T>>;
Естественно, концепция Range входит в концепцию Iterable. Она просто уточняет её, добавляя ограничение на равенство типов begin и end.
Так выглядит иерархия, если мы рассматриваем интервалы, инкременторы и итераторы, но совершенно не обязательно именно так определять их и в программе. Заметьте, что «интервальность» – т.е., схожесть типов begin и end, ортогональна силе итератора begin. Когда нам надо включать в код моделирование RandomAccessRange, мы можем сказать requires RandomAccessIterable && Range и просто сменить всю концепцию.
Разница между, к примеру, BidirectionalIterable и ForwardIterable в концепции, моделируемой итератором begin из Iterable.
Iterable и алгоритмы STL
Но постойте – ведь алгоритмы STL не будут работать с инкременторами, потому что им требуется, чтобы у begin и end было один тип. Так и есть. Поэтому я прошерстил весь STL, чтобы проверить, что можно переписать. Например, std::find
template<class InputIterator, class Value>
InputIterator
find(InputIterator first, InputIterator last,
Value const & value)
{
for (; first != last; ++first)
if (*first == value)
break;
return first;
}
Сейчас std::find использует Ranges. Но заметьте, что алгоритм не пытается поменять позицию итератора end. Алгоритм поиска можно легко поменять так, чтобы он работал с Iterables вместо Ranges:
template<class InputIterator, class Sentinel, class Value>
InputIterator
find(InputIterator first, Sentinel last,
Value const & value)
{
for (; first != last; ++first)
if (*first == value)
break;
return first;
}
Вот и всё – изменение настолько малое, что его даже заметить трудно.
Так какие алгоритмы C++98 можно приспособить к работе с Iterables вместо Ranges? Оказывается, почти все. Легче перечислить те, которые не поддаются. Это:
- copy_backward
- алгоритмы работы с множествами и пирамидами (push_heap, pop_heap, make_heap, sort_heap)
- inplace_merge
- nth_element
- partial_sort и partial_sort_copy
- next_permutation и prev_permutation
- random_shuffle
- reverse и reverse_copy
- sort и stable_sort
- stable_partition
Остальные полсотни требуют чисто механического изменения в коде. Определив концепцию Iterable так, как она определяется в Range, мы даём любому алгоритму, работающему с Iterable, возможность точно так же работать и с Ranges. Это полезно и важно – для итераторов написано слишком много кода, чтобы делать для них какую-то несовместимую абстракцию.
Доказательство в Perf
И что мы получим? Вернёмся к нашим С-строкам. Я описал класс c_string_range и нашёл, что перебор символов генерит плохой код. Начнём снова, только при помощи range_facade, чтобы построить Iterable вместо Range.
using namespace ranges;
struct c_string_iterable
: range_facade<c_string_iterable>
{
private:
friend range_core_access;
char const *sz_;
char const & current() const { return *sz_; }
void next() { ++sz_; }
bool done() const { return *sz_ == 0; }
bool equal(c_string_iterable const &that) const
{ return sz_ == that.sz_; }
public:
c_string_iterable(char const *sz)
: sz_(sz) {}
};
Код получился гораздо проще, чем старый. Всю работу делает range_facade. Итератор и сигнальный итератор реализованы в виде примитивов. Чтобы проверить его, я сгенерил оптимизированный машинный код для следующих функций, одна из которых использует старый класс c_string_range, а другая – новый c_string_iterable:
// Range-based
int range_strlen(
c_string_range::iterator begin,
c_string_range::iterator end)
{
int i = 0;
for(; begin != end; ++begin)
++i;
return i;
}
// Iterable-based
int iterable_strlen(
range_iterator_t<c_string_iterable> begin,
range_sentinel_t<c_string_iterable> end)
{
int i = 0;
for(; begin != end; ++begin)
++i;
return i;
}
Даже не зная ассемблера, можно понять разницу.
|
|
Код с инкременторами гораздо круче. И он практически идентичен с ассемблером, полученным из итераторов «голого» С.
Итераторы, сигнальные итераторы и паритетность
Но что означает сравнение двух объектов разных типов на эквивалентность?
Немного для непосвященных: N3351 определяет, в каких случаях допустимы сравнения разных типов. Недостаточно, чтобы синтаксис «x==y» был допустим и выдавал булевское значение. Если у х и у будут разные типы, то эти типы должны быть сами по себе EqualityComparable, и у них должен быть общий тип, к которому их можно преобразовать, и он также должен быть EqualityComparable. Допустим, мы сравниваем char и short. Это возможно, поскольку они EqualityComparable, и их можно преобразовать в int, который тоже EqualityComparable.
Итераторы можно сравнивать, а сигнальные итераторы сравниваются тривиальным образом. Сложность в том, чтобы найти для них общий тип. Вообще, у каждого итератора и сигнального есть общий тип, который можно создать так: предположим существование нового типа итератора I, который представляет собой тип-сумму, и содержит либо итератор, либо сигнальный итератор. Когда их сравнивают, он ведёт себя семантически так, будто их обоих сначала преобразовали в два объекта типа I, назовём их lhs и rhs, и затем сравнили по следующей табличке:
| lhs сигнальный итератор? |
rhs сигнальный итератор? |
lhs == rhs? |
| true |
true |
true |
| true |
false |
done(rhs.iter) |
| false |
true |
done(lhs.iter) |
| false |
false |
lhs.iter == rhs.iter |
Эта табличка напоминает ту, которая получилась при анализе поведения оператора сравнения c_string_range::iterator. Это не случайно – то был особый случай этой, более общей, схемы. Она подтверждает интуитивное заключение, которое вы уже можете заметить, просмотрев два моих класса, c_string_range и c_string_iterable. Один – пара итераторов, другой – пара итератор/сигнальный, но их схема работы схожи. Мы чувствуем, что возможно построить эквивалентный Range из любого Iterable, если пожертвовать небольшой толикой быстродействия. И теперь мы нашли подтверждение этому.
Возможность сравнивать итераторы и сигнальные итераторы напрямую позволяет нам использовать систему типов C++ для оптимизации большой категории итераций, убирая разветвления в операторе сравнения паритетности.
Возражения
Идея дать разные типы begin и end не нова, и придумал её не я. Я узнал о ней от Дэйва Абрахамса (Dave Abrahams) много лет назад. Недавно сходную идею подал Дитмар Кюэль (Dietmar Kuehl) в списке рассылки Ranges, а в ответ на его письмо Шон Пэрент (Sean Parent) высказал следующее возражение:
Мне кажется, мы возлагаем на итераторы слишком многое. Алгоритмы, работающие с окончанием на основании проверки сигнального итератора или на основании подсчёта – это разные сущности. См. copy_n() и copy_sentinel()
stlab.adobe.com/copy_8hpp.html
Касательно интервалов – я уверен, что можно построить его при помощи:
- пары итераторов
- итератора и количество
- итератора и сигнала
И в этом случае copy(r, out) может выдать нужный алгоритм.
Если я правильно его понял, он говорит о существовании трёх параллельных концепций интервалов: IteratorRange, CountedRange и SentinelRange. И эти иерархии не нужно пытаться связать между собой. Алгоритм копирования должен содержать три разные реализации, по одной на каждую концепцию. Тогда придётся утроить порядка 50 алгоритмов – и это слишком много повторения в коде.
Хуже того, некоторые алгоритмы основаны на уточнённых концепциях. Например, в libc++ алгоритм rotate выбирает одну из трёх реализаций, в зависимости от того, передаёте вы ему прямые, двунаправленные или итераторы произвольного доступа. А для включения трёх разных реализаций Iterator, Counted и SentinelRanges потребовалось бы 9 алгоритмов rotate! При всём уважении, это безумие.
Итого
В начале поста я привёл список проблем, связанных с интервалами с парными итераторами. Я показал новую концепцию, Iterable, которая занимается вопросами быстродействия, и затронул вопрос сложностей реализации интервалов. Пока я не описал, как эта концепция работает с бесконечными интервалами, о чём мы поговорим в четвёртом, финальном посте.
Весь код можно найти в репозитории на github.
Благодарности
Я хотел бы поблагодарить Эндрю Суттона (Andrew Sutton) за помомщь с синтаксисом Concpets Lite и за объяснение требований концепции EqualityComparable для разных типов и общее улучшение и формализацию многих идей. Статьи стали значительно лучше благодаря его большому вкладу.
Другие статьи цикла
Интервалы в С++, часть 1: Интервалы с ограничителями
Интервалы в С++, часть 2: Бесконечные интервалы
Интервалы в С++, часть 4: к бесконечности и далее


nickolaym
Если итератор двунаправленный или прямого доступа, то над терминатором должна быть определена операция декремента, возвращающая итератор.
Тогда можно спокойно переделать фасад функции sort — пусть она будет sort(Iterator start, Sentinel finish), а внутри творит что хочет.
Казалось бы, арифметика над терминатором ломает строгость:
begin() — итератор
end() — терминатор
end()-1 — итератор
end()-1+1 — итератор?!
На самом деле, строгость сломана изначально:
begin()+1 — итератор
begin()+distance(begin(),end()) — итератор == end().
Так что можно расслабиться. Мы в С++, а не в Агде, здесь супер-пупер-типизацией от всего не защитишься.
От самых примитивных косяков, тем не менее, защититься можно. Для этого интерфейсы STL-алгоритмов вполне могут быть sort(Iterator begin, Sentinel end).
Единственно, — поскольку такое объявление слишком расслабляет (можно подсунуть границы не только из разных доменов, но и из разных типов), — придётся ввести проверку
которая показывает, относятся ли I и S к границам одного типа.
И, соответственно,
sermp
Ну, автор оригинального текста решает всё-таки чуть более широкую задачу. Поэтому получается сложнее.