
Если вы в общих чертах представляете себе, как работает компьютерное зрение, но жаждете деталей, то эта статья для вас.
Под катом — о том, как работают нейросети, какого рода алгоритмы используются в системах компьютерного зрения и насколько улучшилось качество распознавания за последние годы. А также о сферах применения: от медицины и геологии до транспорта, строительства и безопасности.
В общем все то, что вы хотели знать, но боялись спросить, или не доходили руки погуглить.
Статья написана по мотивам выступления Евгения Бурнаева, кандидата физико-математических наук, доцента центра Сколтеха по научным и инженерным вычислительным технологиям для задач с большими массивами данных, в московской городской Точке кипения и нашей последующей беседы с ним.
Чтобы сократить уровень посредничества, просто передаем ему слово.
Привет! Я занимаюсь deep learning’ом — глубоким обучением нейросетей для компьютерного зрения и предиктивной аналитики. Наша научная группа включает 30 исследователей. Мы активно публикуемся в передовых журналах и много сотрудничаем с индустрией — Huawei, Airbus, Bosch, Louis Vuitton, Sahara Force India Formula 1 team.
При упоминании словосочетания «искусственный интеллект» все начинают вспоминать страшилки вроде Терминатора.
На самом деле искусственный интеллект — набор технологий на основе математики, аппаратного и программного обеспечения, который позволяет автоматизировать решение рутинных задач.
Ассоциация математического подхода с нейросетями возникла еще в 40-х годах прошлого века, когда Питтс и Мак-Каллок предложили простейшую математическую модель нейрона. Одновременно появился простой алгоритм обучения. В результате люди нафантазировали чуть ли не человекоподобных роботов. В реальности ни одну из этих фантазий так и не внедрили — не существовало технических возможностей. Так наступила, как это теперь называют, «первая зима искусственного интеллекта»: финансирование сократили, а интерес к вопросу снизился.
Следующий всплеск интереса произошел лишь в 90-х, когда появились вычислительные мощности и новые хорошие математические алгоритмы, которые позволяли решать задачи распознавания и прогнозирования. А в 2014 году технологии распознавания получили буквально третье рождение благодаря тому, что мы научились решать подобные задачи на порядок лучше, чем раньше. Но ассоциация с нейронами сохранилась по сей день.
Технологии шагнули довольно далеко. Но пока еще у систем распознавания есть много проблем. Требуется дорабатывать алгоритмы, чтобы повысить эффективность их работы. Здесь есть где развернуться не только инженеру, но и ученому.
Но начнем с того, как это работает.
Компьютерное зрение
Компьютерное зрение — это прикладная область, составная часть искусственного интеллекта.
В теории от компьютерного зрения мы ожидаем возможности имитировать способности человека по распознаванию объектов на фото — способности понимать, где текст, где лицо, а где здание.
Учитывая комбинацию распознаваемых элементов на фото, человек может сказать очень многое. Он видит, что небо голубое, флаги не трепещут на ветру, а значит, ветра нет и погода солнечная. Хотелось бы, чтобы системы компьютерного зрения это повторили.
Тест Тьюринга для систем компьютерного зрения — ответить на любой вопрос об изображении, ответ на который может дать человек.
Первые алгоритмы компьютерного зрения появились давно. Типичный пример — один из самых простых детекторов лиц Виолы — Джонса, который отмечает положение людей в кадре.
Работа алгоритма обнаружения лиц в фотокамерах
Этот алгоритм в некотором смысле необучаем (на обучаемости остановимся чуть позже). Ну а в данный момент мы наблюдаем бум алгоритмов, которые основаны на более сложных принципах.
Как устроены системы компьютерного зрения
Цифровое изображение — это матрица, где каждый пиксель — это некоторый элемент, содержащий число. В случае черно-белого изображения это число от 0 до 255, отражающее интенсивность серого.
Для цветного изображения это обычно комбинация трех цветов. Еще в позапрошлом веке первые цветные фотографии одновременно снимали на три камеры в разном цвете, а потом полученные кадры совмещали. И до сих пор цветные изображения часто раскладывают на те же три цвета — красный, зеленый и синий.
Поговорим о том, как работать с изображениями, чтобы они лучше воспринимались машиной.
Задача категоризации
Компьютерное зрение позволяет решать задачи распознавания. Фактически это базовая задача категоризации, когда мы устанавливаем для фотографии метки из заранее определенного множества категорий.
Эта задача бывает двух типов: бинарная (например, изображен ли на этой картинке человек) и более сложная (к каким типам относится планктон на картинке). Бывает, что одновременно с классификацией объекта мы должны отметить, где он находится.
Имитируем распознавание
Предположим, у нас есть картинка. Инженер подошел бы к распознаванию следующим образом: он начал бы проверять, что есть на этом изображении. Например, какие есть объекты, имеющие овальную форму. Для этого он выбрал бы какие-то признаки, которые на объектах овальной формы принимали бы большие значения.
Это искусственный пример, но здесь важно понять принцип. Когда мы посчитаем эти признаки, они поступят на вход классификатора. Если среди них есть те, что принимают большие значения, мы говорим, что на изображении есть определенные объекты и они находятся в такой-то части.
Типичный пример классификатора — то, что называется деревом решений. Самые простые деревья мы строим в обычной жизни:
Деревья решений такого типа можно строить и в более сложных случаях. Например, при выдаче кредита, но у них будет очень много узлов, где происходят ветвления.
На практике обычно комбинируют множество деревьев решений, то есть получают ответы с каждого, а потом проводят что-то типа голосования.
При распознавании фотографии (поиске ответа на вопрос, есть ли на фото люди) мы можем применить ровно такой же подход — считаем признаки и отправляем их в дерево решений, чтобы получить финальный ответ.
Признаки и их расчет
Какого типа признаки здесь можно было бы использовать?
На практике изображение делят на части и на каждой проводят локальный анализ. Например, оценивают направления, в которых градиенты изображения меняются сильнее всего, или считают среднее значение для пикселей, которые есть в этом изображении, или вычисляют контуры объектов на изображении.
Все это можно делать в том числе с применением известных фильтров — матриц коэффициентов, которые мы «прикладываем» к изображению, двигаясь по нему слева направо (сверху вниз), умножая коэффициенты в матрице, определяющей фильтр, на значения пикселей в соответствующем сегменте изображения и складывая результаты умножений. Если фильтр устроен определенным образом, на выходе можно получить новое изображение, в котором, например, выделены края:
Другой пример — фильтр, увеличивающий высокие частоты (резкость):
А если я возьму такую матрицу чисел, изображение, наоборот, будет размытым:
Классический подход состоит в том, что фильтры строятся вручную исходя из различных математических и инженерных соображений. Основываясь на своем опыте, для каждой задачи человек комбинирует группы фильтров, примерно представляя, что лучше всего подходит в этом случае. Но оказалось, что эти фильтры можно «научить».
Что это значит? Представьте, что в фильтрах стоят не готовые числа, а некие заранее неопределенные коэффициенты. Вы применяете эти фильтры к изображению, а потом объединяете этап построения результатов фильтрации и классификацию в единое целое. По сути, вы настраиваете коэффициенты фильтров для конкретной задачи по большой выборке данных так, чтобы качество решения задачи (например, распознавание) было максимальным.
Для настройки коэффициентов требуются: большая выборка данных, много слоев и специальное вычислительное оборудование. Поговорим о каждом из компонентов.
Большая выборка
Прорыв в этой области произошел в 2010 году, когда появился датасет ImageNet, который содержал 10 млн картинок. Чтобы его получить, проделали огромную работу: каждой из картинок вручную присвоили класс объекта, который там изображен.
На сегодняшний день это уже не единственная база размеченных картинок.
Наличие огромных баз данных, на которых можно обучать коэффициенты фильтров, дало старт развитию систем распознавания.
Многослойность
Предположим, у нас есть изображение. Есть первый слой с каким-то количеством фильтров. Применяя эти фильтры последовательно к изображению, мы получаем новую картинку. После этого применяем к изображению специальное нелинейное преобразование (в нейросетях оно называется Transfer Function — передаточная функция), затем — другие фильтры, а следом — новое нелинейное преобразование. И так далее. Каждый такой этап называется слоем.
В итоге получаем такую нелинейную фильтрацию, которая выделяет характерные признаки изображения. В конце этого процесса у нас будет набор коэффициентов. Для одних типов объектов они будут больше, для других — меньше. И эти признаки-коэффициенты подают на вход стандартного классификатора.
После создания первой системы, обученной на очень большой базе данных, оказалось, что точность распознавания возросла в несколько раз, в какой-то момент сравнилась с точностью человека и даже превысила ее. Нейросеть такого типа содержит 60 млн параметров — это те самые настраиваемые параметры фильтров.
Ниже на гистограмме показано, как со временем эволюционировала точность от 2010-го до 2015 года, а также отмечено количество слоев нейросети, которое необходимо, чтобы достичь такой точности.
Ошибка классификации 3–3,5%, и это лучше, чем у человека. Человек распознает с ошибкой 4–5%.
Говоря о точности, всегда стоит указывать, о какой задаче идет речь. Чем сильнее мы сужаем спектр применений, тем большей точности можем достигнуть.
Качество систем распознавания зависит не только от того, как построена нейросеть, но и от того, как она обучена. Если создатель модели выполнил свою работу некачественно, точность распознавания будет существенно ниже. Правда, это легко проверить. К примеру, можно использовать кросс-валидацию, когда часть обучающей выборки отделяют для проверки работы модели. Этот подход имитирует ситуацию с получением новых данных.
Аппаратное обеспечение
Чтобы подобрать огромное количество коэффициентов, нужно специальное оборудование, которое позволит распараллелить подобные задачи, поскольку обычный CPU решает их последовательно.
Несколько лет назад Nvidia заказала у создателей MythBusters забавный пиарный ролик для демонстрации параллельных вычислений
Речь идет о графических процессорах (GPU), которые изначально создавали для ресурсоемких игр. Их адаптировали под быстрое выполнение матричных вычислений. А нейросети, по сути, у нас и построены на матричных вычислениях, то есть умножениях одной таблицы чисел на другую.
Какие задачи мы можем решить?
Имитируя человека, мы можем на фотографии указать, где находится предмет, и отделить его от окружающих объектов.
Можем ответить на вопрос, какая у человека позиция относительно других тел, и даже спрогнозировать по двумерной фотографии положение частей тела человека в 3D.
Можем отыскать лицо человека.
Имея априорные знания о движении, можем по позе человека на фотографии предположить, в каком направлении он бежит, или спрогнозировать, куда он будет двигаться далее.
Где сейчас используют нейросети
Некоторые из задач, которые я перечислю, можно решать и другими способами. Не надо думать, что нейросети покрывают все. Просто на данный момент это один из наиболее популярных и достаточно эффективных методов решения задач такого типа. Возможно, лет через пять появятся другие, более эффективные в конкретных приложениях архитектуры, которые будут отличаться от «классических нейросетей».
А кроме того, есть большое количество инженерных задач, где старые методы, основанные на тех же дескрипторах, могут показывать лучшие результаты, чем нейросети, требующие большой обучающей выборки.
Поиск по картинкам
Все мы пользуемся стандартной функцией поиска объектов на фото в поисковиках вроде Яндекса и Google. На вход мы подаем фотографию. С помощью фильтров нейросеть считывает признаки, характеризующие семантический смысл фотографии (я говорил о них ранее). Далее они сравниваются с признаками фотографий, которые уже есть в интернете (те заранее были подсчитаны и сохранены в виде векторов чисел). Изображения со сходными признаками оказываются семантически близки.
Распознавание лиц
По такому же принципу устроено детектирование и идентификация лиц. Это приложение важно для обеспечения безопасности тех же банков.
Ниже — реальный пример из презентации одной из компаний. Как вы думаете, правда ли, что в каждом из пунктов на двух соседних фото один и тот же человек? Людям сложно это определить, поэтому возникают ошибки и процветает мошенничество.
Правильно обученные системы компьютерного зрения не ошибутся даже в сложных ситуациях и в условиях плохого освещения. Точность распознавания у них достигает 99%.
В западных странах подобные технологии уже активно используют для контроля доступа и рабочего времени.
Социальный протест
Использование нейросетей, связанное с распознаванием лиц, вызывает у обывателей опасения. Вот один из таких заголовков:
В заметке речь шла о том, что в Китае якобы установили в шлемы рабочих сенсор, фиксирующий, насколько человек погружен в работу и какие он испытывает эмоции. Забегая вперед, скажу, что в текущих условиях это невозможно. Но такие статьи появляются, их связывают с искусственным интеллектом, и это вызывает опасения.
Более реалистичное применение — камеры в учебном классе, которые оценивают, насколько студенты вовлечены в процесс. Так можно косвенно определить эффективность процесса обучения.
Говоря об опасениях, нельзя не вспомнить знаменитую серию публикаций о наличии в Китае системы соцрейтинга, которая мониторит людей и оценивает, насколько они подчиняются правилам.
Насчет китайского опыта существуют разные мнения. Лично я в Китае не жил и не могу описать ситуацию. Но на Западе внедрение подобных систем вызывает социальный протест. Например, некоторое время назад рабочие Amazon жаловались на жесткие рамки учета рабочего времени, прописанные в новой системе мониторинга.
На волне этих протестов некоторые компании и даже правоохранительные органы в городах Америки сворачивают или ограничивают функциональность систем, связанных с трекингом людей и распознаванием лиц. Так что в целом законы о приватности и защите персональных данных работают, то есть опасения относительно нейросетей реально снимать при помощи законодательства.
Модификация фотографий
С помощью подобных нейросетевых моделей можно манипулировать изображениями — к примеру, стилизовать фото.
Нейросетевые модели могут анимировать фотографию или картину, используя видео эмоций другого человека. Лицо с фотографии будет изменять выражение вслед за человеком на видео.
А эту анимацию делали коллеги из дружественной нам группы Сколтеха.
Подобные методы используют при создании фильмов и рекламы.
Физическая безопасность и обучение
Компьютерное зрение активно применяют для обеспечения безопасности, например, чтобы наблюдать за пустой квартирой или контролировать условия труда: ходят ли рабочие в безопасных зонах, носят ли каски.
Контроль соблюдения скоростного режима на дорогах также может осуществляться с помощью нейросетевых моделей.
Компьютерное зрение активно применяют в качестве элемента более сложных задач, например, в системах дополненной реальности. Хороший пример — обучение технического персонала навыкам работы в сложных условиях, когда нужна максимально четкая реакция (тренировки «автоматических» навыков). Физических установок, реалистично имитирующих окружение для отработки подобных действий, мало или у них нет необходимой функциональности. И отработка навыков в дополненной реальности позволяет решить эту задачу.
Строительство и городское планирование
На гигантских объектах трудно понять, действительно ли строительство идет по плану, поскольку даже нескольким людям сразу тяжело все обойти и оценить объем работ за неделю или месяц. Вместо ручной сверки можно снять видео с дрона, взять данные с лидара (лазерного дальномера, оценивающего расстояние от сканера до точек на поверхности объекта) и по ним уже автоматически оценить, что и где построили.
Компьютерное зрение используют для обработки данных дистанционного зондирования (аэрофотосъемки или съемки со спутника). Типичный пример — когда на вход подают огромные снимки, полученные со спутника в разные моменты времени, допустим в конце лета и осенью, чтобы оценить, какие произошли изменения.
Так можно выявить незаконные свалки и понять, насколько быстро они растут, или зафиксировать последствия стихийных бедствий: ураганов, пожаров, землетрясений. Сравнив снимки до и после, можно приблизительно оценить количество пострадавших домов и подсчитать потери страховой компании.
Аналогичные задачи есть в сфере городского планирования, а также в оценке населенности и объемов строительства. На картах не всегда есть информация о том, жилой ли это дом, сколько у него этажей, сколько в нем проживает людей. Но эта информация необходима, чтобы спланировать, например, размещение сетевого магазина. Нужно понять, какие рядом с этим зданием проходят людские потоки. И эту оценку можно выполнить по данным дистанционного зондирования.
Выяснить тип дома можно по крыше — производственная ли это площадка, жилой дом или офисное здание. Высоту и этажность рассчитывают по тени, которую дом отбрасывает и по данным о том, в какой момент времени сделали фотографию. Так оценивают, сколько в среднем там может жить людей. Для большей части территорий с типичной плотностью населения оценки неплохо совпадают с реальностью. Эти данные важны для компаний, которые занимаются застройкой и развитием торговых сетей.

Другой пример — сканирование инфраструктурных объектов. Есть множество производственных помещений, чертежей которых не сохранилось. Однако при планировании ремонта или расширения без них не обойтись. Такую задачу можно решить автоматизированно — обработав данные сканирования лидаром. Причем это можно делать как изнутри здания, так и снаружи. По этим данным можно воссоздать полную цифровую модель здания, с которой можно делать все что угодно, в том числе планировать ремонт и изменения.
Геология
В нефтегазовой индустрии есть задача оценки, насколько легко нефть проходит через породу и, следовательно, можно ли ее существующими промышленными методами извлечь так, чтобы это было рентабельно. Задача решается через бурение. Для этого делают пробные скважины, из которых достают образцы породы (керн). По томограммам этого керна можно восстановить цифровую модель породы и понять, где в ней находятся поры, а где твердое вещество.
От того, насколько эта порода пористая и как через нее распространяется вязкая жидкость, зависит, насколько трудно будет извлечь нефть.
Медицина
В медицине существует большое количество задач, связанных с обработкой снимков, на которые врач тратит довольно много времени. Например, по снимкам сердца и предсердия надо вычислить их объем. Или по данным сканирования глазного дна понять, есть ли там какие-то изменения, связанные с диабетом.
Если врач будет выполнять такого рода работу вручную, она займет много времени. Самое главное, что могут возникнуть ошибки, связанные с тем, что человек, допустим, устал. Чтобы этого избежать, нейросеть выполняет роль советчика. Подобное программное обеспечение уже одобрено минздравами многих стран. Это уже значительный рынок, где методы компьютерного зрения позволяют ускорить работу и сделать анализы более точными.
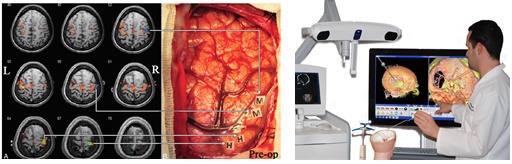

Выше изображен проект, который мы делаем с коллегами из Национального медицинского исследовательского центра нейрохирургии имени академика Н. Н. Бурденко. Это так называемое предоперационное картирование, в рамках которого необходимо понять, что речевой и моторный центры в мозге человека не пересекаются с опухолью (чтобы при удалении опухоли их не травмировать).
В обычных условиях человека будят во время операции и электрическим щупом фактически замыкают контакты на мозговой коре, проверяя, что при этом он внятно говорит, может двигать рукой и так далее. От этой процедуры нельзя отказаться, но хочется минимизировать время, которое тратится на такого рода манипуляции. Для этого делают fMRI-скан (фактически последовательность трехмерных фотографий мозга, каждая из которых показывает, в какой части была активность). Обработка этих сканов позволяет достаточно точно определить, где находятся речевой и моторный центры. Так хирург может заранее спланировать, как лучше удалять опухоль.
Ритейл
Я думаю, многие слышали о магазине Amazon Go. Продавцов там нет. Человек заходит, берет товар. За счет автоматического распознавания товара можно рассчитать стоимость покупки. По выходе из магазина с человека списывают деньги.
Схожая система есть для мерчандайзеров — она оценивает выкладку. Человек берет смартфон, проводит им по полкам и оценивает, где находятся упаковки, сколько их и какого типа, достаточно ли товара.
Эти приложения активно развиваются не только на Западе, но и в России. Первый магазин без продавцов уже протестировали в Москве.
Автономный транспорт
Типичная задача в этой сфере — спрогнозировать положение объектов в трехмерном пространстве по изображениям с камер. Расчет координат центра, угла поворота — все эти задачи успешно решаются с применением нейросетей.
Кроме того, автомобиль, сняв видео окружающей обстановки, может ответить, бывал ли он в этом месте, запечетленном на видео, ранее во время предыдущих поездок. Так можно реализовать визуальную навигацию роботизированных систем, помогающую автономному транспорту ориентироваться в пространстве по ситуации.
Расширение задачи
Вначале мы определяли компьютерное зрение как возможность ответить на любой вопрос об изображении. Но чем сильнее мы хотим имитировать возможности человека, тем больше нам потребуется разных нейросетей, обученных на большом количестве изображений разных объектов. И в этом мы ощущаем свои пределы. Например, в ImageNet содержится порядка 10 тысяч классов объектов.
Мы можем соединить несколько нейросетей, заточенных под конкретные вопросы, это в какой-то степени уже реализуется в некоторых инженерных системах. Но полностью повторить человеческое описание картинки мы пока не можем.
Ошибки и обман систем распознавания
Создание систем распознавания с использованием современного аппарата нейросетей — это решаемая инженерная задача. В базовом варианте она не требует серьезной науки. Но в целом научной работы предстоит очень много, потому что эти системы все еще несовершенны.
Во-первых, их относительно легко можно обмануть. Как пример, ниже приведены фотографии человека с гримом на лице. В определенных ситуациях этот грим может запутать систему распознавания лиц.
Это связано с тем, что системы обучают на выборках большого размера, где присутствуют снимки людей с разной освещенностью, в очках и без них, но фото с таким гримом в этой выборке нет. Поэтому система распознает его как нечто инородное, не относящееся к человеку.
И если обмана или ошибки надо избежать, то рано или поздно разработчики проанализируют ситуацию и поставят соответствующую защиту.
Во-вторых, нейросети такого типа подвержены взлому. Вот один известный пример: к изображению добавляют шум с маленькой амплитудой. Для человека картинка почти не меняется, а нейросеть перестает его распознавать.
Взлом нейросети. Пример смешивания изображений, в результате которого сверточная нейросеть выдает ошибочный результат (источник: spectrum.ieee.org)
Аналогичные вещи можно делать и с физическими объектами, например, добавить посторонние элементы к знакам дорожного движения.
Даже небольшие «помехи» сбивают с толку алгоритм распознавания (подробности: spectrum.ieee.org)
Система распознает знак неправильно или не распознает его в принципе. Такие же проблемы есть с распознаванием других модальностей, например речи.
Но постепенно ситуация улучшается. Вспомним хотя бы систему разблокировки смартфонов по лицу. Первые реализации были ненадежными: чтобы обмануть систему, достаточно было использовать распечатанную фотографию. Теперь же необходимо создать объемный макет.
Как я говорил выше, точность повышают, расширяя набор обучающих данных и повышая число рассчитываемых признаков.
Мысли про сохранность рабочих мест
Отдельная тема — это разговоры про сохранность рабочих мест. Не останутся ли люди без работы после внедрения всех этих технологий? Я полагаю, что проблема не столь катастрофична. Нейросети сокращают одни рабочие места и создают другие — связанные с поддержкой и обучением этих систем. Вдобавок они открывают новые рынки, где тоже будет нужна разработка и обслуживание.
dmtrka
Можно несколько примеров где результаты какой-либо «разумной» (т.е той для которой нет строго детерминированного алгоритма) работы с изображениями без использования нейросетей дает лучший результат чем с использованием? Насколько мне известно уже даже поиск углов и границ на нейросетях делают.