

Каждый год я стараюсь запускать по одному пет-проекту. Самый первый начинался ещё до того, как я умел пользоваться Git, а последний вообще был не программой, а книгой про доступность. Каждый проект учил меня как программированию, так и подходу к продуктовой разработке, что потом помогало в работе и развивало мою карьеру.
Пет — отличный способ прокачаться как начинающим разработчикам, так и опытным. Во время разработки пет-проекта можно побывать и программистом, и дизайнером, и менеджером, и маркетологом.
В этот раз рабочая задача по ускорению билда привела меня к проекту по визуализации модулей в сложных приложениях. Давайте расскажу, как это было.
Проблема и мотивация
Последние два года мы распиливали приложение на модули.
Делать это начали по наитию и чувству прекрасного. Было очевидно, что приложение состоит из понятных отрезков пользовательского пути: меню, карточки продукта, чекаута, оплаты, трекинга. Структурно разделив эти части в разные модули, мы получим более понятное разделение обязанностей. Сначала этот процесс блокировала общая база данных, но со временем мы от неё избавились.
Затем начали писать тесты, и многомодульная архитектура раскрылась с другой стороны: можно компилировать не всё приложение, а лишь его часть, и прогонять тесты относительно неё. Так фидбэк будет быстрее, тесты можно запускать чаще и прийти к нормальному TDD. Ускорение работы дало сильный толчок к распилу, потому что польза стала ощущаться, а простой на времени компиляции уменьшился. Мы начали распиливать ещё активнее.
Отпилив половину модулей от монолита, мы начали писать весь новый код в модулях и их количество начало расти. В какой-то момент заметили, что связи между модулями стали похожи на логотип Хабра. Хорошо, что довольно рано мы приняли правило, что фичевые модули не должны зависеть друг от друга — это сохранило много времени, но остальные связи и время билда всё же нужно было как-то анализировать.
Встроенных инструментов в Xcode нет: от стандартной компиляции остаётся только большой лог, который ни о чём не говорит и его нельзя как-то умно трансформировать.

Однажды я столкнулся с тем, что проект собирался не четыре минуты, а десять. Проблема нашлась довольно быстро, но мне стало интересно поизучать дальше и я пошёл искать инструменты для анализа.
Аналоги
Удалось найти не так много.
Build Times Chart. Очень простой инструмент: в начале и конце компиляции каждого модуля он добавляет скрипт с логом таймстемпа, а потом по логам строит график. На выходе получаем статичную картинку.

График понятный, даже по такой визуализации можно сказать многое:
что хорошо распараллеливается;
что блокирует сборку (например, DUIKit блокирует билд фичевых фреймворков и сам почему-то очень долгий);
сколько времени тратится на компиляцию в основном приложении.
Увы, график не интерактивный и детально из него ничего не узнать. Ещё один минус инструмента в том, что он добавляет дополнительные скрипты в сборку приложения. Идём дальше.
XCLogParser. Mobile Foundation написали парсер билдлогов и поверх него сделали несколько форматов экспорта.


Не понравилось, что нельзя фильтровать типы операций. От этого график ломается, все модули будто начинают собираться в одно время. Это на самом деле так: в одно время делаются первые подготовительные работы, а компиляция может начаться намного позже, но нам важен именно этап компиляции.
В итоге сложно понять зависимости между модулями. Визуализация есть, а толку нет.
Для сравнения вот мой график визуализации.
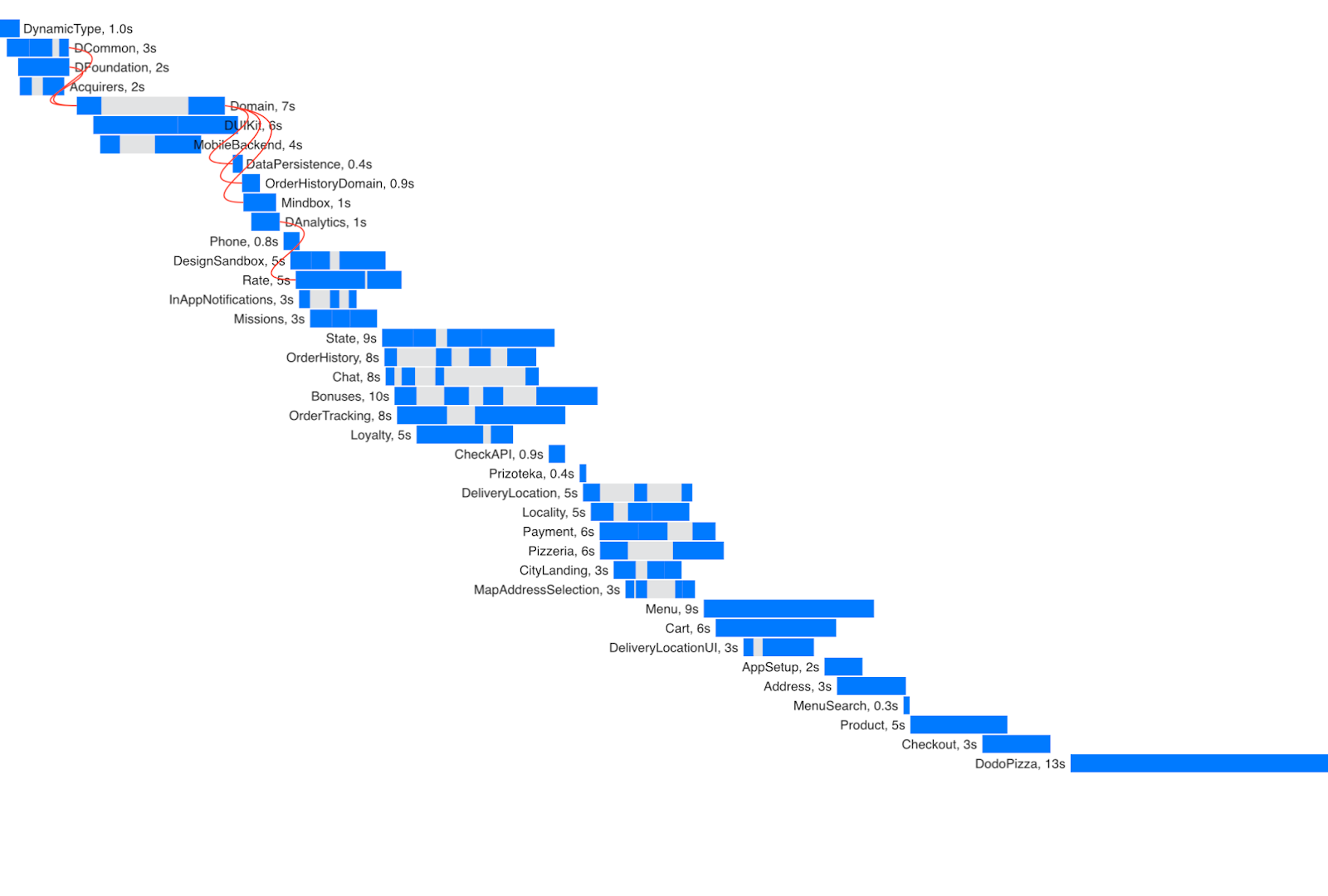
Xcode Build Times. Позволяет измерить общее затрачиваемое время на билд, чтобы потом можно было проанализировать время «простоя» разработчика. Полезно для поверхностной оценки времени билда, но слишком верхнеуровнево.
Можно не возиться со скриптами и купить Buildwatch for Xcode — делает то же самое.
В среднем до прихода М1 каждый наш разработчик тратил час-полтора в день на компиляцию. Попробуйте оценить, сколько времени тратите вы — скорее всего, ужаснётесь. Подробно про это можно почитать в статье Скорость сборки в iOS.
XCGrapher. Нашёл его только тогда, когда писал статью. Показывает связи между модулями, но не рассказывает о времени компиляции (подробнее).
Tuist graph и другие инструменты визуализации
Есть много разных инструментов, которые могут показать связи между разными модулями. Одни работают поверх CocoaPods, другие сами по себе. Проблема одна: они генерируют статичную картинку, которая в реальном проекте превращается просто в мусор.

Пробую XCLogParser
В итоге ничего толкового не нашлось, но XCLogParser позволял взять готовый парсинг логов и сделать с ними что-нибудь интересное. Так идея появилась сама собой, а вот предстоящий процесс было весь в тумане: я не знал, как устроен лог билда, и смутно представлял, что получится в конце. Приложение для Mac надо было написать впервые.
План был простой: взять парсер логов, визуализировать, дать удобные ручки для управления графом и понять, что ещё можно с этим сделать. Важно, чтобы приложение не добавляло дополнительных скриптов к проекту и запускалось без допонительной настройки, все данные у людей уже есть по результатам прошлых билдов.
Подключил пакет, вызвал его поверх своих логов и смог посмотреть, какие есть данные:
время;
продолжительность;
тип операций;
все подзадачи внутри;
закеширован модуль или нет и т.п.

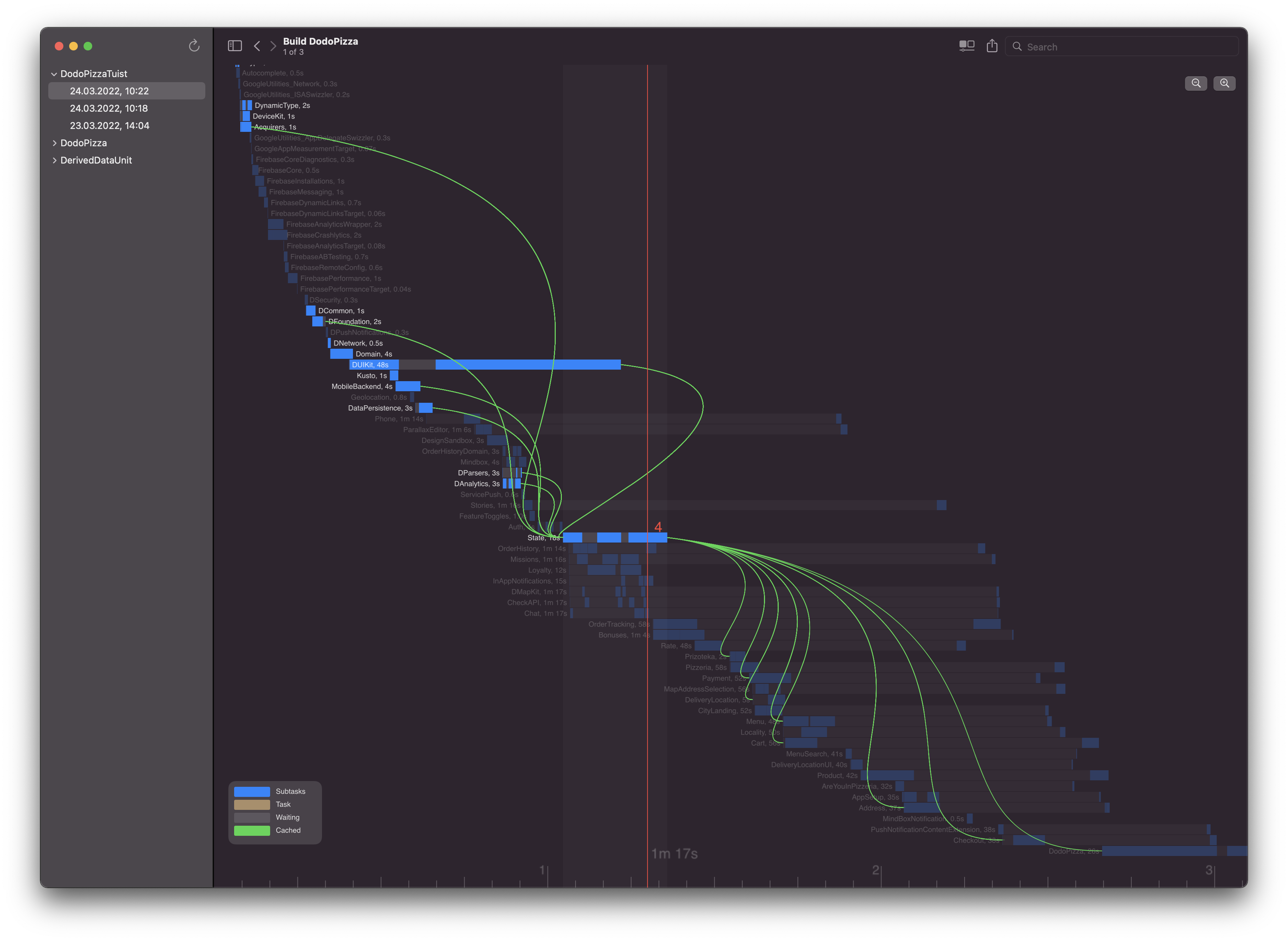
На графике видно несколько проблемных мест.
0. Внешние зависимости. Их связи никак не оптимизировать, но модули можно закешировать. Они хорошо параллелятся, потому что у них слабая связность. Картина может быть намного хуже, если подключать жирную зависимость (Realm, например) — тогда всё приложение будет ждать, пока модуль соберётся.
Жиденькая струйка зависимостей, которые почти не параллелятся. Это значит, что модули связаны между собой и каждый дожидается компиляции предыдущего. Можно улучшить, выделив общий интерфейс.
Модуль дизайн-системы компилируется очень долго, при этом блокирует компиляцию остальных фичевых фреймворков. Позже расскажу, что там так долго происходит.
Тут начинаются фичевые модули. Они собрались в отдельные пучки, а значит, снова есть связи, которые мешают распараллеливанию.
Ещё одно узкое место, надо поправить связи.
Ну, это монолит, надо распиливать. Время, которое занимает его компиляция, примерно совпадает с процентом кода, который в этом монолите лежит.
После того, как построил график по данным, мне стало интересно проверить разные гипотезы. Например, где выполняется мало одновременных задач? Вот, красным показал (до релиза не дожило, показалось бесполезным).

Поняв проблемы и подвигав зависимости, я смог сделать вот такой граф (вверху). Модули, которые компилируются после дизайн-системы, встали в плотный пучок. Это значит, что при работе в этих модулях у меня стало меньше кода для компиляции.

Через пару дней прототипирования я понял, что польза от приложения есть, можно ещё обвешивать инструментами и получится полноценный продукт. Главных задач минимум две: дать возможность переключаться между всеми проектами и разобраться с визуализацией. Шёл октябрь 2021.
Ускоряю XCLogParser
Первое, что очень бесило, — скорость работы. При каждом запуске приходилось ждать парсинга проекта секунд двадцать. С такой скоростью разрабатывать очень неудобно, и я сел ускорять.
Для этого пришлось форкнуть XCLogParser и начать удалять лишний код. Сначала выкинул все форматеры в разные виды представлений (HTML, Chrome Tracing и т.п), чтобы не мешали компиляции проекта.
Затем посмотрел профайлером на скорость выполнения и самые медленные операции. Оказалось, что медленно конвертируется подстрока (в виде индексов) в строчку (полноценное выделение памяти). Переписал так, чтобы в строчку конвертировать надо было не все данные из лога, а только названия этапов. Стало быстрее раз в двадцать.
Компьютер нельзя заставить работать быстрее, но можно дать меньше работы. Так я отфильтровал те задачи, которые не видны на графике: создание файлов, папок и прочее. Времени они занимают мало, график портят, парсинг замедляют.
Можно ускорять и дальше, сделав ленивую загрузку: пройти по всему логу, разметить индексы для будущих строк, но в строчки превращать только то, что видно на экране прямо сейчас. Это ускорит раз в сто, ведь верхнеуровневых модулей мало, а все внутренние задачи парсить просто не нужно до тех пор, пока пользователь не кликнет на нужный модуль.
Изучаю вглубь
В какой-то момент мне сделали разумное замечание: нельзя смотреть на количество одновременно компилирующихся модулей, потому что внутри модуля компиляция отдельных файлов тоже параллелится. Раскрашивание графа в красно-белые столбики пришлось убрать.
XCLogParser давал информацию обо всех шагах внутри одного модуля, поэтому на каждой полоске можно показать выполняемые задачи и время, когда ничего не происходило.

По клику на модуль добавил попап с визуализацией подзадач. Такая детализация позволила изучить, что случилось в дизайн-системе и почему она так долго компилируется. Оказалось, что половину времени занимает компиляция ассетов!

Буквально за месяц до этого мы решили перенести все иконки приложения в модуль дизайн-системы, а это сильно увеличило время его компиляции. Если для иконок создать отдельный модуль, то мы сможем распараллелить работу и общий билд будет быстрее.
Последние версии Xcode прокачали скорость компиляции. Например, он перестал ждать компиляцию ассетов и запускает сборку последующих модулей сразу, как закончилась компиляция кода.
Связи
По предыдущему состоянию графа легко найти проблемы, но сложно понять, что к ним привело. Для поиска решения нужно как-то показывать связи между модулями, потому что исправлять нужно именно их.
Этих данных нет в логе билда, но есть в файле Build/Intermediates.noindex/XCBuildData/*-targetGraph.txt. Я распарсил файл и на его основе добавил связи поверх графа. Этого XCLogParser уже не даёт, и я получил первое фичевое преимущество (хотя нефункциональных было уже достаточно).
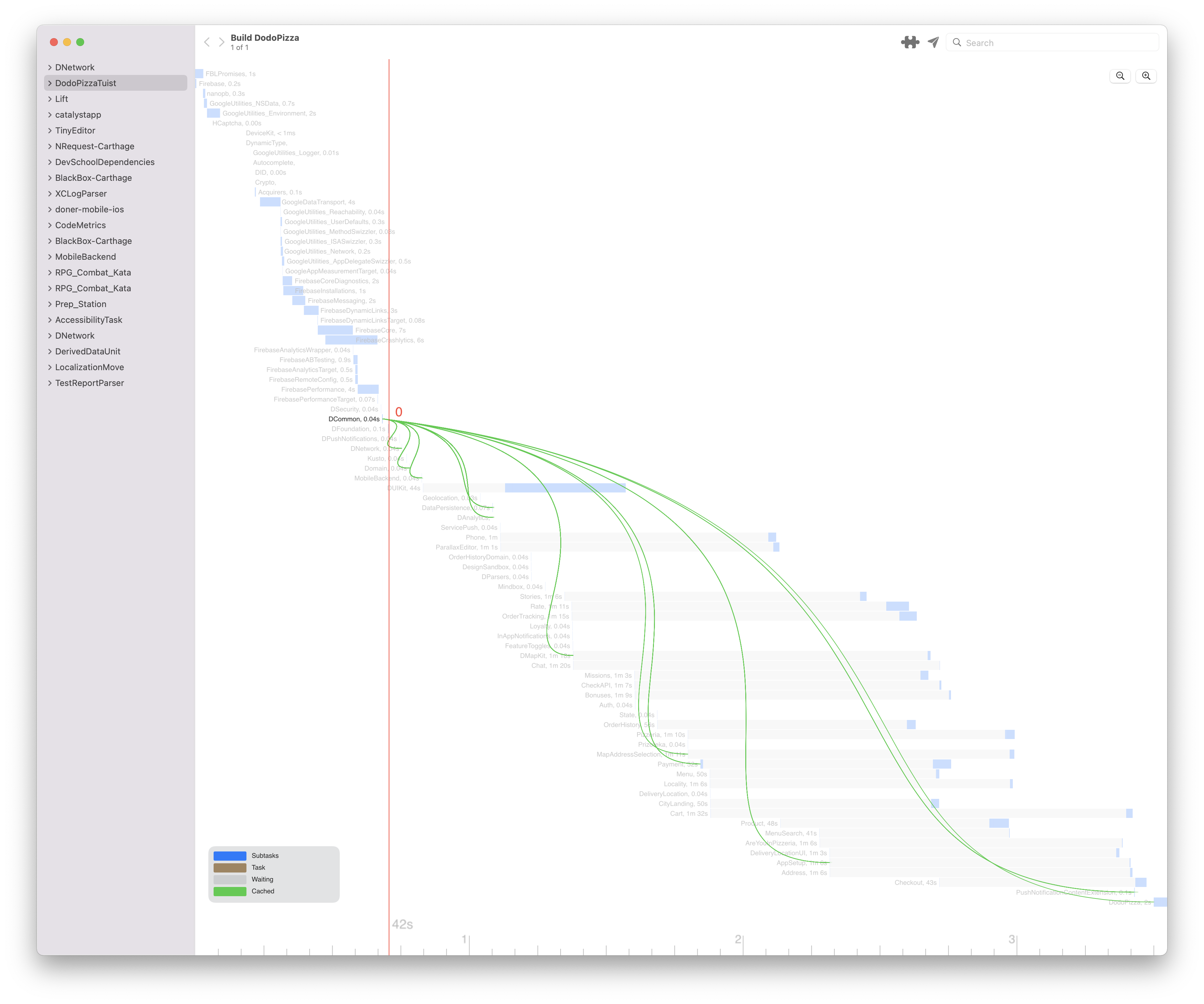
Я решил показывать связи только при наведении на конкретный модуль, потому что если показывать все связи, то граф станет нечитаемый. Попробовал добавить простую эвристику для критичных мест: если модули связаны, а время завершения одного совпадает со временем начала следующего, то на такую связь надо смотреть повнимательней — возможно, это место для оптимизаций. Такие места покрасил в красный и показываю без наведения на них мыши. Для решения можно вынести общий интерфейс в отдельный модуль, тогда обе библиотеки будут компилироваться параллельно.

Фильтрация данных
К XCLogParser у меня было самое главное пожелание — легко фильтровать типы операций. Контроль над типами я вынес в отдельную панель, но там же оказалось удобно считать суммарное время на все задачи. Я подсчитал время и оказалось, что какие-то этапы можно отключить, потому что в них нет задач.
Всё, что находится в блоке Other, обычно неинтересно анализировать, поэтому по умолчанию он отключен: так и граф красивее, и ценность его выше.

AppKit
Визуализация готова, надо завернуть в десктопное приложение.
Днём я iOS-разработчик и использую фреймворк UIKit, но сейчас мне нужно приложение для macOS, и придётся использовать AppKit. Всё очень похоже, но возможностей больше и они более «олдовые»: видно, как при релизе iOS многие механизмы сделали лучше и проще.
AppKit сложнее UIKit, но временами ощущается, что сложность просто не смогли правильно обработать. Например, у одних только кнопок есть сразу два свойства: тип и стиль. Оба свойства работают только в правильных парах, ошибиться очень легко. Чтобы разобраться в этом, люди пишут отдельные гайды.
Сложно искать информацию: ощущение, что под Mac не пишет вообще никто, на простые вопросы ответов на Stack Overflow нет, а документация весьма скудная.
Декомпозиция на NSViewController
Мне всегда было интересно, как разрабатываются «большие» десктопные приложения. Во многом это похоже на разработку для iPad: на экране может быть сразу несколько NSViewController’ов, которые объединяются через NSSplitViewController, и их состояния могут зависеть друг от друга.
Вместе с этим может быть сразу несколько окон на экране, но мне это пока не нужно.
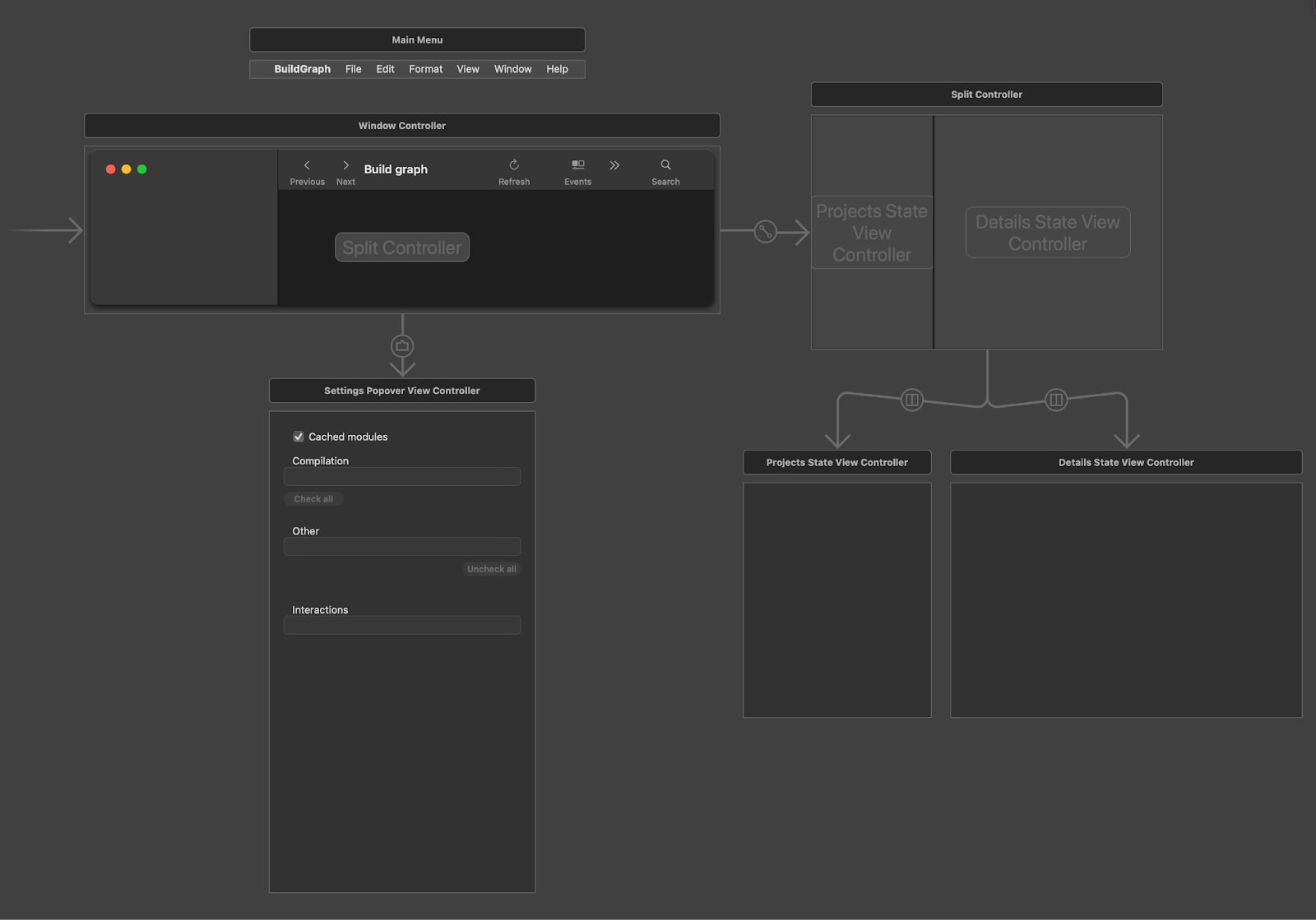
В приложении много разных состояний. Переключаясь между ними можно менять целые NSViewController. Presenter у них может быть как общий, так и в отдельных классах, зависит от сложности самих экранов.
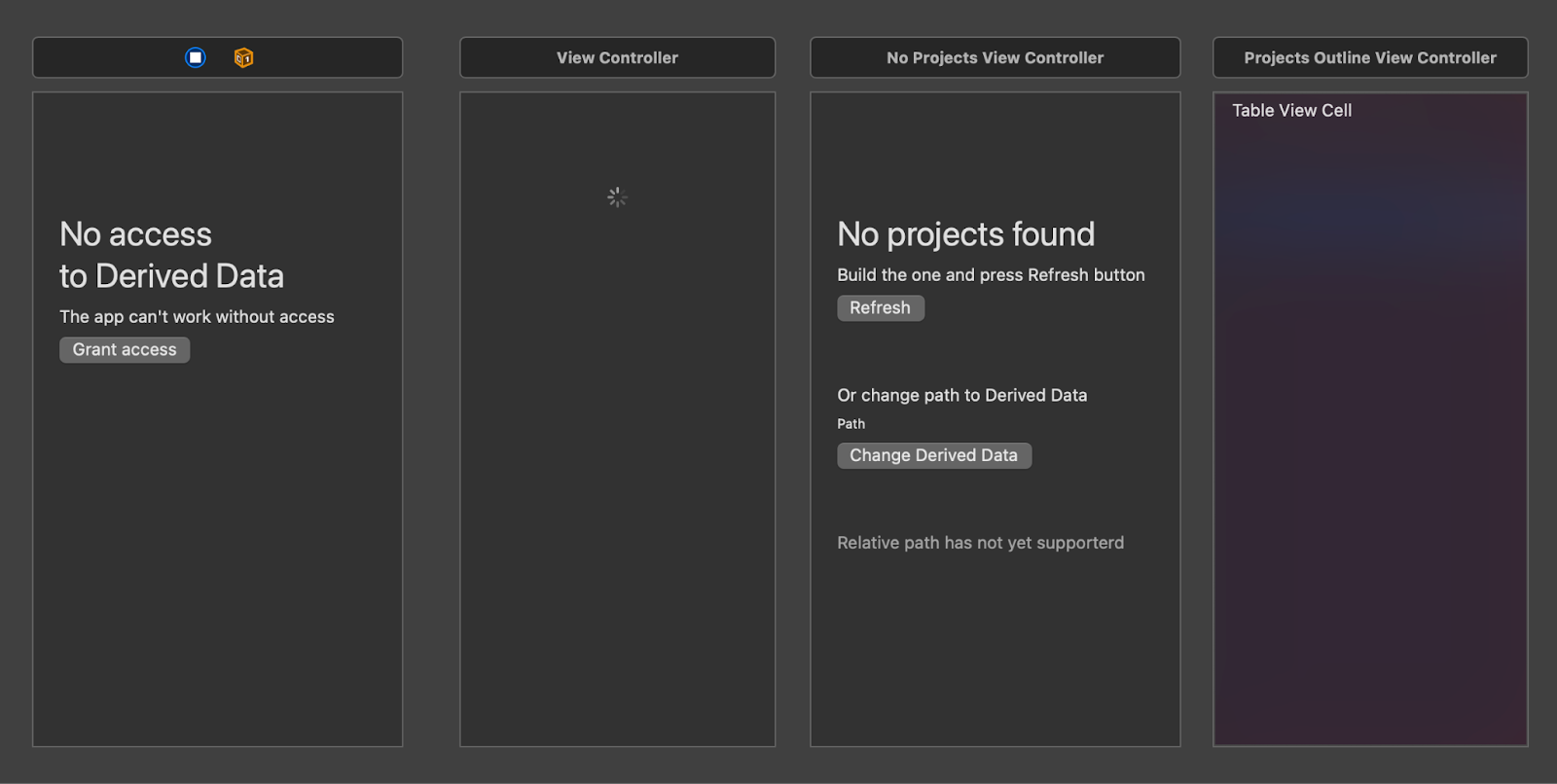
Для списка проектов понадобилось четыре состояния:
нет доступа к файловой системе;
ожидание на чтение файлов;
пустое состояние, когда проектов в папке не нашлось;
список проектов в NSOutlineView (это древовидная структура).
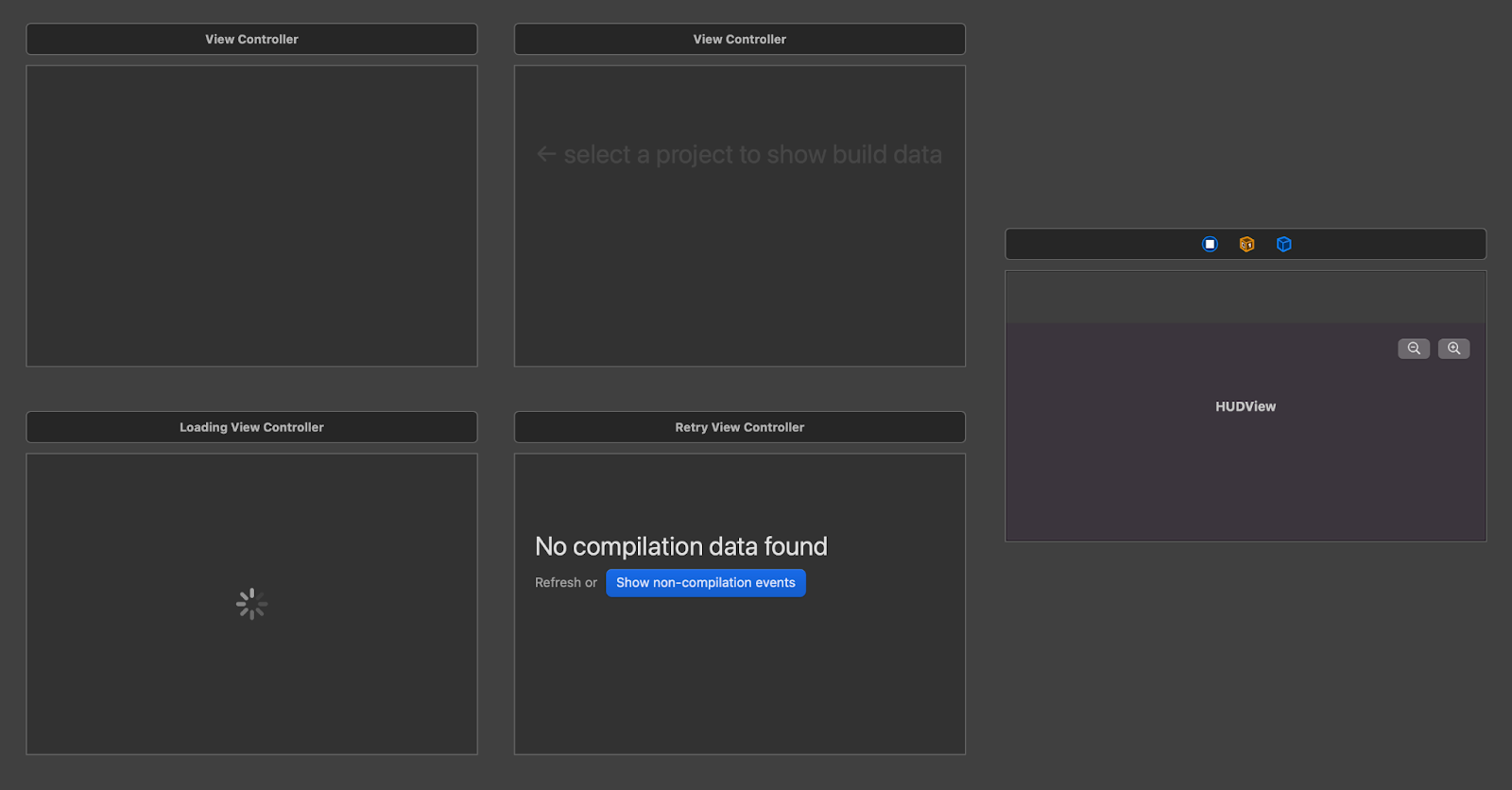
Для детального представления — пять состояний:
пустое, когда проектов не нашлось или нет доступа;
предложение выбрать один из проектов слева;
загрузка проекта;
интересных данных в проекте не нашлось;
визуализация данных.
Для переключения состояний я написал специальный StateViewController, унаследовавшись от которого можно задавать состояния в виде «енумки», а он будет загружать ассоциированный с состоянием контроллер. Состояния при этом описываются так:
enum ProjectsState: StateProtocol {
case loading
case empty(_ derivedDataURL: URL)
case projects(_ selectedProject: ProjectReference?)
case noAccessToDerivedData
static var `default`: Self = .loading
}Архитектура
В первую очередь — модульная. Вряд ли я бы мог наплодить много модулей, но визуализировать граф билда программы с помощью самой программы звучит заманчиво. Увы, проект слишком простой, особо показать нечего.
У меня четыре больших модуля:
поиск папки DerivedData и получение доступа к ней;
выбор проекта в DerivedData и поиск файлов внутри его папки;
парсинг логов (тут модифицированный XCLogParser);
визуализация графа.
И в конце всё это собирается в одно приложение, запихивается в NSWindow и запускается.
Вся логика по обработке данных отделяется в Presenter — мне этого оказалось достаточно для удобного тестирования.
Удобным оказалось отделение небольшого функционала в отдельные сущности. Например, граф можно зумить кнопками на экране, шорткатом с клавиатуры и жестами с трекпада. Весь этот код в отдельном классе с единственной зависимостью на NSScrollView. Другой пример — обработка кликов и хайлайта модулей от мышки — это тоже отдельно от контроллера.
В итоге NSViewController лишь создаёт разные сущности, которые выполняют разные задачи, и синхронизирует их друг с другом.
Тесты на комбинаторику
Все новые приложения я начинаю писать прямо в тестах: фиксирую окружение, файл, с которым работаю, и начинаю дописывать код. Первые прототипы визуализации генерировали мне картинку через снапшот-тест, которую я отправлял коллегам.
С другой стороны, все вопросы парсинга и комбинаторики тестируются легко, а сломать их многообразие совсем не хочется, поэтому тоже покрыто тестами. Каждая новая версия Xcode может генерировать новые данные, и копить знания через тесты сильно поможет на долгой дистанции.
Во время разработки нам дали доступ к Xcode Cloud, поэтому CI развернули на нём ради эксперимента. Стало удобно: пуш не только прогонял тесты, но и выкладывал билд на тестирование через TestFlight.
Если вам кто-то говорит, что тесты замедляют разработку и нужны только для большого энтерпрайза, то вот пример стартапчика, в котором всего 40 тестов, но они существенно сэкономили мне время.
Тёмная тема
Хотелось получить тёмную тему, но надо было разобраться, каким образом. Графика нарисована на CALayer, а значит, и цвета внутри — это CGColor, просто так их не вытащить. Пришлось городит костыль, который ещё и в тестах плохо работал, но тёмная тема появилась.
Техдолг
В пет-проектах техдолг накапливается ужасно быстро, потому что вся разработка идёт в экстремальных условиях: ночью, после работы, урывками. Легко возникает соблазн сделать побыстрее, забив на качество, но это очень плохой путь — уже через пару вечеров можно застрять в собственном коде и замедлиться.
Чтобы вырваться из этой петли, я регулярно повышал качество и понятность кода. Если у меня случался перерыв в разработке, то «въезжал» в проект я не с написания следующей фичи, а с рефакторинга того кода, который уже есть. Если что-то отламывал, то писал рядом комментарии или тесты: если я сейчас потеряю контроль над кодом, то дальше будет только хуже.
В итоге получилось вот такое приложение.
Как находить время на пет-проекты?
Коллеги спросили, где находить время и силы на дополнительный проект. По опыту нескольких проектов я нащупал свое ощущение.
Самое важное, наверное, — то, что я могу себя очень сильно накручивать, почему мне интересно сделать какой-нибудь проект. Всегда представляю большую историю, которая может за этим случиться.
У меня бывают эмоциональные подъёмы, когда я готов поздно ночью или рано утром что-то пойти и делать — в такие моменты надо идти и делать. Например, Haptic Composer я писал одной рукой, пока второй держал и убаюкивал полугодовалого сына, настолько «пёрло» и хотелось сделать.
Бывают «энергетические» спады, когда и на работе-то сидеть сложно, тогда я не делаю ничего: иду гулять, играть на приставке или заниматься повседневными делами и просто жду очередного подъёма.
В итоге оно превращается в синусоиду, и такими набегами получается понемногу продвигаться вперёд. Бывают большие подъёмы в несколько месяцев, чаще всего в начале года — по статистике Хабра, я даже статьи осенью пишу меньше.
Иногда есть среднее желание поделать что-то, но нет запала наа полноценную фичу. В таком случае я делаю рутинную работу: разбираю задачи, пишу тесты, исправляю небольшие баги или рефакторю: это помогает погрузиться в код, починить проблемы, подготовиться к следующему забегу.
Итоги
Этот проект запустился за полгода. Для меня это довольно долго, потому что пара успешных проектов запускались буквально за две недели. Я начал с полного непонимания домена и экспериментов, а закончилось полноценным продуктом. Впереди — улучшение приложения продвижение, чтобы о продукте узнали те, кому он полезен.
Подписывайтесь на канал Dodo Mobile в Телеграме, чтобы узнать больше новостей про нашу разработку. В ближайшее время продолжим про многомодульность и расскажем, как мы переезжали с CocoaPods на Tuist.
Комментарии (6)

domix32
25.03.2022 12:20+2$29.99
ну вот как-то так и нет гайдов и прочего по яблокам - яблочные разрабы изобретают костыли, а сторонние разработчики потом это монетизируют в огромных количествах , а т.к. все закрыто качество надстроек над костылями соответствует уровню костылей. Яблочная разработка - боль.

akaDuality Автор
25.03.2022 13:01+1Как эта проблема решается не для Xcode?
domix32
25.03.2022 13:41+1Она обычно не создается. Ну и всякие performance тесты и бенчмарки, которые следят за временем сборки. Говорю про случай компилируемых языков - c/c++, rust - большинство из мажорных компиляторов имеют в составе некоторый performance triage. Для языков попроще обычно кому-нибудь надоедает и он делает форк сборщика/пакетного менеджера/упаковщика у которого выпиливает легаси или вовсе с нуля пишет сборщик - npm vs grunt vs parcel vs %yournamehere%. Естественно все это живет в opensource и фичерится/развивается при помощи сообщества.
Яблочная инфраструктура сильно закрытая, плюс многие вещи как уже сказано ранее монетизируются, что мешает как распространению софта, так и накоплению знаний, улучшению документации и софта и прочему.
Спасибо, что делитесь знаниями, кстати.
akaDuality Автор
25.03.2022 16:02Если честно, то не вижу связи между открытостью и mac: я могу открыть исходники кода и можем писать коллективно, могу не открывать. С лицензиями надо только разобраться.
Другое дело, что я не очень верю в бесплатные решения. Я привел несколько инструментов, они написаны на самой разной инфраструктуре и языках, допилить что-то в них сложно (требует полной переработки и смены стека), а превратить в законченное решение порой невозможно (прямо сейчас они в том состоянии, в котором есть).
Условно, на мотивации сделать круче, лучше и заработать — проект родился. Опенсурс я лишь потыкал, потом стало понятно, что менять надо просто все, а не слегка улучшать. Если кто-то хочет помочь — всегда можно написать автору и сделать вместе, платность приложения этому не мешает.
На заработанные деньги можно сделать много чего, чего нельзя сделать без них: оплатить труд других разработчиков, дизайнеров, рекламу сделать, опенсурс спонсировать.
нет гайдов и прочего по яблокам
https://dodo.dev/a11y-book – огромная бесплатная книга про доступность. Один платный проект помог родиться этому бесплатному. Все переплетено.
domix32
25.03.2022 21:51На всякий случай дисклеймер - я не против того чтобы вы или кто-либо еще зарабатывал на этом. Да и в опенсорсе есть всякие варианты спонсорства, чего уж там.
egbad
История вдохновляющая! В такие моменты и понимаешь, зачем ТЕБЕ нужно программирование (помимо того, чтобы не помереть с голоду): чтобы делать свою жизнь лучше!