
В этой статье я, по традиции, попробую собрать основную информацию по управлению памятью в iOS (Преимущественно в swift). По этой теме куча клевой инфы, поэтому материал вышел объемный из переводов (мб где-то кривых) и заимствований. Но для объяснений на пальцах основных моментов он получился нормальным
Структура
Управление памятью в современных языках программирования
Value Refence type
MRC
ARC
Weak, Strong, Unowned
Swift Object Lifecycle
Autoreleasepool

Управление памятью в современных языках программирования
Управление памятью — является важной даже в современных технологиях. Неправильное использование может привести к долгой загрузке, крашам приложения или даже операционной системы.
Для чего используется оперативная память?
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
загружать свой собственный байт-код для выполнения;
хранить значения переменных и структуры данных, которые используются в процессе работы;
загружать внешние модули, которые необходимы программе для выполнения задач.
Помимо места, используемого для загрузки своего собственного байт-кода, программа использует при работе две области в оперативной памяти — стек (stack) и кучу (heap).
Стек
Stack — Переменные, выделенные в стеке, хранятся непосредственно в памяти, и доступ к этой памяти очень быстрый, и ее выделение определяется при компиляции программы.
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.
Стек позволяет очень быстро выполнять операции с данными — все манипуляции производятся с «верхней книгой в стопке». Книга добавляется в самый верх, если нужно сохранить данные, либо берётся сверху, если данные требуется прочитать;
Существует ограничение в том, что данные, которые предполагается хранить в стеке, обязаны быть конечными и статичными — их размер должен быть известен ещё на этапе компиляции;
Каждый поток многопоточного приложения имеет доступ к своему собственному стеку;
Когда функция вызывается, все локальные экземпляры этой функции будут помещены в текущий стек. И как только функция вернется, все экземпляры будут удалены из стека.
Если размер вашего value type может быть определен во время компиляции или если ваш value type не содержит рекурсию на себя или не находится в ссылочном типе, тогда потребуется выделение стека.
Куча
Куча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
Операции на куче производятся несколько медленнее, чем на стеке, так как требуют дополнительного этапа для поиска данных;
В куче хранятся данные динамических размеров, например, список, в который можно добавлять произвольное количество элементов;
Куча общая для всех потоков приложения;
Вследствие динамической природы, куча нетривиальна в управлении и с ней возникает большинство всех проблем и ошибок, связанных с памятью. Способы решения этих проблем предоставляются языками программирования;
Подходы в управлением памяти
Ручное управление памятью
Сборщик мусора
Сборщик мусора на основе алгоритма пометок
Сборщик мусора с подсчётом ссылок
Автоматический подсчёт ссылок (ARC)
Ручное управление памятью
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборщик мусора
Сборка мусора — это процесс автоматического управления памятью в куче, который заключается в поиске неиспользующихся участков памяти, которые ранее были заняты под нужды программы. Это один из наиболее популярных вариантов механизма для управления памятью в современных языках программирования. Подпрограмма сборки мусора обычно запускается в заранее определённые интервалы времени и бывает, что её запуск совпадает с ресурсозатратными процессами, в результате чего происходит задержка в работе приложения. JVM (Java/Scala/Groovy/Kotlin), JavaScript, Python, C#, Golang, OCaml и Ruby — вот примеры популярных языков, в которых используется сборщик мусора.
Сборщик мусора на основе алгоритма пометок (Mark & Sweep)
Это алгоритм, работа которого происходит в две фазы: первым делом он помечает объекты в памяти, на которые имеются ссылки, а затем освобождает память от объектов, которые пометки не получили. Этот подход используется, например, в JVM, C#, Ruby, JavaScript и Golang. В JVM существует на выбор несколько разных алгоритмов сборки мусора, а JavaScript-движки, такие как V8, используют алгоритм пометок в дополнение к подсчёту ссылок. Такой сборщик мусора можно подключить в C и C++ в виде внешней библиотеки.

Сборщик мусора с подсчётом ссылок
Для каждого объекта в куче ведётся счётчик ссылок на него — если счётчик достигает нуля, то память высвобождается. Данный алгоритм в чистом виде не способен корректно обрабатывать циклические ссылки объекта на самого себя. Сборщик мусора с подсчётом ссылок, вместе с дополнительными ухищрениями для выявления и обработки циклических ссылок, используется, например, в PHP, Perl и Python. Этот алгоритм сборки мусора так же может быть использован и в C++
Автоматический подсчёт ссылок (ARC)
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift.
Концепция Ownership
Что такое это ваше право собственности?
В любом языке с концепцией разрушения есть понятие собственности. В некоторых языках, таких как C и Objective-C, не относящиеся к ARC, владение явно контролируется программистами. В других языках, таких как C ++ (частично), владение управляется языком. Даже в языках с неявным управлением памятью все еще есть библиотеки с концепциями владения, потому что помимо памяти есть и другие программные ресурсы, и важно понимать, какой код отвечает за высвобождение этих ресурсов.
У Swift уже есть система владения, но она «под прикрытием»: это деталь реализации, на которую программисты не могут повлиять
О ней можно долго говорить, а лучше ознакомиться здесь, но вкратце основные идеи этой концепции:
Каждое значение в памяти должно иметь только одну переменную-владельца
Когда владелец уходит из области выполнения, память сразу же освобождается. (Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции).
Каждая часть кода несет ответственность за то, чтобы в конечном итоге вызвать уничтожение объекта
Окей, вроде с основными моментами разобрались. Давайте теперь перейдем к Swift. Начнем с базовых вещей
Value/Reference Types
Value и Reference Types — это основные концепции Swift. В Swift есть три способа объявления типа: классы, структуры и перечисления. Их можно разделить на типы значений (структуры и перечисления) и ссылочные типы (классы). То, как они хранятся в памяти, определяет разницу между ними:
Value Type — каждая переменная типа значения имеет свою собственную копию данных, и операции с одной не влияют на другую. За него отвечает стэк.
Reference Type — у нас есть ссылка, указывающая на это место в памяти. Переменные ссылочного типа могут указывать на одни и те же данные; следовательно, операции с одной переменной могут повлиять на данные, указанные другой переменной. За него отвечает куча.
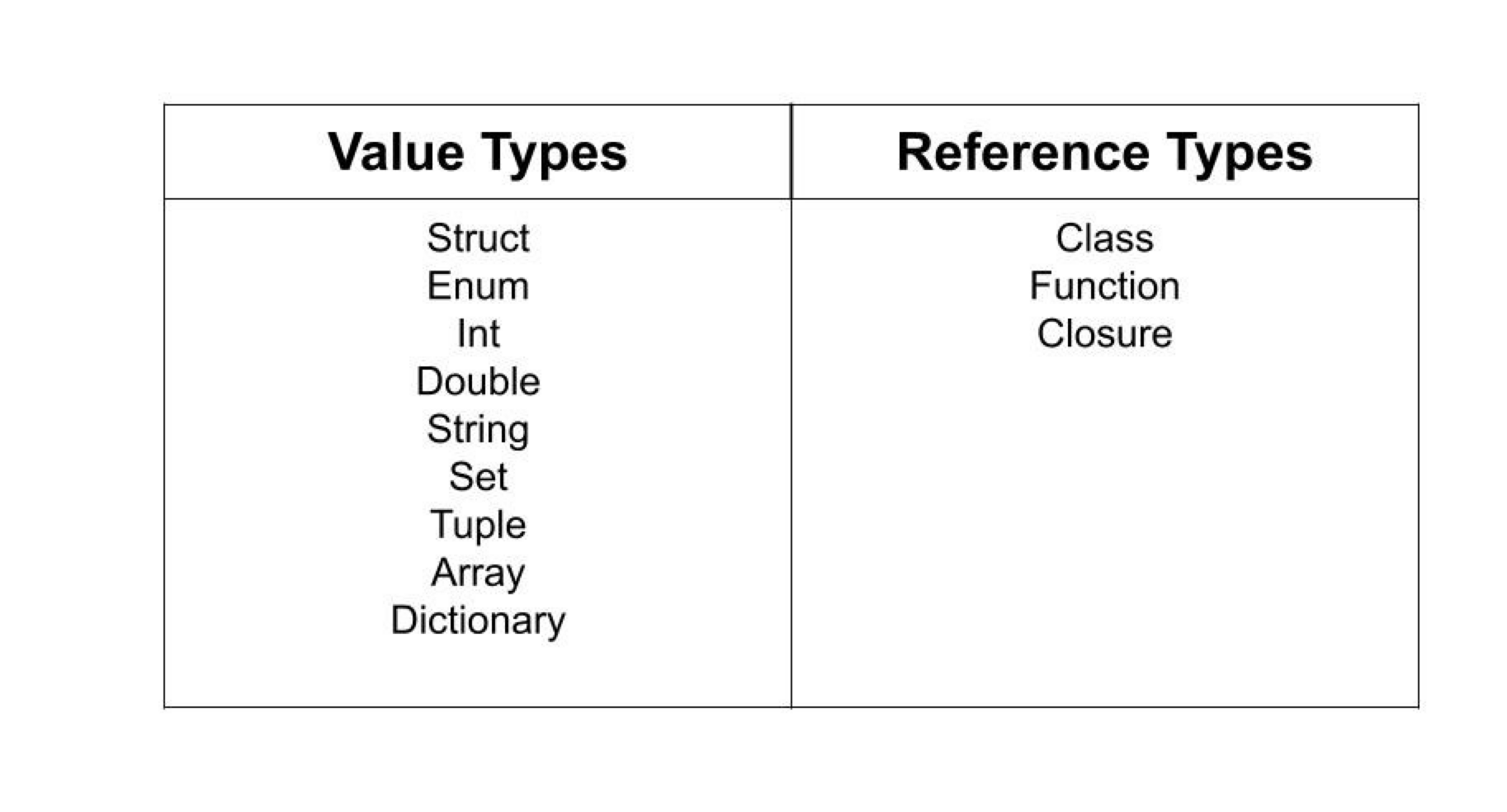
Основные замеры по которым делается сравнение структур и классов это:
стоимость копирования
стоимость allocation и deallocation
стоимость подсчета ссылок
Что такое память?
Память - это просто длинный список байтов. Байты расположены упорядоченно, каждый байт имеет свой адрес. Диапазон дискретных адресов известен как адресное пространство.
Адресное пространство приложения iOS логически состоит из четырех сегментов: текста, данных, стека и кучи.
Текстовый сегмент содержит машинные инструкции, которые образуют исполняемый код приложения. Он создается компилятором путем перевода кода Swift в машинный код. Этот сегмент доступен только для чтения и занимает постоянное место.
Сегмент данных хранит статические переменные Swift, константы и метаданные типов. Сюда попадают все глобальные данные, которым требуется начальное значение при запуске программы.
В стеке хранятся временные данные: параметры метода и локальные переменные. Каждый раз, когда мы вызываем метод, в стеке выделяется новая часть памяти. Эта память освобождается при выходе из метода. За некоторыми исключениями сюда попадают все типы значений Swift.
В куче хранятся объекты, у которых есть время жизни. Это все ссылочные типы Swift и некоторые случаи типов значений. Куча и стопка растут навстречу друг другу.

Затраты на выделение и освобождение памяти в куче намного больше, чем на выделение памяти в стэке (https://developer.apple.com/videos/play/wwdc2018/416/)
Хотя типы значений и ссылки обычно выделяются в стеке и куче соответственно, есть исключения из этих правил.
Назначение в Stack ссылочных типов
Компилятор Swift может продвигать ссылочные типы для размещения в стеке, когда их размер фиксирован или время жизни может быть предсказано. Эта оптимизация происходит на этапе генерации SIL.
Swift Intermediate Language (SIL) - это промежуточный язык высокого уровня, ориентированный на Swift, подходящий для дальнейшего анализа и оптимизации кода Swift.
Компилятор Swift может упаковывать типы значений и размещать их в куче:
При соблюдении протокола. Помимо затрат на выделение ресурсов, возникают дополнительные накладные расходы, когда тип значения хранится в экзистенциальном контейнере и превышает длину 3 машинных слов.
Экзистенциальный контейнер - это общий контейнер для значения неизвестного типа среды выполнения. Value Types небольших размеров могут быть встроены в экзистенциальный контейнер. Более крупные размещаются в куче, и ссылка на них хранится в экзистенциальном буфере контейнера. Время жизни таких значений управляется Value Witness Table. Это вводит накладные расходы на подсчет ссылок и несколько уровней косвенного обращения при вызове методов протоколаПри смешивании value и reference типов. Обычно ссылка на класс хранится в структуре, а структура является полем класса:
// Class inside a struct
class A {}
struct B {
let a = A()
}
// Struct inside a class
struct C {}
class D {
let c = C()
}3. Generic с value типом
struct Bas<T> {
var x: T
init(xx: T) {
x = xx
}
}4.Escaping closure captures.
В сlosure все локальные переменные фиксируются по ссылке. Некоторые из них все еще могут быть переведены в стек, как описано в CapturePromotion.
SIL указывает, что определение функции закрывается над символической ячейкой памяти. Эта инструкция является переменной.
5.Inout аргумент
Аргументы @inout передаются в точку входа по адресу. Вызываемый объект не получает права собственности на указанную память. Указанная память должна быть инициализирована при входе в функцию и выходе из нее. Если аргумент @inout относится к хрупкой физической переменной (Unowned Unsafe), то аргументом является адрес этой переменной. Если аргумент @inout относится к логическому свойству, тогда аргумент является адресом буфера обратной записи, принадлежащего вызывающей стороне.
func inout(_ x: inout Int) {
x = 1
}Цена копирования
Как говорили выше, большинство value types размещаются в стеке, и их копирование занимает постоянное время. На скорость влияет то, что примитивные типы, такие как целые числа и числа с плавающей запятой, хранятся в регистрах ЦП, и при их копировании нет необходимости обращаться к оперативной памяти. Большинство расширяемых типов Swift, таких как строки, массивы, наборы и словари, копируются при записи (copy-on-write). Это означает, что копирование происходит только в момент мутации.
Поскольку ссылочные типы не хранят свои данные напрямую, мы несем затраты на подсчет ссылок только при их копировании.
Все становится интересно, когда мы смешиваем значения и ссылочные типы. Если структуры или перечисления содержат ссылки, они будут платить накладные расходы на подсчет ссылок пропорционально количеству ссылок, которые они содержат
В iOS есть 2 вида подсчета ссылок:
Manual Reference Counter
Automatic reference counter (ARC)
Давайте разберем каждый по отдельности
Manual Reference Counter
MRC - это ручное управление ссылками через код. В самом начале и в доисторические времена разработчики сами управляли подсчетом ссылок через команды. Было это, мягко говоря, жестко:
alloc - создание объекта (создаем ссылку)
retain - обращение к нему (+1 к ссылке)
release - уменьшаем счетчик ссылок (-1)
dealloc - если счетчик ссылок равен 0 = выгрузка из памяти
По сути, вы выделяете объект, сохраняете его в какой-то момент, а затем отправляете один release для каждого отправленного вами alloc/retain. Метод dealloc вызывается для объекта, когда он удаляется из памяти.
Но у такого подхода есть минусы, о которых мы говорили вначале:
Нужно постоянно считать retain, release
Крэш при обращении из выгруженного из памяти
Забыли поставить релиз - утечка памяти
Automatic Reference Counter
После того, как умные программисты поняли, что можно придумать механизм, который сам за программиста считает ссылки - мир в iOS поменял. Больше не нужно было считать ссылки и следить за ними. За нас это делает ARC автоматически. Он сам понимает куда и зачем что вставлять и когда удалять. Стоит понять, ЧТО ARC РАБОТАЕТ ПРИ КОМПИЛЯЦИИ, А ПОДСЧЕТ ССЫЛОК В РАНТАЙМЕ.
Что изменилось?
(release/retain - нельзя вызывать) dealloc - работает частично
У property появились модификаторы:
strong - аналог retain
weak - аналог assign. в проперти при освобождении ставится нил и не крэшит приложение при обращении
Но есть и минусы, с которыми не справляется ARC. О них мы тоже говорили выше и iOS эти проблемы никуда не ушли:
Retain cycle - это когда объем выделенного пространства в памяти не может быть освобожден из-за циклов сохранения. Поскольку Swift использует автоматический подсчет ссылок (ARC), цикл сохранения происходит, когда два или более объекта содержат сильные ссылки друг на друга. В результате эти объекты сохраняют друг друга в памяти, потому что их счетчик сохранения никогда не уменьшится до 0, что предотвратит вызов функции deinit и освобождение памяти
Deep Dive ARC
Swift Runtime представляет каждый динамически выделяемый объект со структурой HeapObject. Он содержит все части данных, которые составляют объект в Swift: количество ссылок и метаданные типов.
Внутри каждый объект Swift имеет три счетчика ссылок: по одному для каждого типа ссылки. На этапе генерации SIL компилятор swiftc вставляет вызовы методов swift_retain () и swift_release (), где это необходимо. Это делается путем перехвата инициализации и уничтожения HeapObjects.
Типы ссылок
Strong
Weak
Unowned
Цель сильной ссылки - сохранить объект в живых. Сильные ссылки могут привести к нескольким нетривиальным проблемам:
Retain cycles (о нем говорили выше)
Не всегда возможно сделать сильные ссылки действительными сразу при создании объекта, например с делегатами.
Weak решают проблему обратных ссылок. Объект может быть уничтожен, если на него указывают слабые ссылки. Слабая ссылка возвращает nil, когда объект, на который она указывает, больше не жив. Это называется обнулением.
Unowned ссылки имеют различную разновидность weak, рассчитанные на инварианты жесткой валидности. Необнуляемые ссылки не обнуляются. При попытке прочитать несуществующий объект по неизвестной ссылке программа выйдет из строя с ошибкой. Четкой причины их юзать до сих пор не знают и много спорят, но все выводы уходят в легкость дебагинга.
Side Tables
Side tables — это механизм для реализации слабых ссылок Swift.
Обычно объекты не имеют слабых ссылок, поэтому резервировать место для подсчета слабых ссылок в каждом объекте нецелесообразно. Эта информация хранится извне в дополнительных таблицах, поэтому ее можно выделить только тогда, когда это действительно необходимо.
Как только мы начинаем ссылаться на объект слабо (weak reference), то создается боковая таблица, и теперь объект вместо сильного счетчика ссылок хранит ссылку на боковую таблицу. Сама боковая таблица также имеет ссылку на объект.
Side Table — это просто счетчик ссылок + указатель на объект. Они объявлены в Swift Runtime следующим образом (код C ++)
class HeapObjectSideTableEntry {
std::atomic<HeapObject*> object;
SideTableRefCounts refCounts;
// Operations to increment and decrement reference counts
}Жизненный цикл объекта Swift

На Live состоянии объект жив. Его счетчики ссылок выставлены по 1. Если есть указатель на слабую ссылку, то создается side table
-
Когда strong RC достигает нуля, вызывается deinit(), и объект переходит в следующее состояние. Это состояние Deiniting. На данном этапе операции со strong ссылками не действуют. При чтении через unowned ссылку будет срабатывать assertion failure. Но новые unowned ссылки еще могут добавляться. Если есть боковая таблица, то weak операции будут возвращать nil. Далее из этого состояния уже можно перейти в два других.
Первое: если нет боковой таблицы (то есть нет weak ссылок) и нет unowned ссылок, то объект переходит в Dead состояние и сразу удаляется из памяти.
Второе: если у нас есть unowned или weak ссылки, объект переходит в состояние Deinited. В этом состоянии функция deinit() завершена. Сохранение и чтение сильных или слабых ссылок невозможно. Как и сохранение новых unowned ссылок. При попытке чтения unowned ссылки вызывается assertion failure. Из этого состояния также возможно два исхода.
В том случае, если нет слабых ссылок, объект переходит непосредственно в состояние Dead, которое было описано выше.
В случае наличия weak ссылок, а значит и боковой таблицы, осуществляется переход в состояние Freed (Освобожден). В Freed состоянии объект уже полностью освобожден и не занимает места в памяти, но его боковая таблица остается жива.
После того как счетчик слабых ссылок достигает нуля, боковая таблица также удаляется и освобождает память, и осуществляется переход в финальное состояние — Dead.
В мертвом состоянии от объекта ничего не осталось, кроме указателя на него. Указатель на HeapObject освобождается из кучи, не оставляя следов объекта в памяти.
Autoreleasepool
В эпоху Obj-C в iOS использование этого типа было важным для предотвращения утечек памяти вашего приложения в определенных случаях
Что такое @autoreleasepool?
В дни ручного управления памятью, до ARC для Obj-C, для управления потоком памяти в приложении iOS приходилось использовать функции keep () и release (). Поскольку управление памятью iOS работает на основе счетчика сохраненных объектов, пользователи могут использовать эти методы, чтобы сигнализировать, сколько раз на объект ссылаются, чтобы его можно было безопасно отключить, если это значение когда-либо достигнет нуля.
Вместо того, чтобы мгновенно уменьшить счетчик удержания объекта, autorelease () добавляет объект в пул объектов, которые необходимо освободить когда-нибудь в будущем, но не сейчас. По умолчанию пул освобождает эти объекты в конце RunLoop'a выполняемого потока, чего более чем достаточно, чтобы покрыть все случаи. Или почти все
Нужен ли @autoreleasepool в Swift ARC?
Ответ в зависимости от обстоятельств. Если наш проект содержит obj-c код, то да. В чистом swift проекте возможно это потребуется только в каких-то библиотеках, которые содержат obj-c код.
Summary
Слабые ссылки указывают на Поинт в side table. Unowned и Strong ссылки указывают на объект.
Автоматический подсчет ссылок реализован на уровне компилятора. Компилятор swiftc вставляет вызовы для освобождения и сохранения там, где это необходимо
Объекты Swift не уничтожаются сразу. Вместо этого они проходят 5 этапов своего жизненного цикла: live → deiniting → deinited → freed → dead.
Используемая литература
Отдельно хочется выделить статьи автора блога https://www.vadimbulavin.com:
https://www.vadimbulavin.com/swift-memory-management-arc-strong-weak-and-unowned/
https://www.vadimbulavin.com/value-types-and-reference-types-in-swift/
Отстальные:
https://www.raywenderlich.com/9481-reference-vs-value-types-in-swift
https://docs.swift.org/swift-book/LanguageGuide/AutomaticReferenceCounting.html#ID52
https://medium.com/flawless-app-stories/you-dont-always-need-weak-self-a778bec505ef
https://belkadan.com/blog/2020/08/Swift-Runtime-Heap-Objects/
https://medium.com/swift2go/autoreleasepool-uses-in-2019-swift-9e8fd7b1cd3f
https://dev.to/deepu105/demystifying-memory-management-in-modern-programming-languages-ddd
Также подписывайтесь на мой телеграм-канал, где я публикую интересные статьи из мира iOS https://t.me/iosmakemecry
Комментарии (10)

NZeee
29.11.2021 21:10Отличная статья, довольно подробно расписано. Я Android разработчик, но ознакомился для общего развития, как устроено у вас. Можно обновлять резюме :D

Florelit
29.11.2021 21:22+1«По умолчанию пул освобождает эти объекты в конце RunLoop'a выполняемого потока, чего более чем достаточно, чтобы покрыть все случаи.»
По умолчанию, пул не освобождает эти объекты в конце RunLoop'а, а уменьшает счётчик ссылкок на 1.t-nick
30.11.2021 13:20Функция "release" переводиться как "освободить", и уменьшает счетчик ссылок на 1. Так что формулировка вполне корректная.

sys_adm1n
29.11.2021 21:58Информативная статья, как и телеграм-канал. Спасибо, что предоставляете возможность погрузиться в iOS-разработку

Yoooriii
30.11.2021 02:17Познавательно. Не думал, что в iOS программа компилится в байт-код. Кстати, возвращаясь к данным в памяти, есть еще tagged pointers, объект объёмом до 8 байт может лежать в одном машинном слове.
stingray06
30.11.2021 06:16Пропущены слова в абзаце про СТЕК: Если размер вашего value type может быть определен во время компиляции или если ваш не содержит рекурсию на себя или не находится в ссылочном типе, тогда потребуется выделение стека.
Ваш не содержит рекурсию?
А так спасибо за статью.

yu_vl
30.11.2021 06:16Уже идет работа по move-only типам (в виде атрибутов для локальных переменных, аргументов функций и возвратов, полей классов), правда непонятно как это будет работать value типами у которых внутреннее хранилище реализовано с использованием класса и будет ли deinit у структур.

yomayo
01.12.2021 23:00+1С одной стороны, Вы пишите об управлении памятью в iOS и swift. С другой стороны, у Вас достаточно обязывающий заголовок: «Управление памятью в современных языках программирования». Поэтому можно окинуть критическим взглядом не только iOS и swift. И этот взгляд, упавший на swift показывает, что этот язык хоть и современный, но в некоторых вопросах (судя по Вашему описанию) он отнюдь не современен.
«Существует ограничение в том, что данные, которые предполагается хранить в стеке, обязаны быть конечными и статичными — их размер должен быть известен ещё на этапе компиляции»
В других языках это не всегда так. Тот же Си выходит за описанные Вами рамки двумя способами. Первый — с помощью функций с переменным количеством аргументов, которые, как известно, кладутся на стек перед вызовом функции. Хотя размер стекового кадра известен во время компиляции, но он не статичен, он меняется от вызова к вызову.
Второй способ — с помощью функции alloca, которая выделяет память не в куче, а в стеке. В этом случае размер стекового кадра не только не статичен, но ещё и неизвестен во время компиляции. Правда, пользоваться функцией не всегда удобно. Если, допустим, надо создать в стеке какой-то объект, то сперва надо вычислить его размер и только потом вызвать alloca. Такое преодоление пропасти в два прыжка мешает написать конструктор объекта, который бы сделал это всё сразу.
Проблему решает модель памяти не с одним, а двумя стеками. В ней цепочка подпрограмм использует стеки по очереди: чётные подпрограммы используют чётный стек, а нечётные — нечётный стек. Тогда конструктор, работающий в одном стеке, может создать объект вычисляемой длины в другом стеке. Такие манипуляции возможны потому, что локальные данные конструктора находятся в своём стеке и они не будут перекрываться создаваемым в другом стеке объектом. Подробнее можно посмотреть здесь.
Есть ещё одна интересный вопрос — а как удлинить массив в стеке? На первый взгляд проблема нерешаема: массив в архитектуре x86 растёт в сторону старших адресов, а стек — наоборот, в сторону младших адресов. Тогда надо «перевернуть» массив, чтобы он рос в обратном направлении! По факту элемент массива с индексом [n] станет на самом деле элементом с индексом [-n]. Этот массив может расти при условии, что он находится на вершине стека и за ним ничего нет. Если наращиванием массива будет заниматься какая-то вызываемая функция, то возникнет угроза перекрытия растущего массива и локальных данных этой функции. Так что для аккуратного программирования тут лучше опять использовать модель памяти с двумя стеками. Подробности — здесь. Ещё надо заметить, что массив — не единственный агрегатный тип данных, который может расти в стеке. Расти, наверное, могут многие, если не все — при условии правильного исполнения. Массив же выбран в качестве примера по причине его простоты.
Всё вышеперечисленное подчиняется дисциплине LIFO: буква «L» в этой аббревиатуре означает «Last», «последний». То есть и резервирование памяти с помощью alloca, и создание нового объекта конструктором в двухстековой модели, и удлинение массива — всё это делается в памяти, лежащей ниже последнего («Last») элемента стека.
И последнее: пока что мне не знакомы языки, в которых есть двухстековая модель памяти или удлинение массива на вершине стека. Надеюсь, мои замечания добавили недостающие штрихи к портрету всем известного стека.

ulkoart
Спасибо за статью - ????