
В феврале прошлого года я впервые обращался к теме прогнозирования новых химических соединений методами глубокого обучения — когда опубликовал перевод об инструменте FermiNet. Такие исследования, находящиеся на стыке физики, химии, биоинформатики и фармакологии, призваны смоделировать потенциально возможные химические связи и конфигурации молекул. Так можно одновременно удешевить и значительно ускорить разработку новых лекарств. Также я затрагивал эту тему в статье о выращивании кристаллов, но в несколько ином аспекте: гравитация вносит коррективы в форму молекул, поэтому некоторые конфигурации молекул быстро «сминаются». Эта проблема остро стоит при производстве баснословно дорогих препаратов (прежде всего, противораковых), терапевтический эффект которых заключается в поддержании строго определенной формы молекул, блокирующих патологические биохимические процессы. Если бы мы могли поставить на поток производство филигранных молекул (в частности, ферментов), блокирующих работу определенных белков, это преобразило фармакологию, в значительной степени ее персонализировав. Но у такой линии исследований есть и обратная сторона: она открывает путь к созданию чрезвычайно токсичных и цепких веществ, которые было бы практически невозможно «выковырять» из биохимического аппарата, если они там окажутся.
Несколько слов о машинном и глубоком обучении
Невозможно было бы сделать в этой статье даже краткий обзор машинного и глубокого обучения как предметной области, не отвлекаясь от темы. Поэтому я оговорюсь лишь о том, что машинное и глубокое обучение являются подразделами искусственного интеллекта и не идентичны друг другу. Машинное обучение можно сравнить с исключительно продвинутым статистическим анализом больших множеств данных; машинное обучение позволяет выявлять закономерности и находить решения именно по статистическим признакам и явно программировать компьютер (указывать ему пошаговую последовательность операций для достижения цели) при машинном обучении не требуется. При глубоком обучении компьютеры образуют (многослойную) нейронную сеть: на каждом из слоев этой сети обрабатываются признаки анализируемого множества данных, после чего вывод предыдущего слоя сети служит вводом для следующего. При этом применяются и методы машинного обучения, но методы глубокого обучения не сводятся к чистой статистике, а отличаются значительным разнообразием: например, при помощи глубокого обучения удобно обрабатывать данные, полученные методом компьютерного зрения. Максимально популярный обзор машинного обучения имеется в блоге Вастрика, а более строгое, но вполне понятное изложение (в частности, о соотношении глубокого и машинного обучения, а также о видах нейронных сетей) дается в работе Дмитрия Павленко. Там же есть иллюстрация с соотношением рассматриваемых здесь предметных областей:
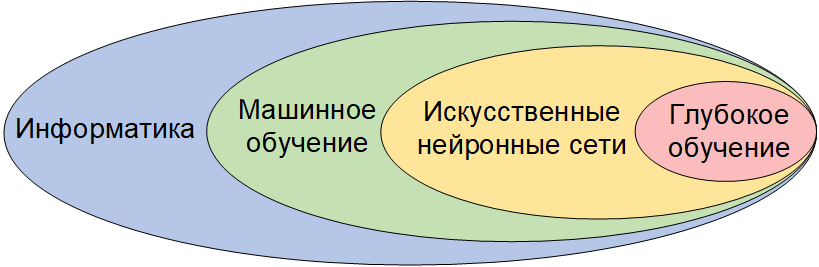
В целом (особенно, учитывая работу с признаками, описанную в работе Павленко здесь и далее) я бы охарактеризовал машинное обучение как «неизвестное об известном», а глубокое обучение как (одновременно) «понятное о неизвестном» или «достоверное о неизвестном». Поэтому при проектировании новых молекул ученым требуется прежде всего глубокое обучение с тщательной отбраковкой неоптимальных вариантов. Глубокое обучение в рассматриваемой области идет на основе данных о химических свойствах, совместимости и геометрии молекул.
Нейронные сети как биохимический полигон
Открытие новых препаратов нацелено на поиск новых химических соединений с конкретными свойствами, как правило – терапевтическими. В последние годы эта область тесно смыкается с информатикой, поскольку опирается на приемы машинного обучения, ставшие в последнее время гораздо более доступными. Библиотеки машинного обучения, предназначенные для решения узкоспециальных задач, чаще всего реализуются на языке Python – и ниже в этой статье будут упомянуты некоторые из таких библиотек, предназначенных именно для фармацевтического моделирования. В настоящее время развивается концепция «точной медицины» (precision medicine), с которой связан специфический набор проблем. Можно считать, что история точной медицины начинается с американского мальчика Николаса Волкера (Nicolas Volker), который в 2009 году (в возрасте около 2,5 лет) попал под наблюдение врачей в детской больнице штата Висконсин, а к 2011 году перенес около 160 операций. Мальчик страдал непрекращающимися воспалениями кишечника, природа которых оставалась невыясненной. Потребовалось полностью секвенировать его геном, чтобы найти редкую мутацию в гене XIAP, отвечающем за апоптоз (запрограммированную смерть клеток). Природа точной медицины такова, что лекарства для нее крайне сложно разрабатывать традиционными методами – через обширные когортные исследования. Когортное исследование длится многие месяцы или годы и охватывает сотни и тысячи человек. В разработках точной медицины счет идет в лучшем случае на годы, а уровень персонализации настолько высок, что исследовать препарат можно только на самом пациенте, либо на небольшой группе людей, страдающих таким же заболеванием (например, генетическим или онкологическим). Поэтому в доклинических исследованиях как никогда важными становятся воспроизводимые и стандартизированные приемы моделирования молекул и их взаимодействий. Эта новая научная дисциплина, условно именуемая хеминформатикой (cheminformatics) сейчас переживает период «большого взрыва» и позволяет резко сократить стоимость и сроки открытия новых лекарственных веществ. Конечно, у нее есть свои ограничения, но массу других ограничений (в том числе, связанных с государственным регулированием) она снимает – поэтому темная сторона этих разработок пока игнорируется или недооценивается. Но темные и труднопрогнозируемые стороны хеминформатики напрямую связаны с достоинствами и недостатками нейронных сетей.
В процессе открытия новых лекарств подходы машинного обучения могут применяться в следующих целях:
Прогнозировать структуру целевых препаратов
Идентифицировать и уточнять перспективные варианты
Исследовать биологическую активность новых лигандов
Проектировать модели, предсказывающие фармакокинетику и токсикологические свойства веществ-кандидатов
В биохимических исследованиях применяются варианты машинного обучения (ML), которые можно условно разделить на три категории: обучение с учителем (supervised learning), обучение без учителя (unsupervised learning) и последовательное обучение (sequential learning). Данные, используемые для машинного обучения, бывают размеченными и неразмеченными. Под спойлером – краткая характеристика трех этих видов обучения.
Hidden text
Для обучения с учителем нужен размеченный (тренировочный) набор данных – на котором модель и тренируется. Натренировавшись, модель может сама приступать к выдаче прогнозов и формулированию решений по мере получения новых данных. Из методов обучения с учителем в биохимических задачах применяется метод опорных векторов и искусственные нейронные сети (ANN), способные вычленять сложнейшие паттерны в больших датасетах.
Обучение без учителя позволяет выявить взаимосвязи или паттерны в неразмеченных данных. Модель учится сама по себе, наблюдая множество данных и объединяя найденные закономерности и отношения в кластеры.
Последовательное обучение позволяет агенту (это сущность, перед которой поставлена цель) учиться в интерактивной среде методом проб и ошибок, оценивая опыт взаимодействий с этой средой как положительный и отрицательный. Следовательно, последовательное обучение – это вариант обучения с подкреплением (reinforcement learning).
Применение компьютеров при разработке лекарств началось еще в 1970-е, задолго до распространения машинного обучения. Технология CADD (Computer-aided drug discovery) (CADD) уже позволяет значительно удешевить и ускорить разработку лекарств на основе наиболее перспективных веществ-кандидатов, причем, пока препарат еще существует «на кончике пера». Практически методом Монте-Карло создаются обширные базы данных с «фармацевтическими» молекулами, чьи структурные формулы затем подвергаются виртуальному скринингу. В CADD используется два основных подхода к проектированию молекул: 1) структурный и 2) на основе лигандов (ligand-based drug discovery, LBDD). Такое проектирование еще называется QSAR. Метод на основе лигандов позволяет проверить, какие мелкие молекулы могут подсоединиться (фактически – пристыковаться) к крупной белковой молекуле. Такой подход легко поддается оптимизации и моделируется при помощи готовых библиотек на Python. Первичная оценка свойств препарата, также выполняемая виртуально, сокращенно именуется QSAR («поиск количественных отношений структура-свойство»). QSAR позволяет отыскивать потенциально активные соединения. Несмотря на относительную легкость такого поиска, даже «виртуальные» молекулы должны подвергаться предварительной оценке по параметрам ADMET (всасывание, распределение, метаболизм, выделение, токсичность). Соответственно, такая работа позволяет собирать данные не только о потенциально лечебных, но и о токсичных молекулах.
Метод молекулярного докинга позволяет виртуально опробовать варианты стыковки молекул и степень их химического сродства (аффинности). При докинге выбирается белок-мишень, к которому затем подбирается молекула-лиганд – как правило, встраиваемая в белок с целью блокирования его работы:
Именно на материале молекулярного докинга накапливается тот датасет, на основании которого можно ускорять разработку молекул. Ниже будут рассмотрены две разработки: движок DeepBAR, созданный в MTI (Массачусетском технологическом институте) и библиотека Pysmiles, позволяющая моделировать молекулы.
Движки и нейронные сети
Итак, препарат будет работать лишь при условии успешного прикрепления к белкам-мишеням в организме. Оценка такой «прилипчивости» - ключевое препятствие в процессе открытия и скрининга препаратов. Новые исследования в этом направлении идут на стыке химии и машинного обучения.
В MIT была разработана новая технология DeepBAR, позволяющая быстро вычислять сродство к связыванию между препаратами-кандидатами их мишенями. Такое сродство определяется свободной энергией связывания – чем меньше эта величина, тем крепче связь. На практике низкая энергия связывания приводит к тому, что препарат «выигрывает» у других молекул, также пытающихся связаться с белком. Следовательно, свободная энергия связывания – прямой индикатор потенциальной эффективности препарата.
Методы для вычисления свободной энергии связывания относятся к двум основным категориям, и у каждой – свои недостатки. Методы одной категории позволяют вычислить эту энергию точно, на что тратится значительное время и вычислительные ресурсы. Методы второй категории не так ресурсозатратны, но и свободную энергию связывания вычисляют лишь приблизительно.
DeepBAR занимает в этом отношении золотую середину, поскольку вычисляет искомую величину точно, но выполняет для этого гораздо меньший объем вычислений, чем более ранние методы – поскольку большая часть работы выполняется не при самих вычислениях, а на предварительном этапе, в ходе машинного обучения.
Аббревиатура «BAR» в DeepBAR означает «Bennett acceptance ratio», «оценочная функция Бенетта» - это алгоритм, используемый в структурной химии уже не один десяток лет. Для работы по этому алгоритму, как правило, требуется знать энергию двух «крайних» состояний: 1) молекула препарата прочно связана с белком и 2) молекулы белка полностью диссоциированы в растворе, а также учитывать множество промежуточных состояний (например, различные степени промежуточного связывания).
DeepBAR выстраивает цепочку этих промежуточных состояний, вычисляя оценочную функцию Бенетта при помощи нейронных сетей, точнее – глубоких генеративных моделей. Такие модели позволяют создать для каждой конечной точки два референсных состояния – «связь есть» и «связи нет».
Такие глубокие генеративные модели во многом основаны на наработках компьютерного зрения – в том, что очерчивание промежуточных состояний происходит примерно по тому же принципу, что и консолидация фрагментов при синтезе изображений компьютером. Фактически, молекула воспринимается как картинка (точнее – скульптура, поскольку у молекулы важна пространственная ориентация), и на таких картинках модель может учиться распознавать как сами молекулы, так и варианты связывания молекул и препаратов.
Иным образом устроена библиотека Pysmiles, реализующая на языке Python технологию SMILES. SMILES позволяет выражать цепочки химических связей в виде строк, а далее преобразовывать эти строки в последовательности целых чисел. Далее нейронная сеть, изучающая последовательности SMILES, присваивает весовые коэффициенты последовательностям чисел, которые вычленяет из датасета SMILES – и, следовательно, прогнозирует вероятность образования и прочность разнообразных химических связей. Работа Pysmiles выглядит примерно так:
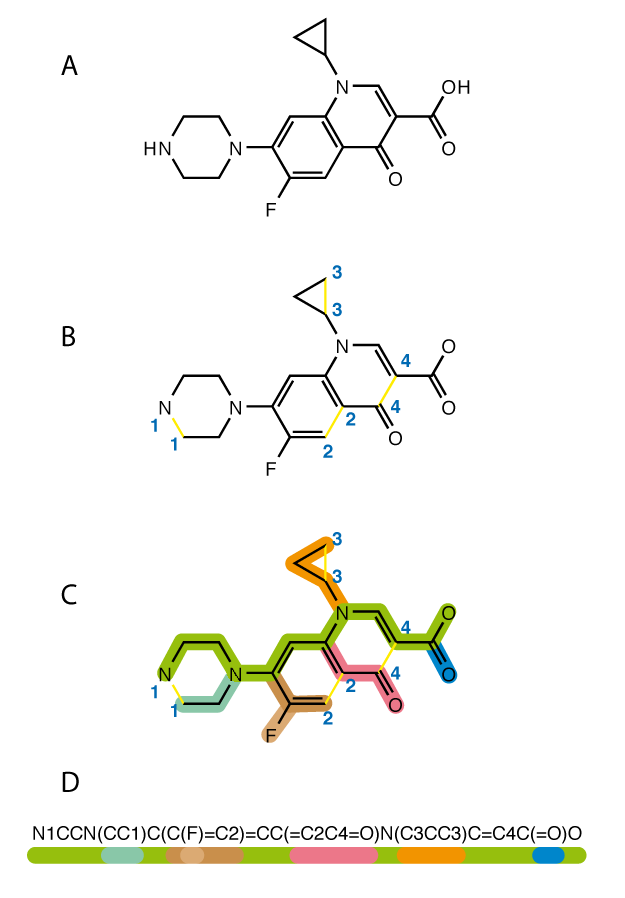
Существуют и другие специализированные библиотеки для подбора конфигураций молекул:
Magpie — библиотека на языке Java, прогнозирующая свойства материалов при помощи методов машинного обучения.
PyMKS — библиотека на языке Python для соотнесения химической структуры веществ с их свойствами
Openbabel — библиотека на языках Python и С++ для биоинформатики и хеминформатики/
Наиболее заметной инициативой по оценке токсичности проектируемых препаратов был конкурс Tox21, состоявшийся в 2014 году. Участники конкурса строили вычислительные модели (как правило, основанные на использовании глубокого обучения), позволявшие оценивать 12 параметров токсичности у 12 000 лекарственных препаратов и химикатов, встречающихся в окружающей среде. На основании конкурса удалось построить своеобразный конвейер DeepTox, обеспечивающий многоступенчатую проверку. На тот момент казалось, что ценность этой работы – в основном академическая и классификационная. Она показала, какие методы глубокого обучения и архитектуры нейронных сетей наиболее удобны для моделирования новых молекул: оказалось, что таковы метод опорных векторов (SVM), искусственные нейронные сети (ANN), метод k-ближайших соседей (KNN), линейный дискриминантный анализ (LDA), наивный байесовский классификатор (NB) и некоторые другие – от лучшего к худшему. В результате этой работы во второй половине 2010-х появились коммерческие программные пакеты для проектирования новых лекарств. Одной из наиболее современных разработок стала программа MegaSyn, использующая вышеупомянутую технологию SMILES и генеративно-состязательные нейронные сети (GAN). GAN – целое направление разработок в глубоком обучении, особая черта этих нейронных сетей – создание несуществующих, но при этом крайне реалистичных образцов на основе изученного датасета.
Обоюдоострая фабрика ядов
Летом 2021 года Фабио Урбина и Шон Икинз из компании «Collaborations Pharmaceuticals», штат Северная Каролина, произвели с MegaSyn убийственно простой и тем более шокирующий опыт. Они обратили «функцию полезности», встроенную в этот программный пакет, предоставили программе коммерческий датасет и предложили ей смоделировать вещества, максимально губительные для организма. При этом «по умолчанию» программа проектировала молекулы в направлении двух целей: повышения полезности и повышения биоактивности, и исследователи обратили только одну из этих функций, превратив полезность в токсичность. На такой странный опыт их натолкнула аналогия со знаменитой нейронкой GPT-3, предназначенной для обработки естественного языка. Обратив функцию полезности GPT-3 на противоположную, группа исследователей из Торонто заставила нейронку разразиться потоком оскорбительных сентенций, прежде всего, расистских, сексистских и бранных.
Всего за 6 часов работы нейронная сеть Урбины и Икинза «изобрела» около 40 000 молекул, каждая из которых представляет собой потенциальное химическое оружие. В частности, у нейронки получился газ VX, известный по боевику «Скала»:
Многие из предложенных программой молекул в природе не существуют и пока не получены, но, по всей видимости, также окажутся сильнейшими ядами. Авторы особо подчеркнули, что многие из предложенных нейронкой молекул являются столь экзотическими соединениями, что химики даже не пытались искать токсичных свойств в этой биохимической области. Но, поскольку обращенная функция полезности работает для всех веществ одинаково, в смертоносности этих молекул сомневаться не приходится.
В конце марта 2022 года в журнале «Nature» вышла статья Урбины и Икинза «Dual use of artificial-intelligence-powered drug discovery» («Двойное использование методов открытия новых препаратов с использованием искусственного интеллекта»), обобщающая эти исследования и приходящая к неутешительному выводу, что современные мощности нейронных сетей уже создали условия для возникновения биохимического терроризма.
Более того, с учетом оптимизации сродства лигандов к белкам и технологии DeepBAR, описанной выше, технология проектирования вредоносных препаратов может найти широкое применение в производстве синтетических наркотиков, которые будут вызывать более острые ощущения и более быстрое привыкание, чем их известные аналоги. Также эта технология могла бы применяться для производства препаратов, подавляющих волю, «сывороток правды», а также «веществ-меток», которые могли бы использоваться для поиска человека по биохимическому анализу крови и при этом очень плохо выводились бы из организма.
Хотелось бы заблуждаться в столь мрачных прогнозах, но даже беглый анализ, представленный в этой статье, позволяет оценить как перспективы, так и опасность применения нейронных сетей в биохимии. Очевидно, что органика – это во многом комбинаторика, и в такой комбинаторике искусственный интеллект сейчас непозволительно превосходит все предохранительные и регулирующие меры, которые мы могли бы принять.
Комментарии (5)

Blackjaguar1982
27.04.2022 16:48+1А теперь к каждому из 40000 веществ ищем антидот

vassabi
27.04.2022 18:57мда .. судя по всему - вариант "улететь на Марс" окажется и дешевле по деньгам и быстрее для внедрения :)

TsarS
Ну это неизбежность. Любым инструментом можно убить.
Скажите, а есть какие-нибудь библиотеки попроще - скажем, просто набор веществ присутствующих в организме человека с своими свойствами? Ну не "пятиуглеродный мевалонат превращается в активный изопреноид", а просто "холестерин"? Без молекулярных графов
bbs12
Но не каждым инструментом можно убить всё живое на Земле. В теории ИИ обладает таким потенциалом. Но я всё равно считаю, что развивать ИИ нужно, у нас нет пути назад, но нужен тщательный контроль научного сообщества.