
Данные в виде графа. Как их хранить? Как с ними работать?
Периодически возникают задачи и проекты, где данные имеют структуру графа. Например, данные о компьютерных сетях, где узлы связаны между собой. А на узлах зарегистрированы пользователи и они связаны или не связаны между собой. Еще пример — результат работы какого-то web crawler, который собирает данные из сети и хранит ссылки страниц между собой. Социальные сети. Список друзей, у которых тоже есть друзья — граф. Населенные пункты и дороги между ними — еще один пример графа.
Чтобы нам было удобнее давайте определимся с решаемой задачей. Допустим мы делаем систему администрирования некоторого сетевого ПО. Это ПО установлено на всех узлах сети. И из центра администрирования оно получает конфигурацию своей работы. Сети на практике большие, несколько администраторов одновременно могут включать и отключать связи между узлами. Либо напрямую, либо неявно через какие-то косвенные настройки. Наша задача обнаружить несвязанные сегменты в получившейся сети и не сохранить такую конфигурацию. Потому что плохая конфигурация приведет к неработоспособности.
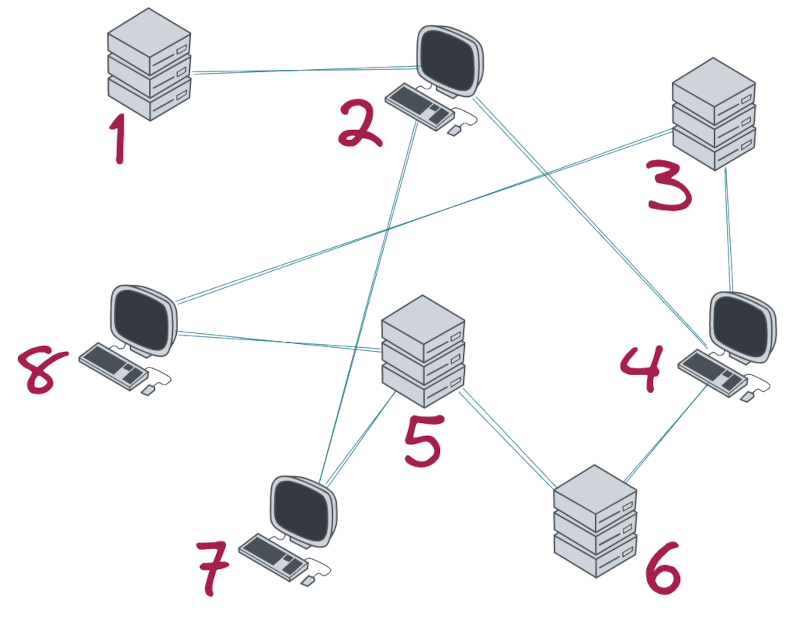
На схеме выше видно, что из любого узла сети есть как минимум один путь. Это хорошо.
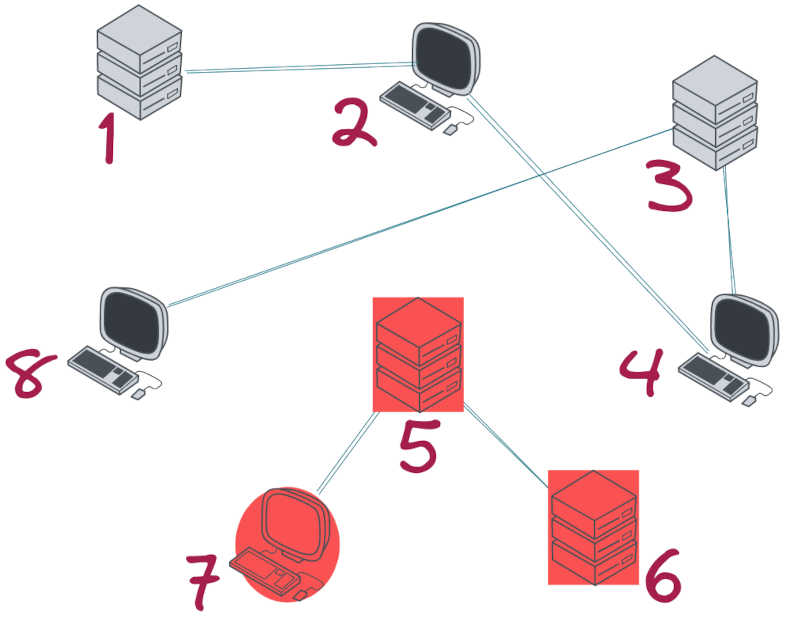
А вот на этой схеме дело плохо. Подсеть из узлов 7,5,6 — не доступна для другой части сети. И такую конфигурацию отправлять нельзя.
Когда мы познакомились с задачей давайте попробуем порассуждать о способе хранения информации о сети. Очевидный формат — это использование реляционного хранилища. В нем можно завести таблицу с описанием узлов сети (Идентификатор, Название узла, Время включения в сеть, Название операционной системы и т.п.). Но нам более интересно как хранить связи этих узлов. Можно создать таблицу со списком связей node_to_node (пример для рисунка выше):
node1_id |
node2_id |
additional_properties |
|---|---|---|
1 |
2 |
{latency: 102} |
2 |
4 |
{latency: 65} |
2 |
7 |
{latency: 81} |
3 |
4 |
{latency: 325} |
3 |
8 |
{latency: 12} |
4 |
6 |
{latency: 281} |
5 |
6 |
{latency: 347} |
5 |
7 |
{latency: 110} |
5 |
8 |
{latency: 54} |
Здесь все просто — идентификатор первого узла, идентификатор второго узла и какие-то свойства связи (скорость задержки от узла к узлу). Естественно оба столбца нужно проиндексировать. Идентификатор выберем типа int. Нужно определиться представляем ли мы связь одной записью или двумя. В случае если мы храним одну запись код проверки будет несколько сложнее:
select 1 from node_to_node where node1_id = 1 and node2_id = 2
union all
select 1 from node_to_node where node1_id = 2 and node2_id = 1Если же хранится и перевернутая запись — объем данных в два раза больше, но код проверки уменьшается:
select 1 from node_to_node where node1_id = 1 and node2_id = 2Еще можно внести условие, что записи хранятся в виде node1_id < node2_id. Но это только если у вас численные идентификаторы. Но стоит ли об этом задумываться? Выглядит как мелочь. И так и так можно…
Сюрприз
PostgreSQL эффективен в большинстве сценариев. Применительно к нашей задаче все сильно зависит от объема сети. Если у нас есть сеть из 65536 узлов и каждый из них связан с каждым мы получаем 4294967296 связей. Нам нужно 64Гб на то, чтобы сохранить все связи. Либо даже 128Гб для случая если мы храним еще и перевернутую запись (см. выше). Причем таблица связей будет в центре бизнес-логики. Время выполнения проверки имеет большое значение. Разница между 2 мс и 300 мс в конечном счете будет накапливаться и вы получите откровенно не работоспособные сценарии. Мало кто согласиться ждать 2 дня для проверки целостности сети.
Какие могут быть решения? Можно попробовать хранить связи как матрицу смежности. Где каждый бит обозначает наличие связи между узлами.

Тут вполне можно обойтись 512 Мб памяти и это будет быстрее. Но и тут проблемы. Код такого движка надо писать. При этом нужно учитывать возможность многопользовательского режима. Транзакционности и отказоустойчивости.
Вероятно сейчас уже появились такие решения. Несколько лет назад мне их найти не удалось. Напишите в комментариях что вы рекомендуете.
Существует целый класс графовых баз данных Graph Databases. Самая популярная из которых Neo4j. Но и тут решения проблем производительности нет. Зато есть очень выразительный язык запросов, который сильно упрощает их написание. Да и читабельность кода повышается.
Идея решения
Существует несколько алгоритмов сжатия графов. Применительно к нашей ситуации интерес представляет алгоритм выделения “виртуальных узлов”, которые заменяют собой “сгустки” связей.
Пусть у нас есть вот такая сеть:

Здесь мы видим, что есть два ряда узлов, где каждый из узлов ряда связан с узлами из другого ряда. Всего в такой сети 35 связей.
Если мы поставим между этими рядами некоторый привнесенный, вымышленный узел. То все узлы по прежнему будут связаны через него. Будем называть такие узлы виртуальными.
На рисунке ниже можно видеть результат. Общее число связей уменьшилось до 20. И плюс один узел “виртуальный узел”.
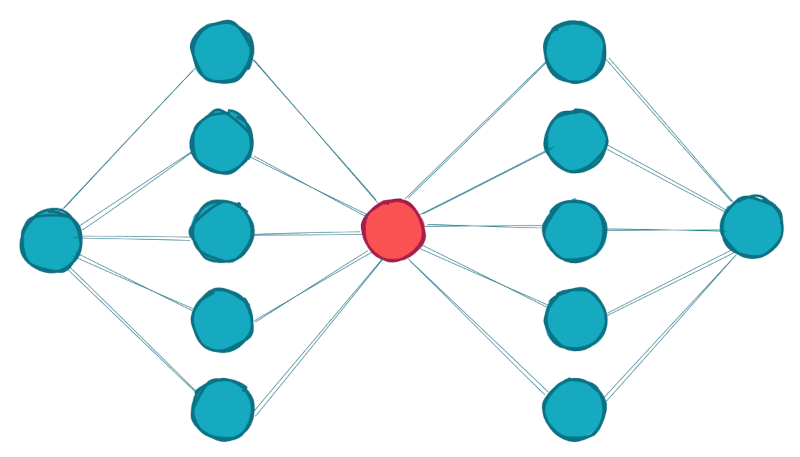
Понятно, что для сетей такой размерности нет никакого смысла экономить 15 связей из 35. Но чем больше в такой сети подобного рода “сгустков связей”, тем больше экономия. Для нашего экстремального случая из примера выше, где 65536 узлов связаны все со всеми, мы вместо 64Гб для хранения такой сети нужно всего лишь 1 Мб. Все операции будут “летать”. :)
Замеры производительности
Давайте посмотрим как будет меняться скорость для сжатых и не сжатых сетей. Для примера возьмем сеть из рисунка выше (с двумя рядами узлов). И будем искать кратчайший путь из начального узла в конечный. Для этого можно использовать следующий код:
WITH RECURSIVE search_graph(
node1,
node2,
depth,
path) AS (
SELECT
g.node1,
g.node2,
1 as depth,
ARRAY[g.node1] as path
FROM node_to_node AS g
WHERE node1 = 30 -- старт
UNION ALL
SELECT
g.node1,
g.node2,
sg.depth + 1 as depth,
path || g.node1 as path
FROM node_to_node AS g, search_graph AS sg
WHERE g.node1 = sg.node2
AND (g.node1 <> ALL(sg.path))
)
SELECT * FROM search_graphwhere node2 = 1003 -- финиш
limit 1;В случае с виртуальным узлом нужно добавить еще и проверку на признак виртуальности. И в алгоритме поиска воспринимать его как технический узел, который не удлиняет путь между узлами.
Узлов в первом ряду |
Узлов во втором ряду |
Общее число связей |
Связей после сжатия |
Время до сжатия |
Время после сжатия |
|---|---|---|---|---|---|
1000 |
1000 |
1002000 |
4000 |
300 мс |
50 мс |
100000 |
100000 |
10000020000 |
400000 |
16 мин |
55 мс |
Из таблицы видно насколько внушительно уменьшается число связей. По сжатому графу PostgreSQL работать в разы легче.
Но это все искусственный тест. Хотелось бы посмотреть что происходит с реальными данными. В сети полно открытых источников Laboratory for Web Algorithmics. Давайте возьмем наименьший датасет cnr-2000 (Italian Consiglio Nazionale delle Ricerche domain). В нем 3216152 связей. А в результате сжатия у меня вышло 1612981 связей и 100 виртуальных узлов. То есть ровно в два раза, точнее 1,9939 :). На скорости это сказалось аналогичным образом. Если на не сжатой сети мы получали время выполнения запроса 350 мс, то на сжатой он выполнялся уже за 150 мс.
Как реализовать такой алгоритм сжатия?
Мы убедились, что можно получить прирост скорости. Дело осталось за малым — реализовать такое сжатие. Сам алгоритм подробно описан в статье Gregory Buehrer, Kumar Chellapilla. A Scalable Pattern Mining Approach to Web Graph Compression with Communities. Она легко ищется в интернете.
Общая идея описывается в несколько предложений. Сначала мы разбиваем исходных граф на кластеры с похожим набором связей. Для каждого кластера строим суффиксное дерево со списком вершин-кандидатов для генерации виртуальных узлов. Считаем потенциальное сжатее для каждого из кандидатов и выбираем наилучший. И так продолжаем, пока кандидатов не останется. Не вижу надобности описывать сейчас этот алгоритм подробнее. Ссылку на статью привел выше. Но если будет потребность в этом — могу сделать в одной из следующих статей. Пишите в комментариях - нужно это или нет.
Выводы
Графы хоть и встречаются на проектах, но не очень часто. Чаще приходится иметь дело с обычной реляционной структурой данных. Но даже если у вас графовые данные. Вовсе не означает, что описанный выше способ вам подойдет. Нужно учитывать насколько статична структура данных, насколько в данных велика избыточность. Но вот если после всего этого анализа вы пришли к выводу, что это ваш случай. Можно получить ощутимый выигрыш в скорости и в объеме БД.
Комментарии (22)

Hashbash
06.02.2022 22:18+1Использую аналогичный подход, когда графы в постгресе. Только с 2-мя отличающимися нюансами, которые, возможно, вам будут полезны:
WHERE g.node1 = sg.node2 AND not (g.node1 = ANY(sg.path)) -- тоже самое, но останавливаемся на первом вхождении AND ((sg.depth = 1) or (sg.depth > 2 and sg.node1 > g.node1) ) -- исключаем логические повторы -- актуально если 30 2 3 1003 и 30 3 2 1003 - одно и тоже -- оставляем только одну последовательность (30 2 3 1003)

grebenyukov
07.02.2022 00:50Здравствуйте! Добавление виртуального графа создает аналог прямой связи между узлами одного и того же столбца. В оригинальном графе они связаны лишь через крайний узел и узлы соседнего столбца. Разве не так?

RinNas
07.02.2022 03:15Добрый день, а https://postgrespro.ru/docs/postgresql/14/datatype-bit пробовали?

Spinifex Автор
07.02.2022 10:21Для матрицы смежности? Пробовали. Строго говоря подобного можно добиться оперируя битами в наборе числовых значений (если у вас не PostgreSQL). Вполне себе вариант. Но обвес кода нужно будет прилично так написать.

mentin
07.02.2022 09:52+1Для постгресса есть расширение pgRouting. Им конечно в основном географы пользуются, но работает на произвольных графах, и там есть алгоритм pgr_connectedComponents, вычисляющий связанность. Описанную в начале схему по-моему можно без изменений ему скормить. Интересно, насколько быстрее / медленнее.
Spinifex Автор
07.02.2022 10:22+1Да, интересно… честно говоря как-то руки не дошли. Обязательно попробую.

Caraul
07.02.2022 11:02Для графовых БД есть такой https://tinkerpop.apache.org/gremlin.html - язык обхода графов. Для PostreSQL нету, а вот MS для новой CosmosDB реализовал. Про призводительность не знаю.
Spinifex Автор
07.02.2022 12:21+1Да, Гремлин весьма распространен в графовых БД. Однако у лидера этого класса БД (Neo4j) есть свой язык — Cypher. Мне он показался еще более удобным…
Но с производительностью использование диалекта связывать смысла не имеет. Важно что у вас за движок выполняет запросы. Но вот читабельность кода будет ясно выше, поэтому такие диалекты и изобретают.Caraul
07.02.2022 20:20Полюбопытствовал - Гремлин имеет вид FluentAPI, а вот Cypher больше похож на SQL. Есть даже старый транслятор от openCypher - https://github.com/opencypher/cypher-for-gremlin


mrbald
07.02.2022 17:12Я бы попробовал на плюсах написать простой прототип (или на numpy, или на любом языке с массивами и векторизацией) и использовал как бенчмарк. Может оказаться, что никакой multi-tier и не понадобится. Человечество начинает забывать какими быстрыми могут быть программы без проводов и баз данных.

charypopper
07.02.2022 18:04Спасибо за статью.
Чтобы свернуть так граф, которые приведены в решении - нужен полносвязный участок, на рискнках не такой (на них граф с полным двудольным подграфом).
На первом рисунке (я пронумеровал вершины), чтобы попасть в вершину 2 из 1 надо одно ребро пройти. А чтобы в 3 из 1 - надо пройти 2 ребра. На второй картинке у вас получается одинаковое расстояние - 2 ребра (через виртуальный узел).
P.S. Если ориентировать ребра ("от" виртуального и "к"), то можно свернуть так, как на рисунке и потом иметь возможность получить исходный граф (считать связью только "к"+"от" и "от"+"к")

Spinifex Автор
07.02.2022 20:21+1Зависит от того направленный граф или нет. Я изначалько подразумевал направленный граф, но стрелочки загромождают схему. :) Поправлю схемы чуть позже... На суть это не сильно влияет.
charypopper
08.02.2022 11:22Только если все направления от чётных к нечётным или наоборот. Если смешанное, то не получится. В статье что Вы приводите как раз так на первом рисунке

kawena54
просто скажите мне почему все рекомендуют использовать граф БД для соц сетей? в 99% задач , например найти пересечение друг друзей друга это пересечение SET'OV
Spinifex Автор
Не знаю почему. :) Согласен, что к выбору нужно подходить вдумчиво и никому не подражать. У графовых БД часто очень выразительный и удобный синтаксис написания запросов. Вместо 8 строчек с джойнами вы можете получить 1 строчку как аналог. Но средства диагностики, администрирования по своему развитию уступают реляционным. Поэтому поступаем как всегда — анализируем требования, в том числе не функциональные. И выбираем то, что лучше всего подходит для нашего проекта.