
NLP-решение для 5Post – логистической компании X5 Retail Group
-
Постановка задачи
Чуть ли не каждый день мы слышим, что большие данные, машинное обучение и искусственный интеллект – это и есть четвёртая индустриальная революция. Научные журналы охотно пополняются новыми статьями, описывающими более эффективные методы нахождения значения в числах. Но между научными прорывами и широкой индустриальной адаптацией очень часто лежит пропасть. Эта пропасть – установление связи между красиво представленными на бумаге теоретическими моделями и их эффектом для каждодневных процессов бизнеса. Следовательно, научить красивую новую технологию машинного обучения приносить пользу бизнесу в ежедневных процессах - задача всегда непростая и интересная.
В этой статье мы опишем опыт внедрения нашей командой Accenture технологии машинного обучения в бизнес логистической компании 5Post по обработке обращений. Мы уделим внимание не только описанию сути проекта и специфике опробованных технологий, но и сделаем акцент на коммуникации с бизнесом, чтобы обеспечить максимальный эффект от проекта, и опишем его.
5Post – одна из крупнейших логистических компаний в России. У Компании возникла потребность увеличить скорость обработки клиентских обращений колл- центром и снизить при этом нагрузку на операторов. Поскольку все возможности горизонтального масштабирования (привлечь еще больше операторов) стали нецелесообразны, было предложено автоматизировать обработку обращений с помощью машинного обучения. Любой проект начинается с формирования глубокого понимания бизнес-модели компании клиента. Успешное ее понимание влечёт за собой:
Список бизнес-процессов, которые влияют на задачу или затрагиваются поставленной задачей, – появляется структура проекта.
Какие факторы помогут составить оценку решения задачи: оценка бизнес-эффекта.
-
Бизнес-модель
Бизнес 5Post выглядит следующим образом. Логистическая компания занимается доставкой посылок от продавца к покупателю. Три основных этапа визуально описаны в диаграмме внизу. Первое – это сбор товаров со складов партнёров (внутренних или международных). Второе – доставка посылки по логистической цепи, состоящей из распределяющих и сортировочных центров и складов. Последний этап – размещение посылок в постаматах, пунктах выдачи заказов или на кассах в магазинах-партнёрах.

Обзор всего проекта
-
На практике иногда могут случаться проблемы, с которыми клиенты обращаются в колл-центр компании. Каждое обращение сотрудники компании обрабатывают вручную. Такой подход требует от сотрудника колл-центра анализа, решения и изменения данных по обращению. Другими словами, нужно прочитать каждое обращение и проанализировать тип проблемы, что задействует большое количество человеческих ресурсов. Далее необходимо отправить ответ клиенту (часто это информация с данными о заказе), либо второй популярный случай – изменить данные заказа по просьбе клиента.
Недостатки этого подхода:
Ручная обработка поступающих обращений и увеличенный срок предоставления ответа.
Возможность ошибки классификации, разрозненность в разметке похожих обращений.
Высокая загруженность сотрудников.
Разрозненность процессов обработки обращений из разных каналов.
Наше выработанное решение – обучить нейронную сеть, которая способна по тексту обращения автоматически распознавать заранее ранжированные по классам проблемы, извлекать сущность (номер заказа и телефон клиента) и по определённым классам сделать автоматизацию решения. К примеру, автоматически выслать клиенту сведения о статусе его посылки, или автоматически оповещать команду розыска, если поступила жалоба на утерю посылки, или переадресовать посылку, если это возможно.
Для простых и распространенных случаев участия оператора вообще не требуется, и большинство подобных и популярных обращений решается автоматически. Время операторов фокусируется на сложных обращениях, требующих детального, комплексного решения.
Важно отметить, что хоть в этой статье мы акцентируем внимание на внедрении нейронных сетей в автоматизацию, успех проекта напрямую зависит от информационной архитектуры, окружающей модель. Чтобы обеспечить естественную интеграцию нашего решения с работой оператора, было также придумано фронтальное приложение и построено множество сопутствующих IT-сервисов.
Совокупное решение даёт операторам доступ к решениям модели, позволяет быстро редактировать ответы, и открывает возможность постоянного дообучения модели, о котором мы поговорим позже.
Для визуализации нашего решения внизу представлена верхнеуровневая диаграмма разработанного сервиса:

А как пример успешной работы сервиса вот типичный ответ (классы, представленные внизу, используются чисто в иллюстративных целях):

-
Описание бизнес-эффекта
На старте проекта мы оценили потенциальный денежный эффект от этого подхода. Самый простой способ – спрогнозировать, сколько часов работы сэкономит автоматизированное решение. Максимальный эффект автоматизации – 100% на обращение, когда мы автоматизируем весь процесс получения, обработки, поиска решения и ответа клиенту. В части обращений мы не можем автоматизировать весь процесс, а только его часть.
Для примера рассмотрим первую часть – получение и обработка обращения. С помощью модели мы можем автоматически определить тематику, заполнить клиентские данные, извлекая их из текста.
Эта часть может занимать до 30 секунд времени работы сотрудника. В среднем на обработку одного обращения уходит 9 минут, мы тем самым экономим 5-6% времени.
Остальные стадии более затратные по времени, и эффект более значительный. Максимально мы можем достигнуть 74% экономии временных затрат на обработку обращений.
-
Разработка Модели Классификации
В этой секции мы опишем наш подход к разработке модели классификации для данной задачи. Мы коснёмся не только некоторых технических особенностей с проблемами и решениями, но и опишем наш опыт и лучшие практики использования продвинутого анализа для поиска оптимальных бизнес-решений.
Итак, конечный результат мы уже видели: микросервис, который классифицирует обращения и извлекает определённую сущность. Осталось дело за малым – обучить модель, которая не хуже человека будет обрабатывать клиентские обращения в свободной форме. Верхнеуровнево процесс обучения модели был типичным. На вход различным архитектурам моделей машинного обучения мы подавали размеченные данные с клиентскими и партнёрскими обращениями. После итеративного процесса обучения и тюнинга гиперпараметров мы валидировали модели и выбирали лучшую. Но на практике успешная имплементация этого пайплайна оказалась гораздо сложнее.

Как уже было отмечено, для успешной реализации автоматического решения нужно два функционала: классификация обращения по определённым классам (с прописанной логикой решений) и извлечение сущности. Это две разные задачи, о которых мы поговорим в отдельности.
Модель Классификации
Данные
У нас было два источника данных – клиентские и партнёрские обращения. Источником клиентских данных был портал для клиентов, где они оставляли свои вопросы (онлайн и через емейл). Количество таких обращений составило 11 000 (после фильтрации по уникальным и неповторяющимся обращениям). Источником партнёрских обращений стали 60 000 емейлов партнёров, которые мы также уменьшили до 20 000 путём фильтрации и удаления истории переписок при помощи регулярных выражений. Все эти обращения требовали разметки, где человек вручную соотносил обращение к одному из девяти первоначальных классов, которые представил бизнес.
Человеку, не знакомому с NLP (Natural Language Processing), покажется, что самый сложный этап этого проекта – алгоритм обработки данных или архитектура какой-то сложной модели машинного обучения. Ведь как представить смысл человеческой речи компьютеру? На самом деле уже существуют продвинутые и проверенные методы ее обработки, использующие нейронные сети, с распознаванием смысла и контекста – BERT (Bidirectional Encoder Representations from Transformers). Мы ожидали сложности с настройкой и дообучением моделей, а в реальности самым узким местом этого проекта была неопределённость классов и качество разметки. Как гласит известная поговорка в машинном обучении: “Garbage in – garbage out” (или “мусор на вход – мусор на выход”). На протяжении всего проекта мы сталкивались с проблемой конфликтной разметки, которая напрямую негативно влияла на качество модели, так как на вход были даны похожие по смыслу обращения с разной разметкой, что путало модель.
Архитектура модели
Перед тем как выбрать нейронные сети, мы протестировали несколько более стандартных архитектур, случайные леса и бустинг. Нейронные сети – не панацея, и их незачем использовать для задач, которые могут быть решены более простыми моделями, не требующими столь затратных ресурсов (тренировка одной модели на GPU (Graphics Processing Units) занимала 3 часа). Но в задачах по NLP ресурсозатратность себя оправдала. Мы использовали BERT (метод, основанный на трансформерах), который отлично учитывает контекст обрабатываемого обращения. Эта модель была обучена на огромном корпусе русскоязычного текста с двумя задачами – предсказать замаскированное слово в предложениях и предсказать, если одно из предложений следует по смыслу за вторым. Наша задача – дообучить эту языковую модель для нашего приложения (одна модель для классификации и одна – для извлечения сущности).

Погрузившись в данные и прочитав несколько сотен обращений, мы поняли, насколько важен контекст, когда обрабатываешь обращения в свободной форме. Изначально у нас была идея самим создать какие-то фичи, используя би- и триграммы или такие признаки обращения, как номер телефона. Но в большом количестве обращений использованы одни и те же комбинации слов, и только контекст смежных предложений меняет тип проблемы. Как пример:
Посылка утеряна. Пришлите документы, подтверждающие это. (Жалоба на утерю.)
Мне кажется, что моя посылка утеряна: уже неделю нет доставки. Пожалуйста, сообщите, когда она будет доставлена. (Статус: где моя посылка?)
Зона неопределённости по классам
В начале нашего проекта бизнес, ссылаясь на прежний опыт, представил девять классов обращений. После получения неудовлетворительных результатов по точности по первым моделям мы провели диагностику ошибок: начали читать обращения, по которым модель ошибалась (практика, к которой мы будем в дальнейшем многократно прибегать).

Причиной некачественной разметки была не только несогласованность разметчиков, а в основном обширная зона неопределённости по классам. Другими словами, изначально классы были плохо определены и неверно разбивали обращения, так как было много смысловых пересечений, а некоторые ярко выраженные темы вообще не имели отдельного класса (как вопросы с таможней). Сложность проблемы возросла, так как для успешного проекта важна не столько точность, сколько качество предлагаемого решения.
Тематическое моделирование
Чтобы определить, какие ещё есть потенциальные классы, мы повели так называемое тематическое моделирование, используя несколько подходов: начиная от пробалистических моделей (латентное распределение Дирихле, ARTM) и всё те же нейронные сети (BERT). На картинке внизу представлен результат этого моделирования, где мы спроецировали векторы с первого по девятый класс новых тем на двумерное пространство, изначальные темы (красные) и предложенные моделью (голубые).
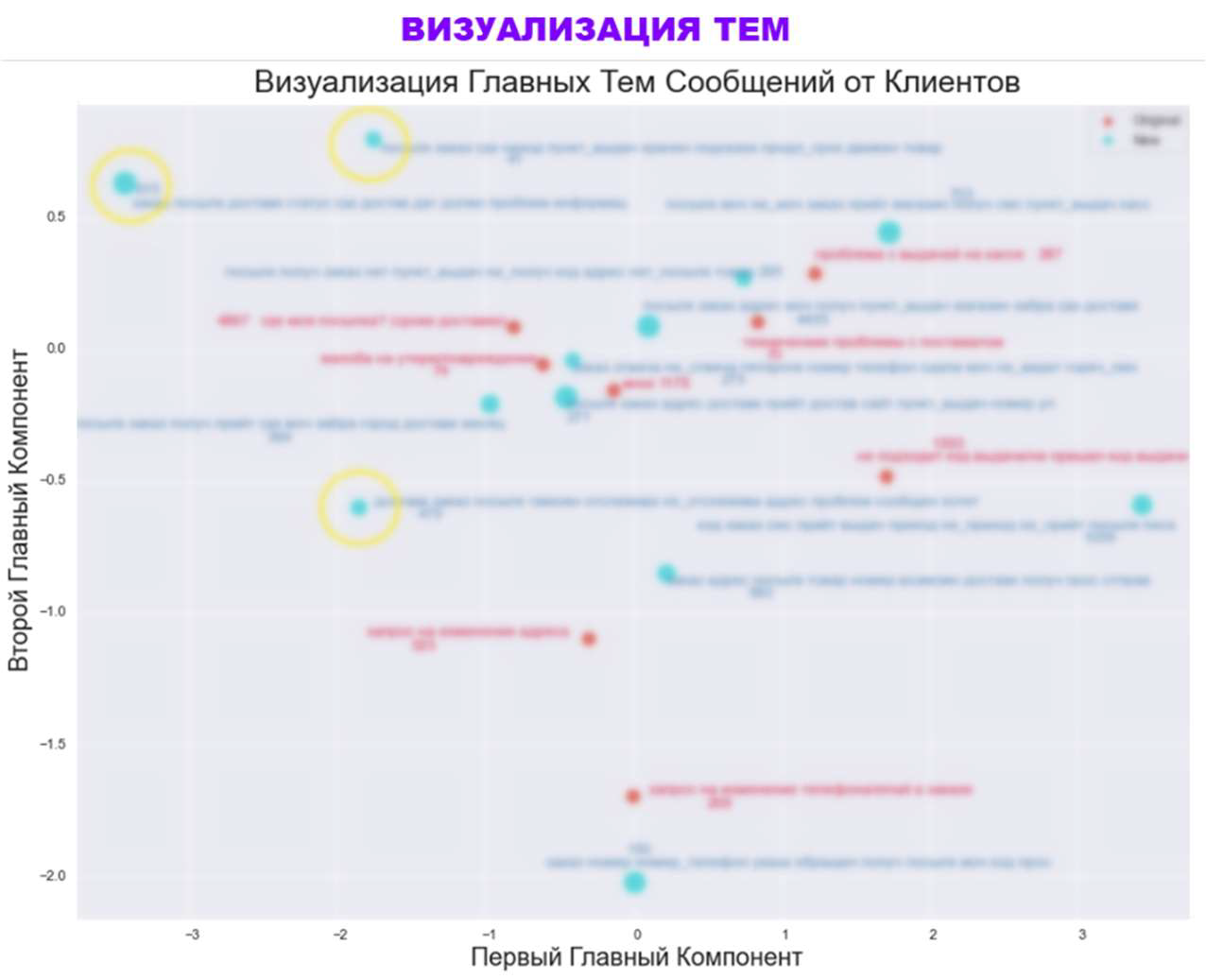
В области старых классов находятся новые – признак того, что модель смогла определить исходные классы (да, тут, конечно, надо отметить, что близость – это очень субъективно, особенно когда рассматриваешь её только в двумерном пространстве, и требуется считать близость в оригинальном n-мерном пространстве) и также определить новые темы (жёлтые), у которых есть свой кластер обращений.
Этот анализ подтвердил нашу гипотезу, что классов на самом деле больше девяти, и это привело к детальному обсуждению смысла классов и изучению, как можно разбивать обращения: по смыслу, по решениям, по бизнес-процессам и т. д. Каждый этап согласования требовал доразметки данных, которыми занимались только дата-саентисты, чтобы быть уверенными в согласованности и качестве данных. По окончании обучения модели классификации была произведена инструкция по разметке, чтобы в дальнейшем обеспечить качество данных, на которых будет производиться дообучение.
Обучение продуктовой модели
После нескольких этапов согласования классов (сначала их было девять, затем – 36) был утвержден 21 класс для модели (основным драйвером для определения классов стала логика решения по ним). Теперь нам нужно было использовать некоторые технические способы, чтобы сделать максимально высоким качество модели, которая на новых классах давала точность 72%. Первое, что мы заметили, что модель предвзято относится к нерепрезентативным классам. Это и понятно, когда смотришь на распределение обращений по классам:

В случае неуверенности модель предсказывает самый частый класс. Мы решили эту проблему путём апсемплинга, то есть увеличением редких классов, чтобы они чаще встречались на этапе обучения.
Второе, мы стандартно провели экстенсивный тюнинг гиперпараметров и изменили нашу метрику с точности на F1, чтобы ставить больше акцента на точность по каждому классу, так как общая точность предвзято относится к доминирующим классам. Изменение оптимизирующей метрики на F1 позволило алгоритму обучения дольше обучаться, так как почти на каждом этапе происходило улучшение по F1, когда метрика была точность, мы достигали плато гораздо быстрее. Результатом наших усилий стало то, что на продовской среде сейчас используется модель со следующей матрицей ошибок:

Модель Извлечения Сущностей
Изначально на этапе MVP (minimum viable product) мы применяли регулярные выражения для извлечения сущности. Регулярные выражения быстрые в имплементации – такой подход не нуждается в разметке или данных, этот метод извлечения не требует дополнительных ресурсов и хорошо работает для определения сущности с чёткими правилами. При этом в первый же день запуска мы начали получать обратную связь от пользователей, которые сообщали, что многие паттерны заказов не распознавались. Протестировав поведение модели на продовских данных, мы обнаружили, что точность извлечения была около 50%. Мы поняли, что хоть мы и охватывали около 80% обращений на момент написания правил, мы не могли учесть все возможные варианты нахождения номеров. Этот метод будет постоянно нуждаться в доработках и прописи дополнительных правил, так как нет чёткого формата номера заказа (может быть как обычный 5323415230, так и 12345/425-0, и ар-41415, и №АП236ОР43), также номера могут появляться в любой части обращения, то есть на каждую позицию требовалось доработка правил. И зачастую эти правила пересекались, выхватывая лишние символы и неправильные номера. Также проблема усложнялась тем, что в обращениях зачастую были не просто номера заказов и телефонов, но и посторонние цифровые символы: номера обращений или инцидентов, которые мы не хотели перепутать. А для полной автоматизации необходимо быть уверенными, что извлечены только правильные номера. Мы поняли, что даже извлечение сущности зависит от контекста, и решили использовать BERT.
Теперь мы дообучаем языковую модель BERT с другой задачей – извлечение сущности.

На вход необходимо представить размеченные данные с маркировкой BIO (beginning, intermediate, O – пустота). Мы производили разметку 800 обращений на DataTurcks:

Точность подхода BERT – 94% на этапе обучения, она валидирована на тестовых данных. Важным этапом стала наша кастомная постобработка или сборка извлечённой сущности. Так как модель предсказывает начало или середину той или иной сущности, мы написали скрипт, суть которого – отчистка результатов от очевидных промахов, таких как появление Intermediate Phone (I-PHONE) перед Beginning Phone (B-PHONE) и т.д. Это постобработка увеличила точность до 98%.
Дообучение модели (Continuous Learning)
На протяжении всего времени обучения модели мы осознавали, что эффективность и актуальность модели будет со временем снижаться. Клиентские формулировки, актуальность проблемных тематик и привлечение новых каналов связи – эти изменения в дальнейшем негативно повлияют на точность классификации.
После успешного апробирования модели мы приступили к разработке сервиса по ее дообучению. В иностранной литературе можно встретить термин Continuous Learning (CL), который объединяет различные методы использования новых данных для поддержания эффективности моделей. Методы CL были положены в основу пайплайна переобучения.
Для реализации дообучения мы создали базу данных, которая сохраняла обращения с продовской среды и класс, который подтвердил сотрудник колл-центра. Сейчас дообучение модели происходит по расписанию раз в две недели по схеме contender – champion. Мы обучаем новую модель на старых и обновленных данных и сравниваем прежнюю и новую модель на выборке из свежих данных, которую не видела ни одна из моделей на этапе обучения. Для обучения берём 100% старых данных плюс 70% свежих, сохраняя 30% для сравнения новой и старой модели.
Также мы разрабатываем функционал по автоматическому определению новых тем из обращений с неопределённым классом (Иное). Периодически все обращения этого класса будут проходить кластеризацию по смысловой схожести. Этот подход позволит нам улавливать новые массивные темы и адаптировать к меняющимся клиентским запросам.
Заключение
В этой статье мы поделились нашим опытом успешного интегрирования новейших технологий по обработке человеческой речи с оптимизацией бизнес-процессов. У таких проектов большая зона неопределённости и мало примеров практического внедрения, что несомненно делает опыт проектной работы увлекательным и непростым.
Противовесом зоне неопределённости, как бы банально это ни звучало, была открытость проектной команды идеям и вкладам коллег из смежных компетенций. Разрабатывающим специалистам было важно и полезно слышать пожелания бизнеса не только от бизнес-аналитиков, но и от тестировщиков, самих работников колл-центра и от заказчиков. Вся команда имела возможность напрямую делиться своими впечатлениями от продукта.
Редкость примеров практического применения является одной из причин создания этой статьи. Это хорошая практика делиться тем, что получается, и опытом применения недавно разработанных технологий.
Хотелось бы сказать и о планах развития. Помимо тематического моделирования и нахождения новых тем, мы активно работаем над автоматизированной обработкой клиентской обратной связи. Дайте знать в комментариях, если видели успешные примеры на рынке!
Автор: @nikita_ny
Блог X5 Retail Group тут
Комментарии (5)

gecube
19.01.2022 19:22очень интересно услышать от коллег из Х5 - почему привлекали внешнюю компанию, по каким критериям выбирали необходимость конкретного подрядчика, а не использовали внутреннюю компетенцию. Насколько мне известно, внутри Х5 достаточно много профессиональных MLщиков, которые умеют делать NLP-продукты
Несомненно, что возможно, что Accenture имеет какое-то готовое решение, которое внедряется в разные крупные компании. И оно отвечает набору каких-то критериев. Но тогда все равно возникает вопрос о полной стоимости владения этим решениям, а также возможности внесения в него доработок

X5RetailGroup
20.01.2022 13:14В Х5 действительно своя сильная команда ML, и она, в том числе, делает задачи 5POST.
В данном случае помимо модели, требовалась автоматизация связанных бизнес-процессов, которая была выполнена единой командой.
Так как важно было начать разработку как можно быстрее, то приняли решение привлечь технологического партнера.
Вся документация и исходный код остаются в Х5, поэтому вопрос стоимости владения остро не стоит.

Arrrrdelina
20.01.2022 15:16Вдохновляющая у вас получилась история! Приятно видеть, что компании внедряют ML в такие важные проекты, как служба доставки.
Кстати о компании, наслышана, что Accenture в целом предлагает клиентам очень классные IT-решения и стратегии развития.
EddyLan
"Автоматизация решений клиентских обращений"
Коллеги, вы уверены, что по-русски это так звучит?
Найдите выпускающего редактора, который знает русский язык.
Accenture_team Автор
и то верно) спасибо, поправим