
Перевод статьи Тима Деттмерса, кандидата наук из Вашингтонского университета, специалиста по глубокому обучению и обработке естественного языка
Глубокое обучение (ГО) – область с повышенными запросами к вычислительным мощностям, поэтому ваш выбор GPU фундаментально определит ваш опыт в этой области. Но какие свойства важно учесть, если вы покупаете новый GPU? Память, ядра, тензорные ядра? Как сделать лучший выбор по соотношению цены и качества? В данной статье я подробно разберу все эти вопросы, распространённые заблуждения, дам вам интуитивное представление о GPU а также несколько советов, которые помогут вам сделать правильный выбор.
Статья написана так, чтобы дать вам несколько разных уровней понимания GPU, в т.ч. новой серии Ampere от NVIDIA. У вас есть выбор:
Каждая секция предваряется небольшим резюме, которое поможет вам решить, читать её целиком или нет.
Обзор
Как работают GPU?
Самые важные характеристики GPU, влияющие на скорость обработки
Тензорные ядра
Перемножение матриц без тензорных ядер
Перемножение матриц с тензорными ядрами
Пропускная способность памяти
Общая память / Кэш L1 / Регистры
Оценка эффективности Ampere в ГО
Теоретические оценки скорости Ampere
Практические оценки скорости Ampere
Возможные неточности оценок
Что ещё следует учесть в случае с Ampere / RTX 30
Разреженное обучение
Вычисления с низкой точностью
Новый дизайн вентилятора и проблемы с теплоотводом
Трёхслотовые карты и проблемы питания
Эффективность GPU при глубоком обучении
Скорость глубокого обучения GPU в пересчёте на стоимость
Рекомендации по выбору GPU
Когда мне понадобится более 11 ГБ памяти?
Когда можно обойтись памятью менее 11 ГБ?
Общие рекомендации
Рекомендации для GPU-кластеров
Какие GPU лучше не покупать
Когда лучше не покупать новых GPU?
Ответы на вопросы и заблуждения
Нужна ли мне PCIe 4.0?
Нужны ли мне линии PCIe 8x/16x?
Как впихнуть четыре RTX 3090, если каждая из них занимает по 3 слота PCIe?
Как охлаждать 4 RTX 3090 или 4 RTX 3080?
Можно ли использовать GPU нескольких разных типов?
Что такое NVLink, и нужно ли оно мне?
У меня нет денег даже на самые дешёвые ваши рекомендации. Что делать?
Что нужно для параллелизации проекта между двумя машинами?
Подходят ли алгоритмы перемножения разреженных матриц для любых разреженных матриц?
Нужен ли мне процессор от Intel для работы с несколькими GPU?
Имеет ли значение для охлаждения форма корпуса?
Догонят ли AMD GPU + ROCm когда-нибудь NVIDIA GPU + CUDA?
Когда лучше использовать облачные сервисы, а когда – специальный компьютер с GPU?
Советы для тех, кому лень читать
Данная статья структурирована следующим образом. Сначала я объясняю, что делает GPU быстрым. Я опишу разницу между процессорами и GPU, тензорные ядра, пропускную способность памяти, иерархию памяти GPU, и как это всё связано с быстродействием в задачах ГО. Эти объяснения, возможно, помогут вам лучше понять, какие параметры GPU вам нужны. Потом я дам теоретические оценки быстродействия GPU и их соответствие с некоторыми тестами на скорость от NVIDIA, чтобы получить надёжные данные по быстродействию без предвзятости. Я опишу уникальные особенности GPU серии NVIDIA RTX 30 Ampere, которые стоит рассмотреть при покупке. Затем я дам рекомендации по GPU для вариантов с 1-2 чипами, 4, 8, и GPU-кластеров. Потом пойдёт раздел ответов на частые вопросы, которые мне задавали в твиттере. Там же будут развеяны распространённые заблуждения и освещены разные проблемы типа облаков против настольных компьютеров, охлаждения, AMD против NVIDIA, и др.
Если вы часто пользуетесь GPU, полезно понимать, как они работают. Это знание пригодится вам, чтобы разобраться, почему в некоторых случаях GPU оказываются медленнее, а в других – быстрее. И тогда вы, возможно, поймёте, нужен ли вам вообще GPU, и какие варианты железа смогут соревноваться с ним в будущем. Вы можете пропустить этот раздел, если просто хотите получить полезную информацию по быстродействию и аргументы в пользу выбора определённого GPU. Лучше всего на общем уровне я объяснил принципы работы GPU в ответе на сайте Quora.
Это общее объяснение, хорошо раскрывающее вопрос о том, почему для ГО GPU подходят лучше, чем процессоры. Если мы изучим детали, мы сможем понять, чем GPU отличаются друг от друга.
Этот раздел поможет вам более интуитивно мыслить на тему быстродействия в области ГО. Это понимание поможет вам оценивать будущие GPU самостоятельно.
Резюме:
Сегодня существует настолько много недорогих GPU, что почти каждый может позволить себе GPU с тензорными ядрами. Поэтому я всегда рекомендую GPU с тензорными ядрами. Полезно разобраться в принципах их работы, чтобы оценить важность этих вычислительных модулей, специализирующихся на перемножении матриц. На простом примере перемножения матриц A*B=C, где размер всех матриц равен 32?32, я покажу вам, как выглядит перемножение с тензорными ядрами и без них.
Чтобы разобраться в этом, сначала вам нужно понять концепцию тактов. Если процессор работает с частотой 1 ГГц, он проделывает 109 тактов в секунду. Каждый такт – это возможность для вычислений. Но по большей части операции идут дольше, чем один такт. Получается конвейер – чтобы начать выполнение одной операции, нужно сначала подождать столько тактов, сколько требуется на выполнение предыдущей операции. Это также называется задержкой операции.
Вот некоторые важные длительности, или задержки операции в тактах:
Также вам нужно знать, что самая малая единица нитей в GPU – пакет из 32 нитей — называется варп [warp]. Варпы обычно работают синхронно – всем нитям внутри варпа нужно дождаться друг друга. Все операции в памяти GPU оптимизированы под варпы. К примеру, загрузка из глобальной памяти идёт по 32*4 байта – по 32 числа с плавающей запятой, по одному такому числу на каждую нить в варпе. В потоковом мультипроцессоре (эквивалент ядра процессора для GPU) может быть до 32 варпов = 1024 нити. Ресурсы мультипроцессора делятся между всеми активными варпами. Поэтому иногда нам нужно, чтобы работало меньше варпов, чтобы на один варп приходилось больше регистров, общей памяти и ресурсов тензорных ядер.
В обоих примерах предположим, что у нас есть одинаковые вычислительные ресурсы. В этом небольшом примере перемножения матриц 32?32 мы используем 8 мультипроцессоров (~10% от RTX 3090) и по 8 варпов на мультипроцессоре.
Если нам нужно перемножить матрицы A*B=C, каждая из которых имеет размер 32?32, тогда нам нужно загрузить данные из памяти, к которой мы постоянно обращаемся, в общую память, поскольку задержки доступа к ней примерно в 10 раз меньше (не 200 тактов, а 20 тактов). Блок памяти в общей памяти часто называют плиткой памяти [memory tile], или просто плиткой. Загрузку двух 32?32 чисел с плавающей запятой в плитку общей памяти можно провести параллельно, используя 2*32 варпа. У нас есть 8 мультипроцессоров по 8 варпов каждый, поэтому благодаря параллелизации нам нужно провести одну последовательную загрузку из глобальной в общую память, на что уйдёт 200 тактов.
Для перемножения матриц нам нужно загрузить вектор из 32 чисел из общей памяти А и общей памяти В, и провести СУС, а потом сохранить выход в регистрах С. Мы разделяем эту работу так, чтобы каждый мультипроцессор занимался 8-ю скалярными произведениями (32?32) для вычисления 8 выходных данных для С. Почему их ровно 8 (в старых алгоритмах – 4), это уже чисто техническая особенность. Чтобы разобраться с этим, рекомендую прочесть статью Скотта Грэя. Это означает, что у нас пройдёт 8 доступов к общей памяти стоимостью в 20 тактов каждый, и 8 операций СУС (32 параллельных), стоимостью 4 такта каждая. В сумме стоимость получится:
200 тактов (глобальная память) + 8*20 тактов (общая память) + 8*4 такта (СУС) = 392 такта
Теперь посмотрим на эту стоимость для тензорных ядер.
При помощи тензорных ядер можно перемножить матрицы 4?4 за один цикл. Для этого нам нужно скопировать память в тензорные ядра. Как и выше, нам нужно прочесть данные из глобальной памяти (200 тактов) и сохранить их в общей. Для перемножения матриц 32?32 нам нужно произвести 8?8=64 операций в тензорных ядрах. В одном мультипроцессоре находится 8 тензорных ядер. С 8 мультипроцессорами у нас будет 64 тензорных ядра – как раз столько, сколько надо! Мы можем передать данные из общей памяти в тензорные ядра за 1 передачу (20 тактов), а потом провести все эти 64 операции параллельно (1 такт). Это значит, что общая стоимость перемножения матриц в тензорных ядрах будет:
200 тактов (глобальная память) + 20 тактов (общая память) + 1 такт (тензорные ядра) = 221 такт
Таким образом, используя тензорные ядра, мы значительно уменьшаем стоимость перемножения матриц, с 392 до 221 такта. В нашем упрощённом примере тензорные ядра уменьшили стоимость как доступа к общей памяти, так и операций СУС.
Хотя в данном примере примерно соблюдается последовательность вычислительных шагов с использованием тензорных ядер и без них, учтите, что это очень упрощённый пример. В реальных случаях перемножения матриц участвуют куда как большие плитки памяти и немного другие последовательности действий.
Однако, как мне кажется, из этого примера становится понятно, почему следующий атрибут, пропускная способность памяти, так важна для GPU с тензорными ядрами. Поскольку глобальная память – наиболее затратная вещь при перемножении матриц с тензорными ядрами, наши GPU были бы гораздо быстрее, если бы удалось уменьшить задержки доступа к глобальной памяти. Это можно сделать, либо увеличив тактовую частоту памяти (больше тактов в секунду, но больше тепла и энергопотребления), либо увеличив количество элементов, которые можно передавать за раз (ширину шины).
В предыдущем разделе мы увидели, насколько быстры тензорные ядра. Настолько быстры, что большую часть времени они простаивают, ожидая, пока к ним поступят данные из глобальной памяти. К примеру, во время обучения по проекту BERT Large, где использовались очень большие матрицы – чем больше, тем для тензорных ядер лучше – утилизация тензорных ядер в TFLOPS составила порядка 30%, что означает, что 70% времени тензорные ядра простаивали.
Это означает, что при сравнении двух GPU с тензорными ядрами одним из лучших индикаторов быстродействия каждого из них будет служить пропускная способность памяти. К примеру, у A100 GPU пропускная способность составляет 1,555 ГБ/с, а у V100 — 900 ГБ/с. Простейший подсчёт говорит, что A100 будет быстрее V100 в 1555/900 = 1,73 раза.
Поскольку ограничивающим быстродействие фактором является передача данных в память тензорных ядер, мы должны обратиться к другим свойствам GPU, позволяющим ускорить передачу к ним данных. С этим связаны общая память, кэш L1 и количество регистров. Чтобы понять, как иерархия памяти ускоряет передачу данных, полезно понять, как в GPU происходит перемножение матриц.
Для перемножения матриц мы пользуемся иерархией памяти, идущей от медленной глобальной памяти к быстрой локальной общей памяти, и затем к сверхбыстрым регистрам. Однако чем быстрее память, тем она меньше. Поэтому нам нужно делить матрицы на меньшие, а потом выполнять перемножение этих меньших плиток в местной общей памяти. Тогда оно будет происходить быстро и ближе к потоковому мультипроцессору (ПМ) – эквиваленту ядра процессора. Тензорные ядра позволяют нам сделать ещё один шаг: мы берём все плитки и грузим их часть в тензорные ядра. Общая память обрабатывает матричные плитки в 10-50 раз быстрее, чем глобальная память GPU, а регистры тензорных ядер обрабатывают её в 200 раз быстрее, чем глобальная память GPU.
Увеличение размера плиток позволяет нам повторно использовать больше памяти. Подробно я писал об этом в моей статье TPU vs GPU. В TPU на каждое тензорное ядро приходится по очень, очень большой плитке. TPU могут повторно использовать гораздо больше памяти с каждой новой передачей данных из глобальной памяти, из-за чего они чуть более эффективно справляются с перемножением матриц по сравнению с GPU.
Размеры плитки определяются объёмами памяти на каждый из ПМ – эквивалент ядра процессора на GPU. В зависимости от архитектур эти объёмы составляют:
Видно, что у Ampere обща память гораздо больше, что позволяет использовать плитки большего размера, что уменьшает количество обращений к глобальной памяти. Поэтому Ampere эффективнее пользуется пропускной способностью памяти GPU. Это увеличивает быстродействие на 2-5%. Особенно увеличение заметно на огромных матрицах.
У тензорных ядер Ampere есть ещё одно преимущество – объём общих для нескольких нитей данных у них больше. Это уменьшает количество обращений к регистрам. Объём регистров ограничен 64 к на ПМ или 255 на нить. Если сравнить с Volta, тензорные ядра Ampere используют в 3 раза меньше регистров, благодаря чему на каждую плитку в общей памяти имеется больше активных тензорных ядер. Иначе говоря, мы можем загрузить в 3 раза больше тензорных ядер тем же количеством регистров. Однако поскольку пропускная способность остаётся узким местом, увеличение TFLOPS на практике будет мизерным, по сравнению с теоретическим. Новые тензорные ядра улучшили быстродействие примерно на 1-3%.
В целом видно, что архитектура Ampere оптимизирована так, чтобы более эффективно использовать пропускную способность памяти посредством улучшенной иерархии – от глобальной памяти к плиткам общей памяти, и к регистрам тензорных ядер.
Резюме:
Этот раздел предназначен для тех, кто хочет углубиться в технические детали того, как я получил оценки быстродействия Ampere GPU. Если вам это неинтересно, его спокойно можно пропустить.
Учитывая вышеизложенные аргументы, можно было бы ожидать, что разница между двумя GPU-архитектурами с тензорными ядрами должна была заключаться в основном в пропускной способности памяти. Дополнительные преимущества получаются за счёт увеличения общей памяти и кэша L1, а также эффективного использования регистров.
Пропускная способность Tesla A100 GPU по сравнению с Tesla V100 увеличивается в 1555/900 = 1,73 раз. Также разумно ожидать увеличения скорости на 2-5% из-за большей общей памяти, и на 1-3% из-за улучшения тензорных ядер. Получается, что ускорение должно составить от 1,78 до 1,87 раза.
Допустим, у нас есть оценка одного GPU для такой архитектуры, как Ampere, Turing или Volta. Легко экстраполировать эти результаты на другие GPU такой же архитектуры или серии. К счастью, NVIDIA уже провела тесты сравнения A100 и V100 на разных задачах, связанных с компьютерным зрением и пониманием естественного языка. К несчастью, NVIDIA сделала всё возможное, чтобы эти числа нельзя было сравнивать напрямую – в тестах использовали различные размеры пакетов данных и разное количество GPU, чтобы A100 не могла выиграть. Так что, в каком-то смысле, полученные показатели быстродействия частично честные, частично рекламные. В целом можно утверждать, что увеличение размера пакетов данных обосновано, поскольку у A100 больше памяти – однако, для сравнения GPU-архитектур нам нужно сравнивать непредвзятые данные по быстродействию на задачах с одинаковым размером пакета данных.
Чтобы получить непредвзятые оценки, можно масштабировать результаты измерений V100 и A100 двумя способами: учитывать разницу в размере пакета данных, или учитывать разницу в количестве GPU – 1 против 8. Нам повезло, и мы можем найти подобные оценки для обоих случаев в представленных NVIDIA данных.
Удвоение размера пакета увеличивает пропускную способность на 13,6% в изображениях в секунду (для свёрточных нейросетей, СНС). Я измерил скорость той же задачи с архитектурой Transformer на моём RTX Titan, и, как ни удивительно, получил такой же результат – 13,5%. Судя по всему, это надёжная оценка.
Увеличивая параллелизацию сетей, увеличивая количество GPU, мы теряем в быстродействии из-за накладных расходов, связанных с сетями. Но система A100 8x GPU лучше работает с сетями (NVLink 3.0) по сравнению с V100 8x GPU (NVLink 2.0) – и это ещё один запутывающий фактор. Если посмотреть на данные от NVIDIA, можно увидеть, что для обработки СНС у системы с 8-ю A100 накладные расходы на 5% ниже, чем у системы с 8-ю V10000. Это значит, что если переход от 1-го A10000 к 8-и A10000 даёт вам ускорение, допустим, в 7,0 раз, то переход от 1-го V10000 к 8-и V10000 даёт вам ускорение только в 6,67 раз. Для трансформеров эта цифра составляет 7%.
Используя эту информацию, мы можем оценить ускорение некоторых определённых архитектур ГО непосредственно на основе предоставленных NVIDIA данных. Tesla A100 имеет следующие преимущества в скорости по сравнению с Tesla V100:
Поэтому для компьютерного зрения числа получаются ниже теоретической оценки. Это может происходить из-за меньших измерений тензора, накладных расходов операций, которые требуются для подготовки перемножения матриц типа img2col или быстрое преобразование Фурье, или операций, не способных насытить GPU (конечные слои часто оказываются относительно маленькими). Также это может оказаться артефактами определённых архитектур (сгруппированная свёртка).
Практическая оценка скорости работы трансформера очень близка к теоретической. Вероятно, потому, что алгоритмы работы с большими матрицами весьма прямолинейны. Для подсчёта эффективности затрат на GPU я буду использовать практические оценки.
Выше даны сравнительные оценки A100 и V100. В прошлом NVIDIA тайком ухудшила работу «игровых» RTX GPU: уменьшила утилизацию тензорных ядер, добавила игровые вентиляторы для охлаждения, запретила передачу данных между GPU. Возможно, что в серии RT 30 также внесли неизвестные ухудшения по сравнению с Ampere A100.
Резюме:
У новых NVIDIA Ampere RTX 30 есть дополнительные преимущества перед NVIDIA Turing RTX 20 – разреженное обучение и улучшенная обработка данных нейросетью. Остальные свойства, типа новых типов данных, можно считать простым повышением удобства – они ускоряют работу так же, как и серия Turing, не требуя при этом дополнительного программирования.
Ampere позволяет с большой скоростью и автоматически перемножать разреженные матрицы. Это работает так – вы берёте матрицу, режете её на кусочки по 4 элемента, и поддерживающее разреженные матрицы тензорное ядро разрешает двум элементам из этих четырёх быть нулевыми. Это приводит к ускорению работы в 2 раза, поскольку требования к пропускной способности во время перемножения матриц в два раза уменьшаются.
В своих исследованиях я работал с разреженным обучением сетей. Работу критиковали, в частности, за то, что я «уменьшаю необходимые для сети FLOPS, но не увеличиваю из-за этого скорость, потому что GPU не умеют быстро перемножать разреженные матрицы». Ну что ж – поддержка перемножения разреженных матриц появилась в тензорных ядрах, и мой алгоритм, или любой другой алгоритм (ссылка, ссылка, ссылка, ссылка), работающий с разреженным матрицами, теперь реально может работать во время обучения в два раза быстрее.
Хотя эта свойство пока считается экспериментальным, а обучение разреженных сетей не применяется повсеместно, если у вашего GPU есть поддержка этой технологии, то вы готовы к будущему разреженного обучения.
Я уже демонстрировал, как новые типы данных могут улучшать стабильность обратного распространения с низкой точностью в моей работе. Пока что проблемой стабильного обратного распространения с 16-битными числами с плавающей запятой является то, что обычные типы данных поддерживают только промежуток [-65,504, 65,504]. Если ваш градиент выйдет за этот промежуток, то взорвётся, выдав значения NaN. Для предотвращения этого мы обычно масштабируем значения, умножая их на небольшое число перед обратным распространением, чтобы избежать взрыва градиента.
Формат Brain Float 16 (BF16) использует больше битов для экспоненты, благодаря чему промежуток возможных значений получается таким же, как у FP32: [-3*10^38, 3*10^38]. У BF16 меньше точность, т.е. меньше значащих разрядов, но точность градиента при обучении сетей не так уж и важна. Поэтому BF16 гарантирует, что вам уже не нужно будет заниматься масштабированием или волноваться о взрыве градиента. С этим форматом мы должны увидеть увеличение стабильности обучения за счёт небольшой потери точности.
Что это значит для вас: с точностью BF16 обучение может быть более стабильным, чем с точностью FP16, а скорость у них одинаковая. С точностью TF32 вы получите стабильность почти как у FP32, а ускорение – почти как у FP16. Плюс в том, что при использовании этих типов данных можно менять FP32 на TF32, а FP16 на BF16, ничего не меняя в коде!
В целом эти новые типы данных можно считать ленивыми, в том смысле, что вы могли получить все их преимущества, используя старые типа данных и немного программирования (правильное масштабирование, инициализация, нормализация, использование Apex). Поэтому эти типы данных обеспечивают не ускорение, а делают использование низкой точности в обучении проще.
По новой схеме вентиляторов для серии RTX 30 есть выдувающий воздух вентилятор и втягивающий воздух вентилятор. Сам дизайн продуман гениально, и будет очень эффективно работать при наличии свободного пространства между GPU. Однако непонятно, как поведут себя GPU, если их понаставить один к другому. Выдувающий вентилятор сможет выдувать воздух прочь от других GPU, но невозможно сказать, как это будет работать, поскольку его форма отличается от той, что была раньше. Если вы планируете поставить 1 или 2 GPU туда, где есть 4 слота, тогда у вас не должно быть проблем. Но если вы захотите использовать 3-4 RTX 30 GPU рядышком, я бы сначала подождал отчётов о температурном режиме, а потом уже решил, понадобятся ли ещё вентиляторы, расширители PCIe или другие решения.
В любом случае, решить проблему с теплоотводом может помочь водяное охлаждение. Многие производители предлагают такие решения для карточек RTX 3080/RTX 3090, и тогда они не будут греться, даже если их будет 4. Однако не покупайте готовых решений для GPU, если вы захотите собрать компьютер с 4 GPU, поскольку в большинстве корпусов будет очень трудно распределить радиаторы.
Ещё одно решение проблемы охлаждения – купить расширители PCIe и распределить карты внутри корпуса. Это очень эффективно – я и другие аспиранты из Ванингтонского университета с большим успехом используем этот вариант. Выглядит не очень аккуратно, зато GPU не греются! Также этот вариант поможет в случае, если вам не хватает пространства для размещения GPU. Если в вашем корпусе есть место, можно, допустим, купить стандартные RTX 3090 на три слота, и распределить их при помощи расширителей по всему корпусу. Таким образом можно решить одновременно проблему с местом и охлаждением 4-х RTX 3090.

Рис. 1: 4 GPU с расширителями PCIe
RTX 3090 занимает 3 слота, поэтому их невозможно использовать по 4 штуки с вентиляторами от NVIDIA по умолчанию. И это не удивительно, поскольку она требует 350 Вт TDP. RTX 3080 лишь немногим уступает ей, требуя 320 Вт TDP, и охлаждать систему с четырьмя RTX 3080 будет очень сложно.
Также сложно питать систему из 4-х карт по 350 Вт = 1400 Вт. Блоки питания (БП) на 1600 Вт бывают, однако 200 Вт на процессор и материнку может не хватить. Максимальное энергопотребление происходит только при полной загрузке, и во время ГО процессор обычно слабо нагружен. Поэтому БП на 1600 Вт может подойти для 4-х RTX 3080, но для 4-х RTX 3090 лучше поискать БП на 1700 Вт и более. На сегодня на рынке таких БП не наблюдается. Могут подойти серверные БП или специальные блоки для криптомайнеров, но у них может оказаться необычный форм-фактор.
В следующий тест вошли не только сравнения Tesla A100 и Tesla V100 – я построил модель, укладывающуюся в эти данные и четыре различных теста, где испытывали Titan V, Titan RTX, RTX 2080 Ti и RTX 2080 (ссылка, ссылка, ссылка, ссылка).
Кроме того я масштабировал результаты тестов таких карт среднего уровня, как RTX 2070, RTX 2060 или Quadro RTX, путём интерполяции точек данных тестов. Обычно в архитектуре GPU такие данные масштабируются линейно по отношению к перемножению матриц и пропускной способности памяти.
Я собирал только данные тестов по обучению FP16 со смешанной точностью, поскольку не вижу причин, по которым нужно было бы использовать обучение с числами FP32.

Рис. 2: Быстродействие, нормализованное по результатам RTX 2080 Ti
По сравнению с RTX 2080 Ti, RTX 3090 работает со свёрточными сетями в 1,57 раз быстрее, а с трансформерами – в 1,5 раз быстрее, при этом стоит на 15% дороже. Получается, что Ampere RTX 30 демонстрирует значительное улучшение со времён серии Turing RTX 20.
Какой GPU будет наиболее выгодным вложением денег? Всё зависит от общей стоимости системы. Если она дорогая, имеет смысл вложиться в более дорогие GPU.
Ниже привожу данные по трём сборкам на PCIe 3.0, которые я использую в качестве базовых ориентиров стоимости систем из 2 или 4 GPU. Я беру эту базовую стоимость и добавляю к ней стоимость GPU. Последнюю я высчитываю как среднюю цену между предложениями с Amazon и eBay. Для новых Ampere я использую только одну цену. В совокупности с приведёнными выше данными по быстродействию это даёт значения быстродействия в пересчёте на доллар. Для системы из 8 GPU за основу я беру Supermicro barebone – промышленный стандарт для RTX-серверов. Приводимые графики не учитывают требования к памяти. Вам сначала нужно задуматься о том, какая вам требуется память, а потом поискать наилучшие варианты на графиках. Примерные советы по памяти:
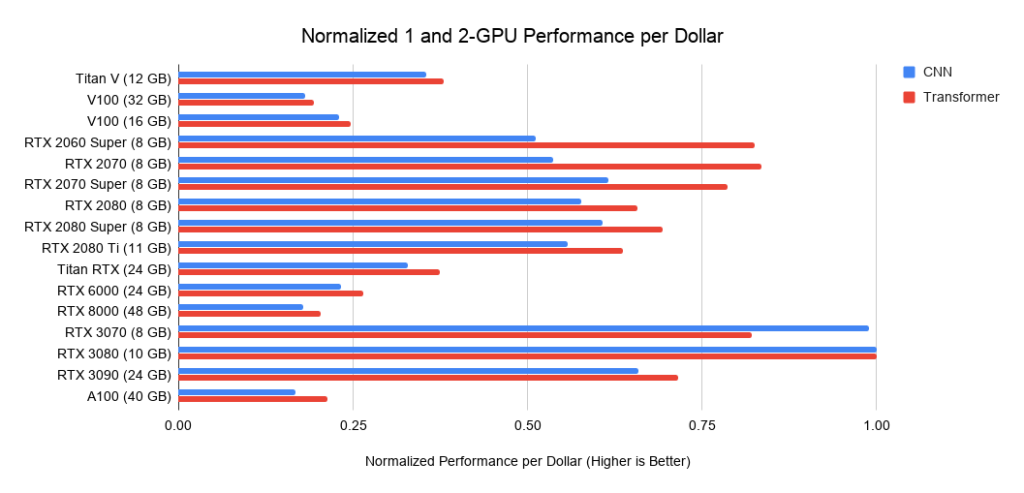
Рис. 3: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.

Рис. 4: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.
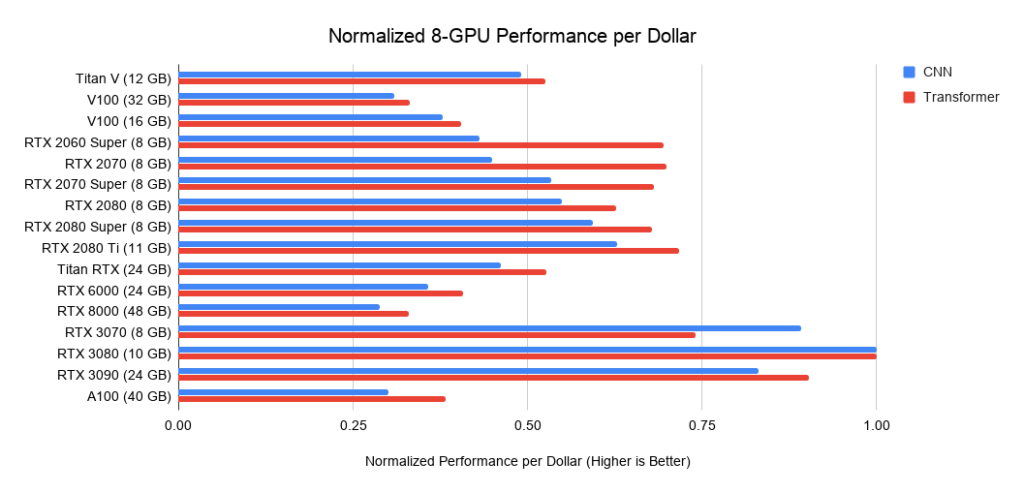
Рис. 5: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.
Ещё раз хочется подчеркнуть: при выборе GPU сначала убедитесь, что у него хватает памяти для ваших задач. Шаги при выборе GPU должны быть следующие:
Некоторые из шагов требуют задуматься о том, чего вы хотите, и провести небольшое исследование на тему того, какие объёмы памяти используют другие люди, занимающиеся тем же самым. Я могу дать несколько советов, но не могу полностью ответить на все вопросы в данной области.
Я уже упоминал, что при работе с трансформерами вам потребуется не менее 11 ГБ, а при проведении исследований в этой области – не менее 24 ГБ. У большинства предыдущих предварительно обученных моделей очень большие требования к памяти, и их обучали на GPU классом не ниже RTX 2080 Ti с объёмом памяти не менее 11 ГБ. Поэтому, если у вас меньше 11 ГБ памяти, запуск некоторых моделей может стать трудным или вовсе невозможным делом.
Другие области, требующие больших объёмов памяти – обработка медицинских снимков, передовые модели компьютерного зрения, и всё с изображениями большого размера.
В целом, если вы стремитесь разработать модели, способные опередить конкурентов – будь то исследования, промышленное применение или соревнования Kaggle – дополнительная память, возможно, даст вам конкурентное преимущество.
Карты RTX 3070 и RTX 3080 – мощные, но памяти им не хватает. Однако для многих задач такого количества памяти может и не потребоваться.
RTX 3070 идеально подходит для обучения ГО. Базовые навыки обучения сетей большинства архитектур можно приобрести, уменьшая масштаб сетей или используя изображения меньшего размера. Если бы мне пришлось учиться ГО, я бы выбрал себе RTX 3070, или даже несколько штук, если бы мог себе их позволить.
RTX 3080 на сегодня – наиболее эффективная карта по отношению цены к быстродействию, и поэтому идеально подходит для прототипирования. Для прототипирования нужны большие объёмы памяти, а память стоит недорого. Под прототипированием я понимаю прототипирование в любой области – исследования, соревнования Kaggle, проба идей для стартапа, эксперименты с исследовательским кодом. Для всех подобных применений RTX 3080 подойдёт лучше всего.
Если бы я, допустим, руководил исследовательской лабораторией или стартапом, 66-80% всего бюджета я пустил бы на машины RTX 3080, и 20-33% — на RTX 3090 с надёжным водяным охлаждением. RTX 3080 более эффективна в пересчёте на стоимость, и доступ к ней можно организовать через Slurm. Поскольку прототипированием надо заниматься в эджайл-режиме, его нужно вести с моделями и наборами данных меньшего размера. И RTX 3080 идеально для этого подходит. Когда ученики/коллеги создадут отличную модель-прототип, они смогут выкатывать её на RTX 3090, масштабируя до более крупных моделей.
В целом модели серии RTX 30 очень мощные, и я определённо их рекомендую. Учтите требования к памяти, как указано ранее, а также требования к питанию и охлаждению. Если у вас между GPU будет свободный слот, с охлаждением проблем не будет. Иначе обеспечьте картам RTX 30 водяное охлаждение, расширители PCIe или эффективные карты с вентиляторами.
В целом я бы рекомендовал RTX 3090 всем, кто может себе её позволить. Она не только подойдёт вам сейчас, но и останется очень эффективной в следующие 3-7 лет. Маловероятно, что в ближайшие три года HBM-память сильно подешевеет, поэтому следующий GPUУ будет всего на 25% лучше, чем RTX 3090. Лет через 5-7, наверное, мы увидим дешёвую HBM-память, после чего вам определённо нужно будет обновлять парк.
Если вы собираете систему из нескольких RTX 3090, обеспечьте им достаточное охлаждение и питание.
Если у вас нет жёстких требований к конкурентным преимуществам, я бы порекомендовал вам RTX 3080. Это более эффективное решение в пересчёте на стоимость, и оно обеспечит быстрое обучение большинства сетей. Если вы примените нужные трюки с памятью и не против написания дополнительного кода, то есть много трюков, позволяющих впихнуть сеть на 24 ГБ в GPU с 10 ГБ.
RTX 3070 тоже отличная карта для обучения ГО и прототипирования, и она на $200 дешевле, чем RTX 3080. Если вы не можете позволить себе RTX 3080, тогда ваш выбор – это RTX 3070.
Если ваш бюджет ограничен, и RTX 3070 для вас слишком дорогая, то на eBay можно найти использованную RTX 2070 по цене порядка $260. Пока неясно, выйдет ли RTX 3060, но если ваш бюджет невелик, возможно, стоит подождать её выхода. Если её ценообразование будет соответствовать RTX 2060 и GTX 1060, тогда она должна будет стоить около $250-$300, и выдавать неплохие результаты.
Схема GPU-кластера сильно зависит от его использования. Для системы с 1024 GPU и более главным будет наличие сети, но если вы используете не более 32 GPU за раз, то вкладываться в построение мощной сети смысла нет.
Вообще, карточки RTX по соглашению CUDA нельзя использовать в дата-центрах. Однако часто университеты могут стать исключением из этого правила. Если вы хотите получить подобное разрешение, стоит связаться с представителем NVIDIA. Если вам можно использовать карты RTX, то я бы порекомендовал стандартную систему Supermicro на 8 GPU RTX 3080 или RTX 3090 (если вы можете обеспечить им охлаждение). Небольшой набор из 8 узлов A10000 гарантирует эффективное использование моделей после прототипирования, особенно если обеспечить охлаждением серверы на 8 RTX 3090 не получается. В данном случае я бы порекомендовал A10000 вместо RTX 6000 / RTX 8000, поскольку A10000 довольно эффективные в пересчёте на стоимость, и не устареют быстро.
Если вам нужно обучать очень большие сети на кластере GPU (256 GPU и более), я бы порекомендовал систему NVIDIA DGX SuperPOD с A10000. от 256 GPU сеть становится необходимой. Если вы хотите расшириться, и выйти за пределы 256 GPU, вам понадобится очень оптимизированная система, для которой стандартные решения уже не подойдут.
Особенно на масштабах 1024 GPU и более единственными конкурентоспособными решениями на рынке остаются Google TPU Pod и NVIDIA DGX SuperPod. На таких масштабах я бы предпочёл Google TPU Pod, поскольку их специальная сетевая инфраструктура выглядит лучше, чем NVIDIA DGX SuperPod – хотя в принципе, эти системы довольно близки. В прикладных приложениях и ГО система из GPU бывает более гибкой, чем TPU, при этом системы из TPU поддерживают модели большего размера и лучше масштабируются. Поэтому у обеих систем есть свои достоинства и недостатки.
Не рекомендую покупать по нескольку RTX Founders Edition или RTX Titan, если только у вас не будет расширителей PCIe, решающих их проблемы с охлаждением. Они просто разогреются и их скорость сильно упадёт по сравнению с той, что указана в графиках. Четыре RTX 2080 Ti Founders Edition быстро разогреются до 90 °C, понизят тактовую частоту и будут работать медленнее, чем RTX 2070 с нормальным охлаждением.
Рекомендую покупать Tesla V100 или A100 только в крайних случаях, поскольку их запрещено использовать в дата-центрах компаний. Или покупать их, если вам нужно обучать очень крупные сети на огромных GPU-кластерах – их соотношение цены и быстродействия не идеальное.
Если вы можете позволить себе что-то лучше, не берите карты GTX 16-й серии. У них нет тензорных ядер, поэтому быстродействие в ГО у них плохое. Я бы взял вместо них б/у RTX 2070 / RTX 2060 / RTX 2060 Super. Их можно брать, если ваш бюджет сильно ограничен.
Если у вас уже есть RTX 2080 Ti или лучше, обновляться до RTX 3090 практически бессмысленно. Ваши GPU и так хороши, а преимущества в скорости будут пренебрежимо малы по сравнению с приобретёнными проблемами с питанием и охлаждением – оно того не стоит.
Единственная причина, по которой я захотел бы обновиться с четырёх RTX 2080 Ti до четырёх RTX 3090 – если бы я занимался исследованиями очень крупных трансформеров или других сетей, сильно зависящих от вычислительных мощностей. Однако если у вас проблемы с памятью, сначала стоит рассмотреть различные трюки, для того, чтобы впихнуть крупные модели в существующую память.
Если у вас есть одна или несколько RTX 2070, я бы на вашем месте дважды подумал, прежде чем обновляться. Это довольно неплохие GPU. Возможно, будет иметь смысл продать их на eBay и купить RTX 3090, если вам не хватает 8 ГБ – как и в случае со многими другими GPU. Если памяти не хватает, обновление назревает.
Резюме:
Обычно — нет. PCIe 4.0 отлично подходит для GPU-кластера. Полезна, если у вас машина на 8 GPU. В иных случаях преимуществ у неё почти нет. Она улучшает параллелизацию и чуть быстрее передаёт данные. Но передача данных не является узким местом. В компьютерном зрении узким местом может быть хранение данных, но не передача данных по PCIe от GPU к GPU. Поэтому для большинства людей причин использовать PCIe 4.0 нет. Она, возможно, улучшит параллелизацию четырёх GPU на 1-7%.
Как и в случае с PCIe 4.0 – обычно нет. Линии PCIe требуются для параллелизации и быстрой передачи данных, что почти никогда не является узким местом. Если у вас 2 GPU, для них хватит 4-х линий. Для 4-х GPU я бы предпочёл 8 линий на GPU, однако если линий будет 4, это уменьшит производительность всего на 5-10%.
Можно купить один из двух вариантов, рассчитанных на один слот, или распределить их при помощи расширителей PCIe. Кроме пространства нужно сразу же задуматься об охлаждении и подходящем БП. Судя по всему, наиболее простым решением будет покупка 4-х RTX 3090 EVGA Hydro Copper со специальной петлёй водяного охлаждения. EVGA много лет выпускает версии карт с медным водяным охлаждением, и качеству их GPU можно доверять. Возможно, есть варианты и подешевле.
Расширители PCIe могут решить проблемы с пространством и охлаждением, однако в вашем корпусе должно быть достаточно места для всех карт. И убедитесь, что расширители достаточно длинные!
См. предыдущий раздел.
Да, но эффективно распараллелить работу не получится. Могу представить систему, где работает 3 RTX 3070 + 1 RTX 3090. С другой стороны, параллелизация между четырьмя RTX 3070 будет работать очень быстро, если вы впихнёте на них свою модель. И ещё одна причина, по которой вам может это понадобиться – использование старых GPU. Работать это будет, но параллелизация будет неэффективной, поскольку самые быстрые GPU будут ждать самых медленных GPU в точках синхронизации (обычно при обновлении градиента).
Обычно NVLink вам не нужна. Это высокоскоростная связь между несколькими GPU. Она нужна, если у вас есть кластер из 128 и более GPU. В иных случаях у неё почти нет преимуществ перед стандартной передачей данных по PCIe.
Определённо покупать б/у GPU. Отлично сработают использованные RTX 2070 ($400) и RTX 2060 ($300). Если не сможете их себе позволить, следующим наилучшим вариантом будут использованные GTX 1070 ($220) или GTX 1070 Ti ($230). Если и это слишком дорого, найдите использованные GTX 980 Ti (6GB $150) или GTX 1650 Super ($190). Если это тоже дорого, вам лучше пользоваться облачными сервисами. Они обычно предоставляют GPU с ограничением по времени или мощности, после чего придётся платить. Меняйте сервисы по кругу, пока не сможете позволить себе собственный GPU.
Для ускорения работы посредством параллелизации между двумя машинами нужны сетевые карты на 50 Гбит/с или более. Рекомендую поставить хотя бы EDR Infiniband – то есть, сетевую карту со скоростью не менее 50 Гбит/с. Две EDR карты с кабелем на eBay обойдутся вам в $500.
В некоторых случаях вы обойдётесь и Ethernet на 10 Гбит/с, но это обычно срабатывает только для определённых типов нейросетей (определённых свёрточных сетей) или для определённых алгоритмов (Microsoft DeepSpeed).
Видимо, нет. Поскольку от матрицы требуется, чтобы на каждые 4 элемента у неё было 2 нулевых, разреженные матрицы должны быть хорошо структурированными. Вероятно, можно немного подправить алгоритм, обрабатывая 4 значения в виде сжатой репрезентации двух значений, но это будет значить, что точное перемножение разреженных матриц на Ampere будет недоступно.
Я не рекомендую использовать процессор от Intel, если только вы не нагружаете процессор довольно сильно в соревнованиях Kaggle (где процессор загружен подсчётами линейной алгебры). И даже для таких соревнований процессоры от AMD отлично подходят. Процессоры от AMD в среднем оказываются дешевле и лучше для ГО. Для сборки из 4-х GPU моим однозначным выбором будет Threadripper. В нашем университете мы собрали десятки систем на таких процессорах, и все они работают отлично, без нареканий. Для систем с 8-ю GPU я бы взял тот процессор, опыт использования которого есть у вашего производителя. Надёжность процессора и PCIe в системах из 8-и карт важнее, чем просто быстродействие или эффективность в пересчёте на стоимость.
Нет. Обычно GPU прекрасно охлаждаются, если между GPU есть хотя бы небольшие промежутки. Разные виды корпусов могут дать вам разницу в 1-3 °C, а разное расстояние между картами – разницу в 10-30 °C. В общем, если между вашими картами есть промежутки, с охлаждением проблем нет. Если промежутков нет, вам нужны правильные вентиляторы (выдувающий вентилятор) или другое решение (водяное охлаждение, расширители PCIe). В любом случае, вид корпуса и его вентиляторы значения не имеют.
Не в ближайшие пару лет. Проблем там три: тензорные ядра, ПО и сообщество.
Сами кристаллы GPU от AMD хорошие: отличное быстродействие на FP16, отличная пропускная способность памяти. Но отсутствие тензорных ядер или их эквивалента приводит к тому, что их быстродействие страдает по сравнению с GPU от NVIDIA. А без реализации тензорных ядер в железе GPU от AMD никогда не будут конкурентоспособными. По слухам, на 2020-й год запланирована какая-то карточка для датацентров с аналогом тензорных ядер, однако точных данных пока нет. Если у них будет только карта с эквивалентом тензорных ядер для серверов, это будет означать, что мало кто сможет позволить себе GPU от AMD, что даст NVIDIA конкурентное преимущество.
Допустим, AMD представит в будущем железо с чем-то вроде тензорных ядер. Тогда многие скажут: «Но программ-то, работающих с GPU от AMD, нет! Как мне их использовать?» Это, в основном, заблуждение. ПО для AMD, работающее с ROCm, уже неплохо развито, а поддержка в PyTorch прекрасно организована. И хотя я не видел много отчётов о работе AMD GPU + PyTorch, все функции ПО туда интегрированы. Судя по всему, можно выбрать любую сеть и запустить её на GPU от AMD. Поэтому в данной области AMD уже неплохо развита, и эта проблема практически решена.
Однако, решив проблемы с ПО и отсутствием тензорных ядер, AMD столкнётся ещё с одной: с отсутствием сообщества. Наткнувшись на проблему с GPU от NVIDIA, вы можете поискать решение в Google и найти его. Это вызывает доверие к GPU от NVIDIA. Появляется инфраструктура, облегчающая использование GPU от NVIDIA (любая платформа для ГО работает, любая научная задача поддерживается). Есть куча хаков и трюков, сильно облегчающих использование GPU от NVIDIA (к примеру, apex). Экспертов и программистов для GPU от NVIDIA можно найти под каждым кустом, а вот экспертов по AMD GPU я знаю гораздо меньше.
В плане сообщества, ситуация с AMD напоминает ситуацию Julia vs Python. У Julia большой потенциал, и многие справедливо укажут, что этот язык программирования лучше подходит для научных работ. Однако же Julia по сравнению с Python используют крайне редко. Просто сообщество любителей Python очень велико. Вокруг таких мощных пакетов, как Numpy, SciPy и Pandas, собирается куча народу. Эта ситуация напоминает ситуацию NVIDIA vs AMD.
Поэтому с большой вероятностью AMD не нагонит NVIDIA, пока не представит эквивалент тензорных ядер и крепкое сообщество, построенное вокруг ROCm. AMD всегда будет иметь свою долю рынка в особых подгруппах (майнинг криптовалют, дата-центры). Но в ГО NVIDIA, скорее всего, ещё года два будет удерживать монополию.
Простое правило: если вы рассчитываете заниматься ГО дольше года, дешевле купить компьютер с GPU. Иначе лучше пользоваться облачными сервисами – если только у вас нет обширного опыта по облачному программированию, и вы хотите воспользоваться преимуществами масштабирования количества GPU по желанию.
Точный переломный момент, в который облачные GPU становятся дороже, чем собственный компьютер, сильно зависит от используемых сервисов. Это лучше подсчитывать самому. Ниже привожу примерный расчёт для сервера AWS V100 с одним V100, и сравниваю его со стоимостью настольного компьютера с одним RTX 3090, что близко по быстродействию. Компьютер с RTX 3090 стоит $2200 (2-GPU barebone + RTX 3090). Если вы в США, то прибавьте к этому $0,12 за кВт*ч за электричество. Сравним это с $2,14 в час за сервер в AWS.
При 15% утилизации в год компьютер использует
(350 Вт (GPU) + 100 Вт (CPU))*0.15 (утилизация) * 24 часа * 365 дней = 591 кВт*ч в год.
591 кВт*ч в год дают дополнительные $71.
Переломный момент, когда компьютер и облако сравниваются в цене при 15% утилизации, наступает где-то на 300-й день ($2,311 против $2,270):
$2.14/ч * 0.15 (утилизация) * 24 часа * 300 дней = $2,311
Если вы рассчитываете, что ваши модели ГО будут работать более 300 дней, лучше купить компьютер, чем использовать AWS.
Похожие расчёты можно провести для любого облачного сервиса, чтобы принять решение о том, использовать свой компьютер или облако.
Распространённые цифры по утилизации вычислительных мощностей следующие:
В целом, процент утилизации ниже в тех областях, где важнее размышлять о передовых идеях, чем разрабатывать практические решения. В некоторых областях процент утилизации меньше (исследования интерпретируемости), а в других – гораздо выше (машинный перевод, моделирования языка). В целом утилизацию личных машин обычно всегда переоценивают. Обычно большинство личных систем утилизированы на 5-10%. Поэтому я настоятельно рекомендую исследовательским группам и компаниям организовывать GPU-кластеры на Slurm вместо отдельных настольных компьютеров.
Лучшие GPU в общем: RTX 3080 и RTX 3090.
Каких GPU стоит избегать (вам как исследователю): карточек Tesla, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Хорошее соотношение быстродействия к цене, но дорогая: RTX 3080.
Хорошее соотношение быстродействия к цене, подешевле: RTX 3070, RTX 2060 Super.
У меня мало денег: Покупайте использованные карты. Иерархия: RTX 2070 ($400), RTX 2060 ($300), GTX 1070 ($220), GTX 1070 Ti ($230), GTX 1650 Super ($190), GTX 980 Ti (6GB $150).
У меня почти нет денег: многие стартапы рекламируют свои облачные услуги. Используйте бесплатные кредиты в облаках, меняйте их по кругу, пока не сможете купить GPU.
Я участвую в соревнованиях Kaggle: RTX 3070.
Я пытаюсь выиграть в конкурентной борьбе в области компьютерного зрения, предварительного обучения или машинного перевода: 4 штуки RTX 3090. Но подождите, пока специалисты не подтвердят наличие сборок с хорошим охлаждением и достаточным питанием.
Я изучаю обработку естественного языка: если вы не работаете с машинным переводом, моделированием языка или предварительным обучением, RTX 3080 будет достаточно.
Я начал заниматься ГО и серьёзно этим увлёкся: начните с RTX 3070. Если через 6-9 месяцев не надоест, продайте и купите четыре RTX 3080. В зависимости от того, что выберете дальше (стартап, Kaggle, исследования, прикладное ГО), года через три продайте свои GPU, и купите что-то более подходящее (RTX GPU следующего поколения).
Хочу попробовать ГО, но серьёзных намерений нет: RTX 2060 Super будет прекрасным выбором, однако, возможно, потребует замены БП. Если у вас на материнской плате есть слот PCIe x16, а БП выдаёт около 300 Вт, то прекрасным вариантом станет GTX 1050 Ti, поскольку не потребует иных вложений.
GPU кластер для параллельного моделирования объёмом менее 128 GPU: если вам разрешено покупать RTX для кластера: 66% 8x RTX 3080 и 33% 8x RTX 3090 (только при возможности хорошо охлаждать сборку). Если охлаждения не хватает, покупайте 33% RTX 6000 GPU или 8x Tesla A100. Если не можете покупать RTX GPU, я бы выбрал 8 узлов A100 Supermicro или 8 узлов RTX 6000.
GPU кластер для параллельного моделирования объёмом более 128 GPU: задумайтесь о машинах с 8-ю Tesla A100. Если вам нужно более 512 GPU, задумайтесь о системе DGX A100 SuperPOD.
Глубокое обучение (ГО) – область с повышенными запросами к вычислительным мощностям, поэтому ваш выбор GPU фундаментально определит ваш опыт в этой области. Но какие свойства важно учесть, если вы покупаете новый GPU? Память, ядра, тензорные ядра? Как сделать лучший выбор по соотношению цены и качества? В данной статье я подробно разберу все эти вопросы, распространённые заблуждения, дам вам интуитивное представление о GPU а также несколько советов, которые помогут вам сделать правильный выбор.
Статья написана так, чтобы дать вам несколько разных уровней понимания GPU, в т.ч. новой серии Ampere от NVIDIA. У вас есть выбор:
- Если вам не интересны детали работы GPU, что именно делает GPU быстрым, чего уникального есть в новых GPU серии NVIDIA RTX 30 Ampere – можете пропустить начало статьи, вплоть до графиков по быстродействию и быстродействию на $1 стоимости, а также раздела рекомендаций. Это ядро данной статьи и наиболее ценное содержимое.
- Если вас интересуют конкретные вопросы, то наиболее частые из них я осветил в последней части статьи.
- Если вам нужно глубокое понимание того, как работают GPU и тензорные ядра, лучше всего будет прочесть статью от начала и до конца. В зависимости от ваших знаний по конкретным предметам вы можете пропустить главу-другую.
Каждая секция предваряется небольшим резюме, которое поможет вам решить, читать её целиком или нет.
Содержание
Обзор
Как работают GPU?
Самые важные характеристики GPU, влияющие на скорость обработки
Тензорные ядра
Перемножение матриц без тензорных ядер
Перемножение матриц с тензорными ядрами
Пропускная способность памяти
Общая память / Кэш L1 / Регистры
Оценка эффективности Ampere в ГО
Теоретические оценки скорости Ampere
Практические оценки скорости Ampere
Возможные неточности оценок
Что ещё следует учесть в случае с Ampere / RTX 30
Разреженное обучение
Вычисления с низкой точностью
Новый дизайн вентилятора и проблемы с теплоотводом
Трёхслотовые карты и проблемы питания
Эффективность GPU при глубоком обучении
Скорость глубокого обучения GPU в пересчёте на стоимость
Рекомендации по выбору GPU
Когда мне понадобится более 11 ГБ памяти?
Когда можно обойтись памятью менее 11 ГБ?
Общие рекомендации
Рекомендации для GPU-кластеров
Какие GPU лучше не покупать
Когда лучше не покупать новых GPU?
Ответы на вопросы и заблуждения
Нужна ли мне PCIe 4.0?
Нужны ли мне линии PCIe 8x/16x?
Как впихнуть четыре RTX 3090, если каждая из них занимает по 3 слота PCIe?
Как охлаждать 4 RTX 3090 или 4 RTX 3080?
Можно ли использовать GPU нескольких разных типов?
Что такое NVLink, и нужно ли оно мне?
У меня нет денег даже на самые дешёвые ваши рекомендации. Что делать?
Что нужно для параллелизации проекта между двумя машинами?
Подходят ли алгоритмы перемножения разреженных матриц для любых разреженных матриц?
Нужен ли мне процессор от Intel для работы с несколькими GPU?
Имеет ли значение для охлаждения форма корпуса?
Догонят ли AMD GPU + ROCm когда-нибудь NVIDIA GPU + CUDA?
Когда лучше использовать облачные сервисы, а когда – специальный компьютер с GPU?
Советы для тех, кому лень читать
Обзор
Данная статья структурирована следующим образом. Сначала я объясняю, что делает GPU быстрым. Я опишу разницу между процессорами и GPU, тензорные ядра, пропускную способность памяти, иерархию памяти GPU, и как это всё связано с быстродействием в задачах ГО. Эти объяснения, возможно, помогут вам лучше понять, какие параметры GPU вам нужны. Потом я дам теоретические оценки быстродействия GPU и их соответствие с некоторыми тестами на скорость от NVIDIA, чтобы получить надёжные данные по быстродействию без предвзятости. Я опишу уникальные особенности GPU серии NVIDIA RTX 30 Ampere, которые стоит рассмотреть при покупке. Затем я дам рекомендации по GPU для вариантов с 1-2 чипами, 4, 8, и GPU-кластеров. Потом пойдёт раздел ответов на частые вопросы, которые мне задавали в твиттере. Там же будут развеяны распространённые заблуждения и освещены разные проблемы типа облаков против настольных компьютеров, охлаждения, AMD против NVIDIA, и др.
Как работают GPU?
Если вы часто пользуетесь GPU, полезно понимать, как они работают. Это знание пригодится вам, чтобы разобраться, почему в некоторых случаях GPU оказываются медленнее, а в других – быстрее. И тогда вы, возможно, поймёте, нужен ли вам вообще GPU, и какие варианты железа смогут соревноваться с ним в будущем. Вы можете пропустить этот раздел, если просто хотите получить полезную информацию по быстродействию и аргументы в пользу выбора определённого GPU. Лучше всего на общем уровне я объяснил принципы работы GPU в ответе на сайте Quora.
Это общее объяснение, хорошо раскрывающее вопрос о том, почему для ГО GPU подходят лучше, чем процессоры. Если мы изучим детали, мы сможем понять, чем GPU отличаются друг от друга.
Самые важные характеристики GPU, влияющие на скорость обработки
Этот раздел поможет вам более интуитивно мыслить на тему быстродействия в области ГО. Это понимание поможет вам оценивать будущие GPU самостоятельно.
Тензорные ядра
Резюме:
- Тензорные ядра уменьшают количество тактов, необходимых для подсчёта умножений и сложений в 16 раз – в моём примере для матрицы 32?32 с 128 до 8 тактов.
- Тензорные ядра уменьшают зависимость от повторяющегося доступа в общую память, экономя такты доступа в память.
- Тензорные ядра работают так быстро, что вычисления перестают быть узким местом. Единственным узким местом остаётся передача им данных.
Сегодня существует настолько много недорогих GPU, что почти каждый может позволить себе GPU с тензорными ядрами. Поэтому я всегда рекомендую GPU с тензорными ядрами. Полезно разобраться в принципах их работы, чтобы оценить важность этих вычислительных модулей, специализирующихся на перемножении матриц. На простом примере перемножения матриц A*B=C, где размер всех матриц равен 32?32, я покажу вам, как выглядит перемножение с тензорными ядрами и без них.
Чтобы разобраться в этом, сначала вам нужно понять концепцию тактов. Если процессор работает с частотой 1 ГГц, он проделывает 109 тактов в секунду. Каждый такт – это возможность для вычислений. Но по большей части операции идут дольше, чем один такт. Получается конвейер – чтобы начать выполнение одной операции, нужно сначала подождать столько тактов, сколько требуется на выполнение предыдущей операции. Это также называется задержкой операции.
Вот некоторые важные длительности, или задержки операции в тактах:
- Доступ к глобальной памяти до 48 Гб: ~200 тактов.
- Доступ к общей памяти (до 164 КБ на потоковый мультипроцессор): ~20 тактов.
- Совмещённое умножение-сложение (СУС): 4 такта.
- Перемножение матриц в тензорных ядрах: 1 такт.
Также вам нужно знать, что самая малая единица нитей в GPU – пакет из 32 нитей — называется варп [warp]. Варпы обычно работают синхронно – всем нитям внутри варпа нужно дождаться друг друга. Все операции в памяти GPU оптимизированы под варпы. К примеру, загрузка из глобальной памяти идёт по 32*4 байта – по 32 числа с плавающей запятой, по одному такому числу на каждую нить в варпе. В потоковом мультипроцессоре (эквивалент ядра процессора для GPU) может быть до 32 варпов = 1024 нити. Ресурсы мультипроцессора делятся между всеми активными варпами. Поэтому иногда нам нужно, чтобы работало меньше варпов, чтобы на один варп приходилось больше регистров, общей памяти и ресурсов тензорных ядер.
В обоих примерах предположим, что у нас есть одинаковые вычислительные ресурсы. В этом небольшом примере перемножения матриц 32?32 мы используем 8 мультипроцессоров (~10% от RTX 3090) и по 8 варпов на мультипроцессоре.
Перемножение матриц без тензорных ядер
Если нам нужно перемножить матрицы A*B=C, каждая из которых имеет размер 32?32, тогда нам нужно загрузить данные из памяти, к которой мы постоянно обращаемся, в общую память, поскольку задержки доступа к ней примерно в 10 раз меньше (не 200 тактов, а 20 тактов). Блок памяти в общей памяти часто называют плиткой памяти [memory tile], или просто плиткой. Загрузку двух 32?32 чисел с плавающей запятой в плитку общей памяти можно провести параллельно, используя 2*32 варпа. У нас есть 8 мультипроцессоров по 8 варпов каждый, поэтому благодаря параллелизации нам нужно провести одну последовательную загрузку из глобальной в общую память, на что уйдёт 200 тактов.
Для перемножения матриц нам нужно загрузить вектор из 32 чисел из общей памяти А и общей памяти В, и провести СУС, а потом сохранить выход в регистрах С. Мы разделяем эту работу так, чтобы каждый мультипроцессор занимался 8-ю скалярными произведениями (32?32) для вычисления 8 выходных данных для С. Почему их ровно 8 (в старых алгоритмах – 4), это уже чисто техническая особенность. Чтобы разобраться с этим, рекомендую прочесть статью Скотта Грэя. Это означает, что у нас пройдёт 8 доступов к общей памяти стоимостью в 20 тактов каждый, и 8 операций СУС (32 параллельных), стоимостью 4 такта каждая. В сумме стоимость получится:
200 тактов (глобальная память) + 8*20 тактов (общая память) + 8*4 такта (СУС) = 392 такта
Теперь посмотрим на эту стоимость для тензорных ядер.
Перемножение матриц с тензорными ядрами
При помощи тензорных ядер можно перемножить матрицы 4?4 за один цикл. Для этого нам нужно скопировать память в тензорные ядра. Как и выше, нам нужно прочесть данные из глобальной памяти (200 тактов) и сохранить их в общей. Для перемножения матриц 32?32 нам нужно произвести 8?8=64 операций в тензорных ядрах. В одном мультипроцессоре находится 8 тензорных ядер. С 8 мультипроцессорами у нас будет 64 тензорных ядра – как раз столько, сколько надо! Мы можем передать данные из общей памяти в тензорные ядра за 1 передачу (20 тактов), а потом провести все эти 64 операции параллельно (1 такт). Это значит, что общая стоимость перемножения матриц в тензорных ядрах будет:
200 тактов (глобальная память) + 20 тактов (общая память) + 1 такт (тензорные ядра) = 221 такт
Таким образом, используя тензорные ядра, мы значительно уменьшаем стоимость перемножения матриц, с 392 до 221 такта. В нашем упрощённом примере тензорные ядра уменьшили стоимость как доступа к общей памяти, так и операций СУС.
Хотя в данном примере примерно соблюдается последовательность вычислительных шагов с использованием тензорных ядер и без них, учтите, что это очень упрощённый пример. В реальных случаях перемножения матриц участвуют куда как большие плитки памяти и немного другие последовательности действий.
Однако, как мне кажется, из этого примера становится понятно, почему следующий атрибут, пропускная способность памяти, так важна для GPU с тензорными ядрами. Поскольку глобальная память – наиболее затратная вещь при перемножении матриц с тензорными ядрами, наши GPU были бы гораздо быстрее, если бы удалось уменьшить задержки доступа к глобальной памяти. Это можно сделать, либо увеличив тактовую частоту памяти (больше тактов в секунду, но больше тепла и энергопотребления), либо увеличив количество элементов, которые можно передавать за раз (ширину шины).
Пропускная способность памяти
В предыдущем разделе мы увидели, насколько быстры тензорные ядра. Настолько быстры, что большую часть времени они простаивают, ожидая, пока к ним поступят данные из глобальной памяти. К примеру, во время обучения по проекту BERT Large, где использовались очень большие матрицы – чем больше, тем для тензорных ядер лучше – утилизация тензорных ядер в TFLOPS составила порядка 30%, что означает, что 70% времени тензорные ядра простаивали.
Это означает, что при сравнении двух GPU с тензорными ядрами одним из лучших индикаторов быстродействия каждого из них будет служить пропускная способность памяти. К примеру, у A100 GPU пропускная способность составляет 1,555 ГБ/с, а у V100 — 900 ГБ/с. Простейший подсчёт говорит, что A100 будет быстрее V100 в 1555/900 = 1,73 раза.
Общая память / Кэш L1 / Регистры
Поскольку ограничивающим быстродействие фактором является передача данных в память тензорных ядер, мы должны обратиться к другим свойствам GPU, позволяющим ускорить передачу к ним данных. С этим связаны общая память, кэш L1 и количество регистров. Чтобы понять, как иерархия памяти ускоряет передачу данных, полезно понять, как в GPU происходит перемножение матриц.
Для перемножения матриц мы пользуемся иерархией памяти, идущей от медленной глобальной памяти к быстрой локальной общей памяти, и затем к сверхбыстрым регистрам. Однако чем быстрее память, тем она меньше. Поэтому нам нужно делить матрицы на меньшие, а потом выполнять перемножение этих меньших плиток в местной общей памяти. Тогда оно будет происходить быстро и ближе к потоковому мультипроцессору (ПМ) – эквиваленту ядра процессора. Тензорные ядра позволяют нам сделать ещё один шаг: мы берём все плитки и грузим их часть в тензорные ядра. Общая память обрабатывает матричные плитки в 10-50 раз быстрее, чем глобальная память GPU, а регистры тензорных ядер обрабатывают её в 200 раз быстрее, чем глобальная память GPU.
Увеличение размера плиток позволяет нам повторно использовать больше памяти. Подробно я писал об этом в моей статье TPU vs GPU. В TPU на каждое тензорное ядро приходится по очень, очень большой плитке. TPU могут повторно использовать гораздо больше памяти с каждой новой передачей данных из глобальной памяти, из-за чего они чуть более эффективно справляются с перемножением матриц по сравнению с GPU.
Размеры плитки определяются объёмами памяти на каждый из ПМ – эквивалент ядра процессора на GPU. В зависимости от архитектур эти объёмы составляют:
- Volta: 96 кБ общей памяти / 32 кБ L1
- Turing: 64 кБ общей памяти / 32 кБ L1
- Ampere: 164 кБ общей памяти / 32 кБ L1
Видно, что у Ampere обща память гораздо больше, что позволяет использовать плитки большего размера, что уменьшает количество обращений к глобальной памяти. Поэтому Ampere эффективнее пользуется пропускной способностью памяти GPU. Это увеличивает быстродействие на 2-5%. Особенно увеличение заметно на огромных матрицах.
У тензорных ядер Ampere есть ещё одно преимущество – объём общих для нескольких нитей данных у них больше. Это уменьшает количество обращений к регистрам. Объём регистров ограничен 64 к на ПМ или 255 на нить. Если сравнить с Volta, тензорные ядра Ampere используют в 3 раза меньше регистров, благодаря чему на каждую плитку в общей памяти имеется больше активных тензорных ядер. Иначе говоря, мы можем загрузить в 3 раза больше тензорных ядер тем же количеством регистров. Однако поскольку пропускная способность остаётся узким местом, увеличение TFLOPS на практике будет мизерным, по сравнению с теоретическим. Новые тензорные ядра улучшили быстродействие примерно на 1-3%.
В целом видно, что архитектура Ampere оптимизирована так, чтобы более эффективно использовать пропускную способность памяти посредством улучшенной иерархии – от глобальной памяти к плиткам общей памяти, и к регистрам тензорных ядер.
Оценка эффективности Ampere в ГО
Резюме:
- Теоретические оценки на основе пропускной способности памяти и улучшенной иерархии памяти у Ampere GPU предсказывают ускорение в 1,78 – 1,87 раз.
- NVIDIA опубликовала данные по измерениям скорости для Tesla A100 и V100 GPU. Они больше маркетинговые, но на их основе можно построить непредвзятую модель.
- Непредвзятая модель говорит о том, что по сравнению с V100 на Tesla A100 в 1,7 раз быстрее работает обработка естественного языка и в 1,45 раз быстрее компьютерное зрение.
Этот раздел предназначен для тех, кто хочет углубиться в технические детали того, как я получил оценки быстродействия Ampere GPU. Если вам это неинтересно, его спокойно можно пропустить.
Теоретические оценки скорости Ampere
Учитывая вышеизложенные аргументы, можно было бы ожидать, что разница между двумя GPU-архитектурами с тензорными ядрами должна была заключаться в основном в пропускной способности памяти. Дополнительные преимущества получаются за счёт увеличения общей памяти и кэша L1, а также эффективного использования регистров.
Пропускная способность Tesla A100 GPU по сравнению с Tesla V100 увеличивается в 1555/900 = 1,73 раз. Также разумно ожидать увеличения скорости на 2-5% из-за большей общей памяти, и на 1-3% из-за улучшения тензорных ядер. Получается, что ускорение должно составить от 1,78 до 1,87 раза.
Практические оценки скорости Ampere
Допустим, у нас есть оценка одного GPU для такой архитектуры, как Ampere, Turing или Volta. Легко экстраполировать эти результаты на другие GPU такой же архитектуры или серии. К счастью, NVIDIA уже провела тесты сравнения A100 и V100 на разных задачах, связанных с компьютерным зрением и пониманием естественного языка. К несчастью, NVIDIA сделала всё возможное, чтобы эти числа нельзя было сравнивать напрямую – в тестах использовали различные размеры пакетов данных и разное количество GPU, чтобы A100 не могла выиграть. Так что, в каком-то смысле, полученные показатели быстродействия частично честные, частично рекламные. В целом можно утверждать, что увеличение размера пакетов данных обосновано, поскольку у A100 больше памяти – однако, для сравнения GPU-архитектур нам нужно сравнивать непредвзятые данные по быстродействию на задачах с одинаковым размером пакета данных.
Чтобы получить непредвзятые оценки, можно масштабировать результаты измерений V100 и A100 двумя способами: учитывать разницу в размере пакета данных, или учитывать разницу в количестве GPU – 1 против 8. Нам повезло, и мы можем найти подобные оценки для обоих случаев в представленных NVIDIA данных.
Удвоение размера пакета увеличивает пропускную способность на 13,6% в изображениях в секунду (для свёрточных нейросетей, СНС). Я измерил скорость той же задачи с архитектурой Transformer на моём RTX Titan, и, как ни удивительно, получил такой же результат – 13,5%. Судя по всему, это надёжная оценка.
Увеличивая параллелизацию сетей, увеличивая количество GPU, мы теряем в быстродействии из-за накладных расходов, связанных с сетями. Но система A100 8x GPU лучше работает с сетями (NVLink 3.0) по сравнению с V100 8x GPU (NVLink 2.0) – и это ещё один запутывающий фактор. Если посмотреть на данные от NVIDIA, можно увидеть, что для обработки СНС у системы с 8-ю A100 накладные расходы на 5% ниже, чем у системы с 8-ю V10000. Это значит, что если переход от 1-го A10000 к 8-и A10000 даёт вам ускорение, допустим, в 7,0 раз, то переход от 1-го V10000 к 8-и V10000 даёт вам ускорение только в 6,67 раз. Для трансформеров эта цифра составляет 7%.
Используя эту информацию, мы можем оценить ускорение некоторых определённых архитектур ГО непосредственно на основе предоставленных NVIDIA данных. Tesla A100 имеет следующие преимущества в скорости по сравнению с Tesla V100:
- SE-ResNeXt101: 1,43 раз.
- Masked-R-CNN: 1,47 раз.
- Transformer (12 слоёв, машинный перевод, WMT14 en-de): 1,70 раз.
Поэтому для компьютерного зрения числа получаются ниже теоретической оценки. Это может происходить из-за меньших измерений тензора, накладных расходов операций, которые требуются для подготовки перемножения матриц типа img2col или быстрое преобразование Фурье, или операций, не способных насытить GPU (конечные слои часто оказываются относительно маленькими). Также это может оказаться артефактами определённых архитектур (сгруппированная свёртка).
Практическая оценка скорости работы трансформера очень близка к теоретической. Вероятно, потому, что алгоритмы работы с большими матрицами весьма прямолинейны. Для подсчёта эффективности затрат на GPU я буду использовать практические оценки.
Возможные неточности оценок
Выше даны сравнительные оценки A100 и V100. В прошлом NVIDIA тайком ухудшила работу «игровых» RTX GPU: уменьшила утилизацию тензорных ядер, добавила игровые вентиляторы для охлаждения, запретила передачу данных между GPU. Возможно, что в серии RT 30 также внесли неизвестные ухудшения по сравнению с Ampere A100.
Что ещё следует учесть в случае с Ampere / RTX 30
Резюме:
- Ampere позволяет проводить обучение сетей на основе разреженных матриц, что ускоряет процесс обучения максимум в два раза.
- Разреженное обучение сетей до сих пор редко используется, однако благодаря ему Ampere не скоро устареет.
- У Ampere есть новые типы данных с малой точностью, благодаря чему использовать малую точность гораздо проще, однако это не обязательно даст прирост в скорости по сравнению с предыдущими GPU.
- Новый дизайн вентиляторов хорош, если между GPU у вас есть свободное место – однако непонятно, эффективно ли будут охлаждаться GPU, стоящие вплотную.
- 3-слотовый дизайн RTX 3090 будет проблемой для сборок по 4 GPU. Возможные решения – использовать 2-слотовые варианты или расширители для PCIe.
- Четырём RTX 3090 потребуется больше питания, чем может предложить любой стандартный БП на рынке.
У новых NVIDIA Ampere RTX 30 есть дополнительные преимущества перед NVIDIA Turing RTX 20 – разреженное обучение и улучшенная обработка данных нейросетью. Остальные свойства, типа новых типов данных, можно считать простым повышением удобства – они ускоряют работу так же, как и серия Turing, не требуя при этом дополнительного программирования.
Разреженное обучение
Ampere позволяет с большой скоростью и автоматически перемножать разреженные матрицы. Это работает так – вы берёте матрицу, режете её на кусочки по 4 элемента, и поддерживающее разреженные матрицы тензорное ядро разрешает двум элементам из этих четырёх быть нулевыми. Это приводит к ускорению работы в 2 раза, поскольку требования к пропускной способности во время перемножения матриц в два раза уменьшаются.
В своих исследованиях я работал с разреженным обучением сетей. Работу критиковали, в частности, за то, что я «уменьшаю необходимые для сети FLOPS, но не увеличиваю из-за этого скорость, потому что GPU не умеют быстро перемножать разреженные матрицы». Ну что ж – поддержка перемножения разреженных матриц появилась в тензорных ядрах, и мой алгоритм, или любой другой алгоритм (ссылка, ссылка, ссылка, ссылка), работающий с разреженным матрицами, теперь реально может работать во время обучения в два раза быстрее.
Хотя эта свойство пока считается экспериментальным, а обучение разреженных сетей не применяется повсеместно, если у вашего GPU есть поддержка этой технологии, то вы готовы к будущему разреженного обучения.
Вычисления с низкой точностью
Я уже демонстрировал, как новые типы данных могут улучшать стабильность обратного распространения с низкой точностью в моей работе. Пока что проблемой стабильного обратного распространения с 16-битными числами с плавающей запятой является то, что обычные типы данных поддерживают только промежуток [-65,504, 65,504]. Если ваш градиент выйдет за этот промежуток, то взорвётся, выдав значения NaN. Для предотвращения этого мы обычно масштабируем значения, умножая их на небольшое число перед обратным распространением, чтобы избежать взрыва градиента.
Формат Brain Float 16 (BF16) использует больше битов для экспоненты, благодаря чему промежуток возможных значений получается таким же, как у FP32: [-3*10^38, 3*10^38]. У BF16 меньше точность, т.е. меньше значащих разрядов, но точность градиента при обучении сетей не так уж и важна. Поэтому BF16 гарантирует, что вам уже не нужно будет заниматься масштабированием или волноваться о взрыве градиента. С этим форматом мы должны увидеть увеличение стабильности обучения за счёт небольшой потери точности.
Что это значит для вас: с точностью BF16 обучение может быть более стабильным, чем с точностью FP16, а скорость у них одинаковая. С точностью TF32 вы получите стабильность почти как у FP32, а ускорение – почти как у FP16. Плюс в том, что при использовании этих типов данных можно менять FP32 на TF32, а FP16 на BF16, ничего не меняя в коде!
В целом эти новые типы данных можно считать ленивыми, в том смысле, что вы могли получить все их преимущества, используя старые типа данных и немного программирования (правильное масштабирование, инициализация, нормализация, использование Apex). Поэтому эти типы данных обеспечивают не ускорение, а делают использование низкой точности в обучении проще.
Новый дизайн вентилятора и проблемы с теплоотводом
По новой схеме вентиляторов для серии RTX 30 есть выдувающий воздух вентилятор и втягивающий воздух вентилятор. Сам дизайн продуман гениально, и будет очень эффективно работать при наличии свободного пространства между GPU. Однако непонятно, как поведут себя GPU, если их понаставить один к другому. Выдувающий вентилятор сможет выдувать воздух прочь от других GPU, но невозможно сказать, как это будет работать, поскольку его форма отличается от той, что была раньше. Если вы планируете поставить 1 или 2 GPU туда, где есть 4 слота, тогда у вас не должно быть проблем. Но если вы захотите использовать 3-4 RTX 30 GPU рядышком, я бы сначала подождал отчётов о температурном режиме, а потом уже решил, понадобятся ли ещё вентиляторы, расширители PCIe или другие решения.
В любом случае, решить проблему с теплоотводом может помочь водяное охлаждение. Многие производители предлагают такие решения для карточек RTX 3080/RTX 3090, и тогда они не будут греться, даже если их будет 4. Однако не покупайте готовых решений для GPU, если вы захотите собрать компьютер с 4 GPU, поскольку в большинстве корпусов будет очень трудно распределить радиаторы.
Ещё одно решение проблемы охлаждения – купить расширители PCIe и распределить карты внутри корпуса. Это очень эффективно – я и другие аспиранты из Ванингтонского университета с большим успехом используем этот вариант. Выглядит не очень аккуратно, зато GPU не греются! Также этот вариант поможет в случае, если вам не хватает пространства для размещения GPU. Если в вашем корпусе есть место, можно, допустим, купить стандартные RTX 3090 на три слота, и распределить их при помощи расширителей по всему корпусу. Таким образом можно решить одновременно проблему с местом и охлаждением 4-х RTX 3090.
Рис. 1: 4 GPU с расширителями PCIe
Трёхслотовые карты и проблемы питания
RTX 3090 занимает 3 слота, поэтому их невозможно использовать по 4 штуки с вентиляторами от NVIDIA по умолчанию. И это не удивительно, поскольку она требует 350 Вт TDP. RTX 3080 лишь немногим уступает ей, требуя 320 Вт TDP, и охлаждать систему с четырьмя RTX 3080 будет очень сложно.
Также сложно питать систему из 4-х карт по 350 Вт = 1400 Вт. Блоки питания (БП) на 1600 Вт бывают, однако 200 Вт на процессор и материнку может не хватить. Максимальное энергопотребление происходит только при полной загрузке, и во время ГО процессор обычно слабо нагружен. Поэтому БП на 1600 Вт может подойти для 4-х RTX 3080, но для 4-х RTX 3090 лучше поискать БП на 1700 Вт и более. На сегодня на рынке таких БП не наблюдается. Могут подойти серверные БП или специальные блоки для криптомайнеров, но у них может оказаться необычный форм-фактор.
Эффективность GPU при глубоком обучении
В следующий тест вошли не только сравнения Tesla A100 и Tesla V100 – я построил модель, укладывающуюся в эти данные и четыре различных теста, где испытывали Titan V, Titan RTX, RTX 2080 Ti и RTX 2080 (ссылка, ссылка, ссылка, ссылка).
Кроме того я масштабировал результаты тестов таких карт среднего уровня, как RTX 2070, RTX 2060 или Quadro RTX, путём интерполяции точек данных тестов. Обычно в архитектуре GPU такие данные масштабируются линейно по отношению к перемножению матриц и пропускной способности памяти.
Я собирал только данные тестов по обучению FP16 со смешанной точностью, поскольку не вижу причин, по которым нужно было бы использовать обучение с числами FP32.
Рис. 2: Быстродействие, нормализованное по результатам RTX 2080 Ti
По сравнению с RTX 2080 Ti, RTX 3090 работает со свёрточными сетями в 1,57 раз быстрее, а с трансформерами – в 1,5 раз быстрее, при этом стоит на 15% дороже. Получается, что Ampere RTX 30 демонстрирует значительное улучшение со времён серии Turing RTX 20.
Скорость глубокого обучения GPU в пересчёте на стоимость
Какой GPU будет наиболее выгодным вложением денег? Всё зависит от общей стоимости системы. Если она дорогая, имеет смысл вложиться в более дорогие GPU.
Ниже привожу данные по трём сборкам на PCIe 3.0, которые я использую в качестве базовых ориентиров стоимости систем из 2 или 4 GPU. Я беру эту базовую стоимость и добавляю к ней стоимость GPU. Последнюю я высчитываю как среднюю цену между предложениями с Amazon и eBay. Для новых Ampere я использую только одну цену. В совокупности с приведёнными выше данными по быстродействию это даёт значения быстродействия в пересчёте на доллар. Для системы из 8 GPU за основу я беру Supermicro barebone – промышленный стандарт для RTX-серверов. Приводимые графики не учитывают требования к памяти. Вам сначала нужно задуматься о том, какая вам требуется память, а потом поискать наилучшие варианты на графиках. Примерные советы по памяти:
- Использование предварительно обученных трансформеров, или обучение небольшого трансформера с нуля >= 11 ГБ.
- Обучение большого трансформера или свёрточной сети в исследовании или продакшене: >= 24 ГБ.
- Прототипирование нейросетей (трансформера или свёрточной сети) >= 10 ГБ.
- Участие в конкурсах Kaggle >= 8 ГБ.
- Компьютерное зрение >= 10 ГБ.
Рис. 3: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.
Рис. 4: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.
Рис. 5: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.
Рекомендации по выбору GPU
Ещё раз хочется подчеркнуть: при выборе GPU сначала убедитесь, что у него хватает памяти для ваших задач. Шаги при выборе GPU должны быть следующие:
- Понять, чего я хочу достичь при помощи GPU: участие в соревнованиях Kaggle, обучения ГО, исследование мелких проектов, исследования в области компьютерного зрения или обработки естественного языка, в каких-то других областях знаний.
- Определить, сколько памяти нужно для моих целей.
- При помощи приведённых выше графиков по соотношению быстродействия к доллару выбрать подходящий под требования GPU, имеющий нужный объём памяти.
- Есть ли у выбранного GPU какие-то подвохи? К примеру, если это RTX 3090, влезет ли он в мой компьютер? Хватит ли у моего БП мощности для поддержки этого GPU? Будет ли проблемой теплоотвод, или я смогу эффективно охлаждать GPU?
Некоторые из шагов требуют задуматься о том, чего вы хотите, и провести небольшое исследование на тему того, какие объёмы памяти используют другие люди, занимающиеся тем же самым. Я могу дать несколько советов, но не могу полностью ответить на все вопросы в данной области.
Когда мне понадобится более 11 ГБ памяти?
Я уже упоминал, что при работе с трансформерами вам потребуется не менее 11 ГБ, а при проведении исследований в этой области – не менее 24 ГБ. У большинства предыдущих предварительно обученных моделей очень большие требования к памяти, и их обучали на GPU классом не ниже RTX 2080 Ti с объёмом памяти не менее 11 ГБ. Поэтому, если у вас меньше 11 ГБ памяти, запуск некоторых моделей может стать трудным или вовсе невозможным делом.
Другие области, требующие больших объёмов памяти – обработка медицинских снимков, передовые модели компьютерного зрения, и всё с изображениями большого размера.
В целом, если вы стремитесь разработать модели, способные опередить конкурентов – будь то исследования, промышленное применение или соревнования Kaggle – дополнительная память, возможно, даст вам конкурентное преимущество.
Когда можно обойтись памятью менее 11 ГБ?
Карты RTX 3070 и RTX 3080 – мощные, но памяти им не хватает. Однако для многих задач такого количества памяти может и не потребоваться.
RTX 3070 идеально подходит для обучения ГО. Базовые навыки обучения сетей большинства архитектур можно приобрести, уменьшая масштаб сетей или используя изображения меньшего размера. Если бы мне пришлось учиться ГО, я бы выбрал себе RTX 3070, или даже несколько штук, если бы мог себе их позволить.
RTX 3080 на сегодня – наиболее эффективная карта по отношению цены к быстродействию, и поэтому идеально подходит для прототипирования. Для прототипирования нужны большие объёмы памяти, а память стоит недорого. Под прототипированием я понимаю прототипирование в любой области – исследования, соревнования Kaggle, проба идей для стартапа, эксперименты с исследовательским кодом. Для всех подобных применений RTX 3080 подойдёт лучше всего.
Если бы я, допустим, руководил исследовательской лабораторией или стартапом, 66-80% всего бюджета я пустил бы на машины RTX 3080, и 20-33% — на RTX 3090 с надёжным водяным охлаждением. RTX 3080 более эффективна в пересчёте на стоимость, и доступ к ней можно организовать через Slurm. Поскольку прототипированием надо заниматься в эджайл-режиме, его нужно вести с моделями и наборами данных меньшего размера. И RTX 3080 идеально для этого подходит. Когда ученики/коллеги создадут отличную модель-прототип, они смогут выкатывать её на RTX 3090, масштабируя до более крупных моделей.
Общие рекомендации
В целом модели серии RTX 30 очень мощные, и я определённо их рекомендую. Учтите требования к памяти, как указано ранее, а также требования к питанию и охлаждению. Если у вас между GPU будет свободный слот, с охлаждением проблем не будет. Иначе обеспечьте картам RTX 30 водяное охлаждение, расширители PCIe или эффективные карты с вентиляторами.
В целом я бы рекомендовал RTX 3090 всем, кто может себе её позволить. Она не только подойдёт вам сейчас, но и останется очень эффективной в следующие 3-7 лет. Маловероятно, что в ближайшие три года HBM-память сильно подешевеет, поэтому следующий GPUУ будет всего на 25% лучше, чем RTX 3090. Лет через 5-7, наверное, мы увидим дешёвую HBM-память, после чего вам определённо нужно будет обновлять парк.
Если вы собираете систему из нескольких RTX 3090, обеспечьте им достаточное охлаждение и питание.
Если у вас нет жёстких требований к конкурентным преимуществам, я бы порекомендовал вам RTX 3080. Это более эффективное решение в пересчёте на стоимость, и оно обеспечит быстрое обучение большинства сетей. Если вы примените нужные трюки с памятью и не против написания дополнительного кода, то есть много трюков, позволяющих впихнуть сеть на 24 ГБ в GPU с 10 ГБ.
RTX 3070 тоже отличная карта для обучения ГО и прототипирования, и она на $200 дешевле, чем RTX 3080. Если вы не можете позволить себе RTX 3080, тогда ваш выбор – это RTX 3070.
Если ваш бюджет ограничен, и RTX 3070 для вас слишком дорогая, то на eBay можно найти использованную RTX 2070 по цене порядка $260. Пока неясно, выйдет ли RTX 3060, но если ваш бюджет невелик, возможно, стоит подождать её выхода. Если её ценообразование будет соответствовать RTX 2060 и GTX 1060, тогда она должна будет стоить около $250-$300, и выдавать неплохие результаты.
Рекомендации для GPU-кластеров
Схема GPU-кластера сильно зависит от его использования. Для системы с 1024 GPU и более главным будет наличие сети, но если вы используете не более 32 GPU за раз, то вкладываться в построение мощной сети смысла нет.
Вообще, карточки RTX по соглашению CUDA нельзя использовать в дата-центрах. Однако часто университеты могут стать исключением из этого правила. Если вы хотите получить подобное разрешение, стоит связаться с представителем NVIDIA. Если вам можно использовать карты RTX, то я бы порекомендовал стандартную систему Supermicro на 8 GPU RTX 3080 или RTX 3090 (если вы можете обеспечить им охлаждение). Небольшой набор из 8 узлов A10000 гарантирует эффективное использование моделей после прототипирования, особенно если обеспечить охлаждением серверы на 8 RTX 3090 не получается. В данном случае я бы порекомендовал A10000 вместо RTX 6000 / RTX 8000, поскольку A10000 довольно эффективные в пересчёте на стоимость, и не устареют быстро.
Если вам нужно обучать очень большие сети на кластере GPU (256 GPU и более), я бы порекомендовал систему NVIDIA DGX SuperPOD с A10000. от 256 GPU сеть становится необходимой. Если вы хотите расшириться, и выйти за пределы 256 GPU, вам понадобится очень оптимизированная система, для которой стандартные решения уже не подойдут.
Особенно на масштабах 1024 GPU и более единственными конкурентоспособными решениями на рынке остаются Google TPU Pod и NVIDIA DGX SuperPod. На таких масштабах я бы предпочёл Google TPU Pod, поскольку их специальная сетевая инфраструктура выглядит лучше, чем NVIDIA DGX SuperPod – хотя в принципе, эти системы довольно близки. В прикладных приложениях и ГО система из GPU бывает более гибкой, чем TPU, при этом системы из TPU поддерживают модели большего размера и лучше масштабируются. Поэтому у обеих систем есть свои достоинства и недостатки.
Какие GPU лучше не покупать
Не рекомендую покупать по нескольку RTX Founders Edition или RTX Titan, если только у вас не будет расширителей PCIe, решающих их проблемы с охлаждением. Они просто разогреются и их скорость сильно упадёт по сравнению с той, что указана в графиках. Четыре RTX 2080 Ti Founders Edition быстро разогреются до 90 °C, понизят тактовую частоту и будут работать медленнее, чем RTX 2070 с нормальным охлаждением.
Рекомендую покупать Tesla V100 или A100 только в крайних случаях, поскольку их запрещено использовать в дата-центрах компаний. Или покупать их, если вам нужно обучать очень крупные сети на огромных GPU-кластерах – их соотношение цены и быстродействия не идеальное.
Если вы можете позволить себе что-то лучше, не берите карты GTX 16-й серии. У них нет тензорных ядер, поэтому быстродействие в ГО у них плохое. Я бы взял вместо них б/у RTX 2070 / RTX 2060 / RTX 2060 Super. Их можно брать, если ваш бюджет сильно ограничен.
Когда лучше не покупать новых GPU?
Если у вас уже есть RTX 2080 Ti или лучше, обновляться до RTX 3090 практически бессмысленно. Ваши GPU и так хороши, а преимущества в скорости будут пренебрежимо малы по сравнению с приобретёнными проблемами с питанием и охлаждением – оно того не стоит.
Единственная причина, по которой я захотел бы обновиться с четырёх RTX 2080 Ti до четырёх RTX 3090 – если бы я занимался исследованиями очень крупных трансформеров или других сетей, сильно зависящих от вычислительных мощностей. Однако если у вас проблемы с памятью, сначала стоит рассмотреть различные трюки, для того, чтобы впихнуть крупные модели в существующую память.
Если у вас есть одна или несколько RTX 2070, я бы на вашем месте дважды подумал, прежде чем обновляться. Это довольно неплохие GPU. Возможно, будет иметь смысл продать их на eBay и купить RTX 3090, если вам не хватает 8 ГБ – как и в случае со многими другими GPU. Если памяти не хватает, обновление назревает.
Ответы на вопросы и заблуждения
Резюме:
- PCIe-линии и PCIe 4.0 не имеют значения для систем с двумя GPU. Для систем с 4-мя GPU – практически не имеют.
- Охлаждать RTX 3090 и RTX 3080 будет тяжело. Используйте водяное охлаждение или расширители PCIe.
- NVLink нужен только для GPU-кластеров.
- В одном компьютере можно использовать разные GPU (например, GTX 1080 + RTX 2080 + RTX 3090), но эффективной параллелизации не получится.
- Для параллельной работы более чем двух машин потребуется Infiniband и сеть на 50 Гбит/с.
- Процессоры от AMD дешевле, чем от Intel, и у последних почти нет преимуществ.
- Несмотря на героические усилия инженеров, AMD GPU + ROCm вряд ли смогут конкурировать с NVIDIA из-за отсутствия сообщества и эквивалента тензорных ядер в ближайшие 1-2 года.
- Облачные GPU выгодны, если использовать их не более года. После этого настольный вариант становится дешевле.
Нужна ли мне PCIe 4.0?
Обычно — нет. PCIe 4.0 отлично подходит для GPU-кластера. Полезна, если у вас машина на 8 GPU. В иных случаях преимуществ у неё почти нет. Она улучшает параллелизацию и чуть быстрее передаёт данные. Но передача данных не является узким местом. В компьютерном зрении узким местом может быть хранение данных, но не передача данных по PCIe от GPU к GPU. Поэтому для большинства людей причин использовать PCIe 4.0 нет. Она, возможно, улучшит параллелизацию четырёх GPU на 1-7%.
Нужны ли мне линии PCIe 8x/16x?
Как и в случае с PCIe 4.0 – обычно нет. Линии PCIe требуются для параллелизации и быстрой передачи данных, что почти никогда не является узким местом. Если у вас 2 GPU, для них хватит 4-х линий. Для 4-х GPU я бы предпочёл 8 линий на GPU, однако если линий будет 4, это уменьшит производительность всего на 5-10%.
Как впихнуть четыре RTX 3090, если каждая из них занимает по 3 слота PCIe?
Можно купить один из двух вариантов, рассчитанных на один слот, или распределить их при помощи расширителей PCIe. Кроме пространства нужно сразу же задуматься об охлаждении и подходящем БП. Судя по всему, наиболее простым решением будет покупка 4-х RTX 3090 EVGA Hydro Copper со специальной петлёй водяного охлаждения. EVGA много лет выпускает версии карт с медным водяным охлаждением, и качеству их GPU можно доверять. Возможно, есть варианты и подешевле.
Расширители PCIe могут решить проблемы с пространством и охлаждением, однако в вашем корпусе должно быть достаточно места для всех карт. И убедитесь, что расширители достаточно длинные!
Как охлаждать 4 RTX 3090 или 4 RTX 3080?
См. предыдущий раздел.
Можно ли использовать GPU нескольких разных типов?
Да, но эффективно распараллелить работу не получится. Могу представить систему, где работает 3 RTX 3070 + 1 RTX 3090. С другой стороны, параллелизация между четырьмя RTX 3070 будет работать очень быстро, если вы впихнёте на них свою модель. И ещё одна причина, по которой вам может это понадобиться – использование старых GPU. Работать это будет, но параллелизация будет неэффективной, поскольку самые быстрые GPU будут ждать самых медленных GPU в точках синхронизации (обычно при обновлении градиента).
Что такое NVLink, и нужно ли оно мне?
Обычно NVLink вам не нужна. Это высокоскоростная связь между несколькими GPU. Она нужна, если у вас есть кластер из 128 и более GPU. В иных случаях у неё почти нет преимуществ перед стандартной передачей данных по PCIe.
У меня нет денег даже на самые дешёвые ваши рекомендации. Что делать?
Определённо покупать б/у GPU. Отлично сработают использованные RTX 2070 ($400) и RTX 2060 ($300). Если не сможете их себе позволить, следующим наилучшим вариантом будут использованные GTX 1070 ($220) или GTX 1070 Ti ($230). Если и это слишком дорого, найдите использованные GTX 980 Ti (6GB $150) или GTX 1650 Super ($190). Если это тоже дорого, вам лучше пользоваться облачными сервисами. Они обычно предоставляют GPU с ограничением по времени или мощности, после чего придётся платить. Меняйте сервисы по кругу, пока не сможете позволить себе собственный GPU.
Что нужно для параллелизации проекта между двумя машинами?
Для ускорения работы посредством параллелизации между двумя машинами нужны сетевые карты на 50 Гбит/с или более. Рекомендую поставить хотя бы EDR Infiniband – то есть, сетевую карту со скоростью не менее 50 Гбит/с. Две EDR карты с кабелем на eBay обойдутся вам в $500.
В некоторых случаях вы обойдётесь и Ethernet на 10 Гбит/с, но это обычно срабатывает только для определённых типов нейросетей (определённых свёрточных сетей) или для определённых алгоритмов (Microsoft DeepSpeed).
Подходят ли алгоритмы перемножения разреженных матриц для любых разреженных матриц?
Видимо, нет. Поскольку от матрицы требуется, чтобы на каждые 4 элемента у неё было 2 нулевых, разреженные матрицы должны быть хорошо структурированными. Вероятно, можно немного подправить алгоритм, обрабатывая 4 значения в виде сжатой репрезентации двух значений, но это будет значить, что точное перемножение разреженных матриц на Ampere будет недоступно.
Нужен ли мне процессор от Intel для работы с несколькими GPU?
Я не рекомендую использовать процессор от Intel, если только вы не нагружаете процессор довольно сильно в соревнованиях Kaggle (где процессор загружен подсчётами линейной алгебры). И даже для таких соревнований процессоры от AMD отлично подходят. Процессоры от AMD в среднем оказываются дешевле и лучше для ГО. Для сборки из 4-х GPU моим однозначным выбором будет Threadripper. В нашем университете мы собрали десятки систем на таких процессорах, и все они работают отлично, без нареканий. Для систем с 8-ю GPU я бы взял тот процессор, опыт использования которого есть у вашего производителя. Надёжность процессора и PCIe в системах из 8-и карт важнее, чем просто быстродействие или эффективность в пересчёте на стоимость.
Имеет ли значение для охлаждения форма корпуса?
Нет. Обычно GPU прекрасно охлаждаются, если между GPU есть хотя бы небольшие промежутки. Разные виды корпусов могут дать вам разницу в 1-3 °C, а разное расстояние между картами – разницу в 10-30 °C. В общем, если между вашими картами есть промежутки, с охлаждением проблем нет. Если промежутков нет, вам нужны правильные вентиляторы (выдувающий вентилятор) или другое решение (водяное охлаждение, расширители PCIe). В любом случае, вид корпуса и его вентиляторы значения не имеют.
Догонят ли AMD GPU + ROCm когда-нибудь NVIDIA GPU + CUDA?
Не в ближайшие пару лет. Проблем там три: тензорные ядра, ПО и сообщество.
Сами кристаллы GPU от AMD хорошие: отличное быстродействие на FP16, отличная пропускная способность памяти. Но отсутствие тензорных ядер или их эквивалента приводит к тому, что их быстродействие страдает по сравнению с GPU от NVIDIA. А без реализации тензорных ядер в железе GPU от AMD никогда не будут конкурентоспособными. По слухам, на 2020-й год запланирована какая-то карточка для датацентров с аналогом тензорных ядер, однако точных данных пока нет. Если у них будет только карта с эквивалентом тензорных ядер для серверов, это будет означать, что мало кто сможет позволить себе GPU от AMD, что даст NVIDIA конкурентное преимущество.
Допустим, AMD представит в будущем железо с чем-то вроде тензорных ядер. Тогда многие скажут: «Но программ-то, работающих с GPU от AMD, нет! Как мне их использовать?» Это, в основном, заблуждение. ПО для AMD, работающее с ROCm, уже неплохо развито, а поддержка в PyTorch прекрасно организована. И хотя я не видел много отчётов о работе AMD GPU + PyTorch, все функции ПО туда интегрированы. Судя по всему, можно выбрать любую сеть и запустить её на GPU от AMD. Поэтому в данной области AMD уже неплохо развита, и эта проблема практически решена.
Однако, решив проблемы с ПО и отсутствием тензорных ядер, AMD столкнётся ещё с одной: с отсутствием сообщества. Наткнувшись на проблему с GPU от NVIDIA, вы можете поискать решение в Google и найти его. Это вызывает доверие к GPU от NVIDIA. Появляется инфраструктура, облегчающая использование GPU от NVIDIA (любая платформа для ГО работает, любая научная задача поддерживается). Есть куча хаков и трюков, сильно облегчающих использование GPU от NVIDIA (к примеру, apex). Экспертов и программистов для GPU от NVIDIA можно найти под каждым кустом, а вот экспертов по AMD GPU я знаю гораздо меньше.
В плане сообщества, ситуация с AMD напоминает ситуацию Julia vs Python. У Julia большой потенциал, и многие справедливо укажут, что этот язык программирования лучше подходит для научных работ. Однако же Julia по сравнению с Python используют крайне редко. Просто сообщество любителей Python очень велико. Вокруг таких мощных пакетов, как Numpy, SciPy и Pandas, собирается куча народу. Эта ситуация напоминает ситуацию NVIDIA vs AMD.
Поэтому с большой вероятностью AMD не нагонит NVIDIA, пока не представит эквивалент тензорных ядер и крепкое сообщество, построенное вокруг ROCm. AMD всегда будет иметь свою долю рынка в особых подгруппах (майнинг криптовалют, дата-центры). Но в ГО NVIDIA, скорее всего, ещё года два будет удерживать монополию.
Когда лучше использовать облачные сервисы, а когда – специальный компьютер с GPU?
Простое правило: если вы рассчитываете заниматься ГО дольше года, дешевле купить компьютер с GPU. Иначе лучше пользоваться облачными сервисами – если только у вас нет обширного опыта по облачному программированию, и вы хотите воспользоваться преимуществами масштабирования количества GPU по желанию.
Точный переломный момент, в который облачные GPU становятся дороже, чем собственный компьютер, сильно зависит от используемых сервисов. Это лучше подсчитывать самому. Ниже привожу примерный расчёт для сервера AWS V100 с одним V100, и сравниваю его со стоимостью настольного компьютера с одним RTX 3090, что близко по быстродействию. Компьютер с RTX 3090 стоит $2200 (2-GPU barebone + RTX 3090). Если вы в США, то прибавьте к этому $0,12 за кВт*ч за электричество. Сравним это с $2,14 в час за сервер в AWS.
При 15% утилизации в год компьютер использует
(350 Вт (GPU) + 100 Вт (CPU))*0.15 (утилизация) * 24 часа * 365 дней = 591 кВт*ч в год.
591 кВт*ч в год дают дополнительные $71.
Переломный момент, когда компьютер и облако сравниваются в цене при 15% утилизации, наступает где-то на 300-й день ($2,311 против $2,270):
$2.14/ч * 0.15 (утилизация) * 24 часа * 300 дней = $2,311
Если вы рассчитываете, что ваши модели ГО будут работать более 300 дней, лучше купить компьютер, чем использовать AWS.
Похожие расчёты можно провести для любого облачного сервиса, чтобы принять решение о том, использовать свой компьютер или облако.
Распространённые цифры по утилизации вычислительных мощностей следующие:
- Компьютер кандидата наук: <15%;
- Кластер GPU на Slurm кандидата наук: > 35%;
- Корпоративный исследовательский кластер на Slurm: > 60%.
В целом, процент утилизации ниже в тех областях, где важнее размышлять о передовых идеях, чем разрабатывать практические решения. В некоторых областях процент утилизации меньше (исследования интерпретируемости), а в других – гораздо выше (машинный перевод, моделирования языка). В целом утилизацию личных машин обычно всегда переоценивают. Обычно большинство личных систем утилизированы на 5-10%. Поэтому я настоятельно рекомендую исследовательским группам и компаниям организовывать GPU-кластеры на Slurm вместо отдельных настольных компьютеров.
Советы для тех, кому лень читать
Лучшие GPU в общем: RTX 3080 и RTX 3090.
Каких GPU стоит избегать (вам как исследователю): карточек Tesla, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Хорошее соотношение быстродействия к цене, но дорогая: RTX 3080.
Хорошее соотношение быстродействия к цене, подешевле: RTX 3070, RTX 2060 Super.
У меня мало денег: Покупайте использованные карты. Иерархия: RTX 2070 ($400), RTX 2060 ($300), GTX 1070 ($220), GTX 1070 Ti ($230), GTX 1650 Super ($190), GTX 980 Ti (6GB $150).
У меня почти нет денег: многие стартапы рекламируют свои облачные услуги. Используйте бесплатные кредиты в облаках, меняйте их по кругу, пока не сможете купить GPU.
Я участвую в соревнованиях Kaggle: RTX 3070.
Я пытаюсь выиграть в конкурентной борьбе в области компьютерного зрения, предварительного обучения или машинного перевода: 4 штуки RTX 3090. Но подождите, пока специалисты не подтвердят наличие сборок с хорошим охлаждением и достаточным питанием.
Я изучаю обработку естественного языка: если вы не работаете с машинным переводом, моделированием языка или предварительным обучением, RTX 3080 будет достаточно.
Я начал заниматься ГО и серьёзно этим увлёкся: начните с RTX 3070. Если через 6-9 месяцев не надоест, продайте и купите четыре RTX 3080. В зависимости от того, что выберете дальше (стартап, Kaggle, исследования, прикладное ГО), года через три продайте свои GPU, и купите что-то более подходящее (RTX GPU следующего поколения).
Хочу попробовать ГО, но серьёзных намерений нет: RTX 2060 Super будет прекрасным выбором, однако, возможно, потребует замены БП. Если у вас на материнской плате есть слот PCIe x16, а БП выдаёт около 300 Вт, то прекрасным вариантом станет GTX 1050 Ti, поскольку не потребует иных вложений.
GPU кластер для параллельного моделирования объёмом менее 128 GPU: если вам разрешено покупать RTX для кластера: 66% 8x RTX 3080 и 33% 8x RTX 3090 (только при возможности хорошо охлаждать сборку). Если охлаждения не хватает, покупайте 33% RTX 6000 GPU или 8x Tesla A100. Если не можете покупать RTX GPU, я бы выбрал 8 узлов A100 Supermicro или 8 узлов RTX 6000.
GPU кластер для параллельного моделирования объёмом более 128 GPU: задумайтесь о машинах с 8-ю Tesla A100. Если вам нужно более 512 GPU, задумайтесь о системе DGX A100 SuperPOD.





rakhlin
Очень интересно. Оказывается, Тим изменил своё мнение насчёт 16 линий PCI на карту. Раньше он говорил, что это обязательно, и я одно время в это верил. Потом наши подсчёты показали, что такая шина никогда не будет загружена. Из требования 16 линий на карту вытекали очень жесткие ограничения на выбор процессора и материнской платы. Хорошо, что он разобрался сам и не вводит других в заблуждение.