
Если объединить структурный поиск по коду через gogrep и фильтрацию результатов через perf-heatmap, то мы получим profile-guided поиск по коду.
Данная комбинация позволяет находить все совпадения по шаблону поиска, а затем показывает только те результаты, что лежат на "горячем" пути исполнения.
Через perf-heatmap также можно аннотировать файл с учётом того, насколько строка исходного кода "горячая".
Введение
Зачем вообще может потребоваться поиск кода с информацией из профилей исполнения, когда у нас уже есть утилиты типа pprof (тем более он доступен через go tool pprof)?
Через профили можно находить разные потенциально узкие места. Например, можно посмотреть топ по функциям. Но некоторые вещи трудно локализовать и агрегировать.
Как бы вы находили append() вызовы в профиле, если они почти всегда раскрываются компилятором в разный код (причём чаще всего там больше одного вызова)? При этом часть из функций, которые встраиваются вместо append(), не являются для него эксклюзивными, поэтому недостаточно просто просуммировать growslice() и остальные релевантные функции. Можно, конечно, фильтровать по дереву вызовов, но вы рано или поздно упрётесь в то, что не любой фрагмент кода можно агрегировать как вам хочется.
Иногда бывают и другие задачи. Например, вы хотите найти все вызовы функции fmt.Errorf, которые имеют только один аргумент. То есть что-то вроде fmt.Errorf("error occured"). Как раз, чтобы понять, есть ли смысл заменять эти вызовы на какой-нибудь errors.New().
Комбинация gogrep+heatmap позволяют делать как раз это: найти какие-то паттерны в коде, которые встречаются на горячих путях исполнения.
Но сначала нам нужно собрать CPU профиль для нашей программы.
Подготавливаем CPU профиль
Есть несколько наиболее популярных способов собрать профиль исполнения:
- Запустить бенчмарки с параметром
-cpuprofile - Запустить профилировку на старте программы, записать результат в конце исполнения
- Динамическое включение и выключение профилирования на лету через ручку
- На части машин (или на стейдже) всегда держать профилирование включенным
Для анализа сервисов или долго работающих программ лучше всего подходят 3 и 4. Они предоставляют более-менее реалистичные данные. Для некоторых CLI утилит подходит 2-ой вариант.
Собирать CPU-профили на бенчмарках можно, но вы получите очень своеобразные результаты. Написать идеальные бенчмарки невозможно, поэтому почти всегда они будут указывать на то место, которое будет "перегреваться" бенчмарком, то есть данными, которые вы будете использовать для бенчмарк-функции. А ещё нужно быть особо осторожным при их сборе, если вы делаете это на персональном компьютере.
Для простоты воспроизведения, мы будем собирать профили на основе бенчмарков из стандартной библиотеки Go.
# В текущей директории будет создан файл cpu.out,
# над ним мы и будем экспериментировать.
# Внимание! Эта команда займёт несколько минут.
go test -cpuprofile cpu.out -bench . -timeout 20m -count 2 bytesGo экспортирует профили в формате profile.proto. Парсить эти файлы из Go можно пакетом github.com/google/pprof/profile.
perf-heatmap
Пакет perf-heatmap позволяет создать особый индекс на основе CPU-профиля в формате profile.proto.
Вместе с библиотекой в комплекте идёт утилита командной строки, которая имеет две основные операции:
-
perf-heatmap json cpu.outраспечатать heatmap индекс в JSON формате -
perf-heatmap stat cpu.outраспечатать heatmap индекс для данного профиля
Если у вас установлен Go, поставить эту утилиту можно следующей командой:
go install github.com/quasilyte/perf-heatmap/cmd/perf-heatmap@latestВсе семплы, что есть в cpu.out, уже указывают на строки кода, которые точно исполнялись хотя бы раз, так что мёртвый код туда не входит. Параметр -threshold указывает какой процент семплов из топа мы берём. Например, -threshold=0.5 означает, что мы берём top50% всех результатов, -threshold=1.0 разметит все семплы, а -threshold=0.1 возьмёт только самые горячие 10%.
Далее строки, попавшие в topN% диапазон будут распределены на равномерные 5 категорий: от менее горячей к самой пылающей.
Все размеченные семплы (topN%) считаются горячими, разница лишь в их рейтинге (heat level от 1 до 5 включительно). Каждая строка имеет два уровня: локальный (по файлу) и глобальный (по всей программе). Чаще всего нас интересует именно глобальный уровень. Локальный уровень полезен при просмотре файла в редакторе, чтобы просто оценить какие куски кода более горячие относительно остальных в этом же файле.
$ perf-heatmap stat -filename buffer.go cpu.out
func bytes.(Buffer).Write ($GOROOT/src/bytes/buffer.go):
line 168: 0.34s L=0 G=3
line 170: 0.56s L=4 G=3
line 172: 0.44s L=0 G=3
line 174: 3.97s L=5 G=5
func bytes.(Buffer).Grow ($GOROOT/src/bytes/buffer.go):
line 161: 0.11s L=5 G=1
func bytes.(Buffer).Read ($GOROOT/src/bytes/buffer.go):
line 298: 0.05s L=0 G=0
line 299: 0.25s L=4 G=2
line 307: 3.34s L=5 G=5
line 308: 0.06s L=0 G=1
line 309: 0.18s L=3 G=2
line 310: 0.14s L=0 G=2
func bytes.(Buffer).grow ($GOROOT/src/bytes/buffer.go):
line 117: 0.04s L=0 G=0
line 118: 0.01s L=0 G=0
line 120: 0.04s L=2 G=0
line 128: 0.01s L=0 G=0
line 132: 0.01s L=0 G=0
line 137: 0.19s L=5 G=2
line 142: 0.16s L=4 G=2
line 143: 0.05s L=3 G=0
line 148: 0.01s L=0 G=0
func bytes.(Buffer).tryGrowByReslice ($GOROOT/src/bytes/buffer.go):
line 107: 1.26s L=5 G=4
line 108: 0.27s L=0 G=2
func bytes.makeSlice ($GOROOT/src/bytes/buffer.go):
line 229: 0.16s L=5 G=2
func bytes.(Buffer).empty ($GOROOT/src/bytes/buffer.go):
line 69: 0.25s L=5 G=2
func bytes.(Buffer).WriteByte ($GOROOT/src/bytes/buffer.go):
line 263: 0.66s L=0 G=4
line 265: 0.88s L=4 G=4
line 269: 1.11s L=5 G=4
line 270: 0.86s L=0 G=4
func bytes.(Buffer).readSlice ($GOROOT/src/bytes/buffer.go):
line 418: 0.05s L=0 G=0
line 419: 0.97s L=5 G=4
line 420: 0.01s L=0 G=0
func bytes.(Buffer).Len ($GOROOT/src/bytes/buffer.go):
line 73: 0.01s L=5 G=0
func bytes.(Buffer).ReadString ($GOROOT/src/bytes/buffer.go):
line 438: 1.03s L=0 G=4
line 439: 3.30s L=5 G=5
func bytes.(Buffer).WriteRune ($GOROOT/src/bytes/buffer.go):
line 277: 0.25s L=0 G=2
line 283: 0.22s L=0 G=2
line 284: 0.36s L=3 G=3
line 288: 2.51s L=5 G=4
line 289: 0.54s L=4 G=3
line 290: 0.17s L=0 G=2
func bytes.(Buffer).String ($GOROOT/src/bytes/buffer.go):
line 65: 0.04s L=5 G=0-
L— локальный уровень -
G— глобальный уровень
heat levels на примере
Допустим, у нас есть следующий набор семплов:
| file | line | value |
|---|---|---|
a.go |
10 |
100 |
a.go |
10 |
200 |
a.go |
13 |
200 |
b.go |
40 |
100 |
b.go |
40 |
300 |
b.go |
40 |
400 |
b.go |
49 |
100 |
b.go |
49 |
100 |
b.go |
50 |
500 |
b.go |
51 |
100 |
Первый шаг — просуммировать все value для каждой строки. В настоящий CPU профилях value может хранить время в наносекундах. В нашем примере это абстрактные величины.
| file | line | total value |
|---|---|---|
a.go |
10 |
300 |
a.go |
13 |
200 |
b.go |
40 |
800 |
b.go |
49 |
200 |
b.go |
50 |
500 |
b.go |
51 |
100 |
Для того, чтобы расставить global heat level, нужно отсортировать все значения по убыванию и взять первые N, которые попадают под threshold. Допустим, threshold=0.5, тогда мы берём первые 3 записи.
| file | line | total value |
|---|---|---|
+b.go+ |
+40+ |
+800+ |
+b.go+ |
+50+ |
+500+ |
+a.go+ |
+10+ |
+300+ |
a.go |
13 |
200 |
b.go |
49 |
200 |
b.go |
51 |
100 |
Если мы возьмём threshold=0.9, то в результат попадут уже 5 записей: 800, 500, 300, 200, 200.
Когда мы будем строить категории global уровня, то они будут распределены очевидным образом:
| file | line | total value | global heat level |
|---|---|---|---|
b.go |
40 |
800 |
5 |
b.go |
50 |
500 |
4 |
a.go |
10 |
300 |
3 |
a.go |
13 |
200 |
2 |
b.go |
49 |
200 |
1 |
b.go |
51 |
100 |
0 |
Для локальных уровней мы берём срезы внутри файла вместо всех семплов сразу.
gogrep + heatmap
Установим gogrep:
go install github.com/quasilyte/gogrep/cmd/gogrep@latestВыполним поиск по пакету bytes:
# Перейдём в директорию, где лежат исходные коды пакета bytes
cd $(go env GOROOT)/src/bytes
# Запустим поиск append() вызовов, которые лежат в горячих путях
# исполнения (фильтруя по нашему профилю, собранному на бенчмарках)
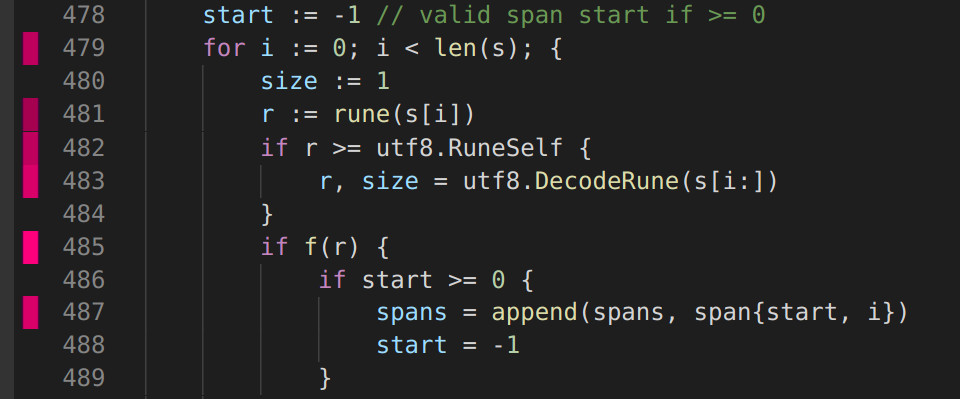
gogrep -heatmap cpu.out . 'append($*_)' '$$.IsHot()'
bytes.go:487: spans = append(spans, span{start, i})
bytes.go:500: spans = append(spans, span{start, len(s)})
bytes.go:626: return append([]byte(""), s...)
bytes.go:656: return append([]byte(""), s...)
bytes.go:702: b = append(b, byte(c))
bytes.go:710: b = append(b, replacement...)
bytes.go:715: b = append(b, s[i:i+wid]...)
found 7 matchesВозможно, вы не знакомы с идиомами gogrep и ruleguard, поэтому вот разъяснения:
-
$*_означает от 0 до N произвольных выражений -
$$— это особая переменная, которая означает "корневой матч", как$0в регулярках
По умолчанию gogrep использует threshold=0.5. Это значение можно переопределить через параметр heatmap-threshold.
gogrep -heatmap cpu.out -heatmap-threshold 0.1 . 'append($*_)' '$$.IsHot()'
bytes.go:487: spans = append(spans, span{start, i})
bytes.go:500: spans = append(spans, span{start, len(s)})
bytes.go:626: return append([]byte(""), s...)
bytes.go:656: return append([]byte(""), s...)
found 4 matchesПоиск всех fmt.Errorf() от одного аргумента может выглядеть как-то так:
gogrep -heatmap cpu.out . 'fmt.Errorf($format)' '$format.IsHot()'Здесь я намеренно использовал именованную gogrep переменную $format, а потом применил фильтр IsHot() именно к ней. В данном случае это почти одно и то же, как и $$.IsHot().
Более подробно язык шаблонов gogrep описан в статье gogrep: структурный поиск и замена Go кода.
Скринкаст с использованием gogrep в формате asciinema.
Как heatmap интегрирован в gogrep
Будем считать, что <var>.IsHot() это предикат типа func isHot(var gogrepVar) bool.
gogrepVar захватывает некоторое AST дерево, которое совпало с шаблоном. В случае $$ это дерево целиком, для именованных переменных типа $x это подвыражение или какой-нибудь statement. На практике gogrepVar — это захваченный ast.Node объект плюс имя переменной шаблона.
isHot(v) получает диапазон строк [fromLine, toLine] через ast.Node. Далее выполняется Index.QueryLineRange(..., fromLine, toLine). Если хотя бы для одной из строк в диапазоне найдётся семпл, прошедший threshold, isHot(v) вернёт true.
На данным момент нельзя найти горячий код по диапазону, который шире одной функции. Замыкания (анонимные функции) считаются отдельными функциями.
Плагин VS Code
perf-heatmap on marketplace.visualstudio.com
Чтобы не требовать от пользователей плагина установки утилиты perf-heatmap, я использовал gopherjs для конвертации Go-кода в JS, который поставляется вместе с VS Code расширением.
Как использовать расширение:
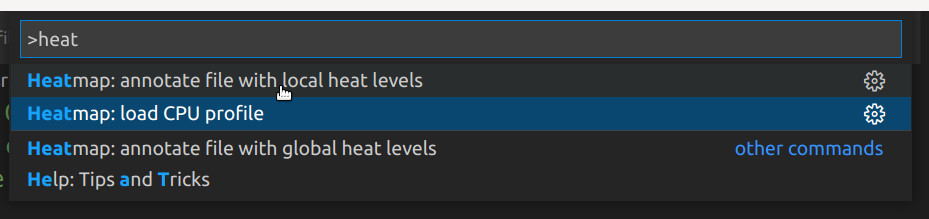
- CPU профиль нужно преобразовать в heatmap индекс и оставить его в памяти. Это можно сделать командой
perf-heatmap.loadProfile - Когда индекс доступен, можно разметить файл локальным или глобальным рейтингом heat level'ов. Делается это командами
perf-heatmap.annotateLocalLevelsиperf-heatmap.annotateGlobalLevels
Найти эти команды можно через ctrl+shift+p (workbench.action.showCommands).
Создание плагина не было основной задачей. Это лишь способ наглядной демонстрации как ещё можно использовать perf-heatmap. Если вам понравилась идея, то можете помочь с улучшением расширения.
Маппинг символов из профиля
Перед тем, как мы перейдём к заключительной части, я хотел бы поделиться как именно heatmap сопоставляет символы при запросах.
В тривиальной ситуации, когда CPU профиль был собран на вашей машине, как и исполняющийся бинарник, то никаких проблем нет. Можно сопоставлять файла и строки кода хоть по абсолютным путям.
Становится сложнее, когда бинарник мог собираться на отдельном build агенте, а профиль собирался в неизвестном окружении. У вас локально путь может вести к модулю (go modules), а на build агенте сборка могла производиться с использованием вендоринга.
Проблема может частично решаться введением префикса проекта. Отрезая префикс от информации из профиля и сопоставляя с файлами на локальной системе (вычитая там префикс от корня проекта), мы можем получить работающий матчинг.
Автоматически этот префикс вычислять не очень просто. А если у нас только 1 семпл, то это вовсе не возможно, ведь на момент построения индекса у нас есть только информация из профиля. Было бы не очень красиво дополнять метаданные индекса по мере исполнения запросов. Нам пришлось бы добавлять синхронизацию на методы запросов (ведь они начинают менять состояние индекса, а он может разделяться между горутинами).
Чтобы избежать этих проблем, heatmap использует составной ключ/отпечаток, который достаточно уникально описывает место в коде, но не требует при этом совпадения полного пути файла.
type Key struct {
// TypeName is a receiver type name for methods.
// For functions it should be empty.
TypeName string
// FuncName is a Go function name.
// For methods, TypeName+FuncName compose a full method name.
FuncName string
// Filename is a base part of the full file path.
Filename string
// PkgName is the name of the package that defines this symbol.
PkgName string
}Допустим, наш ключ равен Key{"Buffer", "Write", "buffer.go", "bytes"}, тогда мы можем сделать следующие запросы к индексу:
QueryLine(key, 10) => HeatLevelQueryLineRange(key, 20, 40) => []HeatLevel
HeatLevel — это пара {LocalHeatLevel, GlobalHeatLevel}.
Если для указанных строк из файла нет семплов или они ниже порога threshold, значения рейтинга будут равны 0.
Заключительные слова

У меня нет готового универсального корпуса лучших шаблонов. Часть из performance диагностик реализована в go-critic (хотя он не использует CPU профили). gogrep+heatmap уникален именно как инструмент для поиска ваших собственных паттернов.
Это так же не заменяет тщательное изучение профилей из pprof и других инструментов.
gogrep+heatmap может расширить ваш арсенал. Эта связка пригодится вам когда остальных средств будет недостаточно.
Когда у меня нет хороших готовых формулировок, я пытаюсь найти какие-то примеры. Поэтому вот вам ещё один пример.
$ gogrep --heatmap cpu.out . \
'var $b bytes.Buffer; $*_; return $b.$m()' \
'$m.Text() == "String" && $m.IsHot()'Этим запросом находятся локализованные использования bytes.Buffer, где мы в конце возвращаем результат как строку. В этих случаях иногда может быть полезно заменить буфер на strings.Builder.
Вместо $b.String() я использовал переменную $m которую потом мы проверяем в фильтре, сопоставляя со String. Сделано это для того, чтобы у нас была дополнительная переменная для привязки IsHot().
Использование $$.IsHot() означало бы, что любой семпл из профиля на пути от var $b bytes.Buffer до return $b.String() сделал бы матч успешный. Использование $b.IsHot() было бы привязано к первой декларации, так как позиция матч переменной всегда связывается с первым совпадением.
Если мы будем смотреть в профиль, то можем найти там bytes.(*Buffer).String() и понять, что это горячая функция. Далее мы можем посмотреть стеки вызовов и найти пути, на которых мы проводим больше всего времени (pprof может даже графы построить прямо в браузере). Но что сделать довольно сложно — это соединить информацию из профиля с какими-то более сложными кейсами. В случае выше по шаблону поиска мы понимаем, что для этого случая есть вполне понятное решение — взять strings.Builder.
Кажется, пора бы уже закругляться, но нет. Вот ещё один пример:
$ gogrep --heatmap cpu.out . \
'return $*_, errors.New($x)' \
'$$.IsHot() && $x.IsStringLit()'В крупной кодовой базе могут быть сотни мест, где делается errors.New прямо из функции. Обычно это не горячее место. Но если вы подвергаетесь атаке или в вашем приложении довольно часто встречаются несовсем корректные входные данные, то сэкономить немного на этом можно. Как же понять, какие errors.New() вообще есть смысл переписывать? Проверить через профиль! При этом фильтры в примере выше так же отбрасывают случаи динамическо создаваемой ошибки, типа errors.New("foo: " + msg), где мы не сможем так легко заменить вызов конструктора на возврат единожды созданной ошибки от константной строки.
Из огромного количества вызовов errors.New() вы получите только 2-3 тех, что действительно стоит переписать.